背景意义
研究背景与意义
随着工业自动化和智能制造的快速发展,孔洞检测作为关键的质量控制环节,受到了广泛关注。孔洞的存在可能会影响产品的强度、密封性和整体性能,因此,准确、快速地检测孔洞对于保障产品质量至关重要。传统的孔洞检测方法多依赖于人工检查或简单的图像处理技术,这些方法不仅效率低下,而且容易受到人为因素的影响,导致检测结果的不一致性和不可靠性。因此,开发一种基于先进计算机视觉技术的自动化孔洞检测系统显得尤为重要。
近年来,深度学习技术的飞速发展为图像识别和目标检测提供了新的解决方案。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而广泛应用于各种视觉任务。特别是YOLOv11的改进版本,凭借其在准确性和速度上的优越表现,成为了研究者们关注的焦点。本项目旨在基于改进的YOLOv11模型,构建一个高效的孔洞检测系统,以实现对工业产品中孔洞的快速、准确检测。
为实现这一目标,我们将使用一个包含1500张经过标注的孔洞图像的数据集。该数据集专门针对孔洞这一单一类别进行了优化,确保模型能够专注于识别和定位孔洞特征。通过对数据集的精细处理和增强,我们期望提高模型的鲁棒性和泛化能力,使其在不同环境和条件下均能保持高效的检测性能。
本研究不仅将推动孔洞检测技术的发展,还将为相关领域的智能检测系统提供有力的技术支持,具有重要的理论意义和实际应用价值。通过这一项目,我们希望能够为工业生产提供更加智能化的解决方案,提升产品质量和生产效率。
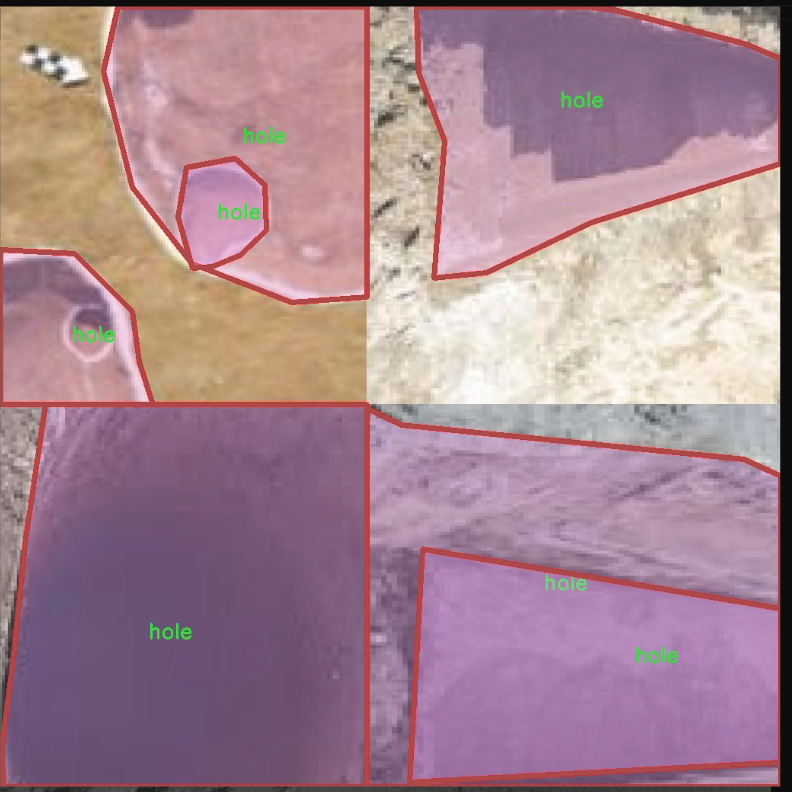
图片效果
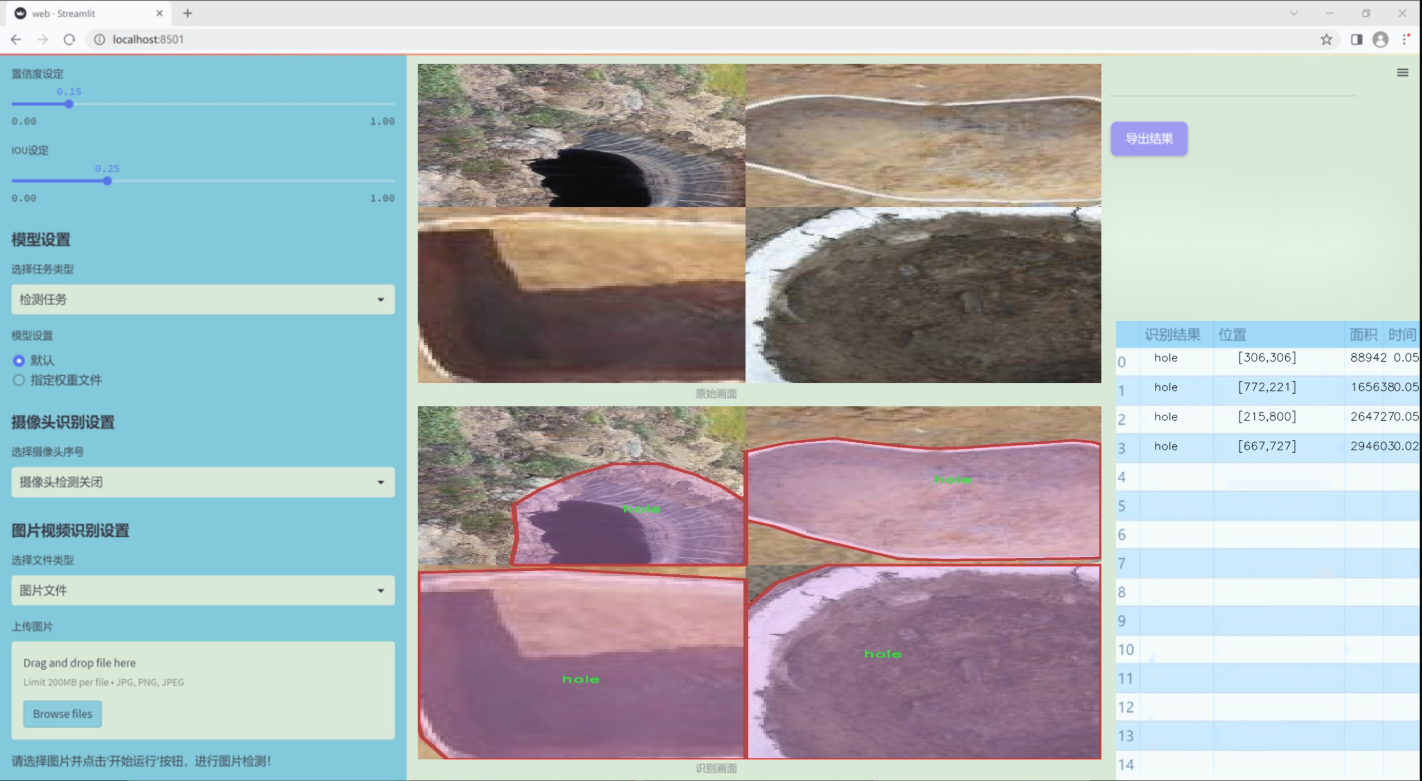
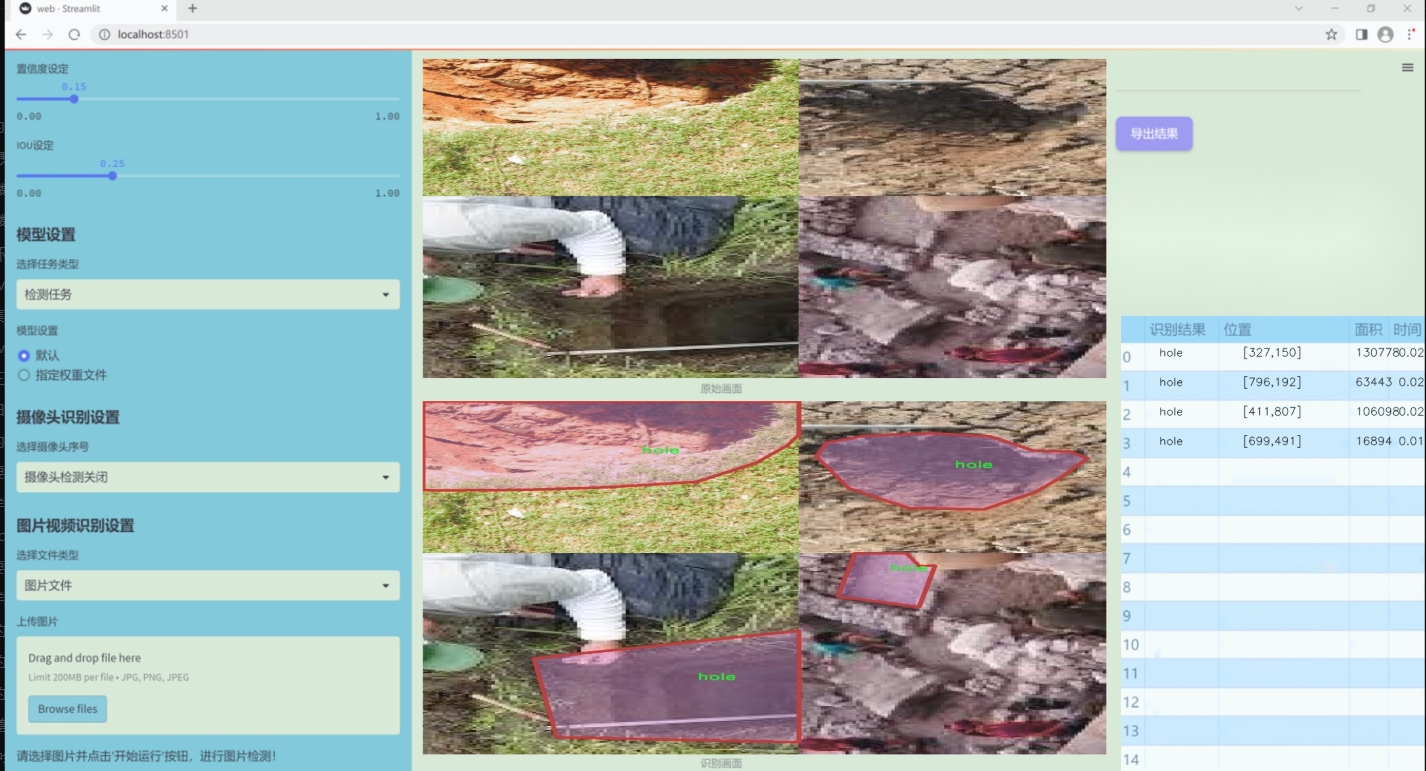
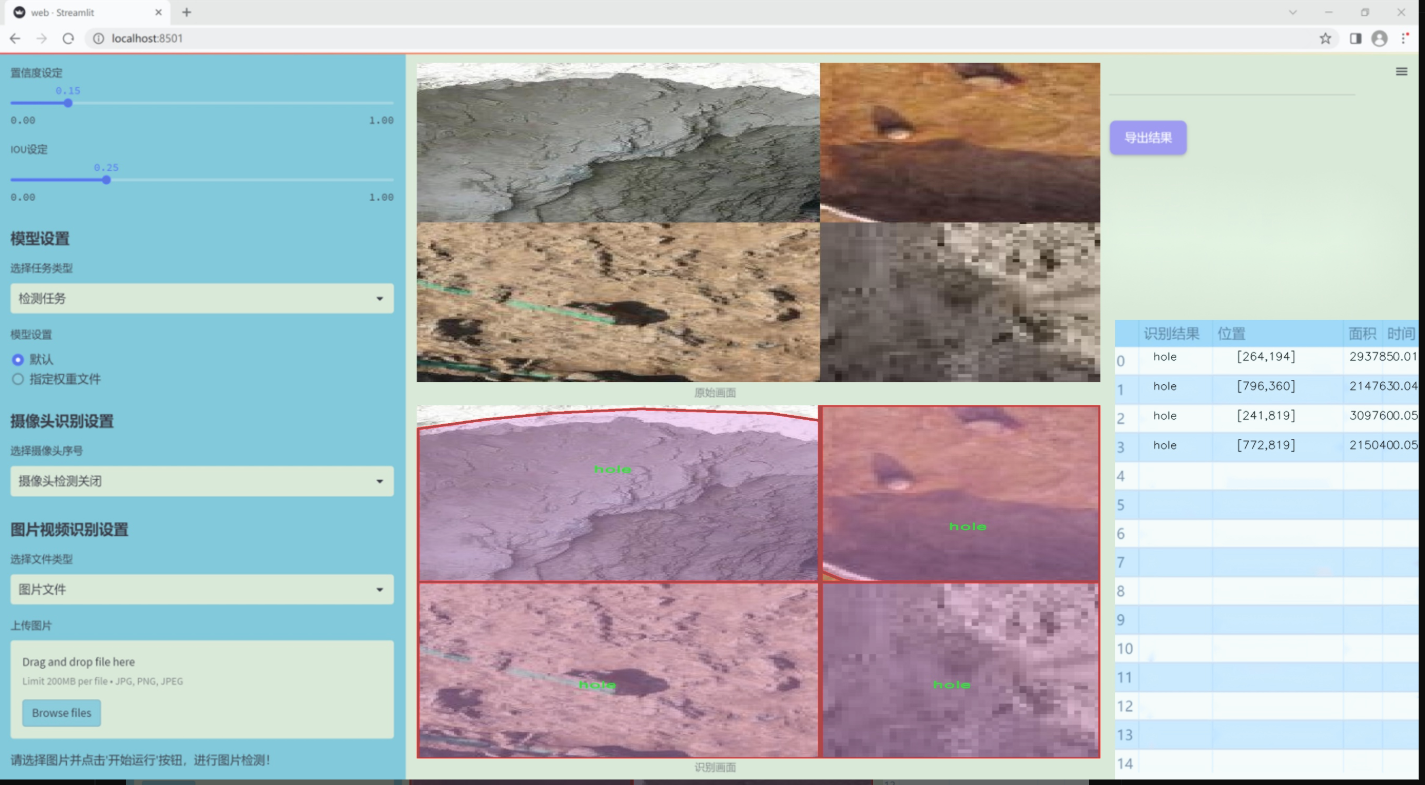
数据集信息
本项目数据集信息介绍
本项目旨在通过改进YOLOv11算法,构建一个高效的孔洞检测系统,以满足工业检测和质量控制的需求。为此,我们构建了一个专门针对孔洞检测的训练数据集,命名为“holes-resize”。该数据集专注于识别和分类不同尺寸和形状的孔洞,涵盖了实际应用中可能遇到的各种情况。数据集中包含的类别数量为1,具体类别为“hole”,这一设计使得模型能够专注于该特定目标的检测与识别。
在数据集的构建过程中,我们收集了大量具有代表性的孔洞图像,这些图像来源于不同的工业场景,包括但不限于制造业、建筑业和材料检测等领域。为了确保数据集的多样性和广泛性,我们对孔洞的尺寸、形状、背景和光照条件进行了精心设计,确保模型在训练过程中能够接触到丰富的样本,从而提高其泛化能力和检测精度。此外,为了增强数据集的实用性,我们还对图像进行了适当的预处理和增强,例如旋转、缩放和亮度调整,以模拟实际应用中可能遇到的各种情况。
