目录
1.8.3select * from performance_schema.replication_group_members;参数说明
2.2.8输入如下命令检测各节点间ssh互信通信配置是否ok
2.4.5在master节点关闭mysql服务模拟主节点数据崩溃
1.MySQL高可用之组复制(MGR)
1.1什么是MGR?
- MGR是MySQL 5.7.17版本诞生的,是MySQL自带的一个插件,可以灵活部署。
- 保证数据一致性又可以自动切换,具备故障检测功能、支持多节点写入。
- 集群是多个MySQL Server节点共同组成的分布式集群,每个Server都有完整的副本,它是基于ROW格式的二进制日志文件和GTID特性。(推荐使用GTID复制)
1.2MGR数据一致性
- 我们将多个节点共同组成一个复制组,在执行读写(RW)事务的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对只读(RO)事务则不需要经过组内同意,直接提交即可 。也就是说在进行写事务的时候,必须要经过组内Node节点同意数量需要大于(N/2+1),这样才能进行写事务。对于只读事务不需要经过组内同意,直接提交即可。
1.3MGR故障切换
- 组内节点通过 “心跳机制(默认每 5 秒发送一次)” 监控彼此状态,若某节点心跳超时(默认 10 秒),则标记为 “疑似故障”,若 “疑似故障节点” 被 “多数节点” 确认故障,集群会自动将其剔除;若故障节点是 “主节点”(单主模式),则剩余节点通过 “选举算法”(优先选 “最新数据节点”“高权重节点”)选出新主,整个过程无需第三方工具。
1.4MGR 优点
- 强一致性:基于原生复制及paxos协议的组复制技术,并以插件的方式提供,提供一致数据安全保证。
- 高容错性:只要不是大多数节点坏掉就可以继续工作,有自动检测机制,当不同节点产生资源争用冲突时,不会出现错误,按照先到者优先原则进行处理,并且内置了自动化脑裂防护机制。
- 高扩展性:节点的新增和移除都是自动的,新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致,如果某节点被移除了,其他节点自动更新组信息,自动维护新的组信息。
- 高灵活性:有单主模式和多主模式。单主模式下,会自动选主,所有更新操作都在主上进行;多主模式下,所有server都可以同时处理更新操作。工作中优先使用单主模式!
1.5MGR 缺点
- 仅支持InnoDB表,并且每张表一定要有一个主键,用于做write set的冲突检测。
- 必须打开GTID特性,二进制日志格式必须设置为ROW,用于选主与write set;主从状态信息存于表中(–master-info-repository=TABLE 、–relay-log-inforepository=TABLE),–log-slave-updates打开。
- MGR不支持大事务,事务大小最好不超过143MB,当事务过大,无法在5秒的时间内通过网络在组成员之间复制消息,则可能会怀疑成员失败了,然后将其驱逐出局。
- 目前一个MGR集群最多支持9个节点。
- 不支持外键于save point特性,无法做全局间的约束检测与部分事务回滚。
- 二进制日志不支持Binlog Event Checksum。
- 注意:MGR没有vip漂移,需要借助keepalived工具进行ip的漂移。
1.6单主组复制

单写模式 group 内只有一台节点可写可读,其他节点只可以读。当主服务器失败时,会自动选择新的主服务器(数据最完整,权重最高的节点)。
1.7多主组复制
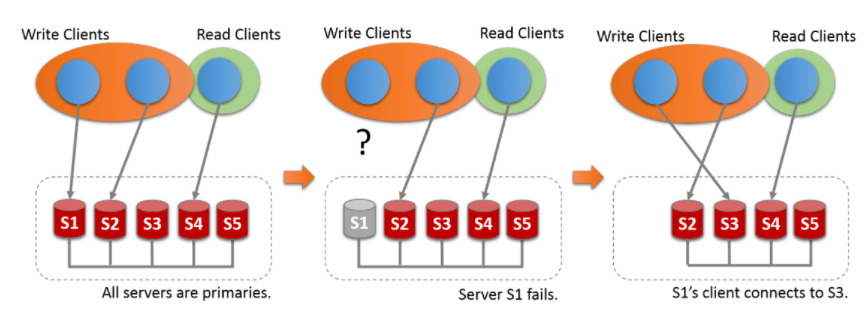
组内的所有机器都是 primary 节点,同时可以进行读写操作,并且数据是最终一致的,某节点故障后,其他节点仍可正常处理写请求,无需选举新主。
1.8配置单主组复制
1.8.1环境说明
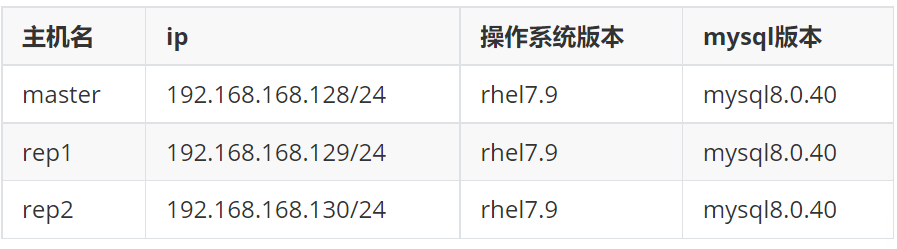
1.8.2master的配置
#1)修改配置文件
[root@master ~]# vim /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
log_timestamps=SYSTEM #设置日志时间和本地时间保持一致
server_id=133
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY" #组复制,数据必须存储在 InnoDB 事务存储引擎中
gtid_mode=ON #组复制要开启gtid
enforce_gtid_consistency=ON
log_bin=binlog #默认开启二进制日志
