这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
具身智能
具身智能是指能够感知、推理和行动并与物理世界交互的智能体
不同于传统AI, 不仅仅是符号推理或数据模式识别,更强调物理存在和交互
视觉与语言导航(VLN)
视觉与语言导航是具身智能的一个子领域,目标是训练智能体根据自然语言指令,融合视觉和语言信息来进行决策,在3D环境中导航。输入包括视觉感知和自然语言指令(如“右转”,“向前走”),输出则是路径点、离散动作(如前进xx米,右转xx度,停止)等,使智能体能够到达目标位置。
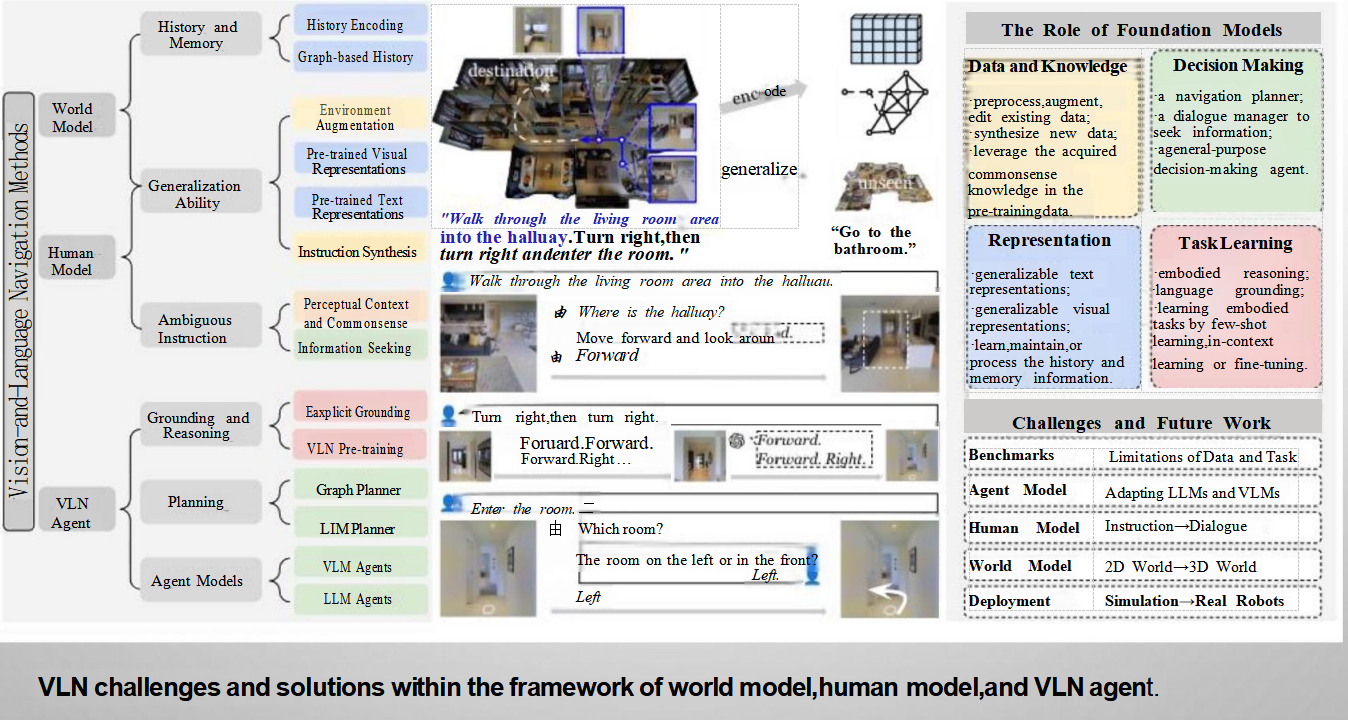
基础模型、人类模型、世界模型和代理模型指的是不同的组成部分或方法框架,它们各自承担着特定的功能,共同作用以实现智能体能够根据自然语言指令在物理环境中进行有效导航。
基础模型(Foundation Models)
基础模型是指那些预先训练好的大型模型,这些模型可以在广泛的任务中提供强大的文本和图像处理能力。在VLN的背景下,基础模型的作用包括但不限于:
- 数据和知识:用于预处理和增强现有数据,以及利用预训练数据中的常识知识。
- 决策制定:作为导航规划器、对话管理器和通用决策代理,帮助智能体做出合适的行动决策。
- 表示:生成可泛化的文本和视觉表示,学习、维护或处理历史和记忆信息。
- 任务学习:通过少量样本学习、上下文学习或微调来学习具体的具身任务。
人类模型(Human Model)
人类模型旨在模拟人类的认知过程,特别是在理解自然语言指令方面的能力。它主要负责:
- 定位和推理:理解语言指令与物理环境的关系,比如识别“前进”、“左转”等动作。
- 规划:使用图形规划器和LIM规划器来制定导航计划,决定下一步该做什么。
- 代理模型:包括VLM代理和LLM代理,用于执行具体的导航任务。
世界模型(World Model)
世界模型是关于智能体如何感知和理解其所处的环境的模型。它主要包括:
- 历史和记忆:帮助智能体记住过去的动作和环境状态,以便更好地理解当前的情况。
- 泛化能力:使智能体能够在不同环境中灵活应用所学知识。
- 模糊指令处理:理解不明确的指令,比如“那个房间”,需要结合上下文和常识进行判断。
代理模型(Agent Model)
代理模型指的是直接执行导航任务的智能体本身,它综合了来自基础模型、人类模型和世界模型的信息,以完成具体的导航任务。其主要职责包括:
- 根据接收到的语言指令和环境信息,决定下一步的行动。
- 实时更新对环境的理解,并调整行动计划。
- 在必要时与用户进行交互,澄清指令或请求进一步的指导。
总的来说,这些模型共同作用,使得智能体不仅能够听懂人的语言指令,还能理解周围的物理环境,进而执行复杂的导航任务。
VLN的关键挑战
挑战和未来工作(Challenges and Future Work)
- 基准测试(Benchmarks):数据和任务的限制。
- 代理模型(Agent Model):适应LLMs和VLMs。
- 人类模型(Human Model):指令-对话。
- 世界模型(World Model):从2D世界到3D世界。
· 感知模糊性:视觉信息可能不完整或模糊。
· 语言模糊性:自然语言指令可能不精确、有歧义或包含隐含信息。
· 泛化能力:在未见过的环境中导航的能力。
· 长程规划:规划跨越多个房间或复杂路径的行动序列。
· 指令遵循:准确理解和执行指令的每个部分。
· 记忆与推理:记住已探索的区域和指令进度。
VLN 中智能体如何“看”世界——计算机视觉
图像识别
- 我在哪种环境?
- 智能体需要对整个视场(VIEW)进行宏观归类,例如判断当前所处的环境是“厨房”还是“卧室”。这种全局语境的理解有助于智能体判断是否已经到达了指令中的目标区域,比如“去厨房”。
目标检测
- 我周围有什么物体?
