Linux 文本处理命令详解
1. cut 命令
cut 命令是 Linux 系统中用于从文本文件或标准输入中提取指定列或字符的工具,主要适用于处理结构化数据(如以特定分隔符分隔的表格、配置文件等),其核心功能是按位置或分隔符拆分文本并提取所需部分。
1.1 基本语法
cut [选项] [文件]
若不指定文件,cut 命令将从标准输入(如管道传递的数据或键盘输入)中读取内容。
1.2 常用选项
- -f 字段列表:按 “字段” 提取内容,“字段列表” 可表示为:
- 单个字段(如-f 3,提取第 3 个字段);
- 多个不连续字段(如-f 1,3,提取第 1 和第 3 个字段);
- 连续字段(如-f 2-5,提取第 2 到第 5 个字段)。
- -d 分隔符:指定字段的分隔符(默认分隔符为制表符\t),例如-d ":"表示以冒号作为分隔符。
- -c 字符位置列表:按 “字符位置” 提取内容,“字符位置列表” 格式与字段列表类似(如-c 1-4提取每行的第 1 到 4 个字符,-c 6提取第 6 个字符)。
1.3 实操示例
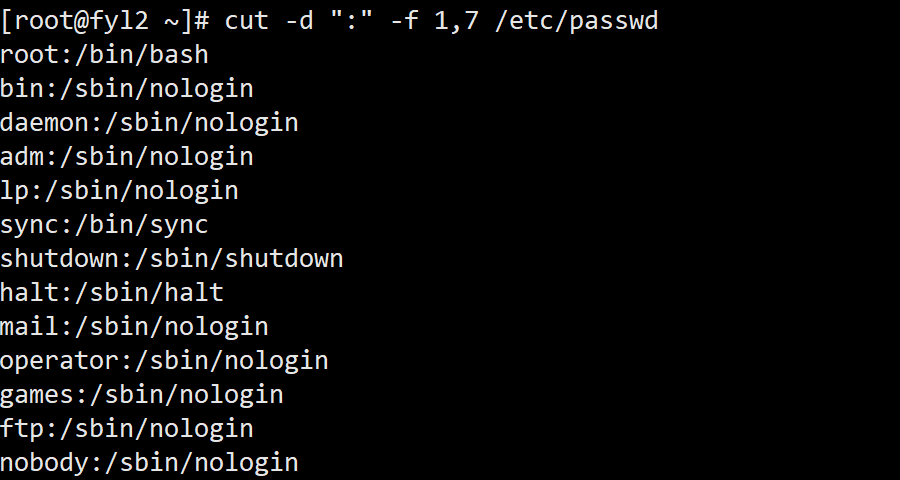
- 从/etc/passwd文件中提取用户名(第 1 个字段)和默认 shell(第 7 个字段),文件以冒号分隔:
cut -d ":" -f 1,7 /etc/passwd
输出结果示例:
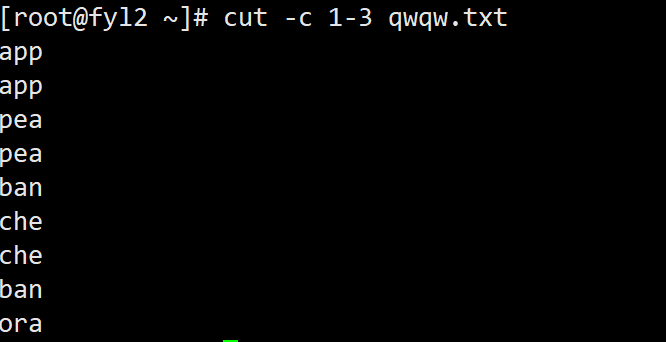
- 提取文本文件qwqw.txt每行的前 3 个字符:
2. sort 命令
sort 命令用于对文本内容进行排序,可根据不同规则(如字母顺序、数值大小、月份等)对文本行进行升序或降序排列,是处理批量数据时的常用工具。
2.1 基本语法
sort [选项] [文件]
若不指定文件,sort 命令将对标准输入的内容进行排序。
2.2 常用选项
- -n:按 “数值大小” 排序(默认按字符串的 ASCII 码值排序,可能导致 “10” 排在 “2” 之前,使用-n可避免此问题)。
- -r:反向排序(默认按升序排列,-r表示降序)。
- -k 字段编号:指定按第几个字段进行排序(需结合-t指定分隔符),例如-t ":" -k 3表示以冒号为分隔符,按第 3 个字段排序。
