🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
目录

OpenAI 终于开源了GPT 级大型语言模型,这是自 GPT-2 以来的首次。全新的GPT-OSS系列(开源系列的简称)包含两个模型:gpt-oss-120b(约 1200 亿个参数)和gpt-oss-20b(约 200 亿个参数)。这些模型不仅具备GPT-4 级别的推理能力,还针对GPT在现代硬件上的本地运行进行了优化。在本文中,我们将深入分析 GPT-OSS 的架构(包括其混合专家设计)、推理能力、性能基准,并提供在硬件上安装和运行 GPT-OSS 的分步指南。
简而言之: OpenAI GPT-OSS是一款先进的大语言模型 ,提供强大的思路链推理、编码、多语言理解和工具使用功能,所有功能均带有权重,您可以自行下载并运行。它在关键基准测试中匹敌甚至超越了类似规模的模型,可以针对自定义用例进行微调,并配备了强大的安全措施,防止滥用。
一、模型架构:混合专家 GPT 解释
GPT-OSS 建立在 GPT-3 架构之上,但引入了混合专家 (MoE)层设计,从而大幅提高容量而无需按比例增加计算量。本质上,MoE 意味着每一层都不只有一个整体式前馈网络,而是有许多“专家”网络,并且对于任何给定的输入token,只有少数专家处于活动状态。对于 GPT-OSS,每个 MoE 层在 120B 模型中包含 128 位专家,在 20B 模型中包含 32 位专家。每个 MoE 层中学习到的路由器会为每个令牌的数据挑选前 4 位专家,并且只使用这些专家的参数(由路由器分数加权)。这样,模型的有效容量非常大,但每个token的活动计算量却低得多。例如,gpt-oss-120b 总共有 116.8B 参数,但每个token仅激活约 5.1B 参数(因为仅使用了 128 位专家中的 4 位)。规模较小的gpt-oss-20b同样拥有 20.9B 的总内存,每个 token 约 3.6B 的活跃内存(32 位专家中的 4 位)。这种 MoE 设计兼具两者的优势:既能高效处理复杂任务,又能更高效地进行推理,因为许多参数对于任何给定的查询都处于闲置状态。
Transformer 与 LLM 中的混合专家的视觉解释:
