作者:来自 Elastic Nitish Pandey

Elasticsearch 是一个基于 Java 的搜索与分析引擎和向量数据库,构建于 Apache Lucene 之上,它是 Elastic 搜索 AI 平台的核心。要在支持的平台上运行 Elasticsearch,你需要一个 Java 虚拟机(JVM)。JVM 提供了一个平台无关的运行环境,你可以在现有操作系统上运行 Elasticsearch 的虚拟环境。JVM 抽象了底层操作系统和硬件,使 Java 应用能够在任何平台上运行。
理解 JVM 的内存管理和通过垃圾回收(garbage collection - GC)进行对象回收,是排查诸如 java.lang.OutOfMemoryError(退出代码 127)等问题的关键。当 JVM 内存耗尽时,或出现退出代码 137(通常表示主机的 OOM/out-of-memory killer 因内存使用过多而终止 JVM 进程)时,就会出现这些问题。本文将指导你如何检查内存使用模式并排查这些 JVM 问题。
我还将解释 JVM 的作用,以及如何借助现有的 Elasticsearch API 进行关联分析,提供 Elasticsearch JVM 状态的有价值洞察,并帮助你判断是否需要根据自身用例进一步调优。
正如 Elasticsearch JVM 文档中提到的,产品自带的 JVM 选项默认值在所有支持的生产环境中都能高效工作;这些默认值可以处理大多数搜索和索引操作的用例。通常不建议更改任何值或为 JVM 选项添加自定义值。
如果你认为对你的工作负载进行任何更改会有益,请在操作前联系 Elastic 支持。
什么是 JVM?
Java 虚拟机是 Java 运行环境(JRE)的核心组成部分,JRE 随 Java 开发工具包(JDK)捆绑提供。
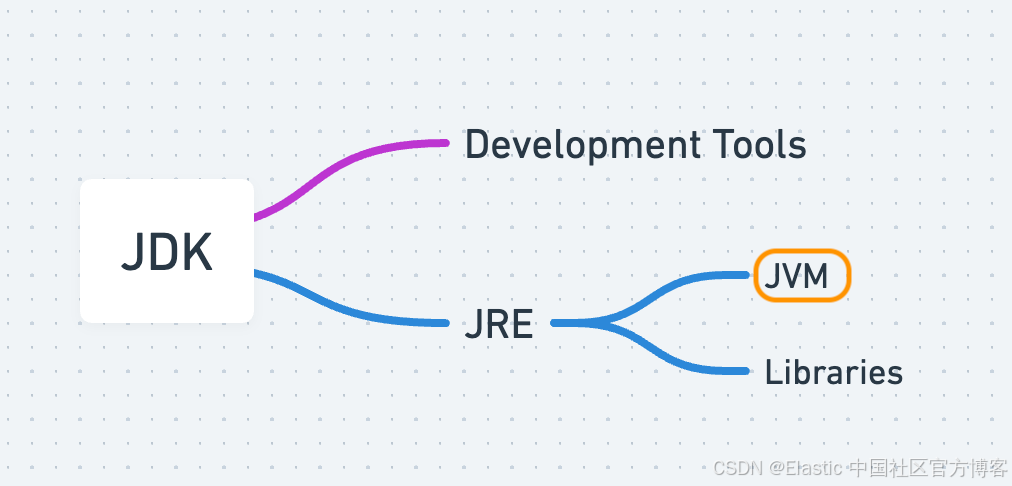
JVM 类似于一个帮助运行 Java 应用程序的计算机程序。它不是一个物理机器,但通过将 Java 代码翻译成受支持操作系统可以理解的指令,表现得像一台机器。JVM 还负责重要任务,如内存管理、垃圾回收处理以及保持应用程序的安全。
接下来,让我们重点关注 JVM 的内存管理和垃圾回收 —— 这是 Elasticsearch 中的一个关键点,在排查内存性能或 OOM 相关问题时我们经常检查。
