摘 要
目前,家庭监控大多数都是人工进行操作,并不能够自动的检测和识别出人员跌倒的情况。针对这一问题,本研究提出了一种基于人工智能和物联网融合的方法,开发了一套能够实时检测并准确判断人员跌倒情况的监控系统,并能够及时发出警报。该系统采用了YOLOv8和OpenCV相结合的技术,以香橙派5作为主控制器,利用海康威视USB摄像头进行视频数据的采集,并通过EC20通信模块实现4G无线通信,进行报警功能。实验结果表明,在背景干扰的情况下,系统对1000张行人状态的数据集进行训练,能够很快地定位运动中的人物,并实现了高达96.9%的跌倒识别准确率,平均精度(MAP)接近82%。此外,系统从检测到跌倒行为到发出警报通知的响应时间仅为3500毫秒,充分证明了其高效性、可行性和实用性。
关键词:YOLOv8;香橙派5;识别跌倒行为
目 录
序 言
随着社会经济的发展,社会老龄化也越来越加剧,对于老人和儿童的安全监护问题也越来越突出,老人和小龄儿童若发生跌倒后,没有及时进行救助,则有可能会导致骨折和颅脑损伤。因此,研发基于人工智能和物联网融合的跌倒监控系统具有重要的意义。该监控系统可实时监测老人和儿童的情况,不仅能够及时发现跌倒事件,降低伤害程度,还能够提高老人和儿童生活环境的安全性。
目前,行人跌倒的检测设备主要有穿戴式和视觉传感器监测两种方式。穿戴式设备通过惯性测量单元收集人物的姿态信息,虽然能够精准的定位到位置,但是老人和儿童容易忘记佩戴,从而达不到实时的监测。2019年,王亚玲[1]设计开发了一种基于NB-IoT技术的可穿戴式老人摔倒监测系统,结合OneNET物联网开放平台的数据接收与处理能力,实现了老人摔倒监测及心率、环境参数监测等功能。杨丽[2]设计基于物联网的智能家居安全监控系统,系统分为感知模块、安全处理模块和设备监控终端三部分实现系统设计。2022年,朱钰龙[3]设计了基于物联网技术的老年人防走丢与摔倒报警系统,具有实时经纬度显示、短信查询定位信息、摔倒检测、呼救等功能,使用方便、成本低廉,具有广阔的市场前景。高尚[4]基于CSI多域统计特征融合的人体摔倒感知方法,研究人体摔倒动作表征与建模。建立基于CSI多域统计特征量的融合建模方法,以获得摔倒动作的细粒度表征,包括CSI数据预处理、动态路径特征联合估计、以及多域统计特征量融合。
视觉传感器借助摄像头进行捕捉检测,不需要老人和儿童进行佩戴检测设备,但要求算法检测程度高、环境光照亮,且对于复杂背景容易产生误判的情况。在2024年,李志翔[5]以RK3588为核心处理器,结合深度学习算法,设计并实现了一款高效、智能的老人监控系统。系统能够迅速准确地识别跌倒和火焰等异常情况,有效解决了监控效率低下和便捷性不足的问题,大幅提升了老人安全监控的效能。陈弘达[6]设计基于提升小波变换的人体行为识别深度学习模型,LSCG网络模型的结构由小波分解模块与特征融合模块组成,使模型关注更重要的人体行为信号,以达到更好的分类效果。帅文璇[7]提出了一种基于手机传感器的多阈值摔倒检测算法。该算法通过分阶段特征分类的方式逐步将摔倒行为和其它日常行为进行区分,利用数据统计、支持向量机以及线性拟合的方式确定相应特征的边界阈值。陈华艳[8]针对室内监控视频中老年人摔倒行为的检测问题,提出一种基于改进YOLOv7网络模型的实时摔倒行为检测算法,使用跨步卷积来实现下采样特征,但这可能会使目标信息的特征模糊,为了解决这个问题,引入了鲁棒特征下采样,以改善下采样过程中目标信息特征的清晰度。