通过使用该数据集进行训练,我们期望改进后的YOLOv11模型能够在孔洞检测任务中表现出色,能够快速、准确地识别出不同尺寸和形状的孔洞。这将为相关行业提供更为高效的检测工具,降低人工检测的成本,提高产品质量和生产效率。我们相信,这一数据集的构建和应用将为孔洞检测技术的发展提供重要的支持和推动力。


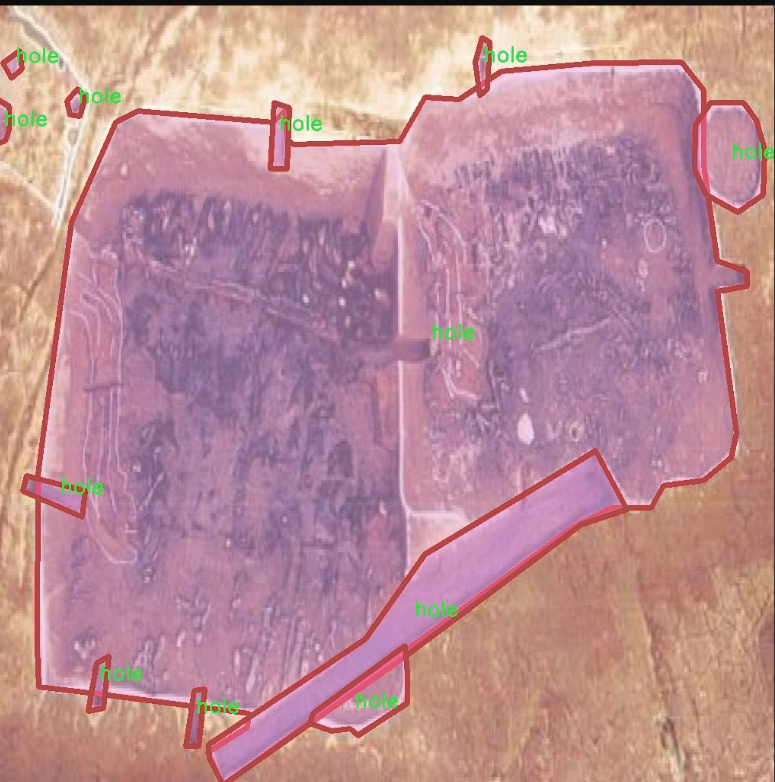

核心代码
以下是提取后的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import numpy as np
class Mlp(nn.Module):
“”“多层感知机(MLP)模块”“”
def init(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().init()
out_features = out_features or in_features # 输出特征数
hidden_features = hidden_features or in_features # 隐藏层特征数
self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换
self.act = act_layer() # 激活函数
self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换
self.drop = nn.Dropout(drop) # Dropout层
def forward(self, x):
"""前向传播"""
x = self.fc1(x) # 线性变换
x = self.act(x) # 激活
x = self.drop(x) # Dropout
x = self.fc2(x) # 线性变换
x = self.drop(x) # Dropout
return x
class CSWinBlock(nn.Module):
“”“CSWin Transformer的基本块”“”
def init(self, dim, num_heads, mlp_ratio=4., drop=0., attn_drop=0., norm_layer=nn.LayerNorm):
super().init()
self.dim = dim # 输入特征维度