log_slave_updates=ON #默认开启级联
binlog_format=ROW #默认开启二进制日志格式必须设置为ROW
transaction_write_set_extraction=XXHASH64 #默认开启,组复制使用此信息在所有组成员上进行冲突检测
plugin_load_add='group_replication.so' #将组复制插件添加到服务器启动时加载的插件列表中
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" #告诉插件它正在加入或创建的组名为“aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa”
group_replication_start_on_boot=off #插件在服务器启动时不自动启动操作,使用手动启动插件
group_replication_local_address= "192.168.168.128:33061" #与其它主机通信时使用的网络地址和端口
group_replication_group_seeds= "192.168.168.128:33061,192.168.168.129:33061,192.168.168.130:33061" #设置组成员的主机名和端口
group_replication_bootstrap_group=off #指示插件是否启动该组,在首次引导组时在一个服务器上启用
group_replication_ip_whitelist="192.168.168.0/24,127.0.0.1/8" #仅允许白名单内的 IP 加入复制组
group_replication_recovery_use_ssl=on #caching_sha2_password插件要求安全传输密码,开启主从之间的连接使用SSL/TLS [root@master ~]# /etc/init.d/mysqld restart
#2)在主的数据库中使用sql语句添加复制账号并授予权限,从上面也需要设置一样的账号
#关闭二进制日志,注意从库上同步二进制日志是靠pos的点进行同步,GTID是靠事务id号进行同步
SET SQL_LOG_BIN=0;
CREATE USER rp@'%' IDENTIFIED BY '123';
GRANT REPLICATION SLAVE ON *.* TO rp@'%';#复制权限
GRANT CONNECTION_ADMIN ON *.* TO rp@'%';#连接管理权限
GRANT BACKUP_ADMIN ON *.* TO rp@'%';#备份管理权限
GRANT GROUP_REPLICATION_STREAM ON *.* TO rp@'%'; #组复制流权限
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
CHANGE REPLICATION SOURCE TO SOURCE_USER='rp', SOURCE_PASSWORD='123' FOR CHANNEL 'group_replication_recovery';
#注意:如果需要重置则使用命令reset master;
#3)查看是否有group_replication插件
mysql> show plugins;
|group_replication | ACTIVE | GROUP REPLICATION | group_replication.so | GPL |
#4)启动MGR集群
#使用当前服务器作为引导服务器启动一个新的群组复制过程或者恢复一个已经存在的群组
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION USER='rp',PASSWORD='123';
SET GLOBAL group_replication_bootstrap_group=OFF;
#在主上查看组信息
mysql> SELECT * FROM performance_schema.replication_group_members;1.8.3select * from performance_schema.replication_group_members;参数说明
CHANNEL_NAME:通道名称。组复制插件创建两个复制通道:
group_replication_recovery:用于与分布式恢复阶段相关的复制更改。 group_replication_applier:用于来自组传入的更改,是应用直接来自组的事务的通道。
MEMBER_ID:组成员实例的server_uuid。