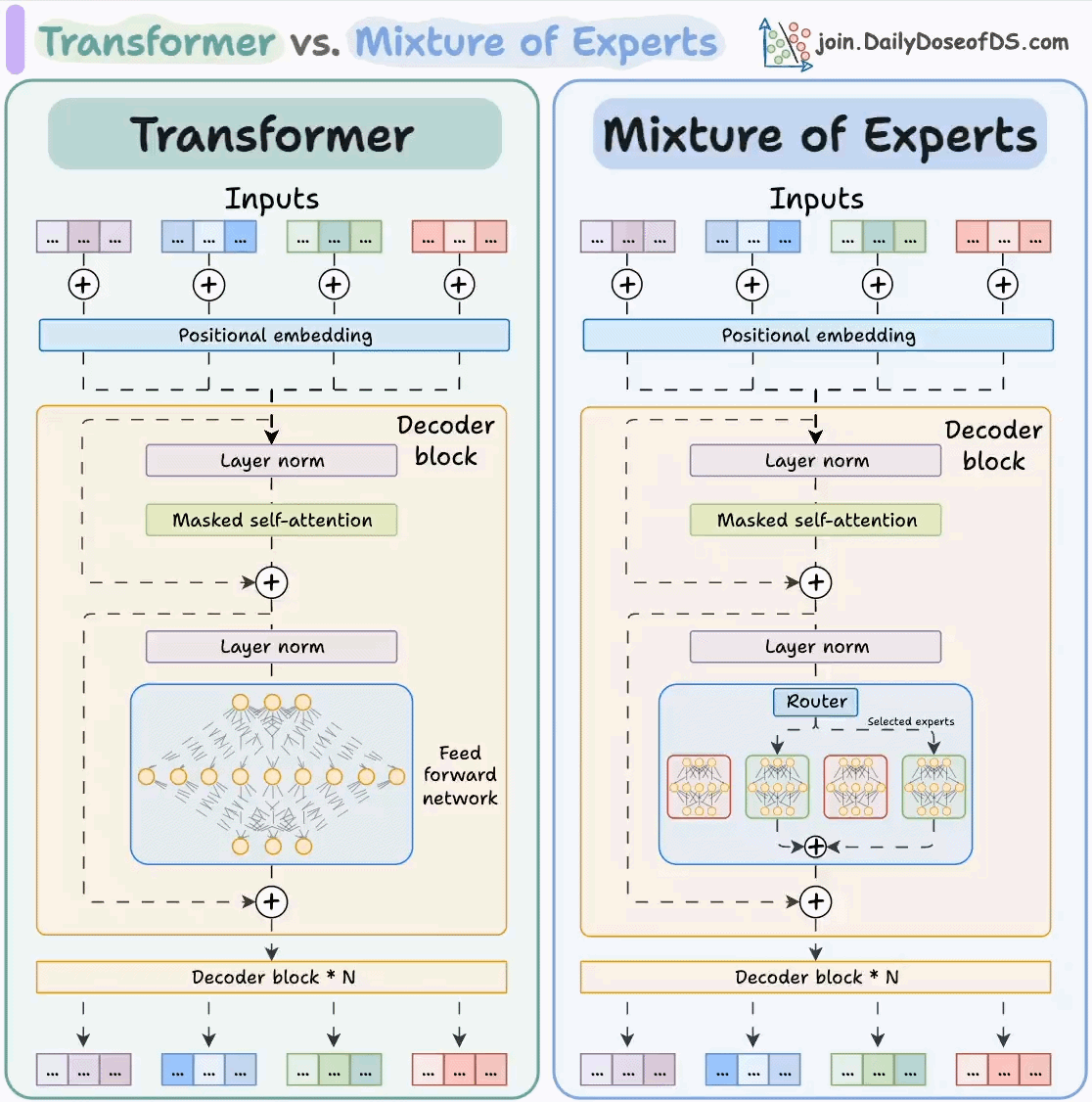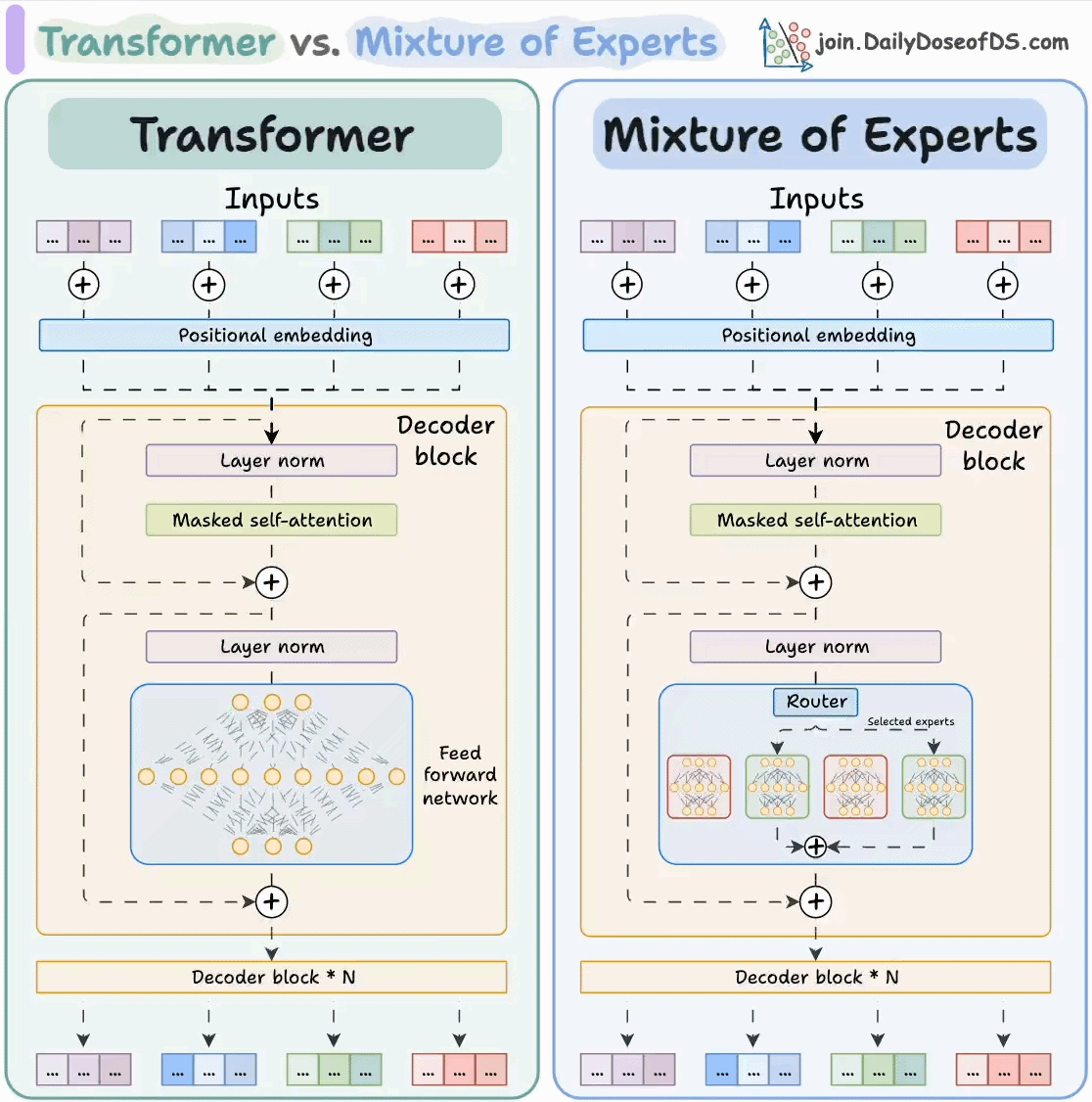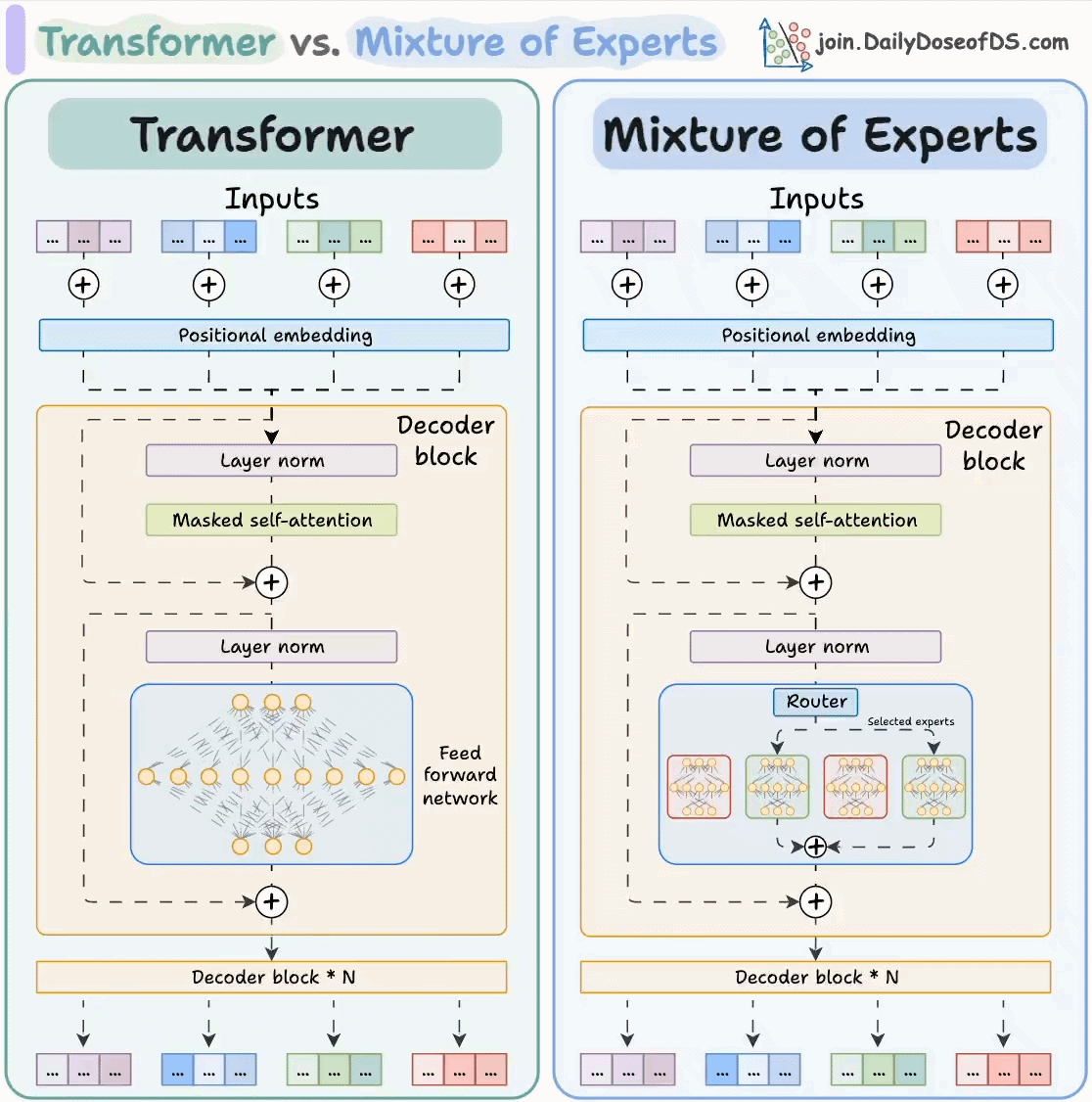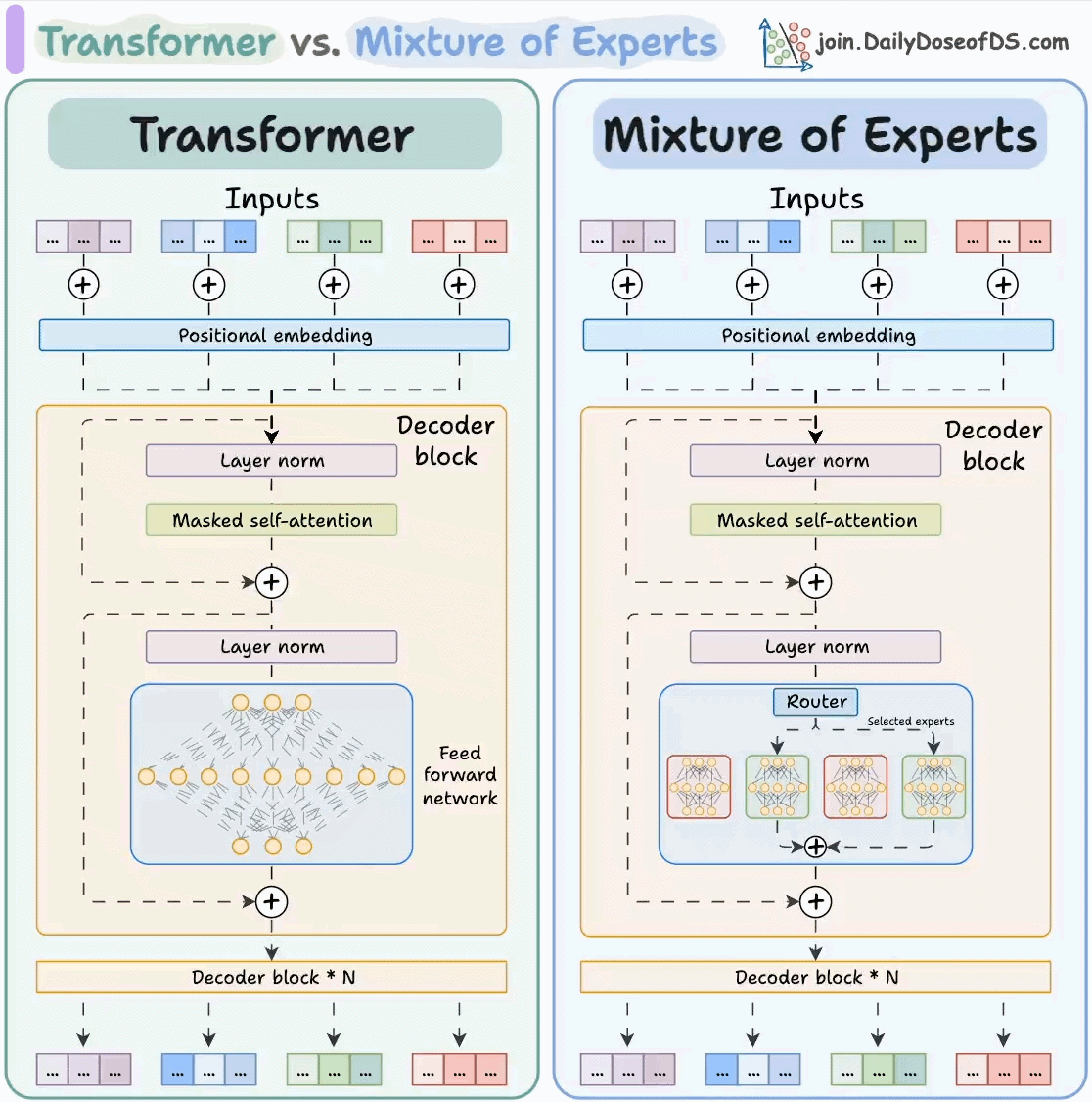
transformer 对比混合专家模型
实际上,GPT-OSS 的架构是一个 36 层(用于 120B)或 24 层(20B)的 Transformer。每一层都在注意块和MoE 块之间交替。注意机制遵循 GPT-3 的交替模式方法:一层使用带状局部注意窗口(128 个标记),下一层对整个序列使用完全密集注意。该模型每层采用 64 个注意头,并使用具有 8 个键值头组的分组查询注意(GQA)来提高效率。OpenAI 还添加了旋转位置嵌入(RoPE)用于位置编码,并使用一种名为 YaRN 的技术将模型的上下文长度扩展至 128k 个标记(是的,128,000 个标记)。这个极长的上下文窗口意味着 GPT-OSS 可以轻松处理长文档或多轮推理(作为参考,128k 个标记大约是 100,000 个单词的文本)。
| 模型 | 层数 | 总参数量 | 激活参数量 | 每个MoE层专家(总计/激活) | 上下文长度 | 所需内存 |
| gpt-oss-120b | 36 | 1168亿 | 51亿 | 128/4 | 128k | 80G |
| gpt-oss-20b | 24 | 209亿 | 36亿 | 32/4 | 128k | 16G |
工具使用:
工具使用是 GPT-OSS 的一项重要功能。在微调过程中,模型学习了如何在需要时调用外部函数(工具)来查找信息或执行计算。训练过程中主要使用了三种工具:
- 浏览工具(网页搜索和打开);该模型可以发出搜索查询并从网页获取内容。这有助于它回答超出其训练范围的最新信息问题,并通过核查来源来提高事实准确性。
- Python 执行工具:该模型可以在沙盒(类似于有状态的 Jupyter Notebook 环境)中编写和运行 Python 代码。这使得它可以在回答问题的过程中进行计算、数据分析或任何可编程任务。本质上,它可以“编写脚本”来解决问题,然后返回结果。
- 自定义工具(开发者定义函数):开发者可以定义任意 API 函数(带有模式),并通过开发者消息将其提供给 GPT-OSS。该模型经过训练,可以通过将函数调用输出格式化为Harmony 格式来根据需要调用这些函数。这类似于 OpenAI 在 API 中的函数调用。GPT-OSS 可以灵活地交织思路推理、函数调用、工具输出和用户可见的答案。