朱强军[9]提出了YOLOv8s摔倒检测模型。在YOLOv8s模型的主干网络中引入SE注意力机制模块,将通道特征分成多个子图特征,让不同组的特征进行融合,使网络自适应地聚焦于关键特征,抑制对当前任务贡献度较小的特征,提高了特征提取能力。蔡鑫斌[10]设计了一种基于YOLOv5目标检测算法的智能拐杖摔倒检测系统,该方法通过训练模型识别特定姿态,从而便于模型学习摔倒特征的多样性,并对模型结构和超参数进行了细致优化,显著提升了算法的识别精准度。
本研究旨在开发一种基于视觉算法的跌倒监控系统,使用香橙派5开发板作为主要控制器,通过摄像头收集老人和小孩跌倒的数据,自制数据集并训练YOLOv8模型,实现老人和儿童的跌倒行为的精准检测。具体内容包括:明确系统的实现功能和系统总体框架;海康威视摄像头采集数据,并对数据进行预处理;研究YOLO模型对于不同环境下跌倒行为的检测准度,优化模型的结构;对系统的检测模型进行测试与优化;选用EC20通信模块,确保跌倒行为发生后及时报警,避免误报和漏报。
第1章 摔倒识别系统总体方案
1.1 系统总体框架
本论文开发的跌倒监控系统由硬件与软件两大部分构成,旨在实现对老人和儿童跌倒事件的精准监测与及时报警。硬件部分主要包括香橙派5开发板、摄像头模块、显示器模块以及通信模块EC20等。香橙派开发板尺寸紧凑(100mm×62mm),质量仅46g,便于携带与安装。其搭载Rockchip RK3588S处理器,采用4核心Cortex-A76(最高频率2.4GHz)和4核心Cortex-A55(最高频率1.8GHz)的大小核架构,并内置6Tops算力的AI加速器NPU,能够显著提升摄像头的帧率捕捉能力,确保目标检测模型的高效运行。开发板配备8GB LPDDR4X RAM和64GB eMMC ROM,具备高速读写和运行能力,保障系统运行流畅。通信模块EC20用于系统的报警通信,能够将跌倒事件的报警信息及时发送至监护人或紧急服务。
软件部分利用Anaconda虚拟环境搭建开发与运行环境。采用YOLOv8算法进行跌倒行为检测,该算法能够快速精准的检测出跌倒行为。通过摄像头模块采集图像和视频数据,YOLOv8算法能够精准识别跌倒动作,并结合通信模块EC20实现报警功能。
跌倒检测系统实现了从数据采集、处理到报警通知的完整功能流程,为老人和儿童提供了全方位的安全保障。系统框架如图1.1所示。
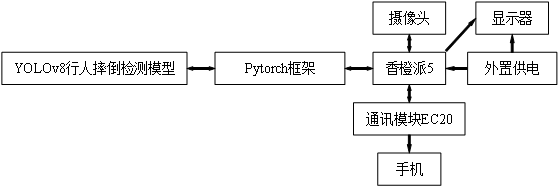
图1.1 摔倒识别系统总框图
1.2 系统运行流程
系统的运行流程主要分为四个关键步骤:数据预处理、模型训练、模型部署以及摔倒识别。在数据预处理阶段,需要收集大量的行人跌倒、站立图片,并标注跌倒、站立两种标签,构建模型的训练、测试数据集。数据标注工具采用LabelImg软件进行数据标注,所标注的数据用于训练模型,在标注过程中要准确的标注出跌倒行为的位置,形成高质量的数据集。然后,对图像数据进行预处理,包括调整图像大小、归一化等操作,以提高模型的训练效率。
在模型训练阶段,搭建PyTorch深度学习框架来训练YOLOv8模型。在训练过程中,调整YOLO模型的参数和超参数,优化模型的识别精度和速度,训练模型能够实时并准确的识别出跌倒行为。训练完成后,将训练好的模型部署到香橙派Orange Pi 5开发板平台上,通过摄像头模块实时捕捉摔倒图像,并将图像输入到模型中进行识别。最后,将识别结果显示在显示器模块上。
