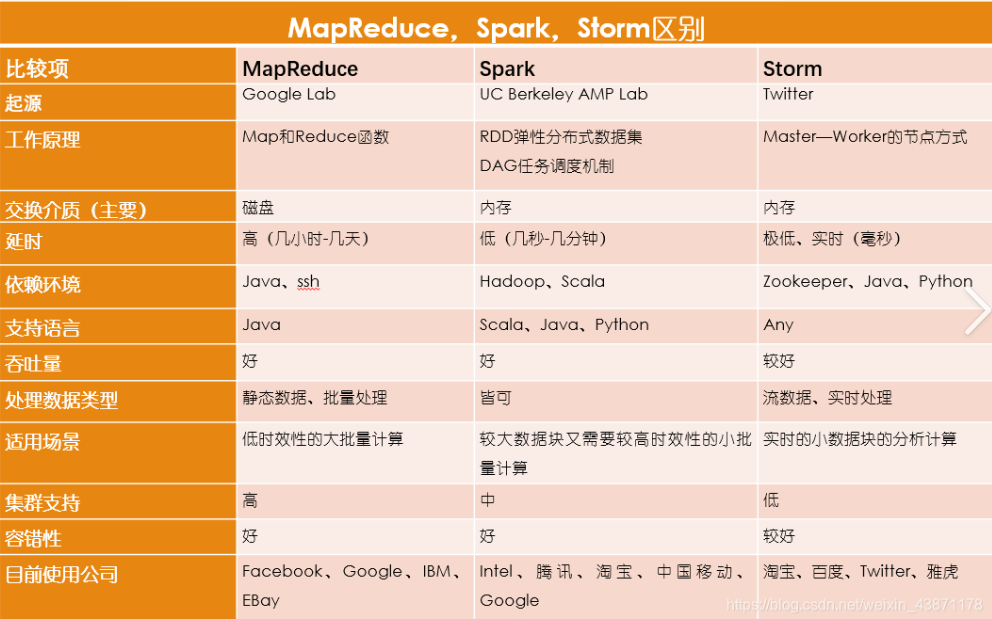
大数据领域框架繁多,各有其设计哲学和最佳应用场景。下面我将从批处理、流处理、交互式查询、OLAP、资源调度等多个维度,对常用的大数据框架进行系统的对比。
核心框架分类对比
1. 批处理框架 (Batch Processing)
主要用于处理海量的、静态的历史数据,通常有高延迟(分钟到小时级)。
| 框架 | 核心理念 | 编程模型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| Apache Hadoop MapReduce | 分而治之,在磁盘上处理 | Map, Reduce | 成熟稳定、容错性强、适合超大规模数据 | 速度慢(大量磁盘I/O)、API繁琐、开发复杂度高 | 超大规模数据的离线批处理(ETL、日志分析、数据挖掘),目前逐渐被更高效的框架替代 |
| Apache Spark | 基于内存的迭代计算 | RDD, DataFrame/Dataset | 速度极快(内存计算)、API丰富易用(Scala/Java/Python/R)、生态强大(Spark SQL, MLlib) | 流处理是微批模式,延迟较高(秒级) | 主流的批处理首选,快速ETL、机器学习、交互式查询、需要与流处理统一的场景 |
2. 流处理框架 (Stream Processing)
用于处理无界的、实时产生的数据流,追求低延迟(毫秒到秒级)。
| 框架 | 核心理念 | 处理模型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| Apache Storm | 最早的流处理框架之一 | Record-by-record (逐条) | 延迟极低(毫秒级)、成熟稳定 | 不能保证精确一次(Exactly-Once)(Trident可以,但性能下降)、API相对底层 | 对延迟极其敏感的实时监控、告警场景 |
| Apache Spark Streaming | 将流数据切成小批量处理 | Micro-Batch (微批) | 与Spark生态无缝集成、Exactly-Once语义、开发简单 | 延迟较高(秒级,无法毫秒级)、微批本质 | Lambda架构中的速度层、需要与批处理共用代码和逻辑的场景 |
| Apache Flink | 真正的流处理,流批统一 | Record-by-record (逐条) | 低延迟、高吞吐、 Exactly-Once语义、流批一体API、状态管理强大 | 相对Spark,与Hadoop生态集成稍弱(但在改善) | 实时数据 pipeline、事件驱动型应用、实时报表、需要取代Lambda架构的Kappa架构 |
| Apache Kafka Streams | 一个客户端库而非集群框架 | Record-by-record (逐条) | 轻量级(无需额外集群)、直接集成Kafka、Exactly-Once | 功能较Flink/Spark简单,重度依赖Kafka | Kafka生态内的轻量级流处理,如实时数据转换、 enrichment |
3. 交互式查询/数据仓库 (Interactive Query & Data Warehousing)
用于快速查询大规模数据集,响应时间通常在秒到分钟级。
| 框架 | 核心理念 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Apache Hive | 将SQL翻译成MapReduce/Tez/Spark任务 | SQL语法丰富(HQL)、生态成熟、社区活跃 | 延迟高(传统MR引擎),不适合交互式查询 | 传统的数仓离线分析,Hadoop上的标准SQL接口 |
