1. 软件介绍
1.1. Flume概述
高可用的,高可靠的, 分布式的海量日志采集、聚合和传输的系统 。Flume 基于流式架构,灵活简单。
1.2. Flume优点
高速采集数据,采集的数据能够以想要的文件格式及压缩方式存储在hdfs上
事务功能保证了数据在采集的过程中数据不丢失
部分Source保证了Flume挂了以后重启依旧能够继续在上一次采集点采集数据,真正做到数据零丢
失,一定的高可用
2. Flume体系架构
2.1. 架构概述
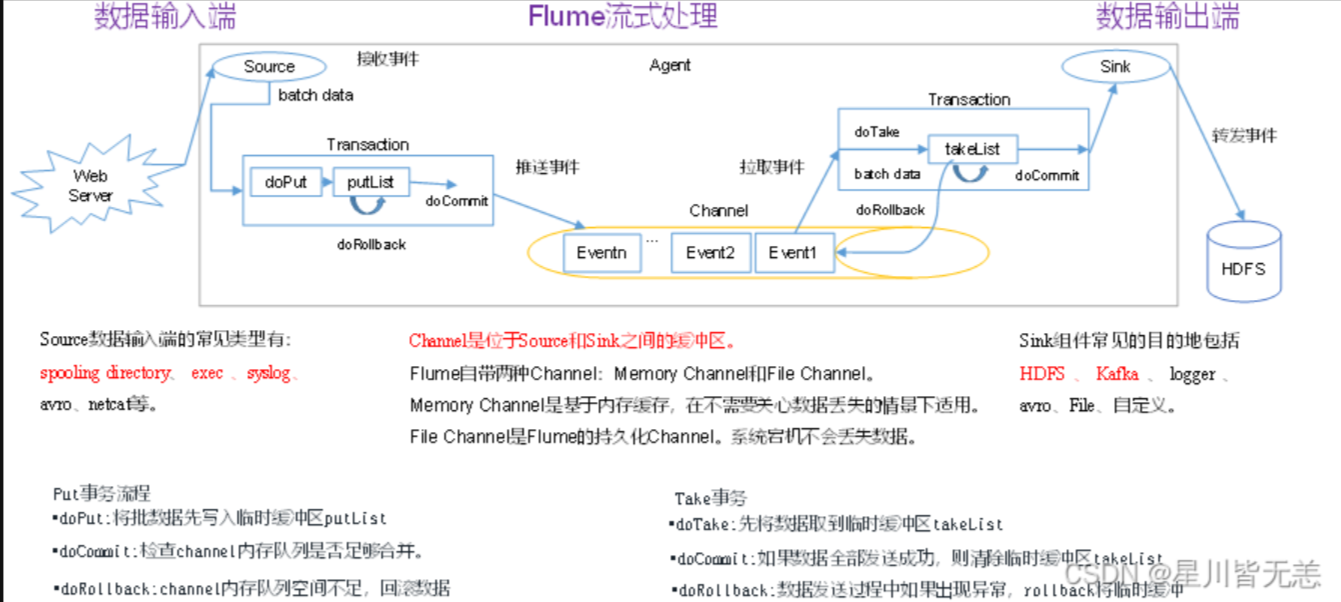
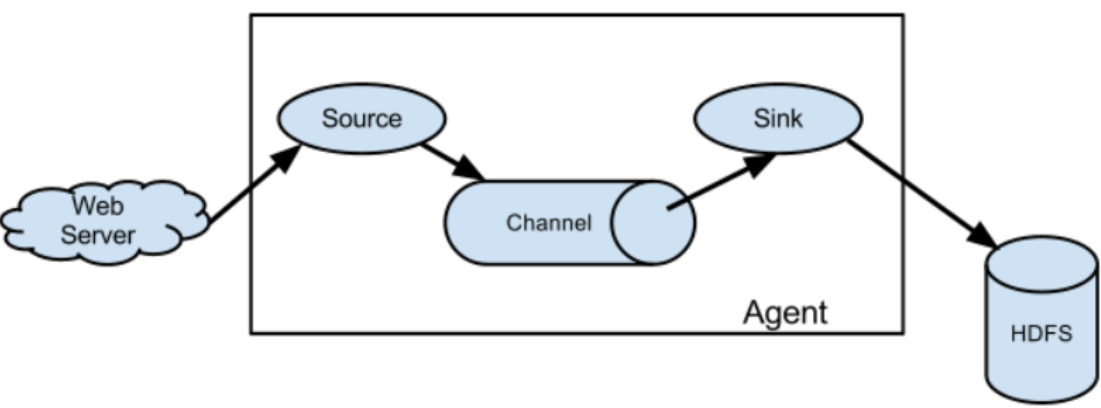
Client(WebServer):Client生产数据,运行在一个独立的线程。
Event:一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
header(k=v) map对象 body(byte array)字节数组
Flow:Event从源点到达目的点的迁移的抽象。
Agent:一个独立的Flume进程,包含组件Source、 Channel、 Sink。
Source:数据收集组件。(source从Client收集数据,传递给Channel)
Channel:中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接
sources 和 sinks ,这个有点像一个消息队列。)
Sink:从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的
话(Sink从Channel收集数据,运行在一个独立线程。)
2.1.1. Agent
jvm的进程,以事件的形式将数据从源头发送到目的地,是flume传输的基本单元。
由Source、Channel、Sink组成。
2.1.2. Source
Agent的收集端,将数据获取后特殊的格式化,将数据封装到事件(event)里,再将事件推入(put)Channel中。
Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。
可以让应用程序使用官方已有的Source,如AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
NetCat Source:绑定的端口(tcp、udp),将流经端口的每一个文本行数据作为Event输入
type:source的类型,必须是netcat。
bind:要监听的(本机的)主机名或者ip。此监听不是过滤发送方。一台电脑不是说只有一个
IP。有多网卡的电脑,对应多个IP。
port:绑定的本地的端口。
Avro Source:监听一个avro服务端口,采集Avro数据序列化后的数据
type:avrosource的类型,必须是avro。