为了确保系统的能够快速准确的识别不同环境下的跌倒行为,还需要对模型进行数据更新训练和优化模型,以适应不同人员摔倒和不同光照环境的下的跌倒行为检测,从而提升模型检测跌倒行为的准确度。此外,系统还设计了通信模块EC20,用于将报警信息及时发送至监护人,提高了报警的及时性和跌倒后救治的有效时间。
1.3 系统硬件模块设计
本系统硬件部分主要包括香橙派Orange Pi5开发板、摄像头模块、显示器模块、外置供电模块和通信模块EC20等模块。
(1)香橙派Orange Pi5开发板
香橙派Orange Pi 5开发板实物图如图1.2所示,广泛应用于多种场景。它采用瑞芯微RK3588芯片,基于8nm LP制程,具备8核64位处理器,包括4个Cortex-A76(主频2.4GHz)和4个Cortex-A55(主频1.8GHz),并配备独立的NEON协处理器。此外,它还内嵌了6TOPS算力的NPU,支持INT4/INT8/INT16/FP16混合运算,能够满足多种AI场景的需求。在摔倒检测方面,所选的开发板能够快速识别摔倒行为。

图1.2 Orange Pi5开发板图
(2)摄像头模块
在摔倒识别系统中,摄像头模块是核心组成部分,承担着实时捕捉图像并进行检测识别的重要任务。当在家庭环境中用于对老人和儿童的摔倒动作进行识别时,系统需要在便携性与图像清晰度之间找到平衡,同时还要确保与香橙派Orange Pi5开发板的适配性。基于这些需求,本系统选择了海康威视USB摄像头。该摄像头通过转接板连接到系统中,其整体尺寸仅为59mm×29mm,小巧轻便,非常适合在家庭环境中使用。此外,该摄像头配备了高像素的传感器,像素高达1300万,能够以极高的清晰度捕捉到摔倒动作的每一个细节,确保系统能够准确地进行识别和分析。这种高分辨率的图像捕捉能力,结合其便携性设计,完美地满足了系统对于图像质量和便携性的双重要求。海康威视USB摄像头如图1.3所示。

图1.3 海康威视USB摄像头
(3)显示器模块
香橙派Orange Pi5开发板具备强大的视频输出能力,支持HDMI2.1和DP1.4两种视频输出接口,能够满足多种显示需求。其中,HDMI2.1接口支持8K分辨率视频输出,最高可达60Hz的刷新率,而DP 1.4接口的最大输出分辨率也可达8K、30Hz。这两种接口的配置使得Orange Pi5能够轻松应对高分辨率显示任务,为用户带来极致的视觉体验。
在摔倒识别系统的应用场景中,考虑到系统的便携性、成本以及实际显示需求,本系统选用了HDMI接口显示屏,其分辨率为1024px×600px。这种分辨率虽然不及8K的超高分辨率,但对于摔倒识别系统的显示需求来说已经足够,能够清晰地展示摄像头捕捉到的图像细节。通过HDMI线将显示屏连接到香橙派Orange Pi5开发板的HDMI接口上,系统可以实时显示摄像头捕捉到的画面,方便用户随时监控和查看识别结果。这种配置既满足了系统的功能需求,又保证了系统的经济性和实用性。
(4)外置供电模块
香橙派Orange Pi 5开发板采用Type-C接口进行供电,其标准充电规格为5V/4A。需要注意的是,开发板的电源接口不支持PD协商,且Type-C接口中只有一个具备供电功能。过高的电流或电压会导致开发板过载损坏,而过低则会导致供电不足,无法同时驱动开发板与显示器。
