一、基于 kubernetes 的 Prometheus 介绍
1、环境简介
node - exporter + prometheus + grafana 是一套非常流行的 Kubernetes 监控方案
| 组件 | 功能描述 |
|---|---|
| node - exporter | 节点级指标导出工具,可监控节点的 CPU、内存、磁盘、网络等指标,暴露 Metrics 接口 |
| Prometheus | 时间序列数据库和监控报警工具,抓取 Cadvisor 和 node - exporter 暴露的 Metrics 接口,存储时序数据,提供 PromQL 查询语言进行监控分析和报警 |
| Grafana | 图表和 Dashboard 工具,查询 Prometheus 中的数据,以图表方式直观展示 Kubernetes 集群的运行指标和状态 |
2、监控流程
(1) 在 Kubernetes 集群的每个节点安装 Cadvisor 和 node - exporter,用于采集容器和节点级指标数据。
(2) 部署 Prometheus,配置抓取 Cadvisor 和 node - exporter 的 Metrics 接口,存储 containers 和 nodes 的时序数据。
(3) 使用 Grafana 构建监控仪表盘,选择 Prometheus 作为数据源,编写 PromQL 查询语句,展示 K8S 集群的 CPU 使用率、内存使用率、网络流量等监控指标。
(4) 根据监控结果,可以设置 Prometheus 的报警规则,当监控指标超过阈值时发送报警信息。这套方案能够全面监控 Kubernetes 集群的容器和节点,通过 Metrics 指标和仪表盘直观反映集群状态,并实现自动报警,非常适合 K8S 环境下微服务应用的稳定运行。
具体实现方案如下:
| 组件 | 运行方式与作用 |
|---|---|
| node - exporter | 在每个节点作为 DaemonSet 运行,采集节点 Metrics |
| Prometheus | 部署 prometheus Operator 实现,作为 Deployment 运行,用于抓取 Metrics 和报警 |
| Grafana | 部署 Grafana Operator 实现,用于仪表盘展示 |
3、Kubernetes 监控指标
| 指标类型 | 具体指标内容 | 用途 |
|---|---|---|
| CPU 利用率 | 节点 CPU 利用率、Pod CPU 利用率、容器 CPU 利用率等 | 监控 CPU 资源使用情况 |
| 内存利用率 | 节点内存利用率、Pod 内存利用率、容器内存利用率等 | 监控内存资源使用情况 |
| 网络流量 | 节点网络流量、Pod 网络流量、容器网络流量 | 监控网络收发包大小和带宽利用率 |
| 磁盘使用率 | 节点磁盘使用率 | 监控节点磁盘空间使用情况 |
| Pod 状态 | Pod 的 Running、waiting、Succeeded、Failed 等状态数量 | 监控 Pod 运行状态 |
| 节点状态 | 节点的 Ready、NotReady 和 Unreachable 状态数量 | 监控节点运行状态 |
| 容器重启次数 | 单个容器或 Pod 内所有容器的重启次数 | 监控容器稳定性 |
| API 服务指标 | Kubernetes API Server 的请求 LATENCY、请求 QPS、错误码数量等 | 监控 API Server 性能 |
| 集群组件指标 | etcd、kubelet、kube - proxy 等组件的运行指标 | 监控组件运行状态 |
这些都是 Kubernetes 集群运行状态的关键指标,通过 Prometheus 等工具可以进行收集和存储,然后在 Grafana 中设计相应的 Dashboard 进行可视化展示。当这些指标超出正常范围时,也可以根据阈值设置报警,保证 Kubernetes 集群和服务的稳定运行。
二、Prometheus的安装
1、从Github克隆项目分支
git clone -b release-0.10 https://github.com/prometheus-operator/kube-prometheus.git2、安装 Prometheus Operator