self.num_heads = num_heads # 注意力头数
self.mlp_ratio = mlp_ratio # MLP的隐藏层比率
self.qkv = nn.Linear(dim, dim * 3) # 线性变换生成Q、K、V
self.norm1 = norm_layer(dim) # 归一化层
self.attn = LePEAttention(dim, num_heads=num_heads, attn_drop=attn_drop) # 注意力层
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), out_features=dim) # MLP层
self.norm2 = norm_layer(dim) # 归一化层
def forward(self, x):
"""前向传播"""
img = self.norm1(x) # 归一化
qkv = self.qkv(img).reshape(x.shape[0], -1, 3, self.dim).permute(2, 0, 1, 3) # 生成Q、K、V
x = self.attn(qkv) # 注意力计算
x = x + self.mlp(self.norm2(x)) # 加上MLP的输出
return x
class CSWinTransformer(nn.Module):
“”“CSWin Transformer模型”“”
def init(self, img_size=640, in_chans=3, num_classes=1000, embed_dim=96, depth=[2,2,6,2], num_heads=12):
super().init()
self.num_classes = num_classes # 类别数
self.embed_dim = embed_dim # 嵌入维度
self.stage1_conv_embed = nn.Sequential(
nn.Conv2d(in_chans, embed_dim, 7, 4, 2), # 卷积层
nn.LayerNorm(embed_dim) # 归一化层
)
self.stage1 = nn.ModuleList([
CSWinBlock(dim=embed_dim, num_heads=num_heads) for _ in range(depth[0]) # 堆叠CSWinBlock
])
# 其他阶段的初始化略去
def forward(self, x):
"""前向传播"""
x = self.stage1_conv_embed(x) # 初始卷积嵌入