在家庭环境中,直接使用充电器为设备供电可能并不方便,尤其是在需要移动设备时。为解决这一问题,本系统采用了4节21700锂电池并联为开发板供电,并使用升压模块将电池原本的3.7V电压提升到5V,如图1.4所示,以满足开发板的供电需求。这种供电方式不仅保证了设备的充足续航,还方便工作人员携带和使用,确保系统在各种场景下都能稳定运行。
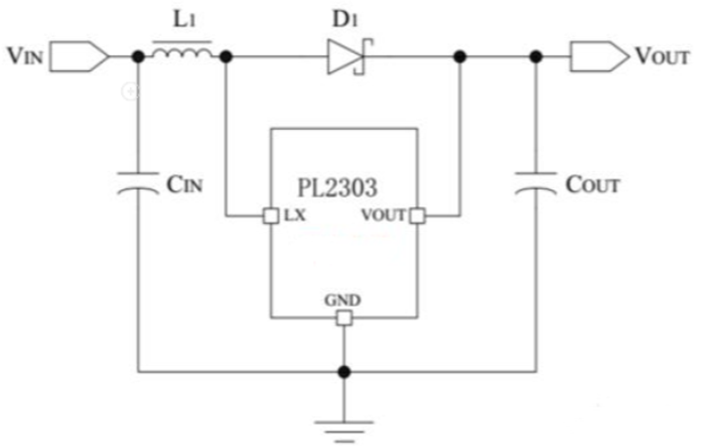
图1.4 升压模块原理图
(5)通信模块EC20
为了实现摔倒事件的及时报警功能,本系统引入了EC20通信模块。EC20是一款由Quectel提供的LTE Cat 4无线通信模块,支持多种网络制式,包括GSM、GPRS、EDGE、WCDMA、HSPA+以及LTE。该模块采用LTE 3GPP Rel.11技术,支持最大下行速率150Mbps和最大上行速率50Mbps。其供电电压范围为3.3V~4.3V,典型值为3.8V。在摔倒识别系统中,EC20模块通过其丰富的网络协议栈,能够将报警信息及时发送至监护人或紧急服务的手机端或其他终端设备,确保在发生摔倒事件时能够迅速通知相关人员采取救援措施。其功能框图如图1.5所示,实物图如图1.6所示。
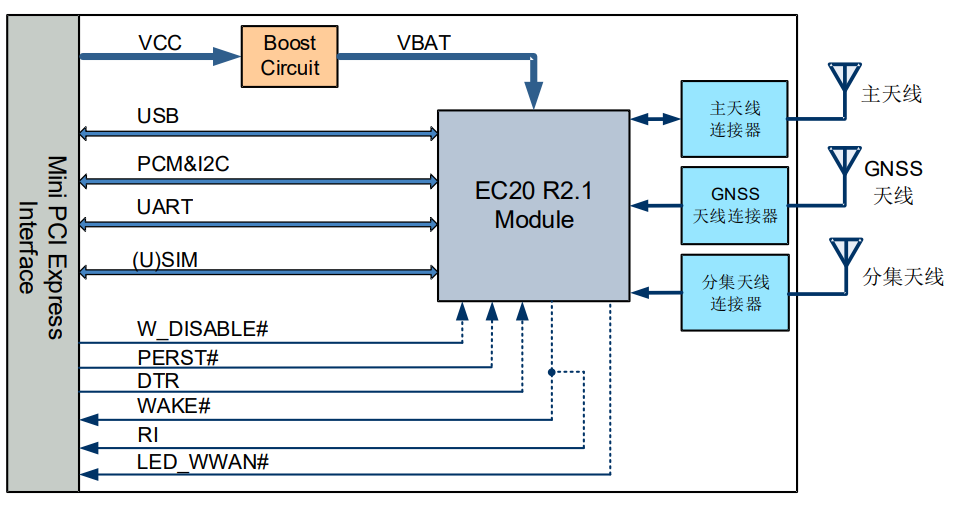
图1.5 通信模块EC20功能框图

图1.6 通信模块EC20实物图
第2章 摔倒识别模型的构建
2.1 模型的选用
YOLOv8模型的特征结构如图2.1所示,基于PyTorch框架实现,YOLOv8的整体架构延续了YOLO系列的单阶段检测器设计,采用端到端的方式直接预测目标的类别和边界框。其主要组成部分包括特征提取、特征融合和最终检测。
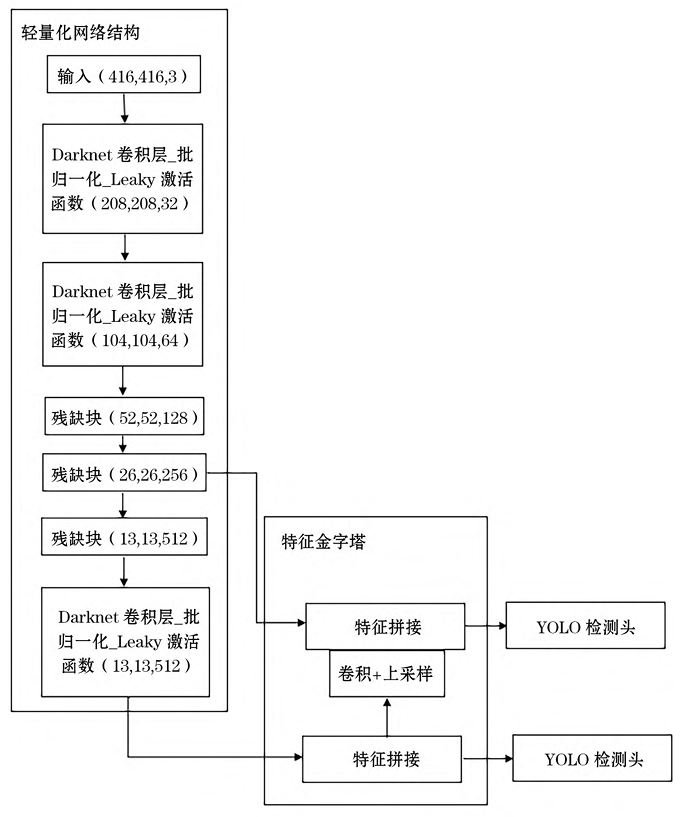
图2.1 YOLOv8特征结构
2.1.1 特征提取
YOLOv8模型在Backbone部分采用了经过优化改进的CSPDarknet53结构。这种结构巧妙地运用了Cross Stage Partial(CSP)设计理念,通过将特征图在不同阶段进行部分连接与融合,有效减少了计算量,避免了冗余计算,同时又能够保留丰富的特征信息,从而在降低运算资源消耗的同时,依然保持了较高的特征提取能力。相较于YOLOv5所使用的结构,YOLOv8做出了重要改进,移除了Focus模块。YOLOv8用更高效的卷积层来替代Focus模块,这种改进不仅进一步简化了整体网络结构,减少了网络的复杂度,还显著提升了模型的推理速度,使得模型在处理图像数据时能够更快速地提取出关键特征,从而在实际应用中展现出更优的性能表现,无论是面对大规模数据的处理还是实时性要求较高的场景,都能更好地满足需求。
2.1.2 特征融合
YOLOv8的Neck部分采用了优化后的PANet(Path Aggregation Network)结构,这一设计通过自底向上和自顶向下的路径聚合,有效增强了不同尺度特征之间的信息流动。具体来说,自顶向下的路径将高层的语义信息传递到低层特征,而自底向上的路径则将低层的细节信息传递到高层特征,两者结合使得每一层的特征都能包含丰富的多尺度信息。
此外,YOLOv8的Neck部分还通过增加特征金字塔的深度,进一步提升了特征融合的能力。这种更深的特征金字塔结构使得模型在处理小目标检测时表现更为出色。同时,优化后的PANet结构在保持高效特征融合能力的同时,也减少了计算开销,确保了模型的实时性。
2.1.3 最终检测
