文章目录
数据挖掘,到底是在挖掘什么?一文带你看透数据背后的价值
一、前言
当今世界正处于“数据爆炸”的时代:电商交易、社交网络、物联网传感器、医疗影像……几乎一切都在源源不断地产生数据。
问题是:
- 数据量越来越大,但大多数还是“沉睡”的原始记录;
- 企业和个人真正能从中提炼出的价值,却往往很有限。
于是,数据挖掘(Data Mining)应运而生。它就像一台“数据金矿的采掘机”,帮助我们从海量的原始数据中抽取模式、发现规律、生成知识,最终指导决策与行动。
很多初学者都会问:数据挖掘到底在挖什么? 下面我们就来系统梳理一下。

二、数据挖掘的对象:挖“石头”
在真正得到“黄金”之前,我们要清楚,数据挖掘面对的原料是什么。
结构化数据
- 来源:数据库、数据仓库
- 形式:表格型(行与列)
- 示例:银行交易记录、销售流水
半结构化数据
- 来源:日志、传感器流、图数据
- 形式:有部分标签或约定格式
- 示例:XML 文件、社交网络关系图
非结构化数据
- 来源:现实世界
- 形式:文本、图像、音频、视频
- 示例:新闻评论、医疗影像、语音助手数据
复杂类型数据
- 生物序列(DNA、蛋白质结构)
- 时空数据(轨迹、地理信息)
- 流数据(实时金融行情、网络流量监控)
总结一句话:数据挖掘处理的原材料,既包括“规整的表格”,也涵盖“碎片化的多媒体信息”。
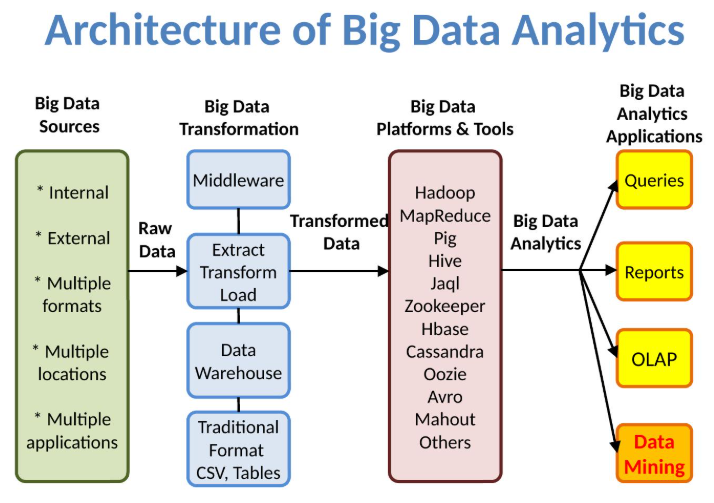
三、数据挖掘的成果:挖“黄金”
真正的价值在于从数据中“挖”出知识和规律,常见的挖掘成果包括:
1. 多维分析(OLAP 与数据立方体)
通过“切片”“钻取”等方式,让管理者快速查看不同维度的数据。
👉 案例:电商可以按“时间 × 地区 × 商品”多维度分析销量。
2. 频繁模式与关联规则
揭示项目之间的共现关系。
👉 经典案例:“啤酒和尿布”经常被一起购买,用于超市商品摆放。
3. 分类与回归
- 分类:预测类别,例如垃圾邮件识别。
- 回归:预测数值,例如预测房价。
4. 聚类
无监督学习,把“相似”的数据分到一组。
👉 案例:银行根据客户行为自动分群,用于精准营销。
5. 异常检测
发现“不合群”的数据点。
👉 案例:信用卡交易中检测欺诈。
6. 深度学习与图挖掘
- 图像识别、自然语言处理(NLP)
- 社交网络影响力传播分析
四、数据挖掘的过程:如何“炼金”
数据挖掘并不是直接套一个模型,而是一个系统化的流程,通常被称为 KDD(Knowledge Discovery in Databases,数据库中的知识发现)。
流程图示意(简化版):
数据源 → 数据清洗 → 数据集成 → 数据选择 → 数据转换 → 数据挖掘 → 模式评估 → 知识展示
关键步骤说明:
- 数据预处理:清洗脏数据、整合多源数据、转换格式。
- 数据挖掘:应用算法(分类、聚类、关联分析等)。
- 模式评估与表示:判断结果是否有意义,避免“垃圾模式”。
可以把它类比成“炼金术”:
- 原料:原始数据
- 炼金:挖掘算法
- 成品:可解释、可应用的知识
五、数据挖掘的应用场景
数据挖掘并不是学术实验室里的“象牙塔”,它已经渗透到各行各业:
- 电商推荐:个性化推荐、商品搭配
- 金融风控:信用评估、欺诈检测
- 医疗健康:疾病预测、药物研发
- 智慧城市:交通预测、能耗优化
- 社交媒体:用户画像、热点发现
一句话:哪里有数据,哪里就有数据挖掘的用武之地。
六、学习数据挖掘的建议
如果你是初学者,可以参考以下路径:
理论基础
- 《数据挖掘:概念与技术》(Jiawei Han)
- 《统计学习方法》(李航)
工具与框架
- Python(pandas、scikit-learn、PyTorch、TensorFlow)
- SQL(基础数据操作必备)
实践项目
- Kaggle 数据竞赛
- 商业案例模拟(电商推荐、金融风控)
进阶方向
- 大数据挖掘(Hadoop、Spark)
- 深度学习应用
总的来说
回到最初的问题:数据挖掘,到底在挖掘什么?
