一、导读
本报告解析了美团LongCat团队推出的LongCat-Flash模型,一个拥有5600亿参数的混合专家模型(Mixture-of-Experts, MoE)。面对大规模语言模型在计算资源和效率上的挑战,LongCat-Flash旨在实现计算效率与高级智能体(Agent)能力的协同发展。论文的核心创新在于两个架构设计:(1)引入零计算专家(Zero-computation Experts)机制,根据上下文需求动态分配18.6B至31.3B的计算预算,优化资源利用;(2)采用快捷连接混合专家模型(Shortcut-connected MoE, ScMoE)架构,通过扩大计算与通信的重叠窗口,显著提升训练和推理效率。结合高效的模型扩展策略与多阶段训练流程,LongCat-Flash在30天内完成了超过20万亿token的训练,并实现了超过100 TPS的推理速度。评测结果显示,作为一个非思维(non-thinking)基础模型,LongCat-Flash在通用能力,尤其是在智能体任务上,展现了与业界顶尖模型相媲美的强大竞争力。
二、论文基本信息

基本信息
论文标题:LongCat-Flash Technical Report
作者:Meituan LongCat Team
作者单位:Meituan
摘要精炼
论文旨在研发一个兼具计算效率与高级智能体能力的5600亿参数MoE语言模型LongCat-Flash。为实现此目标,论文提出了两大核心技术贡献:一是零计算专家机制,它允许模型根据上下文重要性为每个token动态激活18.6B到31.3B(平均27B)的参数,从而实现动态计算预算分配;二是快捷连接MoE(ScMoE)架构,该架构通过扩大计算与通信的重叠窗口,显著提升了模型的训练及推理吞吐量。基于这些创新,论文得出的关键结论是,LongCat-Flash在30天内完成了超过20万亿Token的训练,推理速度在H800上超过100 TPS(每秒生成token数),每百万输出token的成本为0.70美元。全面评测表明,该模型在通用领域,特别是智能体任务中,表现出卓越的性能。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/WF5NShyWV7MnIlHlIRQhcg
https://mp.weixin.qq.com/s/WF5NShyWV7MnIlHlIRQhcg
三、研究背景与相关工作
研究背景
随着大型语言模型(LLM)的快速发展,通过扩大模型尺寸和计算资源来提升性能已成为共识。然而,这一路径也带来了严峻的挑战,即模型扩展的成本效益问题。训练和推理巨型模型需要巨大的计算开销,这使得进一步推动可扩展智能的边界变得愈发困难。因此,如何在保证模型性能的同时,提升计算效率和成本效益,成为了当前LLM研究领域的关键痛点和瓶颈。本研究正是在这一背景下展开,旨在通过创新的模型架构和训练策略,探索更具成本效益的LLM扩展路径。
相关工作
领域内的相关工作主要围绕提升LLM,特别是MoE模型的效率展开。传统的MoE模型虽然能通过稀疏激活来降低计算量,但在大规模部署时,专家间的通信开销成为新的瓶颈。一些工作如共享专家(shared-expert)架构尝试通过重叠通信与单个专家的计算来缓解此问题,但其效率受限于单个专家的有限计算窗口。此外,如何稳定、高效地训练超大规模模型,并系统性地增强其解决现实世界复杂任务(即智能体能力)的本领,也是现有方法需要进一步解决的局限性。本文提出的ScMoE架构和针对智能体能力的多阶段训练流程,正是为了应对这些挑战。