MEMBER_HOST:组成员主机名。如果配置了report_host参数,这里显示IP地址。 MEMBER_ROLE:成员角色,主为PRIMARY,从为SECONDARY。
MEMBER_VERSION:成员数据库实例版本。
MEMBER_STATE:成员状态,取值和含义如下所示:
ONLINE 表示该成员可正常提供服务
RECOVERING 表示当前成员正在从其它节点恢复数据
OFFLINE 表示组复制插件已经加载,但是该成员不属于任何一个复制组
ERROR 表示成员在recovery阶段出现错误或者从其它节点同步状态中出现错误
UNREACHABLE 成员处于不可达状态,无法与之进行网络通讯
1.8.4从上配置
#1)在从上写配置文件
[root@rep1 ~]# vim /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
log_timestamps=SYSTEM
server_id=129
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
gtid_mode=ON
enforce_gtid_consistency=ON
plugin_load_add='group_replication.so'
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address="192.168.168.129:33061"
group_replication_group_seeds="192.168.168.133:33061,192.168.168.129:33061,192.168.168.130:33061"
group_replication_ip_whitelist="192.168.168.0/24,127.0.0.1/8"
group_replication_bootstrap_group=off
group_replication_recovery_use_ssl=on
[root@rep1 ~]# /etc/init.d/mysqld restart
[root@rep2 ~]# vim /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
log_timestamps=SYSTEM
server_id=130
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
gtid_mode=ON
enforce_gtid_consistency=ON
plugin_load_add='group_replication.so'
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address="192.168.168.130:33061"
group_replication_group_seeds="192.168.168.133:33061,192.168.168.129:33061,192.168.168.130:33061"
group_replication_ip_whitelist="192.168.168.0/24,127.0.0.1/8"
group_replication_bootstrap_group=off
group_replication_recovery_use_ssl=on
#2)在所有从的数据库中使用sql语句添加复制账号并授予权限,从上面也需要设置一样的账号
SET SQL_LOG_BIN=0;
CREATE USER rp@'%' IDENTIFIED BY '123';
GRANT REPLICATION SLAVE ON *.* TO rp@'%';
GRANT CONNECTION_ADMIN ON *.* TO rp@'%';
GRANT BACKUP_ADMIN ON *.* TO rp@'%';
GRANT GROUP_REPLICATION_STREAM ON *.* TO rp@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
CHANGE REPLICATION SOURCE TO SOURCE_USER='rp', SOURCE_PASSWORD='123' FOR CHANNEL 'group_replication_recovery';
#3)开启组复制
mysql> START GROUP_REPLICATION USER='rp', PASSWORD='123';
#查看组信息
mysql> SELECT * FROM performance_schema.replication_group_members;1.8.5结果验证
#在主库节点数据库上执行
