1.什么是内存池
1. 池化技术
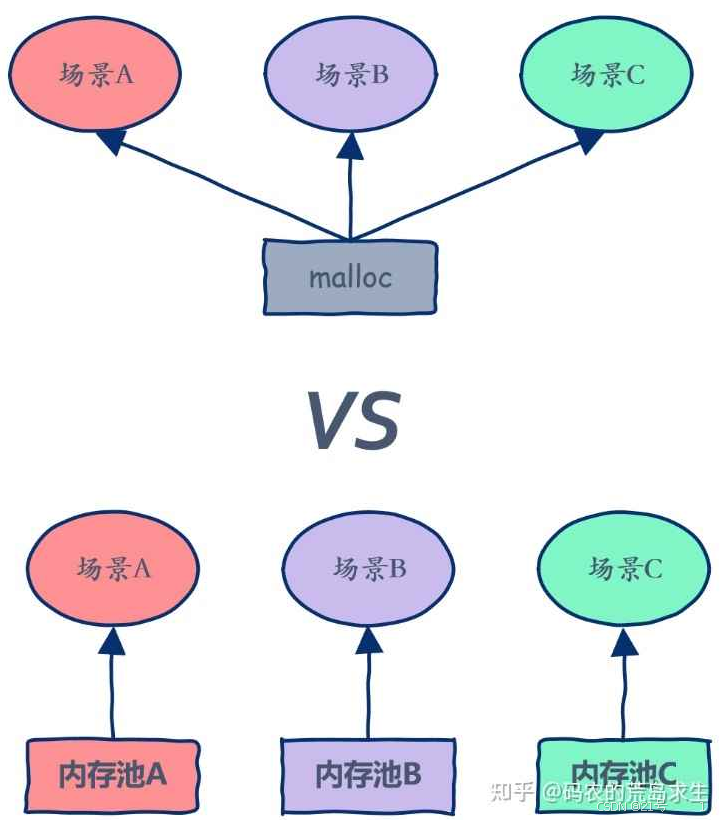
2. 内存池
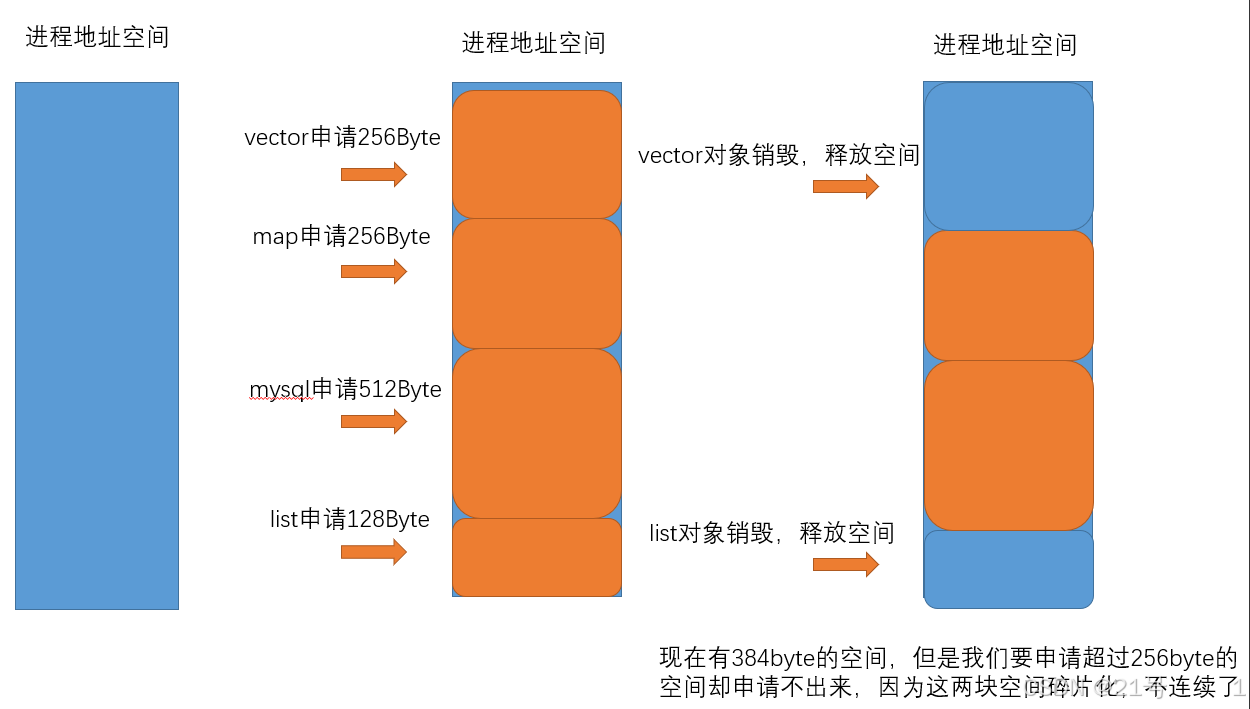
3. 内存池主要解决的问题
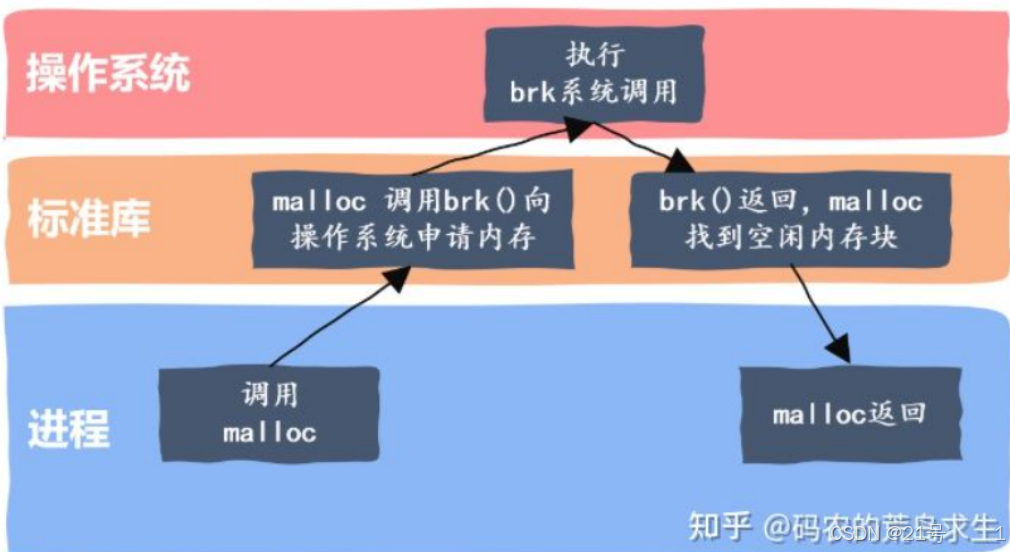
4. malloc
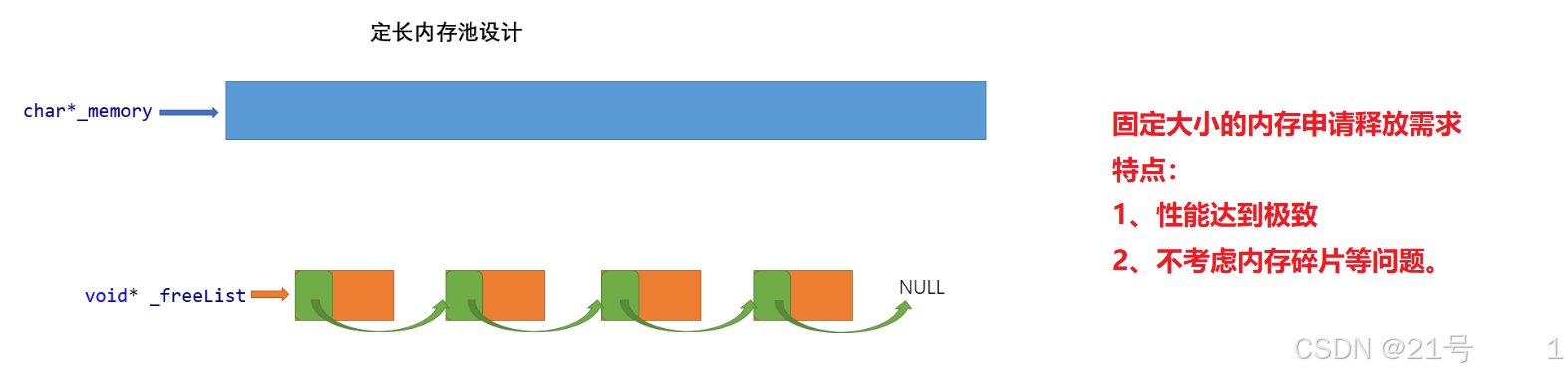
5. 设计一个定长内存池

VirtualAlloc
void* ptr = VirtualAlloc(0, kpage<<13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
各参数含义如下:
第一个参数(lpAddress):
0
