一、环境搭建
github地址:Diffusion-Planner
# 安装 nuplan-devkit
git clone https://github.com/motional/nuplan-devkit.git && cd nuplan-devkit
pip install -e .
pip install -r requirements.txt
# 安装 diffusion_planner
cd ..
git clone https://github.com/ZhengYinan-AIR/Diffusion-Planner.git && cd Diffusion-Planner
pip install -e .
pip install -r requirements_torch.txt
环境变量配置
export PYTHONPATH="..../src/nuplan-devkit:.../src/Diffusion_planner"
仿真测试
2.1、使用作者提供的checkpoints进行仿真
下载配置文件arg.json 和模型model.pt
修改sim_diffusion_planner_runner.sh文件
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7,8
# export CUDA_VISIBLE_DEVICES=0
export HYDRA_FULL_ERROR=1
export OC_CAUSE=1
###################################
# User Configuration Section
###################################
# Set environment variables
export NUPLAN_DEVKIT_ROOT="/D2/NXT/zgh/src/nuplan-devkit" # nuplan-devkit absolute path (e.g., "/home/user/nuplan-devkit")
export NUPLAN_DATA_ROOT="/D2/NXT/aip/nuplan/origin_db/test" # nuplan dataset absolute path (e.g. "/data")
export NUPLAN_MAPS_ROOT="/D2/NXT/aip/maps" # nuplan maps absolute path (e.g. "/data/nuplan-v1.1/maps")
export NUPLAN_EXP_ROOT="REPLACE_WITH_EXP_DIR" # nuplan experiment absolute path (e.g. "/data/nuplan-v1.1/exp")
