前言
在多核CPU普及的互联网时代,串行编程已难以释放硬件性能,Java并行计算成为突破系统瓶颈的关键技术。然而,线程安全、死锁、资源竞争等问题,常让开发者在并行开发中望而却步。本文不堆砌枯燥的理论概念,而是聚焦实战场景,让你真正理解并行计算,写出高效代码。

概念回顾
1.什么是并发?什么是并行?
并发:多个事件在同一时间段内发生,如JD电商大促的抢购;
并行:多个事件在同一时刻发生,如多核CPU同时运行程序。
2.什么是进程?什么是线程?
进程:操作系统(Operating System)进行资源分配的基本单位,即程序执行的单元,如你一边放QQ音乐,一边看爱奇艺视频,那么这个QQ音乐和爱奇艺视频就对应两个进程;
线程:进程内部的基本执行单位,CPU调度的最小单位,一个进程可包含多个线程,比如微信的后台至少有两个线程在“待命”——1.消息接受线程:持续监听新消息;2.界面显示线程:展示聊天窗口、朋友圈页面。
它们之间的关系就像工厂和生产线(分别对应进程和线程)。进程有独立的地址空间,而线程没有;同一进程下的线程之间可以进行资源共享,进程之间的资源是相互独立的。
3.什么是并行系统?什么是分布式系统?
并行系统:指在同一台物理设备(如计算机)上,利用多个处理器(或多核CPU)同时执行多个任务的系统,如气象部门处理复杂科学计算的高性能计算并行系统;
分布式系统:指由多台独立的物理设备(如服务器)通过网络连接而成,协同工作从而共同完成一个复杂任务的系统,如微信、QQ这种超大型分布式系统,稳定支撑海量用户同时在线、高频交互。
简单来说,并行系统是“集中力量办大事”,分布式系统是“分散力量办难事”。
4.什么是串行计算?什么是并行计算?
串行计算:仅利用一个计算单元,按顺序逐个执行计算任务,如本地文件压缩软件(WinRAR),压缩过程中需按文件数据的顺序依次读取、编码、存储,每次只能处理一个文件,只有上一个文件处理完成后,才能开始下一个文件的处理;
并行计算:利用多个计算单元(如多核CPU、多台服务器),同时执行多个计算任务,可在大型数据建模任务中大幅压缩整体计算时间。
多线程实现方式
基础线程实现
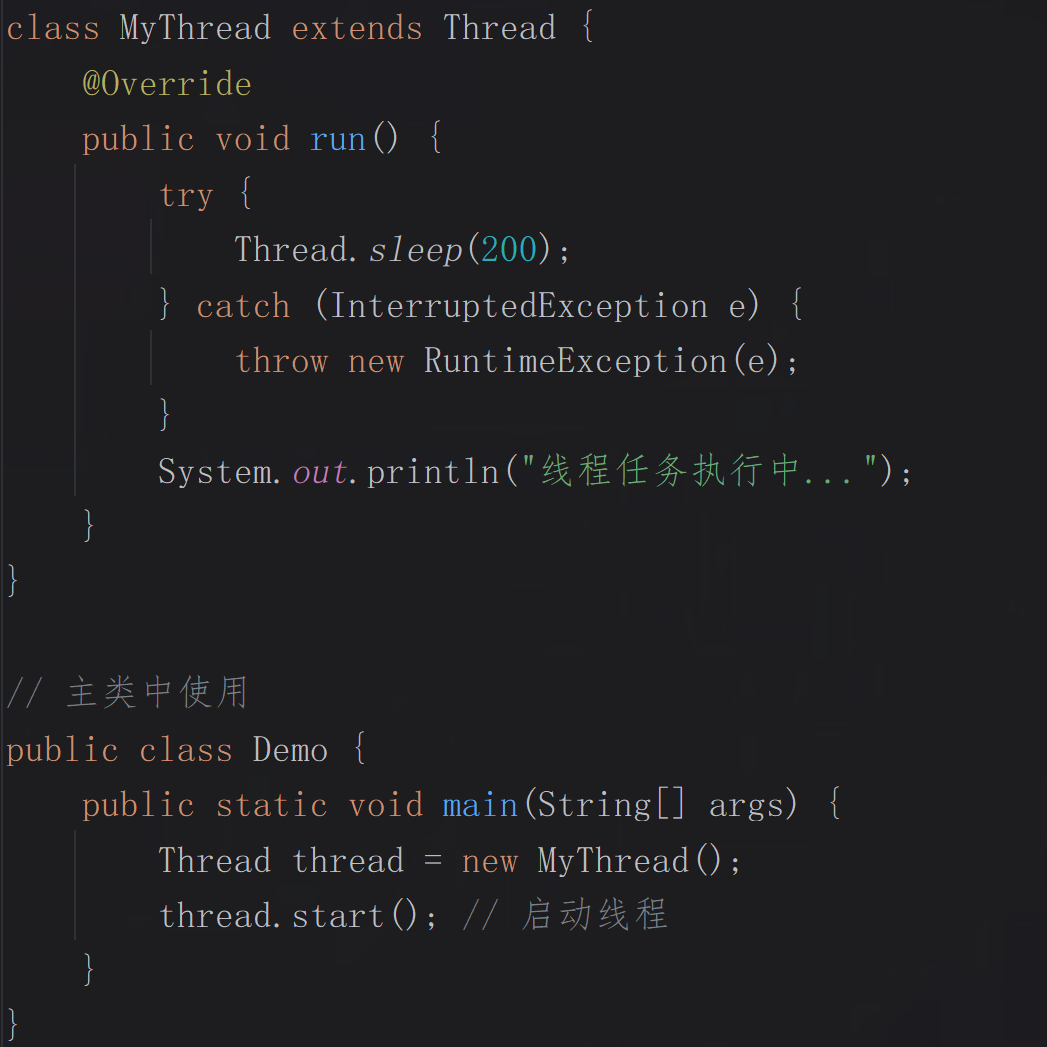
1.继承Thread类:
通过继承Java的Thread类并重写其run()方法,可以定义一个线程任务,启动线程时直接调用start()方法。这种方式简单直观,但由于Java只支持单继承,限制了类的灵活性。
代码示例:
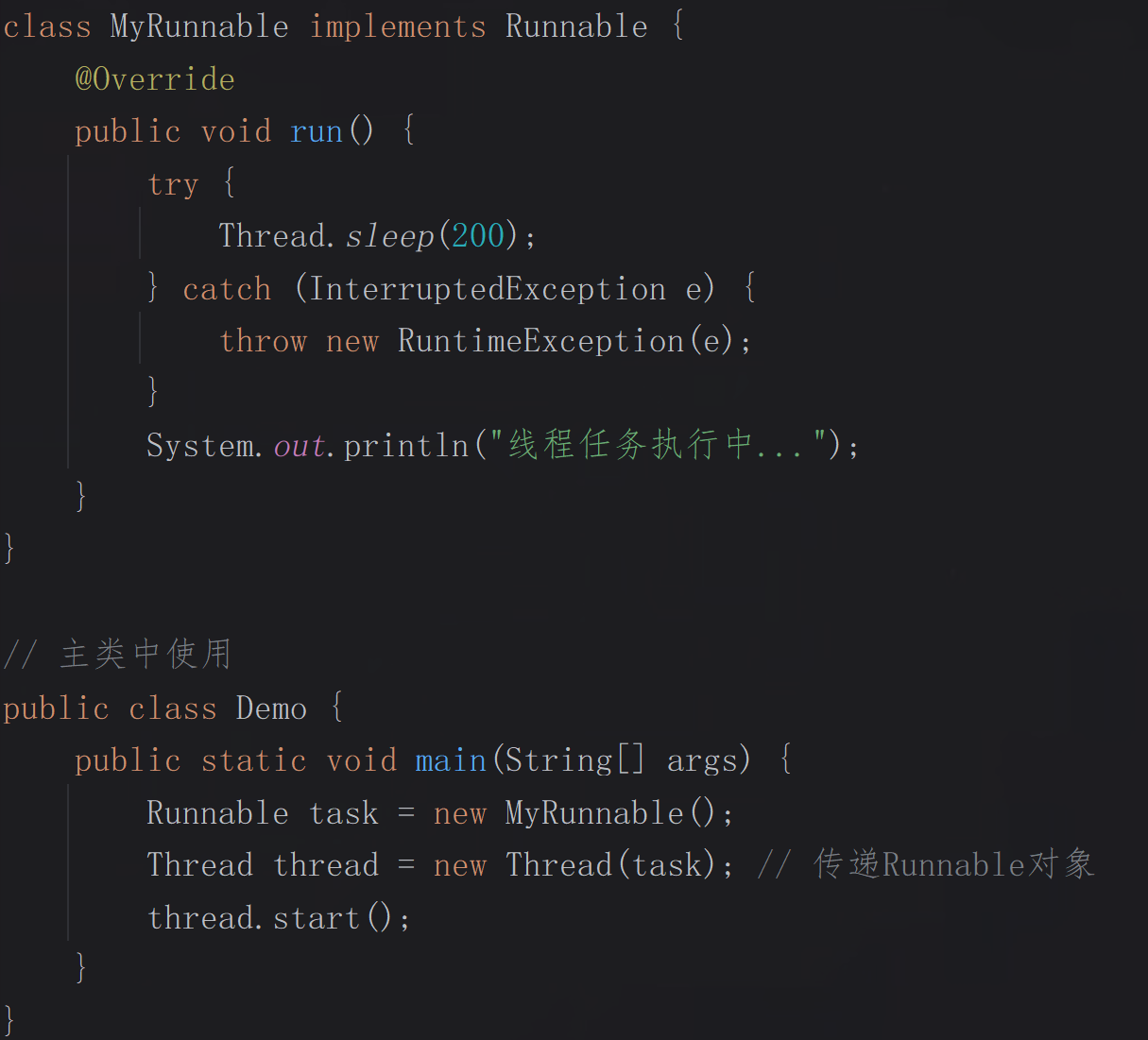
2.实现Runnable接口:
通过实现Runnable接口并定义run()方法,然后将对象传递给Thread类的构造方法。这种方式更灵活,因为一个类可以实现多个接口,任务与线程本身分离,且任务对象task可以被多个线程共享,适合多个线程执行相同任务。
常用的Lambda表达式简化(Java 8+):

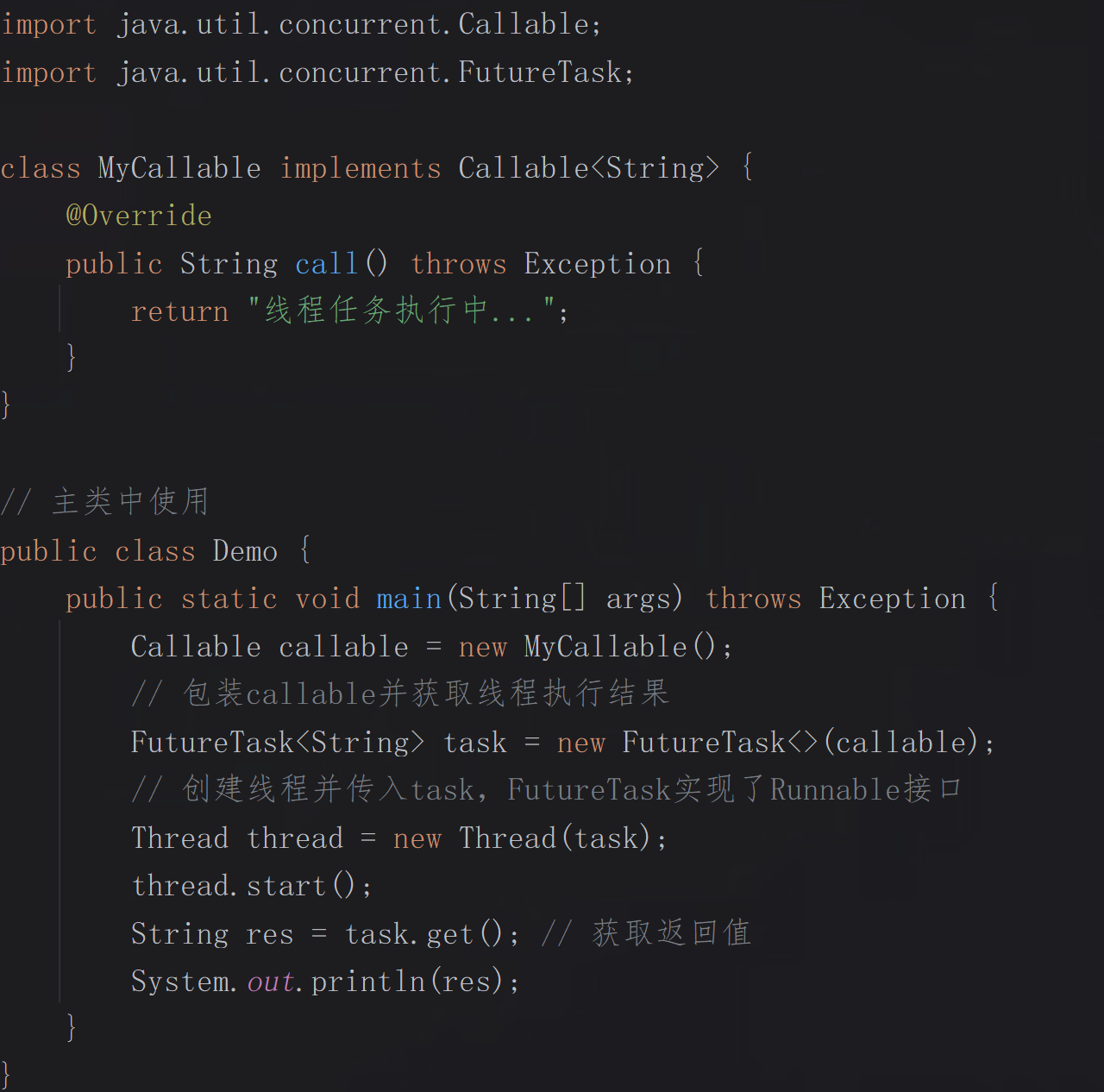
3.实现Callable接口:
通过实现Callable接口并定义call()方法,该方法允许返回值并能抛出异常,通常结合FutureTask类使用,以获取异步执行结果或处理异常。这种方式支持任务结果的返回,适合需要计算结果的场景,同时在任务管理的场景中优势也较明显。
线程池优化
1.Executor框架概述:
Executor框架是Java中实现线程池的核心组件,它封装了线程的创建、调度和执行逻辑,简化了管理并降低了复杂度。
· 核心接口体系:
Executor:最顶层接口,仅定义void execute(Runnable command)方法,负责“提交任务”,不关心线程管理细节。
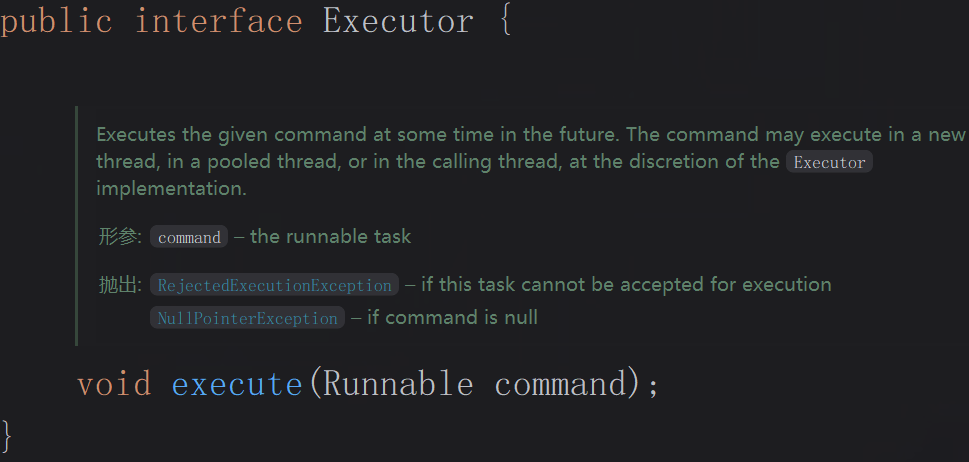
ExecutorService:继承Executor,扩展线程池生命周期管理能力,核心方法包括shutDown()、submit()、awaitTermination()等。

ThreadPoolExecutor:ExecutorService的核心实现类,封装线程池的核心逻辑(线程创建、任务队列、拒绝策略等),是实际开发中自定义线程池的“主力军”。
线程创建:
构造方法,指定核心线程数、最大线程数、临时线程空闲后的存活时间、keepAliveTime的时间单位、任务队列、线程工厂、拒绝策略,初始化线程池基础配置。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { ... } 核心线程数:线程池常驻线程数,即使空闲也不会销毁;