指定要分配的内存起始地址。传入0表示让系统自动选择合适的地址,这是最常用的方式。第二个参数(dwSize):
kpage<<13
表示要分配的内存大小(字节)。kpage<<13等价于kpage * 8192(因为 2^13 = 8192),即分配大小为kpage乘以 8KB。第三个参数(flAllocationType):
MEM_COMMIT | MEM_RESERVE
内存分配类型,这里是两个标志的组合:MEM_RESERVE:在虚拟地址空间中保留一块区域(不实际分配物理内存)MEM_COMMIT:为已保留的区域分配物理内存或页面文件(交换文件)
组合使用表示 "既保留地址空间,又提交物理内存"。
第四个参数(flProtect):
PAGE_READWRITE
内存保护属性,表示该内存区域可读可写,但不可执行(Windows 会启用 DEP 保护)。
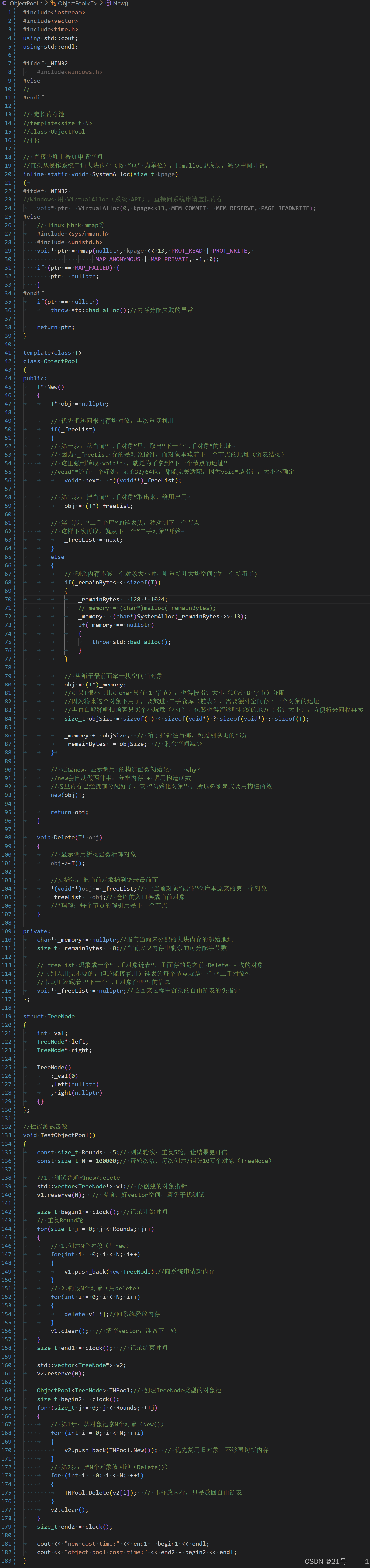
ObjectPool.h
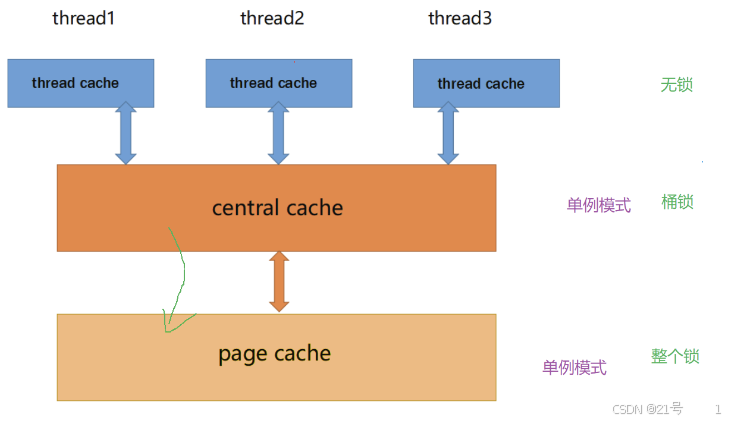
6. 高并发内存池整体框架设计
1. 性能问题。
2. 多线程环境下,锁竞争问题。
Common.h

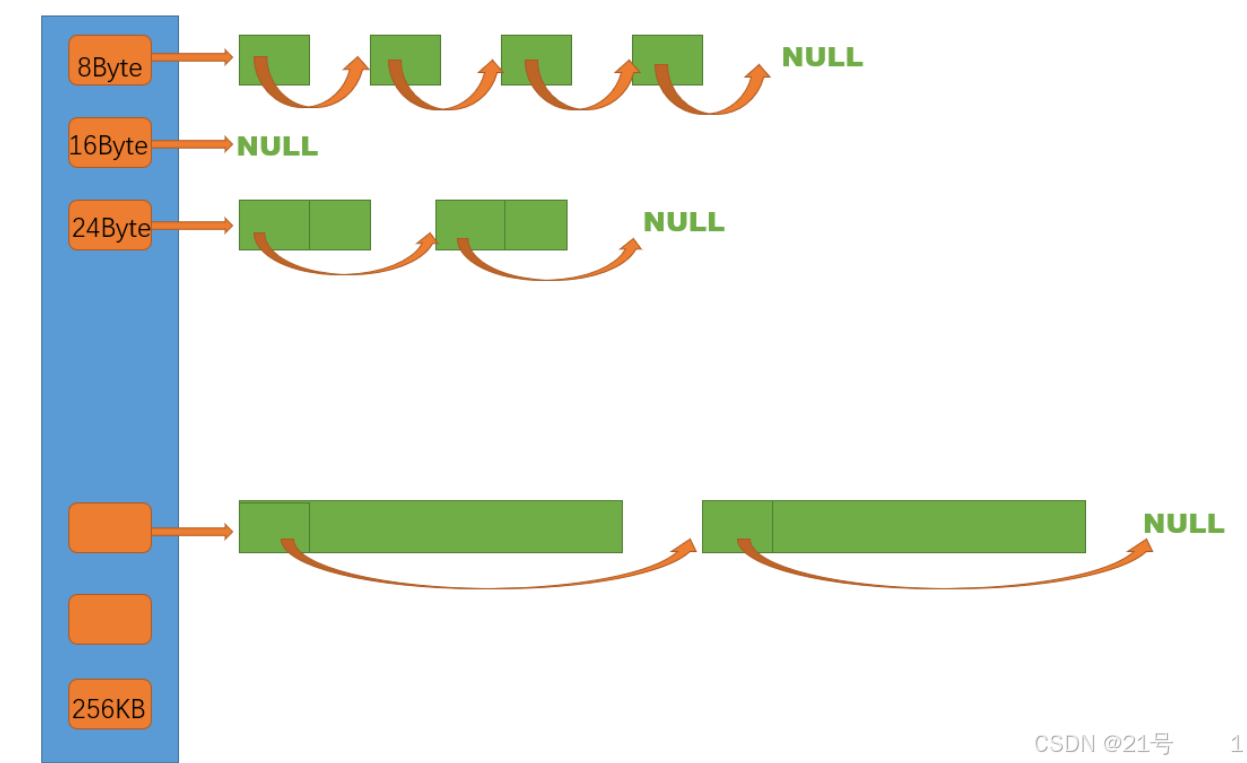
7. 高并发内存池 -- thread cache
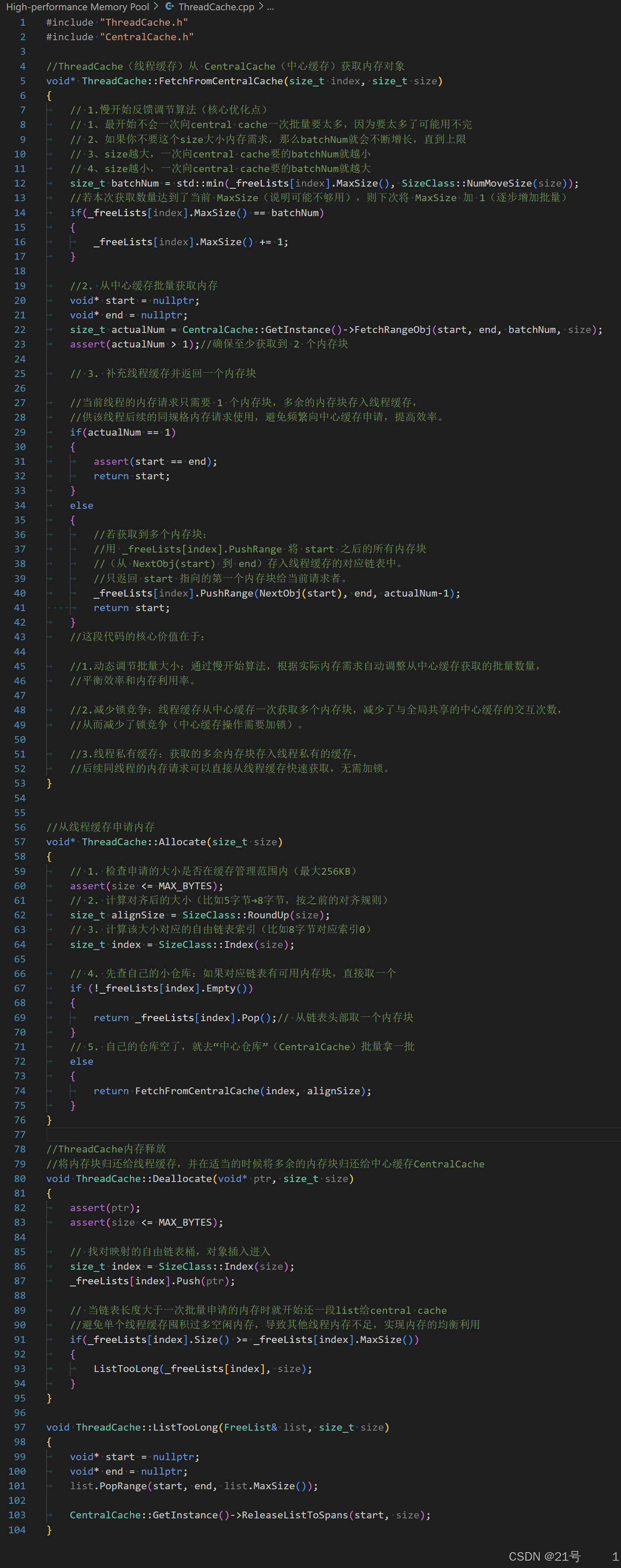
thread cache是哈希桶结构,每个桶是⼀个按桶位置映射⼤⼩的内存块对象的⾃由链表。每个线程都会有⼀个thread cache对象,这样每个线程在这⾥获取对象和释放对象时是⽆锁的。
申请内存:
