简介
照相机成像是一个将三维世界映射到二维图像的过程,如果我们想从图像中恢复出三维世界的信息,我们需要解决一个重要的问题:恢复照相机成像过程中丢失的深度信息。给定单幅图像,我们无法确定每个像素对应三维空间中点的坐标。因为从照相机光心到成像平面的连线上的所有三维空间中的点都可以投影到同一像素上。只有知道一个像素对应的深度,我们才能精确地确定它在三维空间中对应点的空间位置。在本章中,我们将介绍平行双目照相机的构造和成像原理,以及如何利用平行双目照相机获取场景的深度信息。
平行双目照相机
平行双目照相机是目前最常见的深度照相机,它由两台水平放置的独立照相机组成,每台照相机都有自己的光心和成像平面。接下来,我们将介绍平行双目照相机的构成及其工作原理,为了简化描述,除非特别说明,本章中所提及的双目照相机都是平行双目照相机。 概念定义,将两台照相机并排排列,且使其光轴互相平行,可以形成一个类似人类双眼视觉的系统,因此这种配置被称为平行双目视觉系统,这两台照相机就被称为平行双目照相机,其所拍摄的两张照片就构成了一组双目图像。主流的平行双目照相机都是水平平行排布的,左右两台照相机分别对应于人类的左眼和右眼如图18-1所示。
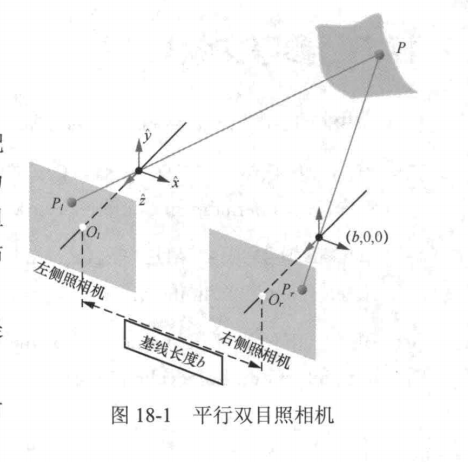
当然纵向的双目照相机从原理上也是可以实现的(读者可以想象那种奇怪的形状)。
在这种左右双目照相机系统中,两台照相机可以被视为具有相同特性的针孔照相机模型。它们被水平放置,这意味着两台照相机的光心均位于x轴上,且它们的光轴平行。照相机光心之间的水平距离称为双目照相机的基线(baseline,长度用b表示),这是衡量双目照相机几何配置的关键参数。
基线的长度对于计算图像间的视差及最终确定场景中物体的深度信息至关重要。
视差
平行双目视觉视差的基本概念
平行双目视觉系统由两个完全相同的相机组成,光轴平行且基线(两相机中心距离)固定。视差指同一空间点在左右相机成像平面上的像素坐标差异,通常以水平方向为主。视差与物体距离成反比,是立体匹配和深度计算的核心依据。
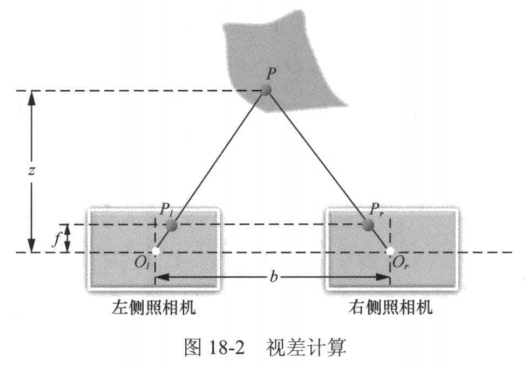
在照相机参数固定的情况下,基线越长,双目视觉系统能够测量的深度范围越大,深度测量的分度值越大;相反,基线越短,能够测量的深度范围越小,深度测量的分度值越小,但测量的精密程度提高。将各像素计算出来的视差绘制在像素坐标处,便得到了对应的视差图(disparity map)。将各像素的视差通过前述公式转换成深度,便可得到深度图(depth map),深度图可以直观地反映出场景中物体的深度信息。
双目特征匹配
尽管使用视差计算深度的公式本身很直接,但实际上获得视差的过程却相对复杂。这一过程要求我们能够精确地确定左图像中某像素在右图像中的对应像素,这一过程就是双目特征匹配。第4章和第7章介绍了模板匹配和特征点匹配,这些技术都可以用于计算视差。不过在双目照相机系统中,情况更为特殊:由于两台照相机是水平对齐的,空间中任一点在这两个照相机成像平面上的投影将具有相同的垂直坐标。因此,在特征匹配过程中,我们只需沿水平方向进行搜索以找到对应的匹配点。一个最直接的方法是选中左图像中的任意像素,然后在右图像中该像素所在的行上搜索其对应的像素。但是单个像素的匹配有极大的不确定性,例如,一个颜色单一的物体在一行上可能存在好几个完全一样的像素。为了减少这种不确定性,我们可以考虑不直接匹配像素,而是匹配像素块,也就是块匹配。在待匹配像素周围选取一个尺寸为w×w的小块,然后以对应行上的每个像素为中心选取很多同样尺寸的小块进行比较,就可以在一定程度上提高区分性。在图18-3(a)的原图像