最大线程数:线程池能创建的最大线程数(核心线程+临时线程);
空闲存活时间:临时线程空闲后的存活时间,超时候销毁;
时间单位:线程存活时间的单位,如MILLISECONDS(毫秒)、SECONDS(秒)、MINUTES(分钟);
任务队列:存放待执行任务的队列,分为有界(ArrayBlockingQueue)和无界(LinkedBlockingQueue);
线程工厂:用于创建线程,可自定义线程名称、优先级等;
拒绝策略:当任务数超出最大线程数+队列容量时的处理策略。
创建Worker封装线程,通过线程工厂生产线程并启动,同时维护工作线程集合。
private boolean addWorker(Runnable firstTask, boolean core) { ... }任务队列:
提交任务,优先创建核心线程,其次入队,最后创建非核心线程。
public void execute(Runnable command) { ... }获取线程池的任务队列实例。
public BlockingQueue<Runnable> getQueue() { ... }拒绝策略:
内置拒绝策略(默认):抛出RejectedExecutionException,适合需要明确知道任务被拒绝的场景。
public ThreadPoolExecutor.AbortPolicy() { ... }内置拒绝策略:由提交任务的主线程直接执行任务,适合不能丢失任务的场景。
public ThreadPoolExecutor.CallerRunsPolicy() { ... } 内置拒绝策略:直接丢弃超额任务,无任何提示,适合可以容忍任务丢失的场景。
public ThreadPoolExecutor.DiscardPolicy() { ... }内置拒绝策略:丢弃队列中最旧的任务,再提交当前任务,适合新任务比老任务重要的场景。
public ThreadPoolExecutor.DiscardOldestPolicy() { ... }· 常用线程池对比:
固定线程数线程池:线程数是固定数量的,核心线程数与最大线程数相等,底层为无界阻塞队列LinkedBlockingQueue,适合任务量稳定、需控制并发数的场景。
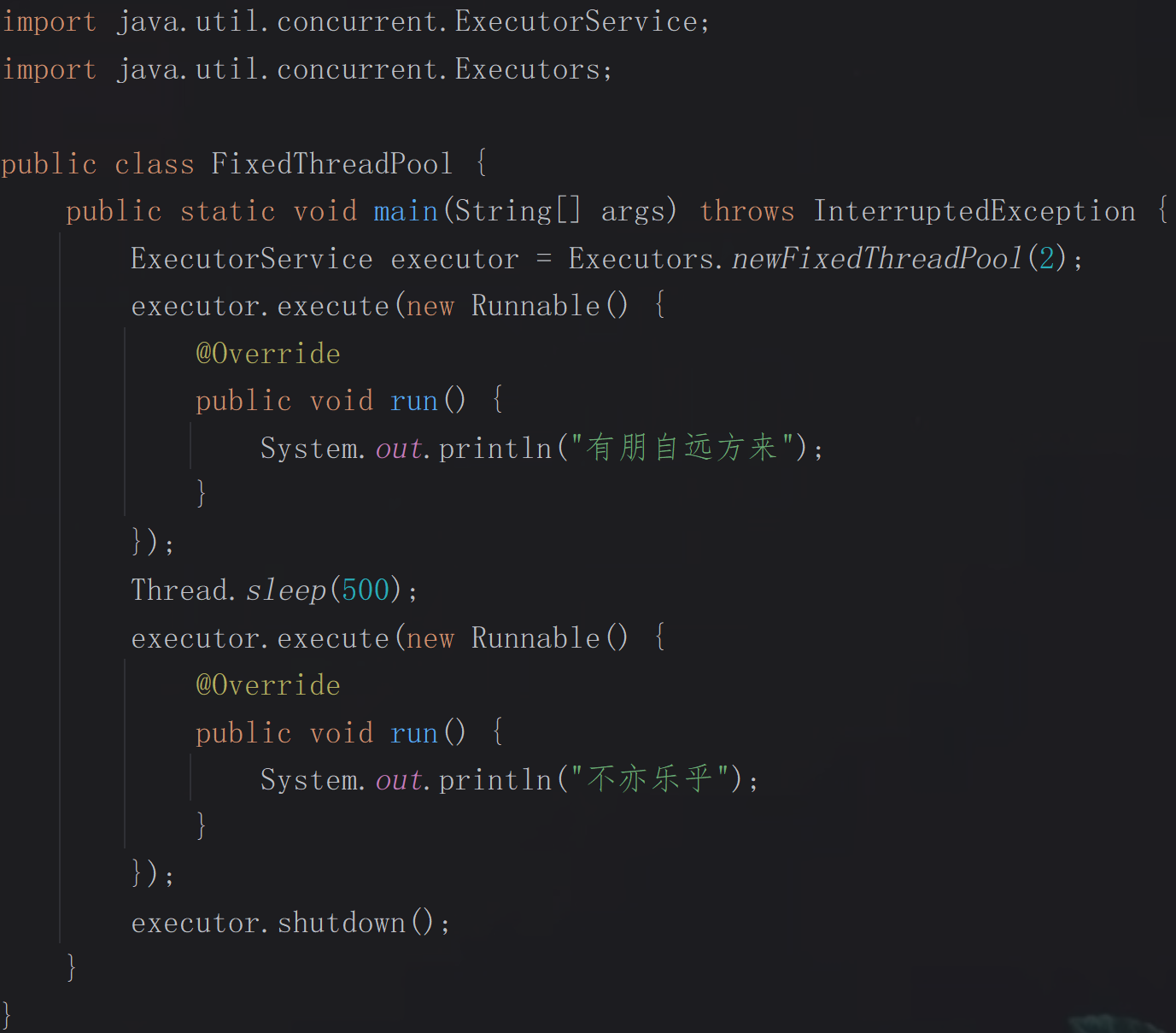
程序效果展示:
缓存线程池:线程数在0到无穷之间动态调整,底层为无存储能力的阻塞队列SynchronousQueue,适合短期、突发且任务量少的场景。
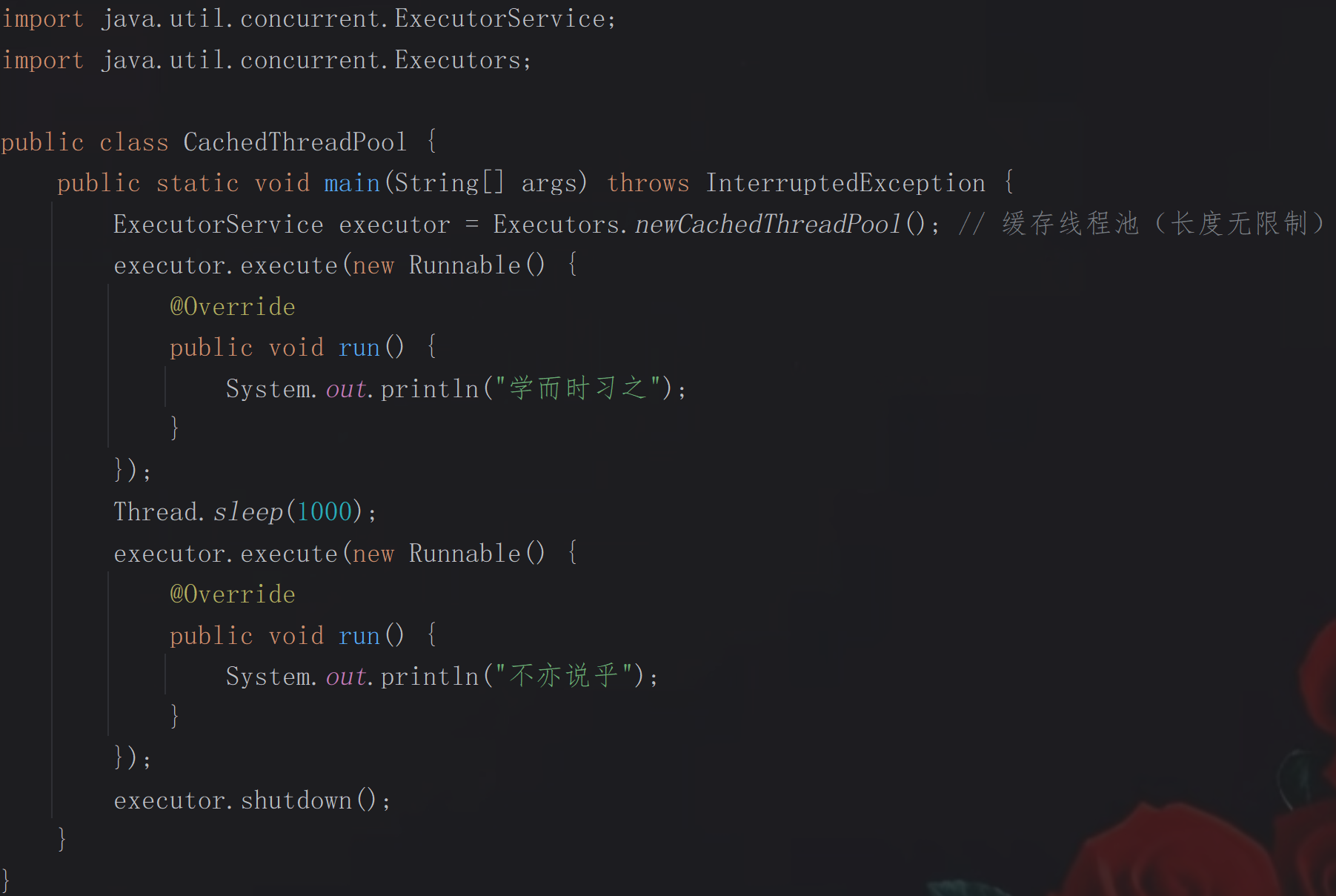
程序效果展示:
单线程线程池:只有1个线程,底层为无界队列LinkedBlockingQueue,适合需保证任务顺序执行的场景。
程序效果展示:
定时/周期性线程池:线程数是固定数量的,底层为DelayedWorkQueue延迟阻塞队列,适合处理定时任务、周期性任务。
程序结果展示:
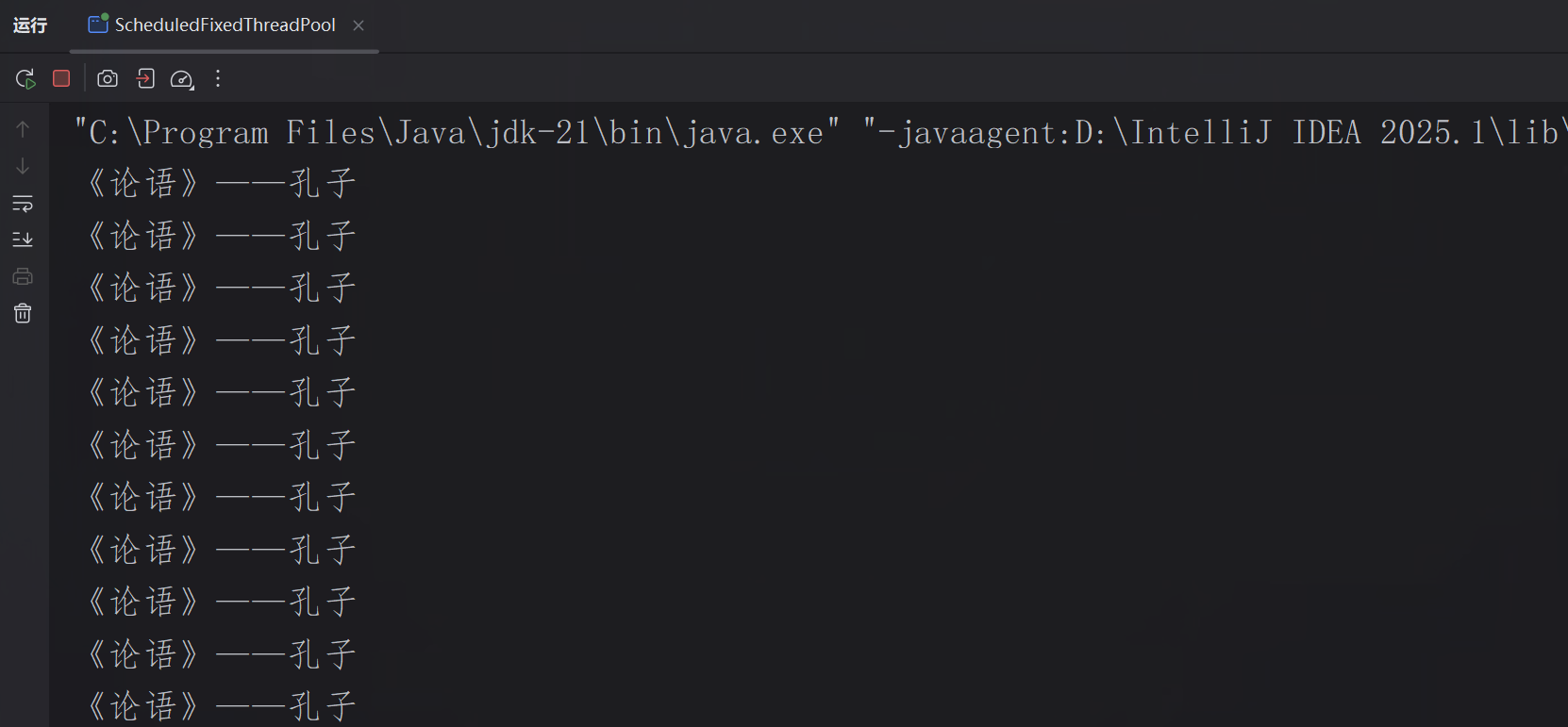
2.线程数优化:
不同场景下,线程池任务配置策略不同:
CPU密集型:少线程少切换,推荐线程数 = CPU核心数 + 1(简记为n + 1),如科学计算、模型推理;
I/O密集型:多线程占满等待,推荐线程数 = CPU核心数 * 2(简记为2n),如文件读写、网络请求。
3.队列类型调整:
调整核心原则:根据任务特性(如是否允许排队、任务优先级、处理时效性)匹配队列类型,平衡线程利用率与任务响应速度。
无界队列(如LinkedBlockingQueue)
特点:队列无固定容量,可无限接收任务,不会触发线程池的拒绝策略;
使用场景:无突发海量任务,常规业务逻辑处理;
风险:若任务提交速度远大于处理速度,任务会无限堆积,可能导致内存溢出(OOM);
有界队列(如ArrayBlockingQueue、LinkedBlockingQueue(手动指定容量))
特点:队列容量固定,当队列满且核心线程数达上限时,会启动非核心线程;若非核心线程也满,则触发拒绝策略;
使用场景:任务量有突发特性,需限制队列最大堆积量,同时通过拒绝策略保障系统稳定性。
优先队列(如PriorityBlockingQueue)
特点:基于任务优先级排序,自定义compareTo()方法,高优先级任务优先被执行;
使用场景:明确优先级区分,需保障核心任务优先处理;
风险:若持续提交高优先级任务,低优先级任务可能被“饿死”,所以要合理控制优先级分布。
同步移交队列(如SynchronousQueue)
