目录
五、Langchain4j 整合MongoDB会话存储案例演示
一、前言
与大模型对话时,细心的伙伴们会发现,前面跟大模型聊的一句话,后面再基于这句话继续问问题的时候,仍然可以得到预期的回答,这就是大模型的记忆能力。什么是记忆?默认情况下向大模型每次发起的提问都是新的,大模型无法把每次对话形成记忆,也无法根据对话上下文给出人性化的答案。比如:第一次提一个问题,大模型给出了一个回答列表,当我再次提问这个回答列表中的一个问题时,它就不知道我在说什么了,因为大模型已经失去了上一次的提问记忆。所以让智能体(如AI助手、机器人、虚拟角色等)拥有记忆功能不仅能提升交互体验,还能增强其功能性、适应性和长期价值。
二、大模型会话记忆介绍
2.1 AI 大模型会话记忆是什么
大模型会话记忆,通常指的是在对话式人工智能系统中,为了让AI能够理解并回应用户输入的信息时,考虑到之前的交互内容的能力。这种能力使得AI能够在长时间的对话中维持上下文,记住之前提到的关键信息,并根据这些信息进行更加准确和相关的回应。在下面的这2段对话中,基于第一次给出的回答内容,再次发起相关的问题时,大模型仍然能够给出预期的回答。
2.2 大模型会话记忆常用实现方案
随着大模型技术的广泛使用,AI大模型实现会话记忆的方式有多种,如下:
基于缓存的记忆:这种方法涉及存储最近几个回合的对话信息,并在处理新的输入时参考这些信息。这可以提供一定程度的上下文,但其容量有限,因为只能记住最近的交互。
外部数据库或知识图谱:在这种方法中,AI可以通过查询外部数据库或知识图谱来获取长期记忆。这种方式允许AI访问大量信息,但是如何高效地检索和利用这些信息是一个挑战。
长短期记忆网络(LSTM)和其他递归神经网络(RNNs):这些是专门设计用来处理序列数据的深度学习模型,能够通过内部状态保存一些关于过去事件的记忆。虽然它们能捕捉到一定的上下文信息,但在处理非常长的对话历史时仍面临挑战。
Transformer架构:近年来,Transformer及其变种(如BERT、GPT等)已经成为构建大规模语言模型的基础,这些模型可以同时关注多个输入部分,从而更有效地理解和记忆对话中的关键信息。特别是自注意力机制允许模型对整个对话历史进行编码,以便更好地生成响应。
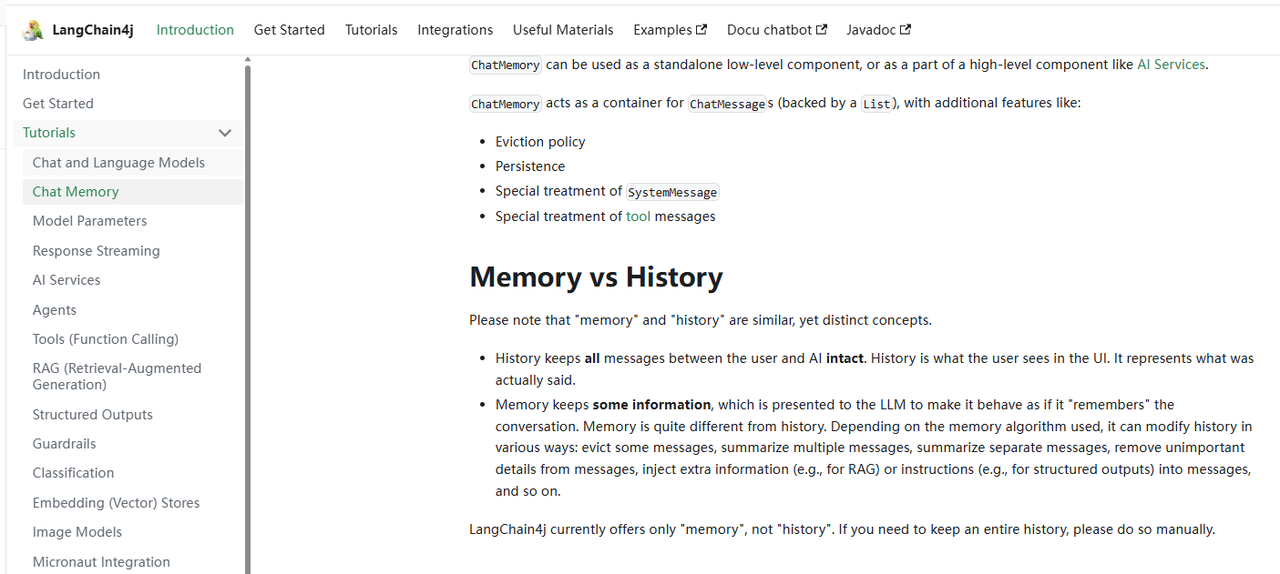
2.3 LangChain4j 会话记忆介绍
LangChain4j 是 Java 版的 LangChain 实现,提供了构建大模型应用的组件,其中会话记忆(Memory)是核心功能之一。入口:Chat Memory | LangChain4j
三、大模型常用会话存储数据库介绍
在之前的学习中,相信很多同学已经了解到,默认情况下,聊天会话的记忆存储在内存中。如果需要持久化存储,可以实现一个自定义的聊天记忆存储类, 以便将聊天消息存储在你选择的任何持久化存储介质中。
3.1 常用的会话存储数据库
大模型中,聊天记忆存储选择哪种数据库,需要综合考虑数据特点、应用场景和性能要求等因素,以下是一些常见的选择及其特点:
1)mysql
特点:关系型数据库。支持事务处理,确保数据的一致性和完整性,适用于结构化数据的存储和查询。
适用场景:如果聊天记忆数据结构较为规整,例如包含固定的字段如对话 ID、用户 ID、时间戳、消息内容等,且需要进行复杂的查询和统计分析,如按用户统计对话次数、按时间范围查询特定对话等,MySQL 是不错的选择。
2)Redis
特点:内存数据库,读写速度极高。它适用于存储热点数据,并且支持多种数据结构,如字符串、哈希表、列表等,方便对不同类型的聊天记忆数据进行处理。
适用场景:对于实时性要求极高的聊天应用,如在线客服系统或即时通讯工具,Redis 可以快速存储和获取最新的聊天记录,以提供流畅的聊天体验。
