目录
1、残差提升树 Boosting Decision Tree
一、梯度提升树
1、残差提升树 Boosting Decision Tree
思想:通过拟合残差的思想来进行提升,残差:真实值 - 预测值
例如:

2、梯度提升树 Gradient Boosting Decision Tree
梯度提升树不再拟合残差,而是利用梯度下降的近似方法,利用损失函数的负梯度作为提升树算法中的残差近似值。

GBDT 拟合的负梯度就是残差。如果我们的 GBDT 进行的是分类问题,则损失函数变为 logloss,此时拟合的目标值就是该损失函数的负梯度值。
二、构建案例
已知:
1、 初始化弱学习器(CART树):
当模型预测值为何值时,会使得第一个弱学习器的平方误差最小,即:求损失函数对 f(xi) 的导数,并令导数为0。

2、 构建第1个弱学习器
根据负梯度的计算方法得到下表:


以此类推,计算所有切分点情况,得到:
由此得到,当 6.5 作为切分点时,平方损失最小,此时得到第1棵决策树。
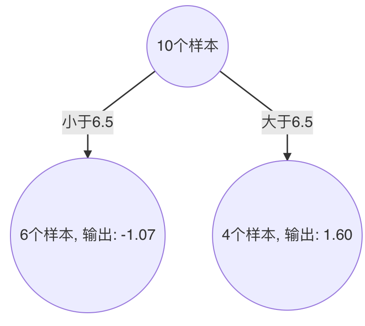
3、 构建第2个弱学习器

以此类推,计算所有切分点情况,得到:

以3.5 作为切分点时,平方损失最小,此时得到第2棵决策树
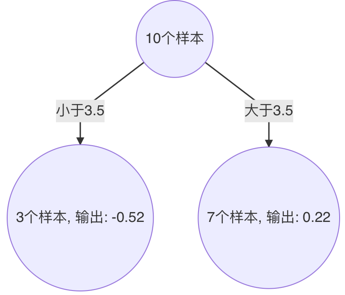
4、 构建第3个弱学习器

以此类推,计算所有切分点情况,得到:

