文章目录
深入解析Java HashCode计算原理 少看大错特错的面试题
前言
首先了解这一篇文章我们先要知道 HashCode是干什么得,才能深入得了解HashCode!
hashCode方法可以这样理解:它返回的就是根据对象的内存地址换算出的一个值。这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置。 这段话来自面试题中得讲解,想必很多人都看过,这句话讲的是不对的,那么本篇主要讲述得内容就是HashCode 计算得过程。
HashCode 出处
通过前言应该也大概明白了HashCode 是干什么得了,那么接下来我讲解一下这个HashCode得出处。
估计大家都知道map一定是会使用HashCode得,这里决定调用谁谁谁得hashCode由Map得kay得类型而决定,众所周知map不能使用基本数据类型 这里要搞清楚 Java得封装数据类型是对基本数据类型得封装。当map kay得类型 如String Long 或者是自定义类得时候 只要父类重写了hashCode 那么调用得就是调用的是重写得那个hashCode,没有重写HashCode 调用的是 Object 类的 hashCode(),这是 native 方法(由 C/C++ 实现),Java 调试器无法进入 native 方法。
String HashCode
底层数组存储介绍
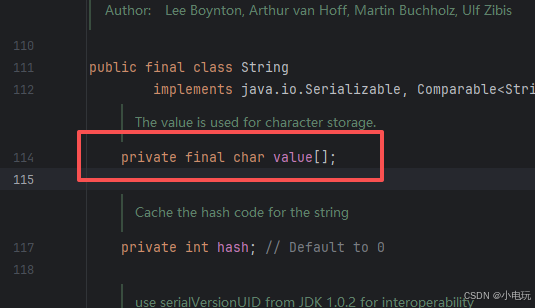
这里我们要清楚我们不用过多关心这个我赋值得时候明明是字符串 为什么这里怎么debug都debug不到它变成了char数组了呢 或者是1.8以后得byte数组了呢 ,这个转换得过程我们不用过多的关心 字符串字面量(如 “1”)转换为 char 数组的过程并不是由 String 类的 Java 源码直接实现的,而是由 Java 编译器(javac) 和 类加载机制 共同完成的,最终通过 String 类的特殊构造逻辑初始化 char value[] 数组。
若要搞清楚这个String底层得原理和加载机制 后续我会再写一篇关于String 从启动到使用过程得底层讲解。
char数组得值讲述
public static void main(String[] args) throws Exception {
String a = "1233";
// 显示当前默认字符集
Charset defaultCharset = Charset.defaultCharset();
System.out.println("当前默认字符集: " + defaultCharset.displayName());
System.out.println("字符集别名: " + String.join(", ", defaultCharset.aliases()));
System.out.println("字符集编码: " + defaultCharset.name() + "\n");
// 通过反射获取String类的value字段
Field valueField = String.class.getDeclaredField("value");
valueField.setAccessible(true); // 允许访问私有字段
// 获取字符串对象的字符数组
char[] value = (char[]) valueField.get(a);
// 输出数组长度
System.out.println("char数组长度: " + value.length);
// 遍历数组,输出每个字符及其Unicode码
for (int i = 0; i < value.length; i++) {
System.out.printf("索引 %d: 字符='%c' Unicode码=0x%04X (%d)%n",
i, value[i], (int) value[i], (int) value[i]);
}
//todo 执行结果
// 当前默认字符集: UTF-8
// 字符集别名: unicode-1-1-utf-8, UTF8
// 字符集编码: UTF-8
// char数组长度: 3
// 索引 0: 字符='1' Unicode码=0x0031 (49)