3)MongoDB
特点:文档型数据库,数据以 JSON - like 的文档形式存储,具有高度的灵活性和可扩展性。它不需要预先定义严格的表结构,适合存储半结构化或非结构化的数据。
适用场景:当聊天记忆中包含多样化的信息,如文本消息、图片、语音等多媒体数据,或者消息格式可能会频繁变化时,MongoDB 能很好地适应这种灵活性。例如,一些社交应用中用户可能会发送各种格式的消息,使用 MongoDB 可以方便地存储和管理这些不同类型的数据。
4)Cassandra
特点:是一种分布式的 NoSQL 数据库,具有高可扩展性和高可用性,能够处理大规模的分布式数据存储和读写请求。适合存储海量的、时间序列相关的数据。
适用场景:对于大型的聊天应用,尤其是用户量众多、聊天数据量巨大且需要分布式存储和处理的场景,Cassandra 能够有效地应对高并发的读写操作。例如,一些面向全球用户的社交媒体平台,其聊天数据需要在多个节点上进行分布式存储和管理,Cassandra 可以提供强大的支持。
3.2 MongoDB 简介
3.2.1 MongoDB 是什么
MongoDB 是一个基于文档的 NoSQL 数据库,由 MongoDB Inc. 开发,具备如下基本特点:
MongoDB 属于非关系型数据库,也叫NoSQL数据库,是对不同于传统的关系型数据库的数据库管理系统的统称。
MongoDB 的设计理念是为了应对大数据量、高性能和灵活性需求。
MongoDB使用集合(Collections)来组织文档(Documents),每个文档都是由键值对组成的,下面是其核心的几个概念:
数据库(Database):存储数据的容器,类似于关系型数据库中的数据库。
集合(Collection):数据库中的一个集合,类似于关系型数据库中的表。
文档(Document):集合中的一个数据记录,类似于关系型数据库中的行(row),以 BSON 格式存储。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成,文档类似于 JSON 对象,字段值可以包含其他文档,数组及文档数组。
3.3 为什么选择MongoDB 作为会话存储数据库
MongoDB 自身的数据库特性,使得其具备了高度的灵活性,能够天然适配各种类型的数据结构,文本、图片、文件、音视频等,选择 MongoDB 作为大模型(如LLM)的会话记忆存储,具有以下优势,尤其适合动态、非结构化的对话数据管理:
灵活的无模式(Schema-less)设计
动态数据结构:会话数据(如对话历史、用户偏好、上下文)通常是非结构化或快速变化的。MongoDB的文档模型(JSON/BSON格式)允许自由存储嵌套、异构的数据(如文本、向量、元数据),无需预先定义表结构。
示例:同一集合中可存储不同格式的对话记录(如纯文本对话、带附件的会话、多轮上下文),适应业务需求变化。
高性能读写与扩展性
高吞吐量:MongoDB的写优化和内存映射引擎适合频繁插入对话记录的场景(如实时聊天应用)。
水平扩展:通过分片(Sharding)轻松应对海量会话数据,支持分布式部署,避免单机瓶颈。
索引优化:可为用户ID、时间戳、会话ID等字段创建索引,加速查询(如“获取用户最近10次对话”)。
原生支持复杂查询
富查询语法:支持字段过滤、范围查询、正则表达式、聚合管道等,方便检索特定对话内容。
例如:db.sessions.find({ "user_id": "123", "timestamp": { "$gt": ISODate("2023-01-01") } })
支持各种聚合需求:统计会话长度、用户活跃度等指标(如$group、$count)。
适合向量数据存储(结合AI场景)