Prometheus Operator 是 CoreOS 开源的项目,它提供了一种 Kubernetes-native 的方式来运行和管理 Prometheus。Prometheus Operator 可以自动创建、配置和管理 Prometheus 实例,并将其与 Kubernetes 中的服务发现机制集成在一起,从而实现对 Kubernetes 集群的自动监控。
Prometheus 和 Prometheus Operator 的区别如下:
Prometheus 是一种开源的监控系统,用于记录各种指标,并提供查询接口和告警机制。而 Prometheus Operator 则是一种用于在 Kubernetes 上运行和管理 Prometheus 的解决方案。相比于传统方式手动部署 Prometheus,Prometheus Operator 可以自动创建、配置和管理Prometheus 实例,并将其与 Kubernetes 中的服务发现机制集成在一起,大幅简化了我们的工作量。
prometheus-operator 的作用主要是用来创建 prometheus 的相关资源以及监视与管理它创建出来的资源对象。
cd kube-prometheus/
ku apply --server-side -f manifests/setup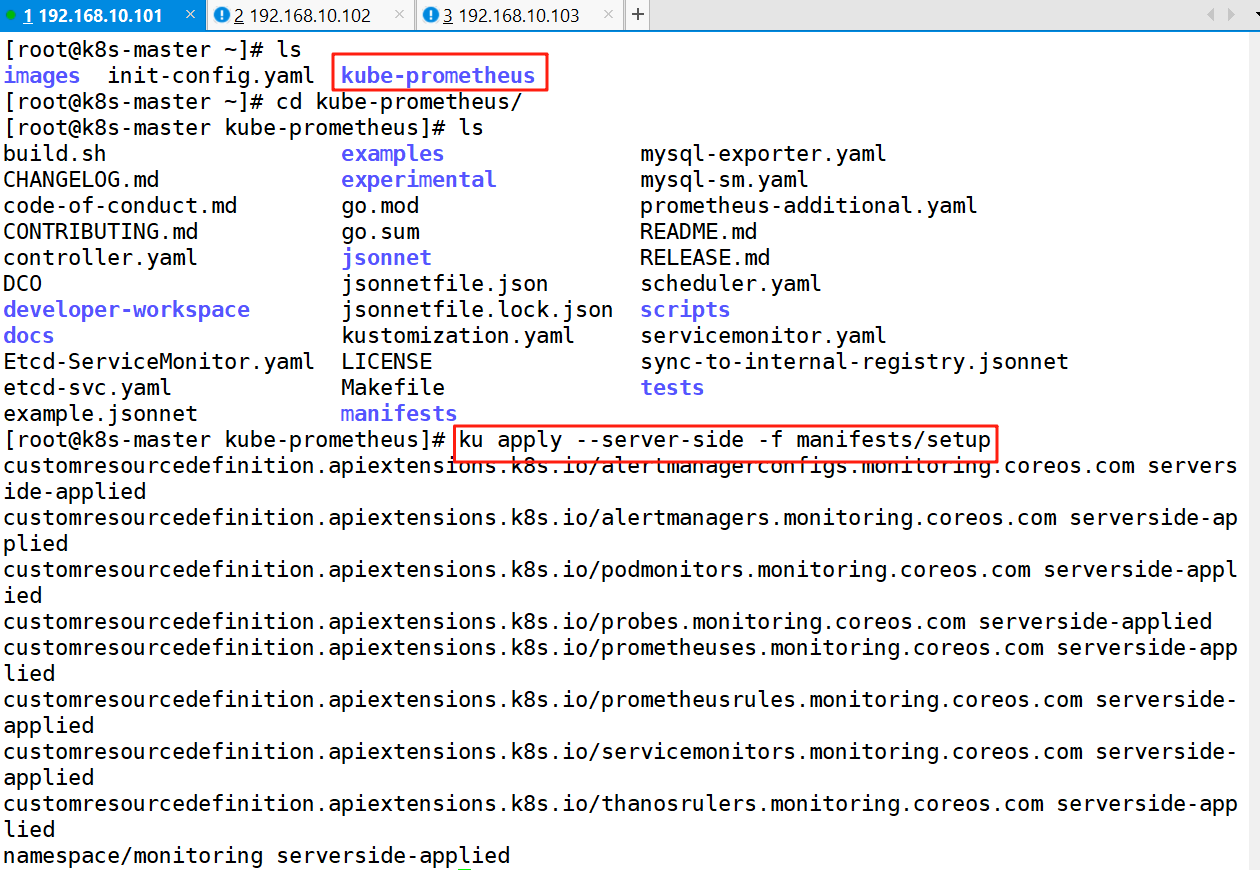
--server-side
这个特性主要目标是把逻辑从 kubectl apply 移动到 kube-apiserver 中,这可以修复当前遇到的很多有关所有权冲突的问题。
可以直接通过 API 完成声明式配置的操作,而无需依赖于特定的 kubectl apply 命令
3、删除 Prometheus Operator
ku delete --ignore-not-found=true -f /root/kube-prometheus/manifests/setup4、安转Prometheus-stack
kube-prometheus-stack 是一个全家桶,提供监控告警组件 alert-manager、grafana 等子组件。
ku apply --server-side -f manifests/5、删除Prometheus-stack
ku delete --ignore-not-found=true -f /root/kube-prometheus/manifests/ -f /root/kube-prometheus/manifests/setup6、查看Prometheus容器的状态
ku get pod -n monitoring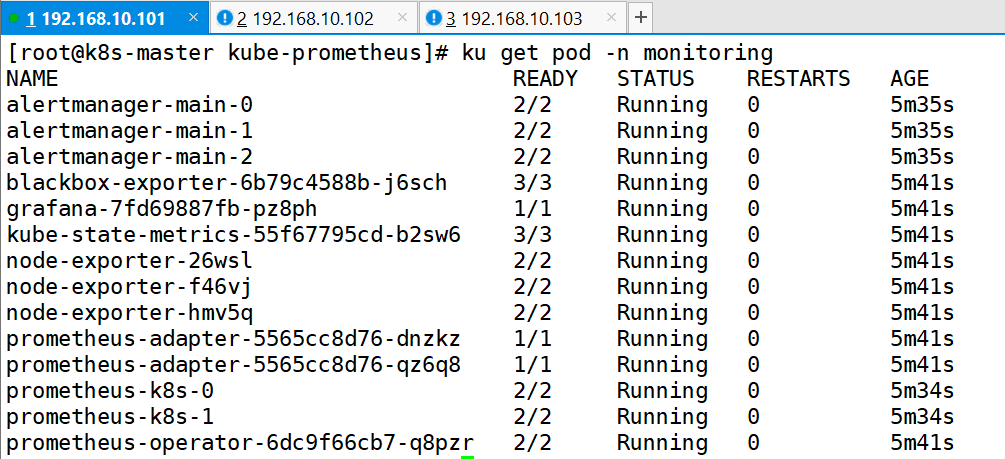
7、查看servicemonitors
| servicemonitors目的 | 具体内容 |
|---|---|
| 动态发现目标 | 自动识别需要监控的 Kubernetes Service 及其关联的 Pod |
| 配置抓取规则 | 定义 Prometheus 如何抓取这些目标的指标(如端口、路径、间隔时间等) |
| 关联 Prometheus 实例 | 通过标签选择器与 Prometheus 实例绑定,使配置生效 |
servicemonitors 定义了如何监控一组动态的服务,使用标签选择来定义哪些 Service 被选择进行监控。这可以让团队制定一个如何暴露监控指标的规范,然后按照这些规范自动发现新的服务,而无需重新配置。
为了让 Prometheus 监控 Kubernetes 内的任何应用,需要存在一个 Endpoints 对象,Endpoints 对象本质上是 IP 地址的列表,通常 Endpoints 对象是由 Service 对象来自动填充的,Service 对象通过标签选择器匹配 Pod,并将其添加到 Endpoints 对象中。一个 Service 可以暴露一个或多个端口,这些端口由多个 Endpoints 列表支持,这些端点一般情况下都是指向一个 Pod。
Prometheus Operator 引入的这个 ServiceMonitor 对象就会发现这些 Endpoints 对象,并配置 Prometheus 监控这些 Pod。ServiceMonitorSpec 的 endpoints 部分就是用于配置这些 Endpoints 的哪些端口将被 scrape 指标的。
Prometheus Operator 使用 ServiceMonitor 管理监控配置。
