引言:从“读懂”到“理解”——探索语义分析的深度
当计算机处理“苹果公司发布了新款手机”这句话时,它能轻易“读懂”其字面含义:一个名为“苹果公司”的实体,执行了“发布”动作,对象是“新款手机”。然而,人类的“理解”远不止于此。我们会联想到其对手机市场格局的冲击、潜在的技术革新、激烈的商业竞争,甚至是我们自己是否需要更换手机的决策。这种从“读懂”到“理解”的鸿沟,正是自然语言处理(NLP)领域中“浅层语义”与“深层语义”的核心差异所在。
本文的核心议题,便是系统性地剖析NLP中浅层与深层语义特征的区别与联系。我们将特别关注语义角色标注(Semantic Role Labeling, SRL)在这一体系中所扮演的关键桥梁作用。文章将遵循一条清晰的分析路径:首先,从理论框架上为两种语义层次进行界定;其次,对比分析提取它们的技术实现与应用场景的差异;最后,探讨它们如何通过预训练语言模型(PLMs)与知识图谱(Knowledge Graphs, KGs)等现代技术融会贯通,共同构建一个完整的语义理解层次。
本文旨在为NLP领域的初学者、研究者和从业人员提供一个清晰的理论与技术图谱,帮助其更深刻地把握不同层次语义分析技术的本质,从而在研究与实践中做出更精准的选择与应用。
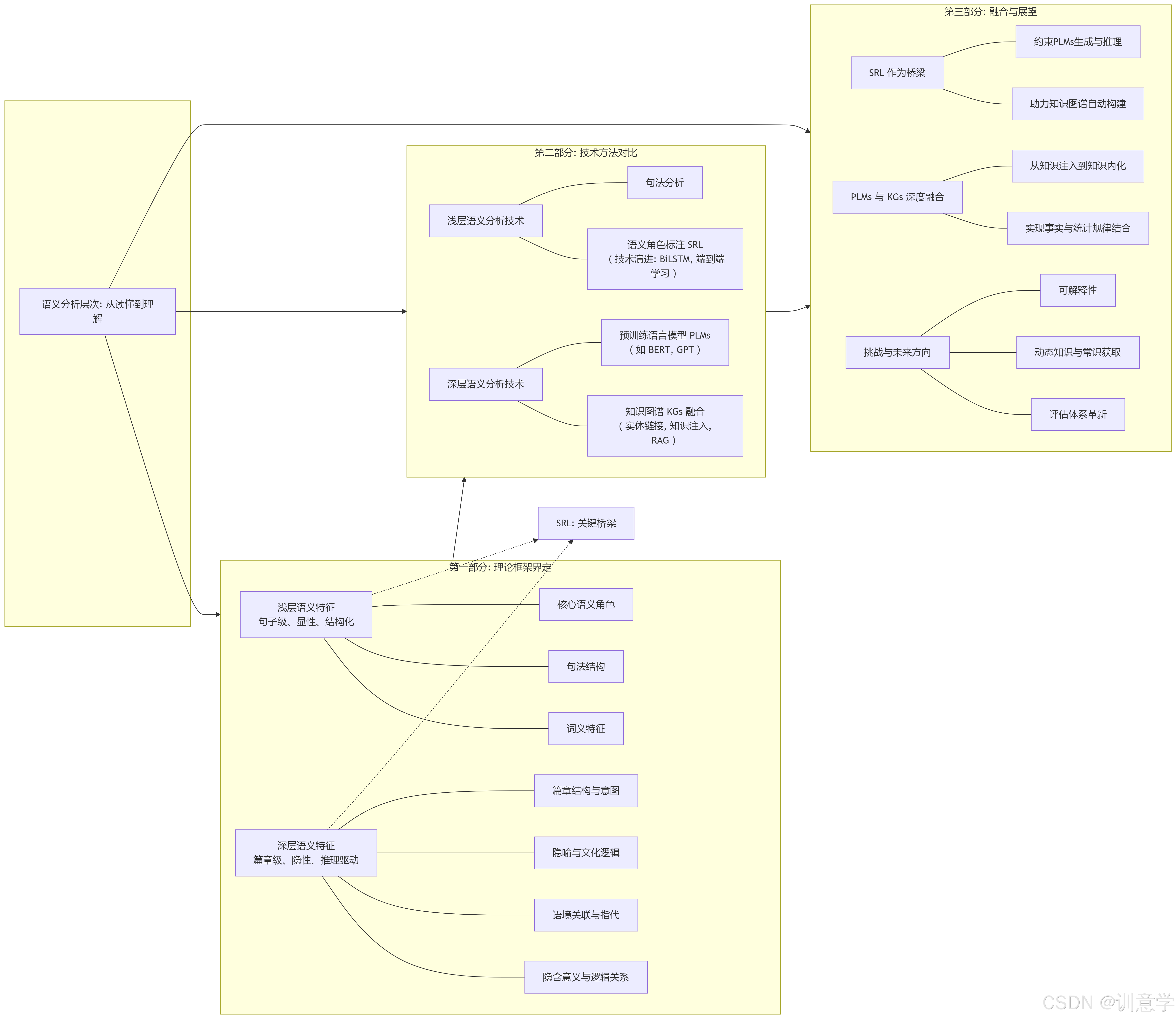
第一部分:语义特征的层次划分:理论框架与界定
为了精确探讨语义特征,我们必须首先为其建立清晰的理论定义。语言学的发展为我们提供了坚实的基础,从关注句子内部形式的结构主义,到探索语境、意图和认知过程的语用学与认知语言学,这些理论共同启发了NLP中对语义层次的划分。
1.1 浅层语义特征(Surface Semantics)的界定
浅层语义特征可以被定义为文本内部显性、结构化的语义信息。它的提取主要依赖于句子本身的词汇和语法结构,较少或完全不依赖外部世界知识。其核心是回答“一句话里,谁对谁做了什么”。浅层语义分析的目标是捕捉句子级的、明确的语义关系,为更复杂的推理提供基础素材。
根据参考资料,浅层语义的构成要素主要包括:
- 词义特征: 这是语义的基本单元,包括词语的核心概念意义(如“书”是“装订成册的著作”),以及附加的感情、语体和形象色彩(如“团结”与“勾结”的褒贬之分)。
- 句法结构: 句子的组织方式,如中文常见的“主语-谓语-宾语”(SVO)结构,为理解基本语义关系提供了骨架。
- 核心语义角色: 这是浅层语义分析的重点,旨在识别出动作的直接参与者,如施事者(Agent)、受事者(Patient)和工具(Instrument)等。
特点总结: 浅层语义具有句子级、显性、结构化、上下文依赖较弱的特点。它关注的是“文本说了什么”,而非“文本意味着什么”。
1.2 深层语义特征(Deep Semantics)的界定
与浅层语义相对,深层语义特征被定义为超越字面意义的、依赖语境、常识和外部知识的隐性语义信息。它致力于揭示文本背后的逻辑、意图和隐含的知识网络。深层语义分析需要回答“为什么会这样”以及“这意味着什么”等更复杂的问题。
其构成要素更为丰富和抽象,相关研究将其归纳为:
- 隐含意义与逻辑关系: 识别跨越句子边界的因果、条件、转折等关系。例如,在“因为暴雨,比赛取消了”中,深层语义分析需要明确“暴雨”与“比赛取消”之间的因果链。