mysql> create database test;
mysql> use test
#必须设置主键,不然无法插入数据
mysql> create table t1(id int primary key,name char(30));
mysql> insert into t1 values (1,'xiaoming');
#在三个节点均可以查看到新增信息
mysql> select * from test.t1;
+----+----------+
| id | name |
+----+----------+
| 1 | xiaoming |
+----+----------+
1 row in set (0.00 sec)
#在从节点测试写入,验证不支持写入操作
mysql> insert into test.t1 values (2,'xiaohong');
ERROR 1290 (HY000): The MySQL server is running with the --super-read-only option so it cannot execute this statement
#测试主节点宕机
mysql> stop GROUP_REPLICATION;
#从库节点查看,发现仅剩2个节点,并且自动选举出主节点
mysql> SELECT * FROM performance_schema.replication_group_members;
#在重新选举出来的rep1上测试插入数据
mysql> insert into test.t1 values (3,'xiaohei');
mysql> select * from test.t1;
+----+----------+
| id | name |
+----+----------+
| 1 | xiaoming |
| 3 | xiaohei |
+----+----------+
2 rows in set (0.00 sec)
#重新启动前面的master主节点,可以看到master已经作为从节点加入到群组中
mysql> START GROUP_REPLICATION;
Query OK, 0 rows affected, 1 warning (10.73 sec)
mysql> SELECT * FROM performance_schema.replication_group_members;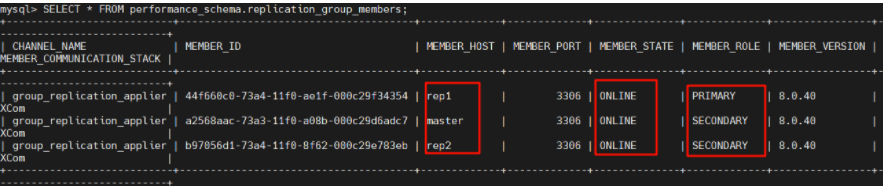
1.9多主组复制
#修改所有的my.cnf的配置文件,添加如下内容
#关闭单master模式
loose-group_replication_single_primary_mode=off
#多主一致性检查
loose-group_replication_enforce_update_everywhere_checks=ON
[root@master mysql]# /etc/init.d/mysqld restart
#在其中一台主机里面执行以下mysql命令
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
#在另外两台主机里面执行以下mysql命令,开启组复制
mysql> START GROUP_REPLICATION;
mysql> SELECT * FROM performance_schema.replication_group_members;
#在三个主机上面分别执行以下三条命令测试是否都可以执行写入操作
mysql> insert test.t1 values (4,'xiaolan');
mysql> insert test.t1 values ('5','xiaozi');
mysql> insert test.t1 values (6,'xiaohei');
mysql> select * from test.t1;
+----+----------+
| id | name |
+----+----------+
| 1 | xiaoming |
| 3 | xiaohei |
| 4 | xiaolan |
| 5 | xiaozi |
| 6 | xiaohei |
+----+----------+
2.MHA高可用架构
2.1MHA工作原理
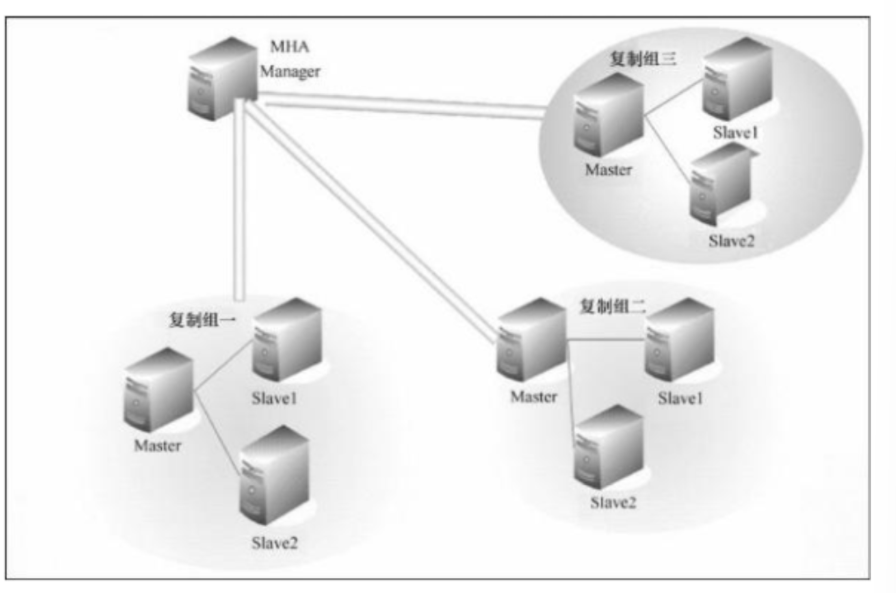
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群必须最少有3台数据库服务器,一主二从,即一台充当Master,一台充当备用Master,一台充当从库。
MHA Node 运行在每台 MySQL 服务器上。
