Apple 团队提出的FastVLM,解决视觉语言模型(VLMs)在高分辨率输入下的效率瓶颈,其核心是创新的混合视觉编码器FastViTHD。
该编码器通过 5 阶段混合卷积 - Transformer 架构,无需额外 token 修剪,仅通过缩放输入图像即可实现视觉 token 数量减少与分辨率提升的平衡;
论文地址:FastVLM: Efficient Vision Encoding for Vision Language Models
代码地址:https://github.com/apple/ml-fastvlm
在 LLaVA1.5 框架下,FastVLM 实现3.2× 的首 token 生成时间(TTFT)提升,与 LLaVA-OneVision(1152×1152 分辨率)相比,使用相同 0.5B LLM 时性能更优,且 TTFT 快85× 、视觉编码器小3.4× 。
- 架构设计(5 阶段结构,125.1M 参数):
阶段 核心组件 下采样倍数 嵌入维度 层数 1-3 RepMixer 块 逐阶段 ×2 96→192→384 2、12、24 4-5 多头自注意力块 最终 ×64 768→1536 4、2 - 关键改进:
- 新增第 5 阶段下采样层,使自注意力在 ×32 下采样张量上运行(传统模型多为 ×16),减少计算量;
- 输出 token 比 FastViT 少 4×,比 ViT-L/14 少 16×(336 分辨率下);
- 预训练与性能:基于 DataCompDR-1B 数据集 CLIP 预训练,在 38 项多模态任务上与 ViT-L/14 性能相当(66.3 vs 66.3),但大小小 2.4×、延迟快 6.9×。
一、模型框架
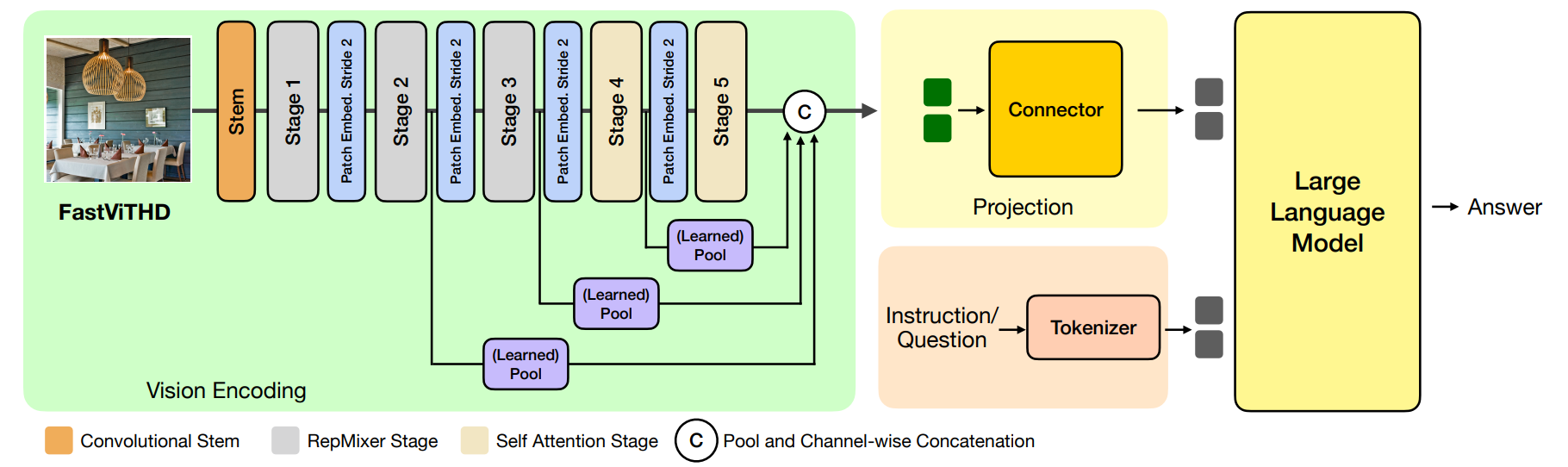
1. 视觉编码:FastViTHD 提取分层特征
输入图像首先进入 Convolutional Stem(卷积干),完成初步特征提取与下采样,为后续阶段奠定基础。
接着,图像特征流经5 个阶段(Stage),分为两类结构:
- 前 3 个阶段:
RepMixer Stage(灰色模块)。RepMixer 是高效的 “卷积 - 混合” 架构,能在低计算成本下提取多尺度局部特征;阶段间通过Patch Embed, Stride 2(步长为 2 的 patch 嵌入)实现特征下采样,减少空间维度、提升计算效率。 - 后 2 个阶段:
Self Attention Stage(米色模块)。自注意力机制捕捉长距离视觉依赖,提炼高阶语义特征;阶段间同样通过Patch Embed, Stride 2调整特征维度。
2. 多尺度特征融合:池化与拼接
从不同 Stage 中,通过 **(Learned) Pool**(学习池化模块)提取关键特征,再经Pool and Channel-wise Concatenation(标记为 “C” 的模块)完成多尺度特征的通道维度拼接—— 融合底层细节(如纹理、边缘)与高层语义(如物体、场景),得到更全面的视觉表征。
3. 跨模态对齐:视觉特征投影 + 文本编码
- 视觉侧:融合后的视觉特征进入
Connector与Projection模块,将视觉特征投影到与语言模型匹配的特征空间(维度、分布对齐),为多模态融合做准备。 - 文本侧:用户输入的
Instruction/Question(指令 / 问题)经Tokenizer(分词器)处理,转化为语言模型可理解的文本 token 序列。
4. 多模态生成:LLM 整合并输出答案
最终,投影后的视觉特征与分词后的文本 token共同输入Large Language Model(大型语言模型),LLM 基于多模态信息推理,生成最终的Answer(答案)。
二、复现
获取代码工程:
git clone https://github.com/apple/ml-fastvlm.git创建Conda环境,然后安装依赖包:
conda create -n fastvlm python=3.10
conda activate fastvlm
pip install -e .等待安装完成:
........
