EfficientViM: Efficient Vision Mamba with Hidden State Mixer based State Space Duality
Sanghyeok Lee 1 Joonmyung Choi 1 Hyunwoo J. Kim 2
1 Korea University 2 KAIST
{cat0626, pizard}@korea.ac.kr hyunwoojkim@kaist.ac.krCorresponding author.
Abstract
为了在资源受限的环境中部署神经网络,先前的工作构建了结合卷积和注意力机制的轻量级架构,分别用于捕获局部和全局依赖关系。近年来,状态空间模型 (SSM) 因其在处理令牌 (tokens) 数量上具有有利的线性计算成本,已成为进行全局交互的有效操作。
为了利用SSM的优势,本文引入了高效视觉Mamba (Efficient Vision Mamba, EfficientViM),这是一种基于隐藏状态混合器状态空间对偶 (Hidden State Mixer-based State Space Duality, HSM-SSD) 的新颖架构,能以进一步降低的计算成本高效捕获全局依赖关系。
通过观察发现SSD层的运行时间主要由对输入序列的线性投影 (linear projections) 驱动,本文重新设计了原始SSD层,在HSM-SSD层中于压缩的隐藏状态 (hidden states) 内部执行通道混合 (channel mixing) 操作。
此外,本文提出了多阶段隐藏状态融合 (multi-stage hidden state fusion) 来增强隐藏状态的表示能力,并提供了缓解由内存边界操作 (memory-bound operations) 引起的瓶颈的设计。
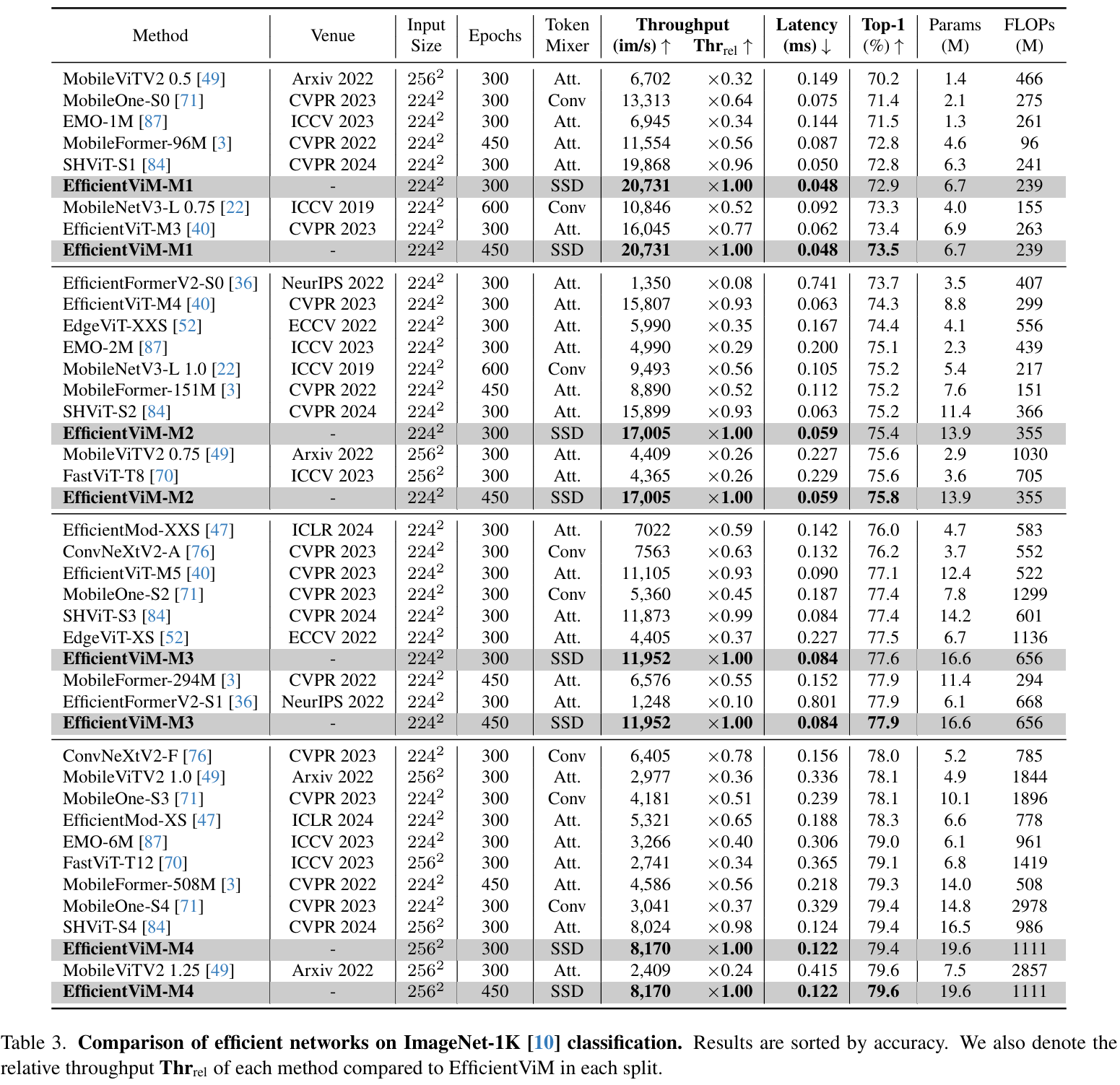
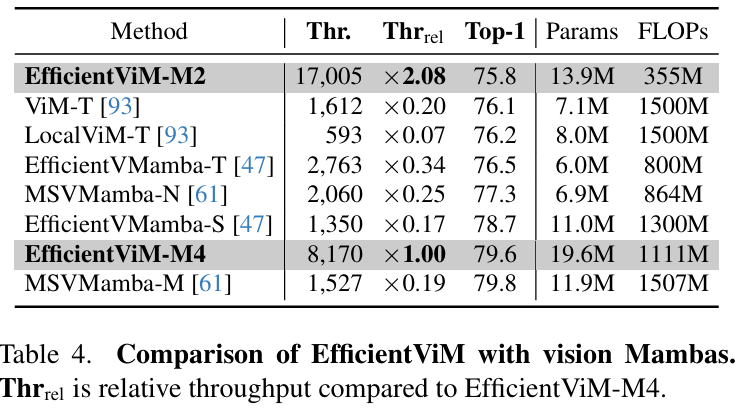
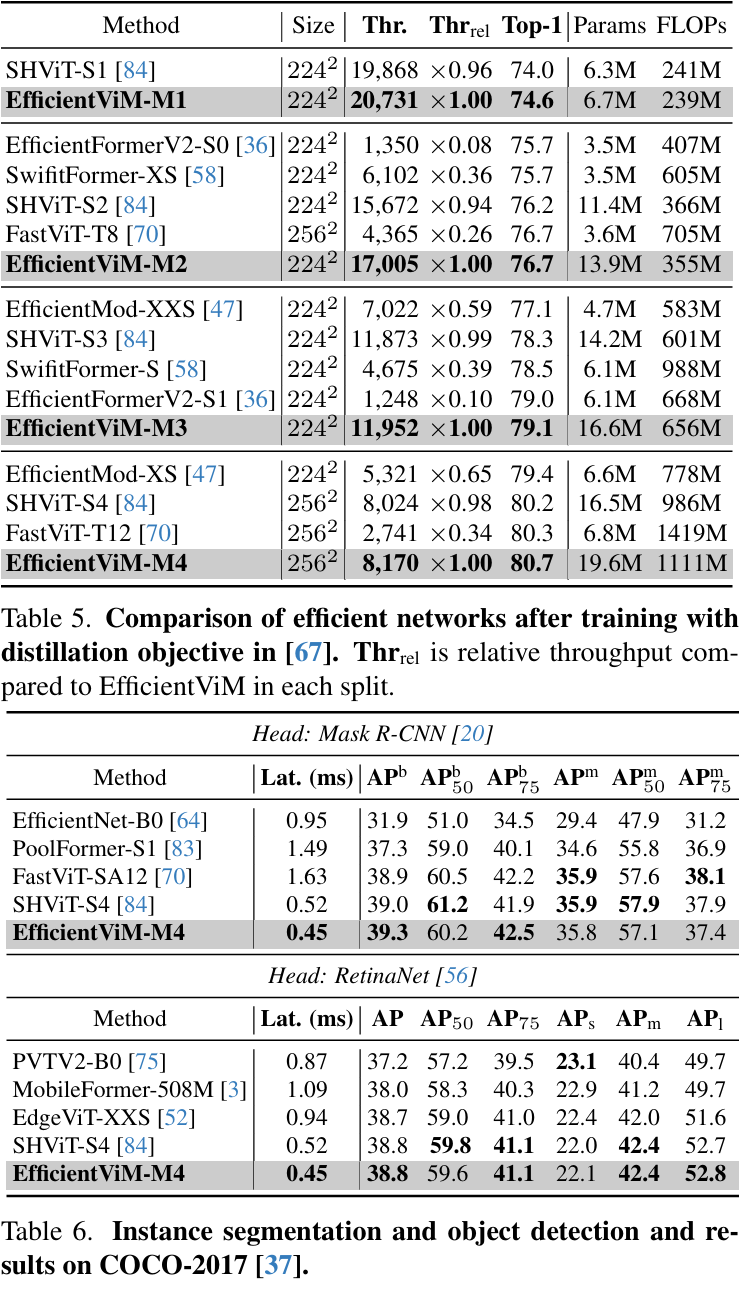
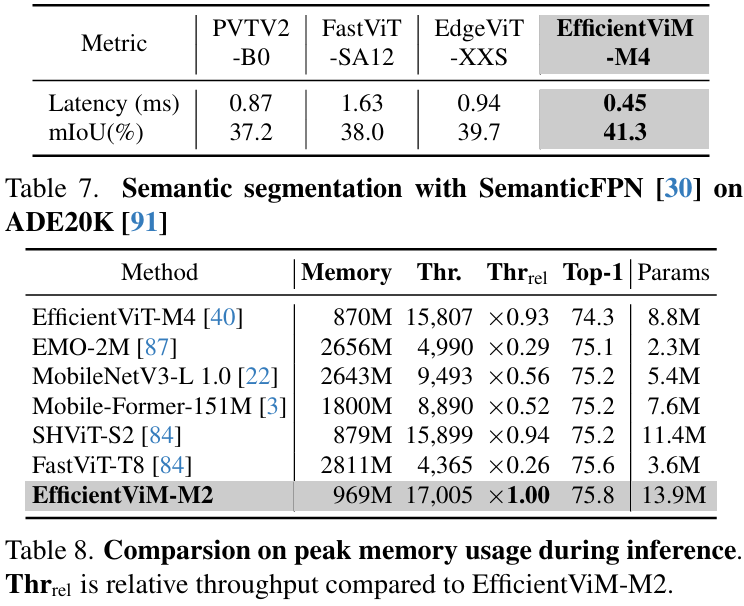
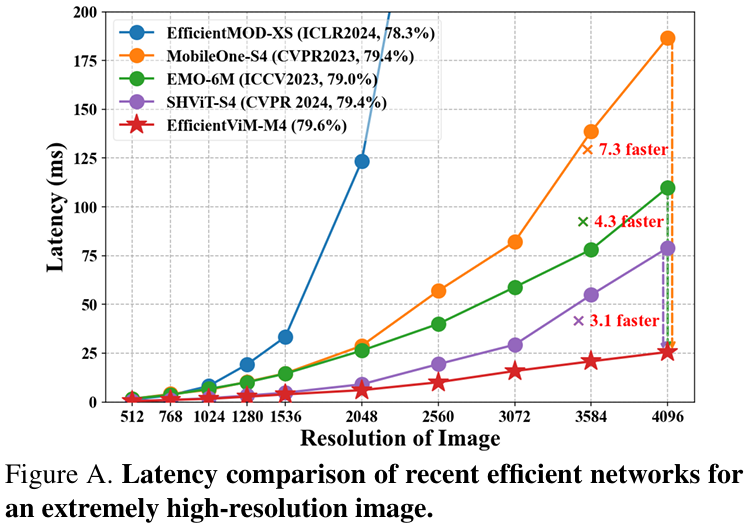
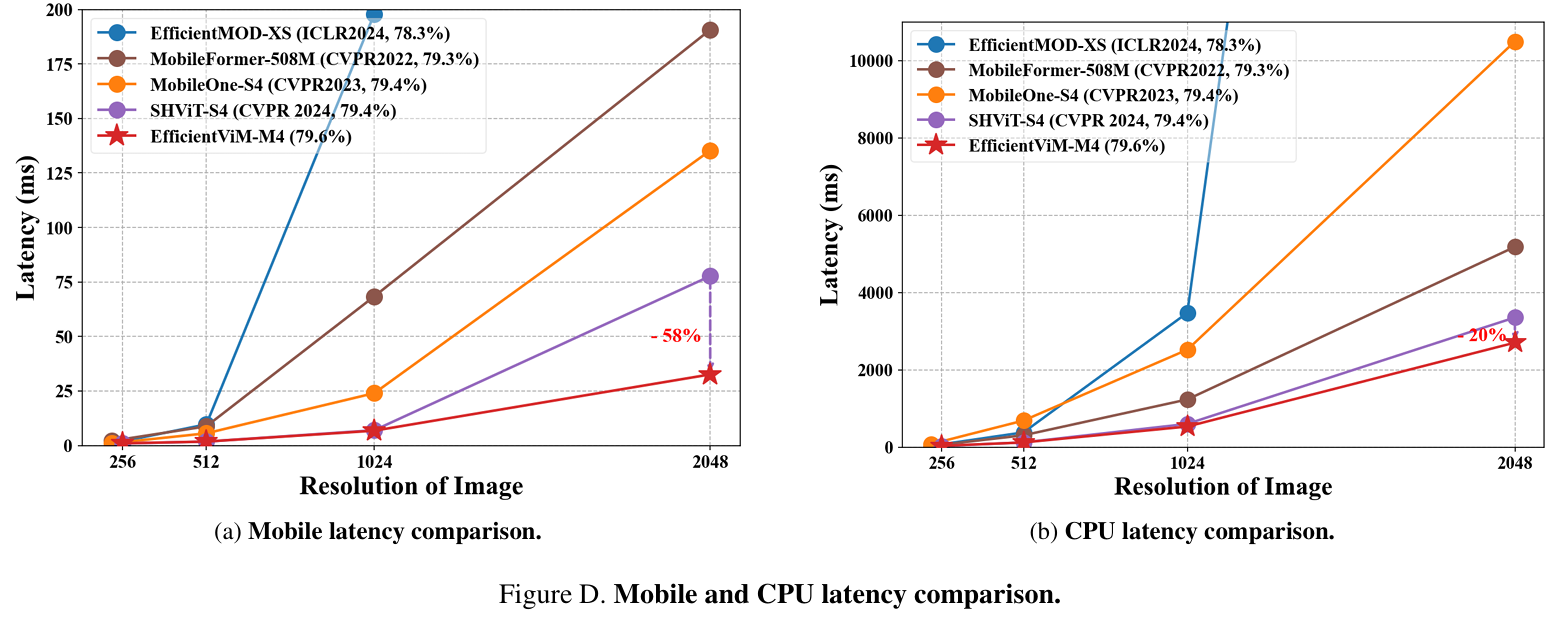
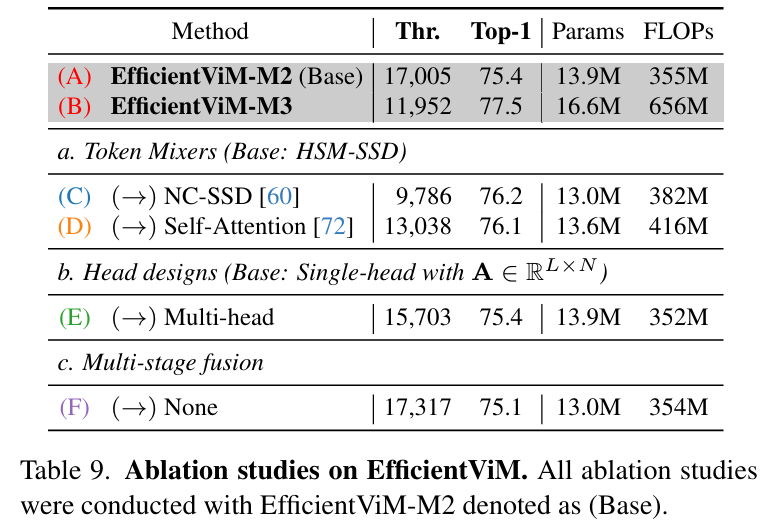
