一、概述
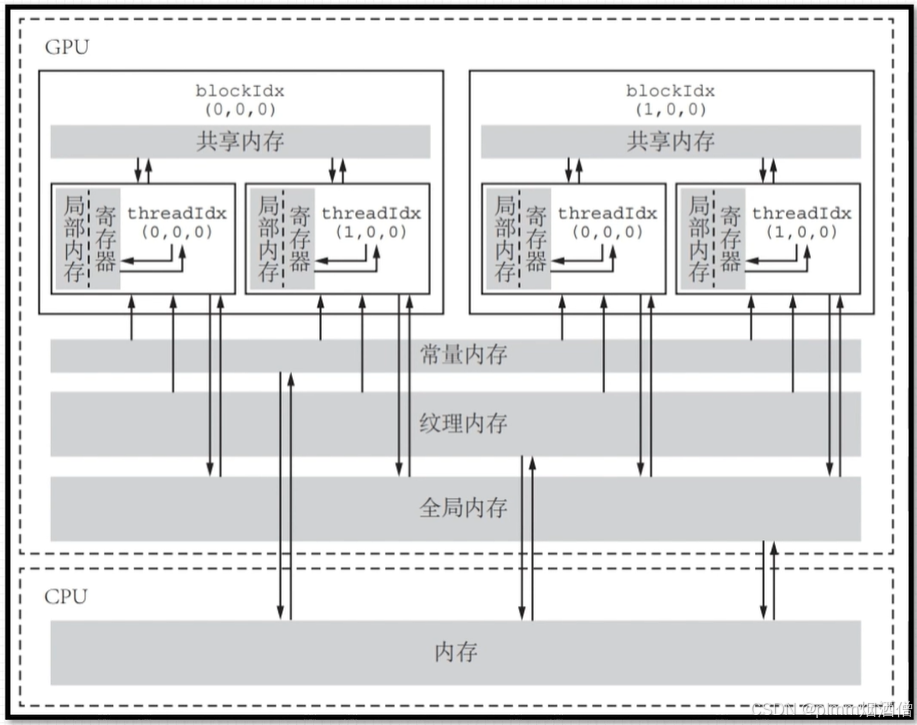
CUDA内存模型包括:
- 寄存器(Registers)
- 共享内存(Shared Memory)
- 局部内存(Local Memory)
- 常量内存(Constant Memory)
- 纹理内存(Texture memory)
- 全局内存 Global Memory
一个线程拥有自己私有的寄存器和局部内存;
一个 block 内的所有线程可以读写该 block 专有的共享内存;
所有线程可以读写全局内存;
纹理内存,线程一般只能读取,不能修改。
只读内存,线程只能读取,不能修改。
这里会涉及到一个有关 Block 独立性与共享内存隔离性的知识点,可查看:
CUDA 编程笔记:Block 独立性与共享内存隔离性-CSDN博客![]() https://blog.csdn.net/plmm__/article/details/149307692
https://blog.csdn.net/plmm__/article/details/149307692
二、寄存器
1、普通变量
核函数中定义的不加任何限定符的变量→ 默认存放在寄存器中
(示例:int i = 0;)
2、内建变量
gridDim, blockDim, blockIdx等 → 强制存放在寄存器中
(由CUDA运行时自动管理)
3、数组的特殊处理
小规模数组可能被优化存入寄存器(如int arr[4];)
大规模/动态索引数组可能降级存储到本地内存(Local Memory)
(受寄存器容量/编译器优化策略影响)
三、本地内存
1. 每个线程最多可使用高达 512KB 的本地内存;
2. 本地内存从硬件角度看只是全局内存的一部分,延迟也很高,本地内存的过多使用会降低程序的性能;
3. 对于计算能力2.0以上的设备,本地内存的数据存储在每个SM的一级缓存和设备的二级缓存中。
寄存器放不下的内存会存放在本地内存,主要包括以下三种情况:
1. 索引值不能在编译时确定的数组(如运行时动态计算的数组下标);
2. 可能占用大量寄存器空间的较大本地结构体和数组(如过大的临时缓冲区);
3. 任何不满足核函数寄存器限定条件的变量(如编译器因寄存器不足自动降级存储)。
本地内存虽然属于线程私有,但访问速度显著低于寄存器,优化时应尽量避免触发上述情况。
四、全局内存
全局内存在片外。
特点:容量最大,延迟最大,使用最多;
全局内存中的数据所有线程可见,Host 端可见,且具有与程序相同的生命周期。
1、动态全局内存
主机代码中使用 CUDA 运行时 API cudaMalloc动态分配内存空间,由 cudaFree释放
2、静态全局内存
使用 __device__关键字静态声明全局内存
五、共享内存
(1)共享内存位于GPU芯片片上(on-chip),相比本地内存和全局内存具有更高的带宽和更低的延迟。
(2)共享内存中的数据对所属线程块内的所有线程可见,可用于线程间通信,其生命周期与线程块一致。
(3)使用 shared 修饰的变量存放在共享内存中,支持动态和静态两种分配方式。
(4)每个SM(流多处理器)的共享内存容量是固定的,如果在单个线程块中分配过多的共享内存,将会限制活跃线程束(Warp)的数量。
(5)访问共享内存时必须使用同步机制,例如通过线程块内同步函数 __syncthreads() 来确保数据一致性。
共享内存变量修饰符:__shared__
静态共享内存声明示例:
__shared__ float tile[size][size]; // 需在编译时确定数组维度核心限制:静态共享内存的大小必须在编译时确定
静态共享内存作用域规则:
核函数内声明 → 仅对该核函数可见
文件全局范围声明 → 对所有核函数可见
这里的作用域需要注意:同一个线程块内的线程可以通过共享内存通信,但不同线程块之间不能直接共享。
两种作用域的区别,从编程语言层面和使用效果来看,可以总结为以下要点:
1. 代码简洁性角度
文件级__shared__声明本质上是一种"语法糖",它避免了在每个核函数中重复定义相同结构的共享内存。
例如多个核函数都需要使用float tile[32][32]时,只需在文件全局声明一次即可。
2. 运行时行为角度
无论声明位置如何,实际运行时表现与局部声明完全一致:
✓ 每个线程块都会获得独立的物理内存副本;
✓ 不同线程块之间仍然严格隔离;
✓ 生命周期仍然绑定到线程块。
当多个核函数需要使用完全相同的共享内存布局时,推荐使用文件级声明
当各核函数需要不同结构或特殊尺寸时,应采用核函数级声明
六、常量内存
1. 物理本质:带有专用缓存的全局内存(片上缓存优化)
2. 容量限制:固定64KB大小(所有计算能力版本通用)
3. 性能优势:
当线程束(Warp)内所有线程读取相同常量时,速度显著快于全局内存
缓存机制可减少对片外内存的访问
4. 定义规范:
使用 __constant__ 修饰符声明(必须位于核函数外部)
仅支持静态定义(不可动态分配)
具有只读属性(运行时不可修改)
cudaMemcpyToSymbol 和 cudaMemcpyToSymbolAsync 用于将主机数据复制到已定义的常量内存变量中。