以6.5 作为切分点时,平方损失最小,此时得到第3棵决策树
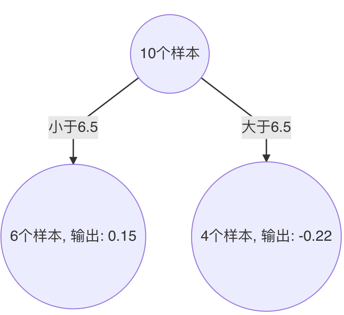
5、 构建最终弱学习器
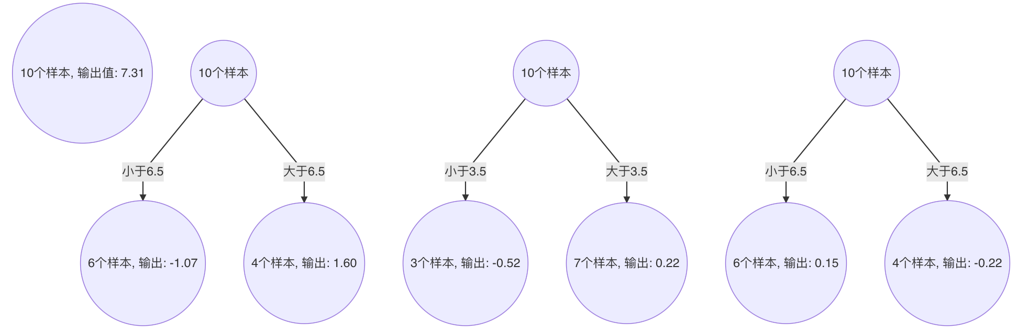
以 x=6 样本为例:输入到最终学习器中的结果 :(存在误差,说明学习器不够)
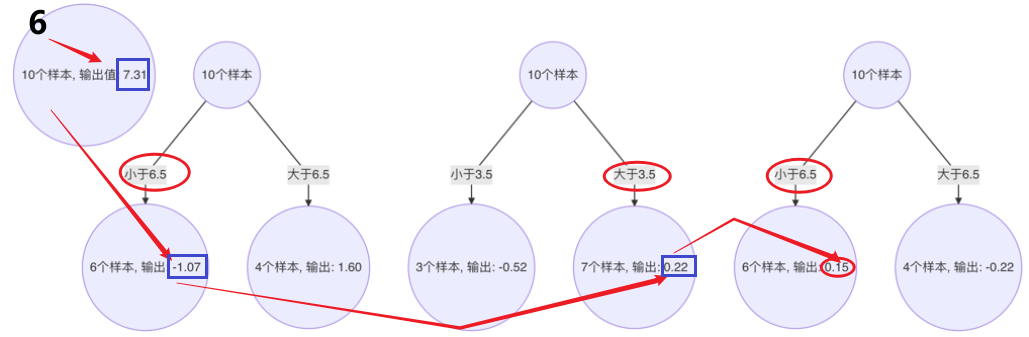
以此类推计算其他的预测值
6、 构建总结
- 初始化弱学习器(目标值的均值作为预测值)
- 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度
- 直到达到指定的学习器个数
- 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出
三、XGBoost
极端梯度提升树,集成学习方法的王牌,在数据挖掘比赛中,大部分获胜者用了XGBoost。
1、Xgb的构建思想
1、构建模型的方法是最小化训练数据的损失函数: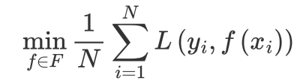
训练的模型复杂度较高,易过拟合。
2、在损失函数中加入正则化项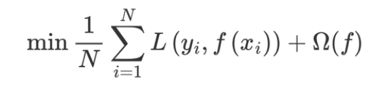 , 提高对未知的测试数据 的泛化性能 。
, 提高对未知的测试数据 的泛化性能 。
2、公式
XGBoost(Extreme Gradient Boosting)是对GBDT的改进,并且在损失函数中加入了正则化项
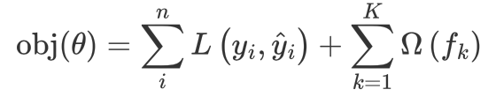
正则化项用来降低模型的复杂度
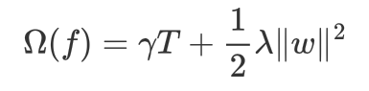
![]() 中的 T 表示一棵树的叶子结点数量。
中的 T 表示一棵树的叶子结点数量。
![]() 中的 w 表示叶子结点输出值组成的向量,
中的 w 表示叶子结点输出值组成的向量,![]() 向量的模; λ对该项的调节系数
向量的模; λ对该项的调节系数
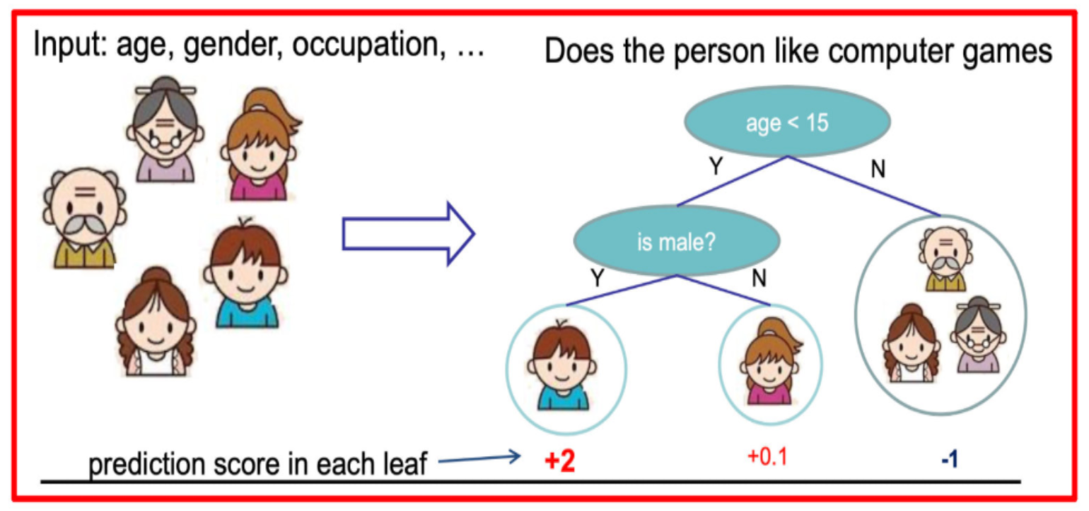
假设我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分
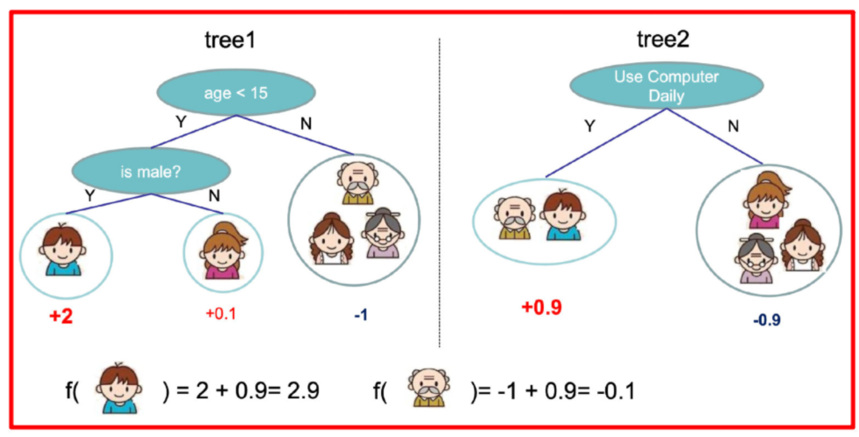
训练出tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论
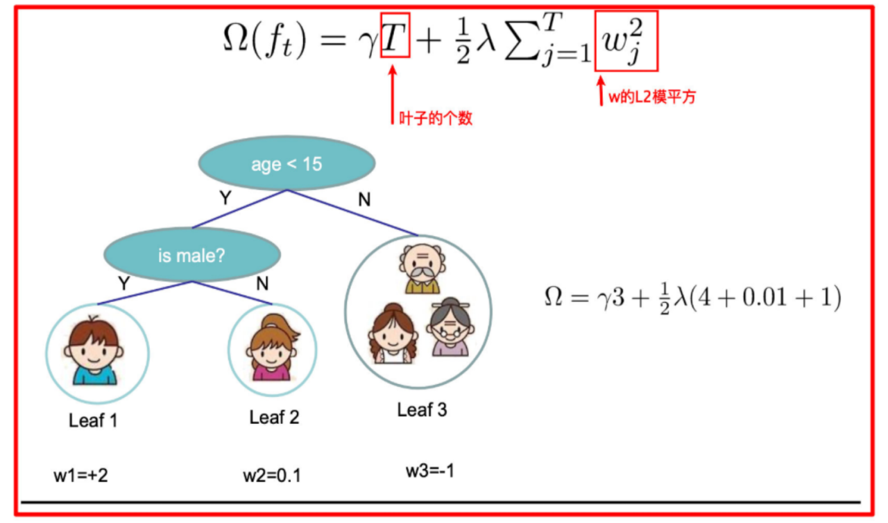
树tree1的复杂度表示为
以此类推,树tree2的复杂度表示为
目标函数为:(推导过程比较复杂,可以另行学习)
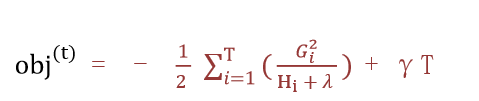

