设计一个结合公司历史测试用例和AI能力的智能测试用例生成工具
工具架构设计
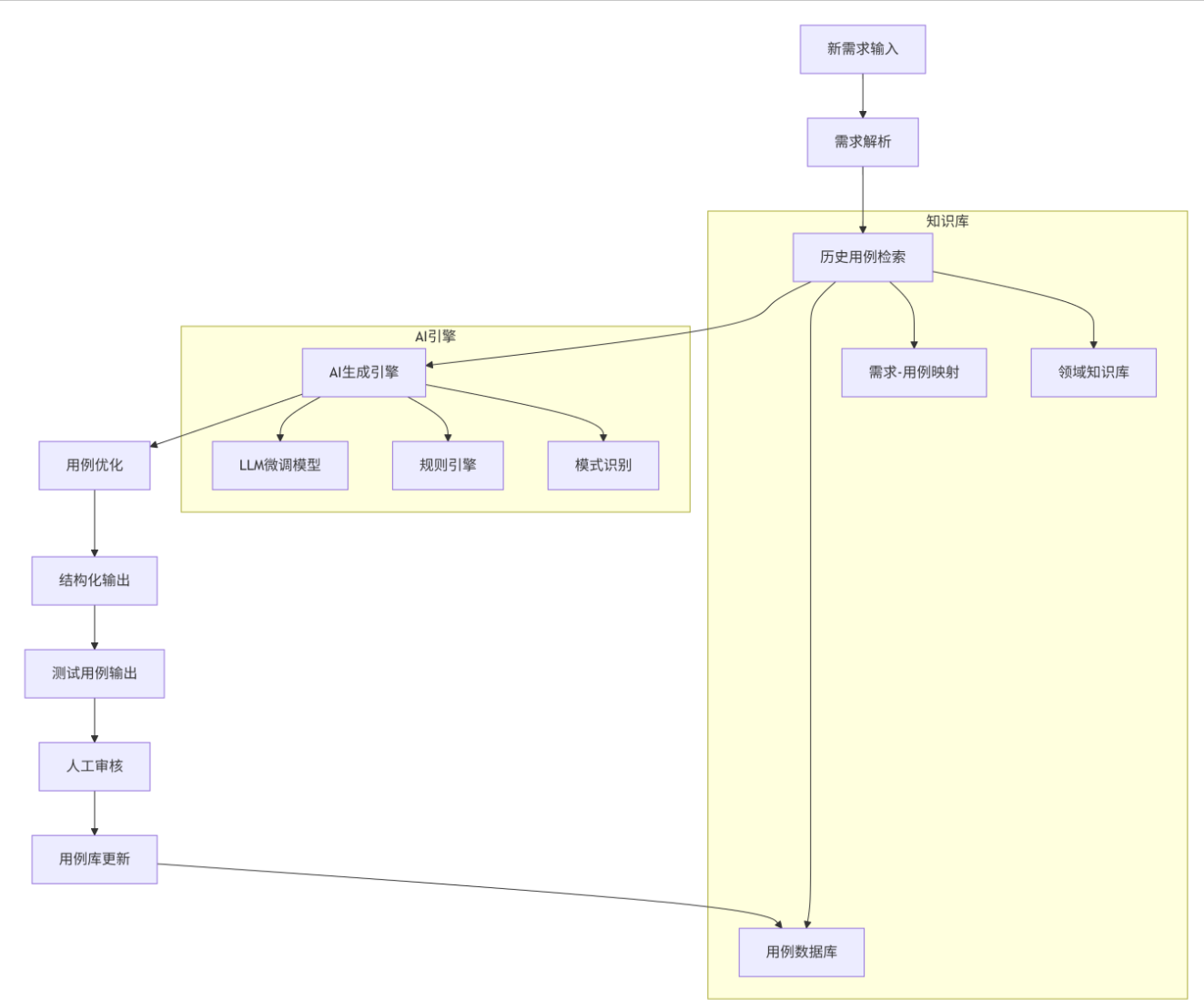
核心组件实现
1. 历史用例集成模块
class HistoricalCaseRetriever:
def __init__(self, case_db_path):
# 加载用例数据库
self.case_db = self._load_case_database(case_db_path)
# 创建语义检索索引
self.index = self._create_semantic_index()
def _load_case_database(self, path):
"""加载公司历史测试用例库"""
# 支持多种格式:Excel, TestRail, JIRA, 自定义JSON等
if path.endswith('.xlsx'):
return pd.read_excel(path).to_dict('records')
elif path.endswith('.json'):
with open(path, 'r') as f:
return json.load(f)