存储嵌入向量:若会话需结合向量搜索(如检索相似对话历史),可将文本的向量嵌入(如OpenAI embeddings)直接存入MongoDB文档,或与专用向量数据库(如Milvus)搭配使用。
高可用架构与持久化存储
副本集(Replica Set):自动故障转移,保障会话数据不丢失。
持久化与缓存:通过
journaling和WiredTiger存储引擎平衡性能与数据安全。
与大模型集成便利
LangChain等工具支持:许多AI开发框架(如LangChain)提供MongoDB的集成接口,方便管理对话记忆。
流式处理:变更流(Change Streams)可实时监听数据变化,触发后续AI处理(如对话摘要生成)。
四、环境准备
4.1 搭建 MongoDB
下面使用docker快速搭建一个MongoDB服务,请提前在服务器或本机安装docker环境,参考下面的操作步骤。
4.1.1 获取镜像
执行下面的命令获取镜像,版本可以结合自身的需求选择
docker pull mongo:4.4
4.1.2 启动容器
在启动镜像之前先创建一个数据目录的映射
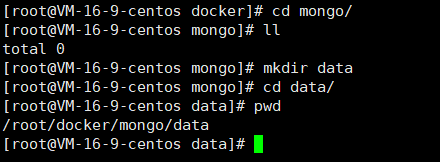
然后使用下面的命令启动容器
docker run --name my-mongo \
-p 27017:27017 \
-v /root/docker/mongo/data:/data/db \
-e MONGO_INITDB_ROOT_USERNAME=admin \
-e MONGO_INITDB_ROOT_PASSWORD=123456 \
-d mongo:4.4
docker 启动参数说明:
--name my-mongo:容器名称(可自定义)。-p 27017:27017:将宿主机的 27017 端口映射到容器内 MongoDB 默认端口。-v /path/to/mongo_data:/data/db:数据持久化(将容器内/data/db挂载到宿主机目录,替换/path/to/mongo_data为实际路径)。-e环境变量:MONGO_INITDB_ROOT_USERNAME:初始化 root 用户名(可选,建议生产环境设置)。MONGO_INITDB_ROOT_PASSWORD:root 用户密码。
-d:后台运行容器。
4.1.3 连接与使用mongodb
1)登录mongodb
执行下面的命令登录到mongodb 的客户端窗口,由于上面搭建的时候没有设置登录账户和密码,如果设置了,需要在下面的命令中加上
docker exec -it my-mongo mongo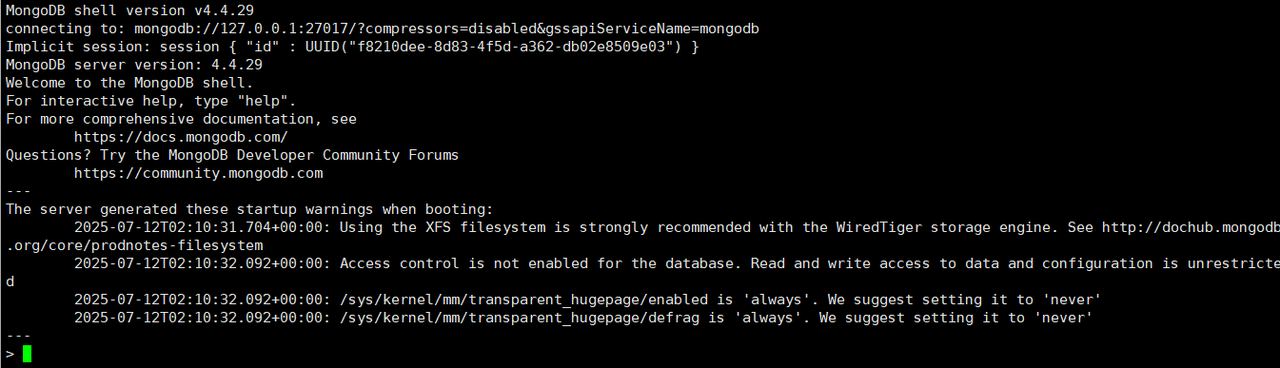
2)基本操作示例
可以使用下面的几个常用的命令在客户端窗口操作一下
// 查看数据库
show dbs
// 创建/切换数据库
use test_db
// 插入文档
db.users.insertOne({ name: "Alice", age: 25 })
// 查询文档
db.users.find()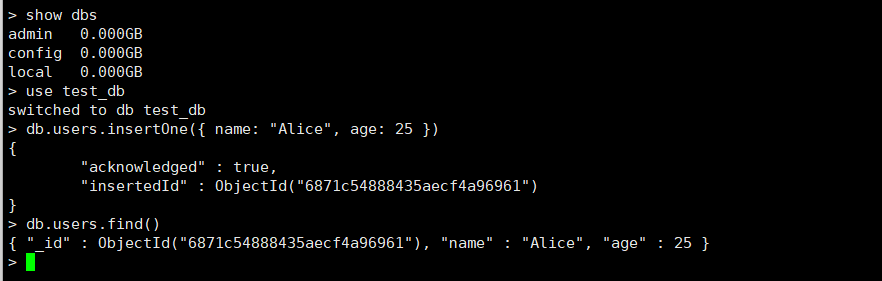
3)常用的操作命令补充说明
为了方便后续的学习和使用,基于上面登录到客户端命令窗口之后,介绍下面一些常用的操作命令
查看当前数据库: db
显示数据库列表: show dbs
切换到指定数据库: use <database_name>
执行查询操作: db.<collection_name>.find()
插入文档: db.<collection_name>.insertOne({ ... })
更新文档: db.<collection_name>.updateOne({ ... })