ku get servicemonitors -A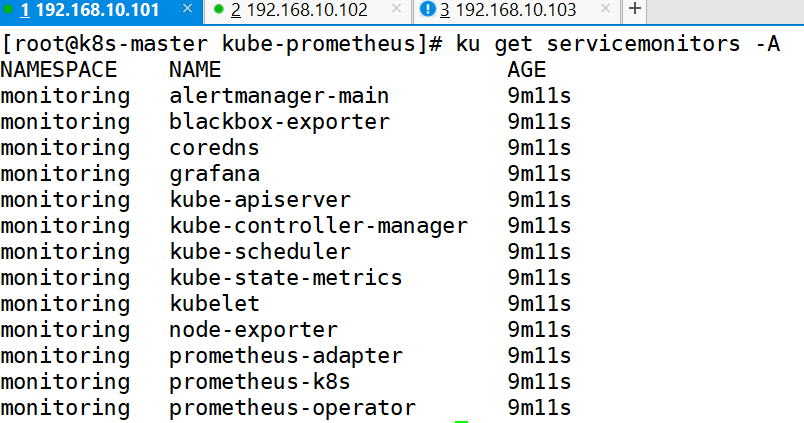
8、修grafana的Service类型为NodePort
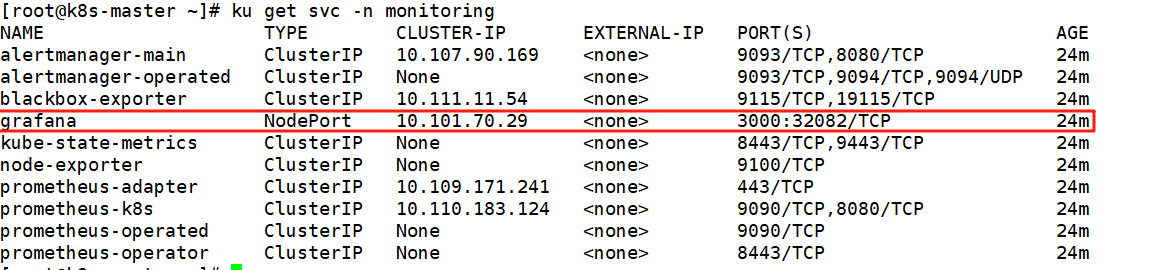
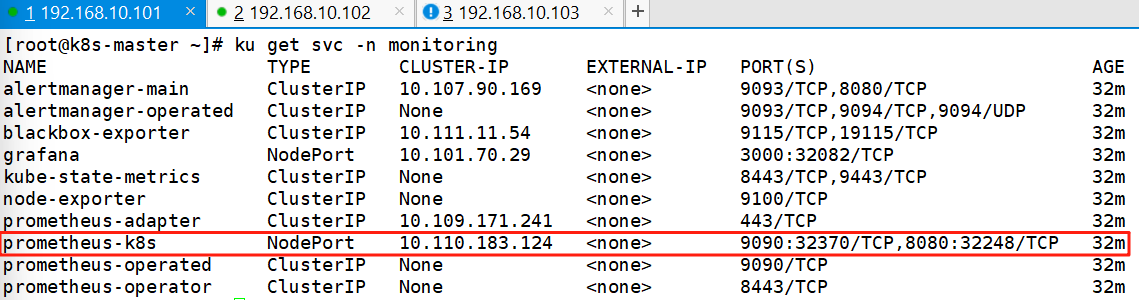
ku get svc -n monitoring
ku edit svc grafana -n monitoring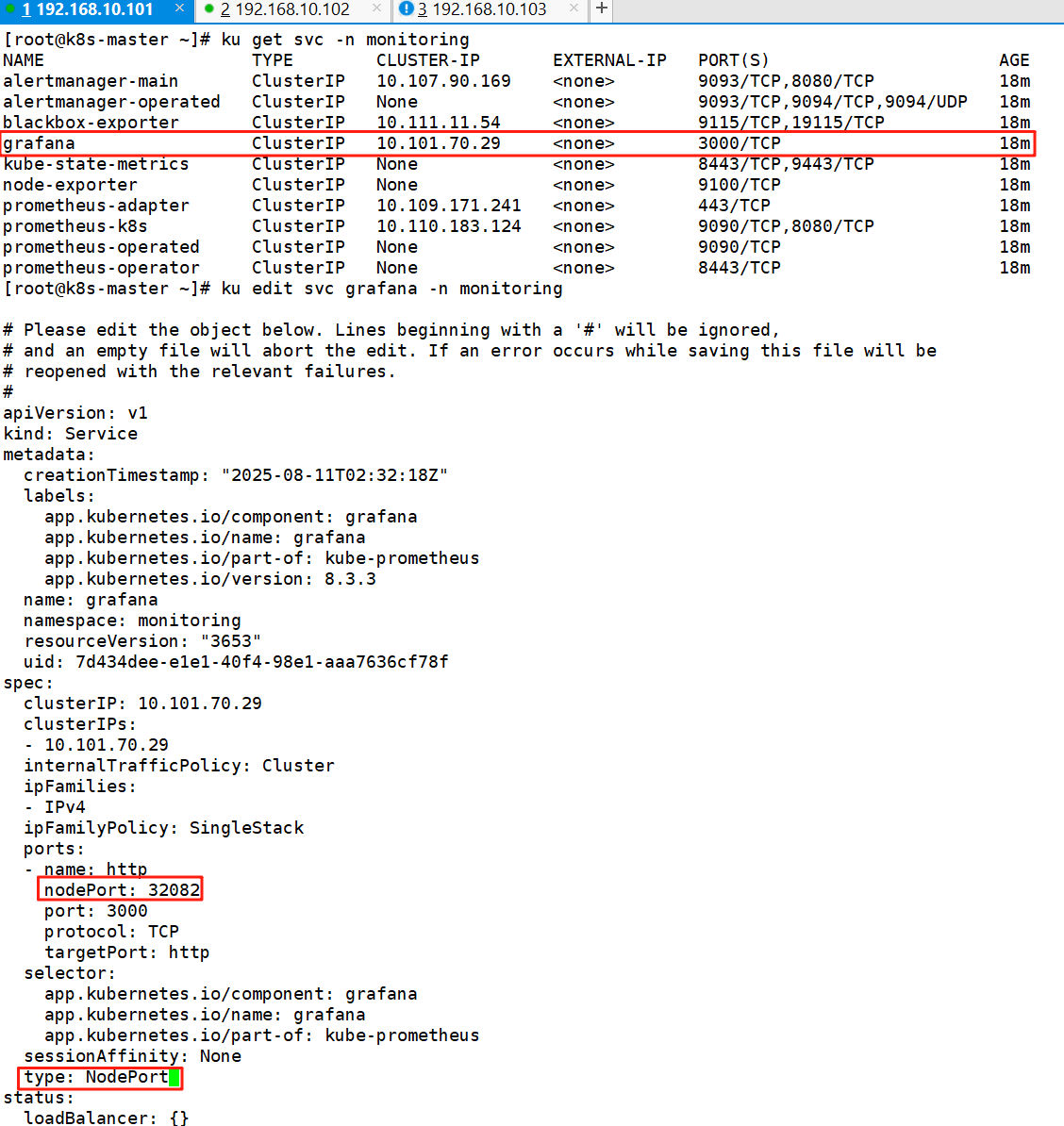
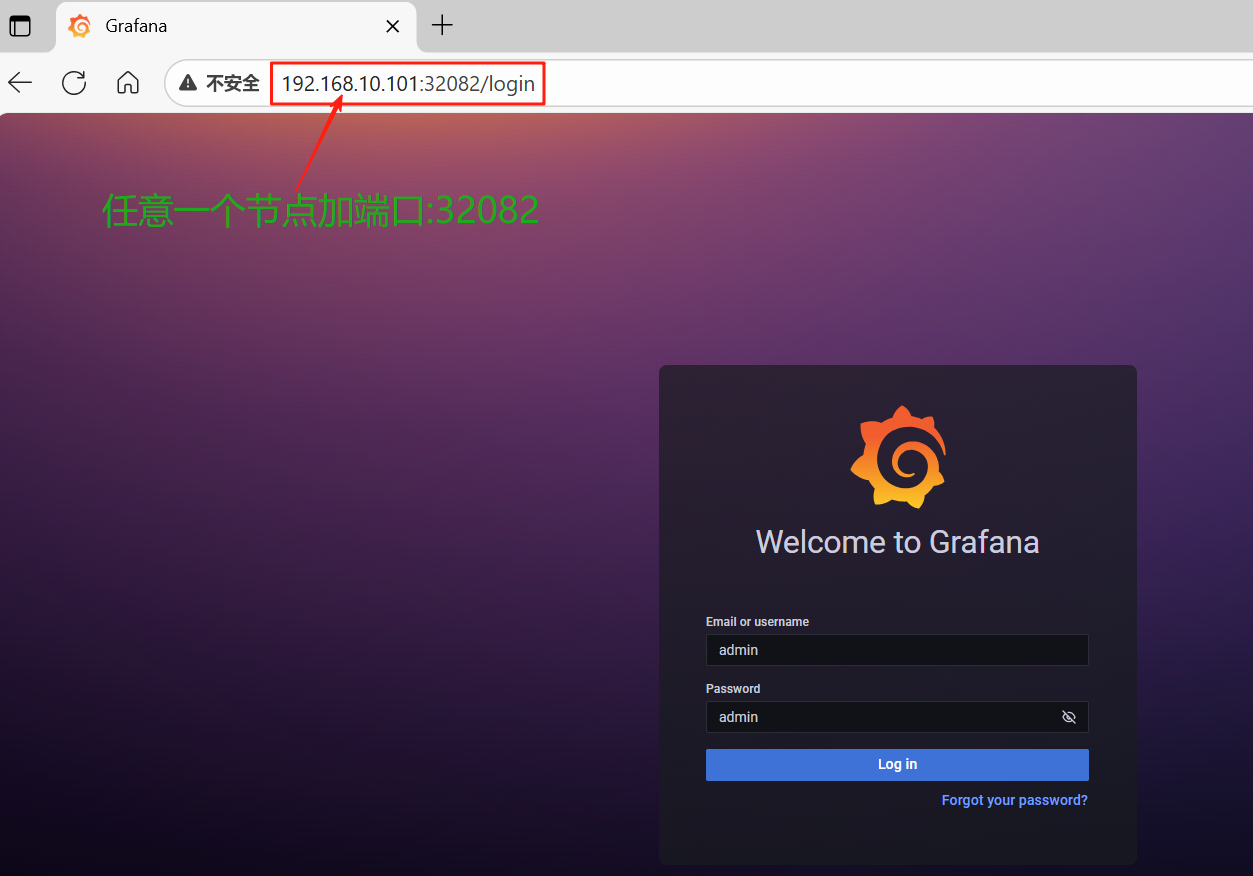
9、访问grafana
默认的登录账号密码为 admin/admin,第一次登陆会提示修改密码,不想修改可以点击 skip 跳过
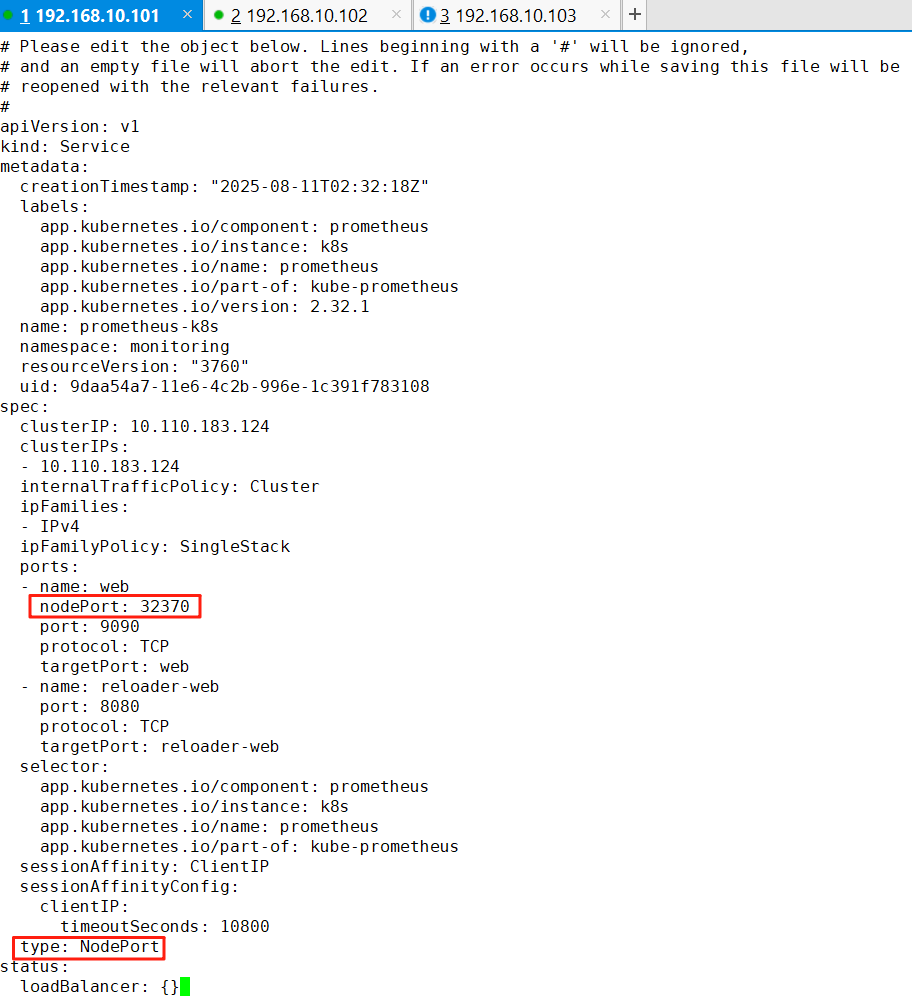
10、修改Prometheus的Service类型
ku edit svc prometheus-k8s -n monitoring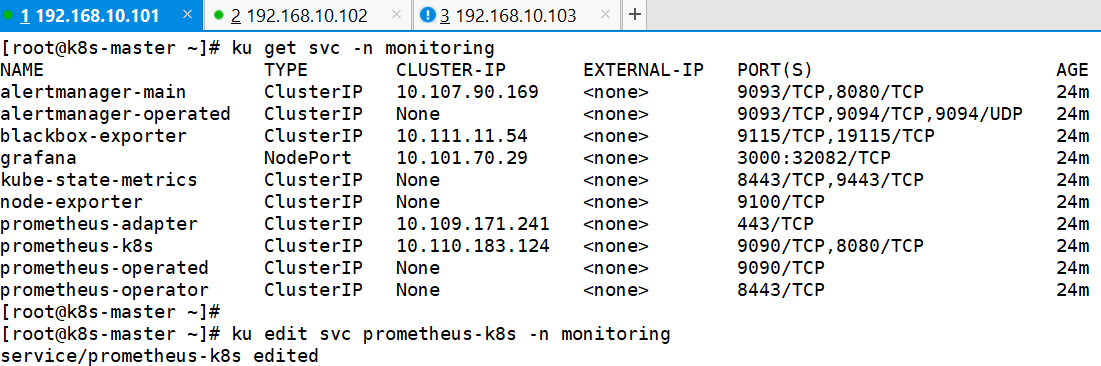
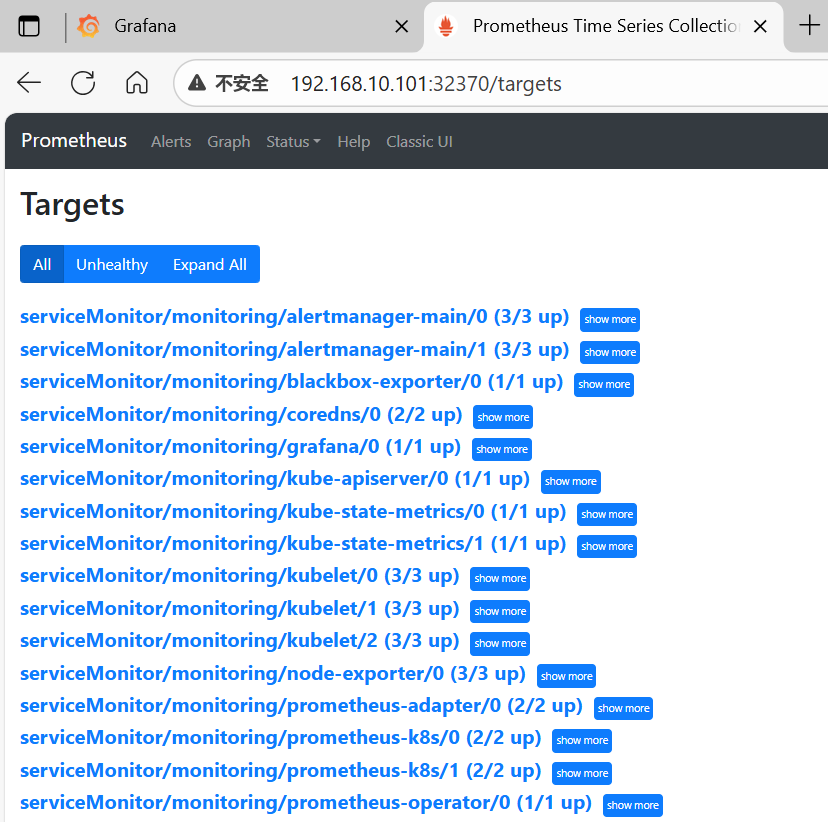
11、访问Prometheus并查看监控目标
| 状态名称 | 状态说明 |
|---|---|
| inactive | 还未被触发 |
| pending | 已经触发,但是还未达到 for 设定的时间 |
| firing | 触发且达到设定时间 |
三、配置grafana的dashboard
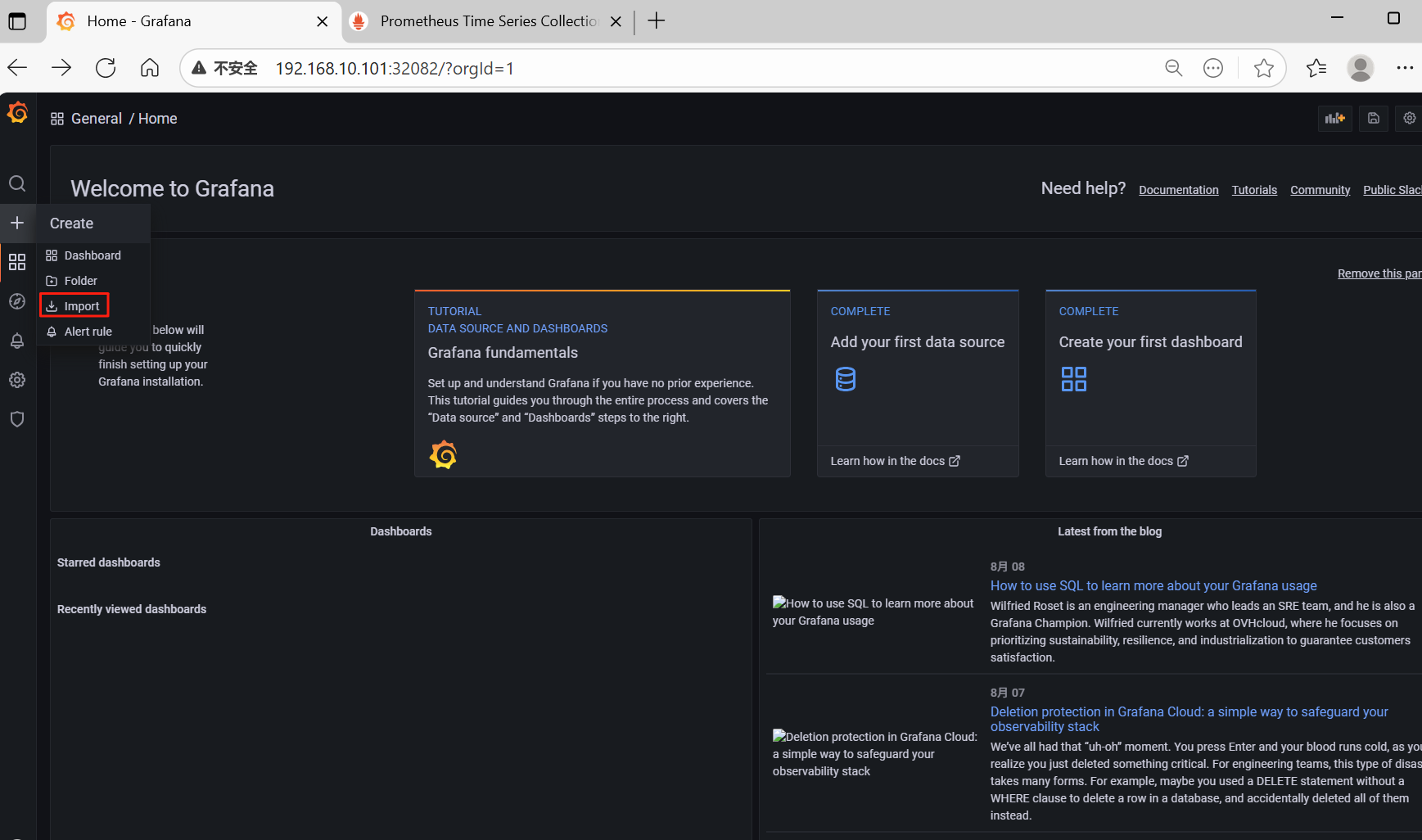
1、导入监控模板
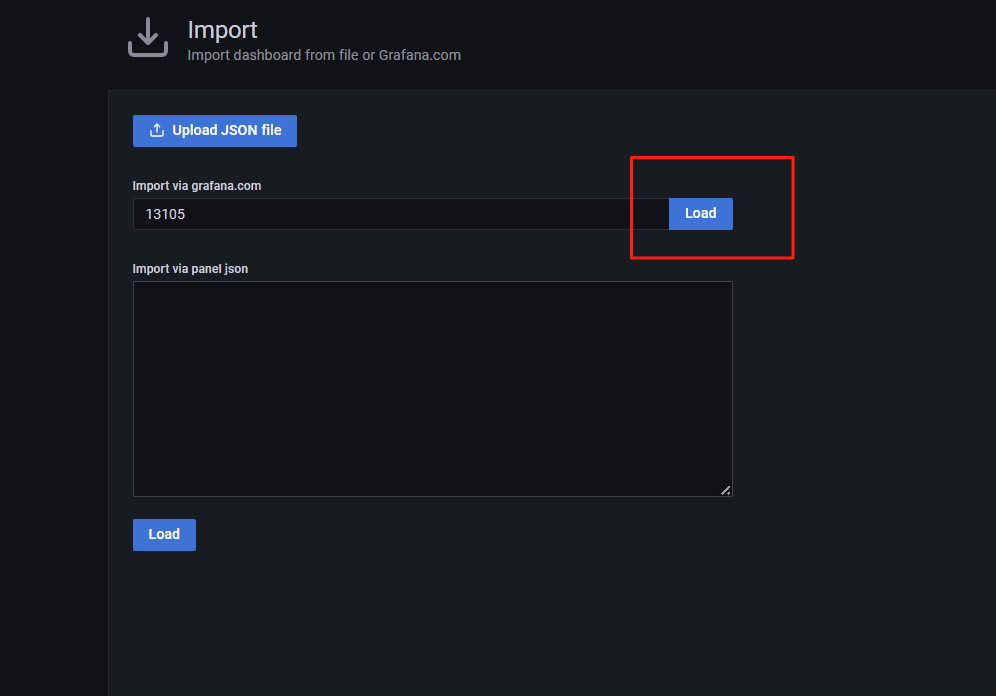
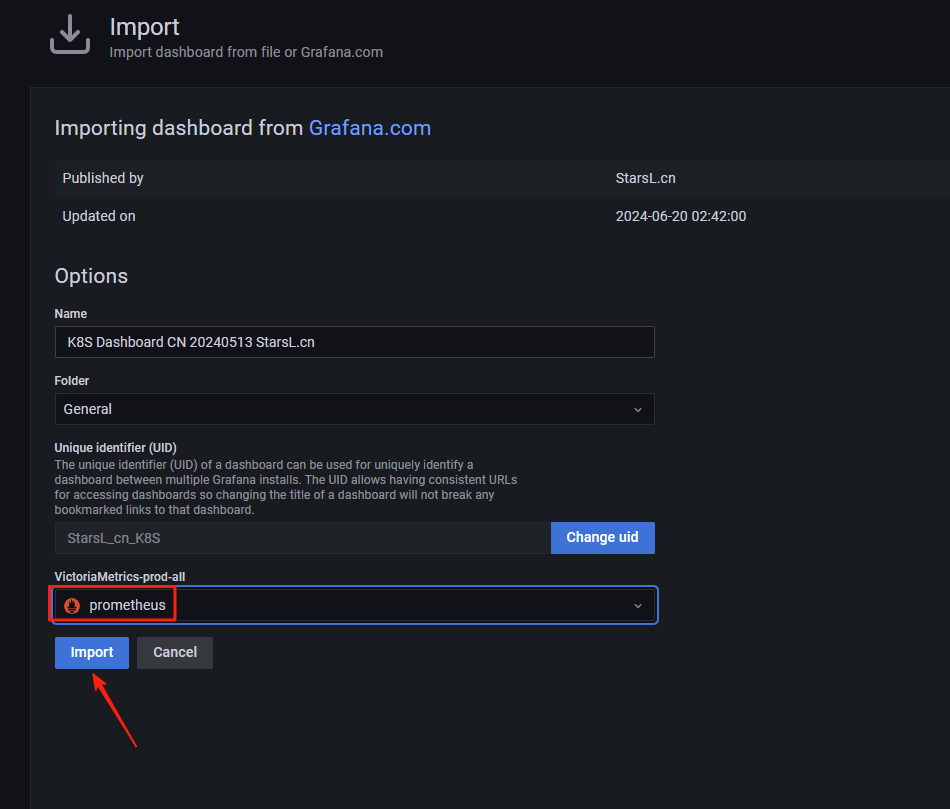
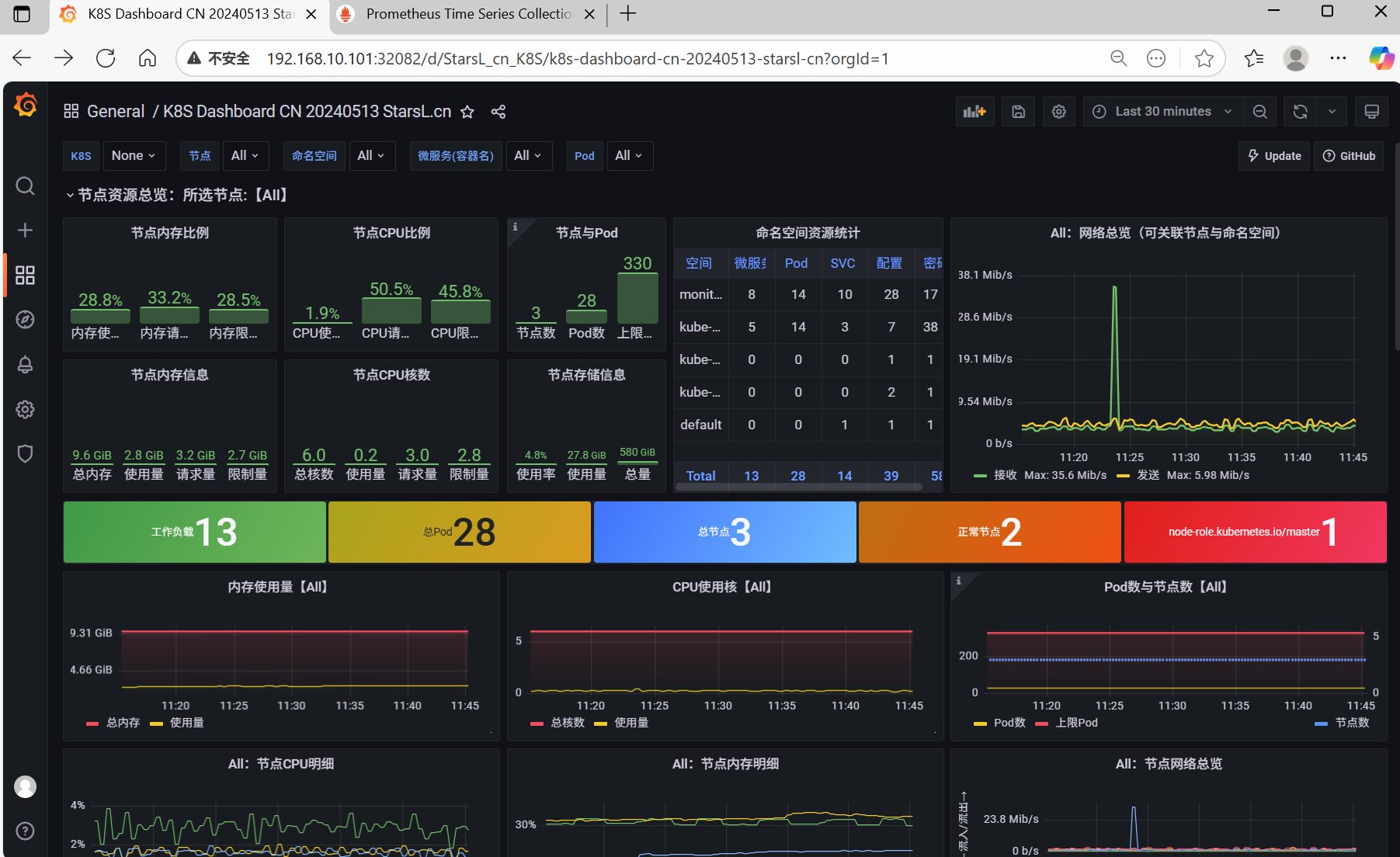
2、其他模板
官网:https://grafana.com/grafana/dashboards/
常见的模板有
Kubernetes Cluster:7249
Docker Registry:9621
Docker and system monitoring:893
K8S for Prometheus Dashboard 20211010 中文版:13105
Kubernetes Pods:4686
Linux Stats with Node Exporter:14731
四、监控 MySQL 数据库
在 Prometheus 的监控体系中,符合云原生设计理念的应用通常自带一个 Metrics 接口,这使得 Prometheus 能够直接抓取到应用的监控数据。然而,对于非云原生应用(如 MySQL、Redis、Kafka 等),由于它们并未原生暴露 Prometheus 所需的 Metrics 接口,因此我们需要借Exporter 来实现数据的采集和暴露。本案例将以 MySQL 为例,详细介绍如何通过 Exporter 实现对非云原生应用的监控,并将其集成到 Prometheus 监控体系中。
1、编辑yaml文件,创建MySQL
vim mysql.yaml
ku create -f mysql.yamlapiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
labels:
app: mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0
resources:
requests:
memory: "512Mi"
limits:
memory: "1Gi"
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "pwd123"
volumeMounts:
- mountPath: /etc/localtime
name: timezone-time
volumes:
- name: timezone-time
hostPath:
path: /etc/localtime
type: File2、创建Service暴漏MySQL的端口
ku expose deployment mysql --type NodePort --port=33063、查看
