目录
数据结构专栏
https://blog.csdn.net/xyl6716/category_13002640.html
精益求精 追求卓越
【代码仓库】:Code Is Here
【合作】 :apollomonasa@gmail.com

引入
前面我们已经学习了单链表及其基本应用,了解到单链表可以单向遍历,一般无头,也可以有头,这里的头就是虚拟头节点(Dummy Head),比特就业课的老师喜欢管这个叫做哨兵位,其他地方没听过,不过不重要,这个头通常用来占位置,方便遍历的时候避免特判讨论。此外还要引入循环的概念,就是链表最后一个节点指向第一个有效节点,以此实现循环的效果,结构上体现为环形链表。
由此,链表就根据带头、单双向、循环可以分为8种,而今天主要介绍双向链表,它是通过存储前驱和后继指针来实现双向访问的。
实际上这里介绍的是带头双向循环链表。
结构定义
和单链表相比,只是增加了一个指针字段,可以概括为,数据区+前驱指针+后继指针,只增加了一个指针,即可实现双向访问。


然后,将每个节点如图连接后,就形成了双向循环链表。
结构操作
接下来将介绍一些常用的操作的实现和代码。
初始化
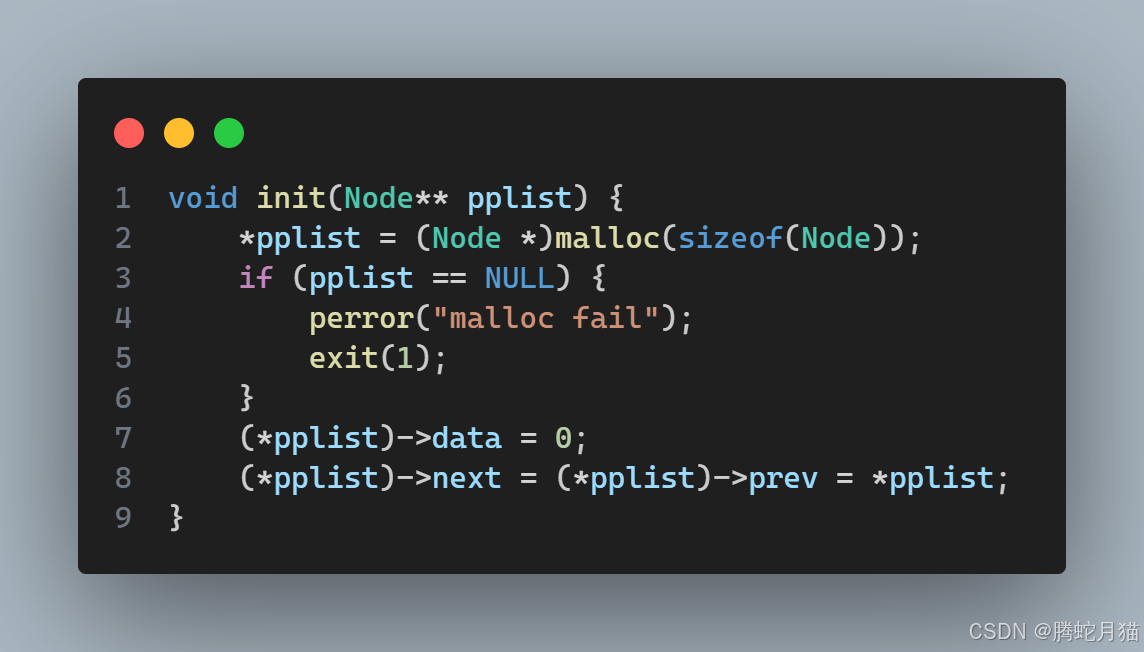
首先是参数列表的设计,由于我们需要知道链表的头,并且还涉及到修改链表的头指针,所以应该传入头指针的地址,也就是二级指针。
其次是前驱后继的指向,由于我们的结构定义指出链表的头的前驱是尾,尾的后继是头,所以对于一开始只有虚拟头节点的空表来说,前驱后继都是自己。
插入
为了方便,编写一个辅助函数,用于创建新节点。
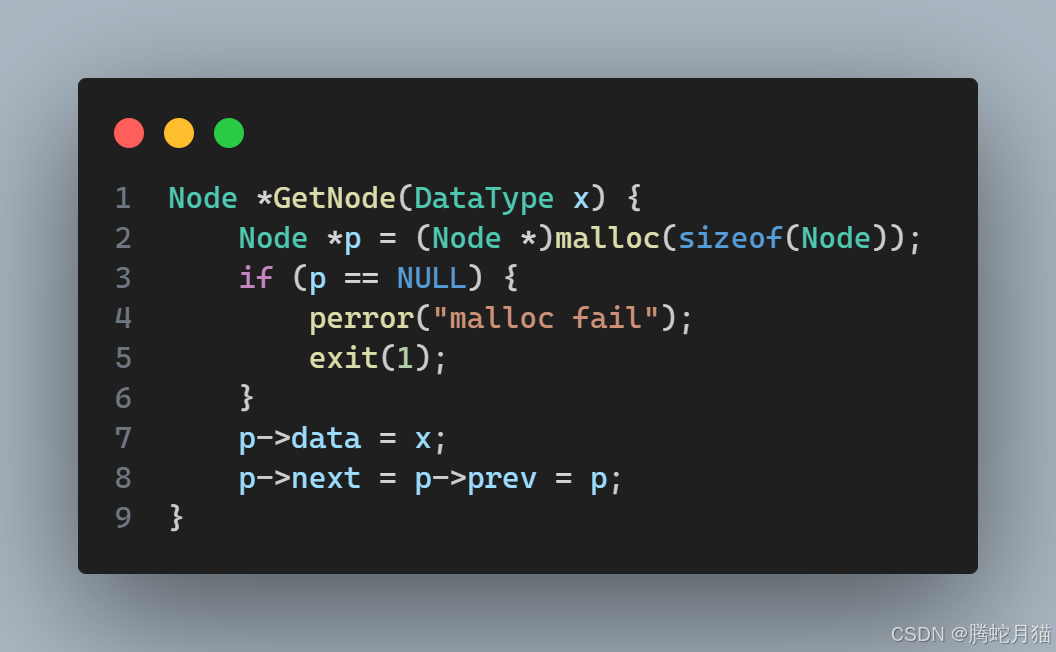