# Dataset split to use
# Options:
# - "test14-random"
# - "test14-hard"
# - "val14"
SPLIT="test14-random" # e.g., "val14"
# Challenge type
# Options:
# - "closed_loop_nonreactive_agents"
# - "closed_loop_reactive_agents"
# CHALLENGE="REPLACE_WITH_CHALLENGE" # e.g., "closed_loop_nonreactive_agents"
CHALLENGE="closed_loop_nonreactive_agents" # e.g., "closed_loop_nonreactive_agents"
###################################
BRANCH_NAME=diffusion_planner_release
ARGS_FILE=/D2/NXT/zhaoguanhua/src/Diffusion-Planner/checkpoints/args.json
CKPT_FILE=/D2/NXT/zhaoguanhua/src/Diffusion-Planner/checkpoints/model.pth
if [ "$SPLIT" == "val14" ]; then
SCENARIO_BUILDER="nuplan"
else
SCENARIO_BUILDER="nuplan_challenge"
fi
echo "Processing $CKPT_FILE..."
FILENAME=$(basename "$CKPT_FILE")
FILENAME_WITHOUT_EXTENSION="${FILENAME%.*}"
PLANNER=diffusion_planner
python $NUPLAN_DEVKIT_ROOT/nuplan/planning/script/run_simulation.py \
+simulation=$CHALLENGE \
planner=$PLANNER \
planner.diffusion_planner.config.args_file=$ARGS_FILE \
planner.diffusion_planner.ckpt_path=$CKPT_FILE \
scenario_builder=$SCENARIO_BUILDER \
scenario_filter=$SPLIT \
experiment_uid=$PLANNER/$SPLIT/$BRANCH_NAME/${FILENAME_WITHOUT_EXTENSION}_$(date "+%Y-%m-%d-%H-%M-%S") \
verbose=true \
worker=ray_distributed \
worker.threads_per_node=64 \
distributed_mode='SINGLE_NODE' \