- 目标检测是指识别并定位视场中的物体实例,如“桌子”、“椅子”、“微波炉”等。这是执行大部分指令的基础。例如,当收到指令“去微波炉那里”时,智能体首先需要检测到“微波炉”的位置,并确定其在环境中的具体位置。
语义分割
- 这个场景的像素级布局是怎样的?
- 语义分割是对视场中的每一个像素进行语义分类,即判断每个像素属于哪个类别,如“地板”、“墙壁”等。通过识别出所有属于特定类别的像素,智能体可以确定可通行区域,从而实现有效的路径规划和避障。
因此,在VLN中的“视觉”,是一个集成了分类、检测与分割能力,能够处 理时序性、第一人称视角输入,并最终服务于语言接地的复杂感知系统。这 个系统是VLN 智能体的“眼睛”,它提供的场景理解质量,直接决定了后续 语言理解和动作规划模块的性能上限。
VLN中智能体如何“理解”指令?——自然语言处理
词嵌入——用向量表达语义,用
是一种将离散的词语符号映射为连续、低维稠密向量的技术,这些向量能够表达词语的语义信息,并且向量间的数学关系可以对应词语之间的逻辑关系。
1. 词嵌入的流程
a. 数据准备
- 文本数据收集:首先需要收集大量的文本数据,这些数据可以是新闻文章、书籍、网页内容等。
- 文本预处理:对文本进行清洗和标准化处理,包括去除标点符号、转换为小写、分词等。
b. 构建词汇表
- 统计词频:统计每个词在文本中出现的频率。
- 选择高频词:根据词频选择一定数量的高频词作为词汇表中的词。
c. 向量化——让意思相近的词,在向量空间里“靠得近”。
- 初始化词向量:为词汇表中的每个词分配一个随机的初始向量。
- 训练模型:通过神经网络模型(如Word2Vec、GloVe等)训练词向量。模型的目标是最小化预测错误,使得具有相似语义的词在向量空间中靠近。
d. 应用与优化
- 应用词向量:将训练好的词向量应用于自然语言处理任务,如文本分类、情感分析等。
- 持续优化:根据任务需求和效果反馈,不断调整和优化词向量。
2. 如何向量化
词向量的生成通常基于以下两种方法之一:
a. Word2Vec
- CBOW模型:给定上下文词,预测目标词。
- ✅ 优点:训练快,适合高频词。
❌ 缺点:对罕见词效果一般。 - Skip-Gram模型:给定目标词,预测上下文词。
- ✅ 优点:对低频词效果更好,学到的语义更细腻。
❌ 缺点:训练更慢,计算量大。
b. GloVe
- 共现矩阵:构建词与词之间的共现矩阵,表示词与词之间的关联程度。
- 最小化损失函数:通过最小化损失函数来优化词向量,使得词向量能够反映词与词之间的语义关系。
3. 如何降维
由于原始的词向量维度较高,为了便于可视化和计算效率,通常需要对词向量进行降维处理。常用的降维方法有:
a. 主成分分析(PCA)
- 计算协方差矩阵:计算词向量的协方差矩阵。
- 求解特征值和特征向量:求解协方差矩阵的特征值和特征向量。
- 选择主成分:选择前k个最大的特征值对应的特征向量作为新的基向量,将词向量投影到这k个基向量上,得到降维后的词向量。
b. t-SNE
- 计算高维空间中的相似度:计算词向量在高维空间中的相似度矩阵。
- 计算低维空间中的相似度:计算词向量在低维空间中的相似度矩阵。
- 最小化KL散度:通过最小化高维空间和低维空间相似度矩阵之间的KL散度,优化低维空间中的词向量位置。
通过上述流程和方法,我们可以将离散的词语符号转化为连续、低维的词向量,并通过降维技术将其可视化,从而更好地理解和应用词嵌入技术。
t-SNE 与 KL散度:
KL散度
“两个概率分布有多不一样”的度量。
你可以把它想象成:“你猜的分布”和“真实分布”差了多少?
注意:KL散度不是距离!它不满足对称性(KL(P||Q) ≠ KL(Q||P))
📌 在 t-SNE 中怎么用?
t-SNE 是一种把高维数据(比如词向量)画成 2D/3D 图的方法。
它的核心思想是:
- 在高维空间中,计算每两个词之间的“相似度” → 得到一个概率分布 P。
- 在低维图中,也计算每两个点之间的“相似度” → 得到另一个分布 Q。
- 用 KL散度 来衡量 P 和 Q 差多少。
- 不停调整低维点的位置,让 KL散度最小,也就是让图中的点分布尽量还原高维的相似关系。
KL散度 与 交叉熵
一、KL散度 vs 交叉熵:数学关系
我们先看公式,它们其实是“一家人”:
设:
- P:真实分布(高维空间中点之间的相似性)
- Q:模型预测分布(低维空间中点之间的相似性)
那么:
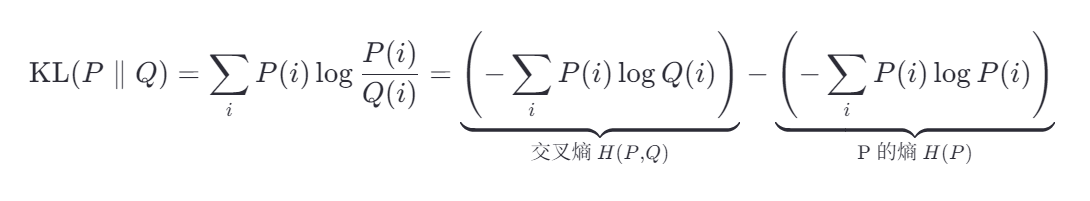
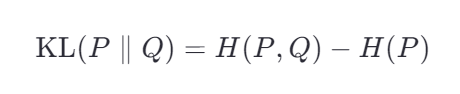
所以:KL散度 = 交叉熵 - 真实分布的熵
而 H(P) 是固定的(因为真实分布 P 不变),所以 最小化 KL散度 等价于 最小化交叉熵。
KL散度工作原理
我们希望P和Q同大同小(高维相似-》低维相似 OR 高维不相似-》低维不相似),因此要对相似度不匹配的项进行惩罚:
KL散度的特性是:
- 当 P(i) 很大,但 Q(i) 很小(即:两个点在高维很相似,但在低维画得很远)→ KL 值爆炸式增长,惩罚非常重 ❗
- 当 P(i) 很小,但 Q(i) 较大(即:高维不相似,低维却靠得太近)→ 惩罚较轻
🎯 这正是我们想要的!
这是如何做到的呢?