该模型学会了决定何时使用工具,何时可以直接回答问题。例如,对于复杂的事实问题,它可能会调用浏览工具来查找答案;对于数学问题,它可能会使用 Python 工具进行精确计算。Harmony格式通过赋予每个工具一个角色(模型“模拟”该工具,然后以消息的形式接收工具的输出)来实现这些交互。OpenAI 已经开源了这些工具的参考实现(一个简单的浏览器和一个 Python 沙盒),以便开发人员可以轻松地复现模型的训练设置。
为了在使用 GPT-OSS 时获得最佳效果,您应该在提示中采用这种和谐聊天格式,或者使用实现它的库。OpenAI 提供了一个Harmony 库(使用 Python 和 Rust 编写)来帮助正确格式化对话。例如,当您开始新的聊天会话时,通常会发送一条系统消息来建立上下文,甚至可能确定推理级别。然后,用户消息和助手响应将被适当包装。此外,在发送新的提示时,您应该删除模型在之前回合中的推理和工具使用痕迹(该模型经过训练,不会看到其过去的“分析”内容,只会看到最终答案)。开源 Harmony 指南提供了一些示例(GPT-OSS 模型卡附录展示了此格式的完整输入/输出示例)。如果使用 OpenAI 提供的聊天客户端或第三方 UI(如 LM Studio 或 Ollama),则会为您处理此格式。关键要点是:GPT-OSS 可以遵循复杂的多轮指令、利用工具并提供其思路链,但它希望对话以 Harmony 格式构建,以使这些功能发挥最佳作用。
二、性能基准和用例
OpenAI 对 GPT-OSS 进行了一系列标准基准测试,涵盖数学、科学推理、编程、工具使用、多语言理解,甚至医学知识。测试结果令人印象深刻;GPT-OSS 的表现常常匹敌甚至超越之前被认为是最先进水平的模型。以下是其性能亮点和潜在用例:
- 复杂推理与数学(竞赛题)
- 常识和质量保证
- 编码和编程协助
- 代理工具的使用
- 多语言理解
- 医疗保健和医疗质量保证
三、本地运行 GPT-OSS:安装和硬件指南
GPT-OSS 最大的吸引力之一是能够在您自己的硬件或基础架构上本地运行 GPT 模型。OpenAI 提供了模型权重和参考代码,使这一过程尽可能简单易行。在本节中,我们将逐步介绍安装和运行 GPT-OSS 的步骤,并讨论 120B 和 20B 版本的硬件要求和选项。