number_of_gpus_allocated_per_simulation=0.15 \
enable_simulation_progress_bar=true \
hydra.searchpath="[pkg://diffusion_planner.config.scenario_filter, pkg://diffusion_planner.config, pkg://nuplan.planning.script.config.common, pkg://nuplan.planning.script.experiments ]"
2.2、使用nuboard可视化
# Useful imports
import os
from pathlib import Path
import tempfile
import hydra
import sys
RESULT_FOLDER = "/D2/NXT/zgh/src/Diffusion-Planner/model_2025-08-22-09-42-24"
# simulation result absolute path (e.g., "/data/nuplan-v1.1/exp/exp/simulation/closed_loop_nonreactive_agents/diffusion_planner/val14/diffusion_planner_release/model_2025-01-25-18-29-09")
env_variables = {
"NUPLAN_DEVKIT_ROOT": "/D2/NXT/zgh/src/nuplan-devkit", # nuplan-devkit absolute path (e.g., "/home/user/nuplan-devkit")
"NUPLAN_DATA_ROOT": "/D2/NXT/aip/nuplan/origin_db/test", # nuplan dataset absolute path (e.g. "/data")
"NUPLAN_MAPS_ROOT": "/D2/NXT/aip/maps", # nuplan maps absolute path (e.g. "/data/nuplan-v1.1/maps")
"NUPLAN_EXP_ROOT": "REPLACE_WITH_EXP_DIR", # nuplan experiment absolute path (e.g. "/data/nuplan-v1.1/exp")
"NUPLAN_SIMULATION_ALLOW_ANY_BUILDER":"1"
}
for k, v in env_variables.items():
os.environ[k] = v
# Location of path with all nuBoard configs
CONFIG_PATH = '../nuplan-devkit/nuplan/planning/script/config/nuboard' # relative path to nuplan-devkit