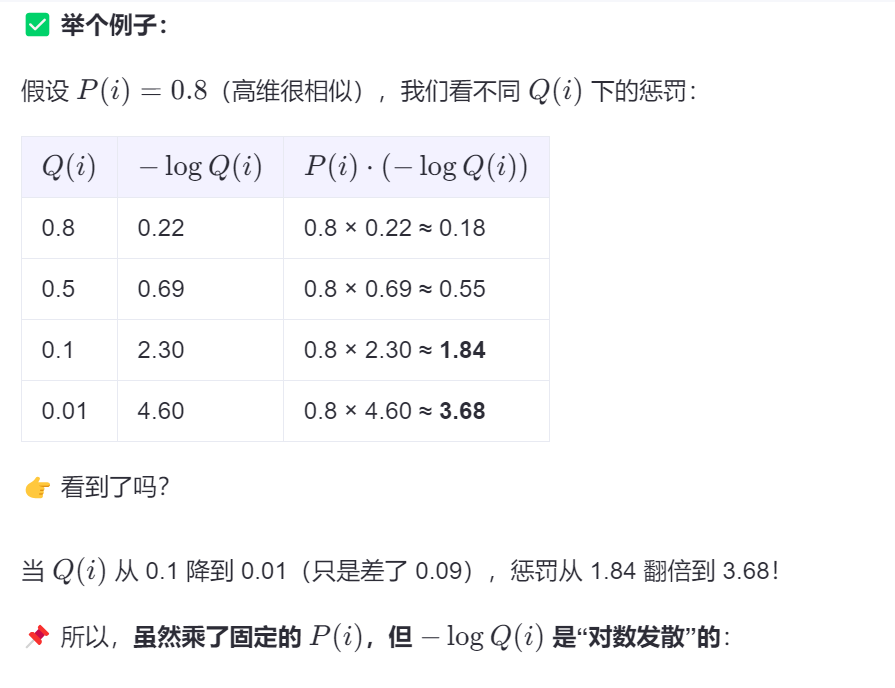
这就是对“相似度几乎为零”的预测的严厉惩罚。
我们也得到了一个普遍的结论,在大多数时候log都起着放大误差的作用。
为什么用KL散度而不是交叉熵?
🍕 比喻:你请朋友吃披萨,但口味不一样
假设你有一块特别调制的披萨(这是真实口味 P),你想让厨师(AI)做一块一模一样的复制品(Q)。
你的目标是:让复制品尽可能接近原版。
✅ KL 散度的视角:
“这个复制品,扭曲了我的原版多少?”
→ 分布匹配视角
这就像你在品尝后说:
- “我这块原版是辣味重、芝士多、蘑菇少。”
- 厨师做的复制品是“不辣、芝士少、蘑菇多”。
你评价:
“你把最辣的部分做得完全不辣,这是严重失真!”
“至于多加了蘑菇?虽然我不常吃,但还能接受。”
📌 KL 散度关心的是:你有没有忠实地还原“重点特征”。
- 原版重点是“辣” → 你做成“不辣” → 严重扭曲,扣大分!
- 原版不强调“蘑菇” → 你多加了 → 小问题,扣点小分
👉 所以 KL 散度像是一个追求“忠于原作”的美食评论家。
✅ 交叉熵的视角:
“如果我只知道你的复制品(Q),要猜出我的原版(P),得多费多少力气?”
→ 编码/预测视角
这就像你在玩一个“猜原版”的游戏:
- 你只能看厨师做的复制品(Q):不辣、芝士少、蘑菇多。
- 然后你要猜:原版是辣的?芝士多的?蘑菇少的?
因为复制品是“不辣”的,你很难猜到原版其实是“很辣”的 → 你需要额外花很多脑力去纠正这个错误。
📌 交叉熵衡量的是:用错误的参考(Q)去理解真相(P),得多付出多少“认知成本”。
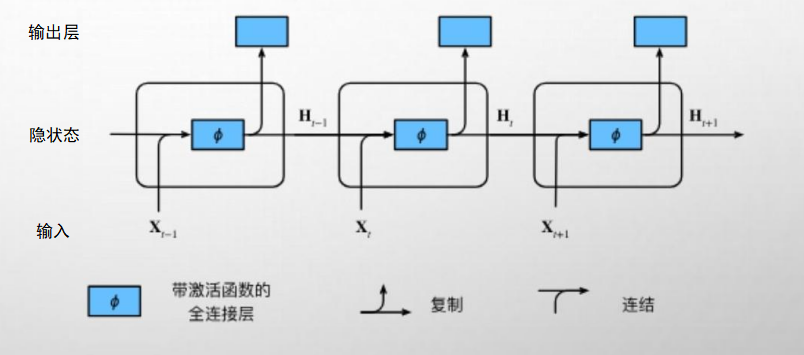
循环神经网络 (RNN)
通过循环传递的“记忆单元”(隐 状态),来处理序列化信息,从而 有效捕获上下文关联,按顺序读取 指令中的词嵌入,将其逐步压缩为 一个能代表完整意图的指令向量。
RNN 可以整合AGENT 过去的动作与观测序列(at-1,0t-1) … , 形成动态的“状态”认知,为当前决策提供依据。
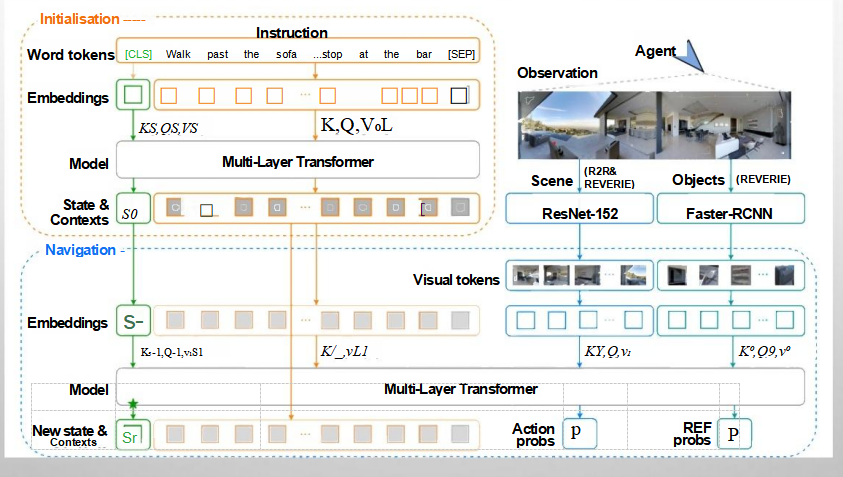
TRANSFORMER 模 型
1. 数据准备阶段
首先,我们需要准备好视觉和语言的数据。对于语言数据,我们将其转换为词嵌入向量;对于视觉数据,我们可能使用预训练的CNN提取图像特征,然后将这些特征也转换为向量形式。这些向量会被输入到Transformer模型中。
2. 编码器工作流程
嵌入层:在这个阶段,无论是语言还是视觉的信息都会被转化为模型可以处理的向量形式。对于语言,每个词会有一个对应的嵌入向量;对于视觉,图像的不同部分也会有对应的特征向量。
位置编码:为了保留序列中的位置信息,我们会给每个嵌入向量加上一个位置编码。这对于理解句子的语法结构或图像中物体的位置关系非常重要。
加&规范化、多头注意力、逐位前馈网络:这是Transformer的核心部分,它允许模型关注输入的不同部分,并从中学习复杂的模式。多头注意力机制让模型可以从多个角度同时考虑输入信息,而逐位前馈网络则进一步处理这些信息,帮助模型做出更准确的预测。
3. 解码器工作流程
解码器的工作原理与编码器类似,但它还包含了掩蔽多头注意力机制,这确保了解码器在生成输出时只能看到当前及之前的输入,模拟了人类阅读和理解的过程。
4. 多模态融合
在VLN任务中,多模态融合的关键在于如何让模型有效地结合视觉和语言的信息。这通常通过在编码器或解码器中引入跨模态注意力机制来实现。例如,当模型处理语言指令时,它可以“注意”到相关的视觉信息,反之亦然。这样,模型就能更好地理解指令与环境之间的关系,从而做出正确的导航决策。
5. 输出与优化
最后,经过一系列的处理后,模型会输出一个结果,比如下一步应该朝哪个方向走。这个结果会与真实情况对比,计算损失函数,然后通过反向传播调整模型参数,不断优化其性能。
编码器、解码器
输入理解器、输出询问器
掩蔽多头注意力机制
训练的时候,翻译 我阐释你的梦 ,当翻译到“你”的时候,模型只能注意到“我阐释你”四个字,不能注意到后面的字(因为这是应用的真实场景)
在解码器的自注意力层中,会引入一个叫 “掩蔽(mask)” 的操作。
我们用一个表格来表示注意力分数(表示每个词关注其他词的程度):
| 当前生成位置 → | 我 | 爱 | 猫 |
|---|---|---|---|
| 我 | 0.8 | 0.2 | 0.1 |
| 爱 | 0.3 | 0.6 | 0.4 |
| 猫 | 0.2 | 0.3 | 0.7 |
但这是“没加掩蔽”的情况,模型可以任意关注所有词。
现在我们加上掩蔽矩阵(look-ahead mask),规则是:
每个词只能关注它自己和它前面的词,不能关注后面的词。
所以我们要把“未来”的位置遮住(设为负无穷,softmax 后就变成 0):
| 掩蔽后 | 我 | 爱 | 猫 |
|---|---|---|---|
| 我 | 0.8 | 0 | 0 |
| 爱 | 0.3 | 0.6 | 0 |
| 猫 | 0.2 | 0.3 | 0.7 |
👉 你看,“我”只能看到“我”;“爱”能看到“我”和“爱”;“猫”能看到全部三个。但谁都不能看到“未来”的词。
如何翻译下一个字
编码器叫“输入理解器”,会通过各种方式彻底理解源语言的深层含义(编码+多头注意力+前馈网络),负责将这个意思输出的就是解码输出器。
现在解码器已经输出了第一个字,表达了第一部分的含义,他就会问编码器,接下来要表达什么?
解码器通过注意力机制把当前最相关的语义信息拉过来,帮助自己预测下一个词应该如何翻译,然后softmax一个概率。