ku get pod
ku get svc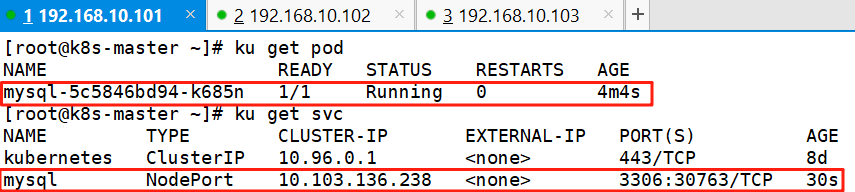
4、访问测试
dnf -y install mysql
mysql -uroot -ppwd123 -h 192.168.10.101 -P 30763
create user exporter@'%' identified by 'exporter';
grant all on *.* to exporter@'%';
flush privileges;
exit5、配置 mysql exporter 采集 mysql 监控文件
vim mysql-exporter.yamlapiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
k8s-app: mysql-exporter
template:
metadata:
labels:
k8s-app: mysql-exporter
spec:
containers:
- name: mysql-exporter
image: registry.cn-beijing.aliyuncs.com/dotbalo/mysqld-exporter
env:
- name: DATA_SOURCE_NAME
value: "exporter:exporter@(mysql.default:3306)/"
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9104
---
apiVersion: v1
kind: Service
metadata:
name: mysql-exporter
namespace: monitoring
labels:
k8s-app: mysql-exporter
spec:
type: ClusterIP
selector:
k8s-app: mysql-exporter
ports:
- name: api
port: 9104
protocol: TCP
6、创建并查看
ku create -f mysql-exporter.yaml
ku get svc -n monitoring
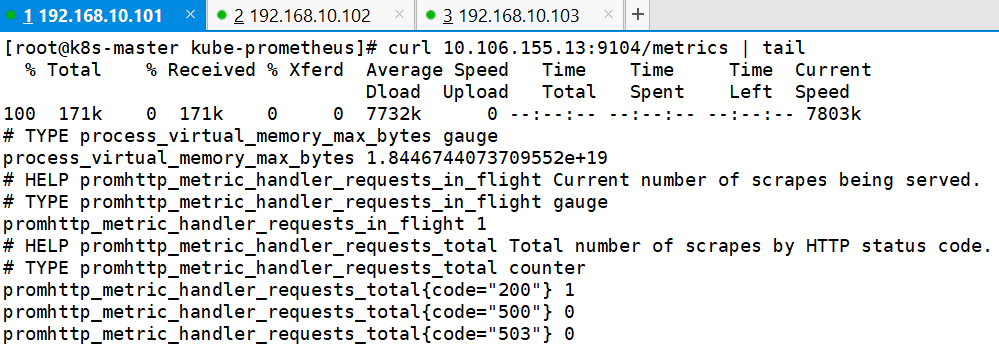
curl 10.106.155.13:9104/metrics | tail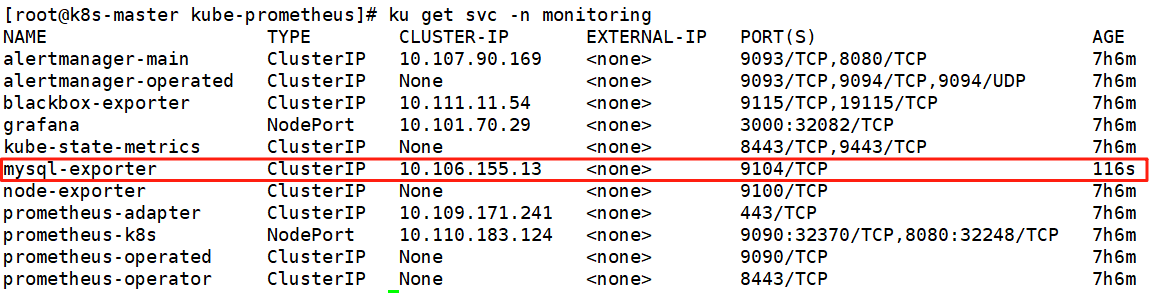
7、配置ServiceMonitor
vim mysql-sm.yaml
ku create -f mysql-sm.yamlapiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: mysql-exporter
namespace: monitoring
labels:
k8s-app: mysql-exporter
namespace: monitoring
spec:
jobLabel: k8s-app
endpoints:
- port: api
interval: 30s
scheme: http
selector:
matchLabels:
k8s-app: mysql-exporter
namespaceSelector:
matchNames:
- monitoring8、查看
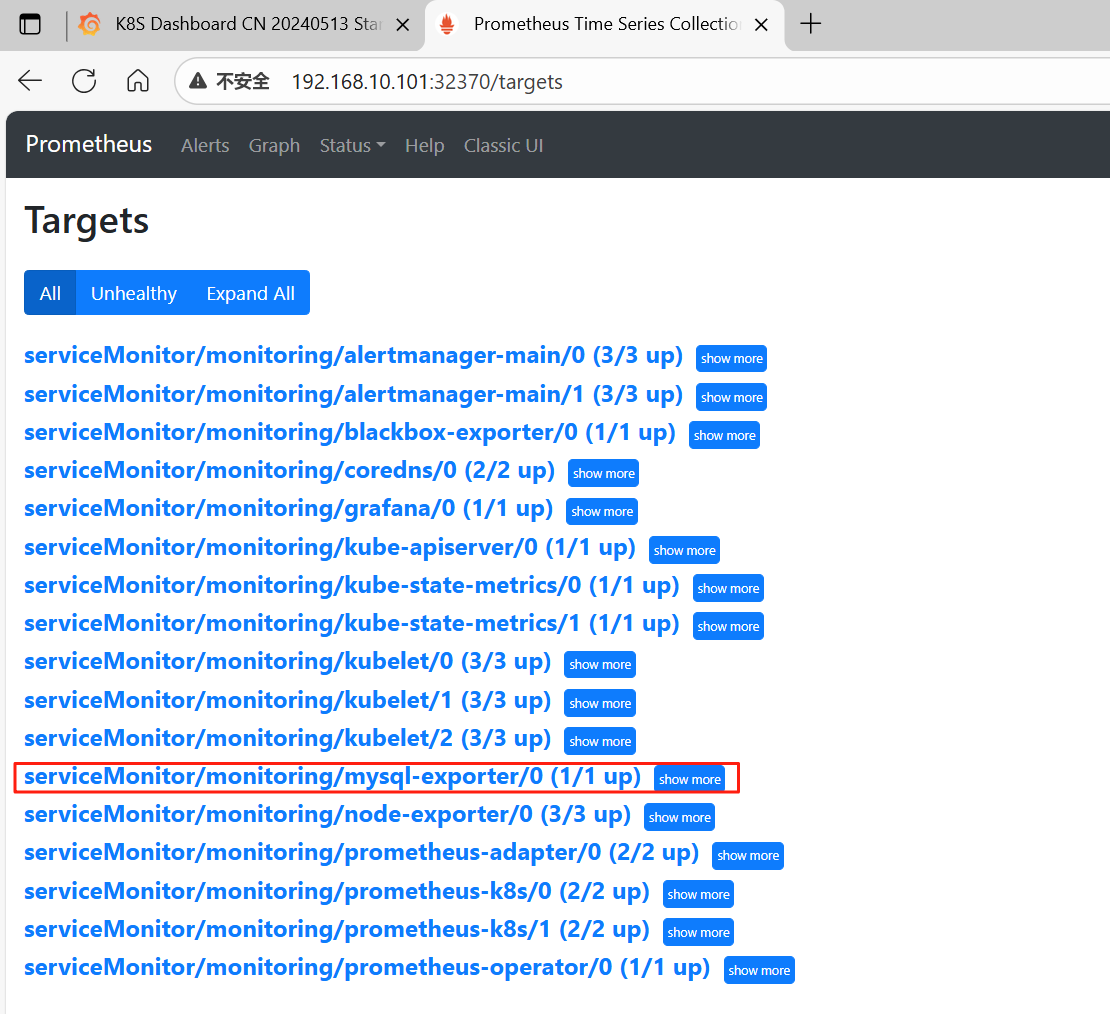
9、添加MySQL监控模板
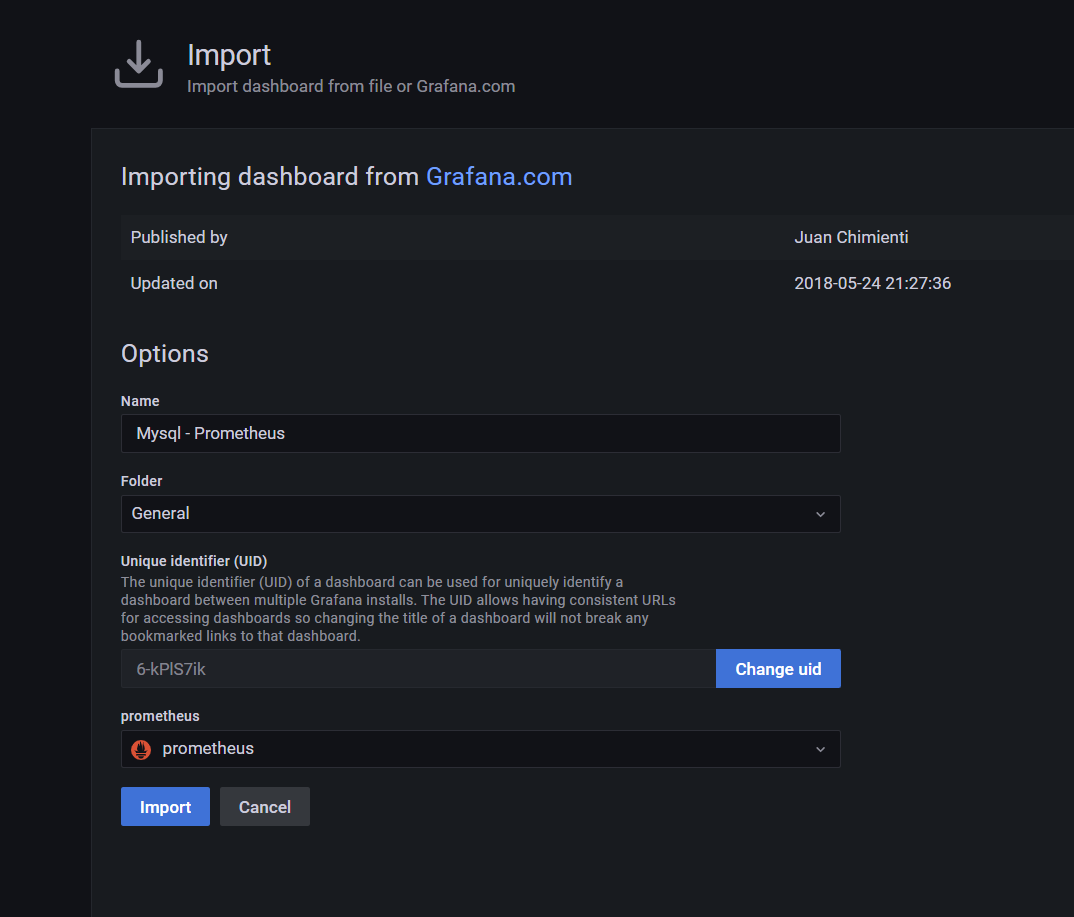
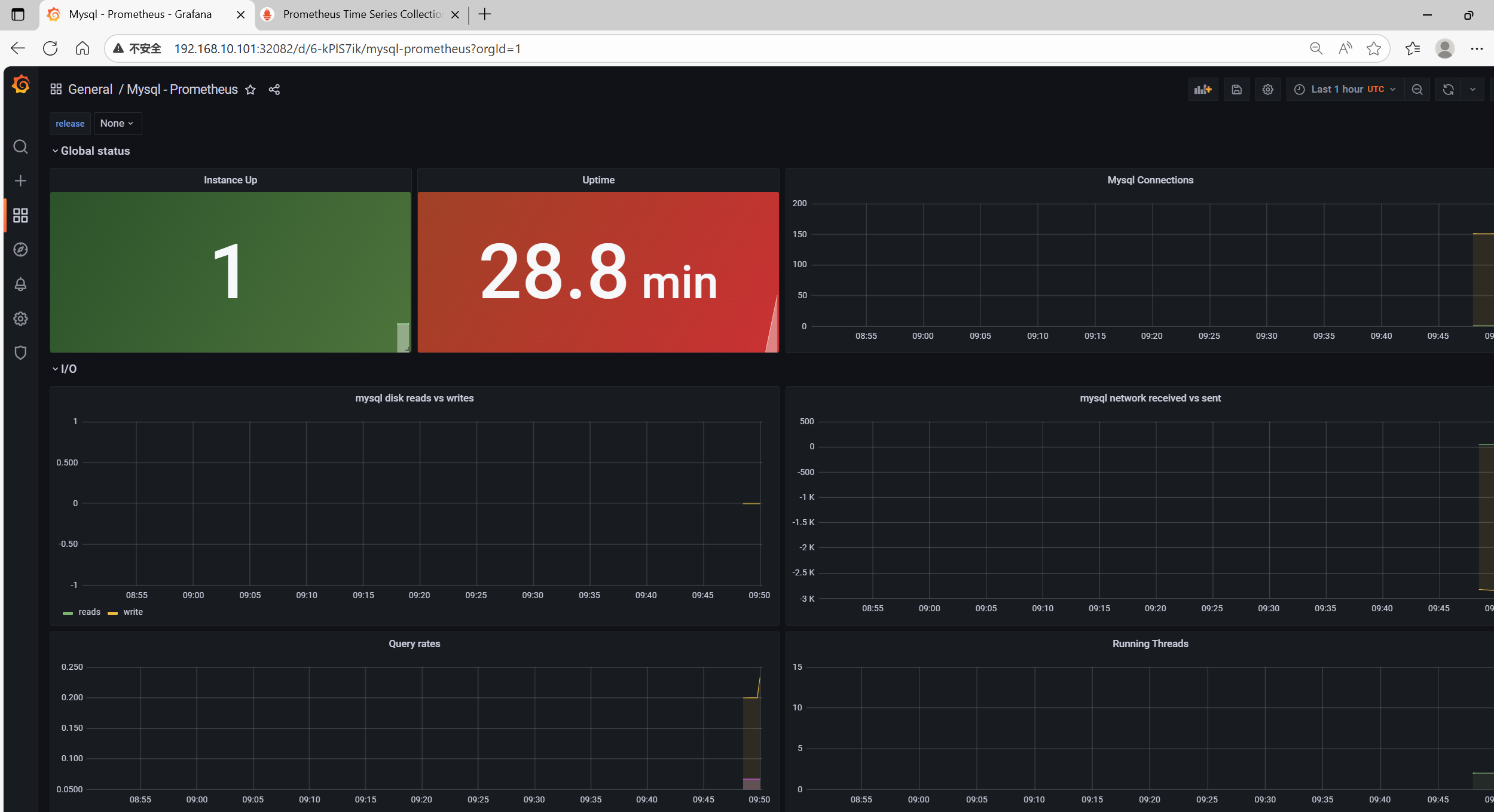
五:对接钉钉报警
首先在钉钉群里面添加一个自定义机器人
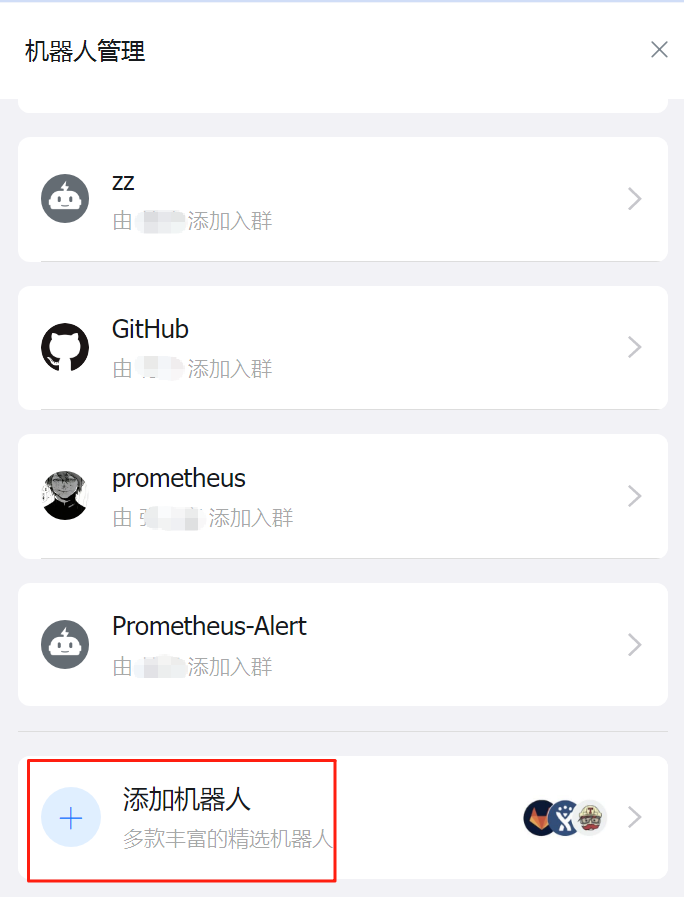
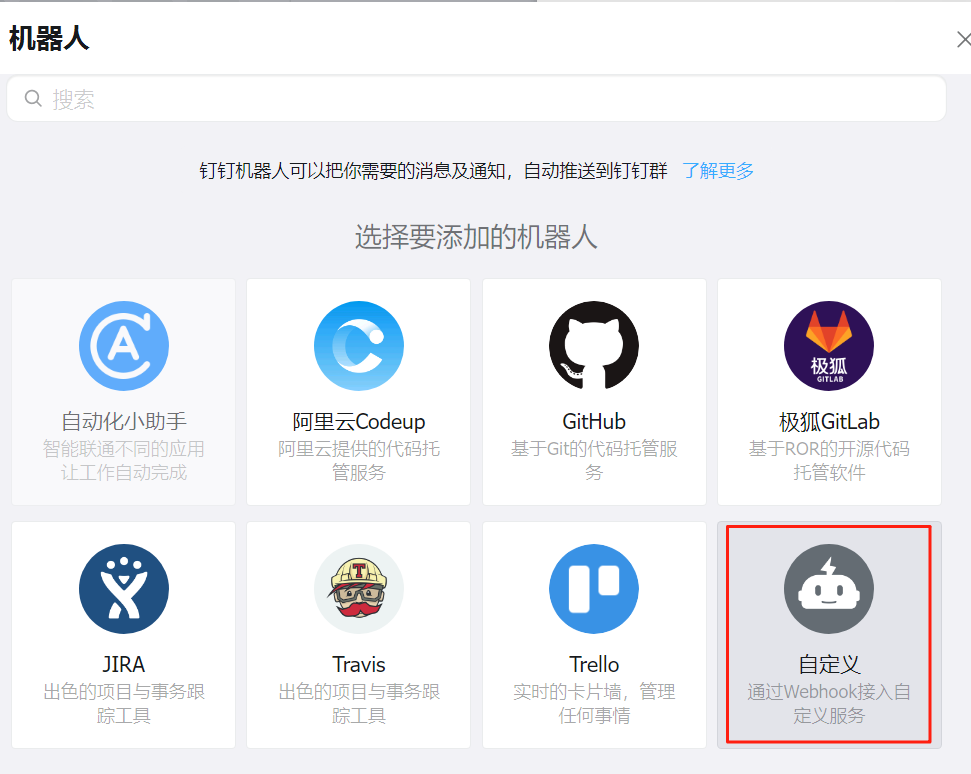
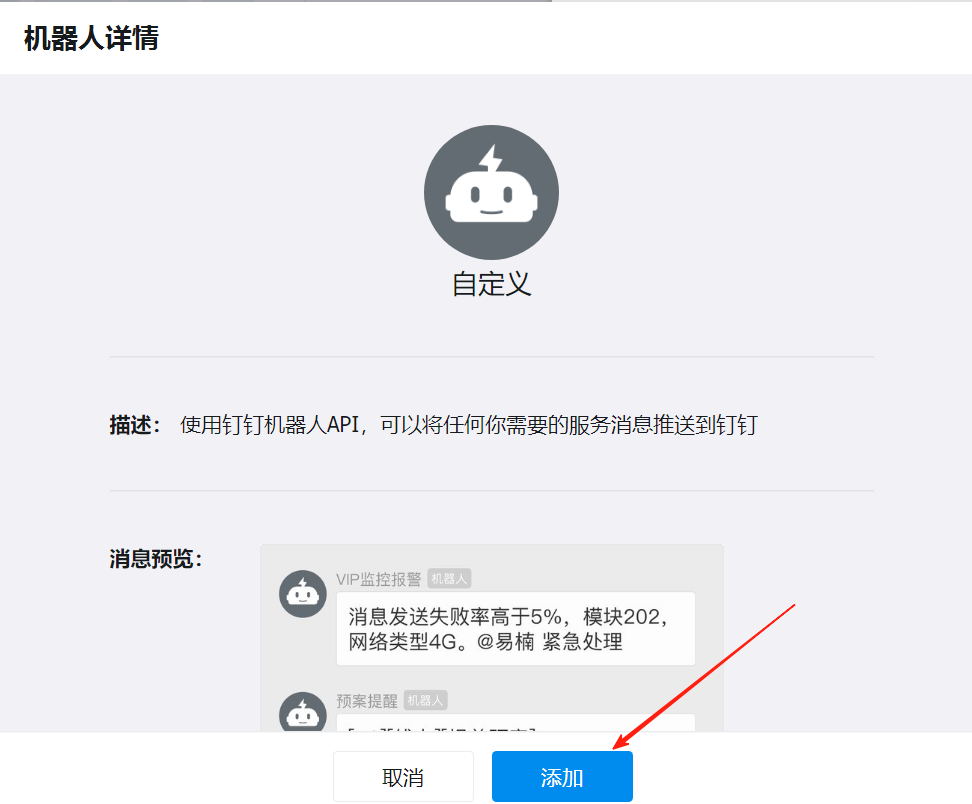
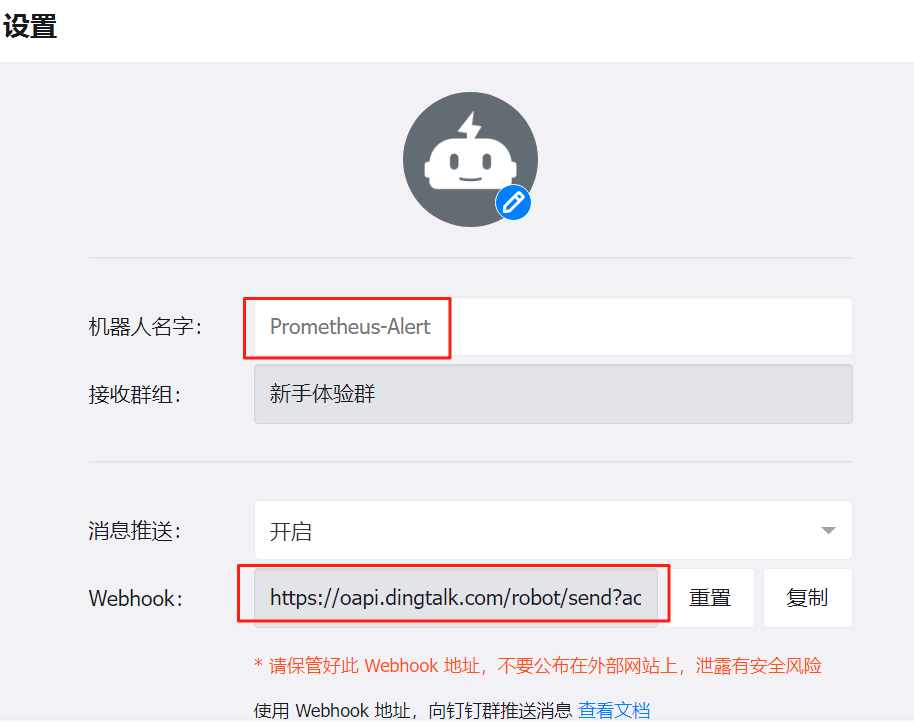
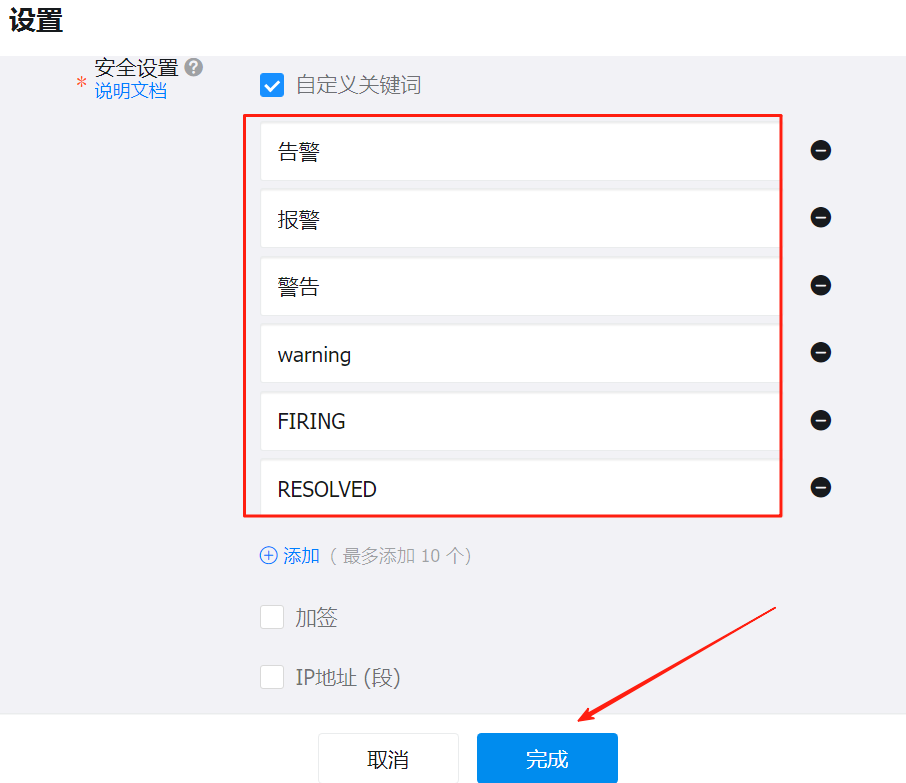
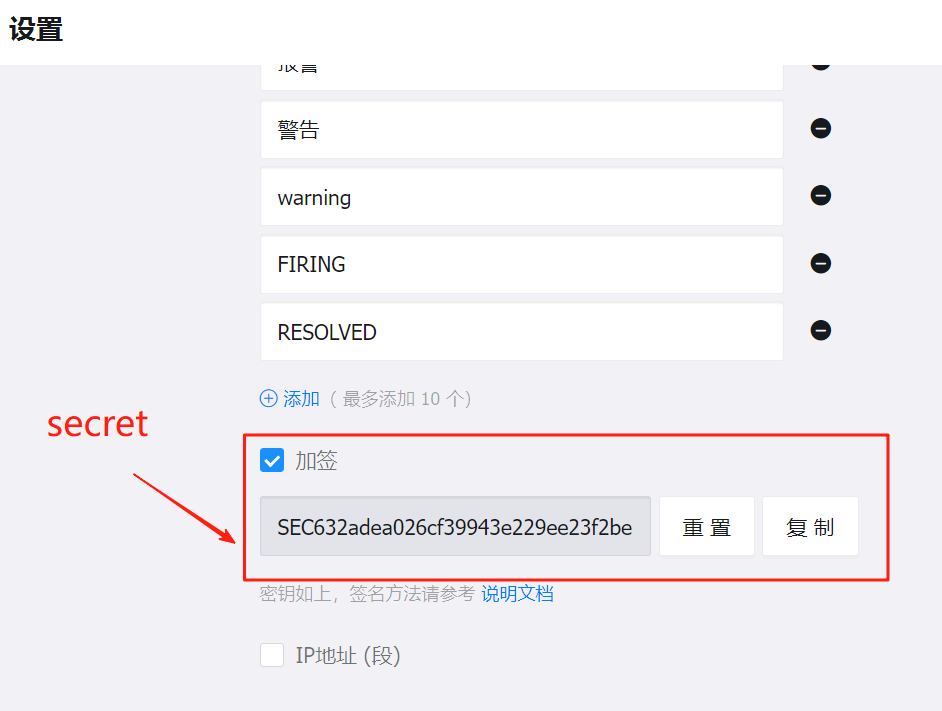
为钉钉机器人添加关键字:FIRING
