摘要
背景与问题
大语言模型出色的生成能力引发了伦理与法律层面的担忧,于是通过嵌入水印来检测机器生成文本的方法逐渐发展起来。但现有工作在代码生成任务中无法良好发挥作用,原因在于代码生成任务本身的特性(代码有其特定的语法、逻辑结构,与一般自然文本生成规律不同,现有水印方法适配性不足),具体表现为对代码质量的保留效果差。
通过扩展了 “修改对数(logit - modifying)” 的水印方法,提出了 “通过熵阈值选择的水印(Selective WatErmarking via Entropy Thresholding,SWEET)”。其核心思路是:在生成和检测水印时,移除低熵的代码片段。低熵通常意味着内容更具确定性、规律性(比如代码中重复的结构、固定的语法模板等),移除这类片段有助于让水印更贴合代码生成的特点,减少对代码正常逻辑和质量的干扰。
第一章 引言

图1
大语言模型(LLMs)在代码生成领域的表现,正以惊人速度向专家水准靠拢。从提升软件工程师的生产效率,到降低非专业人士编程的门槛,它带来的便利有目共睹。但就像一枚硬币有正反两面,大模型在代码领域的飞速发展,也带来了一系列法律、伦理和安全方面的 “暗礁”。代码许可争议、剽窃问题、漏洞隐患,还有恶意软件生成等,都让人们忧心忡忡。比如,一群个人和微软、GitHub、OpenAI 之间,就因涉嫌非法使用与复制源代码,陷入了一场版权集体诉讼。更让人警惕的是,ChatGPT 推出后不久,暗网上就有不少恶意分子分享机器生成的恶意软件和鱼叉式网络钓鱼教程。
在这样的背景下,开发能检测机器生成代码的可靠工具,就成了迫在眉睫且意义重大的事,这对公平部署具备编码能力的大语言模型来说,是关键一步。而像论文里提到的 “SWEET(通过熵阈值选择的水印)” 这类技术,就是探索解决之道的尝试。它致力于在保证代码质量的同时,有效检测出机器生成的代码,为代码生成领域的知识产权保护、安全规范等,提供更有力的技术支撑,助力大模型在代码世界里更健康地发展。
尽管机器生成代码的检测问题亟待解决,但目前针对该问题的研究成果寥寥。相反,众多研究仍将重点放在普通文本的检测问题上(引用了 Solaiman 等人 2019 年、Ippolito 等人 2020 年等诸多相关研究)。
虽然这些 “事后检测” 方法(即在文本生成过程中不进行控制)在自然语言处理的众多领域展现出了强大的性能,但它们在编程语言领域的应用仍未得到充分探索。简单来说,就是现在大家更关注普通文本的检测,而机器生成代码的检测研究很缺,而且那些适用于普通文本的事后检测方法,在代码领域还没怎么被研究过能不能用。
与 “事后检测” 方法不同,另一种用于检测机器生成文本的研究方向受到了关注:基于水印的方法。这类方法会在生成的文本中嵌入隐藏信号(引用了 Kirchenbauer 等人 2023a、b;Kuditipudi 等人 2023;Wang 等人 2023 的研究)。
以 Kirchenbauer 等人(2023a)提出的一种方法为例(我们称之为 WLLM,即大语言模型水印法):在每一个生成步骤中,它会将整个词汇表随机分成两组(即 “绿色列表” 和 “红色列表”),并提高从绿色列表中选取标记(tokens)的概率。具体来说,通过给绿色列表标记的对数概率(logits)添加标量值,模型会更倾向于生成绿色列表中的标记,而非红色列表里的。要检测文本中的水印,我们需要统计绿色标记的数量,然后通过假设检验来判断这个数量是否具有统计显著性,从而推断出模型输出是否是在不了解 “绿 - 红规则” 的情况下生成的。
虽然基于水印的方法和事后检测方法在许多语言生成任务中都能很好地发挥作用,但我们观察到,这些性能在代码生成任务中并不能很好地迁移,比如在图 1 中就有体现。换句话说,以一种可检测的方式嵌入水印,同时又不损害代码功能,要困难得多。我们将此归因于代码生成熵极低的特性。
如果强力应用水印,会严重降低模型输出的质量,这在代码生成中尤为关键,因为哪怕违反一条规则,都可能使整个代码崩溃(见图 1 中的 “强水印”)。另一方面,如果水印应用得太弱,低熵会阻碍水印的恰当嵌入,导致绿色标记出现不足,进而增加检测难度(见图 1 中的 “弱水印”)。这些问题在普通文本生成中并不显著,因为相对较高的熵让水印候选选择更具灵活性。
1.1方法提出与优势
为了解决这些失效模式,我们扩展了 WLLM,并为代码大语言模型(以及通用大语言模型)提出了通过熵阈值选择的水印方法(Selective WatErmarking via Entropy Thresholding,SWEET)。不再对生成过程中的每个标记都应用 “绿 - 红” 规则,而是仅对熵足够高(基于设定的阈值)的标记应用该规则(这是与KGW方法的最大区别)。也就是说,我们不对那些对实现代码功能至关重要的标记应用 “绿 - 红” 规则,同时确保有足够多的绿色列表标记,以便为不太重要的标记生成可检测的水印,从而直接解决上述每种失效模式。在代码生成任务中,我们的方法在检测机器生成代码方面超越了所有基准方法(包括事后检测方法),同时实现的代码质量下降程度比 WLLM 更小。此外,通过各种分析,我们证明即使在没有提示词,或者使用小型替代模型的情况下,我们的方法也能很好地运行,这表明它在实际场景中具有鲁棒性。