删除文档: db.<collection_name>.deleteOne({ ... })
退出 MongoDB Shell: quit() 或者 exit
4.2 springboot 整合MongoDB
4.2.1 添加mongodb 依赖
在pom文件中添加下面的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>4.2.2 添加配置文件
在工程配置文件中添加mongodb的连接信息,如果你设置了账户和密码,还需要连接配置的时候添加一下
spring:
data:
mongodb:
uri: mongodb://IP:27017/chat_memory_db4.2.3 添加一个实体类
为了接下来操作mogodb方便,创建一个实体类,用于映射MongoDB中的文档
package com.congge.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.bson.types.ObjectId;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document("chat_messages")
public class ChatMessages {
//唯一标识,映射到 MongoDB 文档的 _id 字段
@Id
private ObjectId messageId;
////存储当前聊天记录列表的json字符串
private String content;
public ChatMessages(String content) {
this.content = content;
}
}4.2.4 添加测试接口
下面添加几个测试接口,确保能够通过API正常操作MongoDB
package com.congge.controller;
import com.congge.entity.ChatMessages;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/mongo")
public class MongoController {
@Autowired
private MongoTemplate mongoTemplate;
//localhost:8082/mongo/save
@GetMapping("/save")
public String testSave() {
ChatMessages chatMessages = new ChatMessages("测试保存数据");
mongoTemplate.save(chatMessages);
return "mongodb测试成功";
}
/**
* 根据id查询
* localhost:8082/mongo/findById
*/
@GetMapping("/findById")
public Object testFindById() {
ChatMessages chatMessages = mongoTemplate.findById("6871d21399b5544b1bf3d156",
ChatMessages.class);
return chatMessages;
}
}4.2.5 效果测试
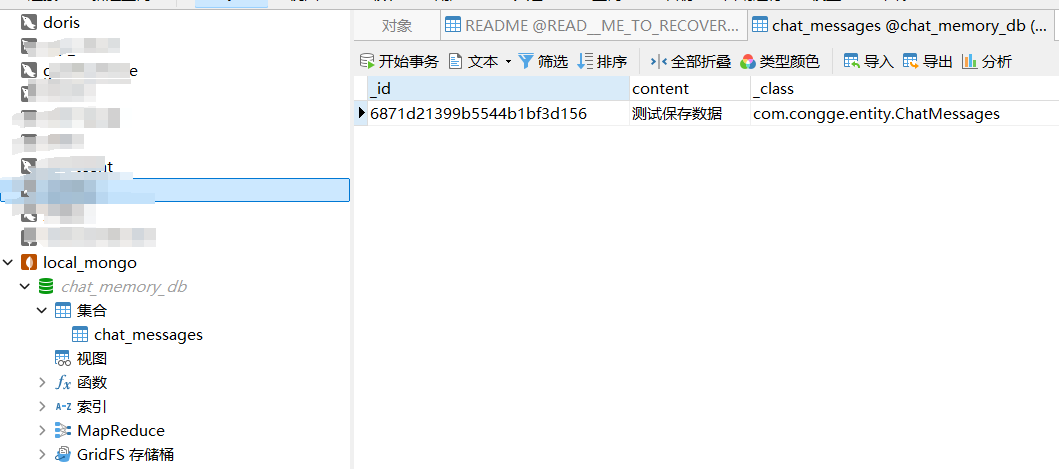
1)新增接口测试
调用新增数据接口
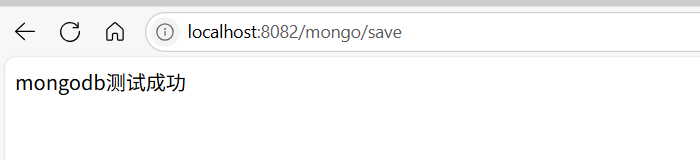
然后登录客户端,可以看到新插入了一条数据
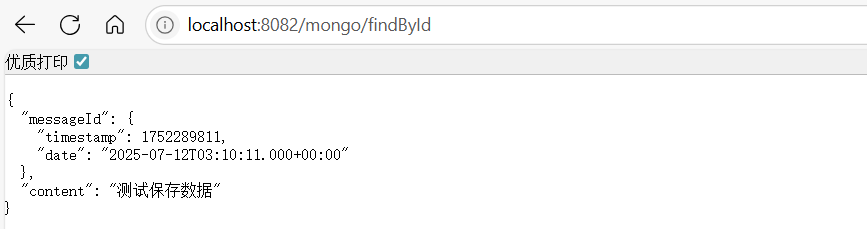
2)查询数据接口测试