因此,EfficientViM家族在ImageNet-1k上实现了新的最优速度-精度权衡 (state-of-the-art speed-accuracy trade-off),在比第二好的模型SHViT更快的速度下,性能提升了高达0.7%。
此外,当缩放图像或采用蒸馏训练 (distillation training) 时,与先前的工作相比,本文观察到吞吐量 (throughput) 和精度均有显著提升。
代码可在 GitHub - mlvlab/EfficientViM 获取。
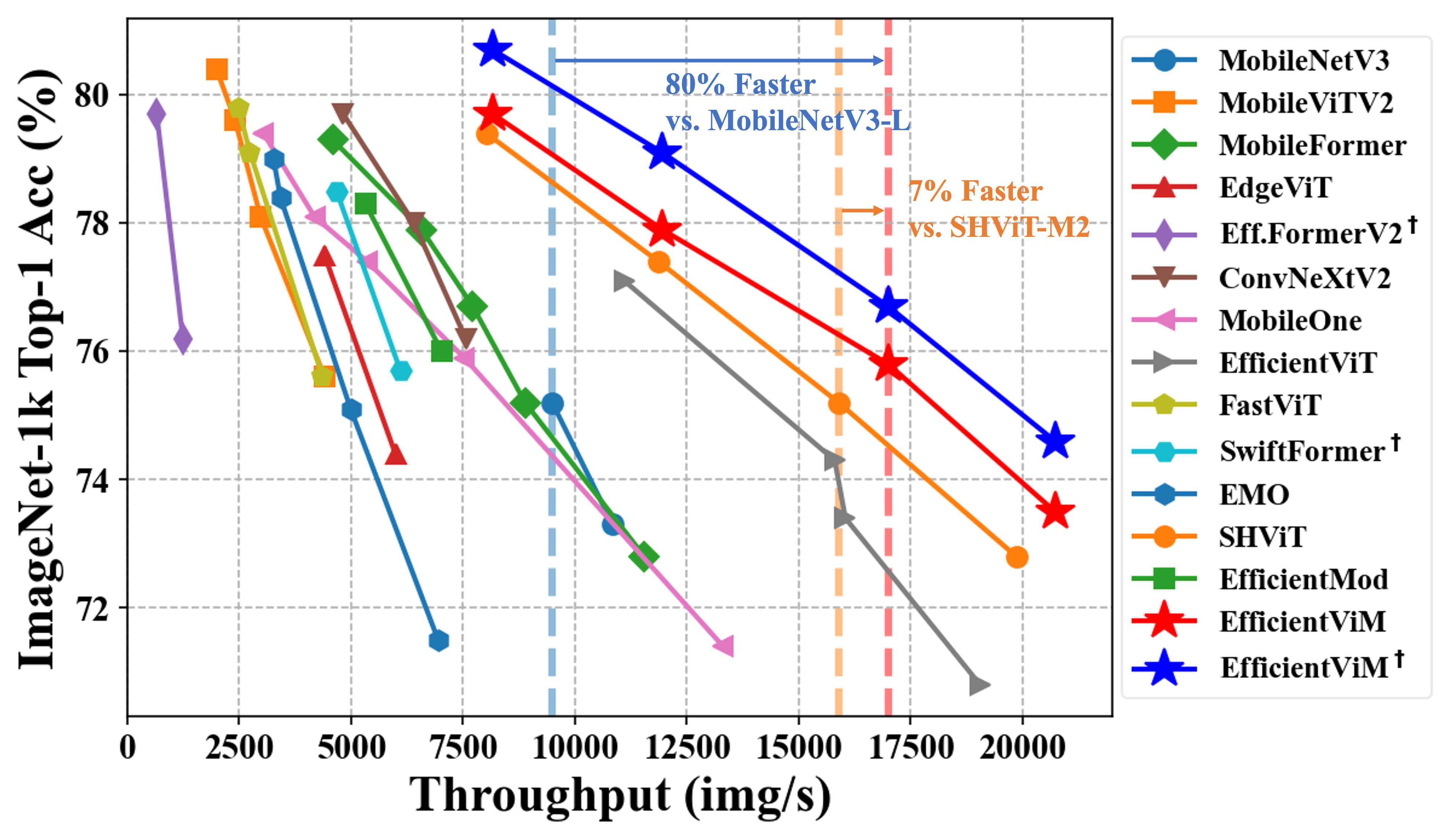
Figure 1:Comparison of efficient networks on ImageNet-1K [10] classification. The family of our EfficientViM, marked as red and blue stars, shows the best speed-accuracy trade-offs. ✝ indicates the model trained with distillation following [67].
