前言:为何选择 Redis 与 C++?
在当今这个数据驱动的时代,高性能的数据存储与访问是构建现代化应用的基石。Redis,作为一个开源的、基于内存的键值对存储数据库,以其无与伦比的读写速度、丰富的数据结构、以及灵活的应用场景(缓存、消息队列、会话存储、排行榜等),成为了后端开发者的瑞士军刀。
与此同时,C++ 作为一门追求极致性能的编程语言,长期以来在游戏开发、金融交易、高性能计算等领域占据着主导地位。当 C++ 的高性能与 Redis 的高速度相结合时,我们便能够构建出响应迅捷、吞吐量巨大的应用程序。
然而,要将二者优雅地结合起来,我们需要一个强大的“桥梁”——Redis 客户端库。redis-plus-plus 就是这样一个专为现代 C++ (C++11 及以上) 设计的优秀库。它不仅封装了 Redis 的原生协议,提供了类型安全、易于使用的 API,还巧妙地利用了 C++ 的新特性(如 std::optional、std::chrono 等),使得与 Redis 的交互变得既安全又直观。
第一章:基础中的基石 —— GET 与 SET 命令
在 Redis 的世界里,最基本、最核心的操作莫过于设置(SET)一个键值对和获取(GET)一个键的值。这构成了所有复杂操作的基础。
1.1 SET 与 GET 的基本用法
SET 命令用于将一个字符串值(value)关联到一个键(key)上。如果这个键已经存在,SET 会覆盖掉旧的值。GET 命令则用于获取指定键所关联的字符串值。
让我们通过一个 C++ 单元测试函数来直观地感受一下:

#include <iostream>
#include <vector>
#include <string>
#include <unordered_map>
#include <sw/redis++/redis++.h>
// 为了方便打印容器内容,我们先定义一个辅助函数
template<typename T>
void PrintContainer(const T& container) {
for (const auto& item : container) {
std::cout << item << " ";
}
std::cout << std::endl;
}
void test1(sw::redis::Redis& redis) {
std::cout << "--- Testing GET and SET ---" << std::endl;
// 清空当前数据库,避免之前残留的数据干扰测试
redis.flushall();
std::cout << "Database flushed." << std::endl;
// 使用 set 设置三个键值对
redis.set("key1", "111");
redis.set("key2", "222");
redis.set("key3", "333");
std::cout << "Set 'key1', 'key2', 'key3'." << std::endl;
// 使用 get 获取 key 对应的 value
auto value1 = redis.get("key1");
std::cout << "Value of key1: " << value1.value() << std::endl;
auto value2 = redis.get("key2");
std::cout << "Value of key2: " << value2.value() << std::endl;
auto value3 = redis.get("key3");
std::cout << "Value of key3: " << value3.value() << std::endl;
// 尝试获取一个不存在的 key
auto value4 = redis.get("key4");
std::cout << "Attempting to get non-existent 'key4'..." << std::endl;
// 下面这行代码会引发问题
// std::cout << "Value of key4: " << value4.value() << std::endl;
}
int main() {
try {
// 创建 redis 对象时,需在构造函数中指定 Redis 服务器的地址和端口
sw::redis::Redis redis("tcp://127.0.0.1:6379");
test1(redis);
} catch (const sw::redis::Error &e) {
std::cerr << "Redis connection error: " << e.what() << std::endl;
return 1;
}
return 0;
}
1.2 编译与运行中的“陷阱”:std::bad_optional_access
当满怀信心地编译并运行上述代码(包含获取key4并直接调用.value()的那一行)时,我们很可能会遇到一个程序崩溃的错误,如下图所示:
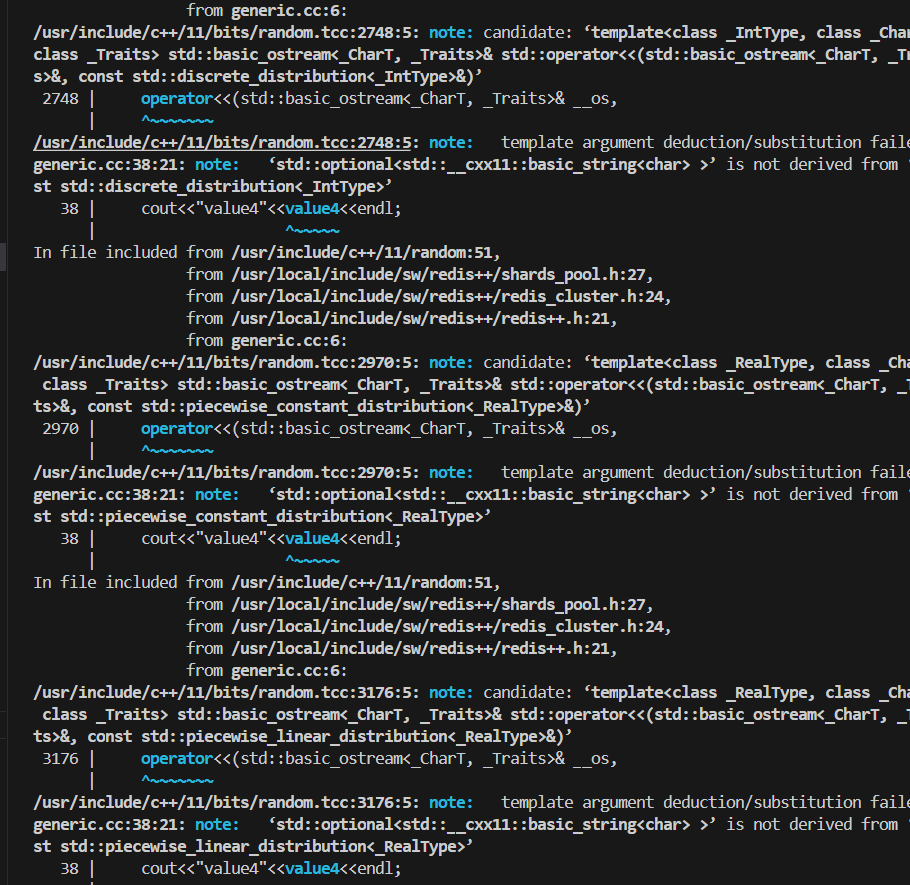
编译时,编译器可能会提示 .value() 不是一个直接可用的成员,这引导我们发现 redis.get() 的返回值并非一个简单的 std::string。而在运行时,我们会遇到一个名为 std::bad_optional_access 的异常,它明确地告诉我们:“你试图访问一个不存在的值”。
这个错误的根源,恰恰是 redis-plus-plus 库以及现代 C++ 设计哲学中的一个精妙之处。
1.3 深度剖析:为何 redis.get() 返回 std::optional?