执行查询接口,可以看到能够正确查到上面新增的这条数据
五、Langchain4j 整合MongoDB会话存储案例演示
基于上面的前置操作,我们完成了MongoDB的环境搭建,并且在springboot工程中完成了对MongoDB的集成,接下来,演示下如何将Langchain4j 的会话记忆持久化存储到MongoDB数据库中。
5.1 ChatMemoryStore 说明
还记得最初在学习会话记忆的时候 ChatMemory 这个接口,在下面的这两段代码中,均可以实现在代码层面,调用大模型的API进行对话聊天时的会话记忆,如下:
@Bean
public ChatMemory chatMemory() {
//设置聊天记忆记录的message数量
return MessageWindowChatMemory.withMaxMessages(20);
}或者使用ChatMemoryProvider 进行实现
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.build();
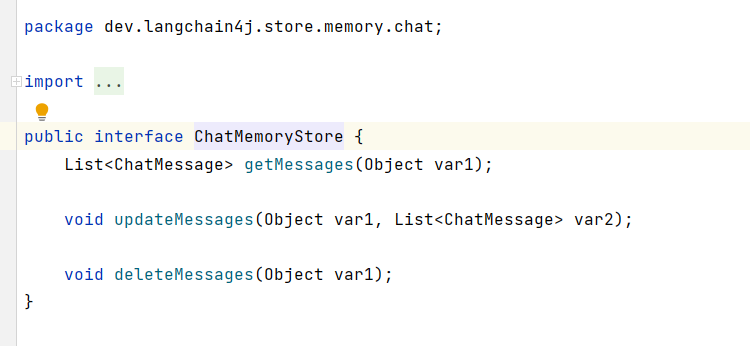
}说到底,最终实现会话记忆的核心底层组件,由ChatMemoryStore这个组件进行实现,通过源码可以看到该接口有3个默认的方法待实现,如果想要实现会话记忆的自定义数据源存储,需要实现该接口,并实现里面的三个核心方法,从源码中可以清楚看到这一点,所以接下来的核心工作,就是需要自定义一个类,来重写该接口中的3个方法,从而实现会话的持久化存储走mongodb数据库
5.2 添加配置文件
本次演示案例基于千问的大模型,同时使用阿里云百炼进行大模型的对接,在配置文件中添加下面的配置信息
server:
port: 8082
spring:
data:
mongodb:
uri: mongodb://IP:27017/chat_memory_db
#直接对接的是deepseek官网的的大模型
langchain4j:
#阿里百炼平台的模型
community:
dashscope:
chat-model:
api-key: 你的apikey #这个是白炼平台的apikey
model-name: qwen-max
logging:
level:
root: debug5.3 自定义CahtMemory的配置类
在上一步我们说明了如果需要使用mongogb实现会话持久化存储,需要自定义配置类,实现ChatMemoryStore接口,参考下面的自定义配置类代码:
package com.congge.config;
import com.congge.entity.ChatMessages;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
import java.util.LinkedList;
import java.util.List;
@Configuration
public class MongoChatMemoryConfig implements ChatMemoryStore {
@Autowired
private MongoTemplate mongoTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
ChatMessages chatMessages = mongoTemplate.findOne(query, ChatMessages.class);
if (chatMessages == null) {
return new LinkedList<>();
}