1.2研究贡献
我们的贡献如下:
- 我们是首个通过实证探索现有水印和事后检测方法在代码领域失效情况的研究。
- 我们提出了一种简单却有效的方法,名为 SWEET,它改进了 WLLM(Kirchenbauer 等人,2023),在机器生成代码检测方面实现了显著更高的性能,同时比 WLLM 更好地保留了代码质量。
- 我们已经证明了我们的方法在现实场景中的实用性和优越性,例如:1)不使用提示词;2)使用更小的模型作为检测器;3)面对改写攻击时。
第二章 相关工作
2.1软件水印(Software Watermarking)
软件水印是一个研究领域,旨在在不影响代码性能的前提下,将秘密信号嵌入代码中,以防止软件盗版。
- 静态水印(Static watermarking)(Hamilton and Danicic, 2011;Li and Liu, 2010;Myles et al., 2005):通常通过代码替换和重新排序的方式来嵌入水印。
- 动态水印(Dynamic watermarking)(Wang et al., 2018;Ma et al., 2019):则是在程序的编译或执行阶段注入水印。(若需详细综述,可参考 Dey et al., 2018)。
从大语言模型(LLM)生成的代码文本中嵌入水印,与静态水印更为接近。例如,Li 等人(2023c)提出了一种使用同义代码替换的方法。不过,由于这种方法严重依赖特定语言的规则,恶意用户一旦知晓这些规则,就可能逆向破解水印。
2.2大语言模型文本水印(LLM Text Watermarking)
大多数针对大语言模型(LLM)生成文本的水印方法,都是基于通过预先定义的规则集合(Atallah et al., 2001, 2002;Kim et al., 2003;Topkara et al., 2006;Jalil and Mirza, 2009;Meral et al., 2009;He et al., 2022a,b),或者另一个语言模型(比如基于 Transformer 的网络,Abdelnabi and Fritz, 2021;Yang et al., 2022;Yoo et al., 2023)来修改原始文本。
近来,有一类研究工作聚焦于在 LLM 的采样过程中,将水印嵌入到标记(tokens)里(Liu et al., 2024)。它们通过两种方式在 LLM 生成的文本中嵌入水印:一是修改来自 LLM 的对数概率(logits)(Kirchenbauer et al., 2023a,b;Liu et al., 2023a;Takezawa et al., 2023;Hu et al., 2023);二是操控采样过程(Christ et al., 2023;Kuditipudi et al., 2023)。此外,一些近期的研究关注水印对抗攻击的鲁棒性,即抵御移除水印的攻击(Zhao et al., 2023;Liu et al., 2023b;Ren et al., 2023)。最后,Gu 等人(2023)研究了水印在从教师模型到学生模型的蒸馏过程中的可学习性。
然而,这些水印方法在低熵场景下,水印检测性能会出现脆弱性(Kirchenbauer et al., 2023a;Kuditipudi et al., 2023),仅有少数研究(如 CTWL,Wang et al., 2023)试图解决这一问题。我们直接针对低熵情况下水印检测性能下降的问题,并在低熵任务(如代码生成)中证明了我们方法的有效性。
2.3事后检测(Post - hoc Detection)
事后检测方法的目标是在生成过程中不嵌入任何信号的情况下,区分出人类创作的文本和机器生成的文本。
其中一条研究路线是利用基于困惑度的特征,像 GPTZero(Tian 和 Cui,2023)、Sniffer(Li 等人,2023a)以及 LLMDet(Wu 等人,2023)都属于这类。另一条研究路线则是使用预训练的语言模型,例如 RoBERTa(Liu 等人,2019),并对其进行微调,将其作为分类器来识别文本来源(Solaiman 等人,2019;Ippolito 等人,2020;OpenAI,2023b;Guo 等人,2023;Yu 等人,2023;Mitrović等人,2023)。
与此同时,一些近期的研究在没有额外训练流程的情况下解决检测问题,比如 GLTR(Gehrmann 等人,2019)、DetectGPT(Mitchell 等人,2023)以及 DNA - GPT(Yang 等人,2023)。不过,事后检测方法仍然面临挑战。例如,虽然 GPTZero(Tian 和 Cui,2023)仍在使用,但 OpenAI 的 AI 文本分类器(OpenAI,2023b)在推出仅六个月后就因准确率问题停止使用了。此外,我们已经证明,事后检测方法在检测低熵的机器生成代码时是失败的。