bind:要监听的(本机的)主机名或者ip。此监听不是过滤发送方。一台电脑不是说只有一个
IP。有多网卡的电脑,对应多个IP。
port:绑定的本地的端口。
Exec Source:于Unix的command在标准输出上采集数据;
type:source的类型:必须是exec。
command:要执行命令。
Spooling Directory Source:监听一个文件夹里的文件的新增,如果有则采集作为source。
type:source 的类型:必须是spooldir
spoolDir:监听的文件夹 【提前创建目录】
fileSu�ix:上传完毕后文件的重命名后缀,默认为.COMPLETE
deletePolicy:上传后的文件的删除策略never和immediate,默认为never。
fileHeader:是否要加上该文件的绝对路径在header里,默认是false。
basenameHeader:是否要加上该文件的名称在header里,默认是false。
2.1.3. Channel
位于Source和Sink之间的缓冲区,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。多线程,且线程安全。
Memory Channel使用内存作为数据的存储。
Type channel的类型:必须为memory
capacity:channel中的最大event数目
transactionCapacity:channel中允许事务的最大event数目
Memory Channel在不需要关心数据丢失的情景下适用,因为程序死亡、机器宕机或者重
启都会导致数据丢失。
File Channel 使用文件作为数据的存储
Type channel的类型:必须为 file
checkpointDir :检查点的数据存储目录【提前创建目录】
dataDirs :数据的存储目录【提前创建目录】
transactionCapacity:channel中允许事务的最大event数目
Spillable Memory Channel 使用内存作为channel,超过了阀值就存在文件中
Type channel的类型:必须为SPILLABLEMEMORY
memoryCapacity:内存的容量event数
overflowCapacity:数据存到文件的event阀值数
checkpointDir:检查点的数据存储目录
dataDirs:数据的存储目录
2.1.4. Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、
或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
HDFS Sink:将数据传输到hdfs集群中。
type:sink的类型 必须是hdfs。
hdfs.path:hdfs的上传路径。