四、主要贡献与创新
- 可扩展的计算效率架构:创新性地提出了两种设计以提升效率。
零计算专家:根据token的重要性动态分配计算资源,实现了自适应的计算预算。
快捷连接MoE(ScMoE):通过扩大计算与通信的重叠窗口,显著提高了训练和推理的系统吞吐量。
- 高效的模型扩展策略:开发了一套全面的模型扩展与训练稳定框架。
成功应用超参数迁移(hyperparameter transfer)策略,从小型代理模型预测大规模模型的最优配置。
采用模型增长(model growth)初始化方法,基于一个半尺寸模型进行扩展,提升了性能。
设计了包含路由器梯度平衡、隐藏z-loss(hidden z-loss)等多项技术的稳定性套件,确保了训练过程的平稳。
面向智能体能力的多阶段训练流程:通过精心设计的预训练、中期训练和后训练流水线,系统性地增强了模型的推理、代码和工具使用能力,特别是在处理需要迭代推理和环境交互的复杂任务方面。
五、研究方法与原理
总体框架与核心思想
LongCat-Flash的总体框架基于一种新颖的MoE架构。
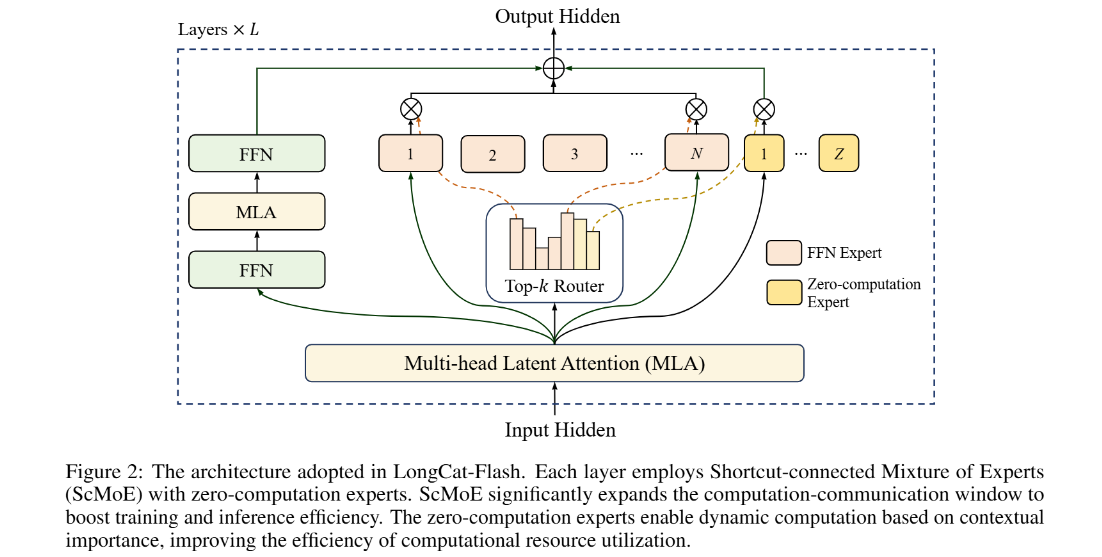
其核心设计哲学是通过优化计算资源的动态分配和最大化计算与通信的并行度,实现极致的训练和推理效率。这个框架的核心创新点体现在两个方面:
在MoE模块中引入了“零计算专家”,使得模型能学会为“简单”的token分配零计算资源,而为“困难”的token激活更多的专家,从而实现上下文感知的动态计算。
采用了“快捷连接MoE”(ScMoE)结构,它重排了Transformer层内的计算顺序,允许前一个模块的计算与当前MoE模块的通信(token分发和聚合)并行执行,极大地掩盖了通信延迟。
关键实现与评估原理
关键实现细节:
计算预算控制:为控制零计算专家的平均激活比例,论文未使用辅助损失,而是通过动态调整每个专家的偏置项(bias)来实现。偏置项的更新采用PID控制器(proportional-integral-derivative)原理,确保专家负载收敛至预设目标。其更新规则如下: 其中
μ是适应速率,K_e是期望激活的FFN专家数。方差对齐设计:为保证模型在扩展尺寸时的稳定性,论文提出了方差对齐技术。例如,在多头潜在注意力(Multi-head Latent Attention, MLA)中引入尺度修正因子
α来平衡不同路径的方差:训练稳定性:为抑制训练中可能出现的激活值爆炸问题,引入了“隐藏z-loss”,其定义为: 其中
z_t是最后一层的隐藏状态输出。
核心评估原理与指标:
论文使用了一系列行业标准和自建的基准来全面评估模型能力,覆盖通用知识、推理、数学、代码和智能体等多个维度。
核心评估指标包括:准确率(Accuracy)、F1分数、代码生成的pass@1、以及在智能体任务中的平均任务完成率。
选用的基准测试集包括 MMLU、ArenaHard-V2、TerminalBench、τ²-Bench 以及专为评估复杂真实世界任务而构建的私有基准 VitaBench。这些指标和基准的选择旨在全面、客观地衡量模型在不同场景下的综合性能。