理解内存管理和垃圾回收,首先需要了解堆区/heap area(或堆内存)的逻辑表示,这里是 JVM 启动时所有对象所在的位置。
理解 JVM 堆内存:新生代和老年代 - yong and old generations
堆区或堆内存是内存池的组合,对象根据其生命周期和年龄存放其中。JVM 堆内存主要由新生代和老年代组成。新生代进一步分为 Eden 区和 Survivor 区,如下图所示。Java 对象根据其年龄和引用分配到这些区域,然后从新生代移动到老年代。
Eden 空间中大部分堆使用很快被回收。未释放的堆会移动到 Survivor 空间(S0 或 S1),通常按照指数衰减模式回收。如果对象在此仍然存在,它将移动到老年代(Tenured space)。
JVM 堆内存总量 = 新生代(Eden 区和 Survivor 区 S0 与 S1)+ 老年代(Tenured)
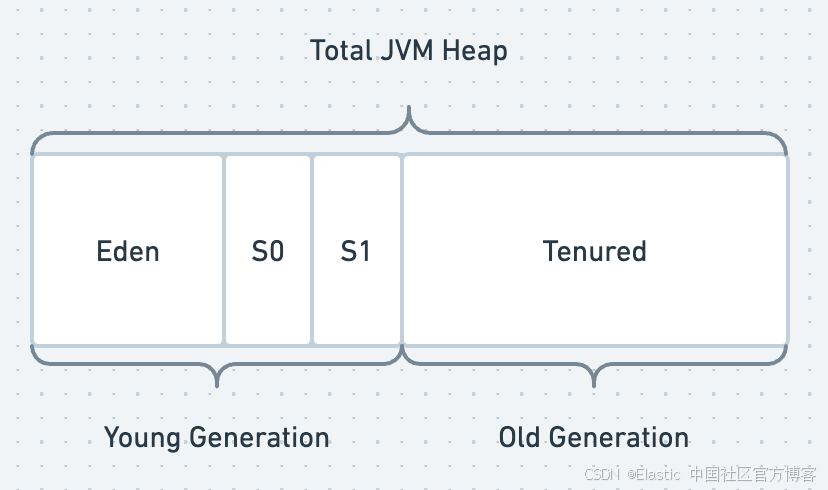
新生代区域
当任何 Java 应用程序启动时,它会创建新对象,并将这些新对象分配到称为堆内存的区域。新生代的 Eden 区是应用程序分配新创建对象的第一个地方。该区域专门用于分配新对象。当 Eden 区满时,符合条件的对象要么被回收(垃圾回收),要么被提升到其他区域。
当发生 Minor GC(小型垃圾回收)时,被引用的对象会移动到另一个子区域 Survivor 区 S0,而未被引用的对象会被删除以释放 Eden 空间。这一区域包含在垃圾回收过程中幸存的对象,因此称为 Survivor 区。
当 Eden 区再次满时,同样的循环会重复。这时,在 Eden 和 S0 中幸存的对象会被移动到 S1 区,这一过程持续进行。
在 Eden、S0 和 S1 中幸存的对象会根据年龄计算器被提升到老年代。
老年代区域
老年代(也称为 Tenured Generation)是一个存放长生命周期对象的区域,这些对象在新生代经历了多次垃圾回收(Minor GC)后仍然存在。经历 Survivor 区一定次数的对象会被算法移动到老年代,这一过程称为对象提升(object promotion)。
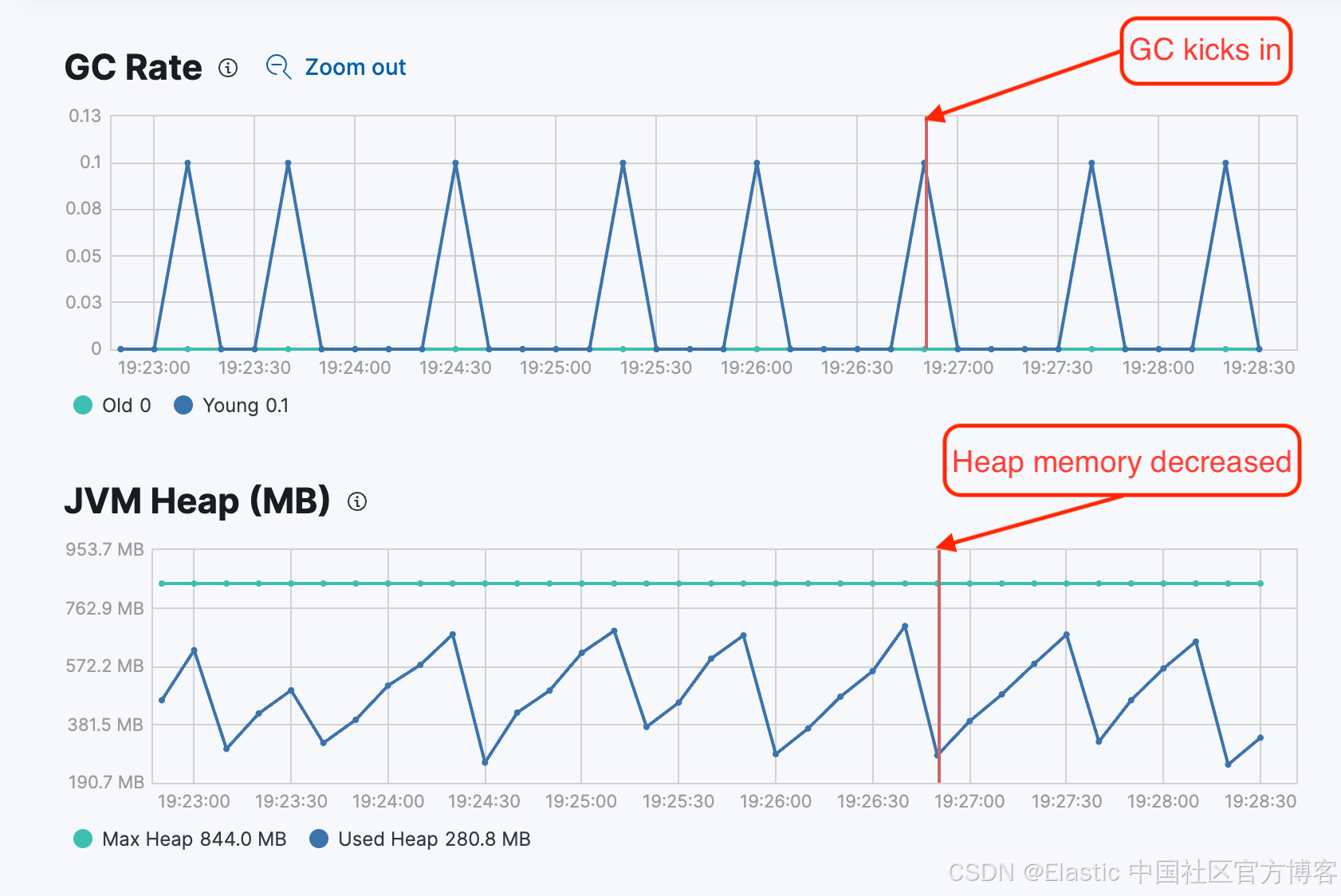