特点:队列不存储任务,提交的线程需立即被线程接收,通常配合CachedThreadPool使用;
使用场景:任务处理耗时短,需快速响应,不允许任务排队。
注意事项总结:
· 避免盲目使用无界队列;
· 匹配线程池核心参数;
· 监控队列状态。
线程安全与同步
synchronized关键字:
synchronized是Java内置的同步机制,常通过给代码块会方法加互斥锁来保证线程安全,防止出现数据不一致等问题,它有三大核心原则,分别是互斥性(同一时间只有一个线程能获取锁并执行同步代码)、可见性(线程释放锁后,自动将修改的变量刷新到主内存,使其他线程能读到最新变量值)和有序性(通过JVM优化禁止指令重排序,保证代码按顺序执行)。
修饰方法:
int cnt = 0;
public synchronized void add() {
cnt++;
}修饰代码块:
Set<Integer> set = new HashSet<>();
Object lock = new Object();
int V = 0;
public void add(int x) {
synchronized (lock) {
V -= x;
set.add(V);
}
}synchronized的缺点:
· 性能开销大(需要获取锁、释放锁);
· 可能导致线程阻塞(如死锁);
· 灵活度不足,复杂度较大。
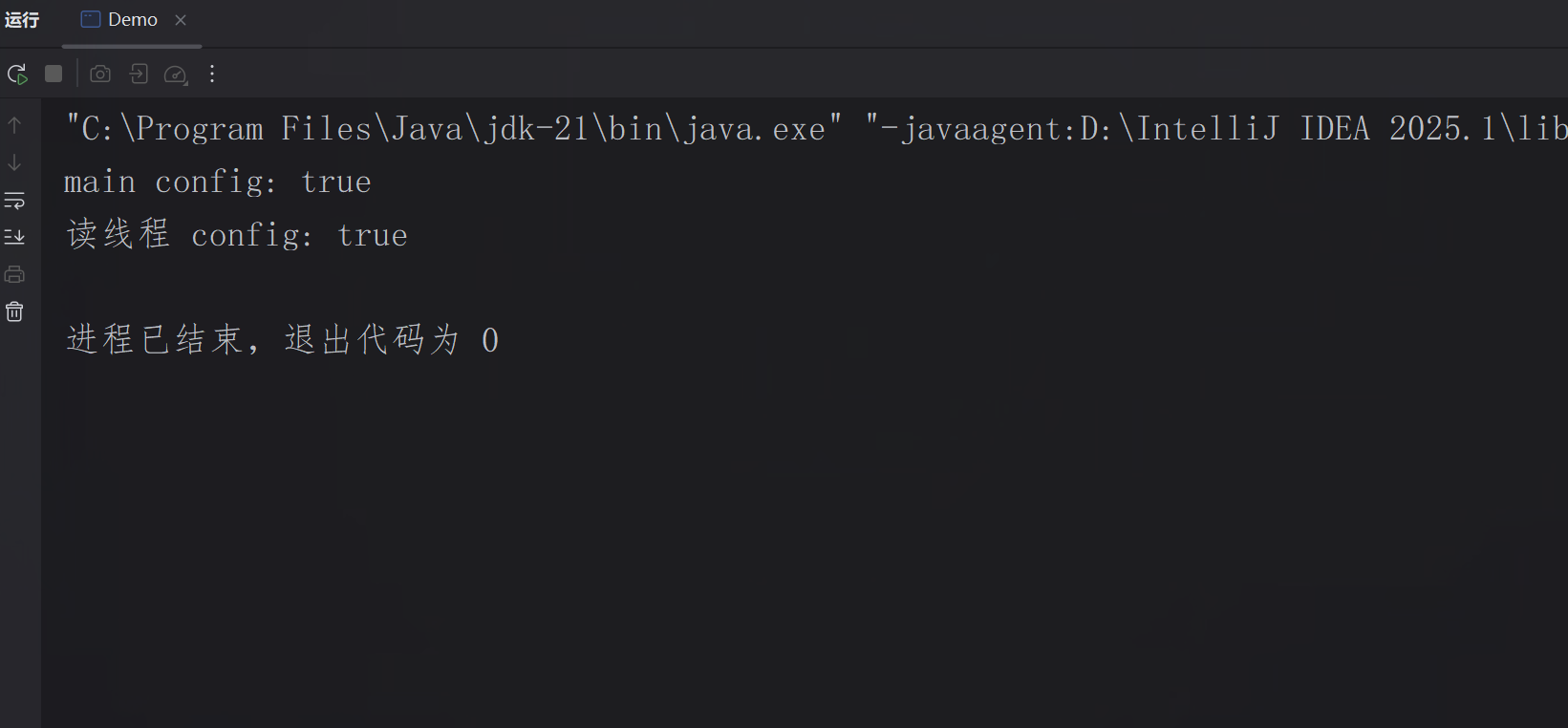
volatile变量:
volatile是JUC中常见的关键字,用于修饰变量,核心作用是保证变量的可见性和程序的有序性,但不保证原子性(并发场景中可能导致数据丢失),相比synchronized更轻量级,适用于状态标记、简单值传递的场景。
数据可见:

控制台输出结果:
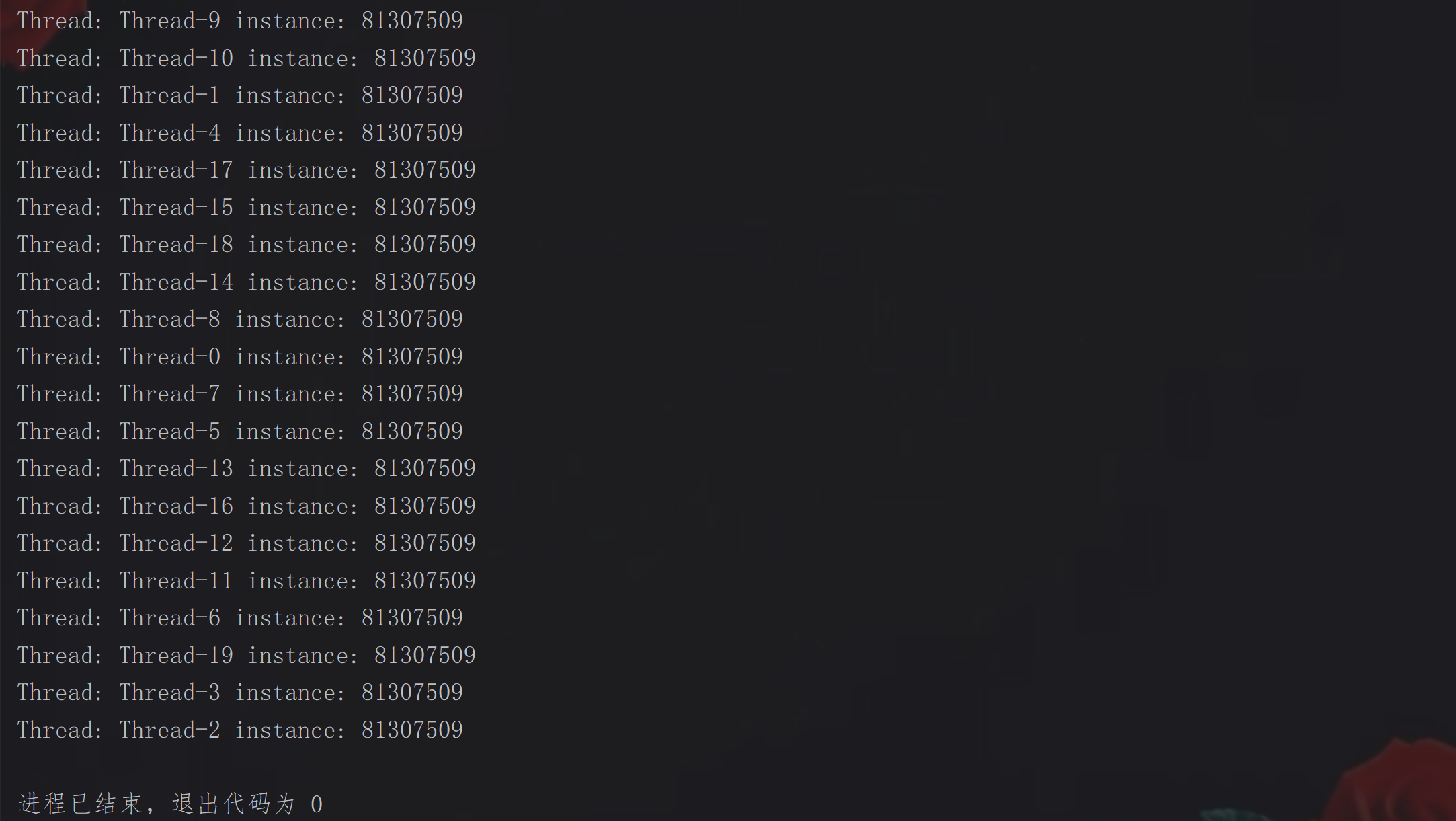
禁止指令重排序:
public class Demo {
private static volatile Demo instance;
private static Object lock = new Object();
private Demo() {
// 私有构造,禁止外部new
}
public static Demo getInstance() {
if (instance == null) { // 若实例存在,直接返回
synchronized (lock) { // 防止多线程等待锁时重复创建
// 分配内存空间 -> 初始化对象 -> 把内存地址赋给instance
if (instance == null) instance = new Demo();
}
}
return instance; // 非空安全
}
public static void main(String[] args) {
for (int i = 1; i <= 20; i++) { // 多线程并发测试
new Thread(() -> {
Demo demo = getInstance();
System.out.println("Thread: " + Thread.currentThread().getName() + " instance: " + demo.hashCode());
}).start();
}
}
}
控制台输出结果:
非原子性:
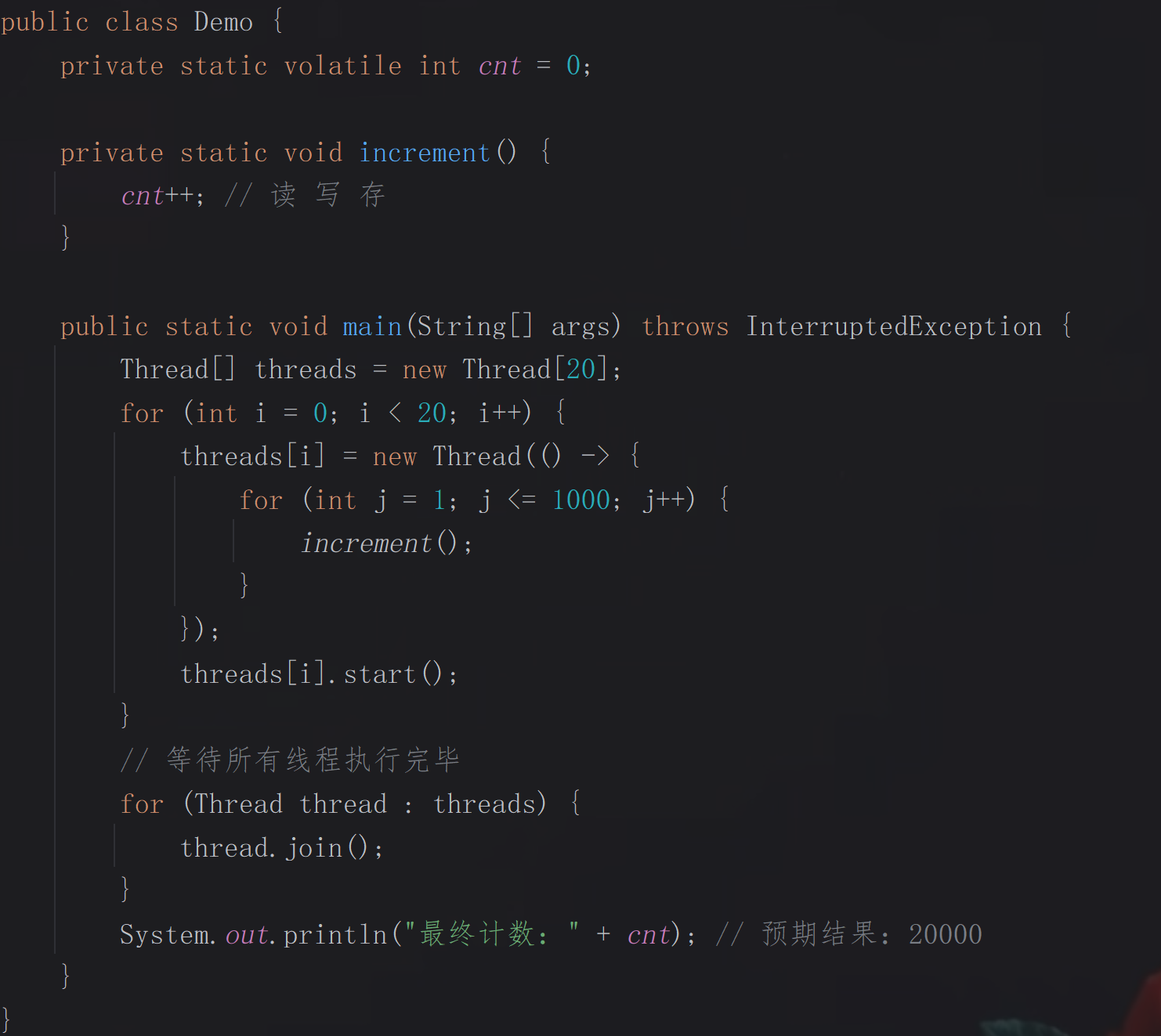
控制台输出结果:
并发工具类:
并发工具类是在并行编程中提供高级抽象的API集合,他们基于并行编译器或预处理器的思想,自动将串行任务分解为可并行执行的子任务,核心目标是简化并行性、提高性能和避免常见错误。
Exchanger类:
本质是一种数据交换,两个线程相遇,交换彼此携带的数据,然后各自离开。
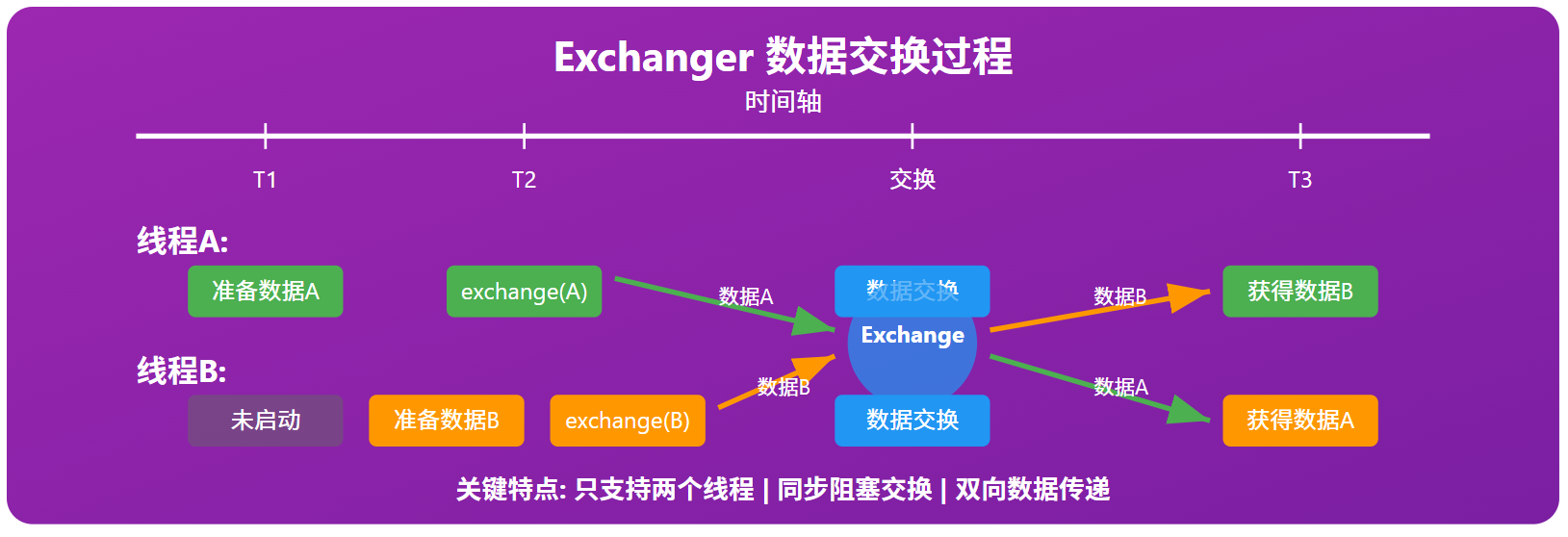
典型应用场景(生产者-消费者数据传递):
import java.util.concurrent.Exchanger;
public class Demo {
private static Exchanger<String> exchanger = new Exchanger<>();
// 生产并交换
private static void producerThread() {
new Thread(() -> {
try {
String data = "生产的商品:计算坤";
System.out.println("生产者:准备交换数据 -> " + data);