YOLOv8的Head部分采用了Anchor-Free设计,直接预测目标的中心点和宽高。这种设计减少了Anchor的复杂性和超参数调优的难度。使用了分离的检测头,分别处理分类和回归任务,提高了检测精度。引入了动态标签分配策略,根据任务的难度动态分配正负样本,提升了训练效率。
综上所述,YOLOv8模型凭借其高效的特征提取、改进的网络结构以及灵活的检测能力,非常适合用于行人摔倒识别任务,能够在实时监控中快速、准确地检测到摔倒事件,为保障行人安全提供有力支持。
2.2 数据集收集与处理
在构建人摔倒识别模型之前,首要任务是创建一个高质量的摔倒数据集。目前利用深度学习进行摔倒识别还处于初步探索阶段,缺乏开源数据集以供使用,因此需要自行制作数据集,而数据集的质量对模型的训练效果起着至关至关重要的作用。
首先需要确定识别的目标类别,本系统主要关注“摔倒”和“站立”两种姿态。为了确保数据的多样性和代表性,从不同光照条件、不同角度和不同背景环境中收集大量的图像,涵盖实际应用中可能出现的各种情况。例如,可以在室内和室外的不同光照条件下拍摄,从正面、侧面和背面等不同角度进行拍摄,同时在不同的背景环境中进行数据采集,如家庭环境、医院病房、养老院等。
使用开源的标注工具LabelImg对采集到的图像进行标注,标记出图像中人物的姿态类别(摔倒或站立),并手动绘制边界框。同时,为了提高模型的泛化能力,对标注后的数据进行数据增强。数据增强操作包括旋转、平移、缩放、翻转、亮度调整等,以模拟不同的拍摄条件和视角变化,使其能够处理各种实际场景中的人体姿态图像。
接着将标注并增强后的数据集划分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型参数和超参数,测试集用于评估模型的性能。一般来说,训练集占比最大,验证集和测试集占比相对较小,最后将划分好的数据集存储为模型训练所需的VOC格式。
2.3 模型训练
YOLOv8模型的网络结构主要包括四个部分:输入层、特征提取层、特征融合层和输出层。整个网络采用了深度可分离卷积和点卷积来减少计算量和参数数量,从而实现轻量级的目标检测。这种设计使得YOLOv8在保持高效检测性能的同时,能够适应资源受限的设备,如移动设备或嵌入式系统。
(1)输入层
网络的起始部分,负责接收待检测的图片数据。YOLOv8模型通常接受416×416大小的图片输入。在输入层,图片会经过一系列预处理操作,如缩放、归一化和颜色空间转换等,以便后续的特征提取。这些预处理步骤确保输入数据的格式和分布适合网络处理,从而提高模型的稳定性和检测性能。
(2)特征提取层
YOLOv8模型的核心部分,主要由一系列卷积层、批量归一化层和激活函数层组成。这些层共同构成了多个特征提取模块,用于从输入图片中提取出有用的特征信息。卷积层是特征提取的基础,通过对输入数据进行卷积操作来提取局部特征。在YOLOv8模型中,卷积层采用了深度可分离卷积和点卷积的组合,以减少计算量和参数数量。批量归一化层用于对卷积层的输出进行归一化处理,使得每一层的输出都具有适当的尺度,从而加速网络的训练过程并提高模型的泛化能力。激活函数层用于引入非线性因素,使得网络能够学习并逼近复杂的函数关系。在YOLOv8模型中,常用的激活函数包括ReLU和Leaky ReLU等。
(3)特征融合层
负责将不同尺度的特征信息进行融合,以提高目标检测的精度。在YOLOv8模型中,特征融合主要通过上采样和拼接操作实现。上采样操作可以将低分辨率的特征图放大到高分辨率,以便与高分辨率的特征图进行拼接。拼接操作则将不同尺度的特征图在通道维度上进行拼接,形成更丰富的特征表示。这种特征融合策略使得模型能够更好地捕捉到目标的多尺度信息,从而在检测小目标和大目标时都能表现出色。