for blk in self.stage1:
x = blk(x) # 通过每个块
return x
示例代码,创建模型并进行前向传播
if name == ‘main’:
inputs = torch.randn((1, 3, 640, 640)) # 输入张量
model = CSWinTransformer() # 创建模型
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的尺寸
代码说明:
Mlp类:实现了一个简单的多层感知机,包含两个线性层和一个激活函数,支持Dropout。
CSWinBlock类:实现了CSWin Transformer的基本构建块,包含注意力机制和MLP。
CSWinTransformer类:整体模型结构,包含输入卷积层和多个CSWinBlock的堆叠。
前向传播:模型通过输入数据进行前向传播,输出特征。
该代码实现了CSWin Transformer的基本结构,适用于图像分类等任务。
这个程序文件 CSWinTransformer.py 实现了 CSWin Transformer 模型,这是一个用于计算机视觉任务的深度学习模型。文件的结构主要包括模型的定义、辅助类和函数,以及一些用于创建不同规模模型的工厂函数。
首先,文件引入了必要的库,包括 PyTorch 和一些来自 timm 库的工具。接着,定义了几个重要的类。
Mlp 类实现了一个多层感知机(MLP),包含两个线性层和一个激活函数(默认为 GELU),并在每个线性层后添加了 dropout 层,以防止过拟合。
LePEAttention 类实现了一个局部增强的自注意力机制。该类通过将输入的特征图转换为窗口形式,来计算自注意力。它的构造函数接受多个参数,包括输入维度、分辨率、头数等,并定义了用于计算注意力的卷积层和 dropout 层。forward 方法实现了注意力的计算过程。
CSWinBlock 类是 CSWin Transformer 的基本构建块,它结合了自注意力机制和 MLP。该类的构造函数定义了输入的维度、头数、分辨率等参数,并初始化了注意力层和 MLP。forward 方法则实现了前向传播过程,计算输入的注意力输出并通过 MLP 进行处理。
img2windows 和 windows2img 函数用于在图像和窗口之间进行转换,方便进行自注意力计算。
Merge_Block 类用于在不同阶段之间合并特征图,通过卷积层和归一化层来处理特征。