- 语境关联与指代: 这包括根据上下文确定代词的指代对象(如“她去看电影了”中的“她”是谁),以及消除多义词的歧义(如“苹果”在不同语境下指代水果还是公司)。
- 隐喻与文化逻辑: 理解非字面表达,如“经济寒冬”中的隐喻,或“喜鹊”在中国文化中象征喜庆的特定含义。这需要模型具备一定的文化背景知识。如ConceptNet等知识库就在致力于提供这类外部信息以增强语言理解 。
- 篇章结构与意图: 分析整个段落或篇章的论证结构(如“问题-解决方案”模式),并推断作者的言外之意,如讽刺、暗示等。
特点总结: 深层语义具有跨句子/篇章级、隐性、推理驱动、强依赖上下文与外部知识的特点。它探索的是语言背后复杂的认知与逻辑世界。
第二部分:技术分野:不同层次语义特征的提取方法对比
对不同层次语义的追求,催生了截然不同的技术路线。从早期的规则和统计方法,到如今由深度学习主导的时代,技术的发展深刻地反映了我们对语义理解深度的不断探索。
2.1 浅层语义分析技术栈
浅层语义分析技术成熟较早,其目标是构建精确、结构化的句子级语义表示。
句法分析(Syntactic Parsing)
句法分析是所有语义分析的基石。它通过生成成分句法树或依存关系图,揭示句子的语法结构。虽然其直接目标是语法而非语义,但它提供的句子骨架是后续识别语义角色的重要依据。语义角色标注(Semantic Role Labeling, SRL)
SRL可以被视为浅层语义分析的核心与巅峰,它完美地连接了句法结构与初步的语义理解。SRL的核心任务是围绕句子中的谓词(通常是动词),识别出其对应的语义角色。例如,在句子“小明用刀切苹果”中,SRL系统会以“切”为中心,标注出:- 施事者 (Agent): 小明
- 受事者 (Patient): 苹果
- 工具 (Instrument): 刀
这一过程主要依赖于如 PropBank(基于动词的论元库)或 FrameNet(基于框架的语义库)等理论框架 。技术实现上,SRL经历了显著的演进。早期的SRL模型多采用基于特征工程的统计方法,后来发展为使用深度学习模型。
深度学习模型,特别是 深度双向长短期记忆网络(BiLSTM) ,极大地推动了SRL的发展 。这类模型通过结合BiLSTM架构、约束解码、正交初始化和RNN-dropout等最佳实践,在CoNLL-2005和CoNLL-2012等权威基准数据集上取得了显著的性能提升,F1分数一度达到83.4% 。后续的研究进一步引入了注意力机制和自注意力机制,例如DEEPATT模型,在相同的基准上实现了当时最先进的性能 。
一个重要的趋势是端到端(End-to-End)学习的兴起,这些模型可以直接从原始文本中预测语义角色,而无需依赖于独立的句法分析步骤,简化了处理流程 。此外,为了应对标注数据稀缺的问题,研究人员还探索了半监督学习方法,例如利用未标注数据和语法不一致性损失来提升模型在低资源场景下的性能 。
2.2 深层语义分析技术栈
深层语义分析则更多地依赖于能够处理复杂上下文和外部知识的现代技术。
- 预训练语言模型(PLMs)的主导作用
BERT 、GPT 等基于Transformer架构 的预训练语言模型的出现,是深层语义分析领域的革命。其核心在于 自注意力机制(Self-Attention) ,该机制使得模型能够动态地权衡句子中所有词语之间的关系,从而捕捉长距离依赖和复杂的上下文信息。这与过去静态的词向量(如Word2Vec)有本质区别。