(4)输出层
YOLOv8模型的最后一部分,负责生成目标检测的结果。在输出层,网络会输出一系列边界框以及对应的类别概率和置信度分数。这些边界框用于定位图片中的人体姿态(如摔倒或站立),而类别概率和置信度分数则用于判断目标的姿态类别和检测的可靠性。通过这些输出信息,YOLOv8模型能够为后续的应用场景(如智能监控、医疗辅助等)提供准确的检测结果。
在人摔倒识别任务中,YOLOv8模型的这种结构设计具有显著优势。由于摔倒场景的多样性和复杂性,特征提取层能够从不同角度和光照条件下提取出关键的特征信息。特征融合层则进一步增强了模型对多尺度特征的处理能力,使得模型能够准确区分摔倒和正常站立的姿态。最终,输出层的高精度检测结果为实时监控和预警提供了可靠的技术支持。
2.4 训练过程与结果
2.4.1 模型训练过程
准备数据集后,开始进行模型的训练。使用PyTorch深度学习框架,加载YOLOv8模型,并设置合适的训练参数和超参数。YOLOv8模型在结构上采用了深度可分离卷积和点卷积,有效减少了计算量和参数数量,使其更适合轻量级目标检测任务。
在训练过程中,首先需要加载预训练模型,这可以显著提升模型的收敛速度和最终性能。预训练模型通常在大规模数据集(如ImageNet)上训练得到,包含丰富的特征信息。通过不断迭代训练集,调整模型权重,使得模型能够准确识别图像中的人体姿态(如摔倒或站立)。
同时,使用验证集来监控模型的性能,并根据验证集上的表现调整模型参数和超参数,如学习率、批大小、迭代次数等。YOLOv8模型的训练流程如下:
① 加载预训练模型:使用预训练权重初始化模型,这有助于在有限的数据集上达到更好的性能。
② 设置训练参数:根据任务需求设置学习率、批大小等超参数。YOLOv8支持动态调整学习率,以适应不同阶段的训练。
③数据增强:在训练过程中,对输入图像进行数据增强(如旋转、翻转、缩放等),以提高模型的泛化能力。
④ 迭代训练:通过多次迭代训练集,逐步调整模型权重,优化检测精度。
⑤ 验证与优化:使用验证集评估模型性能,根据验证集的反馈调整超参数,以达到最佳性能。
2.4.2 模型训练结果
模型在预测中的表现可以用精确率、PR曲线、F1分数等数值体现。
① 在YOLOv8的结果中,通常会有一个P曲线图,横坐标为置信度阈值,纵坐标为精确率。随着置信度阈值的增加,精确率通常会升高,因为只有置信度较高的预测才会被判定为正样本。由图2.2可知,模型在置信度设置为0.8以及0.8以上时可以达到95%的精准度,对“摔倒”姿态的预测表现非常好。
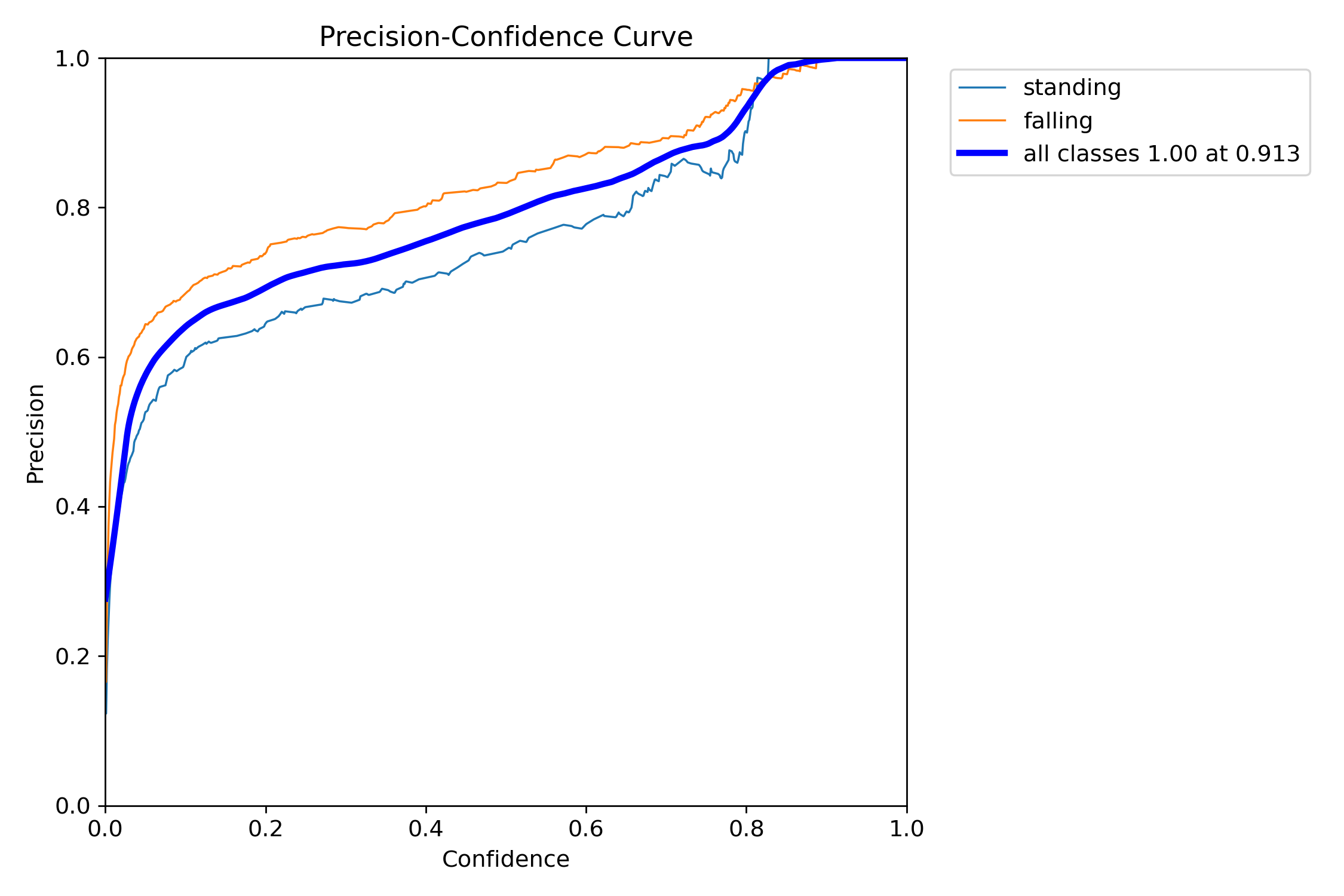
图2.2 P曲线图
② PR曲线展示了在不同分类阈值下,模型的精确率和召回率之间的关系。横轴表示召回率,纵轴表示精确率。PR曲线越靠近坐标轴的右上角,模型性能越好。曲线下方的面积即为平均精度(AP),所有类别的AP平均值即为mAP,用于综合评估多类别目标检测任务中模型的性能。由图2.3可知,模型对“摔倒”姿态P-R曲线下的面积,即在各个召回率下的预测精准度平均值能达到82%。需要收集更多更好的数据样本继续进行训练,以提高预测准确率。
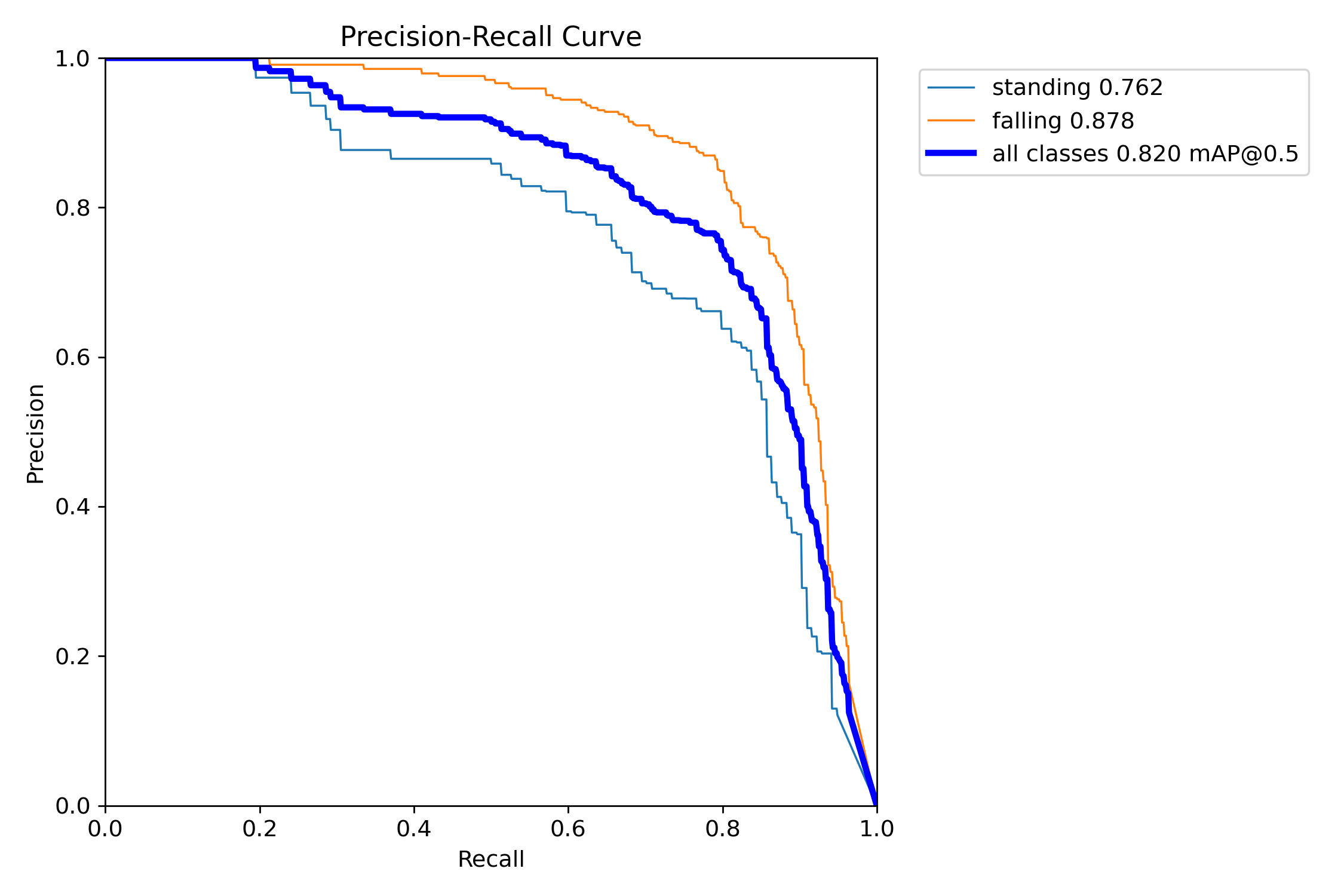
图2.3 PR曲线图