hdfs.filePrefix:hdfs文件的前缀。默认是:FlumeData
hdfs.rollInterval:间隔多久产生新文件,默认是:30(秒) 0表示不以时间间隔为准。
hdfs.rollSize:文件到达多大再产生一个新文件,默认是:1024(bytes)0表示不以文件大小为
准。
hdfs.rollCount:event达到多大再产生一个新文件,默认是:10(个)0表示不以event数目为准。*
hdfs.batchSize:每次往hdfs里提交多少个event,默认为100
hdfs.fileType:hdfs文件的格式主要包括:SequenceFile, DataStream ,CompressedStream,如
果使用了CompressedStream就要设置压缩方式。
hdfs.codeC:压缩方式:gzip, bzip2, lzo, lzop, snappy
注:%{host}可以使用header的key。以及%Y%m%d来表示时间,但关于时间的表示需要在header里有timestamp这个key。
ogger Sink将数据作为日志处理(根据flume中的设置的日志方式来显示)
要在控制台显示在运行agent的时候加入:-Dflume.root.logger=INFO,console 。
type:sink的类型:必须是 logger。
maxBytesToLog:打印body的最长的字节数 默认为16
Avro Sink:数据被转换成Avro Event,然后发送到指定的服务端口上。
type:sink的类型:必须是 avro。
hostname:指定发送数据的主机名或者ip
port:指定发送数据的端口
File Roll Sink:数据发送到本地文件。
type:sink的类型:必须是 file_roll。
sink.directory:存储文件的目录【提前创建目录】
batchSize:一次发送多少个event。默认为100
sink.rollInterval:多久产生一个新文件,默认为30s。单位是s。0为不产生新文件。【即使没有数据也会产生文件】
2.1.5. Interceptor
当我们需要对数据进行过滤修改时,除了我们在Source、 Channel和Sink进行代码修改之外, Flume为我们提供了拦截器,拦截器也是chain形式的。
拦截器的位置在Source和Channel之间,当我们为Source指定拦截器后,我们在拦截器中会得到
event,根据需求我们可以对event进行保留还是抛弃,抛弃的数据不会进入Channel中。
Source---Interceptor---Channel---Sink
Timestamp Interceptor 时间戳拦截器 在header里加入key为timestamp,value为当前时间。
type:拦截器的类型,必须为timestamp
preserveExisting:如果此拦截器增加的key已经存在,如果这个值设置为true则保持原来