// 阻塞等待消费者
String received = exchanger.exchange(data);
System.out.println("生产者:收到消费者的反馈 -> " + received);
} catch (Exception e) {
throw new RuntimeException(e);
}
}).start();
}
// 接收并反馈
private static void consumerThread() {
new Thread(() -> {
try {
String feedback = "反馈:计算坤已收到,能正常使用";
System.out.println("消费者:准备交换数据 -> " + feedback);
// 阻塞等待生产者
String receiced = exchanger.exchange(feedback);
System.out.println("消费者:收到生产者的数据 -> " + receiced);
processData(receiced); // 接收并处理
} catch (Exception e) {
throw new RuntimeException(e);
}
}).start();
}
private static void processData(String s) throws InterruptedException {
System.out.println("开始处理数据:" + s);
// 模拟处理时长
Thread.sleep(1500);
System.out.println("交易完成!");
}
public static void main(String[] args) {
producerThread();
consumerThread();
}
}控制台输出结果:

CyclicBarrier类:
实现线程同步(多线程任务→统一汇总),用于让一组线程互相等待,直到所有线程都到达某个公共屏障点后,再继续一起执行后续操作,且该屏障可重复使用。
典型应用场景(多线程并行计算):
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.Exchanger;
public class Demo {
private static final int THREAD_COUNT = 5; // 并行线程数
private static int[] subSums = new int[THREAD_COUNT]; // 每个线程的子和
private static int sum = 0; // 最终总和
public static void main(String[] args) {
// 分块计算 -> 屏障等待 -> 统一汇总
System.out.println("计算 1 - 1000 的总和:");
// 初始化:指定线程数 + 屏障执行逻辑
CyclicBarrier barrier = new CyclicBarrier(THREAD_COUNT, () -> {
System.out.println(" === === 所有线程计算完成,开始汇总 === ===");
for (int subSum : subSums) {
sum += subSum;
}
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("并行计算结果:" + sum);
});
for (int i = 0; i < THREAD_COUNT; i++) { // 5个线程分别计算不同区间
final int index = i;
new Thread(() -> {
int start = index * 200 + 1;
int end = (index + 1) * 200;
int tmp = 0;
for (int j = start; j <= end; j++) {
tmp += j;
}
subSums[index] = tmp;
System.out.println("线程:" + Thread.currentThread().getId() + " 子和:" + tmp);
try { // 等待其他线程完成
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}).start();
}
}
}控制台输出结果:

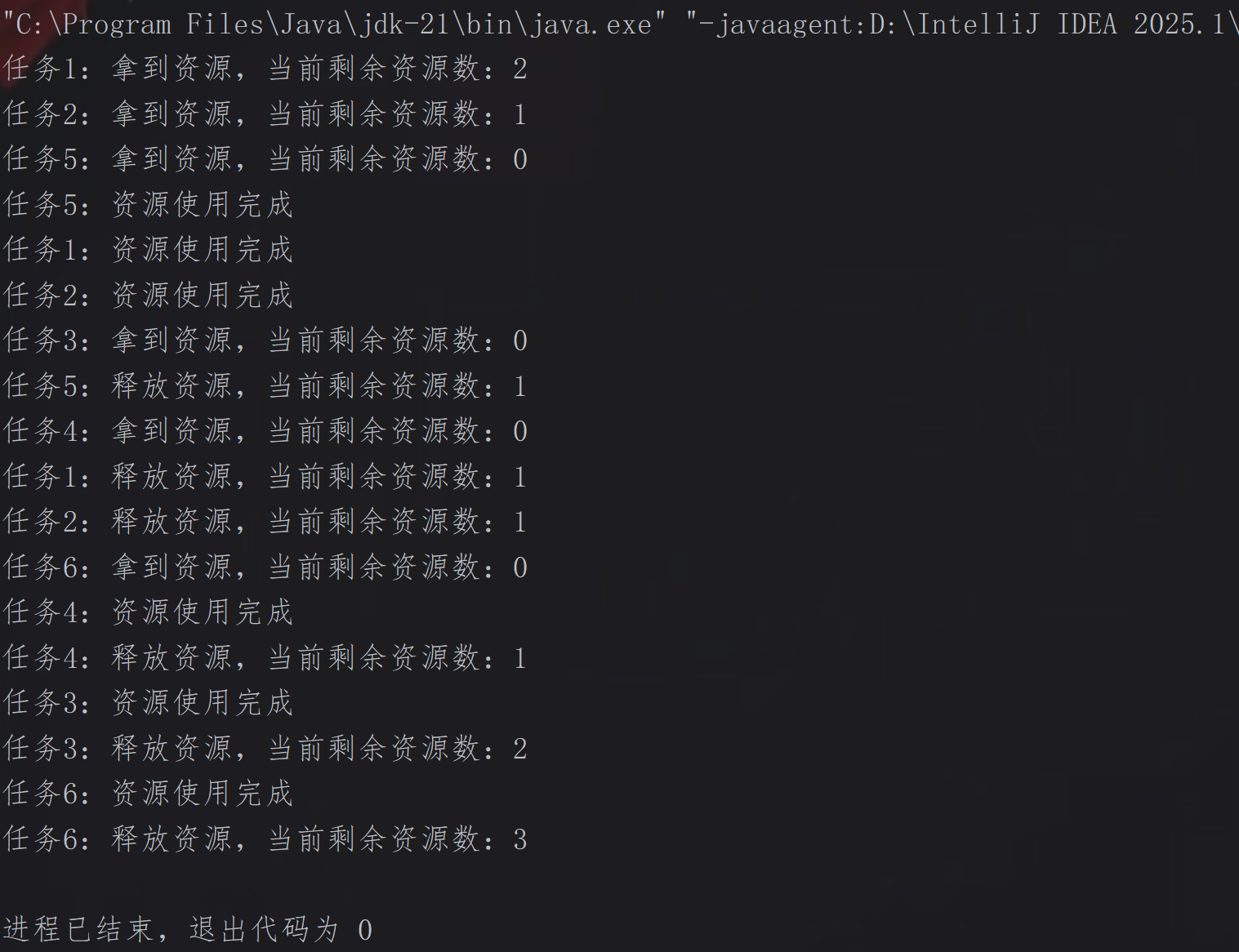