1 Introduction
针对资源受限环境的高效视觉架构一直是计算机视觉领域的研究重点,涵盖图像分类、目标检测与分割等任务。早期研究侧重于设计高效的卷积神经网络,其中Xception提出的深度可分离卷积(DWConv)被广泛应用于MobileNet等轻量级CNN架构。随着Vision Transformer(ViT)的出现,注意力机制成为捕获长程依赖关系的重要工具,但其二次计算复杂度限制了效率。为此,研究者尝试通过近似自注意力或限制令牌数量来优化计算效率,并开发了结合ViT与CNN的混合模型。然而,自注意力的二次复杂性仍是主要瓶颈。
近年来,状态空间模型(SSMs)因其线性计算复杂度与全局感受野能力成为自注意力的替代方案。Mamba通过选择性扫描机制 (selective scanning mechanisms) 实现了硬件感知的序列处理,其后续研究将SSM扩展到视觉任务中,通过多路径扫描机制解决因果约束问题。最新工作如VSSD和Linfusion进一步提出非因果状态空间对偶(NC-SSD)以消除因果掩码。
尽管视觉Mamba模型在性能上优于传统方法,其速度仍落后于轻量级视觉模型,且主要瓶颈源于门控操作和输出投影中的线性计算。
本文提出高效视觉Mamba(Efficient Vision Mamba, EfficientViM),这是一个基于Mamba的轻量级视觉主干网络家族,采用基于隐藏状态混合器的 SSD(HSM-SSD)层。该层将通道混合操作从图像特征空间转移至隐藏状态空间,通过压缩潜在表示缓解计算瓶颈,同时保持模型泛化能力。
此外,本文引入多阶段隐藏状态融合方法,通过联合原始logits与各阶段隐藏状态衍生的logits增强表示能力。通过优化内存边界操作并优先考虑实际性能而非理论指标(如FLOPs),EfficientViM实现了最优速度-精度权衡。实验表明,EfficientViM-M2以7%和80%的速度提升超越SHViT和MobileNetV3,精度提高0.6%。
贡献如下:
- 提出基于Mamba的轻量级架构EfficientViM,利用全局令牌混合器的线性计算成本优势;
- 设计HSM-SSD层,通过调整隐藏状态数量可控地降低SSD层开销;
- 通过最小化内存边界操作并结合多阶段隐藏状态融合,实现当前最佳速度-精度平衡。
2 Preliminaries
状态空间模型 (State Space Models, SSM)
受线性时不变 (Linear Time-Invariant, LTI) 连续系统的启发,SSM 将一个输入序列 x(t)∈R映射到一个输出序列 y(t)∈R:
![]()
其中![]() 是隐藏状态 (hidden state)
是隐藏状态 (hidden state)![]() ,
, ![]() 是投影矩阵,N是状态数量。
是投影矩阵,N是状态数量。
为了使这个连续时间系统适应深度学习中的离散数据,给定多元输入序列 x![]() (其中
(其中 ![]() ),Mamba 首先生成参数
),Mamba 首先生成参数![]() ,
,![]() ,其中
,其中 ![]() 是可学习矩阵。
是可学习矩阵。
然后,采用零阶保持离散化 (zero-order hold discretization) 的 SSM 离散化形式定义为:
![]()
其中![]() ,
,![]() 。
。![]() 。
。
在这个公式中,![]() 是一个可学习的对角矩阵,所有投影矩阵
是一个可学习的对角矩阵,所有投影矩阵![]() 实现了线性时变离散系统 (linear time-variant discrete system),可以有选择地关注每个时间戳 t 的输入 x 和隐藏状态 h。
实现了线性时变离散系统 (linear time-variant discrete system),可以有选择地关注每个时间戳 t 的输入 x 和隐藏状态 h。
状态空间对偶 (State Space Duality, SSD)
Mamba2 进一步将演化矩阵 ![]() 的对角形式简化为标量形式
的对角形式简化为标量形式 ![]() ,并通过相同的离散化步骤得到
,并通过相同的离散化步骤得到![]() 。然后,状态空间对偶将公式 (2) 重新表述为矩阵变换:
。然后,状态空间对偶将公式 (2) 重新表述为矩阵变换:
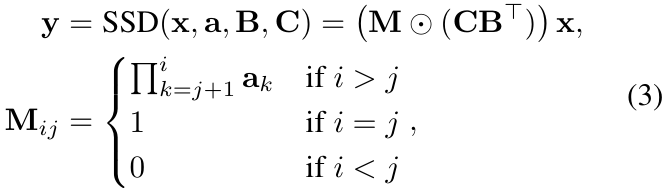
其中![]() ,⊙表示哈达玛积 (Hadamard product)(逐元素相乘)。注意,下三角矩阵 M 充当因果掩码 (causal mask),这对于图像处理来说不是最优的。
,⊙表示哈达玛积 (Hadamard product)(逐元素相乘)。注意,下三角矩阵 M 充当因果掩码 (causal mask),这对于图像处理来说不是最优的。
为了解决这个问题,非因果 SSD (Non-Causal SSD, NC-SSD) [93, 39] 被研究作为 SSD 的替代方案,其将掩码定义为![]() ,导致
,导致![]()
![]() 。
。
此外,在 VSSD [93] 中,它被简化为![]() , resulting in
, resulting in
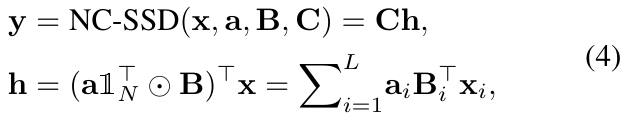
其中![]() 是用于广播 a 的全一向量。由于 a 的累积乘法会限制感受野,本文采用此版本的 NC-SSD 作为本文高效令牌混合器 (token mixer) 的起点。
是用于广播 a 的全一向量。由于 a 的累积乘法会限制感受野,本文采用此版本的 NC-SSD 作为本文高效令牌混合器 (token mixer) 的起点。
[39] Songhua Liu, Weihao Yu, Zhenxiong Tan, and Xin chao Wang. Linfusion: 1 gpu, 1 minute, 16k image. 2024
[93] Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. ICML, 2024.
3 Method
3.1 基于隐藏状态混合器的 SSD(Hidden State Mixer-based SSD)
本文首先简要讨论图 2(a) 所示的 NC-SSD 层的计算成本。NC-SSD 层的整个过程可以总结为:

其中 ![]() ,σ 是激活函数 (activation function)。公式 (5)、(6) 和 (7)(使用恒定卷积核 (kernel) 大小)的计算成本为
,σ 是激活函数 (activation function)。公式 (5)、(6) 和 (7)(使用恒定卷积核 (kernel) 大小)的计算成本为![]() 。随后,执行 NC-SSD 和输出投影分别需要
。随后,执行 NC-SSD 和输出投影分别需要![]() 和
和![]() 。
。
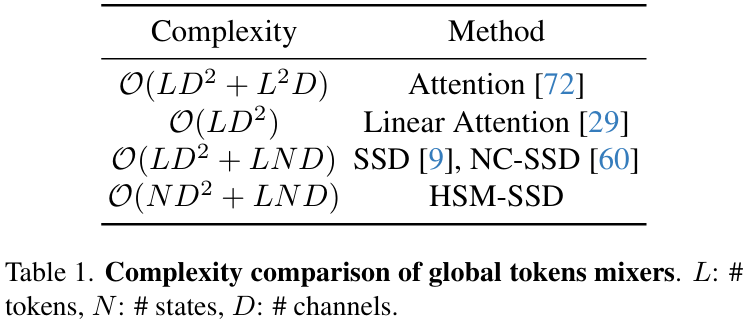
鉴于状态数 N 通常远小于通道数 D(即 N≪D),总体复杂度主要由生成 x、z 和![]() 所涉及的线性投影驱动,导致
所涉及的线性投影驱动,导致![]() 。因此,优化 SSD 块中的线性投影对于可扩展性至关重要。
。因此,优化 SSD 块中的线性投影对于可扩展性至关重要。
(a) NC-SSD layer
Figure 2:Illustration of (left) NC-SSD and (right) HSM-SSD layer. In the HSM-SSD layer, the computationally heavy projections are handled with the reduced hidden state in HSM as highlighted. Red, blue, and orange colors indicate the operation requiring the complexities of 𝒪(LD2), 𝒪(LND), and 𝒪(ND2).