这是一个绝佳的问题,它触及了现代 C++ 在API设计中关于“值可能不存在”这一普遍问题的优雅解决方案。简单来说,调用 .value() 是因为 redis.get() 方法返回的不是一个简单的字符串,而是一个叫做 std::optional 的“容器”或“包装器”。
为了彻底理解,我们分步来看:
1. 传统方式的困境:函数如何表示“没找到”?
想象一下,如果没有 std::optional,redis.get("key") 这个函数在找不到键时应该返回什么?
- 返回“魔术值”:比如返回一个空字符串
""。这是最常见的做法,但存在致命缺陷。如果某个键在 Redis 中存储的值本身就是一个空字符串呢?在这种情况下,调用者无法区分get返回的空字符串是代表“键不存在”还是“键存在,但其值为空”。这种歧义是许多潜在 bug 的温床。 - 通过出参和返回错误码:函数可以设计成
bool get(const std::string& key, std::string& value)的形式。通过返回true或false来表示是否找到,找到的值则通过引用参数value带回。这种方式虽然可行,但使用起来较为笨拙,破坏了函数调用的链式表达能力,使得代码可读性下降。 - 抛出异常:当键不存在时抛出一个异常。这似乎是一个选择,但“在缓存或数据库中未找到某个键”是一个非常高频、完全在预期之内的正常业务流程,而非一个表示程序进入异常状态的“错误”。为这种常规流程频繁地创建和抛出异常,会带来不必要的性能开销,并使异常处理逻辑变得臃肿。
2. std::optional 的优雅方案:一个“可能包含值”的盒子
为了解决上述问题,C++17 标准库引入了 std::optional。你可以把它想象成一个透明的盒子:
- 这个盒子里可能有一个值(比如一个
std::string)。 - 也可能什么都没有(盒子是空的)。
std::optional 就只有这两种状态,它在类型系统层面就清晰地、无歧义地表达了“一个值可能存在也可能不存在”这个概念。
当 redis-plus-plus 库的 get 方法执行时:
redis.get("key1"): Redis 服务器找到了 “key1”,于是redis-plus-plus返回一个装着字符串"111"的std::optional盒子。redis.get("key4"): Redis 服务器没找到 “key4”,于是redis-plus-plus返回一个空的std::optional盒子。
3. .value() 的作用与风险:从盒子里强行取值
现在你拿到了这个 std::optional 盒子,但你真正想要的是里面的东西(那个字符串)。所以你需要一个动作来“打开盒子,取出里面的值”。
value() 方法就是这个动作。它的语义是:“我作为程序员,在此断言这个盒子里肯定有值,请把它给我。”
- 对于
value1(来自 “key1”),它的盒子里确实有"111",所以value1.value()成功地取出了这个字符串。 - 对于
value4(来自 “key4”),它的盒子是空的。但你还是强行执行了value4.value(),这相当于你对一个空盒子说:“我不管,把里面的值给我!” 程序无法满足这个无理的要求,因为它里面什么都没有,所以只能抛出std::bad_optional_access异常来激烈地抗议,最终导致程序崩溃。
1.4 std::optional 的安全使用与最佳实践
std::optional 的设计初衷就是为了通过类型系统强制程序员处理“值可能为空”的情况,从而编写出更健壮、更安全的代码。以下是几种正确、安全地“开箱”方式:
1. 先检查,再取值(最推荐、最通用的方式)
这是最安全、最清晰的做法。std::optional 对象可以被隐式转换为 bool 类型。如果盒子非空,转换结果为 true;如果为空,则为 false。
auto value4 = redis.get("key4");
if (value4) { // 或者使用更明确的 value4.has_value()
std::cout << "Value of key4: " << value4.value() << std::endl;
} else {
std::cout << "'key4' does not exist in Redis." << std::endl;
}
这段代码逻辑清晰:先判断 value4 是否有值,如果有,才安全地调用 .value() 来获取它。
2. 提供默认值(value_or)
如果你希望在键不存在时使用一个预设的默认值,value_or() 方法极其方便:
// 如果 "key4" 存在,就用它的值;否则,就使用 "default_value"
std::string result = redis.get("key4").value_or("default_value");
std::cout << "The result for 'key4' is: " << result << std::endl;
// 输出: The result for 'key4' is: default_value
3. 使用 try-catch 捕获异常
虽然直接调用 .value() 有风险,但如果你有理由确信值在大多数情况下都应该存在,并且希望将“值不存在”视为一种需要特殊处理的异常情况,那么可以使用 try-catch 块。
try {
auto value4 = redis.get("key4");
std::cout << "Value of key4: " << value4.value() << std::endl;
} catch (const std::bad_optional_access& e) {
std::cerr << "Caught exception: " << e.what() << std::endl;
std::cerr << "Could not retrieve 'key4' as it does not exist." << std::endl;
}
不过,正如您的笔记中提到的,在 C++ 中,try-catch 的开销相对较大,通常不推荐用于处理常规的、可预见的业务流程。将其保留给真正的、意外的错误情况会是更好的选择。
综上所述,我们对 test1 函数进行修正,采用最推荐的检查方式:
void test1_fixed(sw::redis::Redis& redis) {
std::cout << "--- Testing GET and SET (Fixed) ---" << std::endl;
redis.flushall();
std::cout << "Database flushed." << std::endl;
redis.set("key1", "111");
redis.set("key2", "222");
redis.set("key3", "333");
std::cout << "Set 'key1', 'key2', 'key3'." << std::endl;
// 安全地获取存在的 key
auto value1 = redis.get("key1");
if (value1) {
std::cout << "Value of key1: " << value1.value() << std::endl;
}
auto value2 = redis.get("key2");
if (value2) {
std::cout << "Value of key2: " << value2.value() << std::endl;
}
auto value3 = redis.get("key3");
if (value3) {
std::cout << "Value of key3: " << value3.value() << std::endl;
}
// 安全地处理不存在的 key
auto value4 = redis.get("key4");
if (value4) {
std::cout << "Value of key4: " << value4.value() << std::endl;
} else {
std::cout << "'key4' was not found." << std::endl;
}
}
再次编译运行,我们将得到清晰、正确且不会崩溃的输出:
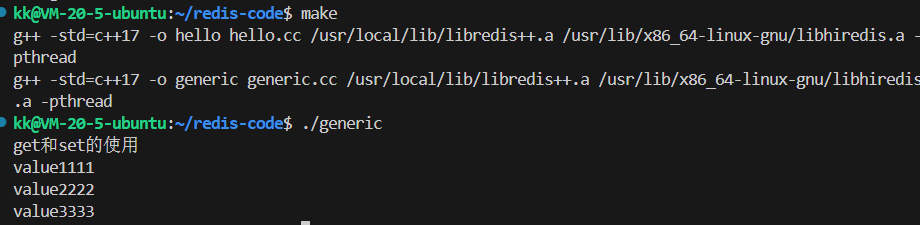
通过 GET 和 SET 的学习,我们不仅掌握了 Redis 最基本的操作,更重要的是理解了 std::optional 这一现代 C++ 的重要工具,它如何帮助我们编写出更安全、更具表达力的代码。
第二章:键的管理艺术 —— EXISTS 与 DEL
在操作数据之前,我们常常需要判断数据是否存在;在数据不再需要时,我们需要将其清理。EXISTS 和 DEL 就是 Redis 提供的用于键生命周期管理的两个基础命令。
2.1 EXISTS:检查键是否存在
EXISTS 命令用于检查一个或多个键是否存在于数据库中。它返回一个整数,代表给定的键中实际存在的数量。
检查单个键:
void test2_exists(sw::redis::Redis& redis) {