Semaphore类:
Semaphore是信号量,本质是“线程并发数的控制器”,内部维护一个许可计数器,围绕“获取许可”和“释放许可”展开,控制同时访问某个共享资源的线程最大数量,可以有效保护有限资源。
典型应用场景(接口限流):
import java.util.concurrent.Semaphore;
public class Demo {
// 限制最大并发量为3,模拟有限资源
private static final Semaphore semaphore = new Semaphore(3);
public static void main(String[] args) {
for (int i = 1; i <= 6; i++) {
final int Id = i;
new Thread(() -> {
try {
// 获取许可,无许可则阻塞等待
semaphore.acquire();
System.out.printf("任务%d:拿到资源,当前剩余资源数:%d%n", Id, semaphore.availablePermits());
Thread.sleep(200);
System.out.println("任务" + Id + ":资源使用完成");
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally { // 释放许可,避免资源泄露
semaphore.release();
System.out.printf("任务%d:释放资源,当前剩余资源数:%d%n", Id, semaphore.availablePermits());
}
}).start();
}
}
}控制台输出结果:
CountDownLatch类:
CountDownLatch是倒计时门闩,通过“计数器递减”实现线程间的等待协作,让一个或多个等待线程阻塞,直到其他任务线程完成指定数量的任务后,等待线程才继续执行。
典型应用场景(服务器启动):
import java.util.concurrent.CountDownLatch;
public class Demo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
new Thread(() -> { // 加载配置
try {
System.out.println(Thread.currentThread().getName() + ":开始加载系统配置...");
Thread.sleep(1200);
System.out.println(Thread.currentThread().getName() + ":配置加载完成!");
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally { // 任务完成,计数器减一
latch.countDown();
}
}, "Config_Thread").start();
new Thread(() -> { // 初始化数据库
try {
System.out.println(Thread.currentThread().getName() + ":开始初始化数据库连接...");
Thread.sleep(1500);
System.out.println(Thread.currentThread().getName() + ":数据库初始化完成!");
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
latch.countDown();
}
}, "DB_Thread").start();
new Thread(() -> { // 预热缓存
try {
System.out.println(Thread.currentThread().getName() + ":开始预热缓存数据...");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + ":缓存预热完成!");
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
latch.countDown();
}
}, "Cache_Thread").start();
System.out.println(Thread.currentThread().getName() + ":等待所有组件初始化完成...");
latch.await(); // 主线程在此阻塞,直至计数为0