的值,否则覆盖原来的值。默认为false
Host Interceptor 主机名或者ip拦截器,在header里加入ip或者主机名
type:拦截器的类型,必须为host
preserveExisting:如果此拦截器增加的key已经存在,如果这个值设置为true则保持原来
的值,否则覆盖原来的值。默认为false
useIP:如果设置为true则使用ip地址,否则使用主机名,默认为true
hostHeader:使用的header的key名字,默认为host
Static Interceptor 静态拦截器,是在header里加入固定的key和value。
type:avrosource的类型,必须是static。
preserveExisting:如果此拦截器增加的key已经存在,如果这个值设置为true则保持原来的
值,否则覆盖原来的值。默认为false
key:静态拦截器添加的key的名字
value:静态拦截器添加的key对应的value值
2.2. Flume事务
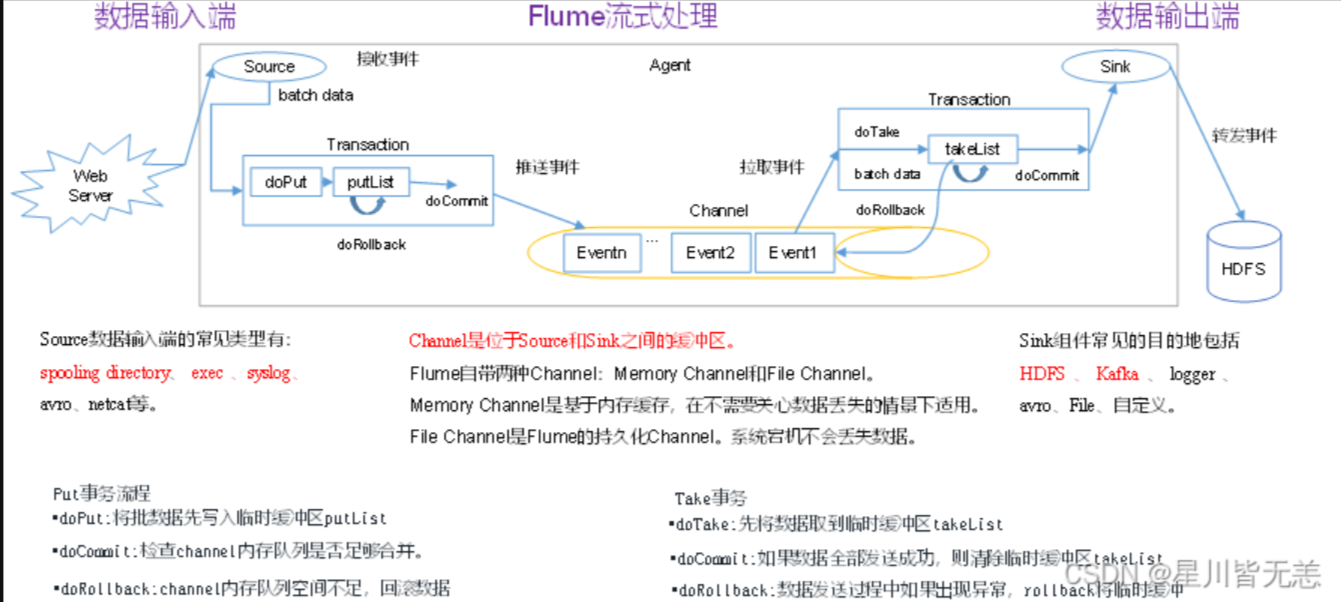
推送事务流程(Source→Channel)
doPut: 把批数据写入到临时缓冲区putList
doCommit: 检查Channel容量是否足够,如果容量足够则把putList里的数据发送到Channel
doRollBack:如果Channel容量不够,则把数据回滚到putList
拉取事务流程(Channel→Sink)
doTake:把数据读取到临时缓冲区takeList
doCommit:检查数据是否发送成功,成功的话,则把event从takeList中移除
doRollBack:如何发送失败,则把takeList的数据回滚数据到Channel
可靠性
只有当sink接收到,数据落地完成的信息之后,才会将数据从通道中删除
事件在每个代理上的一个通道中上游。然后将事件传递到流中的下一个代理或终端存储库
(如HDFS)。仅将事件存储在下一个代理程序的通道或终端存储库中之后,才将其从通道中
删除。这就是Flume中单条消息传递语义如何提供流的端到端可靠性的方式。
数据传输的方式不是byte,而是一个个的event,Flume使用事务性方法来确保事件的可靠传
递。源和接收器分别在事务中封装存储在通道中或由通道提供的事务中提供的事件的存储/检
索。这确保了事件集在流中从点到点可靠地传递。在多条流的情况下,来自上一条的接收器
和来自下一条的源均运行其事务,以确保将数据安全地存储在下一条的通道中。
可恢复
当数据丢失了,只有从存储在磁盘的方式,才能将数据找回,事件在通道中恢复,该通道管理
从故障中恢复。Flume支持持久的文件通道,该通道由本地文件系统支持。还有一个内存通道
可以将事件简单地存储在内存队列中,这虽然速度更快,但是当代理进程死亡时,仍保留在
内存通道中的任何事件都无法恢复。