std::cout << "\n--- Testing EXISTS ---" << std::endl;
redis.flushall();
redis.set("key1", "111");
// 检查存在的 key1
auto ret1 = redis.exists("key1");
std::cout << "Does 'key1' exist? " << (ret1 ? "Yes" : "No") << " (Return value: " << ret1 << ")" << std::endl;
// 检查不存在的 key2
auto ret2 = redis.exists("key2");
std::cout << "Does 'key2' exist? " << (ret2 ? "Yes" : "No") << " (Return value: " << ret2 << ")" << std::endl;
}
运行上述代码,输出将会是:
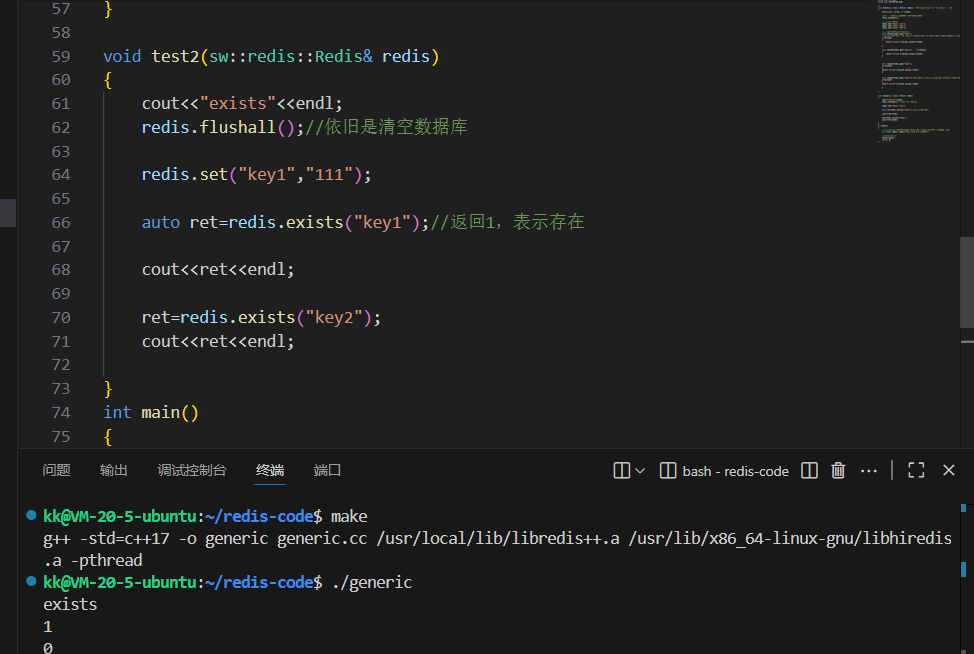
可以看到,当键存在时,redis.exists 返回 1;不存在时返回 0。
检查多个键:
redis-plus-plus 同样支持一次性检查多个键,只需传递一个包含键名的 std::initializer_list 或其他容器即可。
void test2_exists_multiple(sw::redis::Redis& redis) {
std::cout << "\n--- Testing EXISTS (Multiple Keys) ---" << std::endl;
redis.flushall();
redis.set("key1", "111");
redis.set("key3", "333");
// 检查 {"key1", "key2", "key3"},其中 key1 和 key3 存在
long long count = redis.exists({"key1", "key2", "key3"});
std::cout << "Number of existing keys among {'key1', 'key2', 'key3'}: " << count << std::endl;
// 检查都不存在的键
count = redis.exists({"key4", "key5"});
std::cout << "Number of existing keys among {'key4', 'key5'}: " << count << std::endl;
}
这段代码的输出将会是 2 和 0,精确地反映了存在的键的数量。在需要批量检查的场景下,这比多次单独调用 exists 更高效,因为它减少了网络往返的次数。
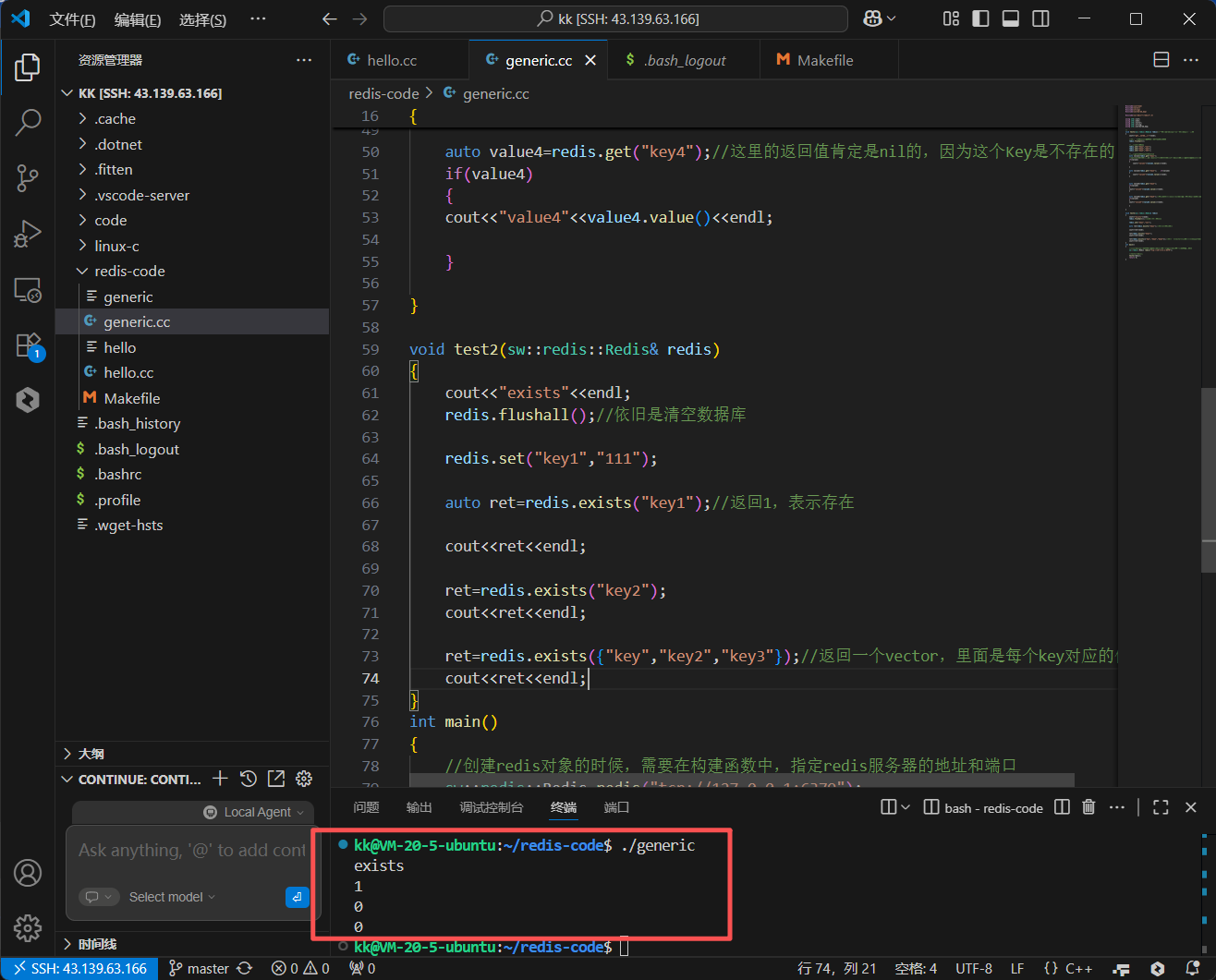
2.2 DEL:删除键
DEL 命令用于删除一个或多个键及其关联的值。与 EXISTS 类似,它也返回一个整数,代表成功删除的键的数量。
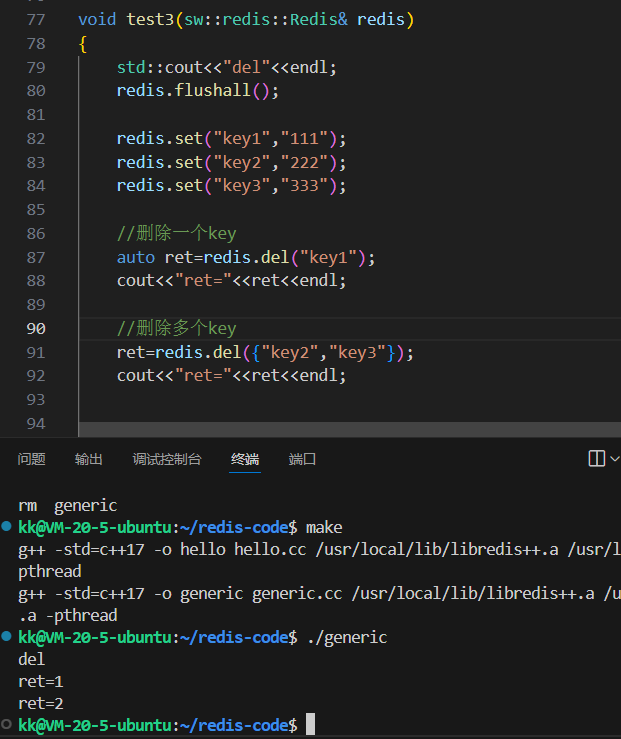
void test3_del(sw::redis::Redis& redis) {
std::cout << "\n--- Testing DEL ---" << std::endl;
redis.flushall();
redis.set("key1", "111");
redis.set("key2", "222");
redis.set("key3", "333");
redis.set("key4", "444");
// 删除单个 key
auto ret = redis.del("key1");
std::cout << "Deleted 'key1'. Keys deleted: " << ret << std::endl;
std::cout << "Does 'key1' still exist? " << redis.exists("key1") << std::endl;
// 删除多个存在的 key
ret = redis.del({"key2", "key3"});
std::cout << "Deleted {'key2', 'key3'}. Keys deleted: " << ret << std::endl;
// 尝试删除一个存在的和一个不存在的 key
ret = redis.del({"key4", "key_nonexistent"});