答案是:
- 挖掘的对象:海量的结构化、半结构化、非结构化数据;
- 挖掘的成果:模式、规律、知识和预测模型;
- 挖掘的过程:从数据预处理到知识发现的一整套流程。
最终目的只有一个:让数据能“说话”,为决策提供支撑,让人和组织更聪明。
- 挖掘的对象:各种数据,包括结构化(数据库表格)、半结构化(日志、图数据)、非结构化(文本、图像、视频)以及复杂类型(时空、流数据、生物序列)。
- 挖掘的成果:模式、规律与知识,如多维分析、频繁模式、分类回归、聚类、异常检测,以及深度学习与图挖掘等前沿方法。
- 挖掘的过程:数据清洗 → 集成 → 转换 → 挖掘 → 模式评估 → 知识表示,形成完整的 KDD(知识发现)流程。
- 应用场景:电商推荐、金融风控、医疗健康、智慧城市、社交媒体等几乎所有与数据相关的领域。
📌 一句话总结:
数据挖掘不是在“挖数据”,而是在数据中发现模式和知识,让数据真正服务于决策和价值创造。
《数据挖掘:概念与技术 原书第4版》好书推荐
本书是介绍数据挖掘的经典书籍之一,将挖掘理论系统化整理,搭建起理论框架,涵盖了该领域的核心内容,有足够的广度和深度。本书首先介绍了数据挖掘的概念,阐述了数据预处理、数据表征以及数据仓储的方法。然后,将数据挖掘方法分为几个主要任务,介绍了挖掘频繁模式、关联和大数据集的相关性的概念和方法,数据分类和模型构建,聚类分析,离群点检测。接着系统地介绍了深度学习的概念和方法。最后,本书涵盖了数据挖掘的趋势、应用和研究前沿。本书适合作为计算机科学、统计学、商业和数据科学等专业学生的数据挖掘教材,也适合作为应用开发者、商业专业人士和研究数据挖掘概念和原理的研究者的参考书。

韩家炜(Jiawei Han)是伊利诺伊大学厄巴纳–香槟分校计算机科学系Michael Aiken讲席教授。他因在知识发现和数据挖掘研究方面的贡献获得了无数奖项,包括ACM SIGKDD创新奖(2004年)、IEEE计算机学会技术成就奖(2005年)和IEEE W. Wallace McDowell奖(2009年)。他是ACM会士和IEEE会士,曾担任ACM Transactions on Knowledge Discovery from Data(2006—2011)创始主编,并担任多种期刊的编委会成员,包括IEEE Transactions on Knowledge and Data Engineering和Data Mining and Knowledge Discovery。
裴健(Jian Pei)现任杜克大学计算机科学、生物统计与生物信息学、电气学与计算机工程教授。2002年,他在Jiawei Han博士的指导下,于西蒙弗雷泽大学获得了计算机科学博士学位。他在很多顶级学术论坛发表了大量关于数据挖掘、数据库、网络搜索和信息检索的文章,并积极为学术界服务。他是加拿大皇家学会会员、加拿大工程院院士、ACM和IEEE的会士。荣获2017年ACM SIGKDD创新奖以及2015年ACM SIGKDD服务奖。
童行行现为伊利诺伊大学厄巴纳–香槟分校计算机科学系副教授。他于2009年在卡内基梅隆大学获得博士学位。他发表了200多篇文章。他的研究获得了多个权威机构的奖项和数千次引用。他是SIGKDD Explorations(ACM)的主编和多家期刊的副主编。
精彩书摘
韩家炜(Jiawei Han)是伊利诺伊大学厄巴纳–香槟分校计算机科学系Michael Aiken讲席教授。他因在知识发现和数据挖掘研究方面的贡献获得了无数奖项,包括ACM SIGKDD创新奖(2004年)、IEEE计算机学会技术成就奖(2005年)和IEEE W. Wallace McDowell奖(2009年)。他是ACM会士和IEEE会士,曾担任ACM Transactions on Knowledge Discovery from Data(2006—2011)创始主编,并担任多种期刊的编委会成员,包括IEEE Transactions on Knowledge and Data Engineering和Data Mining and Knowledge Discovery。
裴健(Jian Pei)现任杜克大学计算机科学、生物统计与生物信息学、电气学与计算机工程教授。2002年,他在Jiawei Han博士的指导下,于西蒙弗雷泽大学获得了计算机科学博士学位。他在很多顶级学术论坛发表了大量关于数据挖掘、数据库、网络搜索和信息检索的文章,并积极为学术界服务。他是加拿大皇家学会会员、加拿大工程院院士、ACM和IEEE的会士。荣获2017年ACM SIGKDD创新奖以及2015年ACM SIGKDD服务奖。
童行行现为伊利诺伊大学厄巴纳–香槟分校计算机科学系副教授。他于2009年在卡内基梅隆大学获得博士学位。他发表了200多篇文章。他的研究获得了多个权威机构的奖项和数千次引用。他是SIGKDD Explorations(ACM)的主编和多家期刊的副主编。
计算机科学与技术、数据科学、人工智能等相关专业的学生,高校及研究机构的研究人员,数据分析师、数据科学家、机器学习工程师及数据挖掘从业人员