第一步:把已生成的内容输入解码器
此时,模型已经生成了第一个字:“我”。现在我们要预测下一个最可能的字。
这个“我”会被:
- 转成词嵌入向量(比如一个256维的数字向量)
- 加上位置编码(表示这是第1个字)
- 输入到解码器的第一层
🧠 第二步:解码器内部发生了什么?
解码器有好几层,每一层都包含两个关键注意力机制:
1️⃣ 掩蔽多头自注意力(Masked Self-Attention)
- 模型先看自己已经生成的内容:“我”
- 由于只有一个字,它就只关注“我”
- 这一步输出一个“增强版”的“我”的表示,知道它在序列中的位置和语义
2️⃣ 交叉注意力(Encoder-Decoder Attention)
这才是最关键的一步!👉 跨模态/跨序列的“翻译”发生在这里。
解码器现在拿着“我”这个字的表示,去问编码器:
“我现在生成了‘我’,根据原文‘I love cats’,我接下来该说什么?”
编码器早就把英文句子“I love cats”全部理解完了,它输出了一堆“视觉+语言”式的特征(你可以想象成每个英文词的“意思向量”)
解码器通过注意力机制,去“查找”哪些英文词和当前最相关。
- 比如,它发现“love”这个词和“我”之后的内容最相关
- 所以它会把“love”的语义信息“拉过来”,帮助自己预测下一个字
这就像你在翻译时,看着英文句子,想着:“我”对应的是“I”,那接下来“love”应该翻译成“爱”。
📤 第三步:前馈网络 + 输出概率
经过多层这样的处理后,解码器的最后一层输出一个向量,表示:
“在当前上下文(已生成‘我’ + 原文‘I love cats’)下,下一个最可能的字是什么?”
这个向量会进入一个线性层 + softmax,变成一个概率分布,比如:
| 字 | 概率 |
|---|---|
| 爱 | 85% ✅ |
| 是 | 5% |
| 的 | 3% |
| 跑 | 1% |
| ... | ... |
模型就会选择概率最高的字:“爱”,作为下一个输出。
🔁 然后重复:继续生成“猫”
现在输入变成:
已生成:[我, 爱]
模型再次运行:
- 掩蔽注意力:只允许“我”和“爱”互相看
- 交叉注意力:拿着“我”和“爱”的表示,再去问编码器:“接下来该说什么?”
- 编码器提示:“cats”还没翻译呢
- 模型输出:“猫”的概率最高 → 选中
最终输出完整句子:“我 爱 猫”
SEQ2SEQ VLN全过程
- 看一眼环境 → 提取对象特征
V = {v₁..vₙ} - 读一遍指令 → 编码语言特征
Q = {q₁..qₘ} - 双向交叉注意力:
- Q 关注相关的 V(哪些物体重要?)
- V 关注相关的 Q(这个物体对应指令哪部分?)
- 融合特征 → 得到联合表示
H
🎯 示例指令:
“走到红色的门前,然后左转。”
我们要把这个句子输入到 Transformer 编码器(比如 BERT 或 VLN-BERT)中,最终得到每个词的语义向量 q₁, q₂, ..., qₘ。
第一步:分词(Tokenization)
模型不能直接理解汉字或单词,必须先把句子拆成“子词单元”(subword units)。常用的是 WordPiece 或 BPE 算法。
我们来对这句话进行分词:
原始句子:
走到红色的门前,然后左转。
分词后(模拟实际模型行为):
["走", "到", "红", "色", "的", "门", "前", ",", "然", "后", "左", "转", "。"]
👉 共 13 个 token(可以理解为“最小处理单位”)
⚠️ 注意:有些模型可能会把“红色”作为一个整体,或者“左转”合并,取决于训练方式。这里为了清晰,按单字拆分。
我们记这些 token 为:
t₁ = "走"
t₂ = "到"
t₃ = "红"
t₄ = "色"
t₅ = "的"
t₆ = "门"
t₇ = "前"
t₈ = ","
t₉ = "然"
t₁₀ = "后"
t₁₁ = "左"
t₁₂ = "转"
t₁₃ = "。"第二步:词嵌入(Word Embedding)
每个 token 会被映射成一个高维向量(比如 768 维),这个过程叫 词嵌入(Word Embedding)。
比如:
"走"→[0.82, -0.31, 0.54, ..., 0.17](768 个数字)"红"→[0.65, 0.72, -0.11, ..., 0.43]"左"→[-0.23, 0.88, 0.37, ..., -0.09]
这些向量是模型在预训练时“学会”的,它们捕捉了词语的基本语义。例如,“红”和“蓝”的向量会比较接近,因为都是颜色。
现在我们有:
E = {e₁, e₂, ..., e₁₃}—— 每个 e 是一个 768 维的词向量
第三步:位置编码(Positional Encoding)
Transformer 本身没有“顺序”概念,所以我们需要告诉它:“走”是第一个字,“到”是第二个……否则它可能把“走到”理解成“到走”。
于是加上 位置编码(Positional Encoding),它是一个根据位置生成的向量(也是 768 维),加到词嵌入上。
比如:
- 位置 1("走")的位置编码:
[0.00, 1.00, 0.00, ..., 0.54] - 加到
"走"的词嵌入上 → 得到新的输入向量
最终每个 token 的输入是:
input_i = word_embedding(t_i) + positional_encoding(i)
第四步:输入 Transformer 编码器
现在,这 13 个带位置信息的向量被送入 Transformer 编码器(通常是多层,比如 12 层)。
🔍 编码器做了什么?