std::cout << "Deleted {'key4', 'key_nonexistent'}. Keys deleted: " << ret << std::endl;
}
运行这段代码,我们可以观察到:
del("key1")返回1,之后对key1的exists检查返回0。del({"key2", "key3"})返回2,因为这两个键都被成功删除了。del({"key4", "key_nonexistent"})返回1,因为DEL只会计算并返回它实际删除的键的数量,不存在的键会被忽略。
DEL 是一个原子操作,这意味着在删除多个键时,这个操作要么全部完成,要么在中间出错(如服务器宕机),但不会出现只删除了一部分的情况。
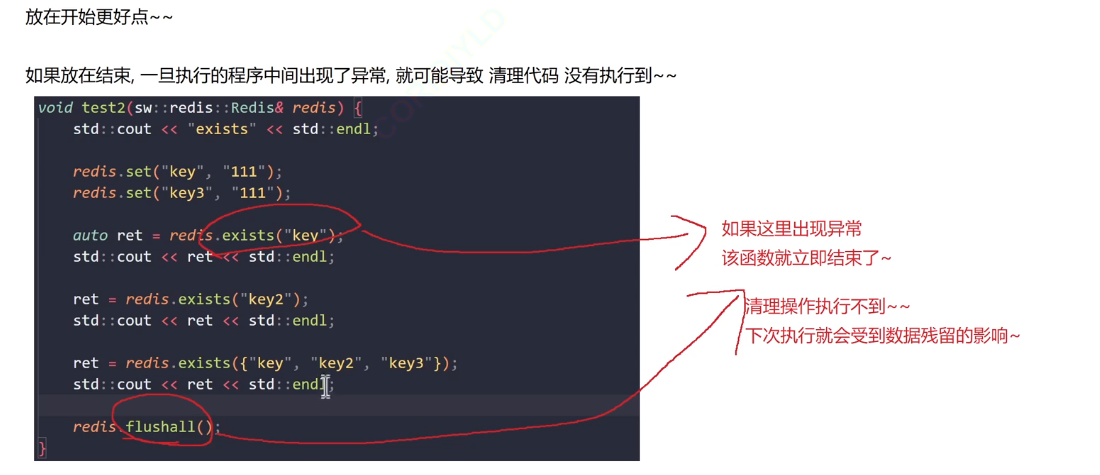
注意:在测试代码中,将 flushall() 放在每个测试函数的开头是一个非常好的习惯,它保证了测试用例之间的独立性,避免了互相干扰。
第三章:探索数据库的钥匙 —— KEYS 命令与迭代器模式
当我们需要了解数据库中存储了哪些键时,KEYS 命令就派上了用场。它支持模式匹配,可以找出所有符合特定规则的键名。
3.1 KEYS 的基本用法与 C++ 实现
KEYS 命令接受一个 glob 风格的模式作为参数。
*匹配任意数量的任意字符。例如KEYS *会返回所有键。?匹配单个任意字符。例如KEYS user:?会匹配user:1、user:a但不匹配user:10。[]匹配括号内的任意一个字符。例如KEYS user:[13]会匹配user:1和user:3。
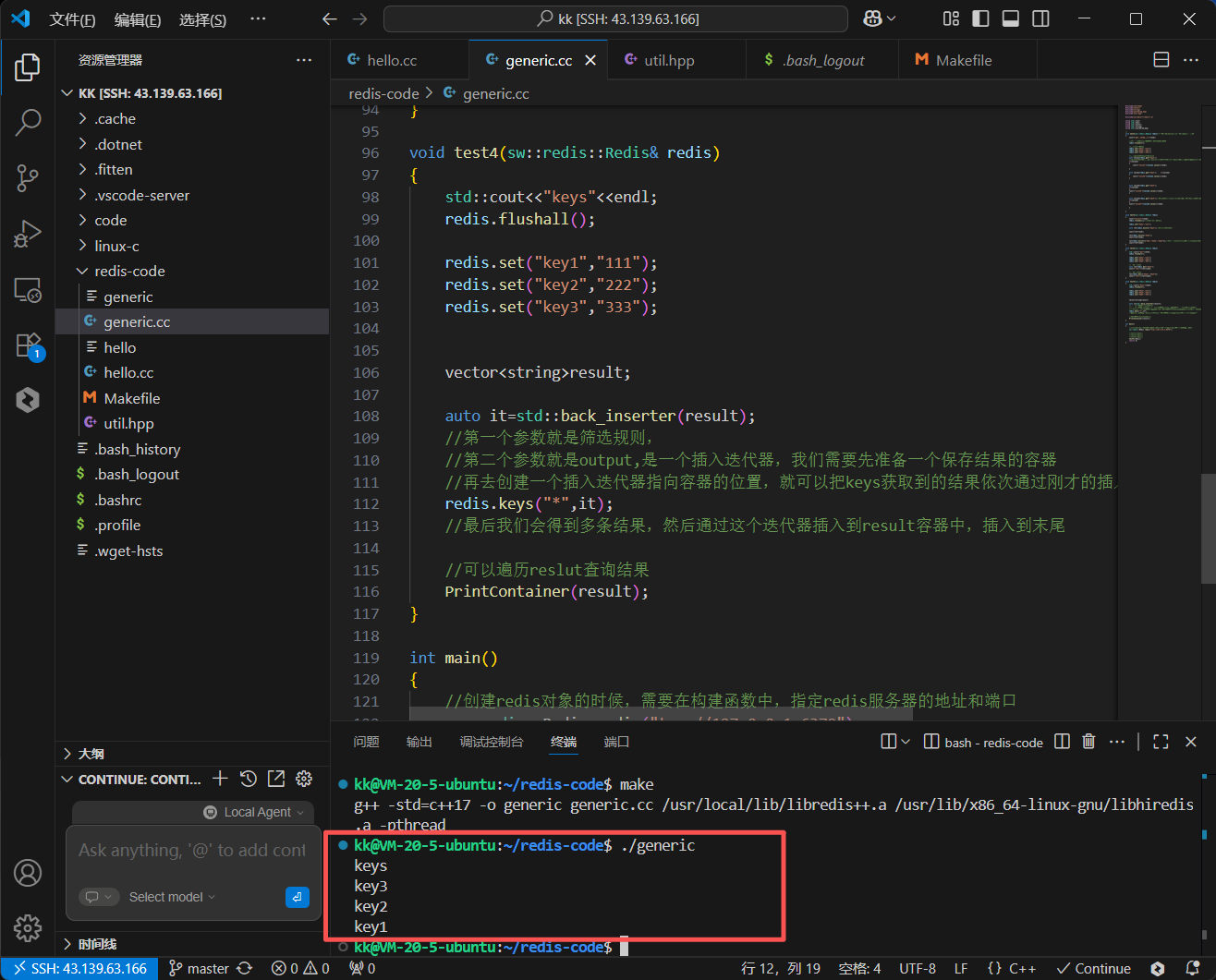
让我们来看一下 redis-plus-plus 是如何优雅地实现 KEYS 命令的调用的。
void test4_keys(sw::redis::Redis& redis) {
std::cout << "\n--- Testing KEYS ---" << std::endl;
redis.flushall();
redis.set("user:1:name", "Alice");
redis.set("user:1:email", "alice@example.com");
redis.set("user:2:name", "Bob");
redis.set("session:xyz", "data");
// 准备一个 vector 用于存储结果
std::vector<std::string> result_keys;
// 创建一个后端插入迭代器,绑定到我们的 vector 上
auto inserter = std::back_inserter(result_keys);
// 调用 redis.keys,使用 "*" 模式匹配所有 key
// 第二个参数是输出迭代器,keys 的结果会被依次插入到 result_keys 的末尾
redis.keys("*", inserter);
std::cout << "All keys (*): ";
PrintContainer(result_keys);
// 清空 vector 并进行下一次查询
result_keys.clear();
redis.keys("user:1:*", inserter);
std::cout << "Keys matching 'user:1:*': ";
PrintContainer(result_keys);
}
这段代码的核心在于 redis.keys("*", inserter) 这一行。它完美地展现了 redis-plus-plus 库与 C++ 标准模板库 (STL) 的无缝集成。
3.2 深度剖析:std::back_inserter 与迭代器的解耦之美
看到这里的 std::back_inserter,您可能会问:为什么 redis.keys 不直接返回一个 std::vector<std::string> 呢?或者为什么不接受一个 std::vector 的引用作为参数,直接在函数内部 push_back?
void keys(const std::string& pattern, std::vector<std::string>& out_vec); // 为什么不这样设计?
答案是:为了解耦合 (Decoupling) 和更高的灵活性。
通过接受一个输出迭代器 (Output Iterator) 作为参数,redis.keys 函数将其核心职责——“从 Redis 获取匹配模式的键列表”——与“如何处理这些获取到的键”这一职责分离开来。
1. 迭代器是什么?