CSWinTransformer 类是整个模型的核心,它定义了输入图像的处理流程,包括卷积嵌入、多个 CSWinBlock 的堆叠以及特征的合并。构造函数中设置了模型的各个阶段,并根据输入的参数初始化相应的层。forward_features 方法用于提取特征,而 forward 方法则是模型的前向传播入口。
此外,文件中还定义了一些辅助函数,例如 _conv_filter 用于转换权重,update_weight 用于更新模型权重,以及几个用于创建不同规模的 CSWin Transformer 模型的工厂函数(如 CSWin_tiny, CSWin_small, CSWin_base, CSWin_large)。
最后,在 main 部分,代码演示了如何使用不同规模的 CSWin Transformer 模型进行推理,生成随机输入并输出各个模型的特征图尺寸。
整体来看,这个文件实现了一个复杂的视觉 Transformer 模型,结合了自注意力机制和卷积操作,适用于各种计算机视觉任务。
10.4 head.py
以下是代码中最核心的部分,经过简化并添加了详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.utils.tal import dist2bbox, make_anchors
class Detect_DyHead(nn.Module):
“”“YOLOv8 检测头,使用动态头进行目标检测。”“”
def __init__(self, nc=80, hidc=256, block_num=2, ch=()):
super().__init__()
self.nc = nc # 类别数量
self.nl = len(ch) # 检测层数量
self.reg_max = 16 # DFL通道数量
self.no = nc + self.reg_max * 4 # 每个锚点的输出数量
self.stride = torch.zeros(self.nl) # 在构建过程中计算的步幅
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # 通道数
# 定义卷积层
self.conv = nn.ModuleList(nn.Sequential(Conv(x, hidc, 1)) for x in ch)
self.dyhead = nn.Sequential(*[DyHeadBlock(hidc) for _ in range(block_num)]) # 动态头块
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(hidc, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for _ in ch