CONFIG_NAME = 'default_nuboard'
# Initialize configuration management system
hydra.core.global_hydra.GlobalHydra.instance().clear() # reinitialize hydra if already initialized
hydra.initialize(config_path=CONFIG_PATH)
ml_planner_simulation_folder = RESULT_FOLDER
ml_planner_simulation_folder = [dp for dp, _, fn in os.walk(ml_planner_simulation_folder) if True in ['.nuboard' in x for x in fn]]
# Compose the configuration
cfg = hydra.compose(config_name=CONFIG_NAME, overrides=[
'scenario_builder=nuplan', # set the database (same as simulation) used to fetch data for visualization
f'simulation_path={ml_planner_simulation_folder}', # nuboard file path(s), if left empty the user can open the file inside nuBoard
'hydra.searchpath=[pkg://diffusion_planner.config.scenario_filter, pkg://diffusion_planner.config, pkg://nuplan.planning.script.config.common, pkg://nuplan.planning.script.experiments]',
'port_number=6599'
])
from nuplan.planning.script.run_nuboard import main as main_nuboard
# Run nuBoard
main_nuboard(cfg)
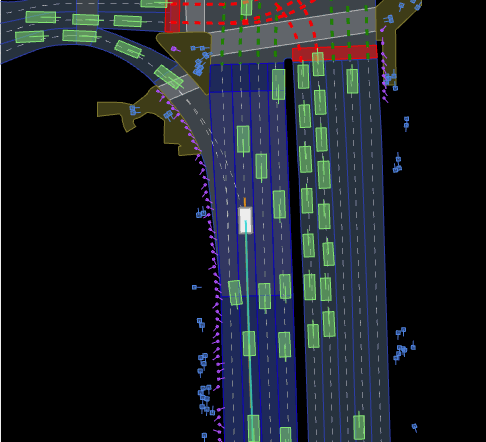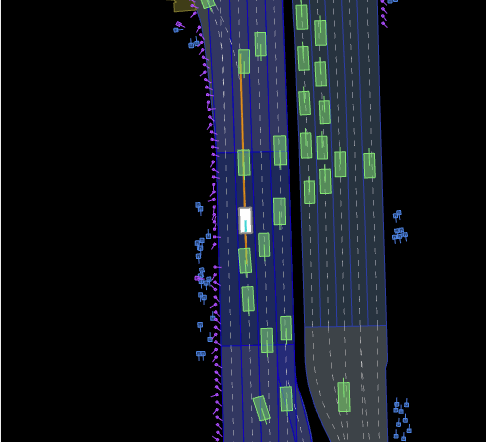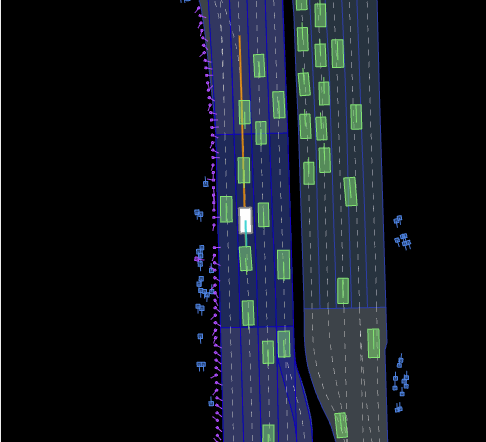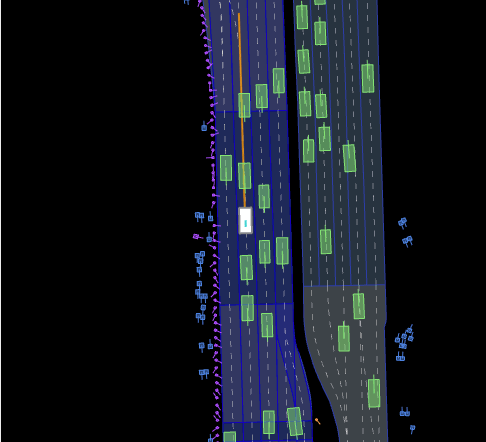