# 其他格式处理...
def _create_semantic_index(self):
"""创建语义检索索引"""
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# 提取用例关键信息
case_texts = [
f"{case['module']}: {case['title']} | {case['steps']}"
for case in self.case_db
]
# 生成嵌入向量
case_embeddings = model.encode(case_texts, convert_to_tensor=True)
return {'model': model, 'embeddings': case_embeddings, 'cases': self.case_db}
def retrieve_similar_cases(self, new_requirement, top_k=5):
"""检索相似历史用例"""
# 编码新需求
query_embedding = self.index['model'].encode(new_requirement, convert_to_tensor=True)
# 计算相似度
cos_scores = util.pytorch_cos_sim(query_embedding, self.index['embeddings'])[0]
top_results = torch.topk(cos_scores, k=top_k)
# 返回最相关的用例
return [{
'score': score.item(),
'case': self.index['cases'][idx]
} for score, idx in zip(top_results[0], top_results[1])]2. AI生成引擎
class TestCaseGenerator:
def __init__(self, api_key, company_rules):
self.llm = ChatOpenAI(
model="gpt-4-turbo",
api_key=api_key,
temperature=0.7
)
self.rules = company_rules # 公司测试规范
def generate_with_context(self, requirement, similar_cases):
"""结合历史用例生成新用例"""
# 构建提示词
prompt = self._build_prompt(requirement, similar_cases)
# 调用AI生成
response = self.llm.invoke(prompt)
return self._parse_output(response.content)
def _build_prompt(self, requirement, similar_cases):
"""构建包含公司规范和历史用例的提示词"""
prompt = f"""
# 角色
你是{self.rules['company_name']}的高级测试工程师,需根据需求生成符合公司规范的测试用例。
# 公司测试规范
{self.rules['testing_standards']}
# 需求描述
{requirement}
# 相关历史用例参考
{self._format_similar_cases(similar_cases)}
# 生成要求
1. 使用Gherkin语法:Feature, Scenario, Given, When, Then
2. 包含正向、逆向和边界测试场景
3. 每个场景包含至少3个测试步骤
4. 输出格式:
## 功能: [功能名称]
### 场景: [场景描述]
- 当 [条件]
- 并且 [条件] (可选)
- 那么 [预期结果]
5. 生成3-5个核心场景
"""
return prompt
def _format_similar_cases(self, cases):
"""格式化历史用例参考"""
return "\n".join([
f"参考用例 {i+1} (相似度:{case['score']:.2f}):\n"
f"模块: {case['case']['module']}\n"
f"标题: {case['case']['title']}\n"
f"步骤: {case['case']['steps']}\n"
for i, case in enumerate(cases)
])
def _parse_output(self, text):
"""解析AI输出为结构化用例"""
# 使用正则提取结构化信息
pattern = r"## 功能: (.+?)\n### 场景: (.+?)\n- 当 (.+?)\n(?:- 并且 (.+?)\n)?- 那么 (.+?)(?:\n\n|$)"
matches = re.findall(pattern, text, re.DOTALL)
test_cases = []
for match in matches:
feature, scenario, given, and_condition, then = match
test_cases.append({
"feature": feature.strip(),
"scenario": scenario.strip(),
"steps": {
"given": given.strip(),
"and": and_condition.strip() if and_condition else "",
"then": then.strip()
}
})
return test_cases3. 完整工作流