)
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(DWConv(hidc, x, 3), Conv(x, c3, 1)),
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),
nn.Conv2d(c3, self.nc, 1),
)
for x in ch
)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() # DFL层
def forward(self, x):
"""前向传播,返回预测的边界框和类别概率。"""
for i in range(self.nl):
x[i] = self.conv[i](x[i]) # 通过卷积层处理输入
x = self.dyhead(x) # 通过动态头处理特征
shape = x[0].shape # 获取输出形状
for i in range(self.nl):
# 将 cv2 和 cv3 的输出进行拼接
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
# 如果在训练模式下,直接返回处理后的特征
if self.training:
return x
# 动态调整锚点和步幅
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
# 将特征展平并分割为边界框和类别
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1) # 分割为边界框和类别
# 解码边界框
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
y = torch.cat((dbox, cls.sigmoid()), 1) # 返回边界框和经过sigmoid处理的类别概率
return y
def bias_init(self):
"""初始化检测头的偏置,要求步幅可用。"""
for a, b, s in zip(self.cv2, self.cv3, self.stride):
a[-1].bias.data[:] = 1.0 # 边界框偏置初始化为1
b[-1].bias.data[:self.nc] = math.log(5 / self.nc / (640 / s) ** 2) # 类别偏置初始化
代码说明:
Detect_DyHead 类:这是 YOLOv8 的检测头,使用动态头进行目标检测。它负责处理输入特征并生成边界框和类别概率。