- -t 分隔符:指定字段的分隔符(与-k配合使用)。
- -u:去除排序后的重复行(仅保留一行)。
- -o 输出文件:将排序结果写入指定文件(默认输出到标准输出)。
2.3 实操示例
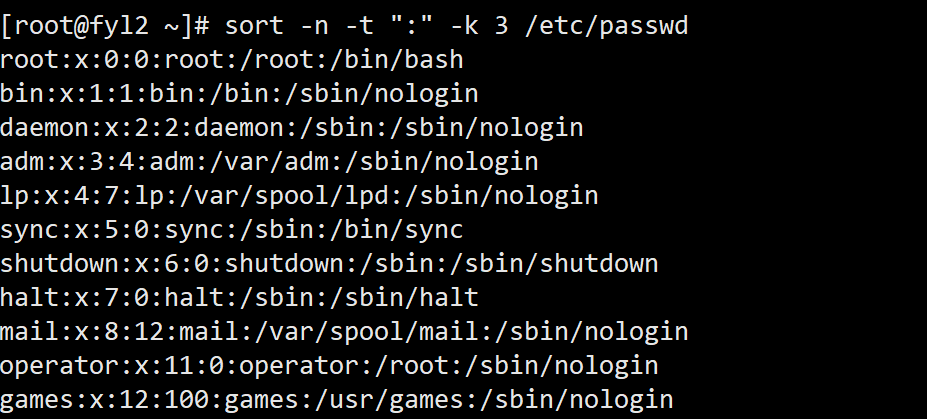
以冒号为分隔符,按/etc/passwd文件中第 3 个字段(用户 ID,UID)的数值升序排序:
输入sort -n -t ":" -k 3 /etc/passwd
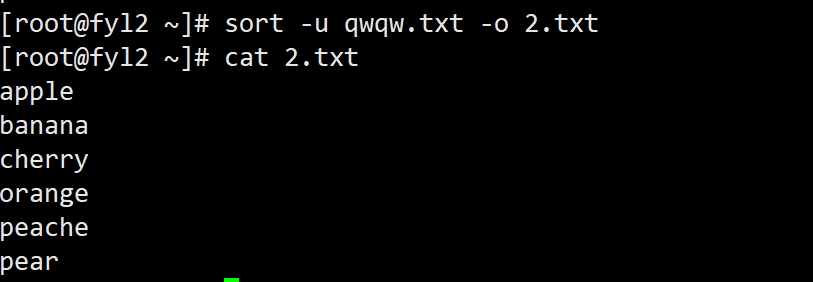
- 对qwqw.txt文件排序并去除重复行,结果保存到2.txt:sort -u qwqw.txt -o unique_words.txt
3. uniq 命令
uniq 命令用于处理文本中连续的重复行,可实现去除重复行、统计重复次数等功能。注意:uniq 仅对 “连续重复” 的行有效,若需处理非连续的重复行,需先使用 sort 命令排序(使重复行连续)。
3.1 基本语法
uniq [选项] [输入文件] [输出文件]
若不指定输入文件,uniq 命令将从标准输入读取内容;若不指定输出文件,结果将输出到标准输出。
3.2 常用选项
- -c:在每行前添加 “重复次数”(统计每行连续出现的次数)。
- -u:仅显示 “不重复的行”(即只出现一次的行)。
- -d:仅显示 “重复的行”(即至少出现两次的行)。
- -i:忽略大小写(将大小写不同的行视为相同行)。
3.3 实操示例
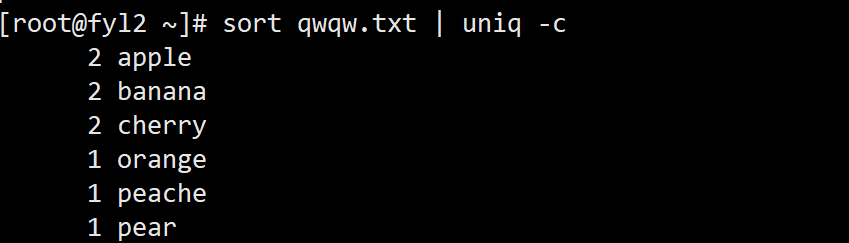
- 统计qwqw.txt文件中每行的重复次数(需先排序使重复行连续):
sort qwqw.txt | uniq -c
输出结果示例:
- 显示qwqw.txt中仅出现一次的行:

- 显示qwqw.txt中重复的行:

4. tr 命令
tr 命令用于对文本中的字符进行转换、删除或压缩,它从标准输入读取内容,按指定规则处理后输出到标准输出,不直接处理文件(需通过管道或重定向配合)。
4.1 基本语法
tr [选项] 字符集1 字符集2
其中,“字符集 1” 和 “字符集 2” 是需要转换的字符对应关系(如tr a-z A-Z表示将小写字母转换为大写字母)。
