前言
《机器学习》又叫西瓜书,一本很出名的机器学习书,书里面教我们怎么挑西瓜。挑西瓜这个场景很适合决策树,那么我们就用决策树实现一个,后面有决策树的图,大家以后买西瓜可以参考下这个决策树看下准不准哈哈。
决策树
1. 什么是决策树
决策树是一种常用的 监督学习方法,既可以用于分类(Classification),也可以用于回归(Regression)。
它的结构类似一棵树:
- 根节点:表示最初的特征选择
- 内部节点:表示对某一特征的判断
- 分支:表示判断结果的不同取值
- 叶子节点:表示最终的分类结果或预测值
通俗来说,决策树就是一连串的 “如果…那么…” 的规则组合,把复杂的问题拆解成若干个简单的判断。
2. 决策树的特点
✅ 优点:
- 直观、容易理解(像流程图一样)。
- 不需要特征归一化或标准化。
- 能处理数值型和类别型数据。
- 可解释性强(能清楚地看到决策依据)。
⚠️ 缺点:
- 容易过拟合(树太深时泛化能力差)。
- 对噪声和异常值敏感。
- 决策边界是矩形的,不够平滑。
3. 决策树的构建方法
核心思想:选择最能“区分”数据的特征来做划分。
常见的划分指标:
信息增益(ID3 算法)
- 基于信息论中的“熵”。
- 选择信息增益最大的特征来划分。
信息增益率(C4.5 算法)
- 改进 ID3,避免偏向于取值过多的特征。
基尼指数(CART 算法)
- 选择基尼指数最小的特征来划分。
- CART 既能做分类树,也能做回归树。
ID3 算法
在这里我们使用ID3算法
ID3(Iterative Dichotomiser 3) 是最早的 决策树生成算法之一,由 Ross Quinlan 在 1986 年提出。
它的核心思想是:选择信息增益最大的特征作为划分属性,从而不断地把数据集划分,生成一棵树。
这里面提到信息增益,在说到信息增益那我们需要先讨论一下信息论的熵
熵
熵 shāng (Entropy)中学化学课上我们都学过,是表示事物的混乱程度。通俗理解:熵越大,系统越无序,可能的微观排列方式越多。
当然这里我们讨论的熵不是化学的熵,而是信息论中的熵。前面要说下化学中的熵是因为如果一个事物名称是一样的,那么它们很多性质,属性,作用基本也是一样的。也就是很多知识我们可以从名称就知道个大概,也更加方便我们理解和学习。
熵最初是由 香农(Claude Shannon) 在信息论里提出的,用来衡量 信息的不确定性 或 平均信息量。如果一个事件越不确定,它携带的信息量就越大。熵越大,信息内容的不确定性越高。
化学中的熵是系统越混乱熵越大,信息论中熵是信息不确定性越大那么熵就是越大。
比如明天太阳从东北升起,概率是1必然发生那么熵就是0;你买一张双色球中1等奖,概率是1/17721088非常低,那么不确定性非常大,那么熵非常大。
一等奖(6+1)中奖概率为:红球33选6乘以蓝球16选1=1/C(33)6*16=1/17721088
以上我们说得都是单个事件,实际信息熵我们说得是系统里的平均事件概率的熵。
- 定义(离散随机变量):
对于随机变量 XXX ,其可能取值为 x1,x2,…,xnx_1, x_2, \dots, x_nx1,x2,…,xn,概率分别为 p1,p2,…,pnp_1, p_2, \dots, p_np1,p2,…,pn:
H(X)=−∑i=1npilog2pi H(X) = - \sum_{i=1}^{n} p_i \log_2 p_i H(X)=−i=1∑npilog2pi
- H(X)H(X)H(X) 称为随机变量 XXX 的香农熵,单位通常为比特(bit)
我们假设世界杯32只队伍,每只队伍夺冠的概率都是1/32,那么世界杯夺冠的概率 信息熵多大。
# 信息熵
# H=-(p1*logp1+p2*logp2+...+p32*logp32)
@staticmethod
def informationEntropy() -> float:
h = 0
for i in range(32):
p = 1 / 32
h += p * math.log2(p)
return -h
平均信息量(熵)我们不只关心单个事件,而是关心整个系统的“平均不确定性”。
熵的范围:最小值0;最大值 log2n,当所有事件等概率,不确定性最大。
信息增益(Information Gain)
信息增益是决策树中选择划分特征的指标,衡量使用某个特征划分后,熵减少了多少。
信息增益 = 原始数据集的熵 - 使用特征 A 划分后的条件熵。
1. 定义
对数据集 DDD 和特征 AAA:
IG(D,A)=H(D)−∑v∈Values(A)∣Dv∣∣D∣H(Dv) IG(D, A) = H(D) - \sum_{v \in Values(A)} \frac{|D_v|}{|D|} H(D_v) IG(D,A)=H(D)−v∈Values(A)∑∣D∣∣Dv∣H(Dv)
- H(D)H(D)H(D):划分前的熵
- DvD_vDv:特征 AAA 取值 vvv 的子集
- ∣Dv∣/∣D∣|D_v|/|D|∣Dv∣/∣D∣:该子集在总数据集中的比例
- ∑∣Dv∣∣D∣H(Dv)\sum \frac{|D_v|}{|D|} H(D_v)∑∣D∣∣Dv∣H(Dv):划分后的加权平均熵
特征信息增益越大 → 使用该特征划分后数据集越纯 → 特征越重要
这里我们举个例子,比如明天你决定要不要去外面踢球,明天有没下雨,明天有没刮风。明天下雨你一定不去踢球了,明天刮风可能回去踢球。那么明天要不要去踢球,最重要的特征就是下雨,也就是他信息增益更大。
代码实现
准备数据集
通过西瓜的’色泽’, ‘根蒂’, ‘敲声’, ‘纹理’, ‘脐部’, '触感’这几个特征来判断是否为好瓜
# ====== 数据集 ======
def createWatermelonDataSet():
"""
创建西瓜数据集和标签
Returns:
dataSet: 数据集,每个样本是列表形式,最后一个元素是类别
labels: 特征标签列表
"""
dataSet = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
]