它通过 自注意力机制(Self-Attention) 让每个词“看到”句子中的其他词,并根据上下文调整自己的表示。
举几个例子:
| 词 | 在上下文中发生了什么变化? |
|---|---|
"红" |
它发现后面是“色”,前面是“走”,但它真正重要的是和“门”连在一起 → 所以它的向量会更接近“红色的门”这个整体概念 |
"门" |
它接收到“红”、“色”、“的”、“前”的信息 → 变成“红色的门前”这个空间位置的语义 |
"左" |
它前面是“然后”,表示这是一个动作指令 → 它的向量会偏向“方向性动作” |
"走" |
它知道目标是“门前”,所以不只是随便走,而是“朝某个门走” |
经过多层处理后,每个词都得到了一个上下文化语义向量(contextualized embedding)。
第五步:得到最终的 Q 向量
输出就是:
Q = {q₁, q₂, ..., q₁₃}
其中每个 qᵢ 是一个 768 维向量,代表第 i 个 token 在整个句子中的完整语义表示。
比如:
q₃(对应“红”)不再是单纯的“颜色”,而是“要走到的那个门的颜色”q₆(“门”)包含了“红色”、“前面”、“目标物”等信息q₁₁(“左”)表示“在到达门之后要执行的转向动作”
假设智能体当前站在一个客厅里,摄像头拍到一张图像:
画面中有一个 红色的门、一张 桌子、一把 椅子、还有一个 窗户
它的任务是根据指令:“走到红色的门前” 来导航。
现在,我们要把这张图变成一组“带语义的视觉特征向量”V。
第一步:使用 Faster R-CNN 进行对象检测(Object Detection)
这不是简单的 CNN 全图卷积,而是要定位并识别图像中的每一个物体。
✅ 用什么模型?
- Faster R-CNN + ResNet + FPN(特征金字塔网络)
- 这个模型已经在 Visual Genome 等数据集上预训练过,能识别上千种物体
🔍 它做了什么?
对输入图像进行扫描,找出所有可能的物体,并给出:
- 边界框(Bounding Box):
(x, y, w, h)表示物体在图中的位置和大小 - 类别标签(Label):比如“door”、“table”、“chair”
- 置信度分数(Confidence Score):模型有多确定这是个门?
比如输出:
- 物体1:红色的门 →
[x=100, y=50, w=80, h=200], label="door", score=0.95 - 物体2:桌子 →
[x=200, y=150, w=120, h=80], label="table", score=0.88 - 物体3:椅子 →
[x=220, y=180, w=60, h=70], label="chair", score=0.82
⚠️ 注意:模型不会只输出3个物体,通常会输出10~36个候选区域(region proposals),包括一些背景或模糊区域,后面会筛选。
第二步:提取每个物体的视觉特征向量 v_i
这才是关键!我们不仅要“看到”物体,还要把它变成一个高维向量,让模型知道它的“样子”和“含义”。
如何提取?
使用 CNN + ROI Pooling / ROI Align
- 主干网络(如 ResNet-101)先对整张图做一次前向传播,得到一个高层特征图(feature map),比如
C × H × W(通道×高×宽) - 对每个检测出的物体边界框(bounding box),从这个特征图上“抠”出对应的区域
- 使用 RoI Align 技术,把不同大小的区域统一成固定尺寸(比如 7×7)
- 再通过一个全连接层或全局平均池化,压缩成一个固定长度的向量(如 2048维 或 768维)
👉 每个物体就得到了一个特征向量:
v₁ = [0.82, -0.31, 0.54, ..., 0.17]→ 对应“红色的门”v₂ = [0.65, 0.72, -0.11, ..., 0.43]→ 对应“桌子”v₃ = [-0.23, 0.88, 0.37, ..., -0.09]→ 对应“椅子”
这些向量不仅包含颜色、形状,还隐含了语义(比如“门”是入口,“椅子”可以坐)。
注意,这些语义是预训练时就与图片关联起来了,比如“门”具有“门把手”,“开闭”属性
第三步:构建 V = {v₁, v₂, ..., vₙ}
最终,我们得到一组向量:
V = {v₁, v₂, v₃, ..., vₖ}
其中k通常是 10~36(常用 36 个对象)
每个 v_i 包括:
- 视觉特征向量(来自 CNN)
- 位置信息(bounding box 的
(x, y, w, h)或归一化坐标) - (可选)类别标签(但一般不用 one-hot,而是让模型自己学)
✅ 这就是 BUTD 中的 “Bottom-Up”:从图像底层像素出发,自下而上地提取出有意义的对象区域。
以上就得到了来自视觉的v_i和来自语义的q_i
融合VQ
🔁 第一阶段:语言 → 视觉 注意力
(也叫:Language-guided Visual Attention)
目标:让每个视觉对象知道“我在语言指令中的重要性”。
✅ 正确做法:
- Query = 视觉特征
v_i(我想知道自己有多重要) - Key = 语言向量
q_j(语言的语义表示) - Value = 语言向量
q_j
👉 这样做的含义是:
“我是一个视觉物体(比如椅子),我去问语言指令中的每一个词:‘我和你相关吗?’”
比如:
v_椅子去问q_红色、q_门、q_前、q_左转……- 发现匹配度都很低 → 所以它的“被关注权重”很低
- 而
v_红门去问q_红色和q_门时,匹配度很高 → 权重变高
输出:
- 每个视觉向量被增强为:
v'_i = v_i + attention(v_i, Q) - 得到增强后的视觉表示:
V' = {v'_1, ..., v'_k}
✅ 现在每个物体都知道:“我是不是指令里提到的目标?”
🔁 第二阶段:视觉 → 语言 注意力
(也叫:Image-guided Language Attention)
目标:让每个语言词知道自己对应哪个视觉区域。
✅ 正确做法:
- Query = 语言向量
q_i(我想知道自己对应哪个物体) - Key = 视觉特征
v_j(图像中的物体) - Value = 视觉特征
v_j
👉 含义是:
“我是词‘红色的门’,我去查图像中哪个物体最像我描述的?”