Successfully installed accelerate-1.6.0 attrs-25.3.0 cattrs-25.2.0 coremltools-8.2 einops-0.6.1 einops-exts-0.0.4 fastapi-0.116.1 ffmpy-0.6.1 gradio-5.11.0 gradio-client-1.5.3 hf-xet-1.1.9 huggingface-hub-0.34.4 latex2mathml-3.78.1 llava-1.2.2.post1 markdown2-2.5.4 mpmath-1.3.0 numpy-1.26.4 nvidia-cublas-cu12-12.4.5.8 nvidia-cuda-cupti-cu12-12.4.127 nvidia-cuda-nvrtc-cu12-12.4.127 nvidia-cuda-runtime-cu12-12.4.127 nvidia-cudnn-cu12-9.1.0.70 nvidia-cufft-cu12-11.2.1.3 nvidia-curand-cu12-10.3.5.147 nvidia-cusolver-cu12-11.6.1.9 nvidia-cusparse-cu12-12.3.1.170 nvidia-cusparselt-cu12-0.6.2 nvidia-nccl-cu12-2.21.5 nvidia-nvjitlink-cu12-12.4.127 nvidia-nvtx-cu12-12.4.127 pydub-0.25.1 python-multipart-0.0.20 ruff-0.12.12 safehttpx-0.1.6 scikit-learn-1.2.2 scipy-1.15.3 semantic-version-2.10.0 sentencepiece-0.1.99 shellingham-1.5.4 shortuuid-1.0.13 starlette-0.47.3 sympy-1.13.1 timm-1.0.15 tokenizers-0.21.0 tomlkit-0.13.3 torch-2.6.0 torchvision-0.21.0 transformers-4.48.3 triton-3.2.0 typer-0.17.4 typing-extensions-4.15.0 wavedrom-2.0.3.post3
(fastvlm) lgp@lgp-MS-7E07:~/2025_project/ml-fastvlm$
模型权重:
| 模型 | 阶段 | Pytorch 检查点 (url) |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| 3 | fastvlm_0.5b_stage3 | |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| 3 | fastvlm_1.5b_stage3 | |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| 3 | fastvlm_7b_stage3 |
下载所有预训练的检查点,请运行以下命令:
bash get_models.sh # Files will be downloaded to `checkpoints` directory.下载好后能看到:
修改predict.py代码:
import os
import argparse
import torch
from PIL import Image
from llava.utils import disable_torch_init
from llava.conversation import conv_templates
from llava.model.builder import load_pretrained_model
from llava.mm_utils import tokenizer_image_token, process_images, get_model_name_from_path
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
def predict(args):
# Remove generation config from model folder
# to read generation parameters from args
model_path = os.path.expanduser(args.model_path)
generation_config = None
if os.path.exists(os.path.join(model_path, 'generation_config.json')):
generation_config = os.path.join(model_path, '.generation_config.json')
os.rename(os.path.join(model_path, 'generation_config.json'),
generation_config)
# 自动检测设备(如果未指定)
if args.device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
else:
device = args.device
# Load model - 使用自动检测或指定的设备
disable_torch_init()
model_name = get_model_name_from_path(model_path)
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path, args.model_base, model_name,
device=device # 使用灵活的设备配置
)
# Construct prompt
qs = args.prompt
if model.config.mm_use_im_start_end:
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
else:
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
conv = conv_templates[args.conv_mode].copy()
conv.append_message(conv.roles[0], qs)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
# Set the pad token id for generation
model.generation_config.pad_token_id = tokenizer.pad_token_id
# Tokenize prompt - 使用统一的设备
input_ids = tokenizer_image_token(
prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt'
).unsqueeze(0).to(torch.device(device))
# Load and preprocess image
image = Image.open(args.image_file).convert('RGB')
image_tensor = process_images([image], image_processor, model.config)[0]
# 将图像张量移动到正确的设备
image_tensor = image_tensor.to(torch.device(device))
# Run inference
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor.unsqueeze(0).half(),
image_sizes=[image.size],
do_sample=True if args.temperature > 0 else False,
temperature=args.temperature,
top_p=args.top_p,
num_beams=args.num_beams,
max_new_tokens=256,
use_cache=True)
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
print(outputs)
# Restore generation config
if generation_config is not None:
os.rename(generation_config, os.path.join(model_path, 'generation_config.json'))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default="./checkpoints/llava-fastvithd_0.5b_stage2")
parser.add_argument("--model-base", type=str, default=None)
parser.add_argument("--image-file", type=str, default="./test_data/1.jpg", help="location of image file")
parser.add_argument("--prompt", type=str, default="Describe the image.", help="Prompt for VLM.")