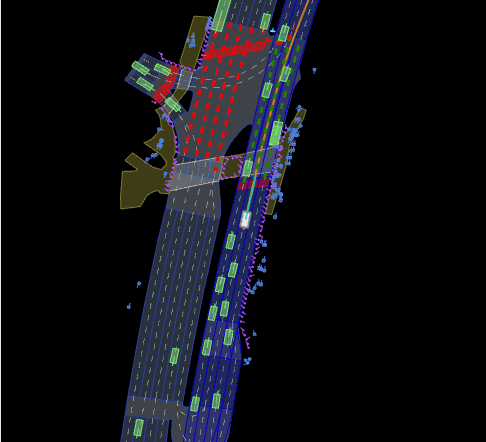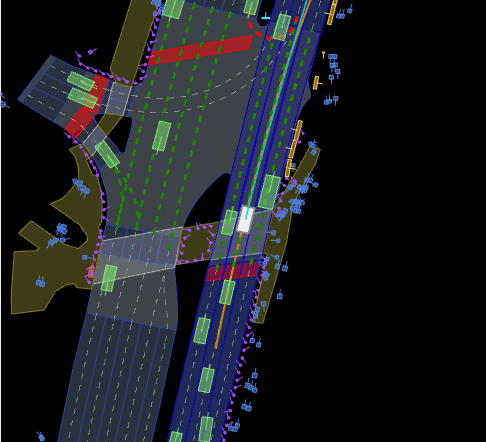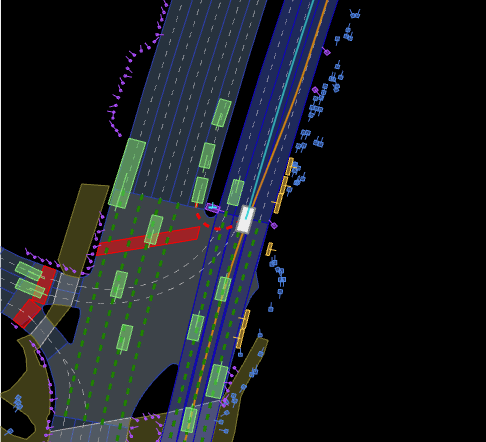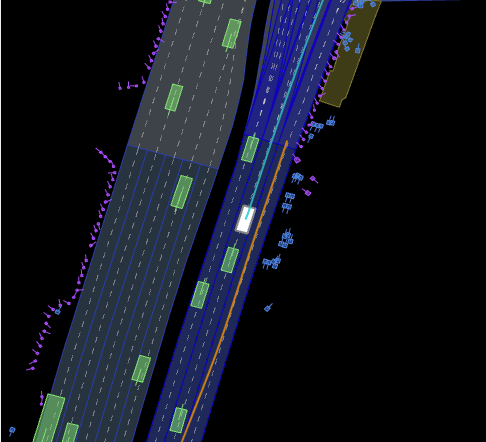
三、生产训练数据
执行data_process.sh脚本
###################################
# User Configuration Section
###################################
NUPLAN_DATA_PATH="/.../nuplan/origin_db/trainval" # nuplan training data path (e.g., "/data/nuplan-v1.1/trainval")
NUPLAN_MAP_PATH="/.../maps" # nuplan map path (e.g., "/data/nuplan-v1.1/maps")
TRAIN_SET_PATH="/.../nuplan_cache_250822_diffusion_planner" # preprocess training data
###################################
python data_process.py \
--data_path $NUPLAN_DATA_PATH \
--map_path $NUPLAN_MAP_PATH \
--save_path $TRAIN_SET_PATH \
--total_scenarios 1000000 \

我这边一台机器生产100万数据大概需要2周左右的时间,觉得慢的可以用多台机器并行跑。
三、训练
错误修改:Diffusion-Planner/diffusion_planner/model/module/decoder.py的初始化中
# self._guidance_fn = config.guidance_fn
self._guidance_fn = getattr(config, 'guidance_fn', None)
3.1、单卡训练
python train_predictor.py \
--train_set /D2/NXT/aip/nuplan/cache/nuplan_cache_250822_diffusion_planner_mini \
--train_set_list diffusion_planner_training_mini.json \
--ddp False \
--batch_size 128 \
--train_epochs 500 \
--save_dir /D2/NXT/zgh/src/Diffusion-Planner/output
3.2、多机多卡训练
创建bash脚本
train_diffusion.sh