MHAManager 会定时探测集群中的master 节点。
当master 出现故障时,它可以自动将最新数据的slave 提升为新的master
然后将所有其他的slave 重新指向新的master,VIP自动漂移到新的master。
整个故障转移过程对应用程序完全透明。
2.2配置MHA
2.2.1环境说明
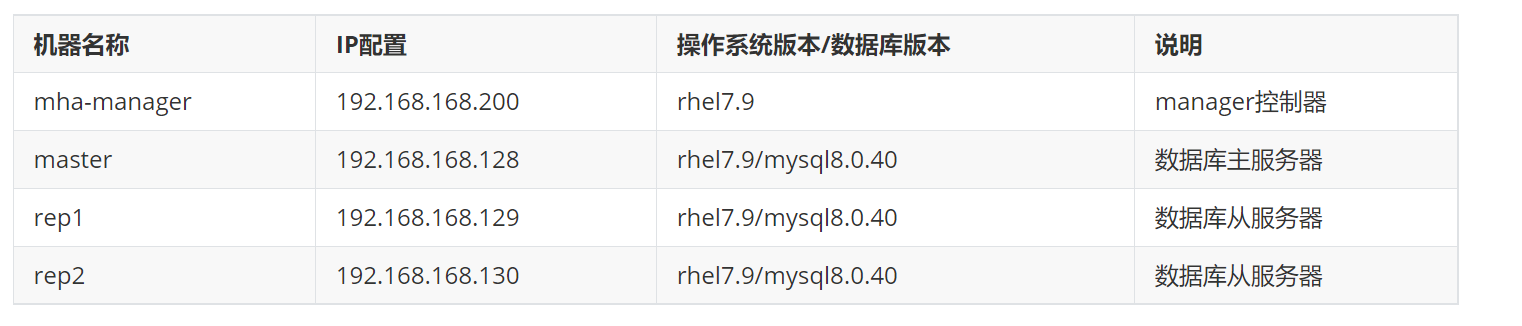
2.2.2初始化主节点master的配置
[root@master mysql]# cat /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
server_id=128 #集群中的各节点的id必须唯一
gtid-mode=on #启用gtid类型
enforce-gtid-consistency=true #启用GTID强一致性检查,防止GTID不兼容的语句导致复制失败
log-bin=binlog #开启二进制日志
relay-log=relay-log #开启中继日志
relay_log_purge=0 #是否自动清空不再需要的中继日志
log-slave-updates=true #slave更新的信息是否记入二进制日志中
[root@master mysql] /etc/init.d/mysqld start2.2.3初始化slave1和slave2节点
[root@rep1 mysql]# cat /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
server_id=129
gtid-mode=on
enforce-gtid-consistency=true
log-bin=binlog
relay-log=relay-log
relay_log_purge=0
log-slave-updates=true
[root@rep1 mysql]# /etc/init.d/mysqld start
[root@slave2 ~]# cat /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
server_id=130
gtid-mode=on
enforce-gtid-consistency=true
log-bin=mysql-bin
relay-log=relay-log
relay_log_purge=0
log-slave-updates=true
[root@rep2 mysql] /etc/init.d/mysqld start2.2.4配置一主多从复制架构
###master节点上,mha只支持mysql_native_password密码认证插件
mysql> create user 'rep'@'%' identified WITH mysql_native_password by '123';
mysql> grant replication slave on *.* to 'rep'@'%';
###slave1和slave2节点上
mysql> CHANGE REPLICATION SOURCE TO
SOURCE_HOST='192.168.168.128',
SOURCE_USER='rep',
SOURCE_PASSWORD='123',
master_auto_position=1,
SOURCE_SSL=1;
mysql> start replica;
mysql> show replica status \G
Replica_IO_Running: Yes
Replica_SQL_Running: Yes2.2.5配置MHA
#mha-manager上安装软件包
[root@mha-manager ~] wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
[root@manager ~] wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#所有主机上配置自解析域名
[root@mha-manager MHA-7] cat /etc/hosts
192.168.168.128 master
192.168.168.129 rep1
192.168.168.130 rep2
192.168.168.200 mha-manager
##其他三个mysql服务器上安装mha4mysql-node即可,复制mha4mysql-node到所有数据库服务器
[root@mha-manager MHA-7] for i in {master,rep1,rep2};do scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@$i:/root;done