比如:
q_红色会关注v_红门q_走到可能关注v_路径或v_地面q_左转可能关注v_走廊方向
输出:
- 每个语言向量被增强为:
q'_i = q_i + attention(q_i, V) - 得到增强后的语言表示:
Q' = {q'_1, ..., q'_m}
✅ 现在每个词都知道:“我说的这个东西,在图像里长什么样。”
旁听指挥官模式
1. 全局表示向量 H 的构建
我们需要把整个场景的“当前状态”压缩成一个向量 H,作为决策依据。
常见方法:
✅ 方法一:池化 + 拼接
- 对增强后的语言向量
Q'做平均池化或 [CLS] 向量提取 → 得到h_lang - 对增强后的视觉向量
V'做加权池化(重要物体权重高) → 得到h_vis - 拼接:
H = [h_lang; h_vis]
✅ 方法二:使用 [SEP] 或 [NAV] 特殊 token
- 类似 BERT,在输入中加入一个特殊 token
[NAV] - 经过多层交叉注意力后,这个 token 的输出向量
h_[NAV]就自然融合了语言和视觉信息 - 直接用
H = h_[NAV]
这个
H就是智能体的“当前认知状态”:我知道指令是什么,我也知道我看到了什么。
2. 动作分类头(Action Head)
将 H 输入一个简单的全连接网络(MLP):
H (768维)
↓
Linear + ReLU
↓
Linear → 输出 4 个 logits(对应 4 个动作)
↓
Softmax → 动作概率分布比如输出:
- 前进:0.7 → 选中!
- 左转:0.15
- 右转:0.1
- 停止:0.05
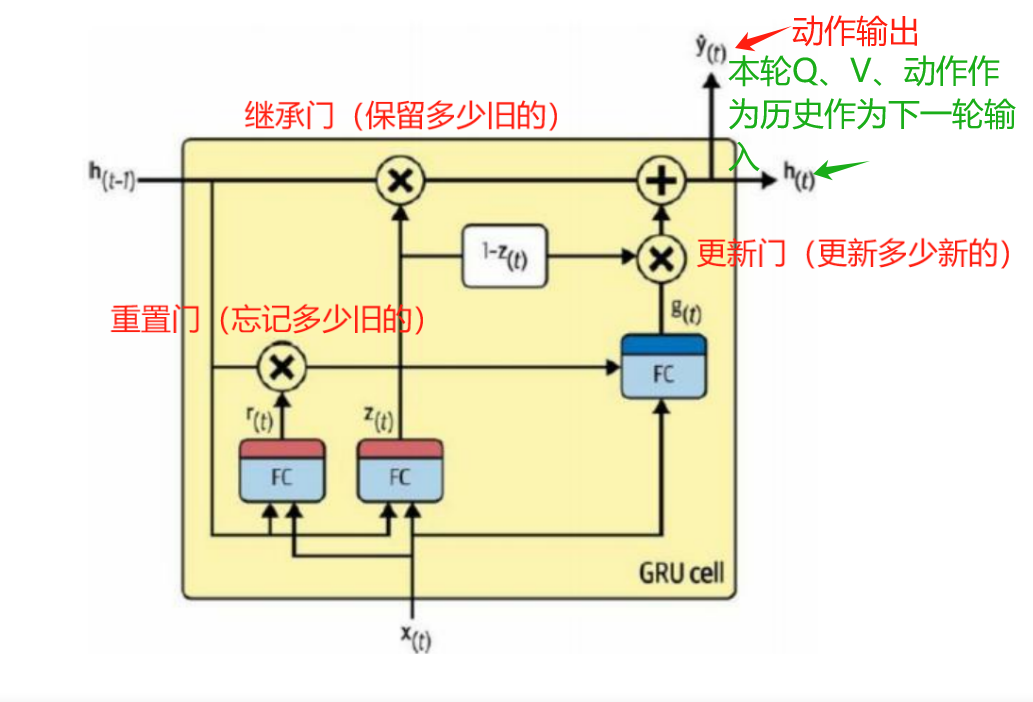
一般分类部分用MLP就够了,什么时候需要用 GRU / LSTM?
当你需要建模历史状态、避免重复、记住走过的路时,就必须引入循环结构。
典型场景:
| 场景 | 为什么需要记忆 |
|---|---|
| 走进死胡同 | 需要记住“刚才来过这里,不能原路返回” |
| 多层建筑 | 需要记住“我已经上过楼了” |
| 指令模糊 | 如“走到门边”,但有多扇门,需记住哪扇是目标 |
如何实现?
# 用 GRU 维护一个“历史状态”
h_t, c_t = gru( H_current, (h_{t-1}, c_{t-1}) )H_current:当前帧的融合特征(来自 MLP 前的 H)h_{t-1}:上一步的隐藏状态(记忆)- 输出
h_t:包含历史信息的新状态 → 输入动作头
👉 这样,模型就有了“记忆力”,不会在一个走廊来回转圈。
🔁 第六步:训练模型 —— 它是怎么学会的?强化学习
模型不是天生就会导航的,它需要在大量带标注的导航路径上训练。
📚 训练数据示例(R2R 数据集):
- 指令:“走到红色的门前,然后左转。”
- 理想路径:前进 → 前进 → 左转 → 停止
- 每一步都有“正确动作”标签
🎯 训练目标:最大化正确动作的对数似然
损失函数(交叉熵):
Loss = -log(P(正确动作 | 当前图像 + 指令))通过反向传播,调整:
- CNN 参数(让视觉特征更准)
- Transformer 参数(让注意力更合理)
- 动作头参数(让决策更准确)
[CLS]是什么?
[NAV]是不是占位向量,插入在Q中,交叉注意力也会注意到他,他没有语义但是也会注意其他人,最终他会包含所有的VQ信息
🧩 一、[CLS] 是什么?(来自 BERT)
起源:
[CLS](Classification Token)最早出现在 BERT 模型中。- 它是一个可学习的特殊 token,被插入到输入序列的最前面。
Input: [CLS] 我 爱 喜茶
Tokens: 0 1 2 3作用:
- 在 BERT 的预训练任务中,
[CLS]的最终向量h_0被用来:- 判断两个句子是否连续(NSP 任务)
- 做文本分类(如情感分析)
为什么它能“代表整个句子”?
因为:
- 它参与了 Self-Attention:
- 所有其他 token(“我”、“爱”、“喜茶”)都会 attention 到
[CLS] - 同时
[CLS]也会 attention 到所有其他 token
- 所有其他 token(“我”、“爱”、“喜茶”)都会 attention 到
- 经过多层 Transformer 后,
[CLS]的向量h_0就“听到了所有人说话” - 最终
h_0成为一个全局语义摘要
👉 所以:[CLS] 不是“有语义”,而是通过 attention 被灌输了语义
🚩 二、[NAV] 是什么?(来自 VLN 模型,如 CMA)
起源:
[NAV](Navigation Token 或 Commander Token)是 VLN 领域的创新设计,灵感来自[CLS]。- 它被插入到语言指令序列中,比如:
Q = [q_走到, q_蓝色, q_招牌, [NAV], q_喜茶]工作流程:
Step 1: 多轮 Cross-Attention
- 每个 q_i ↔ v_j 交互(语言与视觉对齐)
- [NAV] 也参与 attention:它会 attend 到所有 q_i 和 v_j
Step 2: 提取 [NAV] 的输出向量
- 取出 [NAV] 位置的最终向量 → h_nav_t
Step 3: h_nav_t 作为“决策向量”输入 GRU✅ 三、回答你的问题:
❓
[NAV]是不是占位向量?