1. 当内存申请size<=256KB,先获取到线程本地存储的thread cache对象,计算size映射的哈希桶⾃由链表下标i。
2. 如果⾃由链表_freeLists[i]中有对象,则直接Pop⼀个内存对象返回。
ThreadCache.h
ThreadCache.cpp
_RoundUp函数,高效的向上取整算法,用位运算实现
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}核心是利用位运算的特性快速找到 "比目标大的最小对齐数"
关键步骤拆解(以 8 字节对齐为例)
假设 alignNum=8(我们要按 8 的倍数对齐),bytes 是任意需要对齐的数字(比如 10):
计算
alignNum - 1
8-1=7,二进制是000...0111(末尾 3 个 1,因为 8 是 2³)。
这一步的作用是得到 "对齐数的掩码",末尾的 1 的个数等于对齐数的幂次(8=2³,所以 3 个 1)。计算
bytes + (alignNum - 1)
比如 bytes=10 时,10+7=17(二进制10001)。
这一步的作用是:如果 bytes 不是 8 的倍数,就 "凑够" 到下一个 8 的倍数的差值。
比如 10 离 16 差 6,加 7 后就超过了 16,相当于 "进位" 到了下一个区间。计算
~(alignNum - 1)
对 7 取反(二进制111...1000),这是一个 "清除末尾低 n 位" 的掩码(n 是对齐数的幂次)。
作用是:只保留高位,把末尾可能产生的余数部分清零。最后做与运算
&
17(10001) &111...1000= 16(10000),正好是 8 的倍数且大于 10 的最小数。
为什么这样能实现向上取整?