1、部署 DingTalk
DingTalk(钉钉)是阿里巴巴集团开发的一款企业级通讯和协作平台,旨在提升工作效率和团队协作能力。它集成了即时通讯、视频会议、任务管理、日程安排、文件共享等多种功能,适用于企业内部的沟通与协作。DingTalk 支持多平台使用,包括移动设备(iOS、Android)和桌面端(Windows、macOS),并且提供了丰富的 API 接口,方便与企业现有的系统进行集成。
下载地址
https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.0.0/prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz2、解压并修改配置文件
tar zxf prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz
mv prometheus-webhook-dingtalk-2.0.0.linux-amd64 /usr/local/dingtalk
cd /usr/local/dingtalk/
mv config.example.yml config.yml
vim config.yml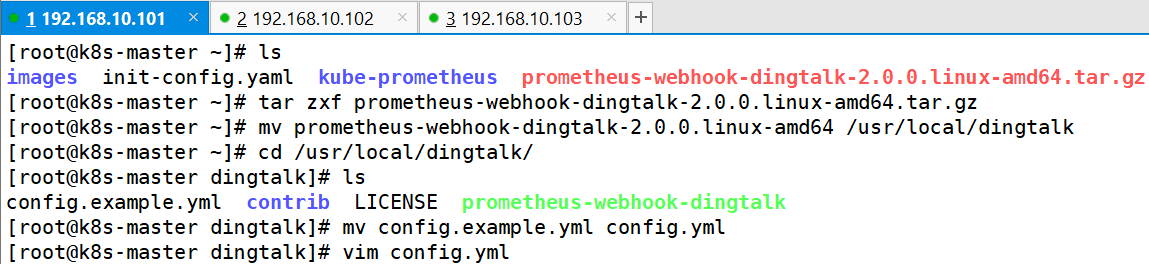
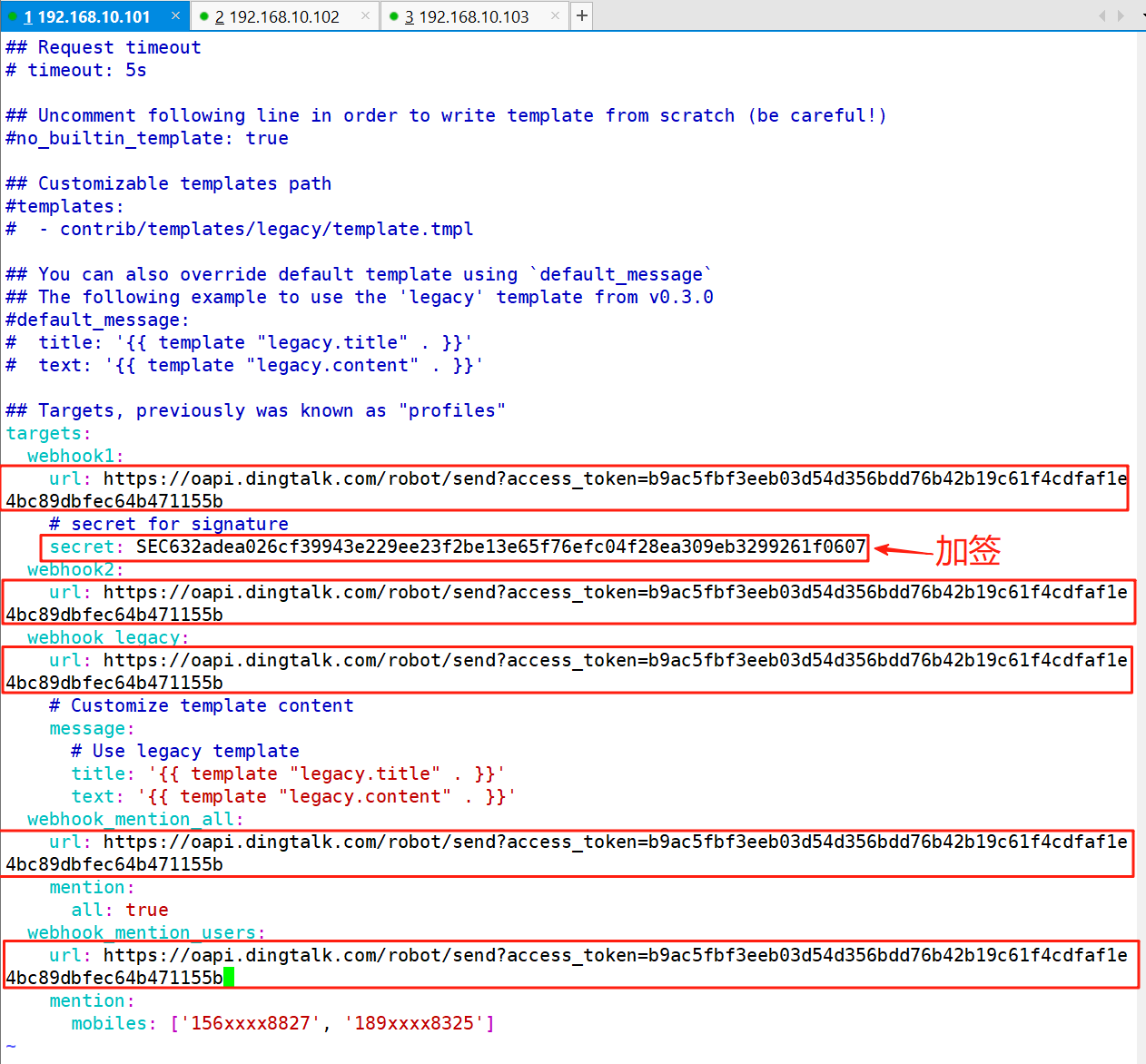
3、将dingtalk服务加入守护进程
vim /lib/systemd/system/prometheus-webhook-dingtalk.service[Unit]
Description=Prometheus Webhook DingTalk
After=network.target
[Service]
User=root
Group=root
WorkingDirectory=/usr/local/dingtalk
ExecStart=/usr/local/dingtalk/prometheus-webhook-dingtalk
Restart=always
RestartSec=5
Environment="CONFIG_FILE=/usr/local/dingtalk/config.yml"
[Install]
WantedBy=multi-user.target4、重载守护进程并重启服务
systemctl daemon-reload
systemctl start prometheus-webhook-dingtalk
ss -anpt | grep 8060
5、配置Alertmanager
cd kube-prometheus/manifests/
vim alertmanager-secret.yamlapiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.23.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = critical"
"target_matchers":
- "severity =~ warning|info"
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = warning"
"target_matchers":
- "severity = info"
"receivers":
- "name": "webhook"
webhook_configs:
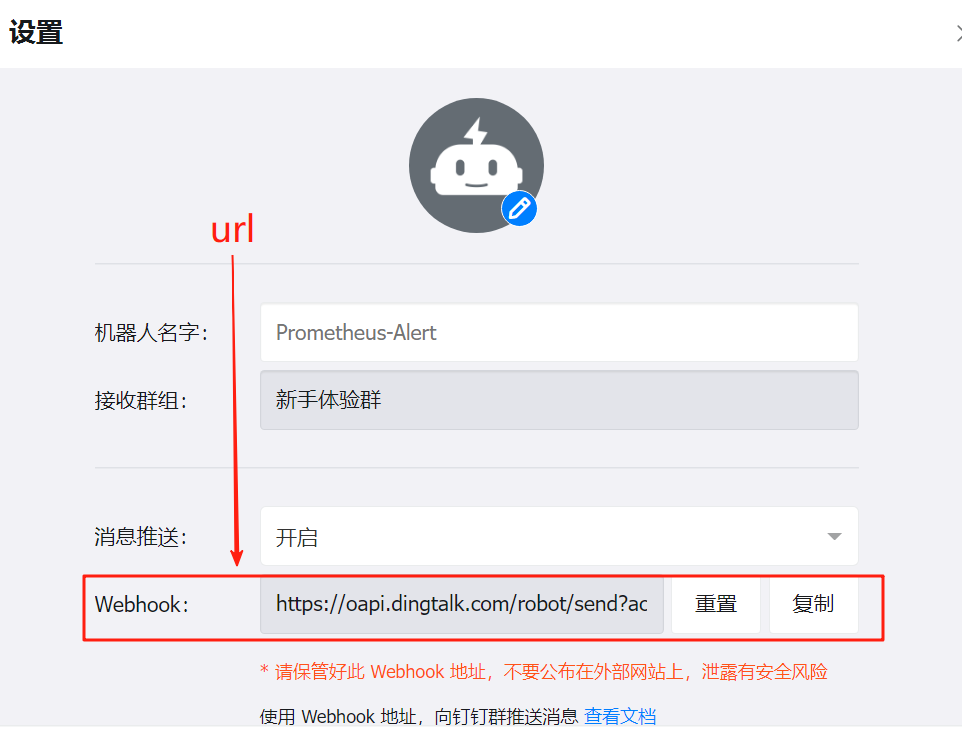
- url: http://192.168.10.101:8060/dingtalk/webhook2/send
send_resolved: true
"route":
"group_by":
- "namespace"
"group_interval": "10s"
"group_wait": "30s"
"receiver": "webhook"
"repeat_interval": "20s"
"routes":
- "matchers":
- "alertname = Watchdog"
"receiver": "webhook"
- "matchers":
- "severity = warning"
"receiver": "webhook"