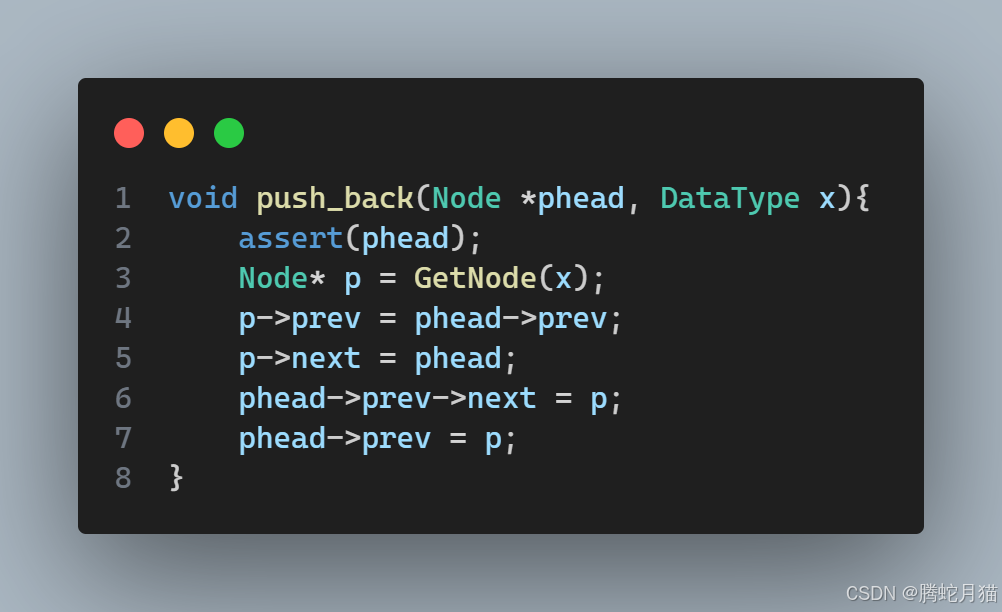
接下来就是尾插操作,创建新节点之后,需要修改的只有头的前驱,尾的后继,以及新节点的前驱后继,优先修改新节点以保留原链表信息,然后再修改尾的后继,最后修改头的前驱。这个顺序是最方便操作的,如果调换,就会发现不太容易找到尾。
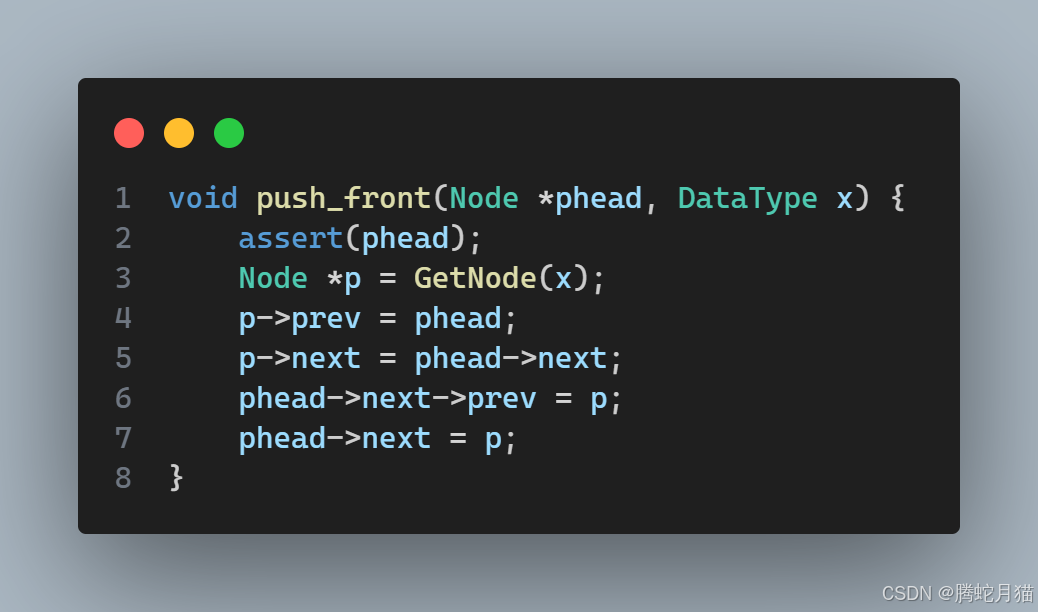
剩下的头插也是大同小异,不多赘述,且看代码:
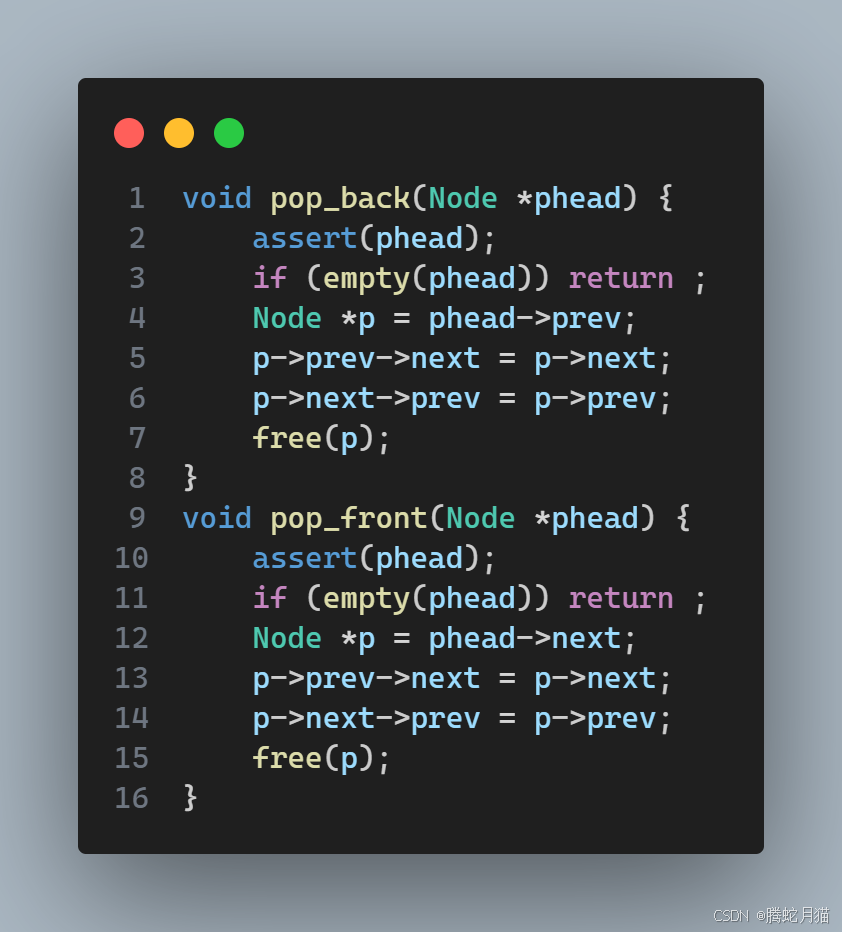
删除