4.2 常用选项
- -d 字符集:删除 “字符集” 中包含的所有字符(如tr -d 0-9删除所有数字)。
- -s 字符集:压缩 “字符集” 中连续重复的字符为单个(如tr -s ' '将多个连续空格压缩为一个)。
4.3 实操示例
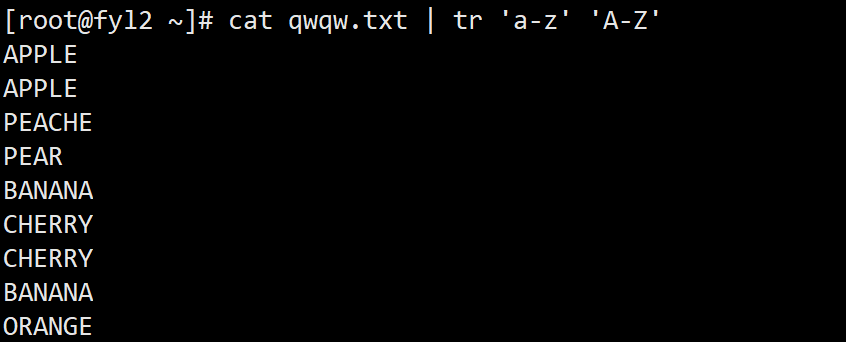
- 将qwqw.txt中的所有小写字母转换为大写字母:cat qwqw.txt | tr 'a-z' 'A-Z'
- 删除data.txt中的所有标点符号(假设标点为.,;:):
5. sed 命令
sed(Stream Editor,流式编辑器)是一种非交互式的文本处理工具,可对文本进行批量替换、删除、插入、追加等操作,支持正则表达式,常用于自动化处理配置文件、日志等。
5.1 基本语法
sed [选项] '操作指令' [文件]
若不指定文件,sed 将处理标准输入的内容。
5.2 常用选项
- -i:直接修改文件内容(默认情况下,sed 仅输出处理结果,不改变原文件)。
- -e 操作指令:执行多个操作指令(如sed -e 's/a/b/' -e 's/c/d/' file.txt)。
- -n:抑制默认输出(仅输出经过处理的行)。
- -r:启用扩展正则表达式(使正则表达式中的+、?、|等元字符无需转义)。
5.3 常用操作指令
- s / 旧字符串 / 新字符串 / 修饰符:替换文本中的字符串,“修饰符” 包括:
- g:全局替换(默认仅替换每行第一个匹配项);
- i:忽略大小写;
- p:打印替换后的行(需结合-n选项)。
示例:sed 's/error/ERROR/g' log.txt(将 log.txt 中所有 “error” 替换为 “ERROR”)。
- d:删除指定行,格式为[行范围]d,例如:
- 3d:删除第 3 行;
- 2,5d:删除第 2 到 5 行;
- /pattern/d:删除包含 “pattern” 的行。
- i / 文本:在指定行前插入文本,格式为[行号]i 文本,例如:3i hello(在第 3 行前插入 “hello”)。
- c:替换,将选定行替换为指定内容。
- p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容