type: Opaque
6、重载Alertmanager
ku replace -f alertmanager-secret.yaml
ku apply --server-side -f manifests/7、编辑Alertmanager的Service类型
ku get svc -n monitoring
ku edit svc alertmanager-main -n monitoring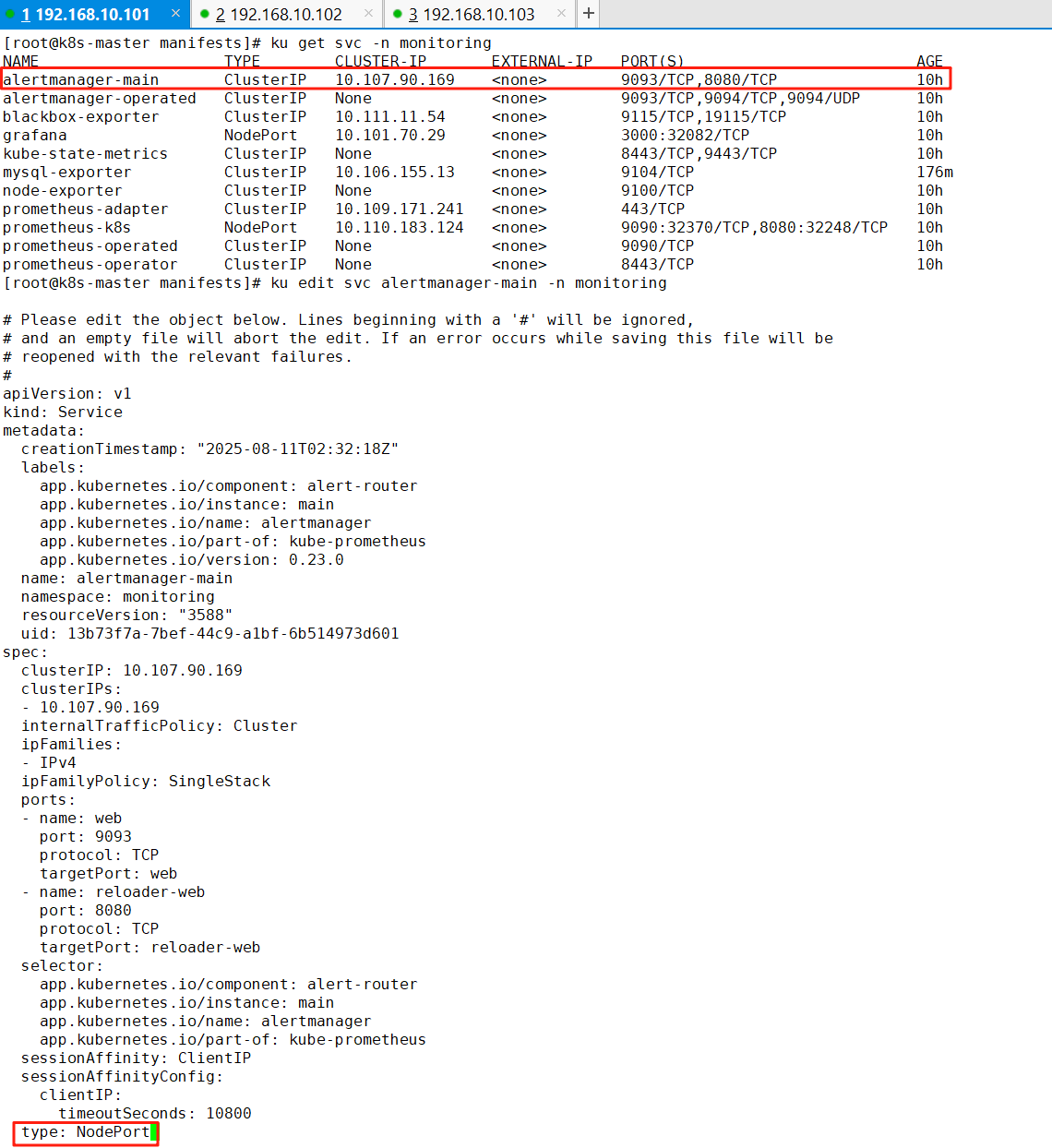
8、查看监听端口
ku get svc -n monitoring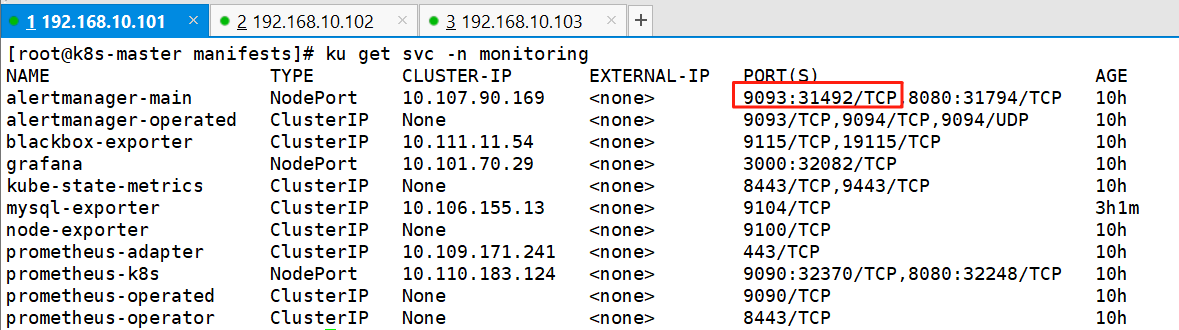
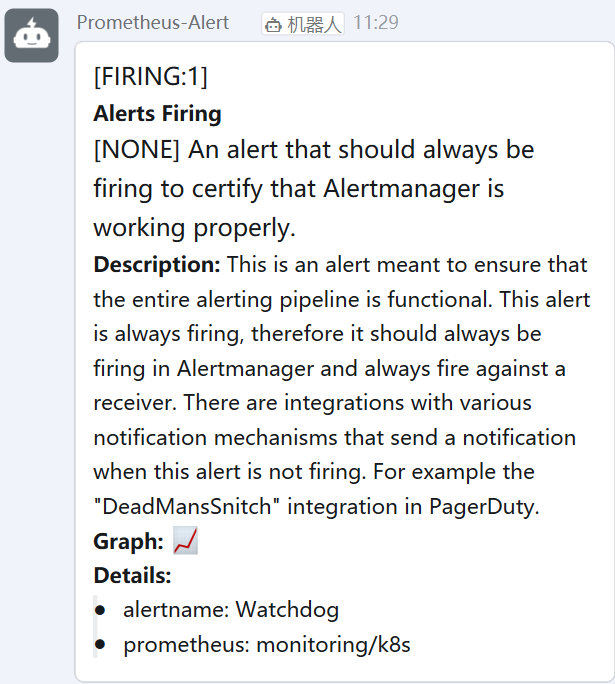
9、添加告警规则
vim manifests/alertmanager-prometheusRule.yaml(1) mysql进程down机告警
- name: mysql.rules
rules:
- alert: MySQLDown
annotations:
description: MySQL instance {{ $labels.pod }} has been unreachable for 30 seconds.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/mysql/mysqldown
summary: MySQL instance is down.
expr: |
mysql_up == 0
for: 10s
labels:
severity: critical(2) mysql进程内存利用率过高告警
- alert: MySQLMemoryUsage
annotations:
description: MySQL container {{ $labels.pod }} in namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage }} of its memory limit.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/mysql/mysqlmemoryusage
summary: High memory usage in MySQL container
expr: |
(container_memory_working_set_bytes{namespace="monitoring", pod=~"mysql-.*", container="mysql-exporter"}
/ on(namespace,pod) group_left()
container_spec_memory_limit_bytes{namespace="monitoring", pod=~"mysql-.*", container="mysql-exporter"}
) > 0.8
for: 5m
labels:
severity: warning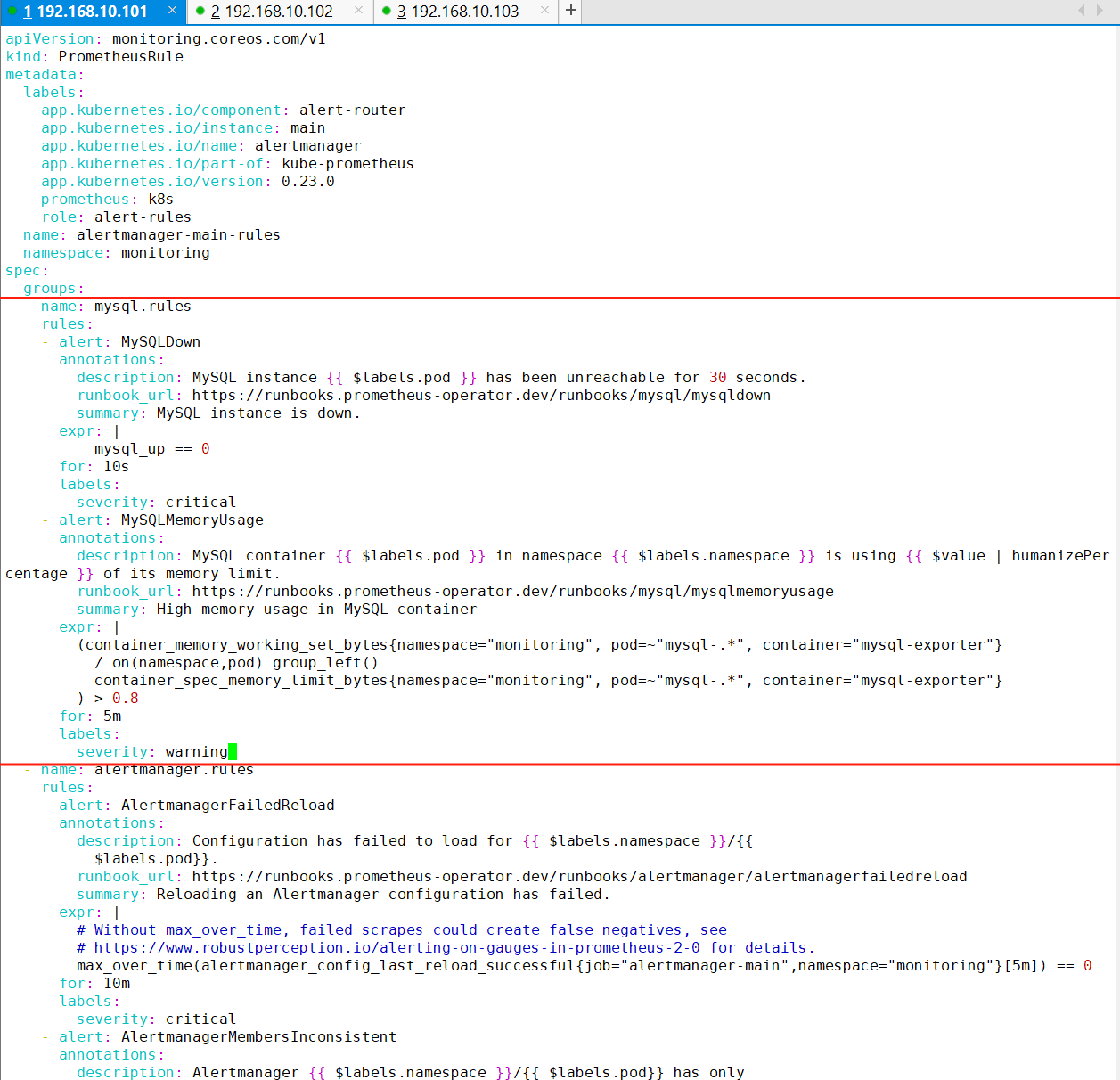
(3) 添加完规则后重载一下Prometheus Stack
kubectl apply --server-side -f manifests/10、在告警媒介中添加接收者信息
MySQLDown - 检测 MySQL 实例是否不可用
MySQLMemoryUsage - 监控内存使用率
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.23.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = critical"
"target_matchers":
- "severity =~ warning|info"
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = warning"
"target_matchers":
- "severity = info"
"receivers":
- "name": "webhook"
webhook_configs:
- url: http://192.168.10.101:8060/dingtalk/webhook2/send