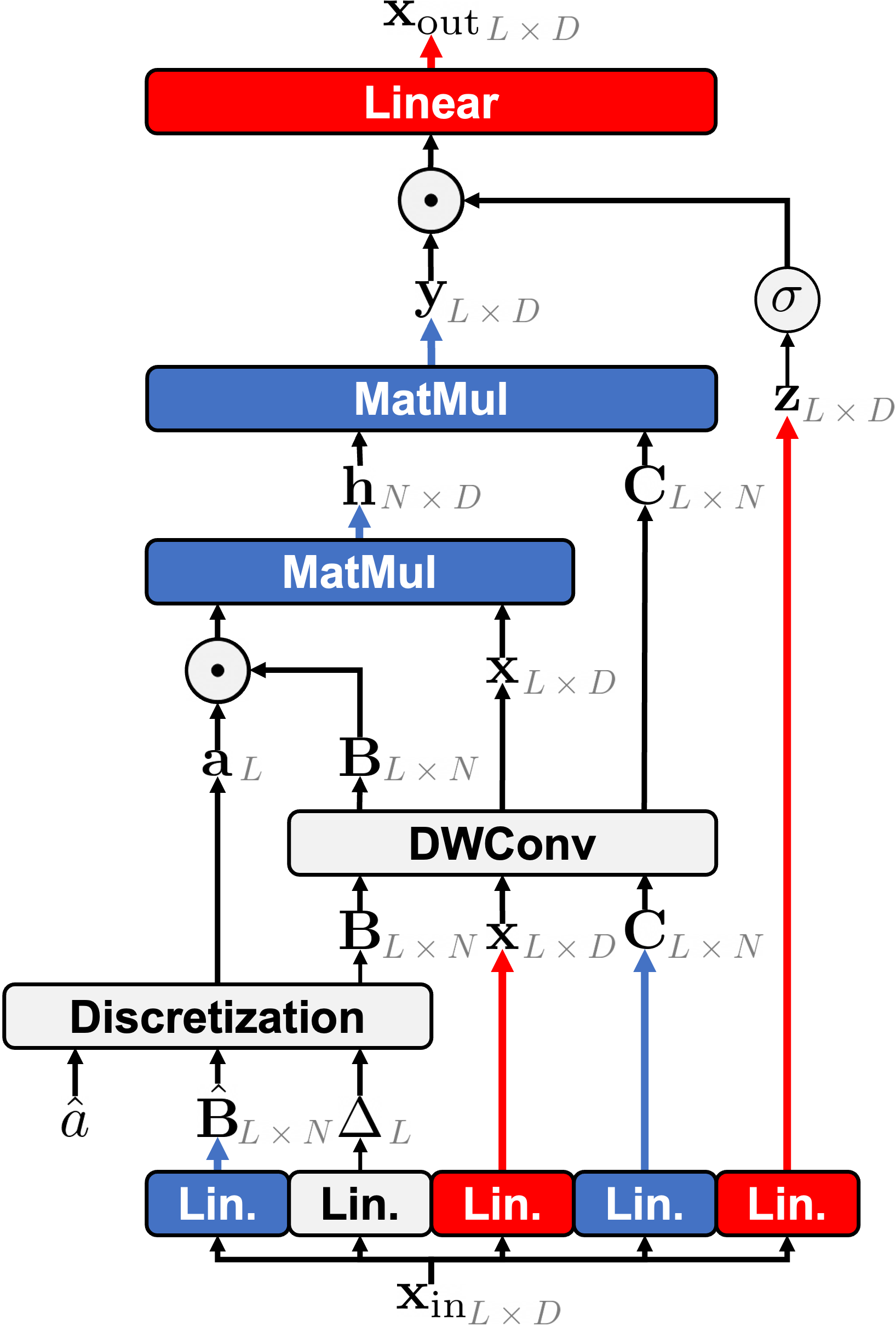
本文深入研究了优化这些计算以实现高效的层设计。NC-SSD(公式 4)可以分解为两个步骤。首先,它使用重要性权重![]() 对输入状态
对输入状态 ![]() 进行加权线性组合,获得共享的全局隐藏状态
进行加权线性组合,获得共享的全局隐藏状态![]() 。其次,每个输入的输出是通过用其对应的
。其次,每个输入的输出是通过用其对应的![]() 投影隐藏状态来生成的。这里,如果将投影后的输入 x 表示为
投影隐藏状态来生成的。这里,如果将投影后的输入 x 表示为 ![]() (移除 DWConv),则下式成立:
(移除 DWConv),则下式成立:
![]()
其中![]() ,且
,且![]() 。通过先计算
。通过先计算 ![]() ,本文执行了一个到隐藏状态空间的线性投影。这种方法将成本从
,本文执行了一个到隐藏状态空间的线性投影。这种方法将成本从![]() 降低到
降低到 ![]() ,这依赖于状态数 N。
,这依赖于状态数 N。
换句话说,可以通过调整状态数使得 N≪L 来减轻该层的主要成本。隐藏状态混合器 (Hidden State Mixer)。下一步是减轻公式 (9) 中门控和输出投影的成本,这仍然是 ![]() 。为了解决这个问题,本文专注于共享的全局隐藏状态 h。
。为了解决这个问题,本文专注于共享的全局隐藏状态 h。
注意,隐藏状态 h 本身是压缩的潜在数组,它以显著更小的序列长度 N 压缩了输入数据。基于这一观察,本文提出了一个隐藏状态混合器 (HSM),它直接在压缩的潜在数组 h 上执行通道混合(包括门控和输出投影),如图 2(b) 高亮所示。
(b) HSM-SSD layer
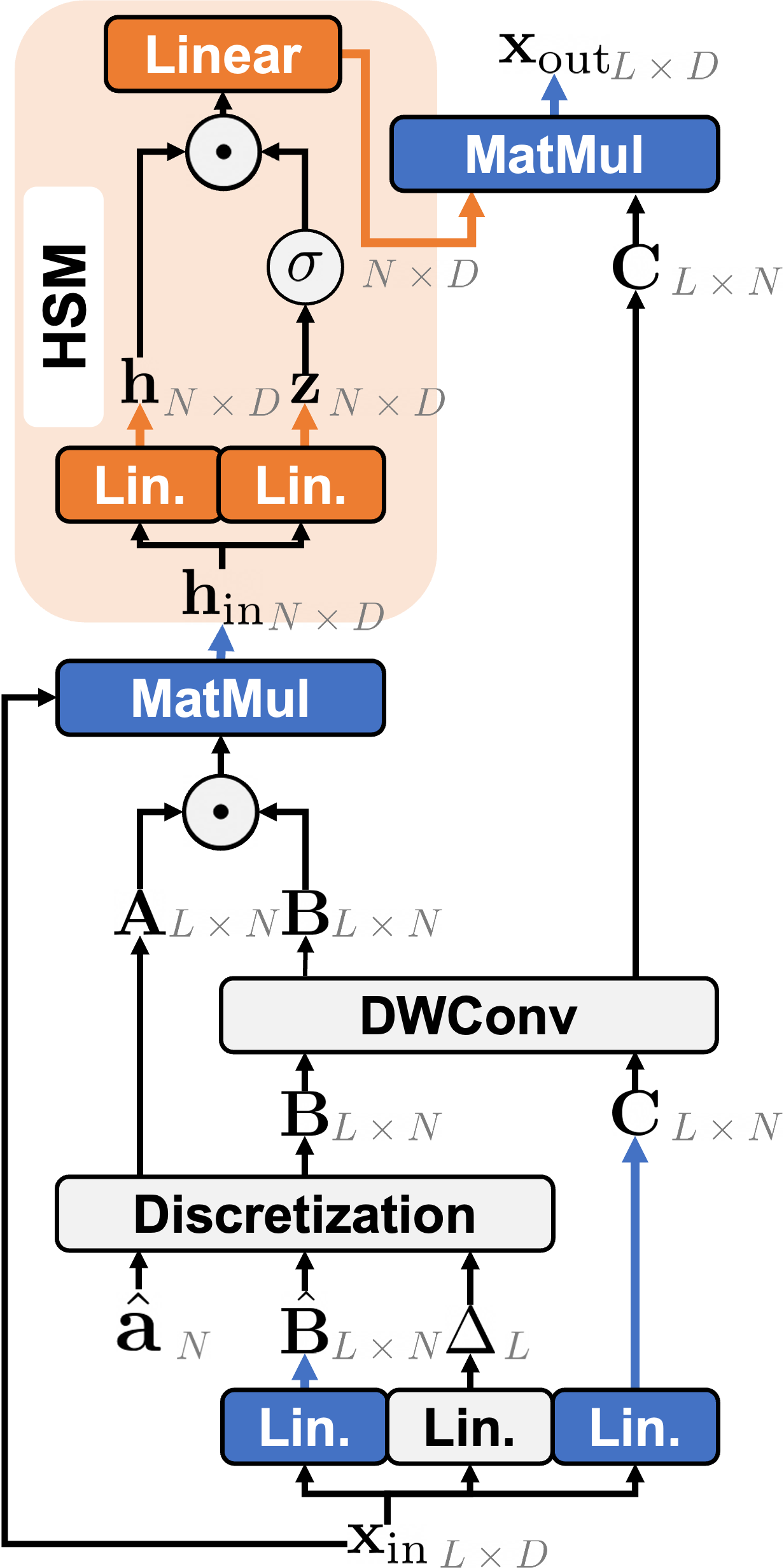
为此,本文近似 NC-SSD 层的输出如下:
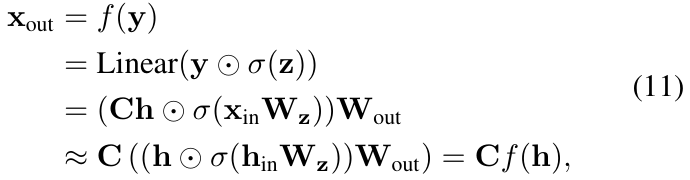
其中 y=Ch 来自公式 (4),f 表示门控函数的通道混合,后跟使用可学习矩阵 ![]() 的线性投影。与原始 NC-SSD 层(先计算 Ch 然后馈入 f)相反,本文使用 HSM 直接将门控和投影应用于隐藏状态。然后,最终输出
的线性投影。与原始 NC-SSD 层(先计算 Ch 然后馈入 f)相反,本文使用 HSM 直接将门控和投影应用于隐藏状态。然后,最终输出 ![]() 通过用 C 投影更新后的隐藏状态来生成。因此,在 HSM-SSD 层中捕获全局上下文的总体复杂度变为
通过用 C 投影更新后的隐藏状态来生成。因此,在 HSM-SSD 层中捕获全局上下文的总体复杂度变为![]() ,随着 NN 变小,这部分成本可以忽略不计。请参阅表 1,了解与先前全局令牌混合器的大 O 复杂度比较。
,随着 NN 变小,这部分成本可以忽略不计。请参阅表 1,了解与先前全局令牌混合器的大 O 复杂度比较。
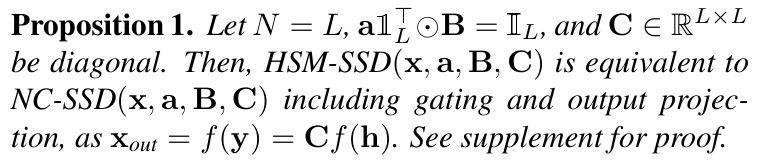
Remark 1.