硬件要求和建议
- GPT-OSS-120B(116.8B 参数):需要一个 80GB 的 GPU(NVIDIA A100 80GB、H100 80GB 等)或多个并行的小型 GPU。该模型设计为在使用优化的 4 位内核时可容纳 80GB 内存。如果您没有单个 80GB 的显卡,则可以使用 2 个或 4 个具有足够组合内存的 GPU(参考 PyTorch 实现支持将 MoE 专家分片到各个 GPU)。例如,4 个 24GB 的 GPU(例如 4 个 RTX 3090/4090 或 A6000)可以通过分担负载来运行 120B。但是,多 GPU 设置更为复杂,并且需要快速互连(NVLink 或至少 PCIe Gen4)才能获得最佳效果。另一种方法是使用提供 80GB GPU 的云实例。由于 OpenAI 与各种硬件供应商合作以确保兼容性,因此还支持在Cerebras等专用硬件上运行。
- 总结一下:要运行 120B,需要大约 80GB 的 GPU 内存,无论是通过一个大 GPU 还是串联几个较小的 GPU。
- GPT-OSS-20B(20.9B 个参数):此模型运行起来更容易。它只需要大约 16GB 内存(GPU 或系统 RAM)。这意味着它可以在多种消费级 GPU 上运行(例如,24GB 的 NVIDIA RTX 3090、16GB 的 RTX 4080 等,或任何大于等于 16GB 的 GPU)。它甚至可以在高内存的笔记本电脑上以 CPU 模式运行,尽管在没有 GPU 的情况下推理速度会很慢。Apple Silicon 用户:20B 可以在使用 Metal 后端(如下所述)的M1/M2 等 Mac上运行。小型模型非常适合 GPU 资源有限的本地用例——例如在本地服务器、边缘设备,甚至是您的游戏 PC 上运行,以提供私人 AI 辅助。
- 仅限 CPU 和其他硬件:虽然建议使用 GPU(为了提高速度),但由于 GPT-OSS 的权重精度较低,因此也可以在 CPU 上运行。像 llama.cpp 这样的库已经支持在 CPU 上运行这种规模的模型,并采用 4 位量化。CPU 上的生成速度可能会慢得多(每个 token 需要数秒),但可以用于原型设计。此外,Windows 上还通过微软的版本支持 ONNX 运行时(OpenAI 与微软合作,使 GPT-OSS-20B 能够通过 ONNX 和 DirectML 在 Windows 设备上运行)。因此,Windows 开发者可以通过这种方式(例如通过 VS Code 的 AI 工具包)在消费级 GPU 上利用 GPU 加速。