| Apache Impala | 专为HDFS/HBase设计的MPP查询引擎 | 查询速度极快(无需转MR,直接执行)、兼容Hive元数据 | 易受底层存储格式影响、内存消耗大 | Hadoop上的快速即席查询(Ad-hoc Query),替代Hive进行交互式分析 |
| Presto / Trino | 分布式MPP SQL查询引擎 | 支持多数据源联邦查询(Hive, Kafka, MySQL, ES等)、速度快 | 内存管理不如Impala稳定,大查询易OOM | 跨多种数据源的交互式分析,商业BI工具对接 |
| ClickHouse | 列式存储的OLAP数据库 | 查询性能极致快(尤其适合大宽表聚合查询)、压缩比高 | 不支持高并发查询、缺少完整的UPDATE/DELETE操作 | 单表大数据量的聚合分析,用户行为分析、日志分析、实时报表 |
4. 资源调度与协调 (Resource Management & Coordination)
这些是底层基础设施,为上层计算框架提供资源管理和分布式协调服务。
| 框架 | 角色 | 说明 |
|---|---|---|
| Apache Hadoop YARN | 资源调度器 | Hadoop 2.0的核心组件,负责集群资源(CPU、内存)的管理和调度,让MapReduce、Spark、Flink等都可以在同一个集群上运行。 |
| Apache Mesos | 资源调度器 | 另一个分布式资源管理平台,设计理念更通用,可以管理整个数据中心的资源。但生态上已被Kubernetes超越。 |
| Kubernetes (K8s) | 容器编排平台 | 云原生时代的事实标准。不仅可以管理资源,更以容器为核心,负责应用的部署、扩展和管理。Spark、Flink等都积极支持在K8s上原生运行。 |
| Apache ZooKeeper | 分布式协调服务 | 提供分布式一致性(同步、配置管理、命名注册、集群选举)等基础服务,是Hadoop HDFS, Kafka, HBase等众多分布式系统的“大脑”。 |
如何选择?一张图帮你决策
我的主要工作是什么?
离线批量ETL和分析:首选 Spark。
超低延迟(毫秒级)实时流处理:首选 Flink 或 Storm。
Kafka数据实时处理:考虑 Kafka Streams(轻量)或 Flink(功能全)。
快速的交互式SQL查询:
数据在HDFS/Hive:Impala, Presto。
需要跨多种数据源查询:Presto/Trino。
单表极速聚合:ClickHouse。
我需要统一的编程模型吗?
希望用一套代码处理流和批:Flink(流批一体)或 Spark(批处理API处理流)。
我的技术栈和基础设施是什么?
传统Hadoop集群:YARN作为资源调度,Spark/Flink on YARN。
云原生/Kubernetes环境:优先选择对K8s支持好的框架,如 Flink、Spark on K8s。
社区和生态活跃度
Spark 和 Flink 是当前最活跃的两个生态,社区庞大,未来发展有保障。ClickHouse 和 Presto/Trino 在OLAP领域也非常活跃。
总结与趋势
批处理:Spark 是绝对的主流,MapReduce已逐渐退出历史舞台。
流处理:Flink 凭借其真正的流处理、低延迟和流批一体的优势,已经成为新项目的首选,挑战着 Spark Streaming 的地位。
交互式查询:Presto/Trino 和 ClickHouse 因其高性能和灵活性,应用越来越广泛。
底层基础设施:Kubernetes 正在成为大数据框架运行的新一代资源管理和调度标准,是未来的大趋势。
最终的选择没有绝对的对错,需要根据你的具体业务需求、数据规模、团队技术栈和运维能力来综合考量。通常,一个成熟的大数据平台会混合使用多种框架。