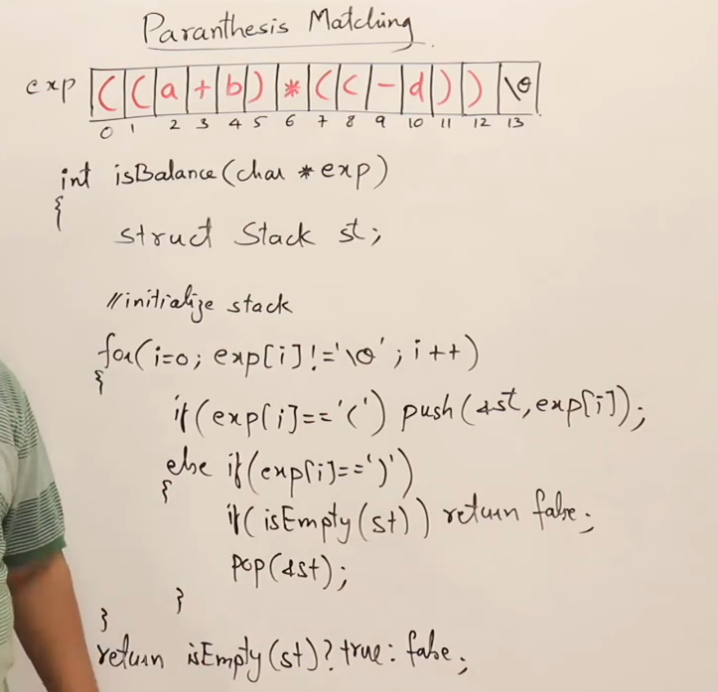目录
什么是匹配?
想象一下,我们拿到一个包含各种括号的字符串,比如 "({[]})"。我们的任务是判断这个字符串里的括号用法是否“正确”。在编程中,括号用于分组(如函数、表达式),如果不匹配,代码会出错。从第一性推导,这是一个“平衡”问题:打开和关闭必须一对一对应,像天平的两端。
匹配条件 = 所有打开括号数量 == 所有关闭括号数量,且顺序正确。
让我们从最简单的例子开始,逐步推导出这些规则。
成功匹配的情况分析(Valid Cases)
我们先看几个我们直觉上认为是“正确”的例子,并试图找出它们的共性。
例子 1:()
观察:有一个左括号
(,也有一个右括号)。它们是一对,不多不少。推论 1(数量原则):左括号和右括号的数量必须相等。
例子 2:{} 和 []
观察:
{必须和}配对,[必须和]配对。(]或者{)这种组合是错误的。推论 2(类型原则):成对的括号必须是同一类型。左括号是
(,则配对的右括号必须是)。
例子 3:(())
观察:这里有两个
(和两个)。我们从左到右看:遇到第1个
(:我们知道,有一个“任务”开始了,我们需要在后面找到一个)来结束它。遇到第2个
(:又一个“新任务”开始了。这个任务比第一个任务更“紧急”,因为它更晚出现。遇到第1个
):这个右括号是来结束哪个任务的?根据就近原则,它应该结束那个最新开始的、尚未完成的任务,也就是第2个(开启的任务。好,()这对内部的括号匹配成功了,这个“新任务”完成了。遇到第2个
):现在,内部的那个任务已经解决了。这个)用来结束哪个任务呢?它用来结束那个最开始的、被搁置的旧任务,也就是第1个(开启的任务。()这对外部的括号也匹配成功了。
推论 3(嵌套/顺序原则):这是一个至关重要的原则。当有多个括号嵌套时,一个右括号必须与离它最近的、尚未匹配的那个左括号进行配对。换句话说,最后打开的括号,必须最先被关闭。
当字符串走完,所有开启的任务都被一一正确地完成了,没有任何遗留,也没有任何中途的错误。我们就判断这个字符串是成功匹配的。
不成功匹配的情况分析(Invalid Cases)
不成功,就是违反了上述三条原则中的任意一条。
不成功条件 = (打开数 != 关闭数) 或 (类型不匹配) 或 (顺序违反最近匹配)。
情况 1:违反“数量原则”
例子:
(()分析:从左到右,我们开启了两个任务,但只完成了一个。当字符串结束时,我们还有一个“未完成的任务”(第一个
()被遗留下来了。这是不匹配的。
例子:
())分析:我们开启了任务1 (
()。然后遇到),任务1完成。接着又遇到了一个),但此时已经没有任何等待被完成的任务了。这个多出来的)无家可归,所以是不匹配的。
情况 2:违反“类型原则”或“嵌套原则”
这两个原则常常是同时被违反的,本质上都是顺序错了。
例子:
(]分析:开启任务
(。遇到]。我们期望一个)来关闭当前任务,但来了一个]。类型不匹配。失败。
例子:
([)](交叉嵌套)分析:这是最典型的嵌套错误。
遇到
(:开启任务1(等待))。遇到
[:开启任务2(等待])。任务2是当前最紧急的。遇到
):一个关闭符号。它应该尝试去关闭那个最紧急的任务,也就是任务2。但任务2需要的是],来的却是)。类型不匹配!所以,尽管字符串里有一个(和一个),但它们的配对被一个未关闭的[阻断了。失败。
特殊与边界情况分析(Edge Cases)
一个完备的分析必须考虑这些不那么典型的例子,以确保算法 robust(稳健)。