虽然本文利用门控和线性投影来实现 HSM,以模拟原始 SSD 层中的操作,但其他方法也是可用的。例如,受 Perceiver 架构 [28] 的启发,本文可以为公式 (11) 中的函数 f 实现一个全局令牌混合器,使用一组减少的潜在变量来高效处理高维输入。此外,HSM-SSD 可以递归地将 HSM-SSD 自身作为隐藏状态混合器应用,进一步降低计算复杂度并形成跨深度展开的循环架构。
[28] Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. In International confer ence on machine learning, 2021.
3.2 HSM-SSD layer
多阶段隐藏状态融合 (Multi-stage hidden state fusion)。为了进一步提高 EfficientViM 的性能,本文引入了一种多阶段隐藏状态融合 (MSF) 机制,它利用来自网络多个阶段的隐藏状态来融合预测 logits。令![]() 表示每个阶段 s 最后一个块处的隐藏状态,其中 S 是总阶段数。对于每个
表示每个阶段 s 最后一个块处的隐藏状态,其中 S 是总阶段数。对于每个 ![]() ,本文通过对隐藏状态进行简单平均来计算一个全局表示
,本文通过对隐藏状态进行简单平均来计算一个全局表示 ![]() :
:
![]()
然后,每个全局表示![]() 被归一化并投影以生成其对应的 logits
被归一化并投影以生成其对应的 logits ![]()
![]() ,其中 c 表示类别数。本文将 EfficientViM 的最终 logit z 设置为所有阶段的 logits 的加权和,包括从最后阶段输出获得的原始 logit
,其中 c 表示类别数。本文将 EfficientViM 的最终 logit z 设置为所有阶段的 logits 的加权和,包括从最后阶段输出获得的原始 logit ![]() ,其定义为:
,其定义为:
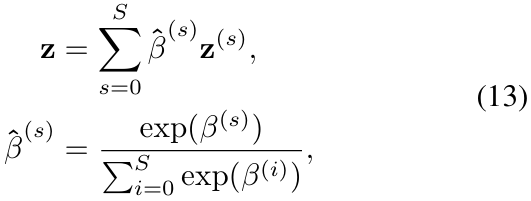
其中 ![]() 是可学习的标量。通过使用这个组合的 logit 进行训练,本文显式地增强了隐藏状态的表示能力,因为它们对最终预测做出了贡献。它还通过整合低层级和高层级特征来丰富信息,从而在推理时增强模型的泛化能力。
是可学习的标量。通过使用这个组合的 logit 进行训练,本文显式地增强了隐藏状态的表示能力,因为它们对最终预测做出了贡献。它还通过整合低层级和高层级特征来丰富信息,从而在推理时增强模型的泛化能力。
Figure 4:(left) Overall architecture and (right) block design of EfficientViM. The dotted line indicates a skip connection for multi-stage hidden state fusion (MSF). Illustration of the HSM-SSD layer in the EfficientViM block is presented in Figure 2.