System.out.println(Thread.currentThread().getName() + ":所有组件初始化完成,服务启动成功!");
}
}控制台输出结果:

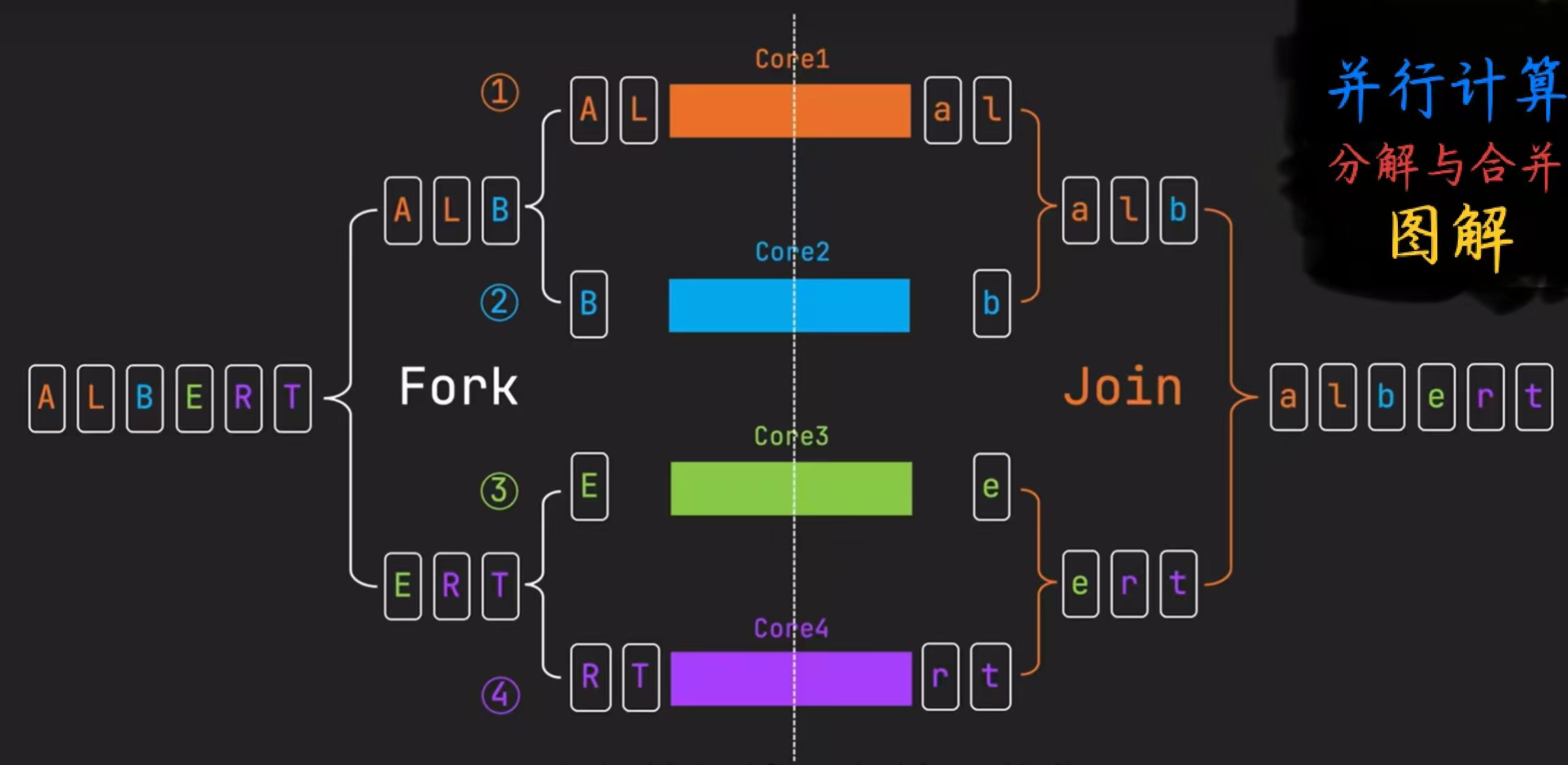
Fork/Join框架
Fork/Join框架是Java 7引入的并行计算框架,基于“分而治之”的思想,核心是将大任务拆分成多个小任务并行执行,最后合并所有小任务,以充分利用CPU多核资源。该框架的核心组件是ForkJoinPool,它支持任务窃取,当一个线程空闲时,可以从其他线程的队列中“窃取”任务来执行,从而保持负载均衡。
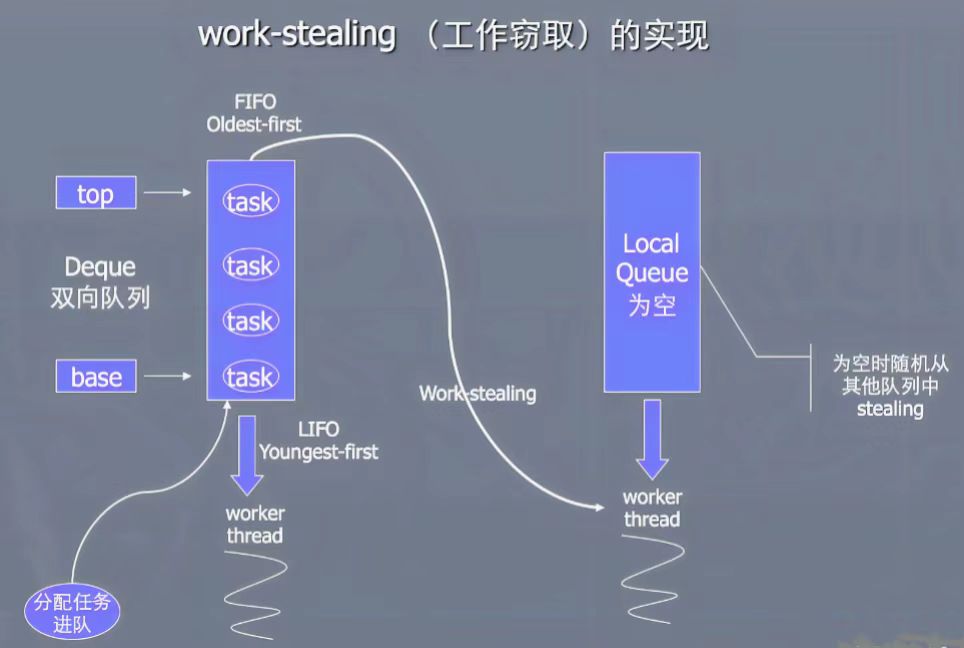
工作窃取机制
· 每个线程维护自己的双端队列
· 线程从队列头部取任务执行
· 空闲线程可以从其他线程尾部“偷取”任务执行
· 实现自动负载均衡,提高CPU利用率
分治策略:
1.判断任务大小是否超过预设阈值,若超过继续拆分任务,若未超过直接计算;
2.小任务在各自线程中独立执行计算逻辑(逻辑通常定义在compute()方法中),无相互依赖;
3.等待所有子任务执行完成并获取其结果,汇总为最终结果。
注意:
阈值过大:任务拆分不足,失去并行意义;
阈值过小:拆分过细,资源开销大,效率降低。
分治策略(Fork/Join框架)适用于以下场景:
· CPU密集型任务;
· 可递归分解的任务;
· 任务间相互独立;
· 数据并行处理;
· 大数组/集合操作。
RecursiveTask与RecursiveAction:
RecursiveTask和RecursiveAction均为Fork/Join框架中实现“递归拆分任务”的核心类,本质是ForkJoinTask的子类,且两者均基于工作窃取机制的调度,仅在返回值处理上有差异,性能与任务具体执行有关,与类本身无关。
RecursiveTask聚焦计算与结果合并,通过join()方法获取泛型<T>定义类型的返回值;而RecursiveAction聚焦执行操作,无返回值。
典型应用示例(文件处理):
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.List;
import java.util.ArrayList;
public class Demo {
private static final int THRESHOLD = 3; // 阈值:3个文件
// 模拟文件类
static class MockFile {
private String name;
private int size;
public MockFile(String name, int size) {
this.name = name;
this.size = size;
}
public String getName() {
return name;
}
public int getSize() {
return size;
}
}
// Fork/Join处理任务类
static class FileProcessAction extends RecursiveAction {
private List<MockFile> files;
private int start, end;
public FileProcessAction(List<MockFile> files, int start, int end) {
this.files = files;
this.start = start;
this.end = end;
}
@Override
protected void compute() {
System.out.println("处理文件范围: [" + start + ", " + end + ") 数量: " + (end - start));
if (end - start <= THRESHOLD) {
// 直接处理文件
for (int i = start; i < end; i++) {
processFile(files.get(i));
}
} else {
// 分解任务
int mid = (start + end) >> 1;
System.out.println("分解文件处理任务 [" + start + ", " + end + ") -> [" + start + ", " + mid + ") + [" + mid + ", " + end + ")");