- a / 文本:在指定行后追加文本,格式为[行号]a 文本,例如:/warning/a check system(在包含 “warning” 的行后追加 “check system”)。
5.4 实操示例
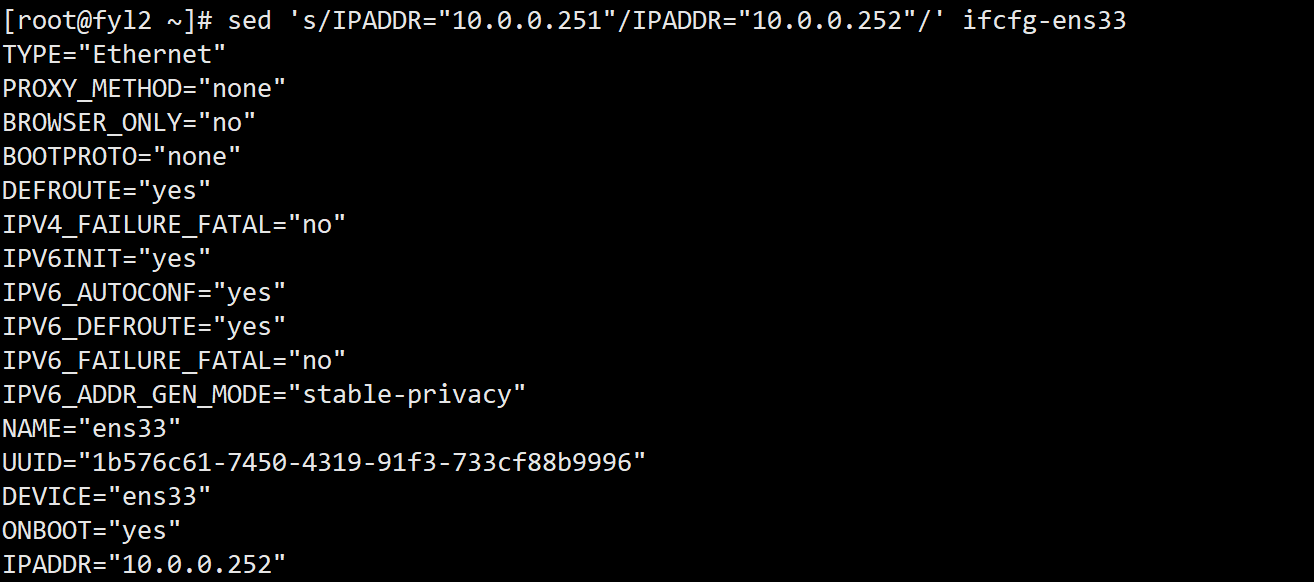
- 直接修改config.ini文件,将IPADDR="10.0.0.251" 替换为 IPADDR="10.0.0.252":
- 输入:sed 's/IPADDR="10.0.0.251"/IPADDR="10.0.0.252"/' ifcfg-ens33
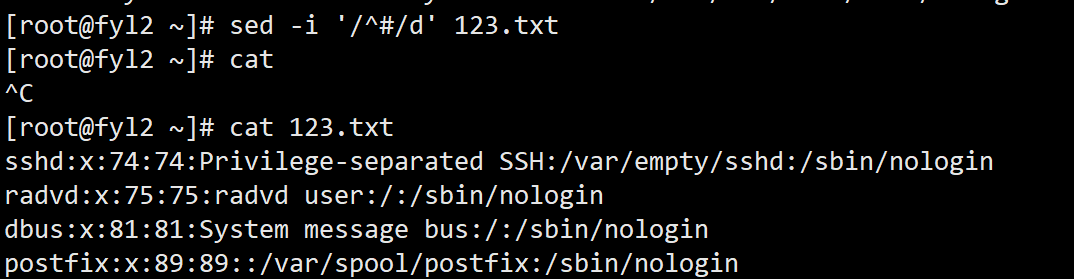
- 删除123.txt中所有以 “#” 开头的注释行:sed '/^#/d' 123.txt
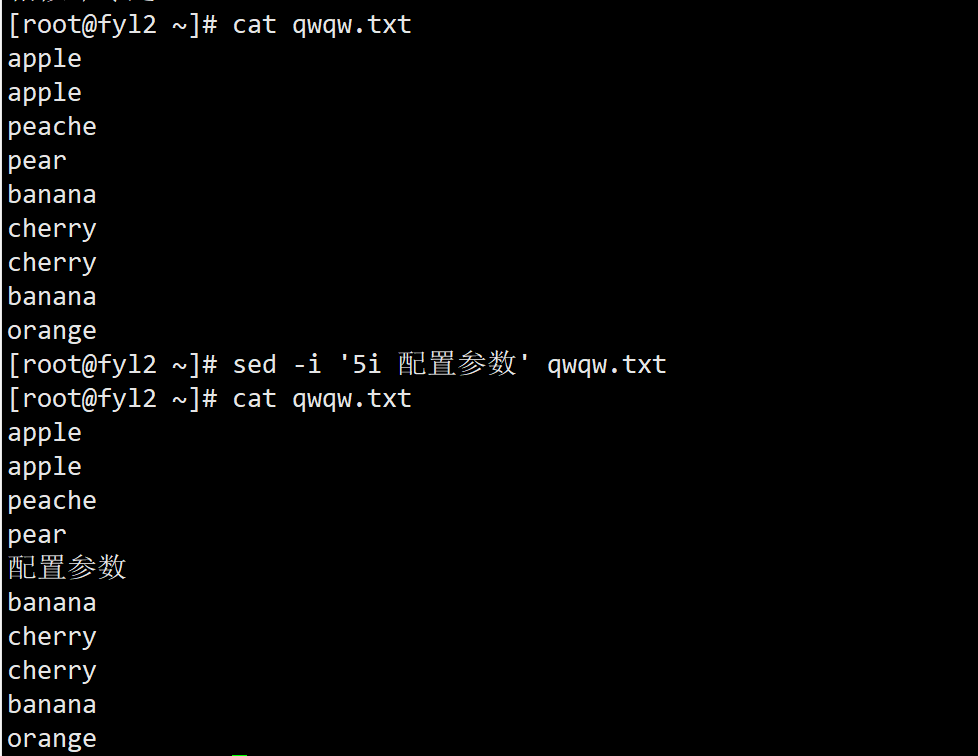
- 在qwqw.txt的第 5 行前插入文本 “ 配置参数”:sed -i '5i 配置参数' qwqw.txt
6. awk 命令
awk 是一种功能强大的文本处理语言,不仅能按字段拆分文本,还支持条件判断、循环、函数等复杂操作,特别适合处理结构化数据(如 CSV、日志等),默认以空格或制表符作为字段分隔符。
原理:
6.1 基本语法
awk '模式 {动作}' [文件]
- “模式”:用于指定处理哪些行(如条件表达式、正则表达式等),若不指定模式,将处理所有行。
- “动作”:对匹配模式的行执行的操作(如打印字段、计算等),需用{}包裹。
6.2 常用内置变量
- $0:表示整行内容。
- $n:表示第 n 个字段(如$1为第 1 个字段,$3为第 3 个字段)。
- NF:当前行的字段总数($NF表示最后一个字段)。
- NR:当前行的行号。
- FS:字段分隔符(默认是空格,可通过-F选项或BEGIN {FS="分隔符"}自定义)。
- OFS:输出字段分隔符(默认是空格,可在BEGIN {OFS="分隔符"}中设置)。
-
FNR 各文件分别计数的行号
-
ORS 输出记录分隔符(默认值是一个换行符)
-
RS:行分隔符。awk从文件上读取资料时,将根据Rs的定义把资料切割成许多条记录, 而awk一次仅读入一条记录,以进行处理。预设值是" \n'