return ChatMessageDeserializer.messagesFromJson(chatMessages.getContent());
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
Update update = new Update();
update.set("content", ChatMessageSerializer.messagesToJson(messages));
//根据query条件能查询出文档,则修改文档;否则新增文档
mongoTemplate.upsert(query, update, ChatMessages.class);
}
@Override
public void deleteMessages(Object memoryId) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
mongoTemplate.remove(query, ChatMessages.class);
}
}5.4 自定义ChatMemoryProvider
需要在自定义的ChatMemoryProvider中,将上一步配置的MongoChatMemoryConfig 添加进去
package com.congge.config;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import jakarta.annotation.Resource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SeparateChatAssistantConfig {
@Autowired
private MongoChatMemoryConfig mongoChatMemoryConfig;
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(mongoChatMemoryConfig)
.build();
}
}5.5 添加自定义 Assistant
添加一个自定义助手接口,配置上一步的ChatMemoryProvider
package com.congge.assistant;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "qwenChatModel",
chatMemoryProvider = "chatMemoryProvider"
)
public interface SeparateChatAssistant {
/**
* 分离聊天记录
* @param memoryId 聊天id
* @param userMessage 用户消息
* @return
*/
String chat(@MemoryId int memoryId, @UserMessage String userMessage);
}5.6 增加测试接口
为方便演示看效果,添加下面的一个测试的接口
@Resource
private SeparateChatAssistant separateChatAssistant;
//localhost:8082/chat/memory/v5?userId=1&userMessage=我是小王
//localhost:8082/chat/memory/v5?userId=1&userMessage=你知道我是谁吗?
//localhost:8082/chat/memory/v5?userId=2&userMessage=我是小李
//localhost:8082/chat/memory/v5?userId=2&userMessage=你知道我是谁吗?