第三章 方法(Method)
我们提出了一种新的水印方法 ——SWEET,它仅对熵足够高的标记(tokens)进行选择性水印嵌入。
3.1 动机(Motivation)
尽管之前的水印方法 WLLM(Kirchenbauer 等人,2023a)可以应用于大语言模型(LLM)生成文本的任何领域,但在代码生成中进行水印嵌入和检测时,会引发两个关键问题,这归因于水印强度方面的困境。
水印会导致性能下降。在编程语言中,表达相同含义的方式仅有少数几种,而且一个错误的标记就可能导致不理想的输出。如果像 WLLM 那样强力嵌入水印(WLLM 会在不利用任何上下文信息的情况下,随机将词汇表分为绿色和红色列表,只提升绿色列表标记的对数概率),必然会增加生成错误标记的可能性。例如,在图 2(a)中,第二行的 “return” 标记之后,对数概率最高的下一个标记是 “sum”,这也是标准解决方案的一部分。但 WLLM 把 “sum” 放到了红色列表,而把 “mean” 放到了绿色列表。因此,采样到的标记是 “mean”,从而导致了语法错误。

图2
3.2图2解析:
- 问题与标准解法:左侧呈现了 HumanEval/4 的问题(要求实现计算平均绝对偏差的函数)以及标准的正确解法。
- 不同方法的代码生成与指标:
- (a)WLLM:生成的代码存在错误(Correctness 为 ×),水印可检测性低(z - score 仅 2.45,水印嵌入比例 1.0)。代码里错误地使用了
mean相关操作,偏离了标准解法中基于sum计算均值的逻辑。 - (b)SWEET - 低熵阈值:生成的代码仍错误(Correctness 为 ×),虽 z - score 提升到 3.39,但水印嵌入比例降至 0.44,代码质量未得到有效改善。
- (c)SWEET - 中等熵阈值:生成的代码正确(Correctness 为√),z - score 达到峰值 4.96,水印嵌入比例 0.20。代码逻辑贴合标准解法,通过合理的变量定义(如
distances列表)和计算步骤,实现了平均绝对偏差的正确计算。 - (d)SWEET - 高熵阈值:代码正确(Correctness 为√),z - score 为 4.67,水印嵌入比例 0.19。代码逻辑同样正确,但相比中等熵阈值,z - score 有所下降。
- (a)WLLM:生成的代码存在错误(Correctness 为 ×),水印可检测性低(z - score 仅 2.45,水印嵌入比例 1.0)。代码里错误地使用了
3.3低熵序列会避免被加水印。
另一个关键问题是,当水印强度过弱,无法在低熵文本中嵌入水印时,若红色列表的标记具有极高的对数概率(logit)值,以至于必然会被生成,就会阻碍水印检测。例如,在图 2(a)中,带有白色背景的标记代表低熵且几乎没有候选标记。这在代码生成任务中会变得更为致命,因为代码生成的结果相对普通文本更短,比如只要求生成一个函数的代码块⁶。WLLM 的检测方法基于统计检验,涉及统计整个长度内绿色列表标记的数量。然而,如果文本长度较短,基于统计检验的水印检测效果就会下降⁷。
3.4SWEET 方法
SWEET 能够通过区分可应用水印的标记,缓解水印强度方面的困境,也就是说,我们仅在熵高的标记中嵌入和检测水印。
生成阶段:我们方法的生成步骤如算法 1 所示。给定一个分词后的提示以及已生成的标记
,模型会计算
的概率分布的熵值
。然后,只有当
高于阈值τ时,我们才应用水印。我们以固定的绿色标记比例
,将词汇表随机分为绿色和红色两类。如果一个标记被选中进行水印嵌入,我们就给绿色标记的对数概率(logits)加上一个常数
,目的是促进绿色标记的采样。通过仅对高熵的标记促进绿色标记的采样,我们防止了模型对其有信心(因此熵低)的标记的对数概率分布发生变化,从而保留了代码质量。
具体说明:
假设我们要生成一个计算数组元素和的 Java 方法,以此具体展示 SWEET 方法的生成阶段:
初始状态
- 提示词分词后
:
["Write", "a", "Java", "method", "to", "calculate", "the", "sum", "of", "an", "array", "of", "integers", "."] - 已生成标记
:
["public", "static", "int", "sumArray", "(", "int", "[", "nums", "]"]
- 提示词分词后
计算下一个标记的熵值
- 模型预测下一个标记时,候选可能有
{")", ":", "{\n", "//"} - 这些候选标记的概率分布比较分散(比如各占 20% - 30% 左右),计算得到熵值
,假设阈值
,由于
,触发水印嵌入。
- 模型预测下一个标记时,候选可能有
应用水印机制
- 设定绿色标记比例
,随机将词汇表分为绿色列表(如
{")", "{\n"})和红色列表(如{":", "//"})。 - 给绿色列表标记的对数概率增加