6.3 常用模式与动作
- 模式:
- 行号:如3 {print}(处理第 3 行);
- 正则表达式:如/error/ {print}(处理包含 “error” 的行);
- 条件表达式:如$3 > 100 {print}(处理第 3 个字段大于 100 的行)。
-
模糊匹配 用~表示包含,!~表示不包含 如 '$1~/root/' (第一列包含root字段的行)
-
BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
-
END一般用来做汇总操作,仅在读取完数据记录之后执行一次
- && 和 || 是逻辑运算符,用于组合多个条件并控制程序流程,&& 要求所有条件都为真时才为真,否则为假。|| 只要有一个条件为真就为真,全为假时才为假
- 动作:
- print:打印指定内容(如print $1, $3打印第 1 和第 3 个字段);
- 条件判断:if (条件) {动作} else {动作};
6.4 实操示例
- 以冒号为分隔符,打印/etc/passwd中用户名(1)和家目录(6):
awk -F ":" '{print $1, "的家目录是", $6}' /etc/passwd
输出结果示例:

- 打印/etc/passwd每一行的行数,列数:awk -F: '{print "行数是"NR,"列数是"NF}' /etc/passwd

- 打印/etc/passwd中的第二行:awk 'NR==2{print}' /etc/passwd

-
akw的运算:比如awk 'BEGIN{x=10;print x+1}' 定义变量x=10 然后打印x+1的值

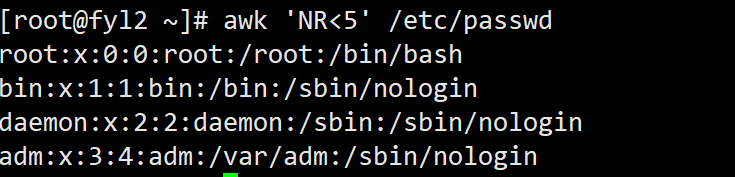
- akw的比较:比如 打印etc/passwd行数小于5的行 awk 'NR<5' /etc/passwd
- 其他内置变量使用,比如打印/etc/passwd 第一列和第二列 并且输入字段的分隔符是 “:”输出时的分隔符是“--" 输入:awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' pass.txt