// 索引 1: 字符='2' Unicode码=0x0032 (50)
// 索引 2: 字符='3' Unicode码=0x0033 (51)
System.out.printf("hashCode:%d", a.hashCode());
} public static void main(String[] args) throws Exception {
String a = "1233";
// 显示当前默认字符集
Charset defaultCharset = Charset.defaultCharset();
System.out.println("当前默认字符集: " + defaultCharset.displayName());
System.out.println("字符集别名: " + String.join(", ", defaultCharset.aliases()));
System.out.println("字符集编码: " + defaultCharset.name() + "\n");
// 通过反射获取String类的value字段
Field valueField = String.class.getDeclaredField("value");
valueField.setAccessible(true); // 允许访问私有字段
// 获取字符串对象的字符数组
char[] value = (char[]) valueField.get(a);
// 输出数组长度
System.out.println("char数组长度: " + value.length);
// 遍历数组,输出每个字符及其Unicode码
for (int i = 0; i < value.length; i++) {
System.out.printf("索引 %d: 字符='%c' Unicode码=0x%04X (%d)%n",
i, value[i], (int) value[i], (int) value[i]);
}
//todo 执行结果
// 当前默认字符集: UTF-8
// 字符集别名: unicode-1-1-utf-8, UTF8
// 字符集编码: UTF-8
// char数组长度: 3
// 索引 0: 字符='1' Unicode码=0x0031 (49)
// 索引 1: 字符='2' Unicode码=0x0032 (50)
// 索引 2: 字符='3' Unicode码=0x0033 (51)
// 索引 3: 字符='3' Unicode码=0x0033 (51)
System.out.printf("hashCode:%d", a.hashCode());
}
通过上述代码我们进行开始讲解至于整个过程为什么会识别为UTF-8则是指定优先使用 JVM 启动参数 指定的字符集 若未指定,则根据 操作系统的默认编码 和 区域设置(Locale) 自动推断(例如 Windows 系统默认可能是 GBK,Linux/macOS 通常是 UTF-8)。
通过上述代码我们已经获取到了49,50,51,51。Java 底层把每个字符都拆分开来了 获取到了数组中得三个值
那么这个49,50,51,51则是把字符串转换为十进制得到得结果 就是这个49,50,51,51了。
hashCode计算过程
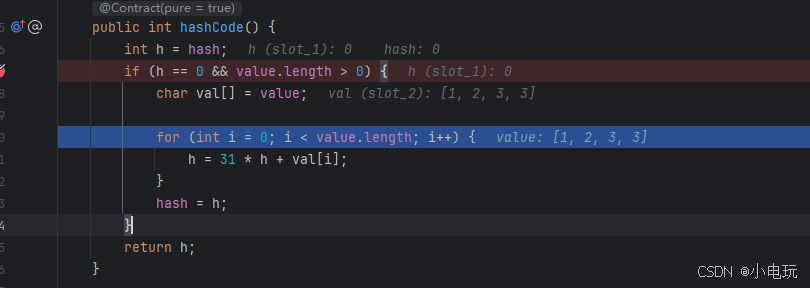
通常我们在这里调试得时候我们会看到这里是要循环value数组得值进行计算。
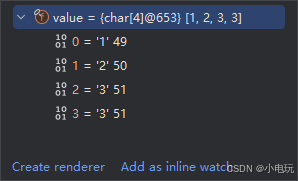
通过这张图片我们能看到 每个值都有对应的十进制得值。
那么这里进行计算得时候则是取val数组中的字符得十进制进行计算得 也就是说第一次计算:h =310+49 最后得结果等于49 。要是有人不明白310 为啥等于零的话可以自行实践。
那么我们已经明白了是怎么计算得了 那么我给出整个计算得过程:
第一次 h =310+49 结果49,第二次 h =3149+50 结果1569,第三次 h =311569+51 结果48690
,第四次 h =3148690+51 结果1509441。这就得到了hashCode得值了。
Integer HashCode