中选中模板窗口T,在图18-3(b)的待匹配图像I,对应高度的像素区域寻找其对应的窗口T成为我们关心的问题。这正是在第4章中讨论过的模板匹配问题。
除了基础的匹配算法,还可以对每个像素块进行预处理,如去除每个小块的均值,实现去均值的SSD、去均值的NCC等。去均值的优势在于,它能够消除图像块之间的亮度差异,从而提高匹配的准确性。具体来说,去均值处理可以使图像块的灰度值更加接近,即使图像块整体上存在亮度差异,也能保证匹配的准确性。每种方法都有其特点和局限性:SAD速度最快,但对局部亮度变化非常敏感;SSD速度中等,对亮度偏移较为敏感:而NCC虽然速度最慢,但其优势在于不受对比度和亮度变化的影响。因此,在实际应用中,选择哪种匹配算法应根据具体需求和场景的特点决定。在块匹配算法中,选取的块的尺寸直接影响匹配的效率和结果的质量。如图18-4所示

不同的块尺寸会产生不同质量的视差图。总的来说,较小的块尺寸能够捕获更多的细节信息,但这同时也可能会导致较多的匹配误差和噪声。相反,较大的块尺寸可以产生更平滑的视差图,但这种方法可能会忽略掉一些重要的细节信息。为了平衡块尺寸对匹配效果的影响,一种有效的策略是采用多尺度窗口匹配方法。对于每个像素,我们不只使用单一尺寸的窗口进行匹配,而是尝试多个不同尺寸的窗口。然后,基于最佳相似性度量选择相应的视差作为最终结果。
全局优化
在之前讨论的方法中,每个像素的深度是独立计算的,这可能导致相邻像素之间存在显著的深度差异。然而,在现实世界中,相邻像素的深度通常相似,深度的突变较少。基于这一先验知识,可以引入空间正则化项来改进深度估计,从而使预测的深度图更加平滑。因此,双目特征匹配问题可以转化为一个全局优化问题。我们先定义什么是优秀的双目特征匹配结果。优秀的双目特征匹配结果应具有以下特性。
(1)高匹配质量:确保每个像素在对应图像中都有一个高质量的匹配点。
(2)深度平滑性:要求相邻像素之间的视差变化保持一致。
代码实现
在上面的章节中,我们介绍了双目照相机的构造以及其计算深度的原理,接下来我们进入动手学环节,学习如何从一组双目图像中获得视差图。
# 首先clone对应仓库 ! git clone https://github.com/boyu-ai/Hands-on-CV.git
Cloning into 'learncv_img'... remote: Enumerating objects: 89, done. remote: Counting objects: 100% (8/8), done. remote: Compressing objects: 100% (8/8), done. remote: Total 89 (delta 0), reused 0 (delta 0), pack-reused 81 Receiving objects: 100% (89/89), 14.23 MiB | 1023.00 KiB/s, done. Resolving deltas: 100% (10/10), done.