情况 1:空字符串
""分析:没有任何括号,所以也就不存在任何不匹配的可能。它没有任何“未完成的任务”。因此,我们应该视其为成功匹配。这是逻辑上的“零态”。
情况 2:不含任何括号的字符串
"hello world"分析:同上。没有开启任何与括号相关的任务,自然也没有任何错误。应视为成功匹配。
情况 3:只有左括号的字符串
"((["分析:开启了多个任务,但直到字符串结束,一个都没有完成。这是“数量原则”的违反,不匹配。
情况 4:只有右括号的字符串
")]}"分析:当遇到第一个
)时,我们发现根本没有任何开启的任务在等待它。它直接就变成了“无家可归”的括号。所以,不匹配。
为什么栈合适?
从以上分析,我们需要什么:
遍历字符串从左到右(线性时间,O(n),n是字符串长度,可复制:O(n))。
遇到打开:括号匹配需要“最近匹配”原则:每个关闭括号必须匹配最近的未匹配打开括号。
遇到关闭:遍历字符串时,遇到打开括号,需要“记住”它(包括类型和位置),因为以后要匹配。
遇到关闭括号时,必须“取出”最近记住的打开括号,检查类型是否匹配。如果没有可取出的,或类型不对,就失败。
结束时,如果还有记住的打开括号没匹配,就失败。
这个“记住”和“取出”的过程,必须是“后进先出”:最晚记住的打开(最近的),必须最早取出匹配。这正好是栈的本质(LIFO)。
所以我们应该使用栈(stack)来解决问题。
代码实现
第一步:打好框架——函数签名与初始化
我们的目标是编写一个函数,它接收一个字符串,返回一个判断结果(比如,1 代表成功,0 代表失败)。那么,函数的基本框架应该是什么样子?
int isValid(const char* str) {
// 这里将是我们的主战场
}根据我们的理论,我们需要一个栈来辅助我们。那么,在函数开始时,我们最先要做的事情,就是准备好这个工具。
数据结构:链表栈的操作实现( Implementation os Stack using List)-CSDN博客
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 此处省略我们已经熟知的链式栈的定义和函数声明
// ...
int isValid(const char* str) {
// 第一要务:创建我们的“待办任务”列表,也就是一个空栈。
LinkedStack* s = CreateStack();
// ... 接下来是核心逻辑 ...
// (先在脑中记下:函数结束前,一定要销毁这个栈,防止内存泄漏)
}当然也可以使用数组栈:
#include <stdio.h>
struct Stack {
char arr*; // 存char类型的括号
int top; // 栈顶索引
int size; //栈的大小
};我们已经搭建好了舞台,并请出了主角——栈。
第二步:核心流程——遍历字符串
我们要对字符串进行判断,就必须逐个检查它的每一个字符。最直接的方式是什么?一个循环。
int isValid(const char* str) {
LinkedStack* s = CreateStack();
int len = strlen(str); // 在循环外获取一次长度,效率更高
// 从左到右,一个不漏地检查字符串中的每个字符
for (int i = 0; i < len; i++) {
char c = str[i];
// 在这里,我们需要根据 c 的类型做出不同的反应
}
// ... 循环结束后的最终判断 ...
// 销毁栈...