该公式也叫做打分函数 (scoring function),从损失函数、树的复杂度两个角度来衡量一棵树的优劣。当我们构建树时,可以用来选择树的划分点,具体操作如下式所示:
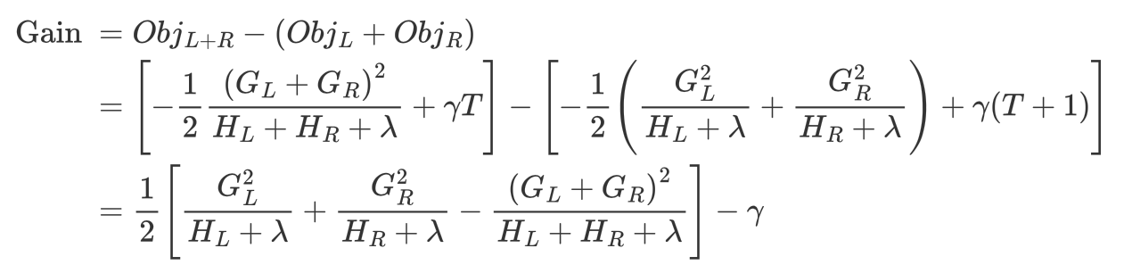
计算的gain值:
1、对树中的每个叶子结点尝试进行分裂
2、计算分裂前 - 分裂后的分数:
- 如果gain > 0,则分裂之后树的损失更小,会考虑此次分裂
- 如果gain< 0,说明分裂后的分数比分裂前的分数大,此时不建议分裂
3、当触发以下条件时停止分裂:
- 达到最大深度 叶子结点数量低于某个阈值
- 所有的结点在分裂不能降低损失
- 等等...
3、XGBoost关键优势
XGBoost通过多项技术创新实现高效训练和强大泛化能力:
1、正则化:在目标函数中加入L1(LASSO)和L2(Ridge)正则化项,惩罚复杂的树结构(如叶子节点数量过多、权重过大),有效抑制过拟合。
2、并行处理:虽然Boosting是串行过程,但XGBoost在特征排序和分裂点选择上支持并行计算(特征间并行),大幅提升训练速度。
3、加权分位法(Weighted Quantile Sketch):用于近似寻找最佳分裂点,仅需考察部分候选点,提升大规模数据下的计算效率。
4、稀疏感知(Sparsity-aware):能自动学习处理缺失值的最佳方向(默认分到左子树或右子树),无需预先填充,并对稀疏数据(如One-hot编码)高效处理。
5、缓存访问优化(Cache-aware Access):通过优化数据存储和访问模式(如按块访问),提高CPU缓存命中率,加速计算。
6、核外计算(Blocks for Out-of-core):当数据无法全部装入内存时,可将数据分块存储在磁盘上,通过块压缩和预取(预取到内存缓冲区)技术减少IO开销,支持大规模数据训练。
XGBoost通过集成学习思想、梯度提升框架,并结合正则化、并行计算、稀疏感知等一系列优化,实现了预测精度与训练效率的卓越平衡。其灵活性、鲁棒性和广泛适用性使其成为处理结构化数据任务的强有力工具,是许多数据科学家和机器学习实践者的首选算法之一。