如果您的 GPU 显存小于 16GB(例如 8GB 或 12GB),您可能需要使用优化的推理库(例如 vLLM 或 DeepSpeed)或进一步量化/下采样模型。但由于 GPT-OSS 已经量化,除非使用 CPU 内存作为交换,否则标准的 8GB 显卡可能无法处理 20B 模型。大多数拥有 12GB 以上显存的现代显卡应该能够使用内存优化技术来处理 20B 模型。
软件设置和安装
OpenAI 已开源gpt-oss GitHub 代码库,其中包含可在多种环境下进行推理的参考实现。您可以根据自己的平台和偏好,选择几种方式开始使用。
两种 gpt-oss 模型均可在 Hugging Face:1 上使用。
openai/gpt-oss-20b
- 使用 MXFP4 时需要约 16GB VRAM
- 非常适合单个高端消费级 GPU
openai/gpt-oss-120b
- 需要≥60GB VRAM 或多 GPU 设置
- 非常适合 H100 级硬件
两者默认均采用 MXFP4 量化。请注意,Hopper 及更高版本的架构支持 MXFP4。这包括 H100 或 GB200 等数据中心 GPU,以及最新的 RTX 50xx 系列消费级显卡。
如果使用
bfloat16MXFP4,内存消耗会更大(20b 参数模型约为 48 GB)。
软件设置
- 安装依赖项
建议创建一个全新的 Python 环境。安装 transforms、accelerator 以及用于兼容 MXFP4 的 Triton 内核:
pip install -U transformers accelerate torch triton kernelspip install git+https://github.com/triton-lang/triton.git@main#subdirectory=python/triton_kernels创建 Open AI Responses/Chat Completions服务
要启动服务器(https://huggingface.co/docs/transformers/main/serving),只需使用transformers serveCLI 命令:
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b四、使用管道进行快速推理
运行 gpt-oss 模型最简单的方法是使用 Transformers 高级pipelineAPI:
from transformers import pipeline
generator = pipeline(
"text-generation",
model="openai/gpt-oss-20b",
torch_dtype="auto",
device_map="auto" # Automatically place on available GPUs
)
messages = [
{"role": "user", "content": "Explain what MXFP4 quantization is."},
]
result = generator(
messages,
max_new_tokens=200,
temperature=1.0,
)
print(result[0]["generated_text"])
五、聊天模板和工具调用
OpenAI gpt-oss 模型使用harmony格式来构造消息,包括推理和工具调用。
要构建提示,您可以使用 Transformers 的内置聊天模板。或者,您可以安装并使用openai-harmony来获得更多控制。
要使用聊天模板:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "openai/gpt-oss-20b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="auto",
)
messages = [
{"role": "system", "content": "Always respond in riddles"},
{"role": "user", "content": "What is the weather like in Madrid?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to(model.device)
generated = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(generated[0][inputs["input_ids"].shape[-1] :]))要集成openai-harmony库来准备提示和解析响应,首先要像这样安装它:
pip install openai-harmony以下是如何使用该库构建提示并将其编码为标记的示例:
import json
from openai_harmony import (
HarmonyEncodingName,
load_harmony_encoding,
Conversation,
Message,
Role,
SystemContent,
DeveloperContent
)
from transformers import AutoModelForCausalLM, AutoTokenizer
encoding = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
# Build conversation
convo = Conversation.from_messages([
Message.from_role_and_content(Role.SYSTEM, SystemContent.new()),
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions("Always respond in riddles")
),
Message.from_role_and_content(Role.USER, "What is the weather like in SF?")
])
# Render prompt
prefill_ids = encoding.render_conversation_for_completion(convo, Role.ASSISTANT)
stop_token_ids = encoding.stop_tokens_for_assistant_action()
# Load model
model_name = "openai/gpt-oss-20b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
# Generate
outputs = model.generate(
input_ids=[prefill_ids],