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜']
return dataSet, labels
计算信息熵
# ====== 决策树核心算法 ======
def calcShannonEnt(dataSet):
"""
计算数据集的香农熵(衡量数据集的不确定性)
Args:
dataSet: 数据集
Returns:
shannonEnt: 香农熵
"""
numEntries = len(dataSet) # 样本总数
labelCounts = {}
# 统计每个类别出现的次数
for featVec in dataSet:
currentLabel = featVec[-1] # 类别标签在最后一列
labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1
shannonEnt = 0.0
# 计算熵
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries # 该类别概率
shannonEnt -= prob * log(prob, 2) # 香农公式
return shannonEnt
构建树
决策树的构建流程
选择最优特征
首先,需要计算各个特征对分类结果(好瓜 / 坏瓜)的影响程度。衡量标准是 信息增益,信息增益越大,说明该特征对分类的贡献越大。生成根节点
将信息增益最大的特征作为当前数据集的划分依据,生成决策树的根节点。随后,从样本集中移除该特征,保留剩余的特征继续分析。递归划分
针对每个子集,重复步骤 1 和步骤 2,不断选择最优特征进行划分。生成的中间节点就是不同的特征,节点间的连线则对应特征的取值路径。生成叶子节点
当数据集被完全划分或没有特征可供选择时,递归结束。此时生成的叶子节点即为分类结果 —— 判断该样本是“好瓜”还是“坏瓜”。
def splitDataSet(dataSet, axis, value):
"""
按照特征划分数据集(去掉划分特征列)
Args:
dataSet: 数据集
axis: 特征索引
value: 特征的取值
Returns:
retDataSet: 划分后的子集
"""
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value: # 只保留该特征值的样本
reducedFeatVec = featVec[:axis] + featVec[axis+1:] # 去掉划分特征
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
"""
选择最优特征(信息增益最大)
Args:
dataSet: 数据集
Returns:
bestFeature: 最优特征索引
"""
numFeatures = len(dataSet[0]) - 1 # 特征数(最后一列是类别)
baseEntropy = calcShannonEnt(dataSet) # 原始熵
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet] # 第i个特征的所有取值
uniqueVals = set(featList) # 去重
newEntropy = 0.0
for value in uniqueVals: # 计算条件熵
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy # 信息增益
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
"""
多数表决法,返回出现次数最多的类别
Args:
classList: 类别列表
Returns:
出现次数最多的类别
"""
classCount = {}
for vote in classList:
classCount[vote] = classCount.get(vote, 0) + 1
# 按次数降序排序,返回次数最多的类别
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels):
"""
递归构建决策树
Args:
dataSet: 数据集
labels: 特征名称列表
Returns:
myTree: 决策树(字典形式)
"""
classList = [example[-1] for example in dataSet] # 当前数据集所有类别
# 如果类别完全相同,则返回该类别
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果没有特征可用,返回出现次数最多的类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) # 最优特征索引
bestFeatLabel = labels[bestFeat] # 特征名称
myTree = {bestFeatLabel: {}} # 初始化树
del(labels[bestFeat]) # 删除已使用特征
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] # 复制标签,防止递归修改
# 递归创建子树
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
决策树
西瓜决策树: {'纹理': {'模糊': '坏瓜', '稍糊': {'触感': {'硬滑': '坏瓜', '软粘': '好瓜'}}, '清晰': {'根蒂': {'蜷缩': '好瓜', '稍蜷': {'色泽': {'乌黑': {'触感': {'硬滑': '好瓜', '软粘': '坏瓜'}}, '青绿': '好瓜'}}, '硬挺': '坏瓜'}}}}
上面就是我们生成的决策树结构,这个适合机器看,我们人类看就很不直观。这里可以用python的matplotlib画一张树图