#所有数据库上安装mha4mysql-node
[root@master ~] yum localinstall mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#设置可以远程访问mysql的用户,并设置管理员权限。
#只需要在master上运行即可
#此用户只能mha-manager(将%改为此ip)
create user 'mhaadm'@'%' identified WITH mysql_native_password by '123';
grant all on *.* to 'mhaadm'@'%';2.2.6配置各节点之间的免密登录
MHA集群中的各节点彼此之间均需要基于ssh互信通信,以实现远程控制及数据管理功能。

authorized_keys文件相当于 "信任列表",包含所有可免密登录当前节点的公钥。- 整个流程通过 "集中收集 - 统一分发" 的方式,确保所有节点的信任列表完全一致。
- 最终实现:任意节点可以无密码登录到其他节点(包括自身)。
#所有节点生成公私钥
ssh-keygen -f /root/.ssh/id_rsa -P '' -q
#将所有节点的公钥上传至manager节点,最后将manager节点的authorized_keys分发到其他节点
[root@master ~] ssh-copy-id root@mha-manager
[root@rep1 ~] ssh-copy-id root@mha-manager
[root@rep2 ~] ssh-copy-id root@mha-manager
[root@mha-manager ~] ssh-copy-id root@mha-manager
[root@mha-manager ~] for i in {master,rep1,rep2};do scp /root/.ssh/authorized_keys root@$i:/root/.ssh;done
#验证
[root@mha-manager ~] for i in {master,rep1,rep2};do ssh $i hostname ;done
master
rep1
rep22.2.7manager配置文件
Manager 节点需要为每个监控的 master/slave 集群提供一个专用的配置文件,而所有的master/slave 集群也可共享全局配置。全局配置文件默认为 /etc/masterha_default.cnf ,其为可选配置。如果仅监控一组 master/slave 集群,也可直接通过 application 的配置来提供各服务器的默认配置信息。而每个 application 的配置文件路径为自定义。也就是说管多个数据库集群(master/slave 组)时,全局配置放通用规则,每个集群再用单独配置写自己的细节。只管一个集群(master/slave 组)时,直接写一个单独配置文件就行,不用搞全局的。
#在manager上创建配置文件目录
[root@mha-manager ~] mkdir -p /etc/mha /var/log/mha/app1
[root@mha-manager ~] vim /etc/mha/app1.cnf
[server default] #适用于server1,2,3个server的配置
user=mhaadm #mha管理用户
password=123 #mha管理用户密码
manager_workdir=/var/log/mha/app1 #mha的工作路径
manager_log=/var/log/mha/app1/manager.log #mha的日志文件
ssh_user=root #基于ssh的秘钥认证
repl_user=rep #主从复制的账号
repl_password=123
ping_interval=1 #ping间隔时长
[server1] #mysql主机信息
hostname=192.168.168.128
ssh_port=22
candidate_master=1 #设置该主机将来可能成为master候选节点
[server2]
hostname=192.168.168.129
ssh_port=22
candidate_master=1
[server3]
hostname=192.168.168.130
ssh_port=22
no_master=12.2.8输入如下命令检测各节点间ssh互信通信配置是否ok
[root@mha-manager ~] masterha_check_ssh --conf=/etc/mha/app1.cnf2.2.9检查mysql复制集群的连接配置参数是否ok