上图的锯齿状 GC 模式从堆监控中显示,当发生 Minor GC(小型垃圾回收)时,JVM 堆内存会减少,因为 GC 正在移除内存中不需要的对象。经过几个周期后,对象会积累,GC 会再次触发以清理这些对象。
垃圾回收方法
Elasticsearch 附带了支持的捆绑 JDK 版本,详细信息记录在发布说明中。直到 v6.4,Elasticsearch 使用的是并发标记清除(CMS)垃圾回收器,该回收器在 JDK9 中被弃用。现在 Elasticsearch 默认使用 Garbage-First(G1)垃圾回收器。与 CMS GC 方法相比,G1GC 的性能更好。G1GC 的内部机制复杂,包含多个阶段,但我们可以简单了解其基本原理。
要使用 G1GC,可在 Elasticsearch JVM 选项中使用 JVM 标志 -XX:+UseG1GC。在 G1GC 中,堆总区域会被划分为大小相等的区域 -XX:G1HeapRegionSize=1m,大小可根据堆大小在 1MB 到 32MB 之间变化。Eden、Survivor 和老年代是这些区域的逻辑集合,并不是连续的。此外,堆内还有 humongous 区和空闲/可用区。humongous 区用于分配大于区域一半大小的对象。
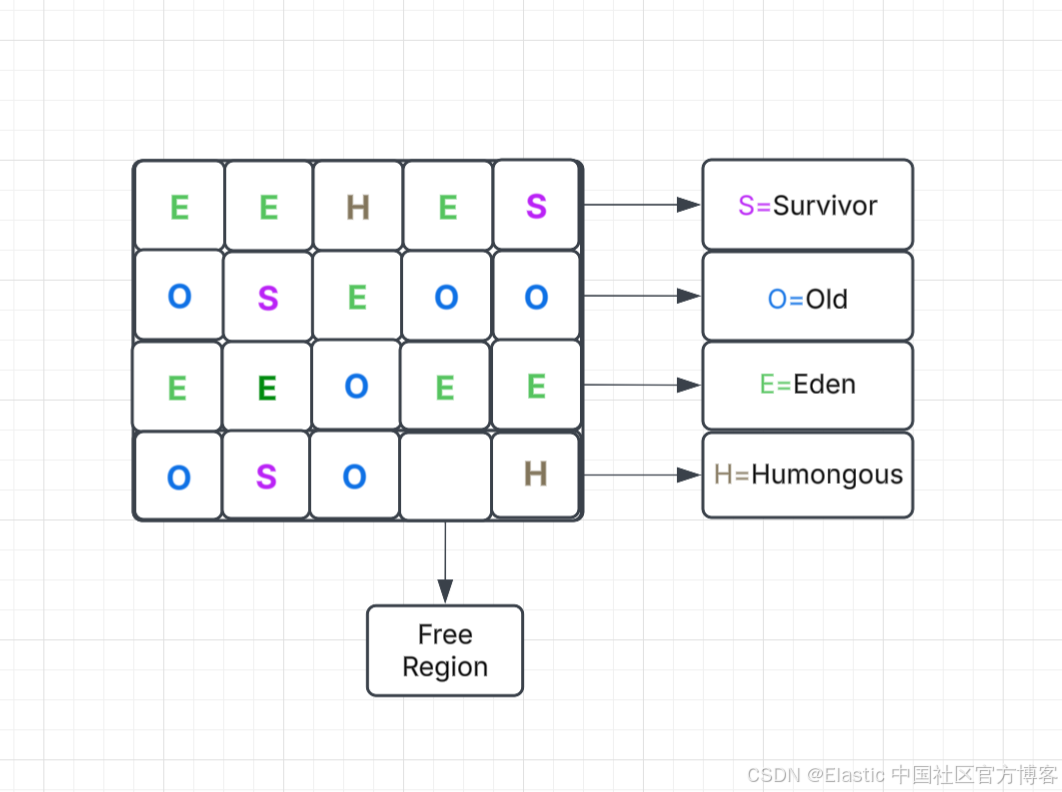
G1GC 有一个暂停时间目标(-XX:MaxGCPauseMillis=200),它会在垃圾回收过程中尽量满足该目标。这意味着在垃圾回收期间,JVM 的暂停时间不会超过这个值,这比 CMS 或其他垃圾回收器更好,因为它们没有此选项。总体而言,建议保持 GC 设置为默认值,这样可以在提升性能的同时将 GC 暂停控制在限制范围内。
Elasticsearch JVM 状态的 API
Elasticsearch 执行的任何任务都需要请求 JVM 分配一些内存以执行操作。如上所述,JVM 代表 Elasticsearch 处理内存管理,因此 Elasticsearch 不必担心。然而,管理员可能希望通过 Elasticsearch API 检查 JVM 状态,以确保系统按预期运行。
要查看为 Elasticsearch JVM 指定或作为输入参数提供的所有设置,可使用带有 JVM 属性的 node info API(文档中也有描述)。
