FedViT:边缘视觉转换器的联邦持续学习
FedViT: Federated continual learning of vision transformer at edge
(北京理工大学-2023年发表于《Future Generation Computer Systems》中科院二区)
highlight:
•提出一种轻量级的客户端联合持续学习方法。
•通过将签名任务的知识整合到客户端上,防止灾难性遗忘。
•减少负面知识转移,无需频繁与服务器通信。
•理论上保证了我们方法更快的训练收敛。
•适用于多任务、多客户端、多ViT的场景。
一.Introduction
background:随着客户端环境的不断变化,需要DNN模型重新训练并适应这些变化。例如图中ViT,需要随着时间的推移处理一系列任务。通常,一个任务由多个类别/对象和每个类别的不同特征组成。
联邦持续学习(FCL)它从由不同任务组成的非平稳数据中增量学习深度模型。FCL在从其他客户端的(间接)经验中学习的直觉的驱动下,将持续学习结合在联邦学习框架中,使客户端中的模型可以不断地从其本地数据和其他客户端的任务知识中学习。
主要问题是灾难性遗忘:当其模型随着时间的推移学习新任务时,它可能会忘记以前学习的任务信息,并且这些任务中的模型准确性会降低。(例:一旦客户端1中的模型完成其初始任务(即任务(1))的训练,其参数收敛到任务损失区域的最优点,产生86%的准确率。然而,当随后适应第二个任务(即使用相同模型的任务(2))时,由于两个任务之间的相关性有限,参数逐渐偏离任务1的最优点,并逐渐接近任务2的最佳状态。因此,尽管在任务 2 上达到了 83% 的准确率,但模型对任务 1 的分类准确率却大幅下降至 54%,这体现了对前一个任务的灾难性遗忘现象。)
当客户端的模型与联邦学习中来自其他客户端的模型聚合时,这种差异带来了重大挑战。其他客户端模型中的不同知识可能会降低模型在其专用本地数据上的性能。这种从全局模型中转移不相关知识的有害转移被称为负向知识转移
ViT对数据分布漂移表现出很强的鲁棒性,这是持续学习和联邦学习面临的关键问题。此外,ViT高度依赖训练数据,例如数据量和数据多样性。在FCL中,随着任务数量的增加,它自然会向ViT提供这些数据资源。
ViT在边缘持续联邦学习中的挑战:
边缘计算是为了降低与云服务器的通信成本,并通过设备上的数据处理增强数据隐私;模型训练中的计算和通信成本随着任务和客户端的数量而增加,并且在资源受限的边缘设备上进行这种昂贵的训练会带来两个技术挑战。
1.有限的计算资源导致显著的精度损失。因此,第一个挑战是设计一种轻量级的学习方法,可以直接在资源受限的边缘设备上保留大量的历史知识并缩短模型训练时间。
2.防止负面知识转移会导致高通信成本和隐私泄露。第二个挑战是如何开发一种分布式方法,可以防止负面的知识转移,而不增加客户之间的额外通信。
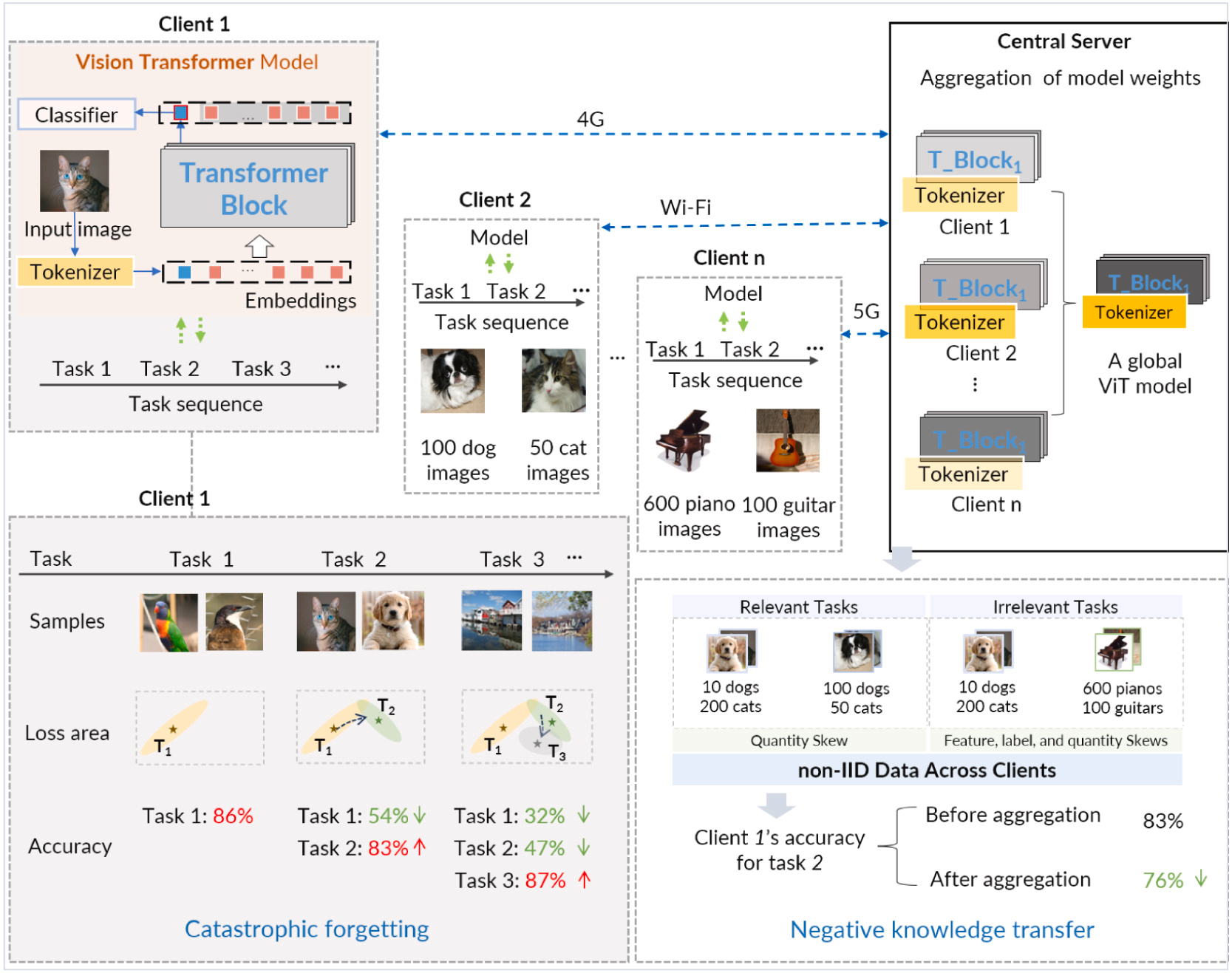
图. 联邦持续学习的示例场景 n 客户
二、方法
总结:FedViT是一种轻量级的客户端解决方案,它集成了包含相关过去和对等任务的签名任务的知识。FedViT 在每个客户端中发挥作用,并提取紧凑且可转移的知识——重要的数据样本。在学习一项新任务时,FedViT 将其与其签名任务的知识相结合,这些任务是从本地过去的任务中识别出新任务中最不同的任务,以防止灾难性遗忘,以及代表其他客户端当前任务的更新全局模型,以防止负面知识转移。通过完成具有多项式时间复杂度的知识集成,FedViT 通过提供高模型精度和边缘低通信开销来解决现有技术的局限性。
1.通过对签名任务的了解提供可扩展的客户端解决方案。
2.通过梯度积分进行高精度模型训练。

主要分为三个部分:知识提取器、梯度恢复器、梯度积分器
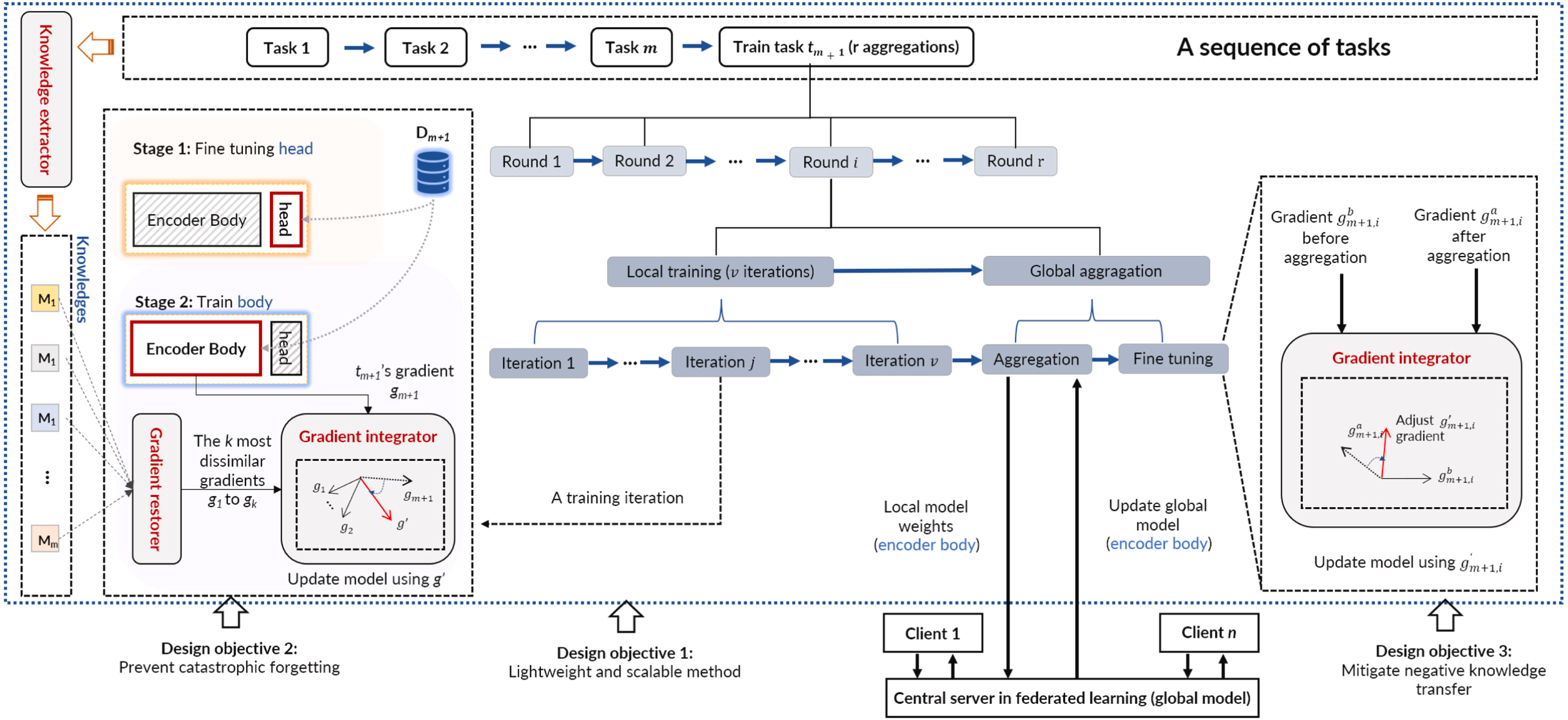
图 FedViT的流程和设计目的

三、实验:
测试平台:Jetson TX2 8 GB; Jetson Nano 4 GB; Jetson Xavier NX 16 GB; Jetson AGX 32 GB
数据集:CIFAR100、FC100、COR50、MiniImageNet、TiniImageNet;分为多个任务,每个任务有多个类别;并随机分配为Non-IID,数据间差异较大
对比基线模型:
- 持续学习方法:gradient episodic memory (GEM)、Balanced Continual Learning (BCN)、Balanced Continual Learning (BCN)、Memory aware synapses(MAS)、Dytox、LVT