在 C++ STL 中,迭代器是一种泛化的指针,它是一种能够遍历容器(如 vector, list, map 等)中元素的对象。迭代器提供了一组统一的接口(如 * 解引用、++ 移动到下一个),使得算法(如 std::sort, std::copy)可以不关心底层容器的具体类型,而只通过迭代器来操作数据。
STL 中主要有五种迭代器,它们的能力逐级增强:
- 输入迭代器 (Input Iterator):只能向前单向移动,只能读取一次。如同磁带机,只能顺着读一遍。
- 输出迭代器 (Output Iterator):只能向前单向移动,只能写入。如同打印机,只能往上写东西。
- 前向迭代器 (Forward Iterator):结合了前两者的能力,可以多次读写同一个位置,并向前移动。
- 双向迭代器 (Bidirectional Iterator):在前向迭代器的基础上,增加了向后移动 (
--) 的能力。std::list的迭代器就是双向的。 - 随机访问迭代器 (Random Access Iterator):在双向的基础上,增加了任意步进 (
+,-) 和比较 (<,>) 的能力,能够以 O(1) 的时间复杂度访问任意位置。std::vector和std::deque的迭代器就是这种。
2. 插入迭代器的魔法
std::back_inserter 是一种特殊的输出迭代器。它会创建一个后端插入迭代器。这个迭代器有以下特点:
- 它内部持有一个指向容器的引用(在我们的例子中是
result_keys)。 - 当你对这个迭代器赋值时(
*it = value),它并不会覆盖容器中的任何元素,而是会在其内部调用所持容器的push_back(value)方法。

所以,redis.keys 函数内部的逻辑大致是这样的:
- 向 Redis 服务器发送
KEYS *命令。 - 接收到 Redis 返回的键列表,例如
["key1", "key2", "key3"]。 - 遍历这个列表,对于每一个键
key_n,执行*inserter = key_n;。 - 这个赋值操作被
back_inserter“翻译”成了result_keys.push_back(key_n);。
3. 解耦带来的好处
- 灵活性:
redis.keys不再关心你希望把结果存到哪里。你可以轻松地将结果存入std::vector,std::list,std::deque,甚至直接打印到屏幕上,只需提供一个对应的迭代器。// 存入 list std::list<std::string> key_list; redis.keys("*", std::back_inserter(key_list)); // 直接打印到 cout redis.keys("*", std::ostream_iterator<std::string>(std::cout, "\n")); - 效率:对于某些容器,预先不知道大小就反复
push_back可能会导致多次内存重分配。如果redis.keys的调用者预先知道结果的大致数量,他可以先reservevector的空间,或者使用其他更合适的容器,而redis.keys函数本身无需关心这些优化细节。 - 可扩展性:如果你定义了自己的一种特殊容器,只要为其实现了符合要求的
push_back方法并能与back_inserter配合,就可以无缝地与redis.keys一起工作。
这种基于迭代器的设计是 C++ STL 强大功能和高度泛化编程思想的集中体现。
3.3 KEYS 命令的重大警告:生产环境慎用!
尽管 KEYS 命令非常方便,但在生产环境中,必须极其谨慎地使用,尤其是 KEYS *。
原因是:KEYS 是一个阻塞式命令。
当 Redis 执行 KEYS 命令时,它需要遍历数据库中所有的键来进行模式匹配。如果数据库中的键数量巨大(比如几百万、上千万),这个遍历过程将会非常耗时。在此期间,Redis 服务器将无法处理任何其他客户端的请求。这会导致服务响应延迟急剧增加,甚至造成服务在一段时间内完全无响应,引发“服务雪崩”。
生产环境的替代方案:SCAN 命令
为了解决 KEYS 的阻塞问题,Redis 提供了 SCAN 命令。SCAN 采用基于游标 (cursor) 的迭代方式,分步地、非阻塞地遍历数据库中的键。
SCAN命令每次调用只会返回一小部分键,以及一个下次迭代应该使用的新的游标。- 客户端需要循环调用
SCAN,传入上一次返回的游标,直到游标返回0,表示遍历完成。 - 由于每次调用只占用很短的时间,
SCAN不会像KEYS那样长时间阻塞服务器。
在 redis-plus-plus 中使用 SCAN 也非常方便,它通常会返回一个包含游标和结果的元组或结构体,你需要在一个循环中处理它。虽然比 KEYS 稍显复杂,但为了生产环境的稳定性,这是绝对必要的。