}第三步:填充逻辑——处理左括号
在循环中,我们遇到的第一类字符是左括号 ( { [。根据我们的映射,遇到它们就意味着“添加一个新任务”。在栈这个工具上,“添加任务”对应的操作是什么?是 Push。
// ... 在 for 循环内部 ...
for (int i = 0; i < len; i++) {
char c = str[i];
// 情况一:如果当前字符是左括号
if (c == '(' || c == '{' || c == '[') {
// 就将其压入栈中,作为一个“待办任务”记录下来
Push(s, c);
}
// 还需要处理右括号...
}
// ...第四步:填充逻辑——处理右括号(关键部分)
现在是更复杂的情况:如果遇到的字符 c 是一个右括号 ) } ]。这意味着需要“销账”了。销账前,我们必须先问一个问题:“有账可销吗?”
如果根本没有待办任务怎么办? 这对应于像 ")]}" 这样的字符串。当我们遇到第一个 ) 时,待办列表(栈)是空的。这显然是错误的。
完善代码(在 if 后面追加 else if):
// ...
else if (c == ')' || c == '}' || c == ']') {
// 这是来“销账”的信号。
// 但我们必须先检查账本(栈)是不是空的。
if (IsEmpty(s)) {
// 如果是空的,说明根本没有对应的左括号。直接失败。
// 在返回前,必须清理我们创建的栈!
DestroyStack(s);
return 0; // 0 代表 false,不匹配
}
// 如果栈不为空,说明有账可销,我们继续...
}
// ...如果有待办任务,它们匹配吗? 如果栈不为空,说明有等待被关闭的左括号。我们需要检查的,是当前这个右括号 c 是否和 栈顶那个最新的左括号 配对。
完善代码(在 IsEmpty 检查之后):
// ... 在 else if 内部,IsEmpty(s) 判断为 false 之后 ...
// 1. 先看一眼栈顶的“待办任务”是什么
char topChar = Peek(s);
// 2. 检查当前右括号 c 是否与栈顶的 topChar 匹配
if ((topChar == '(' && c == ')') ||
(topChar == '{' && c == '}') ||
(topChar == '[' && c == ']')) {
// 如果匹配,说明这个任务完成了,把它从栈中“销账”
Pop(s);
} else {
// 如果不匹配(比如栈顶是'[',来的却是')'),说明顺序错误。
// 立即判定失败。
DestroyStack(s);
return 0; // 不匹配
}到此,循环内部的所有逻辑都已处理完毕。
第五步:收尾工作——最终裁定与清理
当 for 循环正常走完,没有任何中途失败,这就代表匹配成功了吗?不一定。想一想 (() 这个例子,它会顺利走完循环,但显然是失败的。
循环结束后,我们如何做出最终的判决?回顾我们的分析:一个完美匹配的字符串,到最后,它的“待办任务”列表应该是空的。
// ... for 循环结束 ...
// 现在,进行最终的裁决。
// 如果栈是空的,意味着所有左括号都被正确地关闭了。
// 如果栈里还有东西,意味着有左括号没有被关闭。
int result = IsEmpty(s);
// 在返回最终结果之前,履行我们的承诺,销毁栈。
DestroyStack(s);
// 返回最终结果
return result;我们将上述思考过程的碎片组合起来,就得到了最终的、逻辑严谨的代码。
// (此处省略我们已经熟知的链式栈的定义和函数声明)
int isValid(const char* str) {
// 第1步:创建栈
LinkedStack* s = CreateStack();
int len = strlen(str);
// 第2步:遍历字符串
for (int i = 0; i < len; i++) {
char c = str[i];
// 第3步:处理左括号
if (c == '(' || c == '{' || c == '[') {
Push(s, c);
}
// 第4步:处理右括号
else if (c == ')' || c == '}' || c == ']') {
// 4a: 如果栈已空,直接失败
if (IsEmpty(s)) {
DestroyStack(s);
return 0;
}
// 4b: 检查是否匹配
char topChar = Peek(s);
if ((topChar == '(' && c == ')') ||
(topChar == '{' && c == '}') ||
(topChar == '[' && c == ']')) {
// 匹配则出栈
Pop(s);
} else {
// 不匹配则失败
DestroyStack(s);
return 0;
}
}
}
// 第5步:最终裁定与清理
int result = IsEmpty(s);
DestroyStack(s);
return result;
}