[root@mha-manager ~] masterha_check_repl --conf=/etc/mha/app1.cnf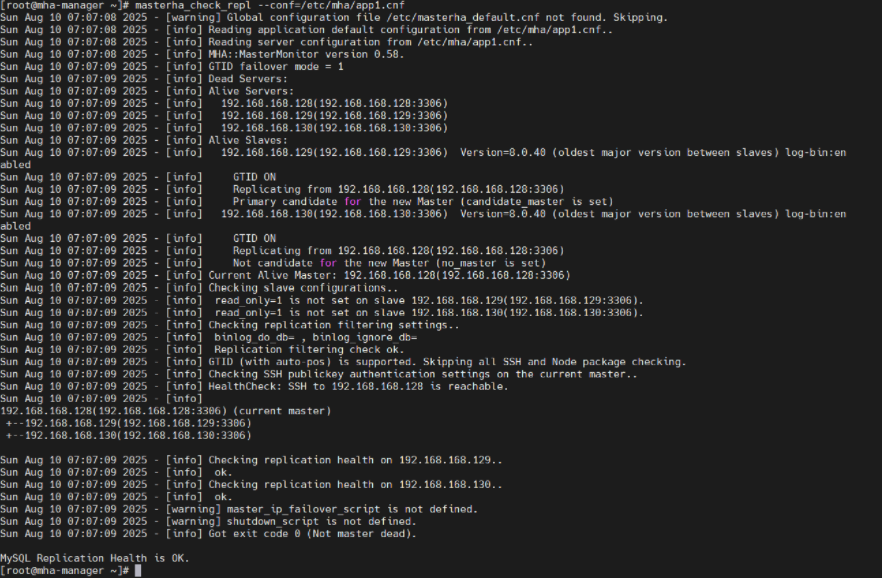
2.3.故障切换(手动)
#模拟master故障
[root@master mysql] /etc/init.d/mysqld stop
#在mha-manager中做故障切换
[root@mha-manager ~] masterha_master_switch --master_state=dead --conf=/etc/mha/app1.cnf --dead_master_host=192.168.168.128 --dead_master_port=3306 --new_master_host=192.168.168.129 --new_master_port=3306 --ignore_last_failover
....省略部分输出....
Master failover to 192.168.168.129(192.168.168.129:3306) completed successfully.
#--ignore_last_failover 表示忽略在/var/log/mha/app1/目录中在切换过程中生成的锁文件
恢复故障mysql节点
[root@master mysql]# /etc/init.d/mysqld start
#将该主机重新加入集群中
mysql> CHANGE REPLICATION SOURCE TO
SOURCE_HOST='192.168.168.129',
SOURCE_USER='rep',
SOURCE_PASSWORD='123',
master_auto_position=1,
SOURCE_SSL=1;
Query OK, 0 rows affected, 3 warnings (0.00 sec)
mysql> start replica;
Query OK, 0 rows affected (0.01 sec)
mysql> show replica status\G
*************************** 1. row ***************************
Replica_IO_State: Waiting for source to send event
Source_Host: 192.168.168.129
Source_User: rep
Source_Port: 3306
Connect_Retry: 60
Source_Log_File: binlog.000003
Read_Source_Log_Pos: 1249
Relay_Log_File: relay-log.000003
Relay_Log_Pos: 451
Relay_Source_Log_File: binlog.000003
Replica_IO_Running: Yes
Replica_SQL_Running: Yes2.4.故障切换(自动)
#删除锁文件,如果不删除的话mha无法故障转移成功
[root@mha-manager ~] rm -rf /var/log/mha/app1/app1.failover.complete
#启动mha。可以使用--ignore_last_failover选项选择忽略锁文件
[root@mha-manager ~] masterha_manager --conf=/etc/mha/app1.cnf
#查看mha的状态,注意不要关闭
[root@mha-manager ~] masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:2510) is running(0:PING_OK), master:192.168.168.129
#模拟主mysql宕机
[root@rep1 ~] /etc/init.d/mysqld stop
#注意:故障转移完成后,mha-manager将会自动停止运行
#查看转移日志
[root@mha-manager ~] cat /var/log/mha/app1/manager.log
----- Failover Report -----
app1: MySQL Master failover 192.168.168.129(192.168.168.129:3306) to 192.168.168.128(192.168.168.128:3306) succeeded
Master 192.168.168.129(192.168.168.129:3306) is down!