FileProcessAction leftAction = new FileProcessAction(files, start, mid);
FileProcessAction rightAction = new FileProcessAction(files, mid, end);
// 并行执行两个子任务
invokeAll(leftAction, rightAction);
System.out.println("完成文件处理任务 [" + start + ", " + end + ")");
}
}
private void processFile(MockFile file) {
// 模拟文件处理
try {
System.out.println("[" + Thread.currentThread().getName() + "] 正在处理: " + file.getName() + " (大小: " + file.getSize() + "KB)");
Thread.sleep(100);
System.out.println("[" + Thread.currentThread().getName() + "] 完成处理: " + file.getName());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
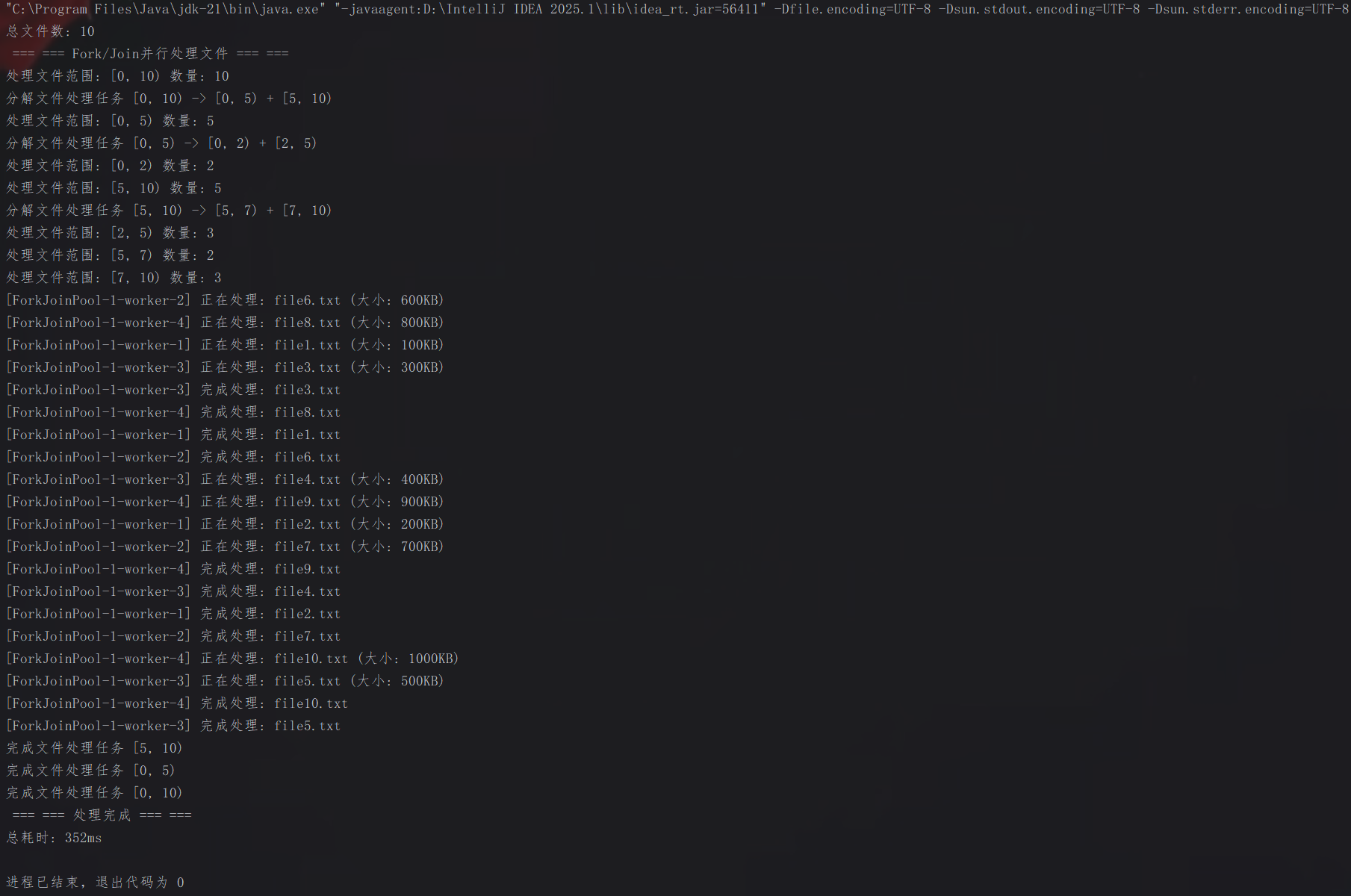
public static void main(String[] args) {
// 创建模拟文件列表
List<MockFile> files = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
files.add(new MockFile("file" + i + ".txt", i * 100));
}
System.out.println("总文件数: " + files.size());
System.out.println(" === === Fork/Join并行处理文件 === ===");
ForkJoinPool pool = new ForkJoinPool();
// 创建任务并执行
FileProcessAction action = new FileProcessAction(files, 0, files.size());
long startTime = System.currentTimeMillis();
pool.invoke(action);
long endTime = System.currentTimeMillis();
System.out.println(" === === 处理完成 === ===");
System.out.println("总耗时: " + (endTime - startTime) + "ms");
pool.shutdown();
}
}控制台输出结果:
Stream API并行处理
并行流:
直接转换
通过集合的parallelStream()方法,直接从数据源创建并行流,一步到位,是最常用的方式。
集合→并行流示例:
import java.util.List;
public class Demo {
public static void main(String[] args) {
// 创建包含整数1、2、3、4的不可变List
List<Integer> list = List.of(1, 2, 3, 4);
// 直接创建并行流,每个元素x映射为它的平方并累加
int sum = list.parallelStream().mapToInt(x -> x * x).sum();
System.out.println("list集合中所有元素的平方和为:" + sum);
}
}效果展示:

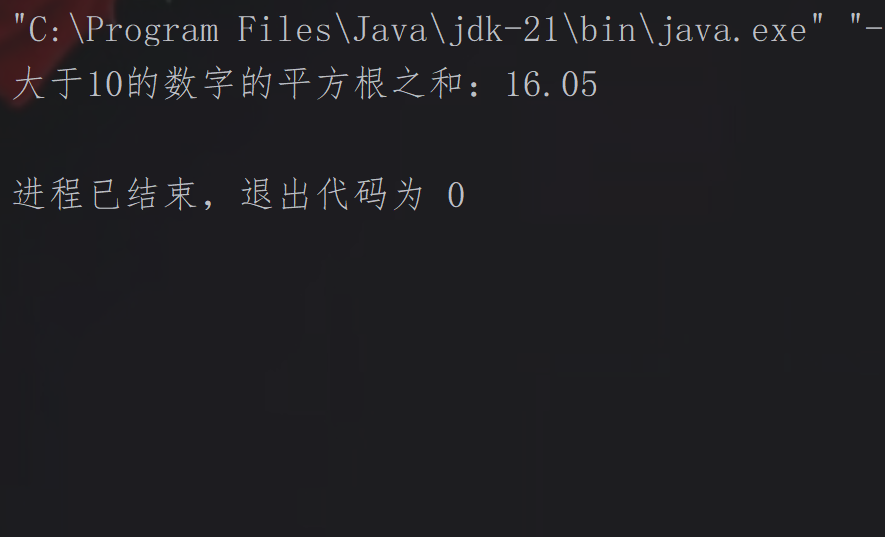
顺序流转并行
先通过stream()创建顺序流,再调用parallel()方法将顺序流转换为并行流,适用于需要先对顺序流做预处理再并行的场景。
顺序流→并行流示例:
import java.util.List;
public class Demo {
public static void main(String[] args) {
List<Integer> list = List.of(5, 12, 8, 15, 2, 20, 7, 18);
double sum = list.