六、实验结果与分析
实验设置
- 核心设置:
数据集: 训练数据混合了网页、书籍、代码等通用数据,以及为增强推理、代码和智能体能力而合成的高质量数据。总训练数据量超过20万亿tokens。
评估指标: 准确率 (acc)、F1 分数、pass@1、以及针对智能体任务设计的平均得分。
对比基线: DeepSeek-V3.1, Qwen3-235B, Kimi-K2, GPT-4.1, Claude4-Sonnet, Gemini2.5-Flash 等前沿的开源和闭源模型。
关键超参: 总参数量560B,激活参数量~27B,模型层数28,上下文长度128k。
核心实验与结论
实验目的: 该实验旨在验证 LongCat-Flash 在处理需要通过与环境(如工具集和用户)进行多轮、复杂交互才能解决的任务时的能力,并将其与业界领先模型进行对比。
关键结果: (此处应插入表3,展示各模型在Agentic Tool Use基准上的得分) 在最具挑战性的私有基准 VitaBench 上,LongCat-Flash 取得了 24.30 的平均分,超越了所有参与评测的对手模型,包括 GPT-4.1 (19.00), Claude4-Sonnet (23.00) 和 Kimi-K2 (18.20)。在公开的 τ²-Bench 基准上,LongCat-Flash 同样表现出色,例如在电信(telecom)场景下得分 73.68,远高于多数对比模型。
作者结论: 作者基于上述结果得出结论:LongCat-Flash 在智能体工具使用领域展现出明显的优势。尤其是在模拟现实世界复杂场景(如VitaBench中定义的密集工具图和多轮用户交互)时,它表现出卓越的问题解决能力,即便与参数规模更大的模型相比也毫不逊色。这证明了其架构设计和针对性训练流程在培养高级智能体能力方面的有效性。
七、论文结论与启示
总结
论文成功推出了一款兼具高效率与强智能体能力的5600亿参数MoE模型——LongCat-Flash。通过引入零计算专家和快捷连接MoE架构,模型在训练和推理效率上实现了显著突破。结合超参数迁移、模型增长等一系列精巧的训练策略,确保了大规模训练的稳定与高效。最终,通过一个多阶段、面向智能体能力的训练流程,LongCat-Flash在保持强大通用能力的同时,在需要迭代推理和环境交互的复杂任务上表现出业界领先的水平,验证了其架构与数据策略的协同价值。
展望
论文的结论部分暗示了未来的研究方向。首先,可以继续优化高效的MoE架构,探索更精细的动态计算分配机制。其次,高质量、多样化的数据策略,特别是用于培养智能体能力的合成数据框架,是未来提升模型能力的关键。最后,虽然模型在智能体任务上表现优异,但在某些特定推理任务(如极长上下文中的结构化数据分析)上仍有提升空间,这为未来的改进指明了具体方向。开放模型权重旨在鼓励社区共同推进这些领域的研究。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/WF5NShyWV7MnIlHlIRQhcg
https://mp.weixin.qq.com/s/WF5NShyWV7MnIlHlIRQhcg