第四章:时间的魔法师 —— EXPIRE 与 TTL
在很多应用场景,我们不希望数据永久地存储在 Redis 中。例如,网站的会话信息、手机验证码、缓存数据等,它们都具有一定的生命周期。Redis 提供了 EXPIRE 和 TTL 等命令来精确地管理键的生存时间。
4.1 EXPIRE:为键设置“倒计时”
EXPIRE 命令用于为一个已经存在的键设置过期时间(以秒为单位)。当键的过期时间到达后,Redis 会自动将其删除。
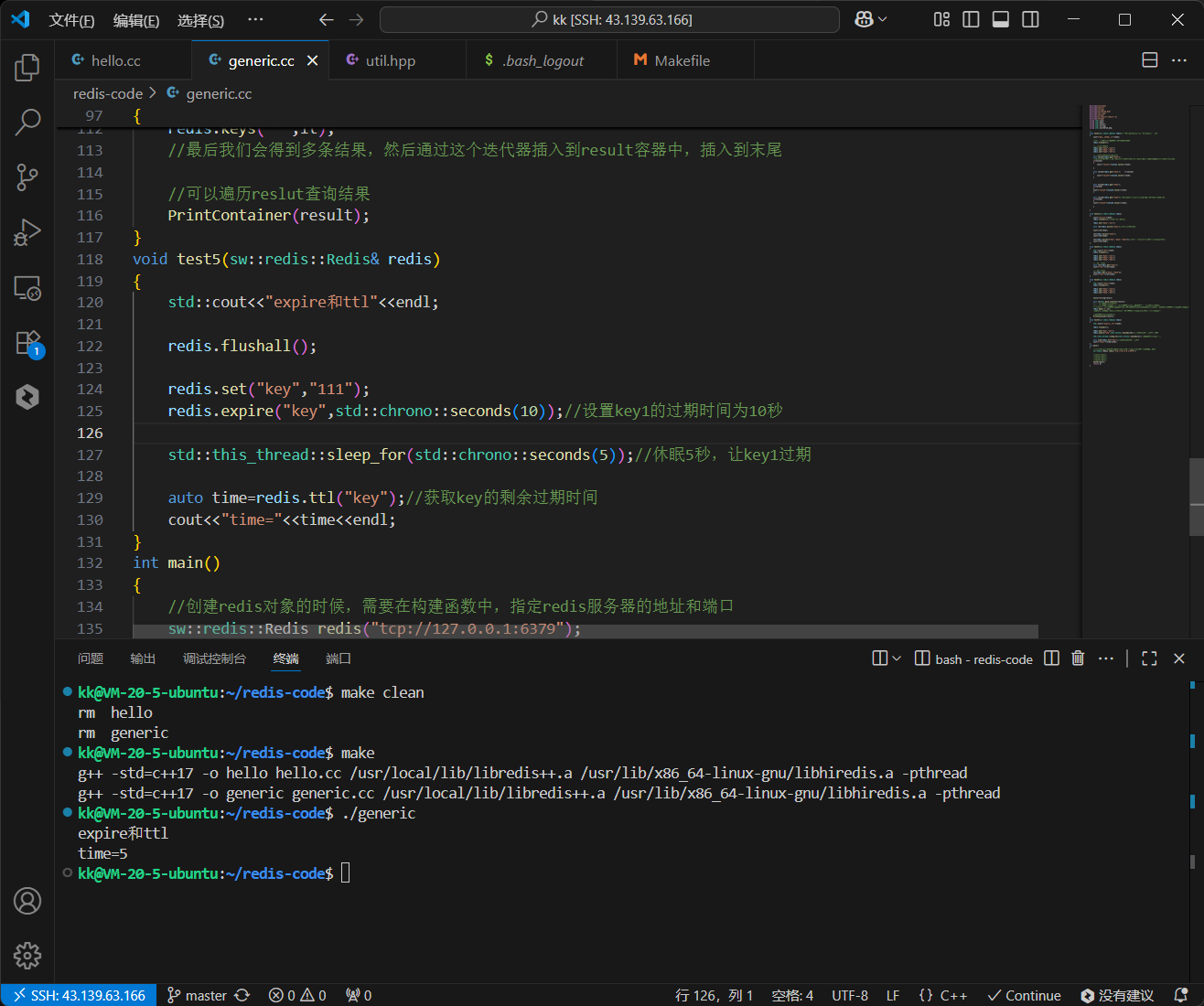
redis-plus-plus 巧妙地利用了 C++11 的 std::chrono 库来处理时间,使得代码更加类型安全和语义化。
#include <thread> // for std::this_thread::sleep_for
void test5_expire_ttl(sw::redis::Redis& redis) {
std::cout << "\n--- Testing EXPIRE and TTL ---" << std::endl;
redis.flushall();
redis.set("key", "some temporary value");
// 设置 key 的过期时间为 10 秒
std::cout << "Setting 'key' to expire in 10 seconds." << std::endl;
bool success = redis.expire("key", std::chrono::seconds(10));
if (!success) {
std::cerr << "Failed to set expire on 'key'." << std::endl;
}
// 休眠 5 秒
std::cout << "Sleeping for 5 seconds..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(5));
// 获取 key 的剩余过期时间
auto time_left = redis.ttl("key");
std::cout << "Time to live for 'key': " << time_left << " seconds." << std::endl;
// 再休眠 6 秒,确保 key 过期
std::cout << "Sleeping for 6 seconds..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(6));
time_left = redis.ttl("key");
std::cout << "After expiry, time to live for 'key': " << time_left << std::endl;
std::cout << "Does 'key' exist now? " << redis.exists("key") << std::endl;
}
代码解读:
redis.expire("key", std::chrono::seconds(10));这一行清晰地表达了“为key设置10秒的过期时间”。std::chrono的使用避免了“魔法数字”,也使得时间单位(秒、毫秒等)的转换不易出错。std::this_thread::sleep_for(...)用于模拟时间的流逝。- 第一次调用
redis.ttl("key")时,由于已经过去了5秒,我们预期返回值会是5或4(取决于命令执行和网络延迟)。 - 第二次调用
redis.ttl("key")时,总共已过去11秒,超过了10秒的过期时间,此时key应该已被 Redis 自动删除。
4.2 TTL:查询剩余生存时间
TTL (Time To Live) 命令用于查询一个键的剩余生存时间(以秒为单位)。它的返回值有特殊的含义:
- 返回一个正整数:表示该键剩余的生存时间(秒)。
- 返回
-1:表示该键存在,但没有设置过期时间(即永久有效)。 - 返回
-2:表示该键不存在。
运行 test5 函数,我们得到的输出将完美印证上述逻辑:
--- Testing EXPIRE and TTL ---
Setting 'key' to expire in 10 seconds.
Sleeping for 5 seconds...
Time to live for 'key': 5 seconds.
Sleeping for 6 seconds...