首先我们读取左右两张图像,并做一个简单的可视化。
import os
import time
import cv2 as cv
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
# 获取左照相机图像
limg_raw = np.asanyarray(Image.open(
r"./learncv_img/stereo/scene1.row3.col1.ppm"))
# 获取右照相机图像
rimg_raw = np.asanyarray(Image.open(
r"./learncv_img/stereo/scene1.row3.col3.ppm"))
# 将图像转化为灰度图
limg = cv.cvtColor(limg_raw, cv.COLOR_BGR2GRAY)
rimg = cv.cvtColor(rimg_raw, cv.COLOR_BGR2GRAY)
# 将图像转化为double类型
limg = np.asanyarray(limg, dtype=np.double)
rimg = np.asanyarray(rimg, dtype=np.double)
# 定义一个和输入图像大小相同的数组
img_size = np.shape(limg)[0:2]
# 简单可视化左右图像
plt.figure(dpi=100)
plt.title("binocular images")
plt.imshow(np.hstack([limg_raw, rimg_raw]))
plt.axis('off')
plt.show()

接下来,我们实现生成视差图的函数。此函数首先计算左右图像的整体差距,然后对每个像素进行视差搜索,并选择最小匹配代价所对应的视差作为最终视差值。
def get_disp_map(max_D, win_size, img_size, match_mode="SAD"):
"""
根据左右图像,获取视差图。
参数:
- max_D: 左右图像之间最大可能的视差值。
- win_size: 块尺寸。
- img_size: 双目图像尺寸。
- match_mode: 匹配模式,可选"SAD"或"SSD"。
"""
# 记录初始时间
t1 = time.time()
# 初始化视差图
imgDiff = np.zeros((img_size[0], img_size[1], max_D))
def SAD(x, y, error_map, win_size):
return np.sum(error_map[(x - win_size):(x + win_size),
(y - win_size):(y + win_size)])
def SSD(x, y, error_map, win_size):
return np.sum(np.square(error_map[
(x - win_size):(x + win_size), (y - win_size):(y + win_size)]))
# 遍历所有可能的视差值
for i in range(0, max_D):
# 记录视差为i时,左右图像的整体差距
e = np.abs(rimg[:, 0:(img_size[1]-i)] - limg[:, i:img_size[1]])
e2 = np.zeros(img_size)
# 遍历所有像素
for x in range(0, img_size[0]):
for y in range(0, img_size[1]):
# 根据匹配模式计算匹配代价
if match_mode == "SAD":
# 计算SAD值
e2[x, y] = SAD(x, y, e, win_size)
elif match_mode == "SSD":
# 计算SSD值
e2[x, y] = SSD(x, y, e, win_size)