,调整后:
- 原概率:
")": 25%,"{\n": 20%,":": 30%,"//": 25%。 - 调整后概率:
")": 38%,"{\n": 32%,":": 20%,"//": 10%。
- 原概率:
- 设定绿色标记比例
采样生成下一个标记
- 最终采样到绿色列表中的
")",已生成标记更新为["public", "static", "int", "sumArray", "(", "int", "[", "nums", "]", ")"]。
- 最终采样到绿色列表中的
继续生成后续标记
- 当下一个预测标记为
"{"时,模型对这个方法体开始的大括号标记的概率预测高达 90%,计算得到,不应用水印。
- 直接按照原概率分布采样,保留
"{"这一低熵但关键的语法标记。
- 当下一个预测标记为
通过这样的过程,SWEET 只在")"这类高熵标记上嵌入水印,既确保了"public"、"{"等低熵关键标记的生成质量,又通过对绿色列表标记的选择性增强实现了水印嵌入。
3.5检测(Detection)
我们在算法 2 中概述了检测过程。给定一个标记序列,标记序列:就是大模型生成的代码,我们的任务是检测
中是否存在水印,从而确定它是否由特定的语言模型生成。与生成阶段类似,我们为每个
计算熵值
。令
表示熵值
高于阈值τ的标记数量,令
表示在
中绿色标记的数量。最后,利用生成步骤中使用的整个词汇表的绿色列表比例
,在文本未被水印嵌入的零假设下,计算z分数:
z分数越高,我们就越有信心认为文本被嵌入了水印。我们将设为临界分数。如果
成立,我们就判定水印被嵌入到
中,因此该文本是由大语言模型(LLM)生成的。检测阶段中熵阈值的影响将在后续章节中描述。
具体说明:
假设我们有一段生成的 Java 代码标记序列\(\boldsymbol{y}\),用于实现计算数组元素和的功能,来具体说明检测过程:
步骤 1:确定标记序列
标记序列为:
["public", "static", "int", "sumArray", "(", "int", "[", "nums", "]", ")", "{", "int", "sum", "=", "0", ";", "for", "(", "int", "i", "=", "0", ";", "i", "<", "nums", ".", "length", ";", "i++", ")", "{", "sum", "+", "=", "nums", "[", "i", "]", ";", "}", "return", "sum", ";", "}"]
步骤 2:计算每个标记的熵值 并统计相关数量
并统计相关数量
- 对序列中每个标记
计算熵值
- 熵值
的标记(即
对应的标记)有:
"sumArray","sum","length","i++","return",共个。
- 在这
对应的标记)有:
"sumArray","sum","return",共个。
- 熵值
步骤 3:设定绿色列表比例 并计算z分数
并计算z分数
- 假设生成步骤中使用的整个词汇表的绿色列表比例
。
- 根据公式
,代入
步骤 4:与临界分数比较判定结果
- 假设设定的临界分数
常见的统计临界值,对应 90% 置信水平单侧检验)。
- 由于计算得到的
,所以判定这段代码序列
没有被嵌入该方法对应的水印,即不认为是由特定大语言模型生成的(当然,实际情况中若z大于临界值则判定为是)。
3.6 熵阈值的影响(Effect of Entropy Thresholding)
本节将展示,基于熵阈值的选择性水印检测能够提高可检测性。
定理 1 表明,与 WLLM 相比,通过 SWEET 检测方法,我们能够确保z分数有更高的下限。这是通过忽略低熵的标记来实现的,这会提高文本中绿色标记的比例,进而提升可检测性。为了进行理论分析,我们使用了尖峰熵(公式 4),它是 Kirchenbauer 等人(2023a)中定义的熵的一个变体。在实际应用中,我们使用公式 5 中的熵。
定理 1
考虑由带水印的代码大语言模型(LLM)生成的标记序列。
是对应的尖峰熵序列,其中模量为
。令
为熵阈值,
和
分别为尖峰熵低于或高于该阈值的标记数量。
若关于低熵标记比例的如下假设成立:那么,当应用熵阈值时,z分数始终存在一个更高的下限。其中,
,
,且
(1为指示函数,满足条件时取 1,否则取 0)。
注记:该假设意味着,选择一个不会忽略过多标记的熵阈值十分重要。
第四章 实验
我们开展了一系列实验,从两个方面评估我们的水印方法在代码生成任务中的有效性:(i)质量保持能力;(ii)检测强度。我们的基础模型是 StarCoder(Li 等人,2023b),它是一款专门用于代码生成的开源大语言模型(LLM)。我们还在一款通用大语言模型 LLaMA2(Touvron 等人,2023)上进行了实验(实验结果见附录 F)。
4.1 任务与指标(Tasks and Metrics)