# Set training data path
TRAIN_SET_PATH="/D2/NXT/aip/nuplan/cache/nuplan_cache_250822_diffusion_planner" # preprocess data using data_process.sh
TRAIN_SET_LIST_PATH="diffusion_planner_training.json"
###################################
node_num=2
torchrun \
--nproc_per_node=8 \ #每台机器有8个GPU
--nnodes=$node_num \ #有几台机器
--master_addr=10.66.8.35 \ #master机器的内网ip
--master_port=15991 \ #我这是随便写的
--node_rank=$1 \ #机器号,master机器是0
train_predictor.py \
--train_set $TRAIN_SET_PATH \
--train_set_list $TRAIN_SET_LIST_PATH \
--batch_size 1024 \
--save_dir /D2/NXT/zgh/src/Diffusion-Planner/output_100W \
用这种方式训练需要修改ddp初始化代码,diffusion_planner/utils/ddp.py
def ddp_setup_universal(verbose=False, args=None):
if args.ddp == False:
print(f"do not use ddp, train on GPU 0")
return 0, 0, 1
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
print("1")
rank = int(os.environ["RANK"])
world_size = int(os.environ['WORLD_SIZE'])
gpu = int(os.environ['LOCAL_RANK'])
# os.environ['MASTER_PORT'] = str(getattr(args, 'port', '29529'))
# os.environ["MASTER_ADDR"] = "localhost"
elif 'SLURM_PROCID' in os.environ:
print("2")
rank = int(os.environ['SLURM_PROCID'])
gpu = rank % torch.cuda.device_count()
world_size = int(os.environ['SLURM_NTASKS'])
node_list = os.environ['SLURM_NODELIST']
num_gpus = torch.cuda.device_count()