③ F1分数是精确率和召回率的调和平均数,用于综合评价模型的性能。它在精确率和召回率之间进行了平衡,取值范围为0到1,值越高表示模型性能越好。在YOLOv8的结果中,F1曲线图展示了不同置信度阈值下的F1分数变化情况。通常在某个置信度阈值下,F1分数会达到最大值,此时模型的精确率和召回率较为平衡。由图2.4可知,模型在置信度设置为0.559时,F1分数可达到0.77,在精确率和召回率之间进行了平衡,模型性能较好。
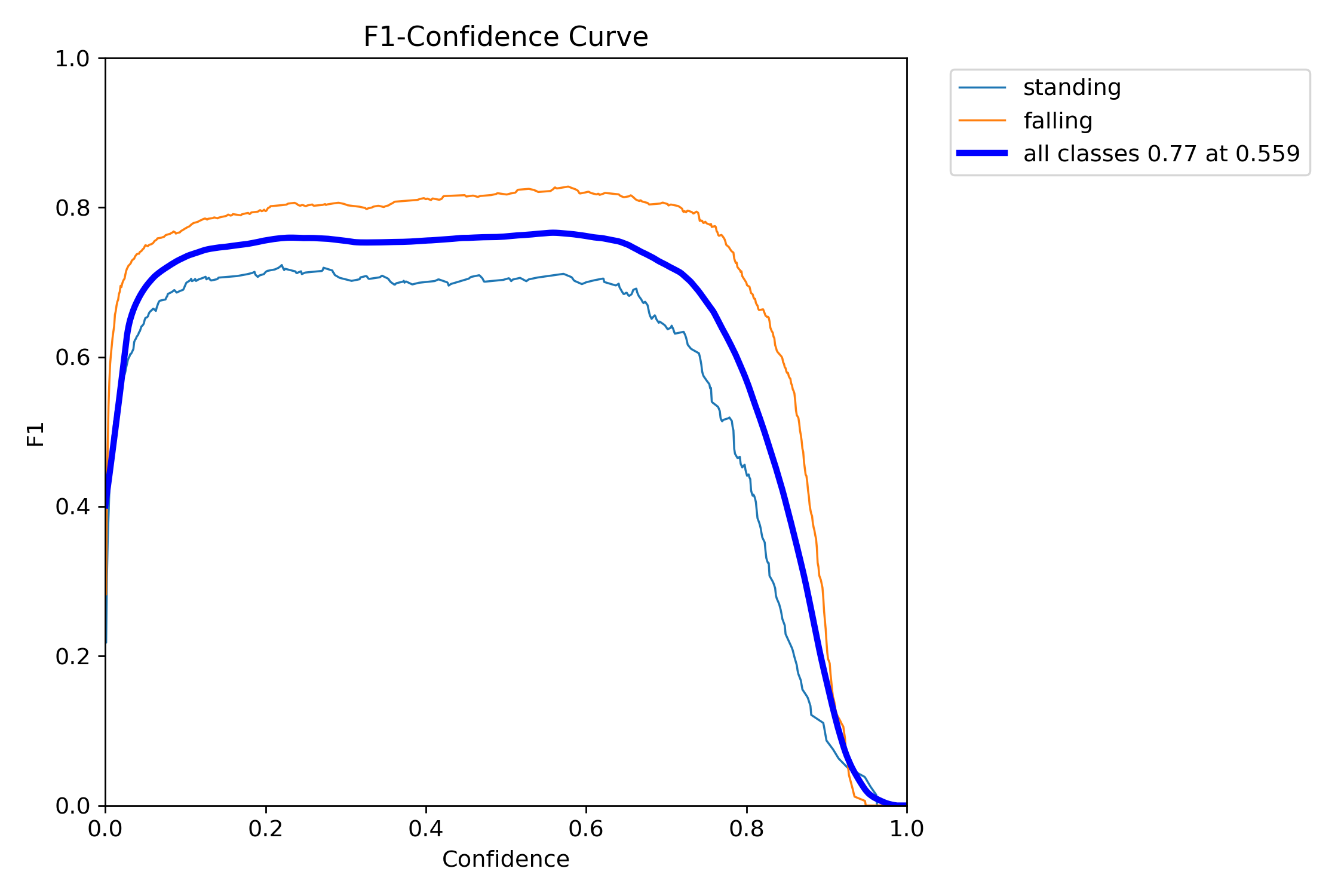
图2.4 F1分数曲线图
在本次模型训练过程中,影响准确率的最关键因素是训练样本不足。为了提升模型的性能,需持续搜集更多高质量的样本,以便在未来的训练迭代中,将各类别的预测准确率提升至理想水平。
第3章 摔倒识别模型部署与测试
3.1 模型部署
为了在实际应用中部署训练好的人摔倒识别模型,需要将模型集成到香橙派的硬件平台上。这涉及到将模型文件、权重以及必要的依赖库移植到开发板上,并编写推理代码以实现实时图像的处理和识别。
首先,将YOLOv8模型转换为PyTorch Lite格式,这是一种轻量级的模型格式,特别适用于移动设备和嵌入式设备。转换过程中,利用PyTorch Lite Converter 工具对模型进行优化,以减少推理时间和内存占用。优化步骤包括去除冗余操作、量化模型权重等,这些优化措施可以显著提升模型在低功耗设备上的运行效率。
然后,将转换后的模型文件、权重以及依赖库复制到香橙派Orange Pi5开发板的存储设备中。并编写一个基 PyTorch Lite的推理程序,该程序能够读取输入的图像,将其预处理为模型所需的格式,并通过模型进行推理。推理结果将输出为识别到的姿态类别(如“摔倒”或“站立”)及其置信度。
在部署过程中,还需要考虑实时性能的要求和确保模型在实际应用中的鲁棒性,还需要对输入图像进行适当的预处理。对图像进行缩放、归一化和颜色空间转换,以确保输入数据的格式和分布与训练时一致。同时,推理程序需要能够处理不同分辨率和格式的输入图像,并在检测到摔倒姿态时及时发出警报或通知。
模型预测流程如下:
① 图像采集:从摄像头或其他图像源获取输入图像。
② 图像预处理:对图像进行缩放、归一化等操作,使其符合模型输入要求。
③ 模型推理:将预处理后的图像输入到 PyTorch Lite 模型中进行推理。
④ 结果解析:解析模型输出,提取姿态类别和置信度。
⑤ 警报或通知:如果检测到摔倒姿态,触发警报或发送通知。
通过上述步骤,可以将YOLOv8人摔倒识别模型成功部署到香橙派Orange Pi5开发板上,实现实时、高效的姿态识别功能,为智能监控、医疗辅助等应用场景提供技术支持。
3.2 模型测试
为确保模型在香橙派平台的效能得到准确评估,本文引入了240张不同质量级别的人摔倒图像作为输入样本,包含“摔倒”和“站立”两种姿态各120张,以细致观察并记录模型在人摔倒识别任务中的表现情况。人摔倒识别结果见表3.1。试验结果表明,经过优化后的YOLOv8模型在香橙派上能够实时识别姿态,识别准确率达到93.3%。
表3.1 摔倒识别结果表
正确识别 |
错误识别 |
|
摔倒 |
112 |
8 |
站立 |
118 |
2 |
对于高质量的人摔倒图像,模型能够准确识别出姿态的类别(“摔倒”或“站立”),并给出较高的置信度。这些图像通常具有清晰的轮廓、良好的光照条件以及较少的背景干扰,使得模型能够快速且准确地进行判断。然而,对于质量较差或存在干扰的图像,例如在低光照环境下拍摄的图像、背景复杂或存在遮挡的图像,模型的识别性能可能会有所下降。尽管如此,模型仍然能够给出有意义的结果,例如在置信度较低时提示可能存在误判,从而为实际应用提供了一定的容错能力。