@GetMapping("/chat/memory/v5")
public String chatMemoryV3(@RequestParam("userId") Integer userId,@RequestParam("userMessage") String userMessage) {
String answer1 = separateChatAssistant.chat(userId,userMessage);
return answer1;
}5.7 效果测试
下面依次调用几个接口,模拟一下对话是否持久化存储的效果
1)接口1效果
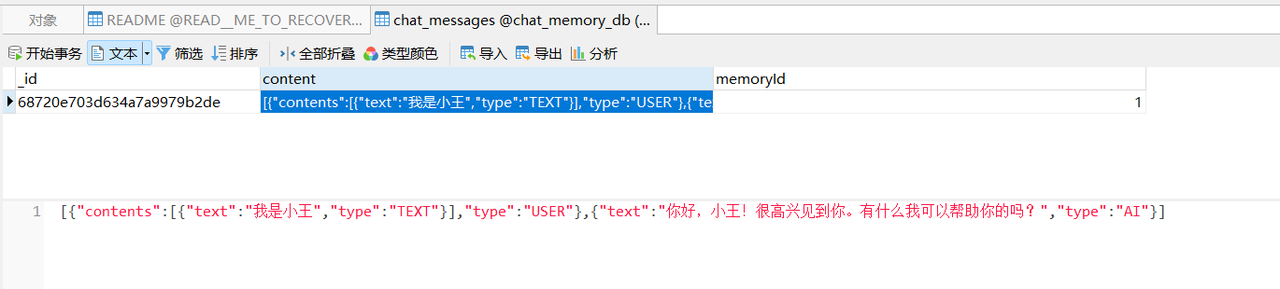
调用第1个接口,userId=1的用户第一次与大模型对话

接口调用成功后,检查数据库,用户会话,以及大模型的回复已经存储
2)接口2效果
调用第2个接口,userId=1的用户第二次与大模型对话

由于第一次会话持久化存储了,从大模型回复来看,是可以读取到第一次的会话内容,同时数据库的存储内容如下
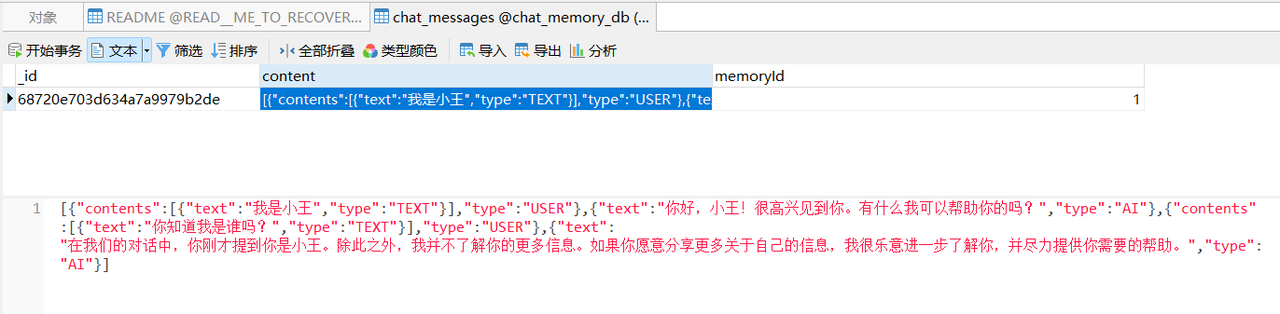
3)模拟会话隔离
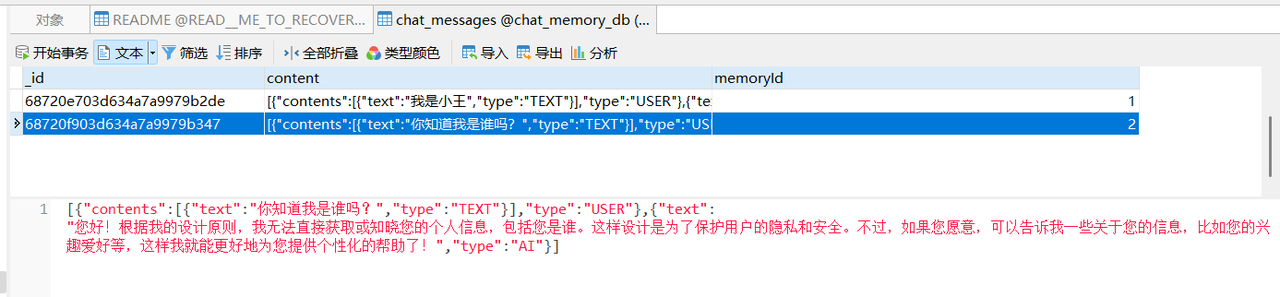
我们尝试使用userId=2的账户与大模型对话,咨询我是谁,从接口的返回结果来看,由于数据库没有存储与2这个用户的会话信息,所以这里大模型无法判断我是谁

同时检查数据库,本次的请求会话信息也做了存储
五、写在文末
本文通过案例操作演示了基于Langchain整合MongoDB数据库存储大模型对话的完整过程,有兴趣的同学还可以基于此做进一步的优化完善,本篇到此结束,感谢观看。