else:
raise NotImplemented
# 将匹配代价存储到imgDiff中
imgDiff[:, :, i] = e2
# 初始化视差图
dispMap = np.zeros(img_size)
for x in range(0, img_size[0]):
for y in range(0, img_size[1]):
# 对匹配代价进行排序
val = np.sort(imgDiff[x, y, :])
# 简单判断是否出了边界
if np.abs(val[0]-val[1]) > 10:
# 找到最小匹配代价的视差索引
val_id = np.argsort(imgDiff[x, y, :])
# 将视差值映射到 0-255 之间
dispMap[x, y] = val_id[0] / max_D * 255
# 打印运行时间
print("所用时间:", time.time() - t1)
# 显示视差图
plt.figure("视差图")
plt.imshow(dispMap)
plt.show()
# 返回视差图
return dispMap
# 最大视差
max_D = 25
# 滑动窗口大小
win_size = 5
# 可视化SAD匹配效果,块尺寸为5像素
_ = get_disp_map(max_D, win_size, img_size)
所用时间: 11.269958972930908
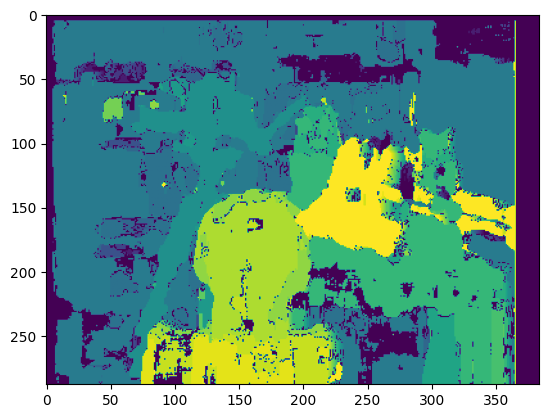
通过生成双目图像的视差图,我们可以观察到一些直观的现象,比如台灯在视差图中的亮度较高,这表明其视差值相对较大;而背景部分的亮度较低,表示视差值较小。视差图中的亮度变化直接反映了物体与相机之间的相对深度差异:亮度较高的区域(视差大)意味着物体相对较近,亮度较低的区域(视差小)则表明物体相对较远。因此,利用视差图,我们可以有效地估计场景中各个物体的深度信息。
接下来我们看看调大块匹配的尺寸的效果:
# 测试更大的块尺寸 win_size = 30 # SAD匹配效果,块尺寸为30像素 _ = get_disp_map(max_D, win_size, img_size)
所用时间: 14.947252035140991
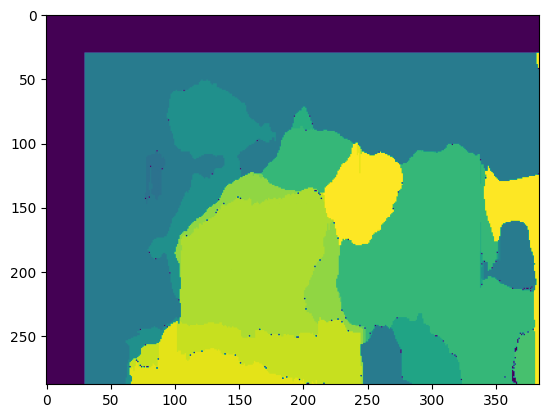
不难发现,块尺寸越大,预测出的视差图更加平滑,细节丢失更加严重,同时计算的时间也增加了。
接下来我们来看看SSD的效果。
win_size = 5 # SSD匹配效果,块尺寸为5像素 _ = get_disp_map(max_D, win_size, img_size, match_mode="SSD")
所用时间: 13.194314956665039
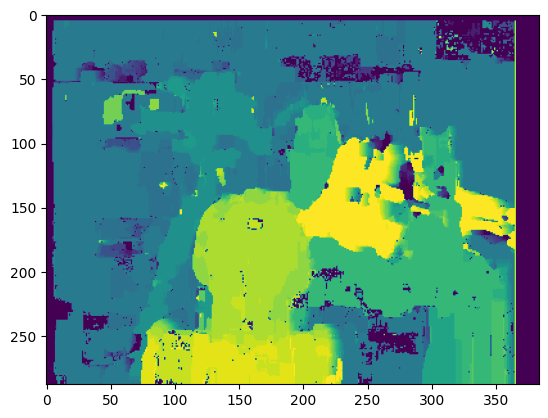
win_size = 30 # SSD匹配效果,块尺寸为30像素 _ = get_disp_map(max_D, win_size, img_size, match_mode="SSD")
所用时间: 18.293694019317627
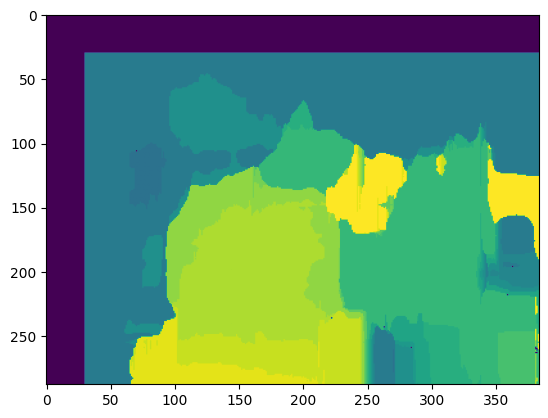
对比SAD和SSD的效果,我们可以发现,SSD保留了更多细节,但是同时它也花费了更多的时间。
小结
平行双目照相机通过模拟人类双眼视觉系统实现深度感知。该系统由两台水平放置、光轴平行的相机组成,基线距离是关键参数。深度计算的核心原理是视差(同一空间点在左右图像中的水平像素差),视差与物体距离成反比。计算过程包括特征匹配(常用SAD/SSD算法)和全局优化,其中块匹配尺寸会影响结果精度与计算效率:小尺寸保留细节但噪声多,大尺寸更平滑但丢失细节。实验表明,SSD算法比SAD保留更多细节但耗时更长。最终生成的视差图可转换为深度图,亮度反映物体远近,为三维场景重建提供基础。