addr = subprocess.getoutput(f'scontrol show hostname {node_list} | head -n1')
os.environ['MASTER_PORT'] = str(args.port)
os.environ['MASTER_ADDR'] = addr
else:
print("Not using DDP mode")
return 0, 0, 1
print(f'gpu{gpu}')
os.environ['WORLD_SIZE'] = str(world_size)
os.environ['LOCAL_RANK'] = str(gpu)
os.environ['RANK'] = str(rank)
torch.cuda.set_device(gpu)
dist_backend = 'nccl'
dist_url = "env://"
print('| distributed init (rank {}): {}, gpu {}'.format(rank, dist_url, gpu), flush=True)
print(f'world_size:{world_size},rank:{rank}')
# dist.init_process_group(backend=dist_backend, world_size=world_size, rank=rank,init_method='env://')
dist.init_process_group(backend=dist_backend,init_method='env://')
torch.distributed.barrier()
if verbose:
setup_for_distributed(rank == 0)
return rank, gpu, world_size
同时需要在master机器的终端查看一下网卡名
ip addr
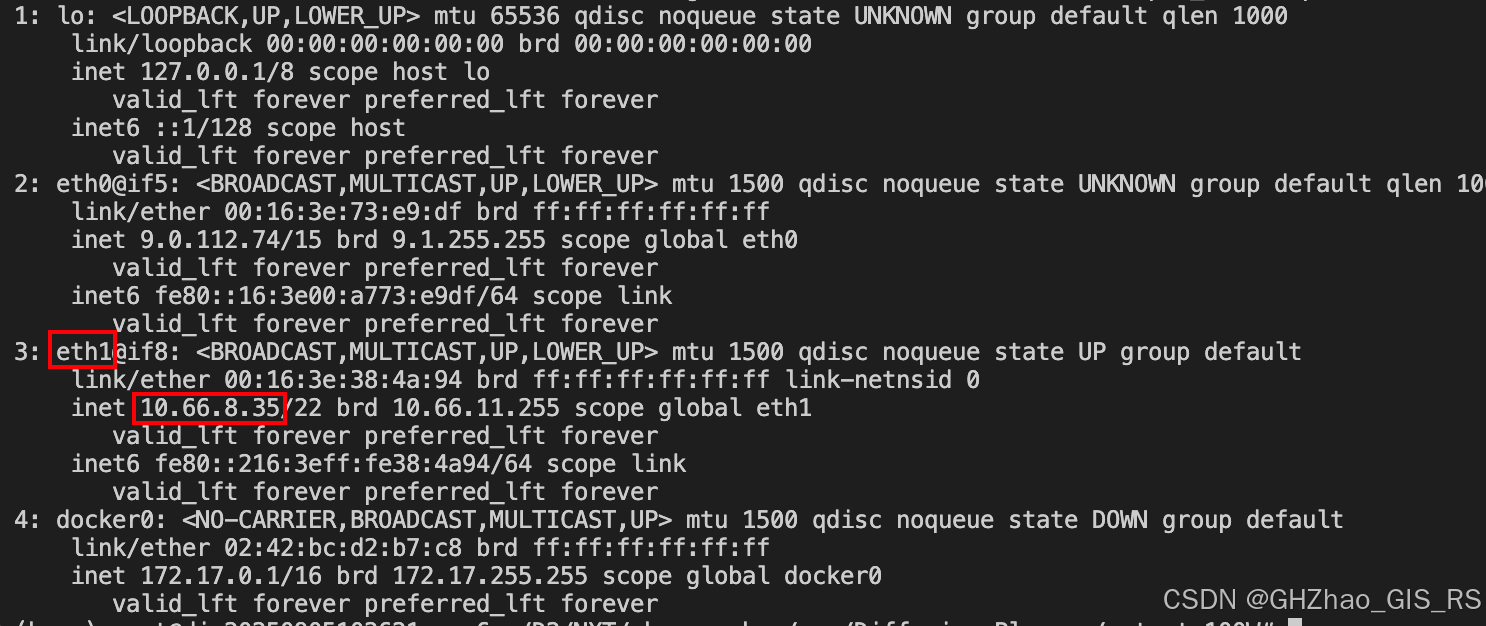
设置环境变量
export NCCL_SOCKET_IFNAME=eth1
export GLOO_SOCKET_IFNAME=eth1
我一开始写成了eth0,导致两台机器不通。
我这里用了两台机器
master机器执行
bash train_diffusion.sh 0
第二台机器执行
bash train_diffusion.sh 0
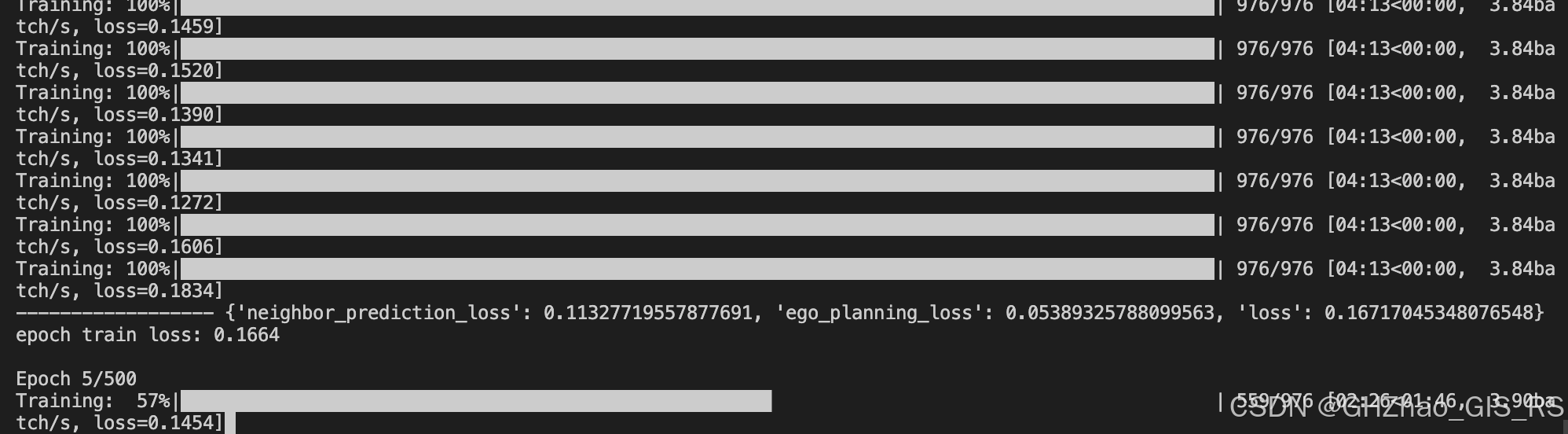
可以在第一台机器上看到训练过程
四、仿真测试
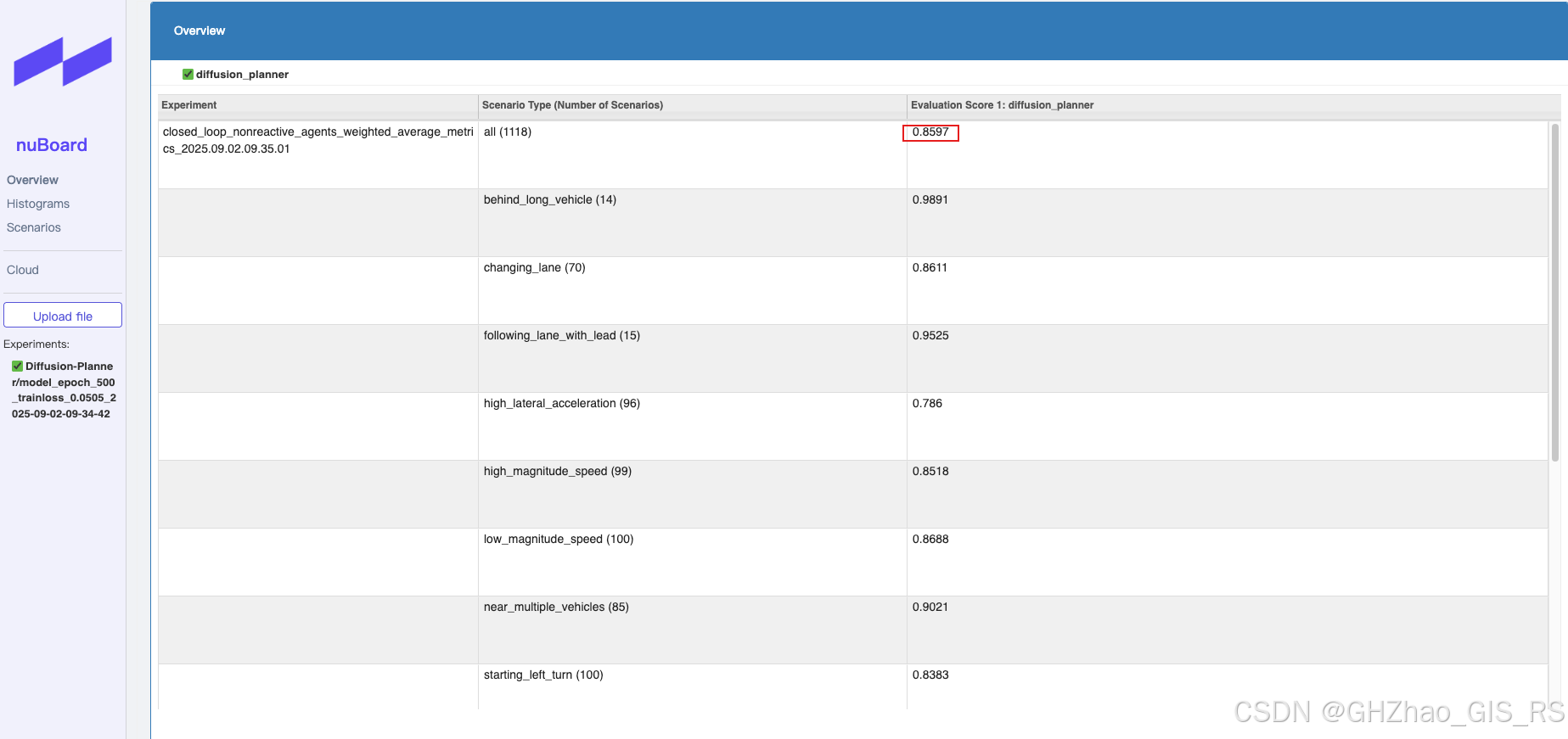
由于100万数据生产比较慢,我先用生产好的40万数据做了训练,拿最后一个模型进行val14和test-random14
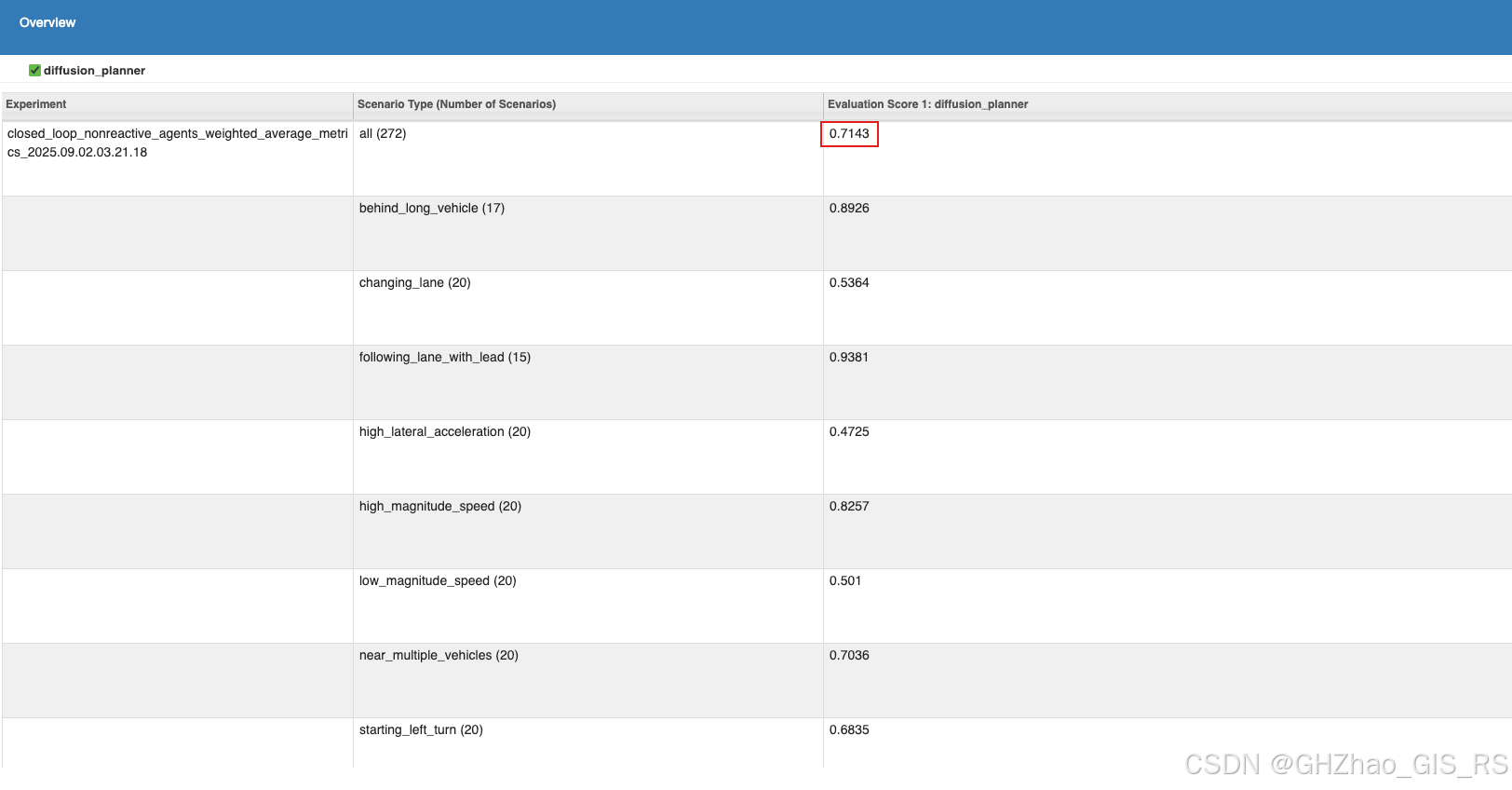
4.1、val14测试集结果
4.2、test14-hard测试集结果