构造函数 (init):初始化检测头的参数,包括类别数量、隐藏通道、检测层数量等,并定义卷积层和动态头块。
前向传播 (forward):处理输入特征,经过卷积层和动态头,最终生成边界框和类别概率。
偏置初始化 (bias_init):初始化边界框和类别的偏置值,确保模型在训练时的稳定性。
这个简化版本保留了核心逻辑,并添加了详细的中文注释,便于理解代码的功能和实现。
这个文件 head.py 是一个实现 YOLOv8 检测头的 PyTorch 模块,包含多个类和方法,用于目标检测、分割和姿态估计等任务。文件中定义了多个检测头类,主要包括 Detect_DyHead、Detect_AFPN_P345、Detect_Efficient 等,这些类继承自 nn.Module,并实现了不同的前向传播逻辑和网络结构。
首先,文件导入了一些必要的库,包括 torch 和 torch.nn,以及一些自定义模块和函数。接着,定义了一个名为 Detect_DyHead 的类,它是 YOLOv8 的检测头,具有动态网格重建和导出模式的功能。该类的构造函数接受类别数、隐藏通道数、块数量和通道配置等参数,并初始化了多个卷积层和动态头块。
在 forward 方法中,输入的特征图经过卷积和动态头块处理后,生成预测的边界框和类别概率。该方法还处理了训练和推理模式下的不同逻辑,包括动态锚框的生成和输出格式的调整。
接下来,文件中定义了多个继承自 Detect_DyHead 的类,例如 Detect_DyHeadWithDCNV3 和 Detect_DyHeadWithDCNV4,这些类实现了不同的动态头块变体。类似地,Detect_AFPN_P345 和 Detect_AFPN_P345_Custom 等类实现了基于自适应特征金字塔网络(AFPN)的检测头。
文件中还定义了一些轻量级和高效的检测头类,如 Detect_Efficient 和 Detect_LSCD,这些类通过共享卷积和轻量化设计来提高模型的效率。每个检测头类都有自己的前向传播逻辑,处理输入特征并生成输出。
此外,文件中还实现了用于姿态估计和分割的检测头类,如 Pose_LSCD 和 Segment_LSCD,这些类在检测头的基础上增加了处理关键点和分割掩码的功能。
最后,文件中包含了一些用于初始化偏置和解码边界框的辅助方法,确保模型在训练和推理过程中能够正确处理数据。整体而言,这个文件实现了 YOLOv8 的多个检测头,支持多种任务和模型变体,具有灵活性和可扩展性。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