class SmartTestCaseGenerator:
def __init__(self, case_db_path, api_key, company_rules):
self.retriever = HistoricalCaseRetriever(case_db_path)
self.generator = TestCaseGenerator(api_key, company_rules)
self.validator = TestCaseValidator(company_rules) # 验证模块
def generate_test_cases(self, requirement):
# 检索相似用例
similar_cases = self.retriever.retrieve_similar_cases(requirement)
# AI生成新用例
generated_cases = self.generator.generate_with_context(requirement, similar_cases)
# 验证和优化
validated_cases = self.validator.validate(generated_cases)
return {
"similar_cases": similar_cases,
"generated_cases": validated_cases
}
def save_to_database(self, cases, requirement):
"""将新生成的用例存入数据库"""
# 实现数据库存储逻辑
pass公司规范集成示例
{
"company_name": "TechCorp",
"testing_standards": {
"priority_levels": ["P0-阻断", "P1-高", "P2-中", "P3-低"],
"required_fields": ["模块", "标题", "前置条件", "测试步骤", "预期结果", "优先级"],
"gherkin_standard": "必须使用Given-When-Then格式",
"boundary_rules": "所有数值输入必须测试边界值±1",
"error_handling": "每个功能必须包含至少1个异常场景",
"data_driven": "支持参数化的测试数据"
}
}使用示例
# 初始化工具
generator = SmartTestCaseGenerator(
case_db_path="company_test_cases.json",
api_key="sk-你的API密钥",
company_rules=load_company_rules("techcorp_rules.json")
)
# 输入新需求
requirement = """
用户注册功能需求:
1. 支持手机号+验证码注册
2. 密码要求:8-16位,包含大小写字母和数字
3. 需要同意用户协议
4. 注册成功后自动登录
"""
# 生成测试用例
result = generator.generate_test_cases(requirement)
# 输出结果
print("检索到的相似用例:")
for i, case in enumerate(result['similar_cases']):
print(f"{i+1}. [{case['case']['module']}] {case['case']['title']} (相似度: {case['score']:.2f})")
print("\n生成的测试用例:")
for i, case in enumerate(result['generated_cases']):
print(f"## {case['feature']}")
print(f"### {case['scenario']}")
print(f"- 当 {case['steps']['given']}")
if case['steps']['and']:
print(f"- 并且 {case['steps']['and']}")
print(f"- 那么 {case['steps']['then']}\n")
# 保存到数据库
generator.save_to_database(result['generated_cases'], requirement)生成用例示例输出
## 功能: 用户注册功能
### 场景: 成功注册新用户
- 当 用户输入符合格式要求的手机号
- 并且 输入正确的验证码
- 并且 设置符合规则的密码(8-16位含大小写字母和数字)
- 并且 勾选用户协议
- 那么 系统创建新账户并自动登录
## 功能: 用户注册功能
### 场景: 手机号格式验证
- 当 用户输入不符合格式的手机号(如不足11位)
- 那么 系统提示"手机号格式错误"
## 功能: 用户注册功能
### 场景: 密码强度验证
- 当 用户设置纯数字密码
- 那么 系统提示"密码必须包含大小写字母和数字"关键优势
知识传承:将历史测试用例转化为可检索的知识库
规范遵循:通过提示词确保符合公司测试标准
智能生成:AI创造新场景 + 规则引擎保证覆盖率
持续优化:新生成的用例可反馈到知识库
效率提升:减少重复工作,聚焦创新性测试场景
部署建议
私有化部署:使用开源LLM(如Llama3)确保数据安全
版本控制:用例库与生成模型版本绑定
人工审核:关键系统用例必须人工验证
质量评估:添加生成用例的质量评分机制
集成CI/CD:与测试管理系统(TestRail/JIRA)对接
这个设计将公司历史资产与AI能力有机结合,既保证了测试用例的规范性和覆盖率,又通过AI生成了创新性测试场景,大幅提升测试设计效率。