- 联邦学习方法:FedAvg、APFL、FedRep
- 联邦持续学习方法:FedWEIT、FedKNOW
评价指标:平均准确率 (Average Accuracy)、遗忘率 (Forgetting Rate)、通信成本 (Communication Cost)、计算成本 (Computation Cost)、存储开销 (Memory Storage)
对比试验:
不同FCL下精度评估:在不同数据集上,测试了不同类型模型的准确度(灾难性遗忘和负面知识转移);此外还评估了异构边缘设备上FedViT的准确率
通信成本评估:
将FedViT和FedWEIT进行对比,在不同数据集上,FedViT在执行相同模型训练任务时需要更少的通信成本;
在不同网络带宽下,FedViT的通信时间始终更少。
客户端和任务数量讨论:
任务数:将TinyImageNet(200类)构建为多任务数据集,50个任务,每个任务4类;为了保证每个任务的数据异构性,将数据集划分为 10 个客户端,每个客户端最多包含 2 类数据样本。 测试不同任务下,对比模型的精度。
客户端数:50个和100个客户端比较准确率和遗忘率。
综上所述,FedViT 利用少量高质量样本作为旧任务知识,使其即使在训练样本极其有限的场景下也能准确恢复旧任务知识。此外,基于梯度积分的知识恢复器有效解决了客户端或任务数量不断增加导致的严重负向知识转移问题,使其成为实际联邦学习应用的潜在候选者。
不同ViT模型的适用性:
测试了5种共8个ViT模型,随任务数增加精度的变化,结果表明在8种模型下,FedViT框架都取得了最好的精度。还对比了不同客户端采样率下的比较;不同知识存储速率下的比较;以及图像分辨率的影响
超参数的影响:
知识存储率的影响 ;所选渐变数量的影响
结论:
FedViT是一个专为分布式边缘设备上基于Transformer的计算机视觉模型而设计的框架。FedViT 在三个方面进行创新,以应对边缘联合持续学习的关键挑战。首先,基于样本的轻量级知识提取减少了设备开销,同时保留了关键的过去任务信息,提高了约束下的持续学习精度。其次,梯度积分消除了负迁移,有利于新旧知识的同化,提高了模型泛化性。最后,签名任务知识的本地化集成可以随着任务和客户的增长实现可扩展性,而无需额外的通信成本。大量实验表明,FedViT 在确保准确性的同时显着降低了通信开销,并表现出很强的可扩展性。