我们选取了三项 Python 代码生成任务,即 HumanEval(Chen 等人,2021)、MBPP(Austin 等人,2021)和 DS - 1000(Lai 等人,2023),作为主要的测试平台。这些任务包含 Python 编程问题、测试用例以及人类编写的标准答案。大语言模型会被给予编程问题提示,并需要生成能通过测试用例的正确代码。为了在更多样化的软件开发场景(如其他语言或其他代码生成范围)中评估我们方法的性能,我们还纳入了另外两个数据集:HumanEvalPack(Muenighoff 等人,2024)和 ClassEval(Du 等人,2023)。有关这些基准测试的实现细节,请参考附录 E。
为了评估生成的源代码的功能质量,我们使用 pass@k(Chen 等人,2021)指标,即对于每个编程问题,生成个输出。该指标用于估计生成的代码中能正确运行的比例。对于检测能力,我们使用 AUROC(即 ROC 曲线下面积)值作为主要指标。我们还报告了当假阳性率(FPR;将人类编写的代码错误检测为大语言模型生成的代码)被限制在低于 5% 时的真阳性率(TPR;将大语言模型生成的代码正确检测为大语言模型生成的代码)。这是为了观察实际场景下的检测比例,在实际场景中,高假阳性比假阴性更不受欢迎。
4.2 基准方法(Baselines)
我们将 SWEET 与机器生成文本检测的基准方法进行对比。事后检测基准方法在生成过程中无需任何修改,因此绝不会损害模型输出的质量。LOGP (X)、LOGRANK(Gehrmann 等人,2019)和 DETECTGPT(Mitchell 等人,2023)是零样本检测方法,不需要带标签的数据集。GPTZERO(Tian 和 Cui,2023)和 OPENAI CLASSIFIER(Solaiman 等人,2019)是经过训练的分类器。对于基于水印的方法,我们纳入了两个基准:WLLM(Kirchenbauer 等人,2023a)和 EXP - EDIT(Kuditipudi 等人,2023)。为了嵌入水印,像 WLLM 或我们的方法这类会扭曲模型采样分布的方法,往往具有更好的检测能力,但可能会导致文本质量下降。另一方面,EXP - EDIT 预计不会造成文本质量下降,因为它们不会扭曲模型的采样分布⁸。更多实现细节见附录 D。
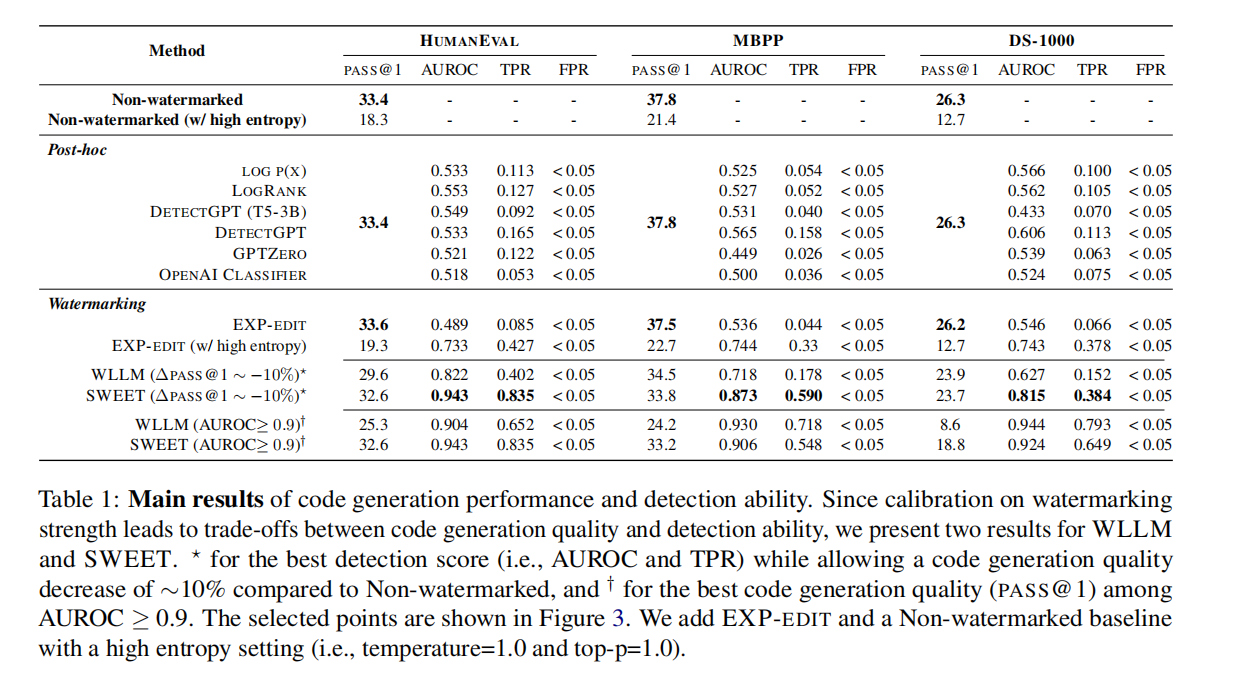
表1
表1解释:
先明确两个核心评价维度
- 代码生成质量:用 “PASS@1” 表示,数值越高越好。意思是 “生成 1 份代码,能通过测试用例的概率”(比如 33.4 表示 33.4% 的概率正确)。
- 检测能力:
- “AUROC”:数值越接近 1 越好,反映 “能否准确区分机器生成代码和人类代码” 的整体能力(0.9 以上算优秀)。
- “TPR@FPR=5%”:在 “错误把人类代码当成机器生成” 的概率≤5% 时,“正确识别机器生成代码” 的概率,数值越高越好。
不同方法的表现对比
1. 无水印方法(作为基准)
- “Non-watermarked”:正常生成代码,不加水印。
- 优点:代码质量最高(PASS@1 在三个任务中分别是 33.4、37.8、26.3)。
- 缺点:无法检测(因为没水印)。
- “Non-watermarked (w/high entropy)”:故意让生成更随机(高熵)。
- 结果:代码质量下降明显(PASS@1 变低),也没法检测。
2. 事后检测方法(生成时不修改代码,事后判断)
- 包括 LOGP (X)、LOGRANK、DETECTGPT 等。
- 优点:代码质量和 “无水印” 一样(因为生成时没动过)。
- 缺点:检测能力弱(AUROC 大多低于 0.8,TPR 也低),很难准确认出机器生成的代码。
3. 基于水印的方法(生成时嵌入水印,方便后续检测)
EXP-EDIT:嵌入水印但不影响代码生成的选择。
- 特点:代码质量接近无水印,但检测能力差(AUROC 低);如果强行提高检测能力(高熵设置),代码质量会暴跌。
WLLM(传统水印方法):
- 带
:为了提高检测能力,牺牲代码质量(比无水印下降约 10%),但检测效果仍一般。
- 带†:要求检测能力达标(AUROC≥0.9),但代码质量下降更多,且正确识别率(TPR)较低。
- 带
SWEET(本文方法):
- 带*:同样允许代码质量下降约 10%,但检测能力显著优于 WLLM(AUROC 达 0.943、0.873 等,TPR 更高)。
- 带†:在保证检测能力达标(AUROC≥0.9)的前提下,代码质量比 WLLM 更好,正确识别率也更高。
第一大列:HumanEval
包含经典的 Python 编程问题(如函数实现、算法题),侧重基础编程能力的测试。比如 “实现计算斐波那契数列的函数” 这类类问题。第二大列:MBPP
以 “自然语言描述 + 测试用例” 的形式呈现,更贴近实际开发中 “根据需求写代码” 的场景,问题更偏向实用功能(如 “写一个函数统计字符串中单词出现次数”)。第三大列:DS-1000