send_resolved: true
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "matchers":
- "alertname = MySQLDown"
"receiver": "webhook"
- "matchers":
- "alertname = MySQLMemoryUsage"
"receiver": "webhook"
type: Opaque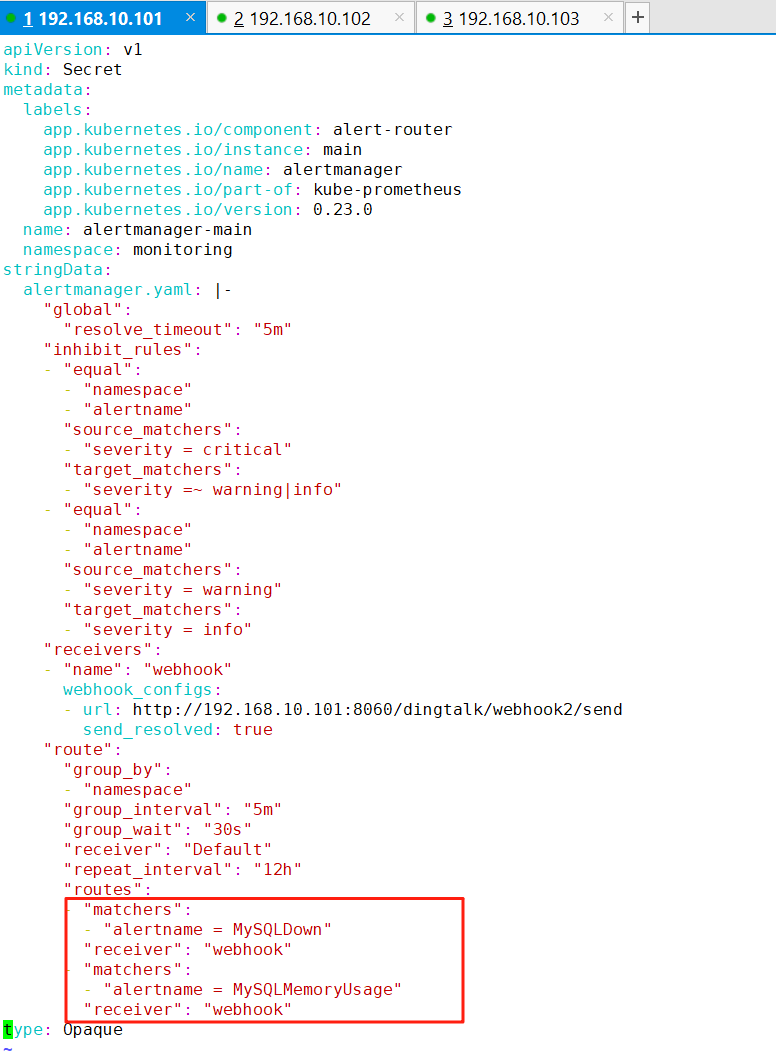
11、将改好的配置加载到Alertmanager
kubectl replace -f alertmanager-secret.yaml六、解决kube-controller-manager误判
1、只勾选Firing
发现虽然在Alert中有KubeControllerManager和KubeScheduler的监控配置,但是没有发现可用的监控目标
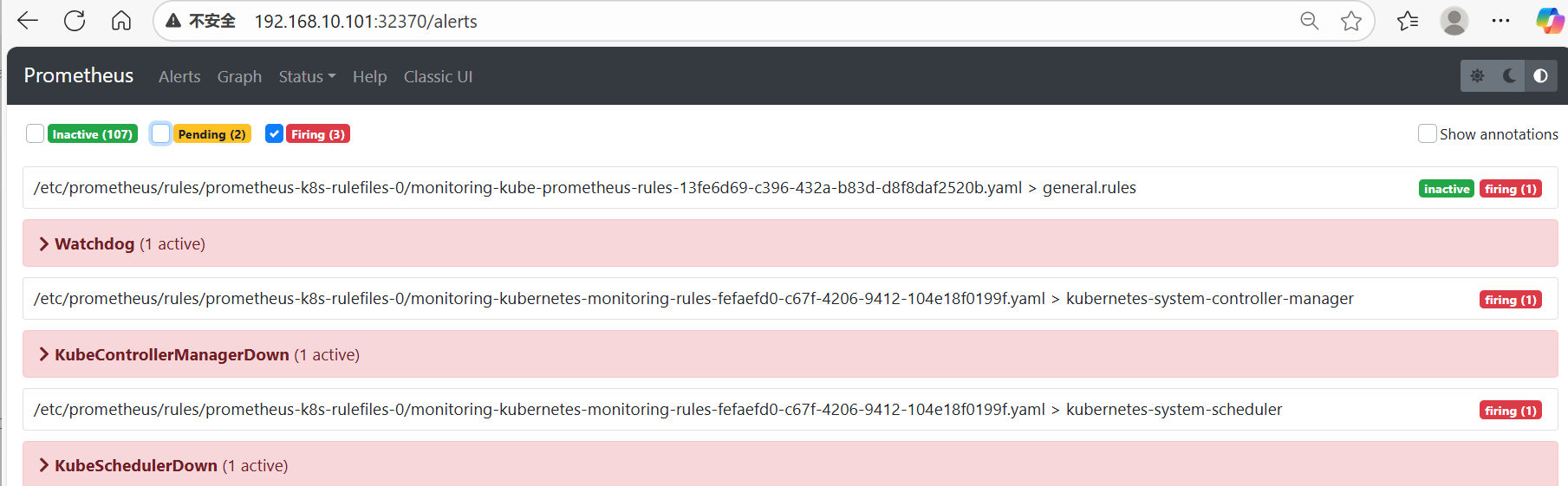
Status-->Target(监控目标中没有kube-controller-manager和kube-scheduler)
2、查看ServiceMonitor是否创建成功
ku get servicemonitor -n monitoring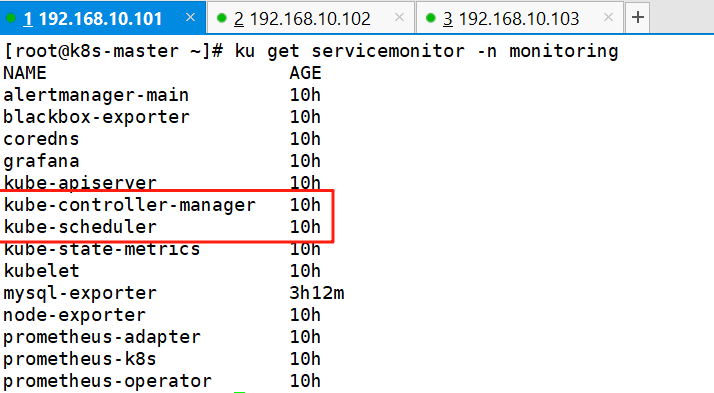
3、解决kube-controller-manager不监控
将kube-controller-manager的监听地址修改为0.0.0.0.原来是127.0.0.1
注意:
从此文件可以看出controller-manager的监听端口为10257,协议为HTTPS
vim /etc/kubernetes/manifests/kube-controller-manager.yaml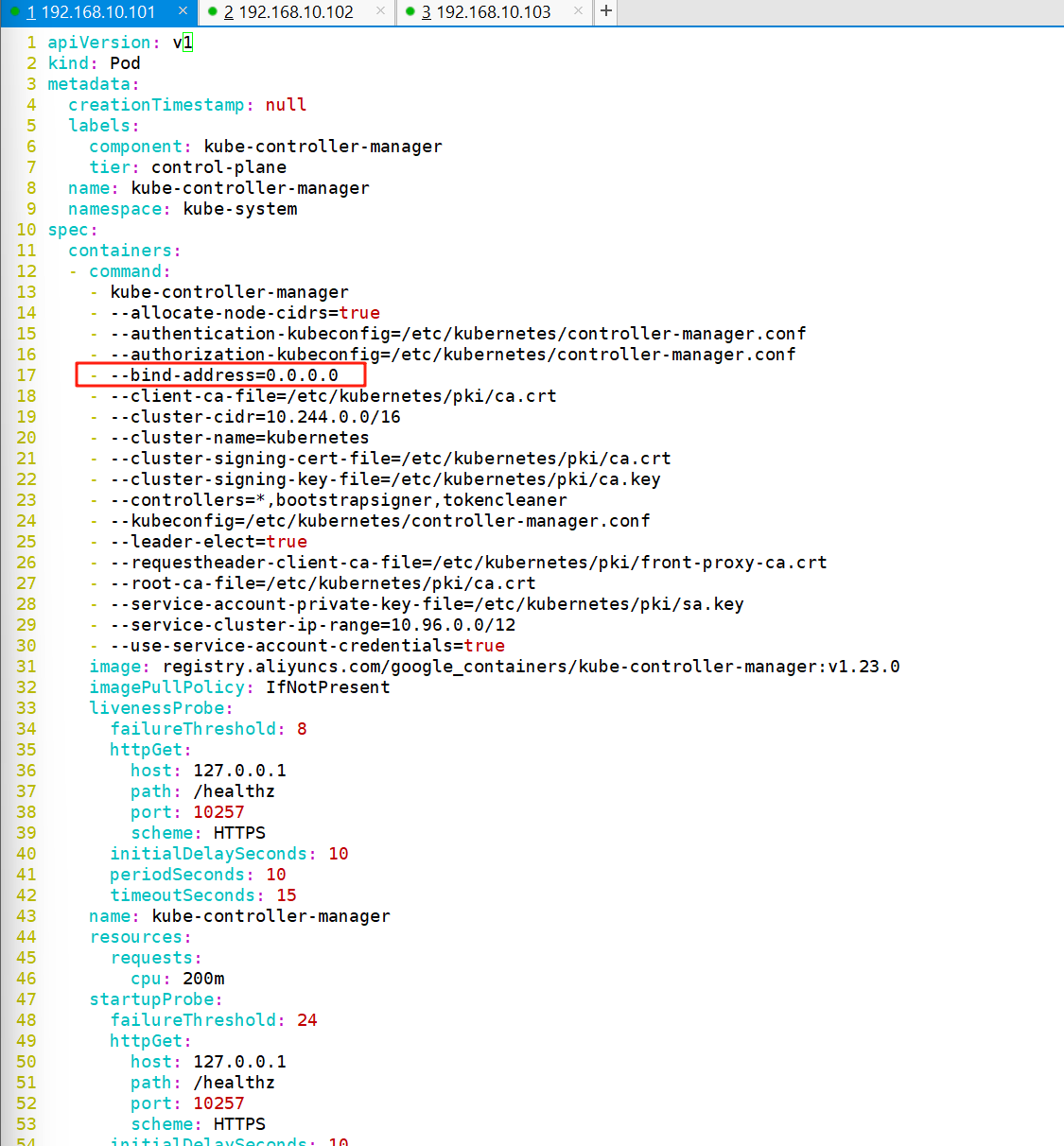
4、重启master节点并查看监听
ku create -f /etc/kubernetes/manifests/kube-controller-manager.yaml
netstat -anpt -lnpt | grep kube-controll
注意:
如果无法看到kube-controll的进程需要等待一会,如果等一会也看不到,可以重建一下kube-controller-manager.yaml,重建一下也不行就重启master节点。
5、查看kube-controller-manager的ServiceMonitor的配置
ku get servicemonitor -n monitoring kube-controller-manager -o yaml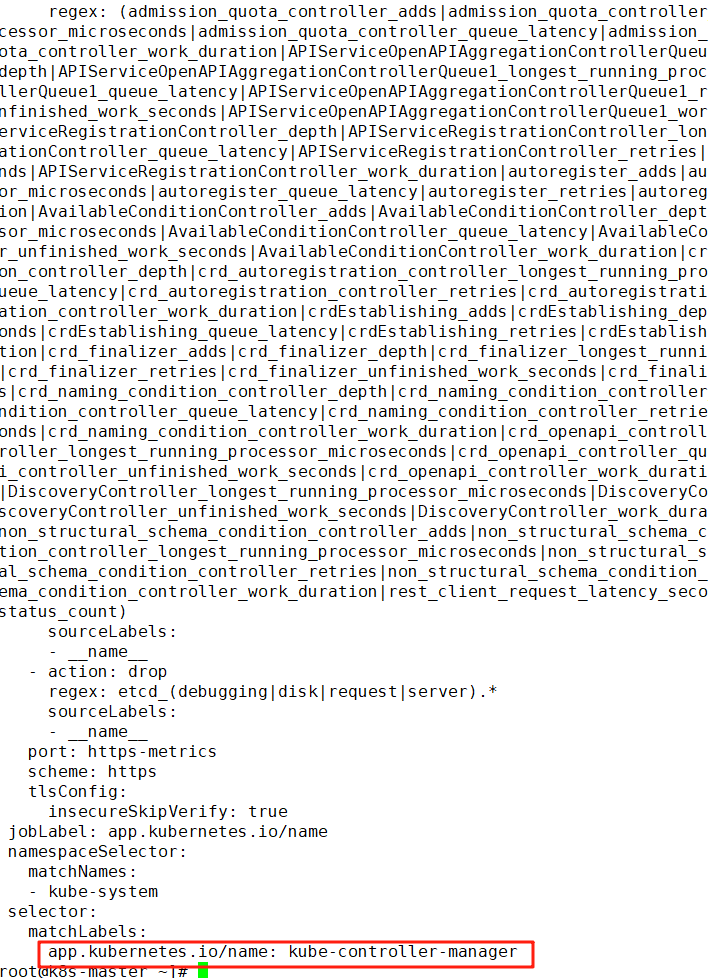
注意:
此处的ServiceMonitor匹配的是kube-system命名空间下具有app.kubernetes.io/name=kube-controller-manager标签的Service。需要查看一下是否有这个Service。
6、查看标签
查看在kube-system的命名空间中中是否有一个标签为app.kubernetes.io/name=kube-controller-manager的Service
kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-controller-manager此处发现没有这个Service

7、创建一个EndPoint和Service,指向自己的Controller Manager
cd kube-prometheus/
vim controller.yamlapiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager-prom
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.10.101
# - ip: YOUR_CONTROLLER_IP02
# - ip: YOUR_CONTROLLER_IP03
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager-prom