parser.add_argument("--conv-mode", type=str, default="qwen_2")
parser.add_argument("--temperature", type=float, default=0.2)
parser.add_argument("--top_p", type=float, default=None)
parser.add_argument("--num_beams", type=int, default=1)
# 添加设备选择参数
parser.add_argument("--device", type=str, default="cpu",
help="设备选择,可选值: 'cuda', 'cpu' 或 'mps'(仅Apple设备)")
args = parser.parse_args()
predict(args)
准备一些测试图片,然后可以开始提问了。
示例1,输入图片如下:(使用llava-fastvithd_0.5b_stage2模型)

prompt 提示词:"Describe the image."
回答:
The image depicts an outdoor seating area of a modern building, likely a café or restaurant. The setting is characterized by a series of tables and chairs arranged in a linear fashion along the sidewalk. The tables are made of dark metal and are paired with brown wicker chairs that have a classic design. Each table is accompanied by a green umbrella, providing shade and a uniform aesthetic to the seating area.
The chairs and tables are arranged in a staggered pattern, creating a sense of depth and inviting visitors to sit and enjoy their surroundings. The flooring is made of red bricks, which adds a rustic charm to the modern setting.
In the background, the building features a combination of brick and glass materials, giving it a contemporary look. The building's facade is adorned with large windows, which likely allow natural light to flood the interior spaces. The windows reflect the sky and surrounding buildings, adding to the overall ambiance of the space.
Along the sidewalk, there are several potted plants, including some with lush green foliage, which contribute to the greenery and natural feel of the area. The plants are placed in black planters, which provide a stark contrast to the greenery and the red brick floor.
The image also shows a pathway or walkway adjacent to the seating area,换一个问题(还是上面的图片)
prompt 提示词:"What is the scene in the picture?"
回答:
The scene in the picture is an outdoor seating area of a modern building, likely a café or restaurant.
The space is well-organized with tables and chairs arranged for customers to dine or relax.
The furniture is made of dark wood, and the chairs have a wicker design, which adds a touch of rustic charm to the modern setting. The tables are paired with green umbrellas, providing shade for the patrons. The plants in the planters add a touch of greenery, enhancing the aesthetic appeal of the space.
The building itself has a contemporary design with large windows and a brick facade, which complements the modern furniture. The pathway leading to the seating area is paved with bricks, and the overall atmosphere is inviting and comfortable.示例2,输入图片如下:(使用llava-fastvithd_1.5b_stage3模型)

prompt 提示词:"Detect the table, chair, and cup in the image and output their location and category."
回答:
To detect the table, chair, and cup in the image, we need to carefully observe the objects present in the scene.
1. **Identify the Table:**
- The table is centrally located in the image.
- It is a rectangular table with a light-colored surface.
- The table is situated under a pergola, which provides shade.
2. **Identify the Chair:**
- There are multiple chairs around the table.
- The chairs have a light-colored fabric and dark metal frames.
- They are positioned around the table, indicating they are meant for seating.
3. **Identify the Cup:**
- On the table, there is a tray with a cup on it.
- The cup is transparent and appears to be made of glass.
- The tray also contains other items, such as a pitcher and some food.
By analyzing these observations, we can conclude the following:
- **Table:** Located centrally under the pergola, light-colored surface, rectangular shape.
- **Chair:** Surrounding the table, light-colored fabric, dark metal frames.
- **Cup:** On the tray of the table, transparent, likely made of glass.
Thus, the table is in the center, the chairs are分享完成~