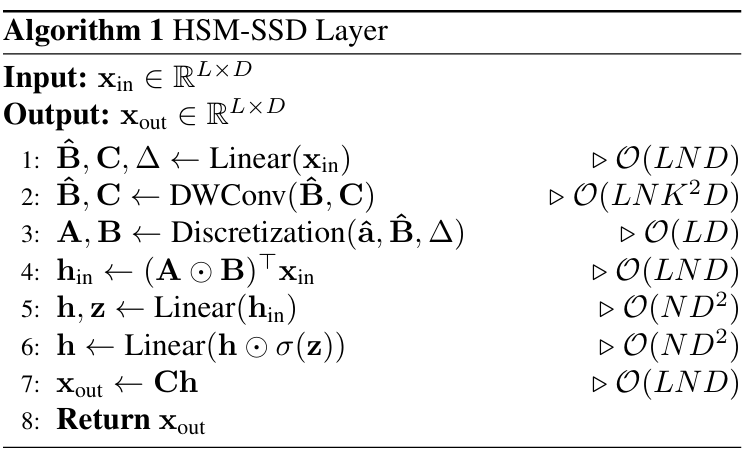
单头 HSM-SSD (Single-head HSM-SSD)。注意力机制中的多头 (multi-head) 设计允许其在每个头内选择性地关注来自独立表示子空间的特征。基于 SSD 的模型通常采用一种称为多输入 SSD (multi-input SSD) 的多头变体,其中输入 x 和 a 是为每个头定义的,而 B 和 C 在头之间共享。然而,最近的工作 [84] 指出,多头自注意力中的大部分实际运行时是由内存边界操作驱动的。
[84] Seokju Yun and Youngmin Ro. Shvit: Single-head vision transformer with memory efficient macro design. In CVPR, 2024.
Figure 3:Runtime breakdown of HSM-SSD with EfficientViM-M2. The operations highlighted in red are memory-bound.
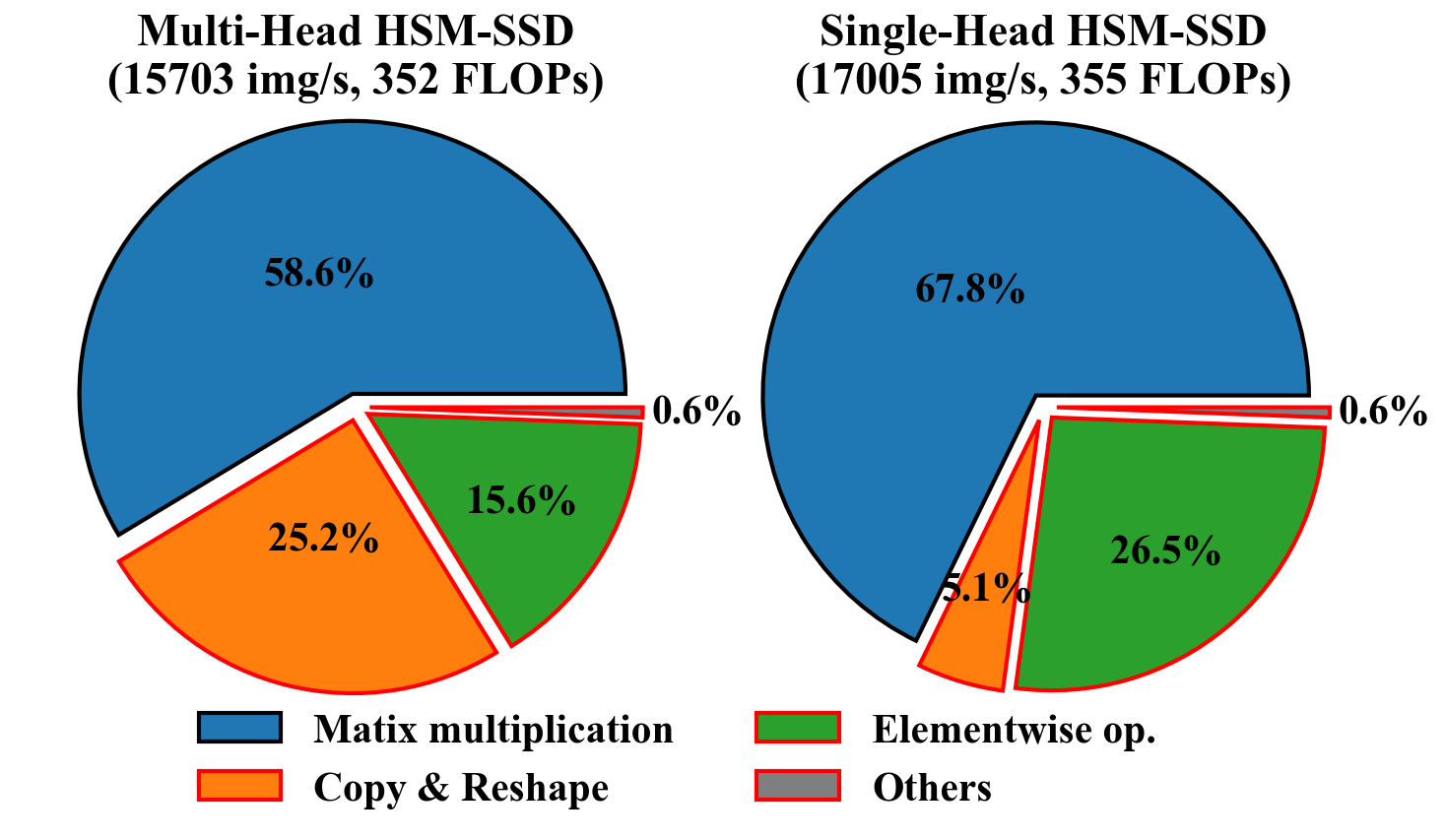
在本文的初步实验中,本文还发现多头配置已成为 HSM-SSD 的瓶颈,如图 3 总结所示。如图所示,多头 HSM-SSD 的实际运行时很大程度上受内存访问的限制,几乎占总运行时的四分之一。因此,本文消除了由多头引起的所有张量操作(例如,重塑 、复制操作)。同时,为了模拟多头捕获多样化关系的能力,本文设置![]() ,使得重要性权重
,使得重要性权重![]() 能够估计每个状态上令牌的重要性。然后,隐藏状态混合器的输入变为
能够估计每个状态上令牌的重要性。然后,隐藏状态混合器的输入变为
![]()
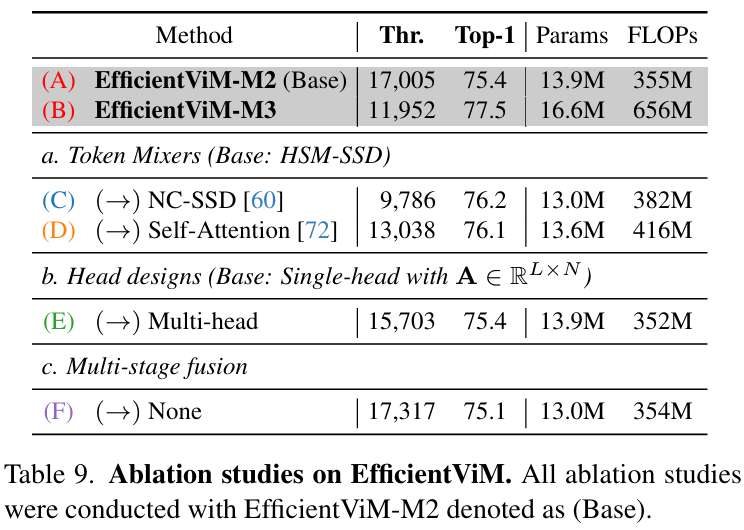
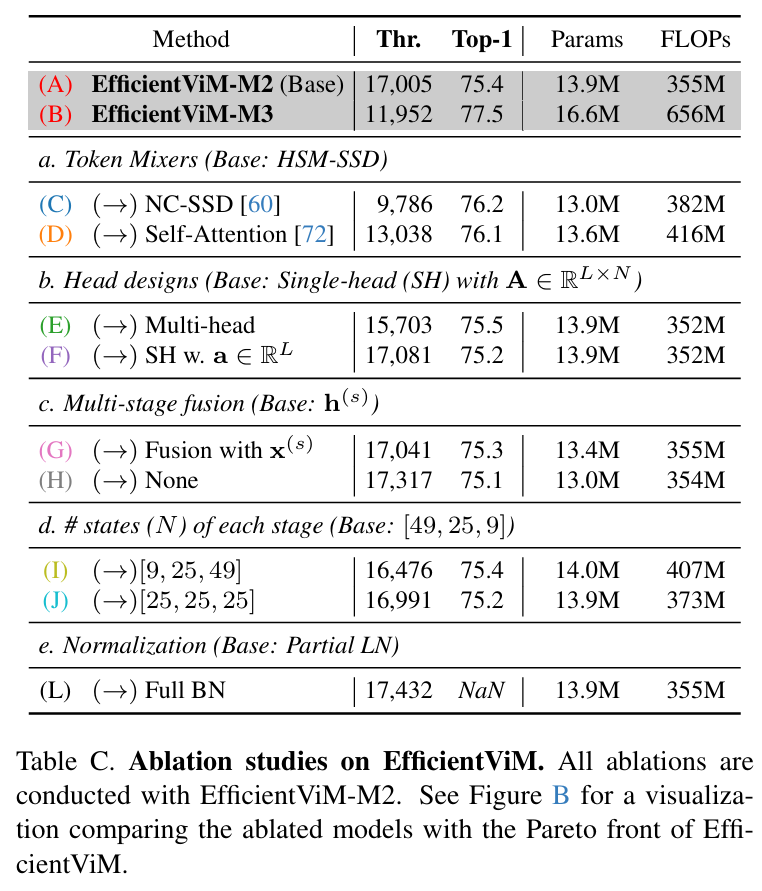
结果,本文的具有状态级重要性权重 (state-wise importance weights) 的单头 HSM-SSD 在相似 FLOPs 下,与多头相比实现了更高的吞吐量 (throughput)(17,005 img/s vs 15,703 img/s)以及具有竞争力的性能(见表 9.b)。单头 HSM-SSD 层的伪代码在算法 1 中提供。
3.3 EfficientViM
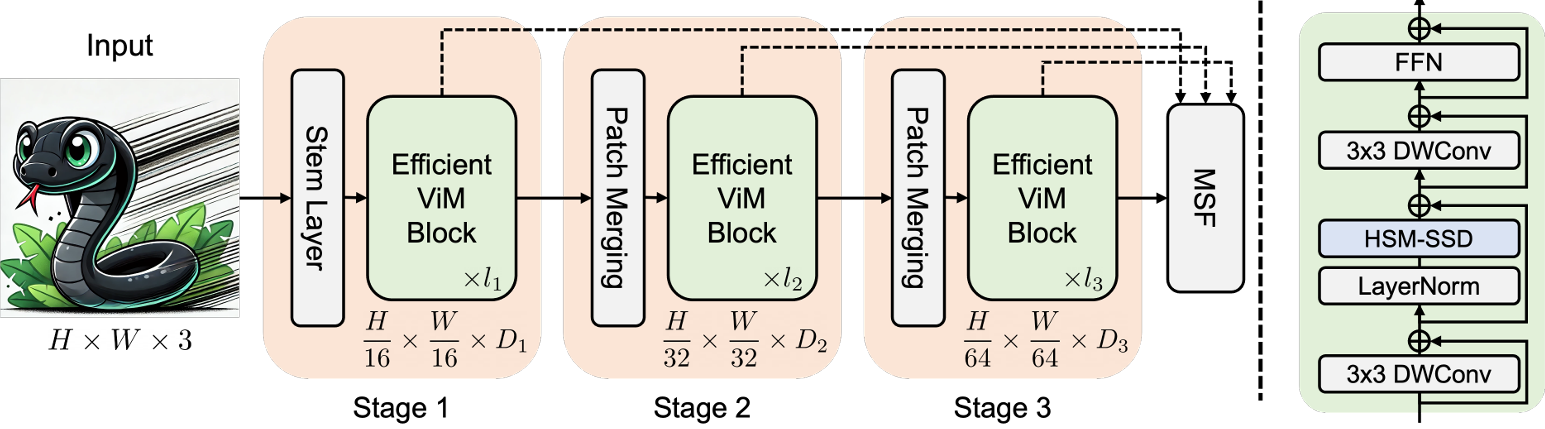
在本小节中,本文介绍 EfficientViM,一个基于 HSM-SSD 层构建的高效视觉 Mamba。整体架构如图 4 所示。
块设计 (Block design)