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10257
protocol: TCP
targetPort: 10257
sessionAffinity: None
type: ClusterIP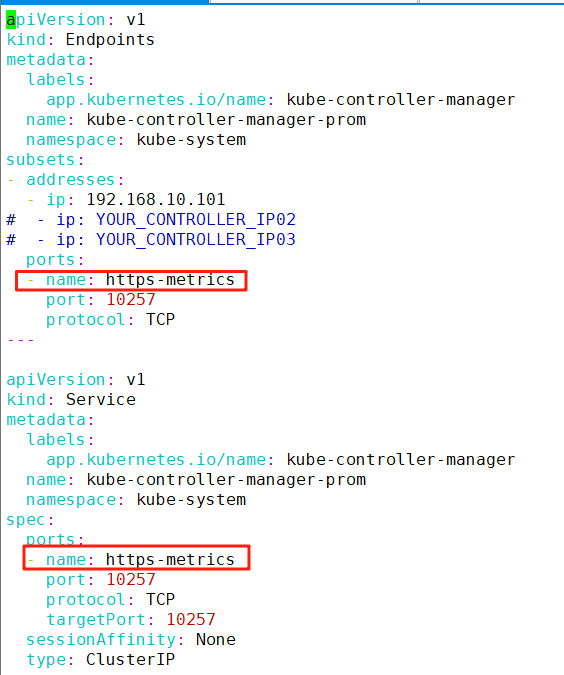
8、创建自定义的Service和Endpoint
ku create -f controller.yaml
9、修改ServiceMonitor的配置和Service的一致(高于1.22版本的默认不用修改)
kubectl edit servicemonitor kube-controller-manager -n monitoring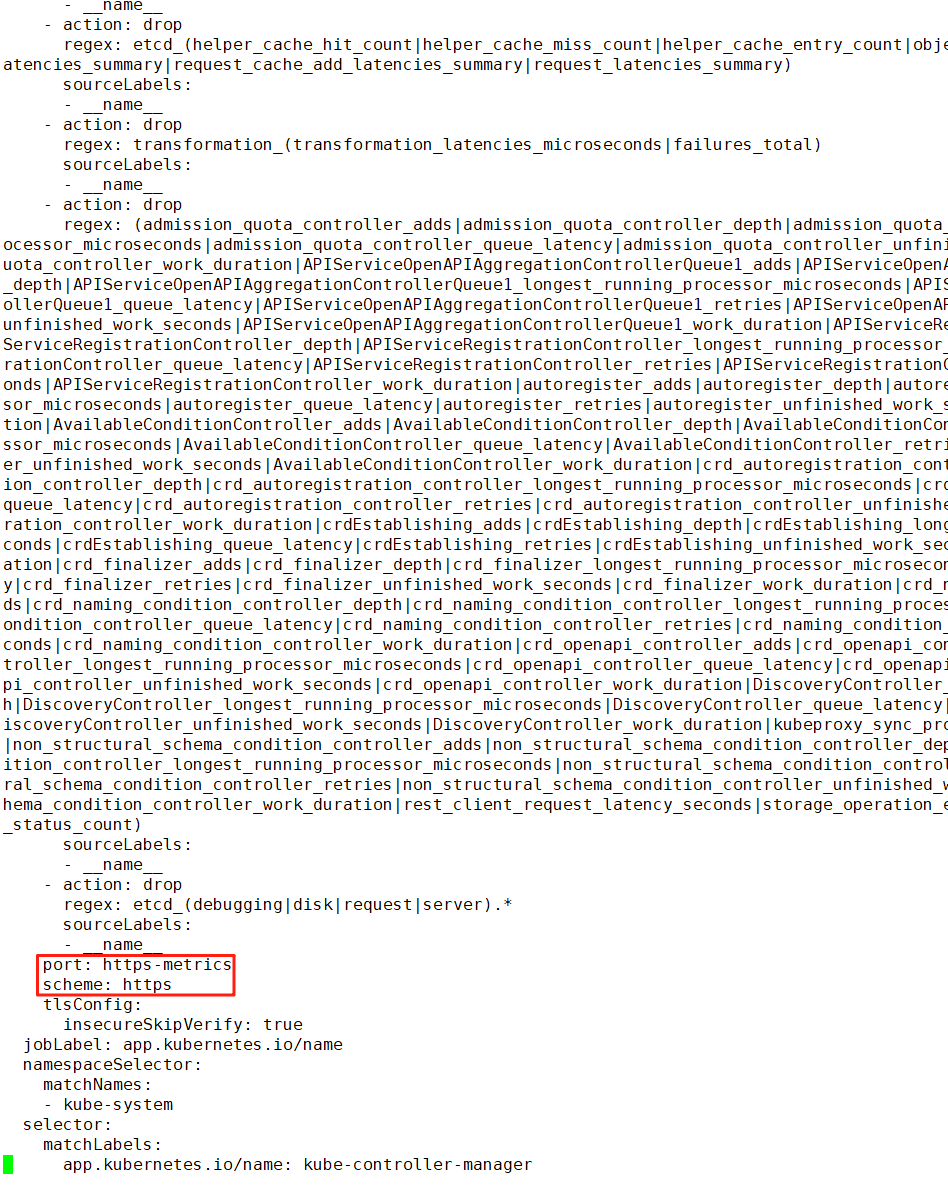
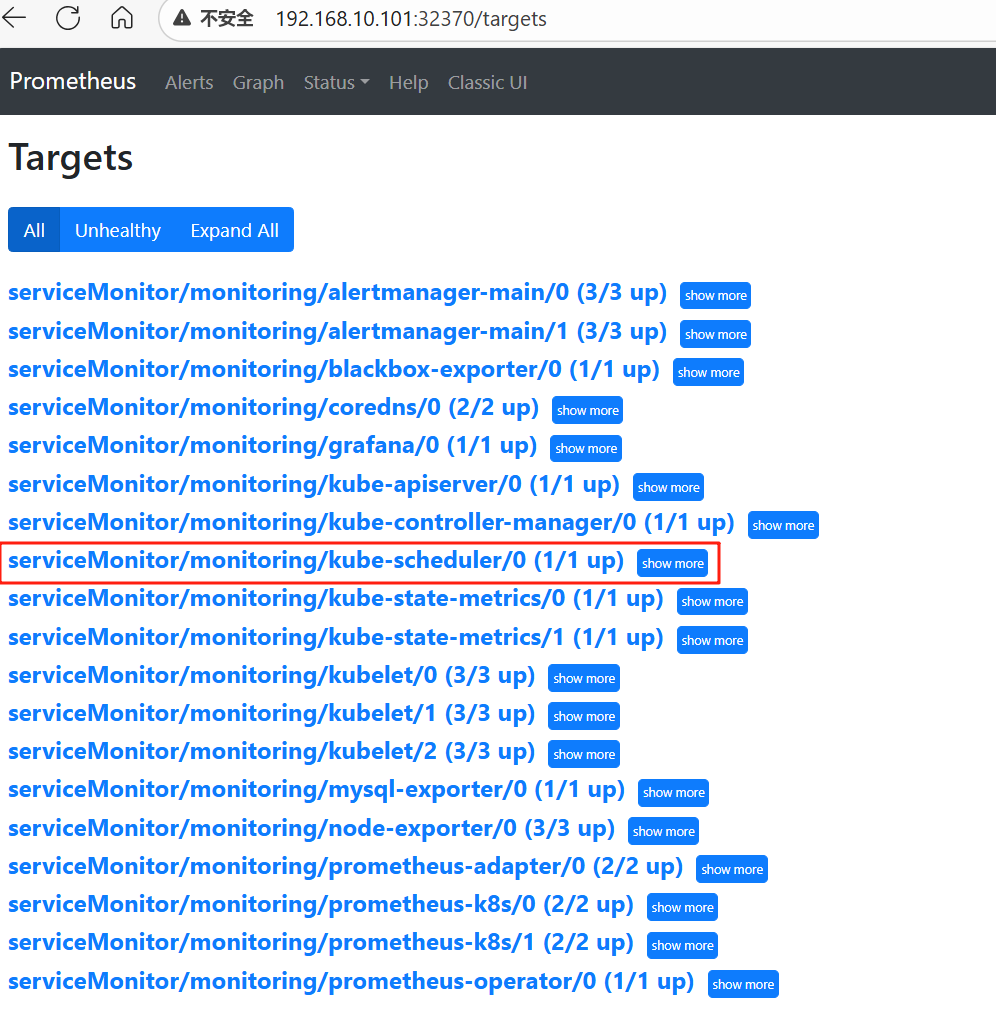
10、查看监控结果
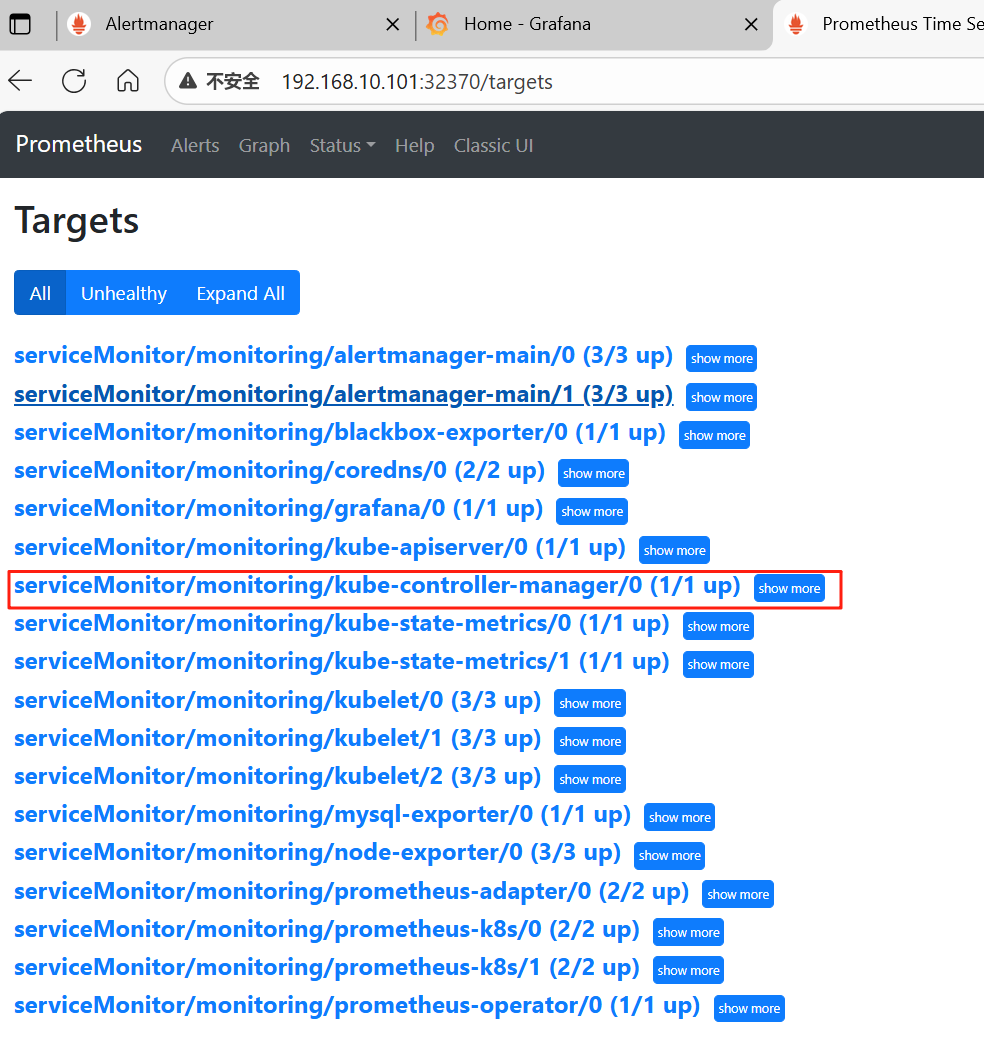
七、解决kube-scheduler误判
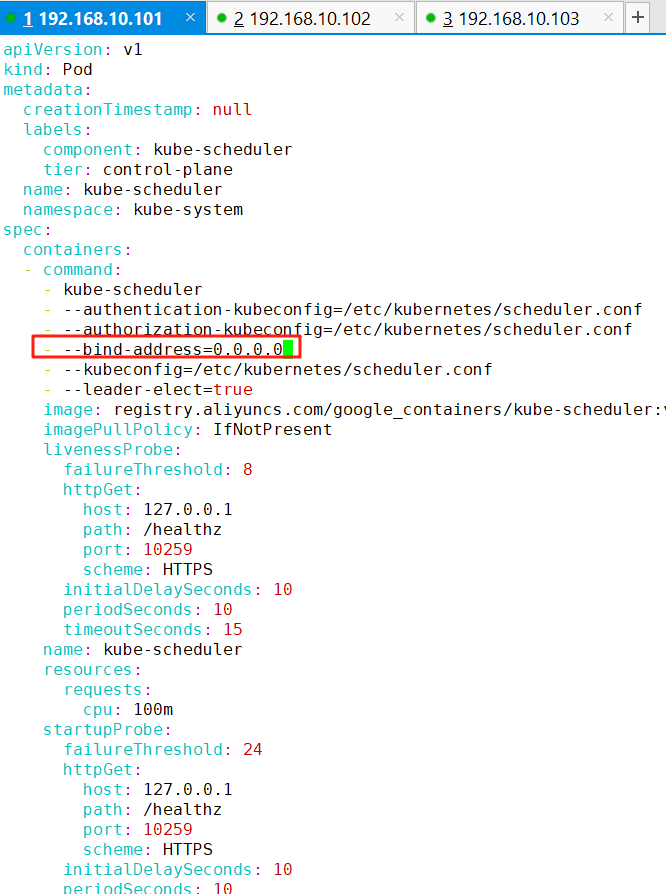
1、修改kube-scheduler的监听地址
vim /etc/kubernetes/manifests/kube-scheduler.yaml注意:
从此文件可以看出scheduler的监听端口为10259,协议为HTTPS
2、查询一下kube-scheduler服务的监听端口
ku delete -f kube-scheduler.yaml
netstat -anpt -lnpt | grep kube-scheduler
注意:
如果无法看到kube-scheduler的进程需要等待一会,如果等一会也看不到,可以重建一下kube-scheduler.yaml,重建一下也不行就重启master节点。
3、查看kube-scheduler的ServiceMonitor的配置
kubectl get servicemonitor -n monitoring kube-scheduler -o yaml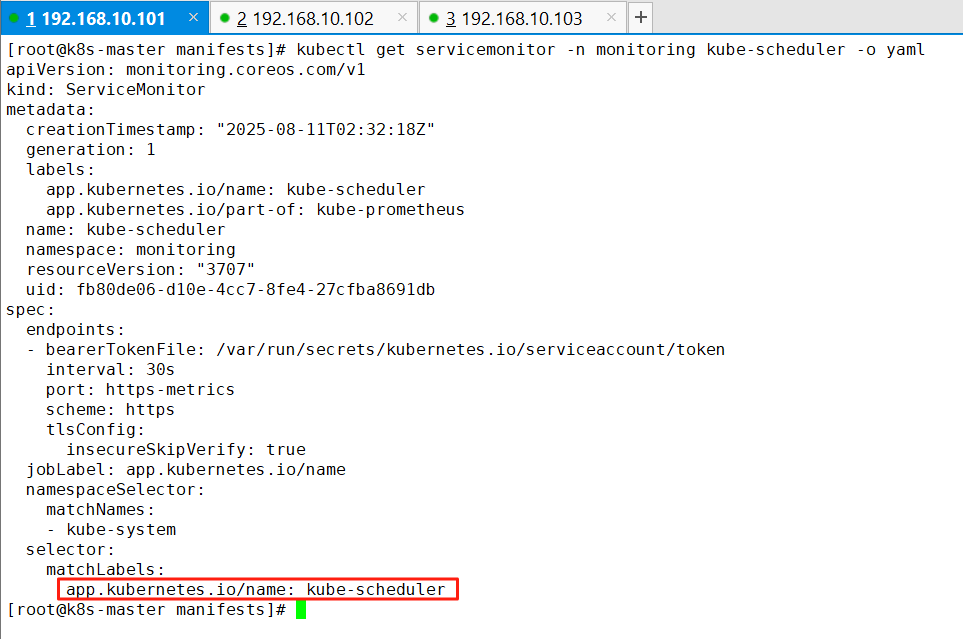
4、查看标签
查看在kube-system的命名空间中是否有一个标签为app.kubernetes.io/name=kube-scheduler的Service
kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-scheduler![]()
5、创建一个EndPoint和Service,指向自己的scheduler
vim /root/kube-prometheus/scheduler .yamlapiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler-prom
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.10.101
# - ip: YOUR_CONTROLLER_IP02
# - ip: YOUR_CONTROLLER_IP03
ports:
- name: https-metrics
port: 10259
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler-prom
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10259
protocol: TCP
targetPort: 10259
sessionAffinity: None
type: ClusterIP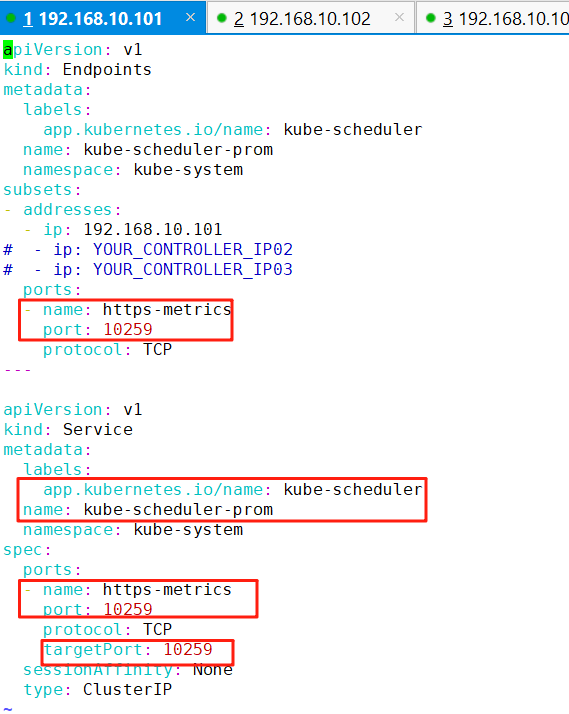
kubectl create -f scheduler.yaml6、查看自定义的Service和Endpoin
kubectl get svc -n kube-system kube-scheduler-prom
7、修改ServiceMonitor的配置和Service的一致(高于1.22版本的默认不用修改)
kubectl edit servicemonitor kube-scheduler -n monitoring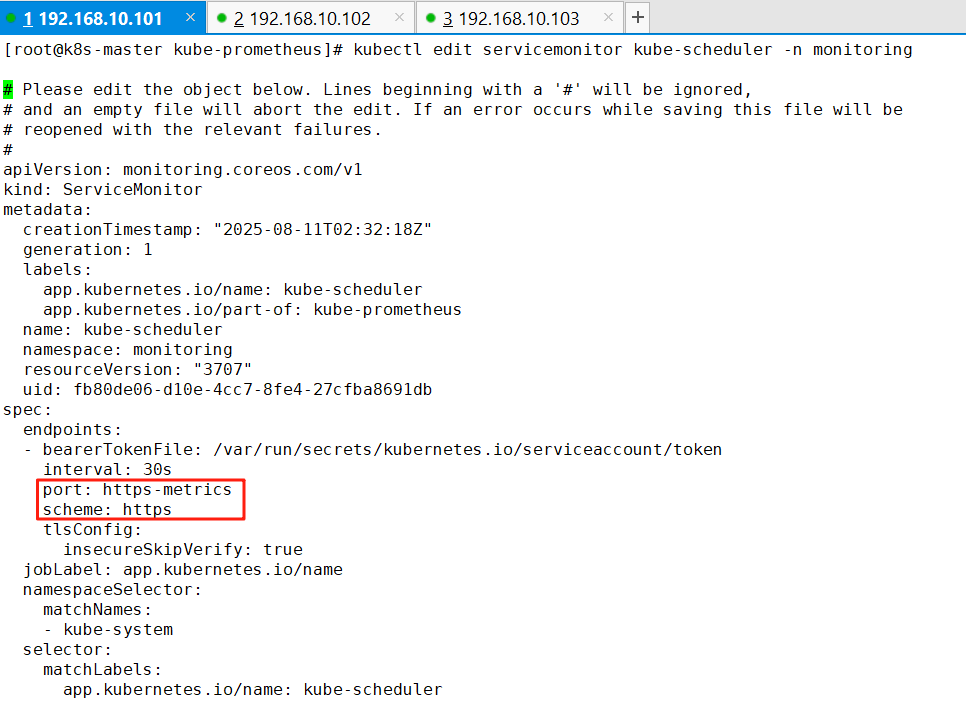
8、查看监控结果