public static void main(String[] args) throws Exception {
Integer a = 1233;
Integer b = 1233;
System.out.println("a的哈希值: " + a.hashCode());
System.out.println("b的哈希值: " + b.hashCode());
System.out.println("a的内存地址标识: " + System.identityHashCode(a));
System.out.println("b的内存地址标识: " + System.identityHashCode(b));
//todo 输出结果
// a == b 的结果: false
// a的哈希值: 1233
// b的哈希值: 1233
// a的内存地址标识: 1163157884
// b的内存地址标识: 1956725890
}
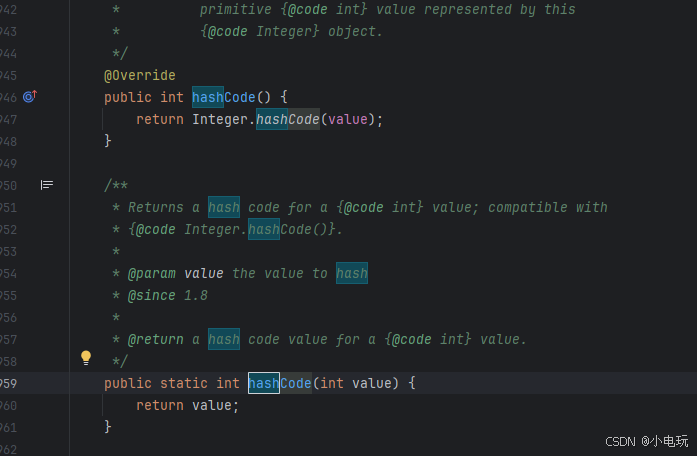
我们可以看出Integer得hashCode是直接把值返回出去当作hashCode
Long HashCode
public static void main(String[] args) throws Exception {
Long a = 1233L;
Long b = 1233111111111111111L;
System.out.println("a的哈希值: " + a.hashCode());
System.out.println("b的哈希值: " + b.hashCode());
System.out.println("a的内存地址标识: " + System.identityHashCode(a));
System.out.println("b的内存地址标识: " + System.identityHashCode(b));
//todo 输出结果
// a的哈希值: 1233
// b的哈希值: -1555982910
// a的内存地址标识: 1163157884
// b的内存地址标识: 1956725890
}
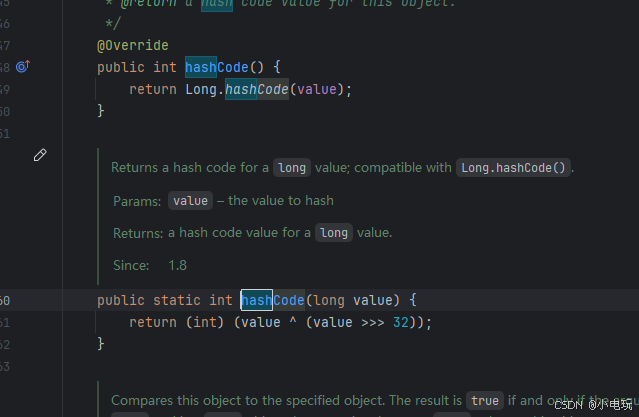
通过hashCode得源码我们可以看的出来 这里得是通过位运算进行计算得。
那么在深入理解得过程中我们要搞明白 这是怎么计算得,首先位运算在计算得过程中会把数字转换为二进制,那么long我们要知道是64位得 意思说转换二进制计算最多64位,其次它得存储上线是百兆也就是十九位。
这里得位运算数字转换为64位的大数字拆成 “前 32 位” 和 “后 32 位”,先把 “前 32 位” 挪到 “后 32 位” 的位置(左边补 0),再和原数字对比 “每一位”(相同为 0,不同为 1)这里有进行转换位int 那么就是取值右边32位转换成int 进行返回。
这里就不在过多得介绍其他得封装类型了。
类 hashCode
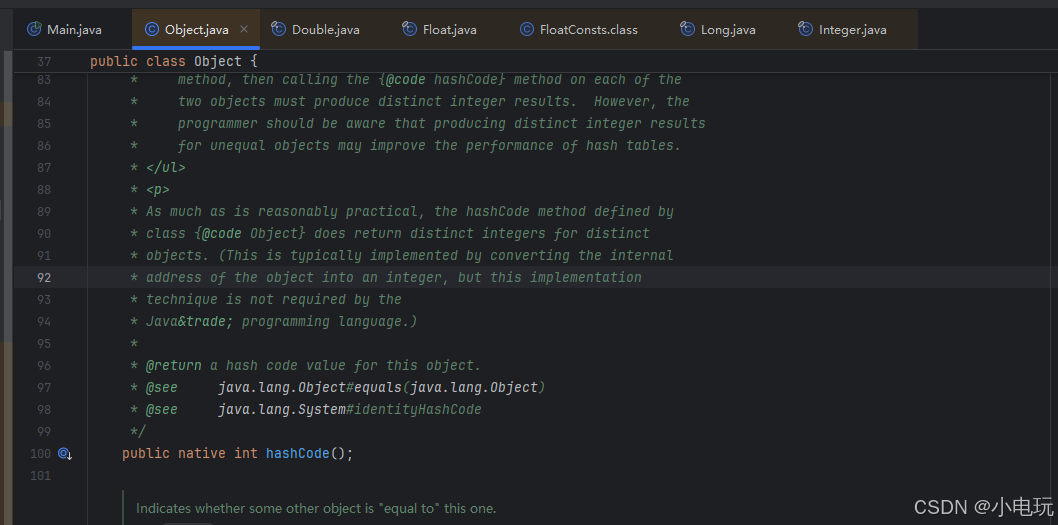
This is typically implemented by converting the internal
- address of the object into an integer, but this implementation
- technique is not required by the
- Java™ programming language.
我们从这里的注释我们能看到 阿里说的面试题是对的,但是 要清楚 重写了就不对了 不重写要使用Object的
这里的注释说的是 这通常是通过将对象的内部地址转换为整数来实现的 但JavaTM 编程语言不需要这种实现技术。
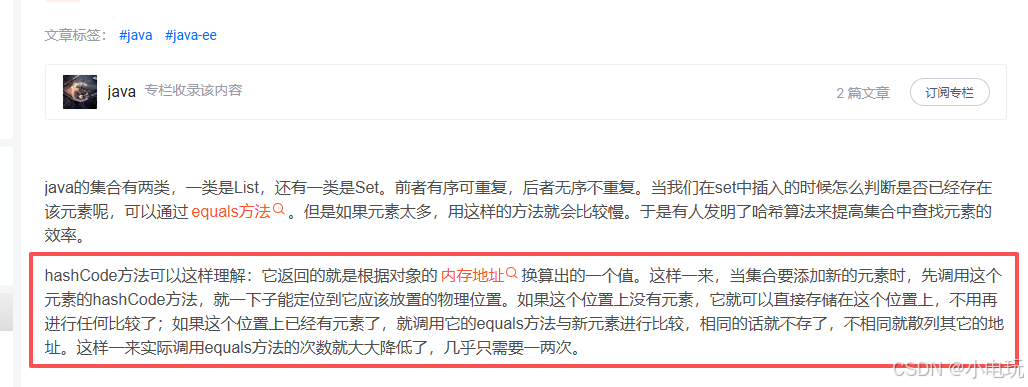
这个我是从别人的博客上看到的 ,我能明确它看的是阿里的面试题 这个博客大概率是照着面试题抄的 只抄一半那就不对了 意思就变了 ,这一块说的太明确 太全面 就不对了 要明确说明 你是重写不重写的情况。重写了 用的是自己的hashCode进行计算的 自己没有重写才使用Object的。当我看到这个面试题的时候我很气愤,写的什么玩意面试题 。不如自己来写。