max_new_tokens=128,
eos_token_id=stop_token_ids
)
# Parse completion tokens
completion_ids = outputs[0][len(prefill_ids):]
entries = encoding.parse_messages_from_completion_tokens(completion_ids, Role.ASSISTANT)
for message in entries:
print(json.dumps(message.to_dict(), indent=2))请注意,DeveloperHarmony 中的角色映射到system聊天模板中的提示。
vLLM
vLLM 建议使用uv进行 Python 依赖项管理。您可以使用 vLLM 启动与 OpenAI 兼容的 Web 服务器。以下命令将自动下载模型并启动服务器。
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-matchvllm serve openai/gpt-oss-20bOllama
如果您尝试在消费类硬件上运行 gpt-oss,则可以在安装 Ollama后运行以下命令来使用 Ollama 。
# gpt-oss-20b
ollama pull gpt-oss:20b
ollama run gpt-oss:20b六、微调
两种 gpt-oss 模型都可以针对各种特殊用例进行微调。
这个较小的模型gpt-oss-20b可以在消费硬件上进行微调,而较大的模型gpt-oss-120b可以在单个 H100 节点上进行微调。
七、结论
GPT-OSS标志着一个里程碑:OpenAI 通过发布功能强大且可供任何人免费使用和修改的模型,验证了开源 LLM 方法。对于开发者而言,GPT-OSS 提供了构建高级 AI 应用程序的机会,无需 API 访问或支付使用费,从而支持从离线个人助理到安全的内部部署企业机器人,再到可解释性和对齐等领域的研究。
这些模型将顶级的推理和编码能力、工具集成以及多语言能力带入开放领域。借助 OpenAI 的安全训练,这些模型的部署相对安全。我们现在有一个强大的开源 GPT-4 替代方案可供实验,并且期待看到社区如何对 GPT-OSS 进行微调和扩展——或许会催生出新的专用模型或改进。