PLMs通过在大规模无标注文本上进行预训练,实现了逐层抽象的特征学习。研究表明,模型的底层网络倾向于学习词法和句法等浅层特征,而高层网络则能形成更丰富的上下文语义表示 。这种内在的层次性使得PLMs在处理需要深度推理的任务时表现卓越,例如自然语言推理(NLI)、机器阅读理解(MRC)和常识推理 。评估这些模型深层语义能力通常依赖于综合性基准,如GLUE CLUE (中文)以及更具挑战性的对抗性基准AdvGLUE 。
- 知识图谱(KG)与外部知识的融合
尽管PLMs能力强大,但它们本质上是从文本数据中学习统计规律,缺乏真实世界的“事实性”知识,容易产生“幻觉”(Hallucination)。为了解决这一问题,将PLMs与知识图谱融合成为关键。知识图谱是一个结构化的知识库,包含了实体、属性及其之间的关系 。
截至2025年,这一领域的融合技术已成为研究热点,并形成了一条清晰的发展路线图 。主要的融合技术包括:
- 实体链接(Entity Linking): 将文本中提及的实体(如“乔丹”)准确地链接到知识图谱中对应的节点(是篮球运动员迈克尔·乔丹,还是科学家迈克尔·I·乔丹)。
2. 知识注入模型(Knowledge-Enhanced Models): 如百度的ERNIE 2.0 、清华的K-BERT等模型,在预训练阶段就将知识图谱中的三元组信息融入模型,使其直接学习知识。KEPLER模型则尝试统一知识嵌入和预训练语言表示的学习过程 。
3. 检索增强生成(Retrieval-Augmented Generation, RAG): 在生成文本时,模型会先从知识图谱或外部文档库中检索相关信息,然后将这些信息作为上下文来指导生成,以提高内容的准确性和事实性。
知识图谱的引入,极大地增强了模型的深层语义推理能力,例如进行常识推理、消除歧义和补全文本中隐含的信息 。已有研究表明,这种融合在生物医学等专业领域取得了显著成效,例如BioLORD-2023模型就成功融合了大型语言模型和临床知识图谱 。
2.3 技术对比总结
下表清晰地总结了两种技术路线的核心差异:
| 特征 | 浅层语义分析技术 | 深层语义分析技术 |
|---|---|---|
| 核心任务 | 识别句子内部的谓词-论元结构(谁对谁做了什么) | 推理文本的隐含逻辑、意图和背景知识 |
| 主要技术 | 句法分析, 语义角色标注 (SRL) | 预训练语言模型 (PLMs), 知识图谱 (KGs) |
| 数据依赖 | 依赖标注语料库 (如PropBank, FrameNet) | 依赖大规模无标注文本和结构化知识库 |
| 处理范围 | 主要在句子级别 (Intra-sentential) | 跨句子、篇章,乃至外部知识 (Inter-sentential) |
| 输出形式 | 结构化的标签或图(如语义角色、依存关系) | 密集的上下文向量、文本生成、逻辑判断 |
| 知识来源 | 主要来自文本自身(词汇、语法) | 来自海量文本的统计规律和外部知识库 |
| 能力上限 | 难以处理歧义、隐喻和复杂推理 | 能够处理上下文相关的复杂语义,但存在事实性问题 |
第三部分:融合与展望:构建完整的语义理解层次
浅层与深层语义分析并非孤立的技术路径,而是构建一个完整语义理解系统的不同层次。进入2025年,我们观察到最前沿的研究正致力于将二者进行深度融合,以期实现优势互补,迈向真正的语言“理解”。