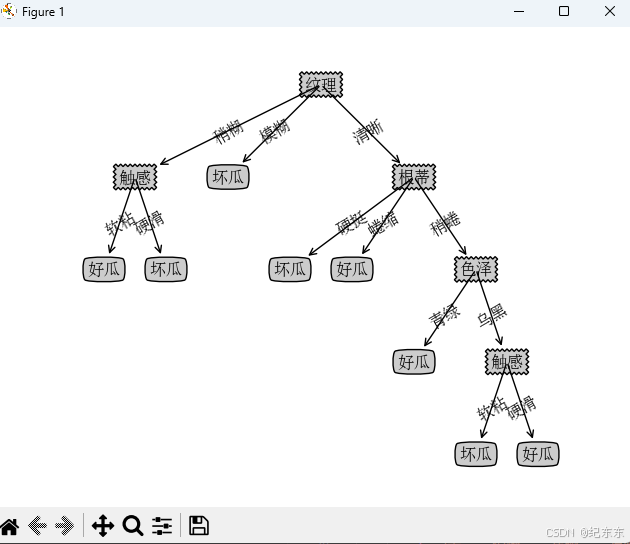
从这上面我们可以看出,如果我们买西瓜那么就需要先看纹理这样比较容易挑到我们的梦中情瓜。
测试
现在我们在街上看到一个瓜张这样,那么我们就用我们的决策树跑一下看下准不准。
test = [‘青绿’, ‘蜷缩’, ‘浊响’, ‘清晰’, ‘凹陷’, ‘硬滑’]
我们测试就是将数据集,进入我们的决策树跑一下,就是从树根节点一直往下走,走到叶子节点。叶子节点就是我们的判断结果。
def classify(inputTree, featLabels, testVec):
"""
使用决策树对输入样本进行分类
Args:
inputTree: 决策树
featLabels: 特征标签列表
testVec: 测试样本
Returns:
分类结果
"""
firstStr = list(inputTree.keys())[0] # 根节点特征名称
secondDict = inputTree[firstStr] # 根节点的子树字典
featIndex = featLabels.index(firstStr) # 找到特征索引
key = testVec[featIndex] # 测试样本该特征的取值
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict): # 如果子节点还是字典,递归
return classify(valueOfFeat, featLabels, testVec)
else: # 到叶节点,返回类别
return valueOfFeat
完整代码
# -*- coding: utf-8 -*-
from math import log
import operator
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# ====== 中文字体设置 ======
# Windows系统使用宋体,Linux或macOS请修改路径
font = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=12)
# ====== 数据集 ======
def createWatermelonDataSet():
"""
创建西瓜数据集和标签
Returns:
dataSet: 数据集,每个样本是列表形式,最后一个元素是类别
labels: 特征标签列表
"""
dataSet = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
]
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜']
return dataSet, labels
# ====== 决策树核心算法 ======
def calcShannonEnt(dataSet):
"""
计算数据集的香农熵(衡量数据集的不确定性)
Args:
dataSet: 数据集
Returns:
shannonEnt: 香农熵
"""
numEntries = len(dataSet) # 样本总数
labelCounts = {}
# 统计每个类别出现的次数
for featVec in dataSet:
currentLabel = featVec[-1] # 类别标签在最后一列
labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1
shannonEnt = 0.0
# 计算熵
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries # 该类别概率
shannonEnt -= prob * log(prob, 2) # 香农公式
return shannonEnt
def splitDataSet(dataSet, axis, value):
"""
按照特征划分数据集(去掉划分特征列)
Args:
dataSet: 数据集
axis: 特征索引
value: 特征的取值
Returns:
retDataSet: 划分后的子集
"""
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value: # 只保留该特征值的样本
reducedFeatVec = featVec[:axis] + featVec[axis+1:] # 去掉划分特征
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
"""
选择最优特征(信息增益最大)
Args:
dataSet: 数据集
Returns:
bestFeature: 最优特征索引
"""
numFeatures = len(dataSet[0]) - 1 # 特征数(最后一列是类别)
baseEntropy = calcShannonEnt(dataSet) # 原始熵
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet] # 第i个特征的所有取值
uniqueVals = set(featList) # 去重
newEntropy = 0.0
for value in uniqueVals: # 计算条件熵
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy # 信息增益
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
"""
多数表决法,返回出现次数最多的类别
Args:
classList: 类别列表
Returns:
出现次数最多的类别
"""
classCount = {}
for vote in classList:
classCount[vote] = classCount.get(vote, 0) + 1
# 按次数降序排序,返回次数最多的类别
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels):