After expiry, time to live for 'key': -2
Does 'key' exist now? 0
这清晰地展示了 EXPIRE 和 TTL 的工作流程。
其他相关命令:
PEXPIRE和PTTL:功能与EXPIRE和TTL相同,但时间单位是毫秒。EXPIREAT和PEXPIREAT:用于设置一个未来的、绝对的 UNIX 时间戳(秒或毫秒)作为键的过期时间点。PERSIST:用于移除一个键的过期时间,使其变回永久有效。PERSIST成功时返回1,如果键不存在或本身就是永久的,则返回0。
第五章:洞察数据本质 —— TYPE 命令
Redis 不仅仅是一个简单的字符串键值存储,它支持多种复杂的数据结构。TYPE 命令就是我们用来识别一个键所存储的值究竟是哪种数据类型的工具。
Redis 的五种基本数据类型是:
- String (字符串):最基本的数据类型,可以是文本、JSON、序列化的对象,甚至是二进制数据(如图片)。
- List (列表):一个字符串元素的集合,按照插入顺序排序。可以从头部或尾部添加/弹出元素,使其可以作为栈或队列使用。
- Hash (哈希):一个键值对的集合,非常适合用来存储对象。例如,一个
user键可以包含name、age、email等多个字段。 - Set (集合):一个无序的、不重复的字符串元素集合。支持高效的成员检查、并集、交集、差集等操作。
- ZSET (Sorted Set, 有序集合):与集合类似,但每个成员都会关联一个分数 (score)。Redis 会根据这个分数对成员进行排序,使其非常适合实现排行榜、范围查询等功能。
5.1 TYPE 命令的 C++ 实践
下面的测试函数将依次创建这五种不同类型的键,并使用 TYPE 命令来验证它们的类型。
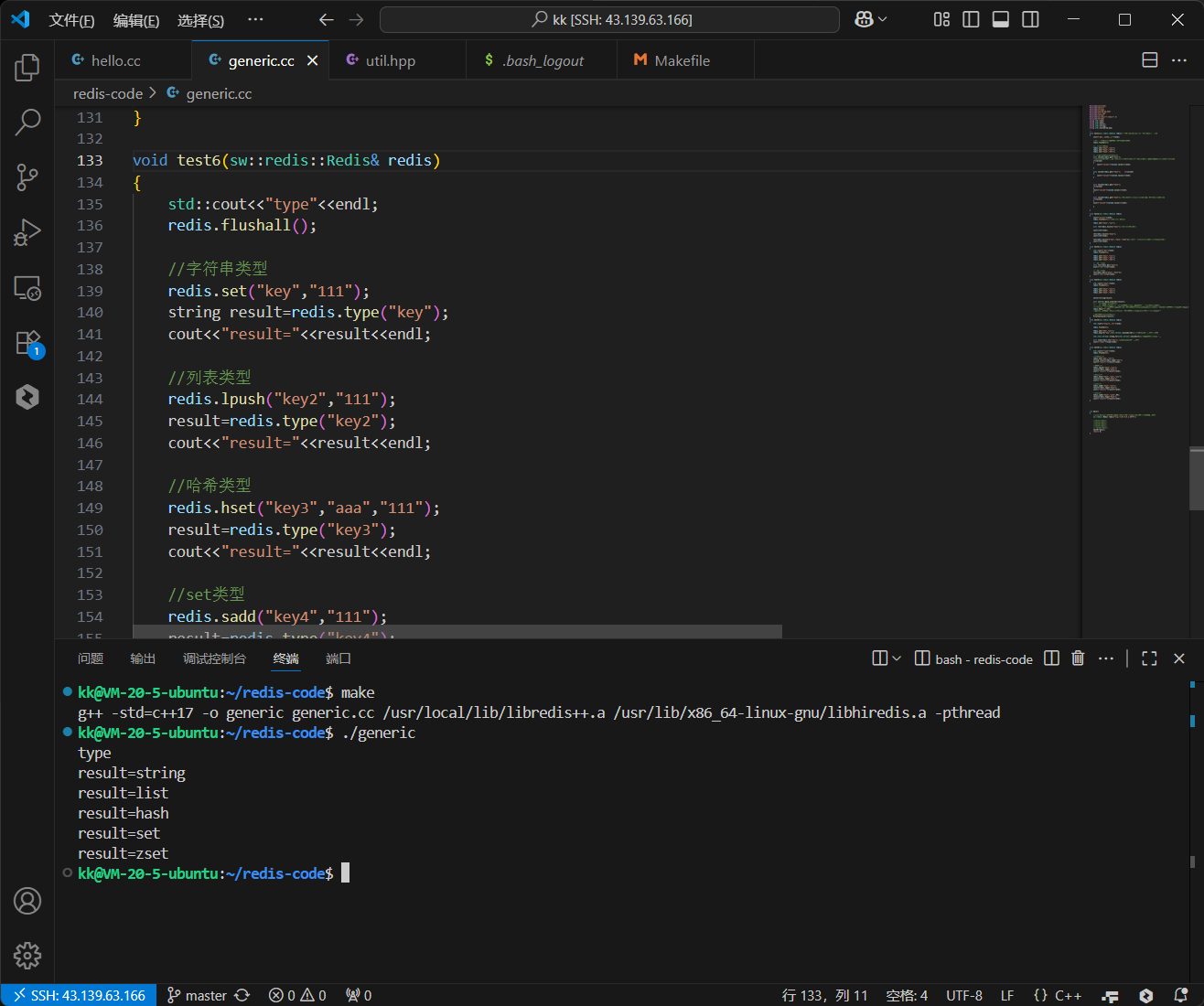
void test6_type(sw::redis::Redis& redis) {
std::cout << "\n--- Testing TYPE ---" << std::endl;
redis.flushall();
std::string result;
// 1. 字符串类型 (String)
redis.set("key_string", "I am a string");
result = redis.type("key_string");
std::cout << "Type of 'key_string': " << result << std::endl;
// 2. 列表类型 (List)
redis.lpush("key_list", "item1");
result = redis.type("key_list");
std::cout << "Type of 'key_list': " << result << std::endl;
// 3. 哈希类型 (Hash)
redis.hset("key_hash", "field1", "value1");
result = redis.type("key_hash");
std::cout << "Type of 'key_hash': " << result << std::endl;
// 4. 集合类型 (Set)
redis.sadd("key_set", "member1");
result = redis.type("key_set");
std::cout << "Type of 'key_set': " << result << std::endl;
// 5. 有序集合类型 (ZSET / Sorted Set)
redis.zadd("key_zset", "Lu Bu", 99);
result = redis.type("key_zset");
std::cout << "Type of 'key_zset': " << result << std::endl;
// 6. 不存在的键
result = redis.type("key_nonexistent");
std::cout << "Type of 'key_nonexistent': " << result << std::endl;
}
redis.type(key) 的返回值是一个字符串,表示该键的类型。如果键不存在,它会返回 none。
运行 test6 函数,输出结果将清晰地展示每种数据结构对应的类型名:
--- Testing TYPE ---
Type of 'key_string': string
Type of 'key_list': list
Type of 'key_hash': hash
Type of 'key_set': set
Type of 'key_zset': zset
Type of 'key_nonexistent': none
这个简单的命令对于调试和理解数据库中的数据状态至关重要。
结语:超越基础,迈向精通
通过本文的详细探讨,我们不仅学习了 Redis 的 GET/SET, EXISTS/DEL, KEYS, EXPIRE/TTL, 和 TYPE 这几组核心通用命令,更重要的是,我们深入了解了 redis-plus-plus 是如何利用现代 C++ 的特性(如 std::optional 和迭代器)来提供一个既安全又灵活的编程接口。
我们看到了 std::optional 如何优雅地解决了“值不存在”的表达问题,避免了传统错误处理方式的种种弊端。我们剖析了基于迭代器的 API 设计如何实现完美的解耦,赋予代码更高的灵活性和可扩展性。我们还强调了在生产环境中使用 KEYS 命令的潜在风险,并指出了 SCAN 作为其安全替代方案的重要性。
今天我们所接触的,仅仅是 Redis 宏伟世界的冰山一角。Redis 强大的数据结构——列表、哈希、集合、有序集合——各自都拥有一套丰富的命令集,能够解决各种复杂的业务问题。希望本文能为您打下坚实的基础,并激发您继续探索 Redis 更高级功能的热情。
将高性能的 C++ 与高速的 Redis 相结合,您将有能力构建出这个时代最顶尖的应用程序。现在,是时候开始您的 Redis C++ 编程之旅了!