GET _nodes/_all/jvm 该 API 会提供节点配置的详细信息,包括 JVM 输入参数、内存池和堆大小。
此外,如果你想查看某个节点的 Elasticsearch JVM 指标,如节点运行时间、所有内存池的堆使用情况或垃圾回收统计信息,可以使用 node statisticsAPI。它会提供上述每个指标的详细数据。
GET _nodes/stats/jvm
or
GET _nodes/stats/jvm?filter_path=nodes.*.jvm注意:Elasticsearch 不建议根据从 nodes stats API 获取的 heap_percent 值做出决策。我们的 UI 会计算内存压力,用户应根据本文中描述的计算结果采取必要的操作。
使用内置 JDK 工具检查 JVM 指标
如果你是高级用户,想在不使用 Elasticsearch API 的情况下查看运行中 JVM 的实时统计信息,可以使用捆绑的 java 并运行 jstat 检查实时数据。为此,首先找到 Java 的 home 目录或 bin 目录,以及 Elasticsearch 进程的 PID。在 bin 目录中使用 jstat 工具:
./jstat -gcutil <PID> 2000这里的 2000 是以毫秒为单位的间隔,表示每隔多长时间获取统计信息并在 CLI 上打印。此命令有助于识别各个区域的 GC 发生频率,以及对象(对象创建和提升)填充内存池的速度。
这不是上述 API 的替代方法,而更多用于开发者级别的调试。
总结
在本文中,我们介绍了 Java 虚拟机的基本概念、各种内存池、垃圾回收的重要性,以及如何检查 Elasticsearch JVM 指标。在下一篇博客中,我们将讨论重要的 JVM 设置以及如何在 Elasticsearch 中轮询当前指标。
如果你有任何问题或需要进一步支持,请随时联系我们。我们始终乐意提供帮助!
- Elastic 支持
- Elastic 讨论论坛
- Elastic 咨询
- Elastic 培训
本文中描述的任何功能或特性的发布和时间完全由 Elastic 决定。任何当前不可用的功能或特性可能无法按时或根本无法交付。
原文:JVM essentials for Elasticsearch: Metrics, memory, and monitoring | Elastic Blog