"""
递归构建决策树
Args:
dataSet: 数据集
labels: 特征名称列表
Returns:
myTree: 决策树(字典形式)
"""
classList = [example[-1] for example in dataSet] # 当前数据集所有类别
# 如果类别完全相同,则返回该类别
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果没有特征可用,返回出现次数最多的类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) # 最优特征索引
bestFeatLabel = labels[bestFeat] # 特征名称
myTree = {bestFeatLabel: {}} # 初始化树
del(labels[bestFeat]) # 删除已使用特征
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] # 复制标签,防止递归修改
# 递归创建子树
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def classify(inputTree, featLabels, testVec):
"""
使用决策树对输入样本进行分类
Args:
inputTree: 决策树
featLabels: 特征标签列表
testVec: 测试样本
Returns:
分类结果
"""
firstStr = list(inputTree.keys())[0] # 根节点特征名称
secondDict = inputTree[firstStr] # 根节点的子树字典
featIndex = featLabels.index(firstStr) # 找到特征索引
key = testVec[featIndex] # 测试样本该特征的取值
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict): # 如果子节点还是字典,递归
return classify(valueOfFeat, featLabels, testVec)
else: # 到叶节点,返回类别
return valueOfFeat
# ====== 绘图函数 ======
decisionNode = dict(boxstyle="sawtooth", fc="0.8") # 决策节点样式(锯齿边框)
leafNode = dict(boxstyle="round4", fc="0.8") # 叶节点样式(圆角矩形)
arrow_args = dict(arrowstyle="<-") # 箭头样式(带箭头)
def getNumLeafs(myTree):
"""递归计算叶节点数"""
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict:
if isinstance(secondDict[key], dict):
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
"""递归计算树的最大深度"""
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict:
if isinstance(secondDict[key], dict):
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
"""绘制节点"""
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args,
fontproperties=font)
def plotMidText(cntrPt, parentPt, txtString):
"""在父子节点之间填充文本"""
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30,
fontproperties=font)
def plotTree(myTree, parentPt, nodeTxt):
"""递归绘制整个树"""
numLeafs = getNumLeafs(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict:
if isinstance(secondDict[key], dict):
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
"""创建决策树可视化入口函数"""
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()
# ====== 测试 ======
if __name__ == '__main__':
data, labels = createWatermelonDataSet()
tree = createTree(data, labels[:])
print("西瓜决策树:", tree)
# 绘制决策树
createPlot(tree)
# 测试分类
test = ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
result = classify(tree, ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感'], test)
print("测试样本 {} 分类结果: {}".format(test, result))
总结
上面就是用决策树算法实现的一个挑西瓜程序,这个决策树特别像我们人类大脑的思考过程,就是如果满足那么就这样,不满足就那样,非常直观。决策树缺点也很明显,就是对噪音影响较大,如果数据噪音很多,那么决策树不准。决策树只能处理离散值,而对于连续值没法处理。