这里有pop_back 和 pop_front,二者大同小异,代码及其相似。
基本思路是先记录要删除的节点,然后站在这个节点调整被它影响到的它前驱和后继的指针,最后释放掉待删除节点的内存。
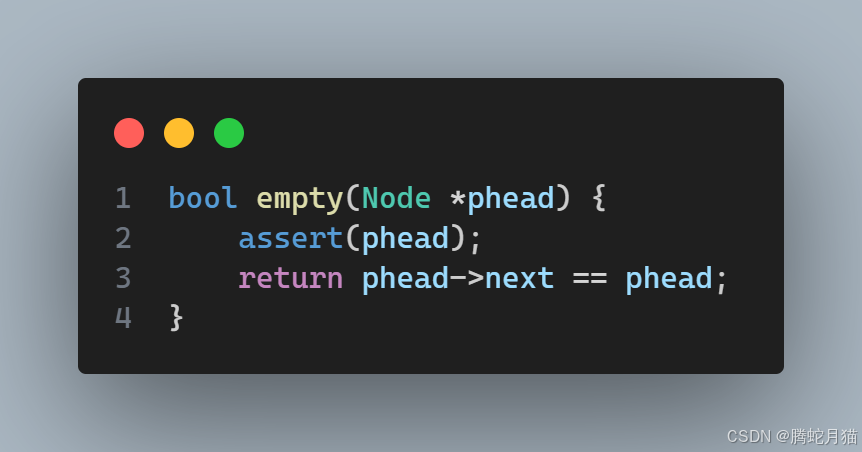
此处补充一个辅助函数empty
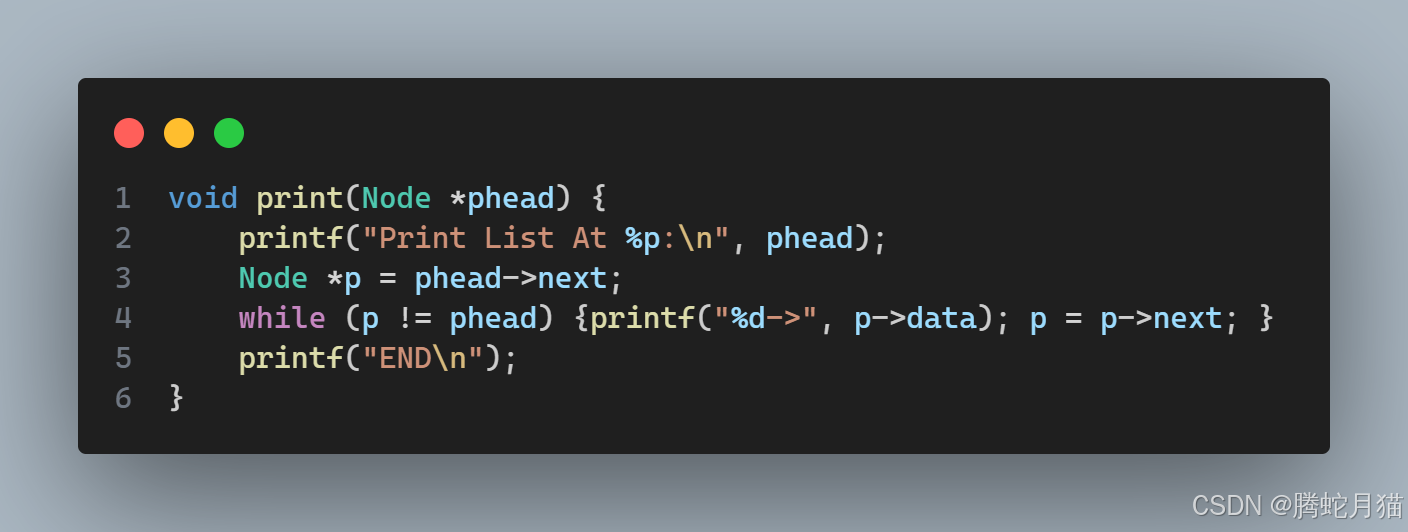
打印
打印就是遍历,和单向链表并无不同,只不过判断终止条件从空指针变成了Dummy Head。
打印效果示例