Check MHA Manager logs at mha-manager:/var/log/mha/app1/manager.log for details.
Started automated(non-interactive) failover.
Selected 192.168.168.128(192.168.168.128:3306) as a new master.
192.168.168.128(192.168.168.128:3306): OK: Applying all logs succeeded.
192.168.168.130(192.168.168.130:3306): OK: Slave started, replicating from 192.168.168.128(192.168.168.128:3306)
192.168.168.128(192.168.168.128:3306): Resetting slave info succeeded.
Master failover to 192.168.168.128(192.168.168.128:3306) completed successfully.
#在从192.168.168.130上查看当前的主是谁,已经成功切换到192.168.168.128
mysql> show replica status \G
*************************** 1. row ***************************
Replica_IO_State: Waiting for source to send event
Source_Host: 192.168.168.128
Source_User: rep
Source_Port: 3306
Connect_Retry: 60
Source_Log_File: binlog.000004
Read_Source_Log_Pos: 523
Relay_Log_File: relay-log.000002
Relay_Log_Pos: 411
Relay_Source_Log_File: binlog.000004
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
#删除锁文件
[root@mha-manager ~] rm -rf /var/log/mha/app1/app1.failover.complete
#恢复故障的从
[root@rep1 ~] /etc/init.d/mysqld start
mysql> CHANGE REPLICATION SOURCE TO
SOURCE_HOST='192.168.168.128',
SOURCE_USER='rep',
SOURCE_PASSWORD='123',
master_auto_position=1,
SOURCE_SSL=1;
mysql> start replica;2.4配置VIP
vip配置可以采用两种方式,一种通过keepalived的方式管理虚拟ip的浮动;另外一种通过脚本方式启动虚拟ip的方式 (即不需要keepalived或者heartbeat类似的软件)。为了防止脑裂发生,推荐生产环境采用脚本的方式来管理虚拟ip,而不是使用keepalived来完成。
2.4.1写脚本
[root@mha-manager ~] vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#注意此处配置的ip地址和网卡名称
my $vip = '192.168.168.88/24';
my $ssh_start_vip = "/sbin/ip a add $vip dev ens32";
my $ssh_stop_vip = "/sbin/ip a del $vip dev ens32";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host
\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
[root@mha-manager ~] chmod +x /usr/local/bin/master_ip_failover2.4.2更改manager配置文件
[root@mha-manager ~] vim /etc/mha/app1.cnf
[server default]
#添加如下信息
master_ip_failover_script=/usr/local/bin/master_ip_failover2.4.3在主库上手动配置第一次的VIP地址
[root@master mysql] ip a a 192.168.168.88/24 dev ens32
[root@master mysql] ip a show ens32
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:d6:ad:c7 brd ff:ff:ff:ff:ff:ff
inet 192.168.168.128/24 brd 192.168.168.255 scope global noprefixroute ens32
valid_lft forever preferred_lft forever
inet 192.168.168.88/24 scope global secondary ens322.4.4在mha-manager上启动MHA
[root@mha-manager ~] masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover2.4.5在master节点关闭mysql服务模拟主节点数据崩溃
[root@master mysql] /etc/init.d/mysqld stop
2.4.6在rep1上查看VIP
[root@rep1 ~] ip a show ens32
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:f3:43:54 brd ff:ff:ff:ff:ff:ff
inet 192.168.168.129/24 brd 192.168.168.255 scope global noprefixroute ens32
valid_lft forever preferred_lft forever
inet 192.168.168.88/24 scope global secondary ens32
valid_lft forever preferred_lft forever
inet6 fe80::104a:bcda:d57c:4ec5/64 scope link tentative noprefixroute dadfailed