✅ 是的,但它不是“空占位”,而是“功能占位”。
- 它没有原始语义(不像“蓝色”、“招牌”)
- 但它有结构功能:作为“信息汇聚点”
❓ 它插入在 Q 中,交叉注意力也会注意到他?
✅ 完全正确!
- 在 Self-Attention 和 Cross-Attention 中,所有 token 都会 interaction
- 其他语言 token 会 attention 到
[NAV] - 视觉 token 也会被
[NAV]attention 到(或反过来)
❓ 他没有语义但是也会注意其他人?
✅ 是的!
- 它的“语义”是在训练过程中动态学习出来的
- 初始时它是随机向量,但通过反向传播,它学会“该关注什么”
❓ 最终他会包含所有的 VQ 信息?
✅ 正是如此!这是它的设计目的!
👉 [NAV] 的最终向量 h_nav_t 包含了:
- 语言指令的语义(通过 self-attention)
- 视觉场景的内容(通过 cross-attention)
- 历史信息(如果用了 state gating)
- 任务目标(通过训练目标引导)
所以它被称为:
“决策向量”(decision vector) 或 “导航状态”(navigation state)
🔁 五、和 [CLS] 的对比
| 特性 | [CLS](BERT) |
[NAV](VLN) |
|---|---|---|
| 位置 | 序列开头 | 可插入任意位置(常在中间) |
| 输入 | 只有语言 | 语言 + 视觉(cross-modal) |
| 输出用途 | 分类、句子相似度 | 导航决策、动作预测 |
| 是否参与 attention | ✅ 是 | ✅ 是 |
| 是否“吸收信息” | ✅ 是 | ✅ 是(更复杂) |
| 是否有语义 | ❌ 初始无,训练后有 | ❌ 初始无,训练后有 |
👉 所以:[NAV] 是 [CLS] 的跨模态升级版
总结:VLN 完整流程
| 步骤 | 内容 |
|---|---|
| 1️⃣ 视觉输入 | 当前图像 → BUTD 提取 V = {v₁..vₖ} |
| 2️⃣ 语言输入 | 指令 → Transformer 编码为 Q = {q₁..qₘ} |
| 3️⃣ 多模态融合 | 双向交叉注意力 → 得到 Q', V' |
| 4️⃣ 状态编码 | 池化融合 → 得到全局向量 H |
| 5️⃣ 动作预测 | MLP 输出动作概率 → 选择并执行 |
| 6️⃣ 环境更新 | 移动 → 新图像 → 回到第 1 步 |
| 7️⃣ 训练 | 用标注路径监督学习,优化决策 |
CMA模型
CMA 不是“取代”Seq2Seq,而是“升级版”的 Seq2Seq —— 它在 Seq2Seq 框架内,把交叉注意力做得更深入、更精细、更动态。
动态注意力
得到Q={q_i...} V={v_i...}后,会进入交叉注意力阶段, 对于普通seq2seq会使用静态注意力,如果没找到就失败
而增强seq2seq(CMA)而言,
问题通过tokenize、词嵌入、位置编码、transformer得到Q={q_i...}
图片通过RGB输入和深度输入在经过BUTD后得到V={v_i...}
输入历史隐藏状态h(t-1),比如“左边已经探测过,无目标”,用predict_bias生成门控信号 g = [-2.0, 0.0, +1.0]
接着正常进行交叉注意力:
引入旁听指挥官[NAV]决策向量,他被插入语言向量中,
Q = [q_走到, q_蓝色, q_招牌, [NAV], q_喜茶]会跟随Q一同进入交叉注意力机制,使得每个物体知道自己在问题中匹配哪一个词,每个词知道自己匹配图像中哪个物体,得到互相匹配的 注意力分值scores
然后加上之前得到的门控信号偏置
modulated_scores = scores + g
= [1.0, 3.0, 1.2] + [-2.0, 0.0, +1.0]
= [-1.0, 3.0, 2.2]softmax得到关注概率
weights = softmax([-1.0, 3.0, 2.2]) ≈ [0.01, 0.64, 0.35]然后加权求和得到h_nav
h_nav_1 = 0.01*v_红 + 0.64*v_蓝 + 0.35*v_绿此时h_hav融合了Q和V,以及历史信息。
h_nav 就是“当前时刻的决策向量”,在交叉注意力中包含了所有信息(当前帧的视觉 + 语言 + 任务目标信息+历史信息)。
然后进入GRU,输入是 本次压缩状态 h_nav。
在GRU中,更新门和继承门决定保留和更新多少之前的h(t-1)也就是(上一次的QV和动作、路径信息)进入隐藏状态,作为下一次输入,
# GRU 更新
h_t = GRU(h_nav)
↑ ↑
历史记忆 当前决策向量
# 动作预测
y = MLP(h_t)
P(a) = softmax(y)- 更新门(update gate):决定
h_{t-1}和h_nav的融合比例 - 重置门(reset gate):控制
h_{t-1}对候选状态的影响 - 输出门:GRU 本身没有输出门(那是 LSTM),但
MLP(h_t)相当于“动作输出门”
同时还会通过输出门决定y(这一轮的动作向量),经过全连接层softmax输出本轮的动作
SEQ2SEQ 与 CMA
| 特性 | 传统 seq2seq | CMA(增强版) |
|---|---|---|
| 语言编码 | Bi-LSTM → Q | Bi-LSTM + Transformer → Q |
| 视觉编码 | CNN → V | CNN + BUTD / DETR → V |
| 多模态融合 | 拼接 Q 和 V | 交叉注意力(Q ↔ V) |
| 注意力机制 | 无 或 单向 | 双向、多轮、可变形 attention |
| 决策依据 | 浅层融合 | 深度语义对齐(词←→物体) |
| 是否有 GRU | ✅ 有 | ✅ 也有 |
| 功能 | 作用 |
|---|---|
| ✅ 多轮 attention | 反复 refine 对齐结果(“是不是喜茶?” → “确认是”) |
| ✅ 可变形 attention | query 主动查找关键区域,不扫描全图 |
| ✅ [NAV] token | 作为“决策中心”汇总信息 |
| ✅ 状态门控 attention | 根据 GRU 状态动态调整注意力 |
| ✅ 双流输入(RGB + 深度) | 更好理解空间结构 |
可变形注意力(Deformable Attention)——减少点积计算
这一步发生在已经得到QV的交叉注意力部分,q_i会根据预训练的数据预测q_i对应的物体大概在图像的哪个部分,生成一组偏移向量,对应q中每个词语的预测对象在图像中的相对偏移
本次KQV注意时就只用匹配这几个偏移位置,而不是全图搜了
他依赖于先验数据(训练时奶茶店的招牌一般在哪),但不受限,如果没找到可以根据需要调整权重。
比如蓝色招牌可能存在于这四个位置,可能性分别是0.6 0.2 0.1 0.1,如果在第一位没找到就找第二位,找到后会调整权重。
# q_蓝色 → 输出 4 个采样点 + 权重
sampling_locations = [
(+0.1, -0.3), # 上中部(高权重,常识)
(+0.0, +0.4), # 下中部(低权重,备用)
(-0.2, -0.1), # 左上
(+0.3, +0.2), # 右下
]
weights = [0.6, 0.2, 0.1, 0.1] # 主要看第一个,但也看别的如何让感知与记忆协作——状态门控
Attention 负责“看清楚现在”,
GRU 负责“记住过去”,
而状态门控让“过去指导现在”。
以前是隐藏状态在cross attention之后在GRU时输入的,
现在让隐藏状态h(t-1)带着历史信息参与交叉注意力,
这样就能在思考和决策的时候都考虑到历史情况
一、门控信号的两种形式
| 类型 | 作用范围 | 形状(假设 N 个视觉 patch) | 效果 |
|---|---|---|---|
| 🔹 全局门控 | 整张图像统一调节 | g: [1] 或 [1, 1] |
整体增强或减弱注意力强度 |
| 🔸 空间门控 | 每个图像区域独立调节 | g: [N] 或 [N, 1] |
对不同区域“区别对待” |
二、全局门控:统一增强/抑制整张图
效果:
- 如果
g ≈ 1→ 正常关注 - 如果
g ≈ 0→ “我现在不确定,先别太相信视觉输入” - 类似于:“整体降低注意力增益”
应用场景:
- 模型刚转弯,视野不稳定 → 暂时降低对当前帧的信任
- 环境太暗/模糊 → 主动抑制当前视觉输入的影响
三、空间门控:对每个区域分别增强/抑制(这才是重点!)