专注于数据科学领域的代码生成(如使用 NumPy、Pandas 处理数据),问题更专业,对领域知识要求更高(如 “用 Pandas 计算 DataFrame 中某列的均值”)。
结论
SWEET 在 “生成高质量代码” 和 “准确检测机器生成代码” 之间找到了更好的平衡 —— 要么在相同代码质量下检测更准,要么在相同检测能力下代码质量更高,明显优于其他方法
第五章 结果(Results)
5.1 主要结果(Main Results)
表 1 呈现了所有基准方法和我们方法的结果。在 WLLM 和 SWEET 中,根据水印强度的不同,检测能力和代码生成能力之间存在明显的权衡。因此,我们在为一个领域的分数设定最大值的同时,为其他领域的分数设定下限。具体而言,为了衡量 AUROC 分数,我们在无水印基础模型约 90% 的 pass@1 性能附近寻找最佳 AUROC 分数。另一方面,为了衡量 pass@1,我们从 AUROC 为 0.9 或更高的结果中进行选择。
检测性能:表 1 显示,总体而言,我们的 SWEET 方法在检测机器生成代码方面优于所有基准方法,代价是代码功能性下降 10%。在 MBPP 和 DS - 1000 数据集上,SWEET 分别实现了 0.873 和 0.815 的 AUROC,而所有基准方法的 AUROC 均未超过 0.8。在 HumanEval 上,SWEET 甚至实现了 0.943 的 AUROC,且代码功能性仅下降 2.4%。然而,当仅允许代码功能性下降约 10% 时,WLLM 的检测性能低于我们的方法。对于无失真水印方法,由于代码生成任务的熵较低,EXP - EDIT 在所有情况下都无法实现超过 0.6 的 AUROC 分数,即使是采用高熵设置的 EXP - EDIT,在检测性能方面也无法超越我们的方法。虽然所有事后检测基准方法都能保留代码功能性,因为它们不修改生成的代码,但它们的 AUROC 分数均未超过 0.6⁹。
代码质量保持(Code Quality Preservation)
在表 1 的最后两行中,尽管 WLLM 和 SWEET 都会不可避免地导致文本质量下降,但与 WLLM 相比,我们的 SWEET 方法在保持 AUROC>0.9 的高检测能力的同时,能更好地保留代码功能性。具体而言,WLLM 在 HumanEval 上的 pass@1 从 33.4 下降到 25.3,代码执行通过率损失了 24.3%。类似地,在 MBPP 和 DS - 1000 数据集上,性能分别下降了 36.0% 和 67.3%。另一方面,我们的方法在 HumanEval、MBPP 和 DS - 1000 上分别仅损失了 2.4%、12.2% 和 28.5%,这显著低于 WLLM 的损失比例。
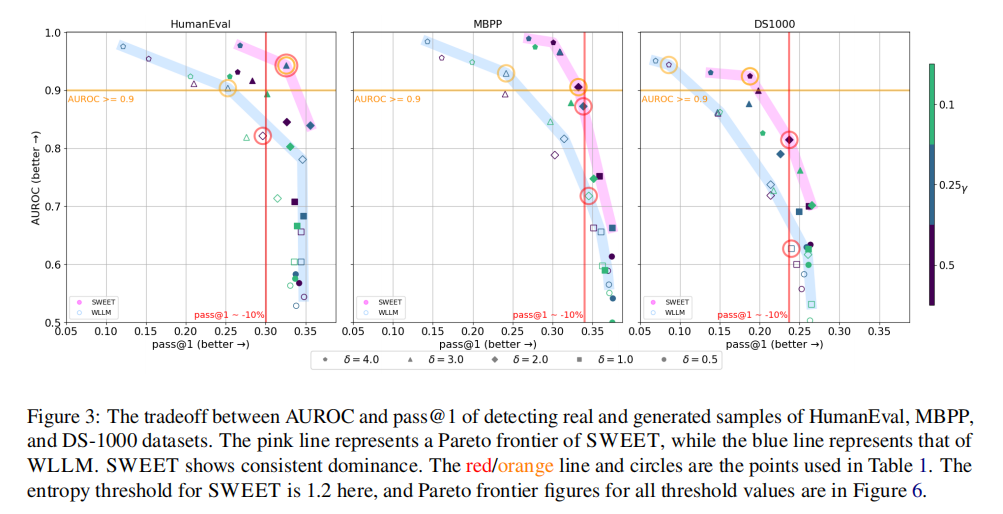
图3
(1)HumanEval 子图
- SWEET(粉色标记):在
AUROC ≥ 0.9时,pass@1仍保持较高水平;即使代码质量下降约 10%(红色竖线处),AUROC 也接近 1.0,检测能力极强。 - WLLM(浅蓝色标记):若要满足
AUROC ≥ 0.9,pass@1下降更明显;在代码质量下降 10% 时,AUROC 远低于 SWEET。
(2)MBPP 子图
- SWEET:在
AUROC ≥ 0.9时,pass@1优于 WLLM;代码质量下降 10% 时,AUROC 也高于 WLLM。 - WLLM:检测能力达标时,代码质量损失更大;同等代码质量损失下,检测能力更弱。
(3)DS1000 子图
- SWEET:整体在 “高 AUROC” 与 “高 pass@1” 的权衡中更占优,即使任务难度大(DS1000 是数据科学领域代码,更复杂),仍能在检测能力达标时,保留更好的代码质量。
- WLLM:检测能力和代码质量的权衡更 “失衡”,要么检测能力不足,要么代码质量下降过多。
C++/Java/ 类级代码生成
表 2 呈现了在其他编程语言(C++ 和 Java)以及另一种代码生成范围(即类级)上的结果。在比 WLLM 更好地保留代码功能性的同时,SWEET 展现出了最高的检测性能,不过在 Java 环境中是例外,此时 WLLM 的真阳性率(TPR)得分高于 SWEET。这些结果表明,我们方法的有效性并不局限于特定类型的编程语言或软件开发环境。有关结果的更多分析,请参考附录 E。
5.2 SWEET 与 WLLM 的帕累托前沿对比
在 SWEET 和 WLLM 的情况中,水印强度和范围会根据绿色列表标记的比例\(\gamma\)以及对数概率增加值\(\delta\)而变化。为了证明无论\(\gamma\)和\(\delta\)取值如何,SWEET 都始终优于基准方法 WLLM,我们在图 3 中绘制了以 pass@1 和 AUROC 为轴的帕累托前沿曲线。我们观察到,在所有三个任务中,SWEET 的帕累托前沿都领先于 WLLM 的。此外,正如图 6 所示,无论我们的方法为熵阈值选择什么值,在所有配置下 SWEET 都优于基准方法。这表明,在广泛的超参数设置范围内,我们的 SWEET 模型在检测能力和代码生成能力方面都能产生更优的结果。完整结果和不同设置请见附录 F。