stream(). // 先创建顺序流
filter(x -> x > 10). // 筛选出大于10的数
parallel(). // 转为并行流
mapToDouble(Math::sqrt). // 类型转换,并行计算每个数的平方根
sum(); // 并行累加所有平方根值
System.out.printf("大于10的数字的平方根之和:%.2f%n", sum);
}
}效果展示:
并行流优化原则:
避免共享变量
共享变量会引发线程安全问题(如数据竞争),进而导致加锁开销或结果错误,是并行流性能与正确性的主要隐患,并行流操作应尽量使每个任务不依赖外部共享数据,也不修改外部数据。
禁用线程不安全的共享集合(ArrayList、LinkedList、HashMap等),若需聚合结果,优先使用并行流内置的collect(),而非手动往共享集合添加元素;若必须使用共享变量,需用线程安全类(AtomicInteger、ConcurrentHashMap等)替代同步锁,减少锁竞争;或通过reduce()继续无状态聚合,避免显示共享。
任务拆分效率
并行流依赖ForkJoinPool拆分任务,若拆分过粗,任务数量少,会导致CPU核心利用率低;若拆分过细,任务数量过多,则会增加线程调度和拆分的开销。任务粒度需平衡“并行收益”与“拆分开销”,确保每个子任务的执行时间远小于拆分与调度时间。
避免阻塞操作
并行流的线程来自ForkJoinPool的公共线程池,若任务中包含阻塞操作(如IO、锁等待),会导致线程长时间空闲,降低整体并行效率。并行流任务尽量是计算密集型,若必须在并行流中执行阻塞操作(如数据库查询、网络请求、文件读写),需自行提高线程数,避免公共线程池被占满,影响其他并行流任务,但需注意,此方式会大量增加线程资源消耗。
自定义并行流:
指定独立线程池(推荐)
通过ForkJoinPool手动创建线程池,将并行流任务提交到线程池执行,任务完成后关闭线程池,这是最常用的方式,不影响全局默认池。
示例:
效果:
替换默认线程池
通过修改JVM系统的默认池配置(全局commonPool的线程数),会影响所有默认池的并行流,资源安全性低,使用场景少。
示例:
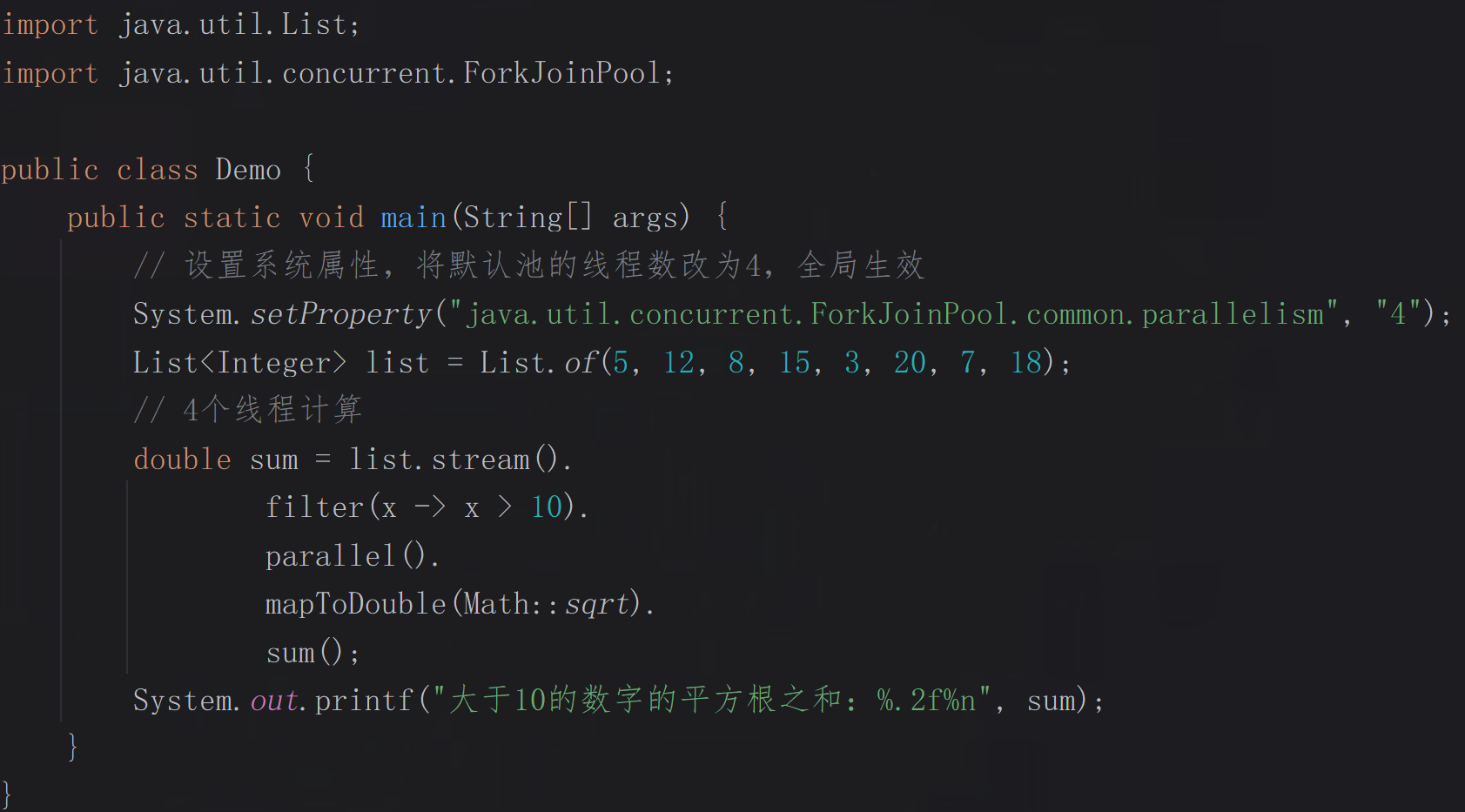
效果:
性能优化建议
合理选择并行度
并行度需匹配硬件资源与任务特性,避免线程切换开销抵消并行收益,同时监控并行度或结合业务负载对并行度进行动态调整,减少资源浪费。
减少锁竞争
锁竞争会导致线程阻塞等待,是并行计算性能的主要瓶颈之一,需通过锁优化或无锁设计降低竞争,如ConcurrentHashMap的高效并发、原子类(如AtomicBoolean,基于CAS机制,无锁且线程安全)、读写锁ReentrantReadWriteLock(适合“读多写少”的场景)。
任务均衡
均匀拆分任务,动态任务分配,减少任务依赖,充分利用并行资源。
监控与调试
通过监控工具和调试技巧及时发现瓶颈,如:监控CPU利用率,若低于70%,则检查任务拆分和锁竞争;使用ForkJoinPool的getQueuedTaskCount()、getActiveThreadCount()分别获取队列任务数和活跃线程数,判断负载是否均衡;排查死锁,防止线程阻塞。
Java并行计算实际应用场景
1.大数据处理与实时分析
(如海量数据ETL、实时指标计算);
2.高频交易与金融风控
(如订单撮合、风险敞口计算);
3.Web服务高并发处理
(如秒杀系统、实时聊天);
4.科学计算与工程仿真
(如流体动力学模拟、分子动力学)。
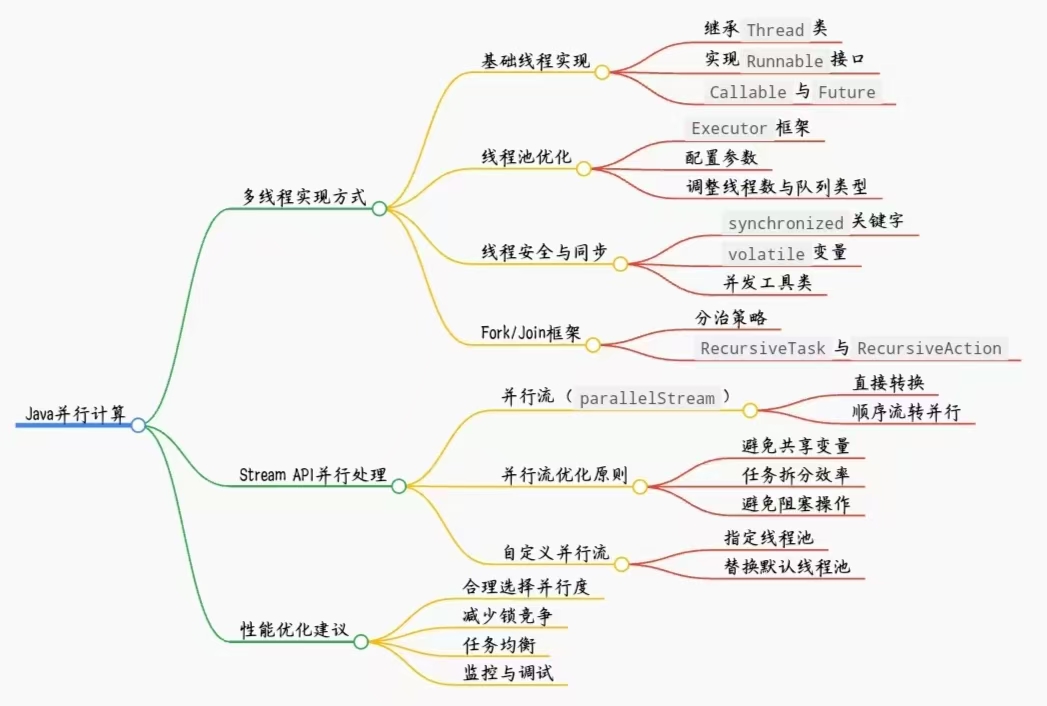
思维导图