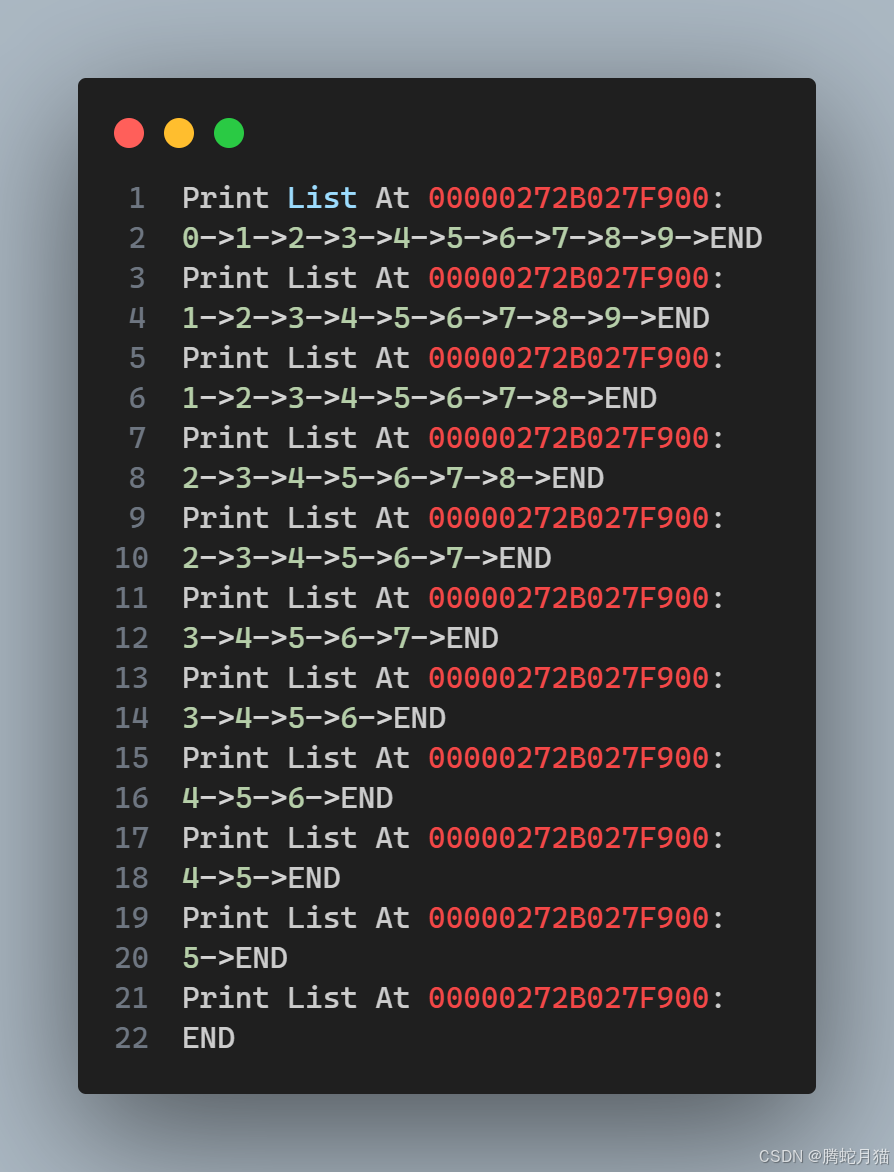
经过测试,头删和尾删功能都正常。
查找
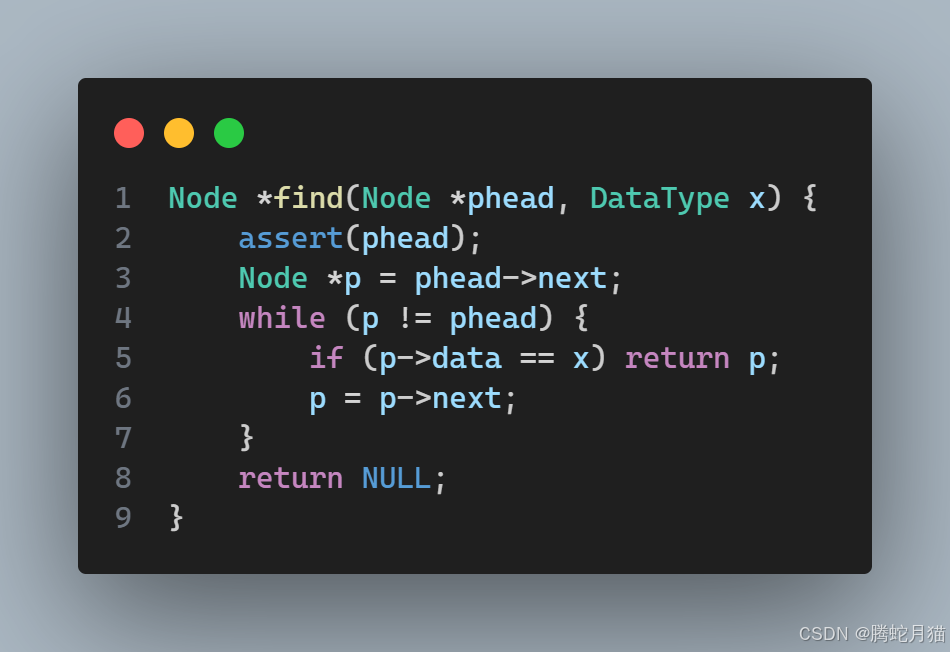
查找功能本质上还是遍历,只是加上一个条件判断。
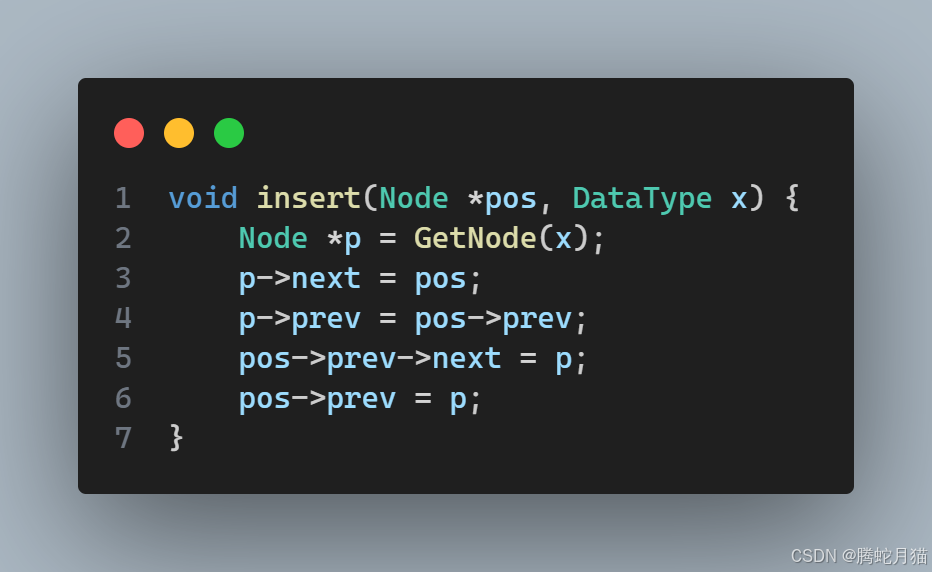
随机位置插入
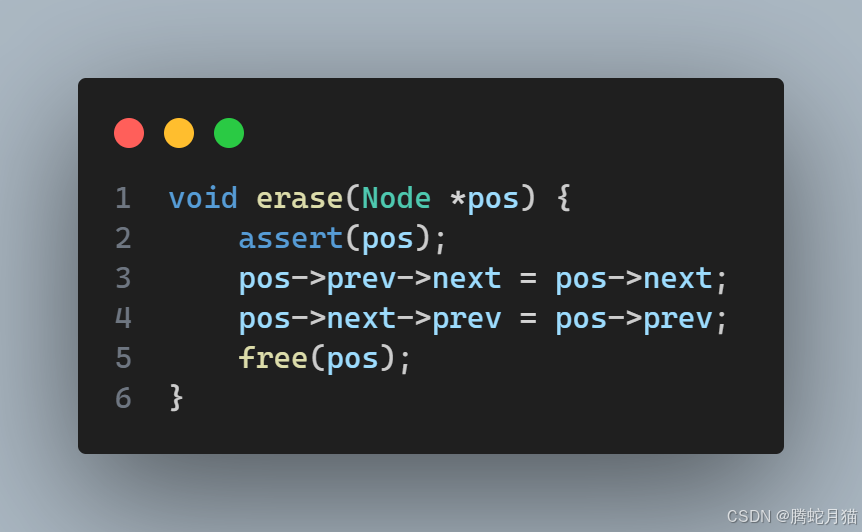
随机位置删除
销毁

总结
比起单链表,双向链表的结构定义虽然更多了,但是结构操作普遍在代码长度和时间复杂度上都更简单,就比如尾插和头插都是O(1)的。换句话说,占用内存更多,运行时间更短,这就是所谓空间换时间。这种时空互换的观念在今后的数据结构学习中还会有更多体现,但在今天初现端倪。
此外,初始化并不一定要像我那样实现,可以设计成返回初始化后的Dummy Head,这样使得函数调用更加一致,避免了传入二级指针。
至此,线性表中的顺序表和链表就讲完了,下一篇文章正式开启栈和队列的学习,并且此后的文章在风格上不会有太大改变,但是在设计上会更加完整,篇幅会大大增加,一种数据结构不会再分为好几篇文章讲解,方便读者查阅。