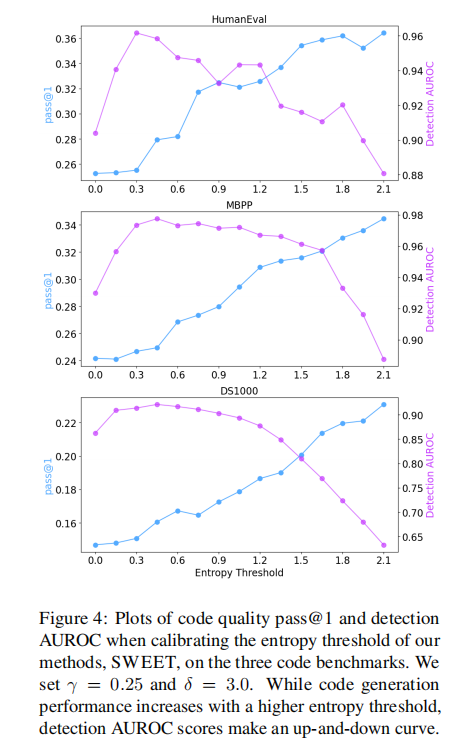
图4
图 4 展示了在三个代码基准测试(HumanEval、MBPP、DS1000)上,校准我们的方法 SWEET 的熵阈值时,代码质量指标 pass@1 和检测指标 AUROC 的变化情况。我们将设为 0.25,
设为 3.0。当熵阈值增大时,代码生成性能(pass@1)有所提升,而检测 AUROC 分数则呈现出上下波动的曲线。
从图中具体来看:
- HumanEval 子图:随着熵阈值从 0.0 增加到 2.1,pass@1(紫色线)整体呈上升趋势,而检测 AUROC(蓝色线)先上升后下降,呈现波动。
- MBPP 子图:pass@1(紫色线)随熵阈值增大而上升,检测 AUROC(蓝色线)同样有波动,先升后降再升。
- DS1000 子图:pass@1(紫色线)随着熵阈值增大而上升,检测 AUROC(蓝色线)则是先有小幅度波动后上升,但整体波动也较为明显。
这表明熵阈值的选择对 SWEET 的代码生成质量和检测能力有重要影响,且两者的变化趋势并非完全一致,存在一定的权衡与复杂的相互作用。
第六章 分析
6.1 熵阈值的影响(Impact of Entropy Thresholds)
图 4 展示了在我们的方法中校准熵阈值时,代码生成性能和检测能力是如何权衡的。WLLM 是不应用熵阈值的情况(即熵阈值 = 0)。随着熵阈值的增加,被水印标记的标记比例下降,因此代码生成性能会向无水印的基础模型收敛。这表明,在代码生成性能方面,我们的方法始终介于 WLLM 和无水印基础模型之间。另一方面,检测能力随着熵阈值的增加,会达到一个局部最大值,但最终会下降。虽然与 WLLM 相比,我们采用适度阈值的方法能有效限制生成红色列表标记,但如果阈值过高,以至于很少有标记被水印化,检测能力最终会下降。我们在附录 H 中进一步研究了如何有效地校准熵阈值。
6.2 无提示时的检测能力
由于检测阶段需要熵信息,因此在我们的方法中,对每个生成时间步t的熵值进行近似是至关重要的。在主要实验中,我们会在目标代码前添加生成阶段所使用的提示(例如图 2 中的问题),以此来重现相同的熵。然而,在现实世界中,我们几乎无法知晓为给定目标代码所使用的提示。因此,我们没有使用理想的提示,而是附加了一个通用的代码生成提示来近似熵信息。我们使用了以下五个通用提示,并对它们的z分数取平均值,用于检测过程。

图 8 展示了在 HumanEval 数据集上使用通用提示时检测能力的变化情况。使用通用提示的 SWEET 表现出比原始 SWEET 更低的 AUROC 值,这表明不准确的近似熵信息会损害检测能力。尽管如此,在检测能力方面,它仍然优于 WLLM 基准方法,在所有熵阈值取值下,其绘制的帕累托前沿都领先于 WLLM。
注记:
“帕累托前沿(Pareto Frontier)” 是一个源于帕累托最优的概念,用来描述 “多目标优化” 中,“无法在不牺牲一个目标的前提下改善另一个目标” 的最优解集合。
结合论文里 “代码生成质量(pass@1)” 和 “水印检测能力(AUROC)” 这两个目标,我们可以这样通俗理解:
1. 核心逻辑:两个目标的 “权衡”
论文里要同时优化 代码生成质量(越高越好,比如pass@1数值高,代表生成的代码更可能正确)和 水印检测能力(越高越好,比如AUROC数值高,代表越容易检测出 “代码是机器生成的”)。
但这两个目标往往是互斥的:
- 若想 “检测能力强”,可能需要在生成代码时嵌入更多水印,这会影响代码的自然性,导致 “代码质量下降”;
- 若想 “代码质量高”,又可能因为嵌入水印少,导致 “检测能力变弱”。
2. 帕累托前沿的作用:找 “最优权衡点”
帕累托前沿就是 “所有无法再同时优化两个目标” 的点的集合。比如在图中,前沿上的每个点都满足:
- “如果想让检测能力更好,代码质量一定会下降”;
- “如果想让代码质量更好,检测能力一定会下降”。
前沿左边 / 下边的点,属于 “可以被前沿上的点支配” 的 “非最优解”(比如检测能力和代码质量都不如前沿上的点);前沿上的点才是 “在当前条件下,两个目标的最优权衡”。
3. 论文里的具体意义
论文说 “SWEET 的帕累托前沿领先于 WLLM”,意思是:
在 “代码生成质量” 和 “检测能力” 的权衡中,SWEET 能做到 “相同代码质量下,检测能力更强”;或者相同检测能力下,代码质量更高”,所以它的 “最优权衡边界” 比 WLLM 更 “靠前 / 靠上”,整体性能更优。
简单总结:帕累托前沿是 “多目标优化中,最优权衡方案的集合”,论文用它来证明 SWEET 在 “代码质量” 和 “检测能力” 的平衡上,比其他方法更优秀~
6.3 替代模型的使用
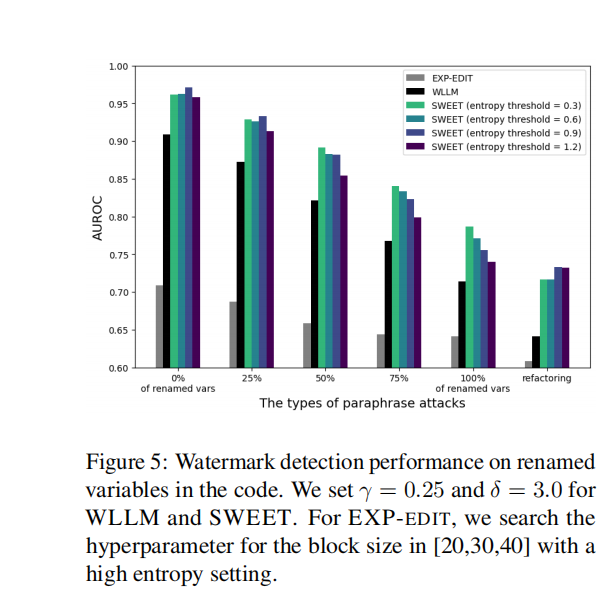
图 5 展示了在代码中变量重命名情况下的水印检测性能。对于 WLLM 和 SWEET,我们将设为 0.25,