3.1 SRL作为桥梁:从结构化语义到上下文表示
SRL提供的显式、结构化的“谓词-论元”信息,可以作为一种重要的中间表示,为深层语义分析提供坚实的语义骨架。其桥梁作用体现在:
- 约束PLMs的生成与推理: PLMs虽然强大,但其内部表示是隐性的(dense vectors),有时会违背基本的语义逻辑。SRL的输出可以作为一种符号约束,引导PLM生成更符合事实和逻辑的文本。例如,在问答系统中,SRL可以帮助模型精准定位答案的关键参与者。
- 知识图谱的自动构建: SRL能够高效地从非结构化文本中抽取出(主语,谓词,宾语)这样的事实三元组,这是自动化构建和扩充知识图谱的关键技术。PLMs可以提升SRL的准确性,而SRL则为PLMs提供可以推理的结构化知识源。
3.2 PLMs与KGs的深度融合:从统计规律到事实推理
PLMs与KGs的融合是当前实现深层语义理解最核心的路径。这一融合正从“浅层拼接”走向“深度一体化”。2024至2025年的研究趋势显示 研究者不再满足于简单地将知识图谱信息作为额外输入,而是探索更深层次的协同机制。例如,有研究探讨大型语言模型如何在不同网络层级获取和处理概念知识 这标志着我们正从外部“知识注入”转向内部“知识内化”的研究。这种融合使得模型能够从海量文本中学习到的统计规律(知道“鸟会飞”是常见的搭配)与知识图谱中存储的客观事实(“企鹅是鸟,但不会飞”)相结合,从而实现更鲁棒的、基于事实的推理。
3.3 挑战与未来方向:对“真正理解”的持续探索
尽管进展显著,通往机器“真正理解”语言的道路依然充满挑战。
可解释性(Interpretability): 当前的PLMs和融合模型仍是“黑箱”。我们迫切需要更先进的可解释性技术来剖析模型的决策过程。目前,研究人员主要通过输入显著性分析、隐藏状态探查和神经元激活等方法来解释模型 并通过专门的可解释性评估基准来衡量解释的合理性(Plausibility)和忠实度(Faithfulness)。然而,这些方法大多停留在相关性分析,未来的突破在于建立因果层面的解释框架 。
动态知识与常识的获取: 知识图谱通常是静态的,难以跟上世界的快速变化。如何让模型持续学习新知识,并有效处理那些难以被结构化的常识知识,是一个巨大的挑战。大型语言模型的持续学习和知识“遗忘”机制已成为2025年的一个前沿课题 。
评估体系的革新: 随着模型能力的增强,许多标准基准(如GLUE)逐渐饱和。未来的评估需要更加关注模型的鲁棒性、常识推理、因果推断和对复杂社会文化背景的理解能力。新的评估范式,如对模型训练早期的能力进行评估(如NeurIPS 2025竞赛所示 ,以及更全面的评估框架正在被积极探索 以更准确地衡量模型的“深度语义理解”水平。
结论
从浅层语义的结构化分析到深层语义的推理理解,自然语言处理正在经历一场深刻的范式革命。语义角色标注(SRL)作为连接句法与语义的经典任务,为机器提供了理解句子核心语义的结构化框架。而预训练语言模型(PLMs)与知识图谱(KGs)的深度融合,则为机器赋予了联系上下文、运用外部知识进行复杂推理的能力。
截至2025年,我们看到一个清晰的趋势:单一技术的时代已经过去,一个融合符号知识与神经表示、结合浅层结构与深层推理的综合性语义理解框架正在形成。未来的研究将继续在可解释性、知识动态性以及评估科学性等核心挑战上寻求突破,最终弥合机器“读懂”文本与人类“理解”世界之间的鸿沟。