此外,为了进一步验证模型的鲁棒性,还对不同场景下的图像进行了测试,包括室内、室外以及不同拍摄角度的图像。如图:

图3.1 室内摔倒检测图

图3.2 室外摔倒检测图

图3.3 摔倒不同角度检测图
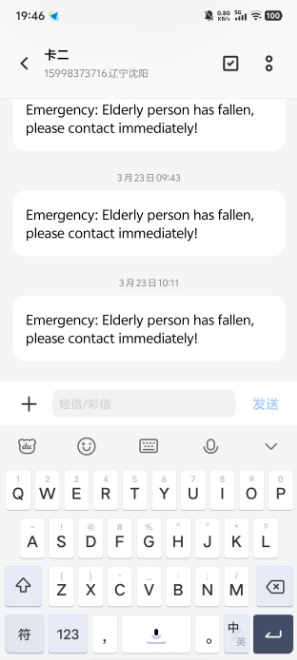
图3.4 电话和短信报警测试图
结果显示,经过优化的YOLOv8模型在多种复杂场景下均表现出良好的适应性,能够在实时监控系统中有效识别摔倒姿态,并且能够及时收到相关的报警信息,为智能监控和医疗辅助等应用场景提供了可靠的解决方案。
第4章 结论与建议
4.1 结论
针对传统跌倒检测技术在特定环境下的应用局限性,本文提出了一种部署于香橙派Orange Pi 5开发板上基于YOLOv8的轻量级人摔倒识别模型,并开展了相关测试,获得了以下结论:
(1)高效特征提取与目标检测性能
该系统利用摄像头采集图像,以改进的CSPDarknet53作为网络骨干,并融合了优化后的PANet特征融合模块,以提升网络的特征提取能力,从而实现了高效的目标检测性能。这种结构优化使得模型在处理复杂背景和多姿态场景时表现出色,能够快速准确地识别出“摔倒”和“站立”两种姿态。
(2)高准确率与快速检测能力
本研究采用YOLOv8模型对人摔倒识别进行了试验,测试结果表明,该模型的识别准确率达到了93.3%,本模型仅需将待识别对象置于镜头范围内即可迅速完成识别。尽管在图像质量较差或存在较大干扰的情况下,模型的识别性能会有所下降,但总体而言,其准确率和识别速度相较于传统方法仍展现出显著的提升。
(3)轻量化模型的高效部署
相较于YOLOv4等模型系列,轻量化的YOLOv8模型在不牺牲模型精度的情况下简化了其结构,使得该模型更适合在配置较低的设备上部署,具备了较高的便携性,更好地满足了智能监控和医疗辅助等实际应用场景的需求。
本系统成功解决了在复杂环境(如医院病房、养老院等)中进行人摔倒识别的难题,实现了对多种姿态的快速且精确辨识,显著提升了跌倒检测的效率与精确度。
4.2 建议
基于上述研究结论,提出以下建议:
(1)进一步优化模型结构
虽然YOLOv8模型已经表现出良好的性能,但仍有优化空间。可以尝试引入更先进的网络结构改进,例如使用更深的特征金字塔或更高效的注意力机制模块,进一步提升模型对复杂场景的适应能力和识别精度。
(2)增强数据集多样性和质量
在后续研究中,应进一步扩大数据集规模,增加不同场景、光照条件和拍摄角度的图像样本。同时,对数据集进行更严格的标注和筛选,确保数据质量,以提高模型的泛化能力。
(3)多模态融合与实时反馈机制
为了进一步提升系统的鲁棒性,可以考虑引入多模态数据(如深度图像、红外图像等)与RGB图像相结合,以弥补单一模态在某些场景下的不足。此外,结合实时反馈机制,如在检测到摔倒姿态时及时发出警报并通知相关人员,可以更好地满足实际应用需求。
(4)硬件优化与边缘计算
针对香橙派Orange Pi5等嵌入式设备的性能限制,可以进一步探索硬件优化策略,例如使用专用的AI加速芯片或优化设备的系统资源分配,以提高模型的推理速度和实时性。
通过以上建议,可以进一步提升人摔倒识别系统的性能和实用性,为智能监控和医疗辅助等领域提供更可靠的技术支持。