在 EfficientViM 的每个块中,本文依次堆叠 HSM-SSD 层和一个前馈网络 (FFN),分别促进全局信息聚合和通道交互。FFN 层由两个连续的 1×1 卷积层称为逐点卷积组成,扩展比 (expansion ratio) 为 4。
为了以最小的计算成本捕获局部上下文,本文在 NC-SSD 和 FFN 层之前都加入了一个 3×3 深度wise卷积 (DWConv) 层。每个层都使用残差连接 并结合了层缩放 (layer scale) 。
对于归一化,本文仅在 HSM-SSD 层之前应用层归一化 (LN) 以保持数值稳定性,而在 DWConv 和 FFN 中使用批归一化 (BN),考虑到其速度比 LN 更快。
整体架构 (Overall architecture)
Stem layer 首先通过四个连续的步长为 2 的 3×3 卷积层,将 H×W×3 的输入图像映射到下采样后的特征图![]() 。
。
然后,将得到的特征图馈入由 EfficientViM 块构建的三个阶段。为了实现分层架构 (hierarchical architecture) 并提高效率,本文在每个阶段结束时通过从 [57] 采用的下采样层 来下采样特征图同时增加通道数。
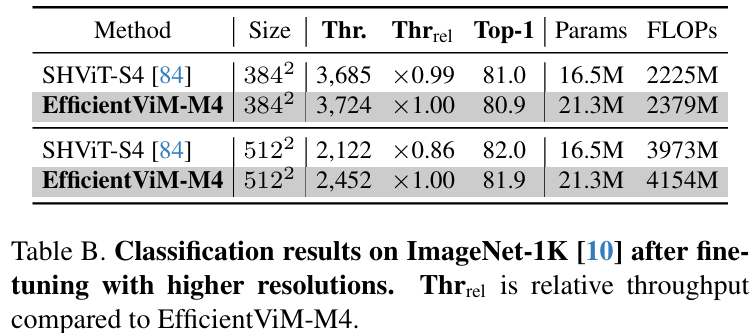
关于激活函数 (activation functions),本文仅在 HSM-SSD 层中使用 SiLU,其他层使用 ReLU,因为复杂激活函数(例如 GELU, DynamicReLU等)的延迟 (latencies) 很大程度上取决于设备。EfficientViM 变体的详细架构规格见表 2。
[57] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zh moginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR, 2018.
| Model | # Blocks | # Channels | # States |
|---|---|---|---|
| EfficientViM-M1 | [2,2,2] | [128,192,320] | [49,25,9] |
| EfficientViM-M2 | [2,2,2] | [128,256,512] | [49,25,9] |
| EfficientViM-M3 | [2,2,2] | [224,320,512] | [49,25,9] |
| EfficientViM-M4 | [3,4,2] | [224,320,512] | [64,32,16] |
Table 2:Specification of EfficientViM variants.
4. Experiment
seting
Results