用 h_{t-1} 预测一个“注意力偏置图”(attention bias map),告诉模型:“这些地方你之前看过了,别再看了;那些地方还没探索,重点看!”
场景:
- t=0:视角偏左,没看到蓝色 → 模型决定“右转”
- t=1:新视角,现在能看到右边了
空间门控如何工作?
# h_0 记录:“左半边已探索,无目标”
attn_bias = predict_bias(h_0) # 输出:左半边 patch 偏置为 -2,右半边为 +1
attention_scores = Q @ K.T
modulated_scores = attention_scores + attn_bias
# 结果:左边得分被压低,右边被抬高“左边我已经看过了,这次重点看右边!”
具体执行:
用历史状态h(t-1)生成一个门控信号g
# h_0 是来自 GRU 的上一个隐藏状态
g = torch.sigmoid(linear_layer(h_0)) # 生成一个[0,1]范围内的门控信号他是用来放大或抑制某些位置的注意力权重,使得模型能够更灵活地关注重要信息,忽略不相关的信息。
正常计算注意力得分,用KQV方法(查询向量(Q)与键向量(K)之间相似度的度量)
# 原始注意力得分
attention_scores = torch.matmul(Q, K.transpose(-2, -1))接着,用g调节注意力得分
全局门控:
g = torch.sigmoid(linear(h_{t-1})) # 输出一个标量,如 0.8
attention_scores = Q @ K.T # 原始得分 [1, N]
modulated_scores = g * attention_scores # 所有位置都 ×0.8空间门控:
# h_0 记录:“左半边已探索,无目标”
attn_bias = predict_bias(h_0) # 输出:左半边 patch 偏置为 -2,右半边为 +1
attention_scores = Q @ K.T
modulated_scores = attention_scores + attn_bias
# 结果:左边得分被压低,右边被抬高最后
# 应用 softmax 函数得到最终的注意力权重
attention_weights = F.softmax(modulated_scores, dim=-1)空间门控工作原理
示例背景:
- 指令:
Q = "蓝色招牌的喜茶" - 当前视角图像:
V_1 = [v_左红店, v_中蓝店, v_右绿店] - 上一时刻状态:
h_{t-1}记录了“刚才左边红色店铺已经看过了,没有目标”
Step 0: 从 h_{t-1} 生成空间门控信号 g
# h_{t-1} 包含历史记忆:“左半区已探索,无蓝色招牌”
g = MLP(h_{t-1}) # 输出一个 [3] 的向量,对应三个区域
# 假设输出:g = [-2.0, 0.0, +1.0]
# 左红店 中蓝店 右绿店👉 这个 g 是空间门控偏置(spatial bias),不是乘法因子,而是加到 attention scores 上的偏移量。
Step 1: 交叉注意力计算原始 attention scores
先不考虑历史,只看当前语言-视觉匹配度:
Q · v_左红店 → 1.0 → softmax前得分
Q · v_中蓝店 → 3.0
Q · v_右绿店 → 1.2原始 scores = [1.0, 3.0, 1.2]
Step 2: 加入空间门控偏置 g
modulated_scores = scores + g
= [1.0, 3.0, 1.2] + [-2.0, 0.0, +1.0]
= [-1.0, 3.0, 2.2]👉 效果:
- 左红店:虽然颜色匹配,但被
g惩罚(-2.0)→ 因为“之前看过了” - 中蓝店:强匹配 + 无惩罚 → 依然高分
- 右绿店:轻微匹配 + 正向鼓励(+1.0)→ “这是新区域,值得看”
Step 3: softmax → 最终 attention weights
weights = softmax([-1.0, 3.0, 2.2]) ≈ [0.01, 0.64, 0.35]对比无门控时的 [0.1, 0.8, 0.1],现在:
| 区域 | 无门控 | 有空间门控 |
|---|---|---|
| 左红店 | 0.1 → 被关注 | 0.01 → 几乎忽略 ✅ |
| 中蓝店 | 0.8 | 0.64 → 仍是主目标 |
| 右绿店 | 0.1 | 0.35 → 探索新可能 ✅ |
👉 模型变得更“聪明”了:不再重复看左边,而是更关注中蓝店,同时留意右边是否有新线索
Step 4: 加权求和 V_1 → 得到 h_nav_1
h_nav_1 = 0.01*v_红 + 0.64*v_蓝 + 0.35*v_绿✅ 结果:仍然是“以蓝色店为主”,但包含了对右侧新区域的探索倾向
Step 5: 输入 GRU → 更新状态
h_t = GRU(h_{t-1}, h_nav_1)新的 h_t 会记录:
- “我刚才重点看了中蓝店”
- “也留意了右边”
- “左边确认无目标”
为下一步决策提供更丰富的记忆。
Step 6: 预测动作
可能输出:
- “走向中蓝店”(如果匹配度很高)
- 或“向右转一点,确认右边是否也有蓝色招牌”(如果有歧义)
👉 模型学会了“避免重复探索”,并“主动探索未知区域”