设为 3.0。对于 EXP - EDIT,我们在高熵设置下,在 [20,30,40] 范围内搜索块大小的超参数。从图中可以看到,不同的改写攻击类型(变量重命名比例为 0%、25%、50%、75%、100% 以及代码重构)下,不同方法(EXP - EDIT、WLLM、不同熵阈值的 SWEET)的 AUROC(检测性能指标)存在差异。整体而言,SWEET 在不同熵阈值下,相比 EXP - EDIT 和 WLLM,在多数改写攻击类型下都展现出更优的检测性能,不过随着变量重命名比例增加或进行代码重构,各方法的检测性能均有不同程度的下降。
在检测文本中的水印时,使用更小的语言模型(LM)作为替代模型可能在计算上更高效且更具成本效益(Wang 等人,2023)。我们研究了在检测阶段使用这种替代模型的影响。具体而言,我们使用原始模型(LLaMA2 - 13B)生成带水印的代码,并使用更小的模型(LLaMA2 - 7B)检测水印。
在图 10 的结果中,检测性能的下降并不显著,而且我们使用替代模型的方法仍然超过了基准方法。这种性能的保持可能是因为 LLaMA2 7B 和 13B 是在相同的训练语料库上训练的(Touvron 等人,2023)。有关计算成本的进一步分析可在附录 I 中找到。
6.4 对改写攻击的鲁棒性
即便文本带有水印,恶意用户仍可能尝试通过改写来移除文本中的水印(Krishna 等人,2023;Sadasivan 等人,2023)。对代码文本进行改写比处理普通文本更具限制性,因为必须避免引发任何代码故障。我们通过采用两种类型的攻击 —— 更改变量名和使用商业代码重构服务,来评估水印方法针对改写的鲁棒性 ¹⁰。具体而言,对于每种水印方法,我们从 MBPP 任务中选取 273 个源代码,这三种方法都能成功生成这些代码且无语法错误。在代码重命名攻击中,我们选择带水印代码中的变量,并用长度在 2 到 5 个字符之间的随机生成字符串对其进行重命名。我们使用五个随机种子进行重命名。
图 5 展示了对改写后代码的检测性能结果。当改写程度增加时,所有水印方法的 AUROC 分数都有所下降,而我们的方法仍然表现出比基准方法更好的性能。然而,我们的方法也显示出,当所有变量都被重命名时,AUROC 分数下降到约 0.8。我们发现这是因为变量名在代码文本中占高熵标记的很大比例(详情见附录 J)。
第七章 结论
我们明确并强调了代码大语言模型(Code LLM)水印的需求,且首次对其进行了形式化定义。尽管大语言模型的编码能力发展迅速,但鼓励代码生成模型安全使用的必要措施尚未落实。我们的实验表明,现有水印和检测技术在代码生成场景下无法正常运作。这种失效存在两种模式:一是代码未妥善嵌入水印(因此无法被检测到);二是带水印的代码无法正常执行(质量下降)。另一方面,我们提出的方法 SWEET,通过引入选择性熵阈值(过滤与执行质量最不相关的标记),在一定程度上改善了这两种失效模式。在代码生成任务中,我们的方法优于包括事后检测方法在内的基准方法,同时实现的质量下降更少。更全面的分析表明,我们的方法在现实场景中仍然表现良好,特别是在没有提示、使用更小的替代模型或遭受改写攻击的情况下。
7.1局限性
我们指出了本研究的局限性,并提出了减轻这些局限性的方法。首先,该领域当前存在以下两个共性问题。(1)对抗改写攻击的鲁棒性:由于用户可根据自身特定需求调整大语言模型(LLM)的代码,因此对抗改写攻击的鲁棒性至关重要。我们在第 6.4 节中探讨了这一问题,并将进一步增强鲁棒性的工作留待未来开展。(2)水印伪造的可能性:攻击者可能会窥探出水印规则,而暴力机制中的次运行会使攻击成为可能。为应对这种攻击,可应用增强水印模型安全性的技术,例如像 WLLM 论文中提到的那样,根据之前的
个标记划分绿色 / 红色列表,或者应用如 SelfHash(Kirchenbauer 等人,2023b)之类的方法。
对于我们的研究,还存在以下两个额外问题。(1)熵阈值校准:我们证明了在广泛的熵阈值范围内,我们的方法优于基准方法(见第 6.1 节),并研究了如何校准熵阈值(见附录 H)。然而,要获得最佳性能,我们仍需要对熵阈值进行调整,这会带来计算成本。(2)检测时对源大语言模型的依赖:SWEET 在白盒设置下工作。尽管已经表明,即使使用更小的替代大语言模型,仍能在一定程度上保持检测性能(见第 6.3 节),但这对于一些想要应用我们研究成果的用户来说,可能是一种计算负担。
7.2伦理声明
尽管水印方法旨在通过检测机器生成的文本来应对大语言模型(LLMs)所有潜在的滥用情况,但它们同时也可能带来新的风险。例如,如果特定大语言模型的水印机制被泄露给公众,知晓该机制的恶意用户可能会滥用水印,去创建嵌入了该模型水印的不道德文本。为了防止此类情况发生,我们建议所有用户务必谨慎行事,避免暴露详细的机制,比如我们方法中用于划分绿色和红色列表的哈希函数的密钥值。
文献来源:Who Wrote this Code? Watermarking for Code Generation