- 对齐数(如 8、16)都是 2 的幂次方(2ⁿ),它们的二进制只有一位是 1(8=1000,16=10000)。
alignNum - 1则是 "末尾 n 个 1"(7=0111,15=01111),取反后就是 "高位全 1,末尾 n 个 0"。- 加
alignNum-1确保了如果有余数,就会 "进位" 到下一个区间;再与取反后的掩码做与运算,就会把余数部分清零,只保留完整的对齐数。
再举两个例子
bytes=8(正好对齐)
8+7=15 → 15 &111...1000= 8(正确,本身就是 8 的倍数)。bytes=15(需要对齐到 16)
15+15=30(假设 alignNum=16,16-1=15) → 30 &111...11110000= 16(正确)。
简单说,这个算法的本质是:先把数字 "顶" 到下一个对齐区间,再把多余的零头 "切掉",用位运算实现比除法 / 乘法更高效。
_Index函数:单个区间内的偏移索引计算
((bytes + (1 << align_shift) - 1) >> align_shift) - 1关键参数说明:
bytes:当前区间内需要计算索引的内存大小(已根据区间做过范围调整,比如第二个区间会用bytes-128)。align_shift:对齐粒度的 “幂次”(因为对齐数都是 2 的幂,比如 8=2³,所以align_shift=3)。
1 << align_shift等价于 “当前区间的对齐数”(比如align_shift=3时,1<<3=8)。
公式拆解(以 “8 字节对齐,align_shift=3” 为例):
假设在第一个区间(bytes<=128,8 字节对齐),我们要计算bytes=9对应的局部索引:
- 计算
1 << align_shift:即对齐数,1<<3=8。 - 计算
bytes + (1 << align_shift) - 1:
即9 + 8 - 1 = 16。这一步和_RoundUp的逻辑类似,是对bytes做 “向上对齐到对齐数” 的预处理(9 对齐到 8 的倍数是 16)。 - 计算
>> align_shift:右移 3 位(等价于除以 8),16 >> 3 = 2。这一步得到 “对齐后的大小是对齐数的多少倍”(16 是 8 的 2 倍)。 - 最后减 1:
2 - 1 = 1。得到该bytes在当前区间内的局部偏移索引。
Index函数:全局索引拼接
Index函数的作用是将 “局部偏移索引” 转换为全局的FreeList索引(因为整个内存池有 208 个FreeList,分属不同区间)。
核心逻辑:
- 区间划分:将
MAX_BYTES(256KB)按对齐粒度分为 5 个区间(和RoundUp的对齐规则对应)。 - 局部索引计算:在每个区间内用
_Index计算局部偏移索引。 - 全局索引拼接:加上 “前面所有区间的
FreeList数量”,得到最终的全局索引。
8. 高并发内存池 -- central cache
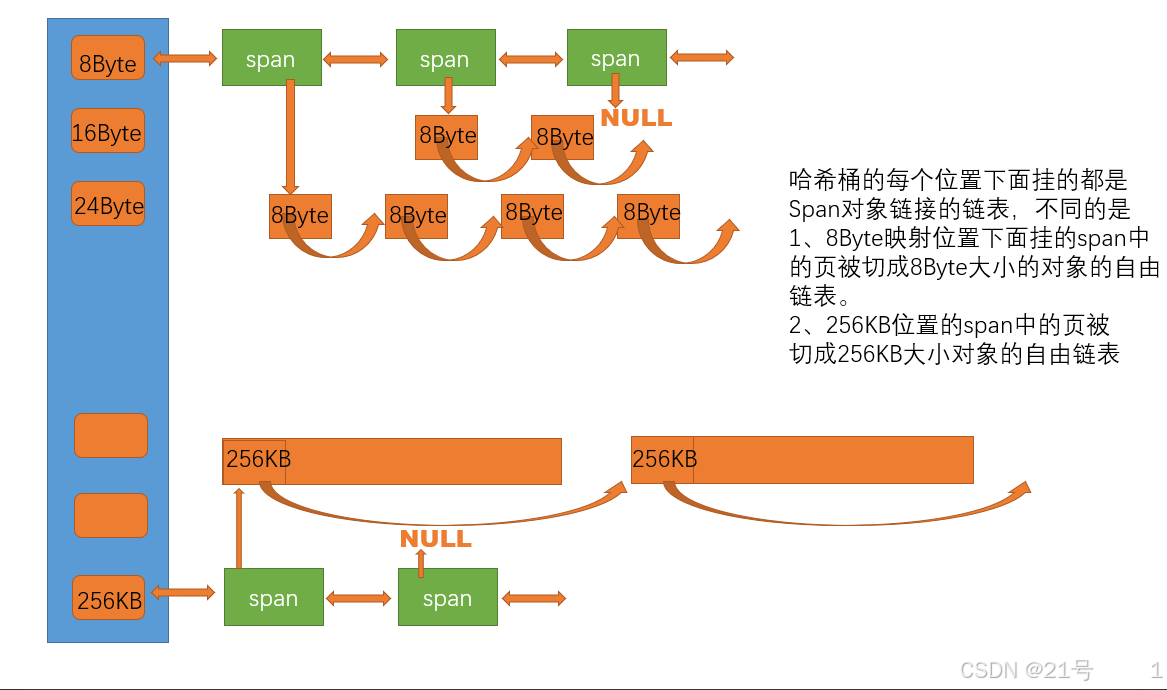
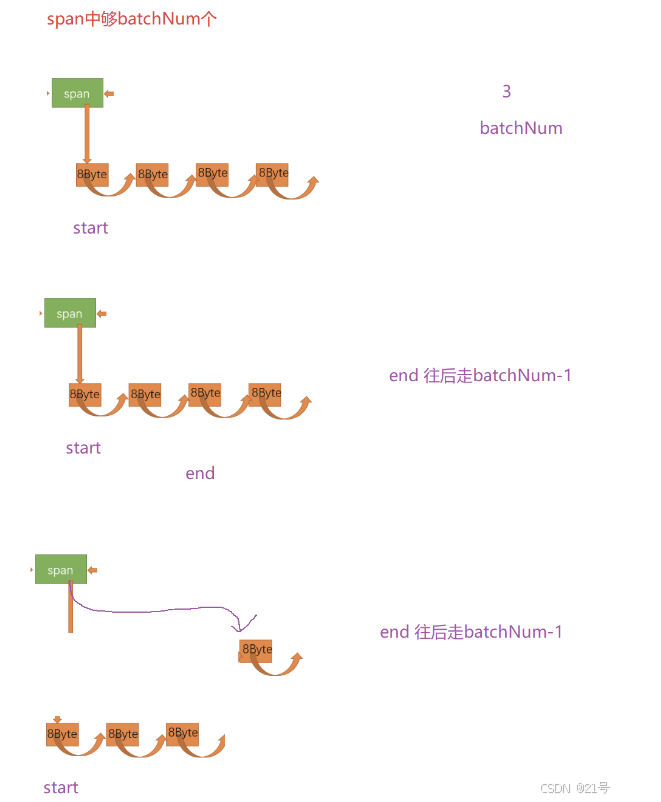
申请内存:
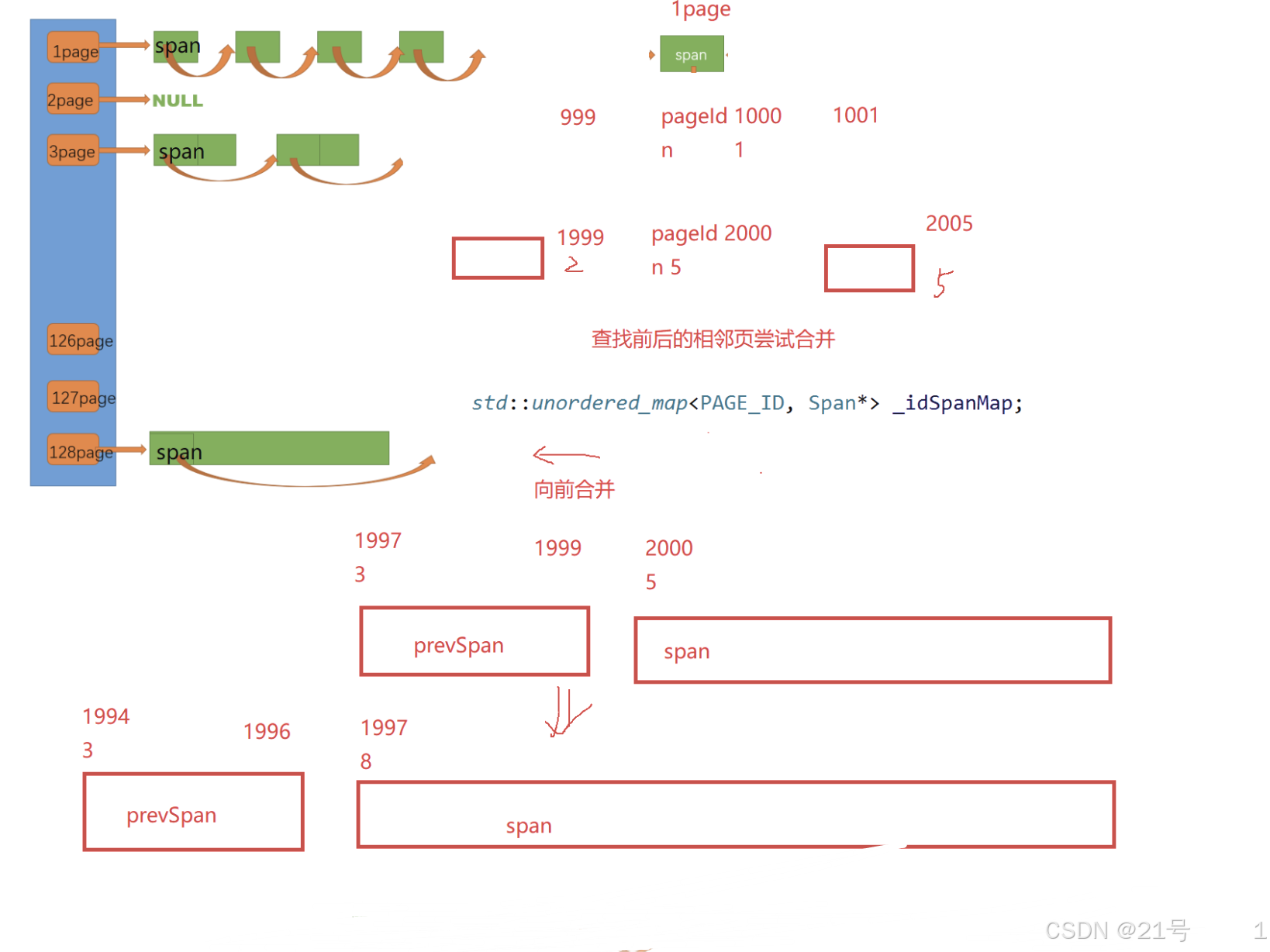
CentralCache.h
CentralCache.cpp
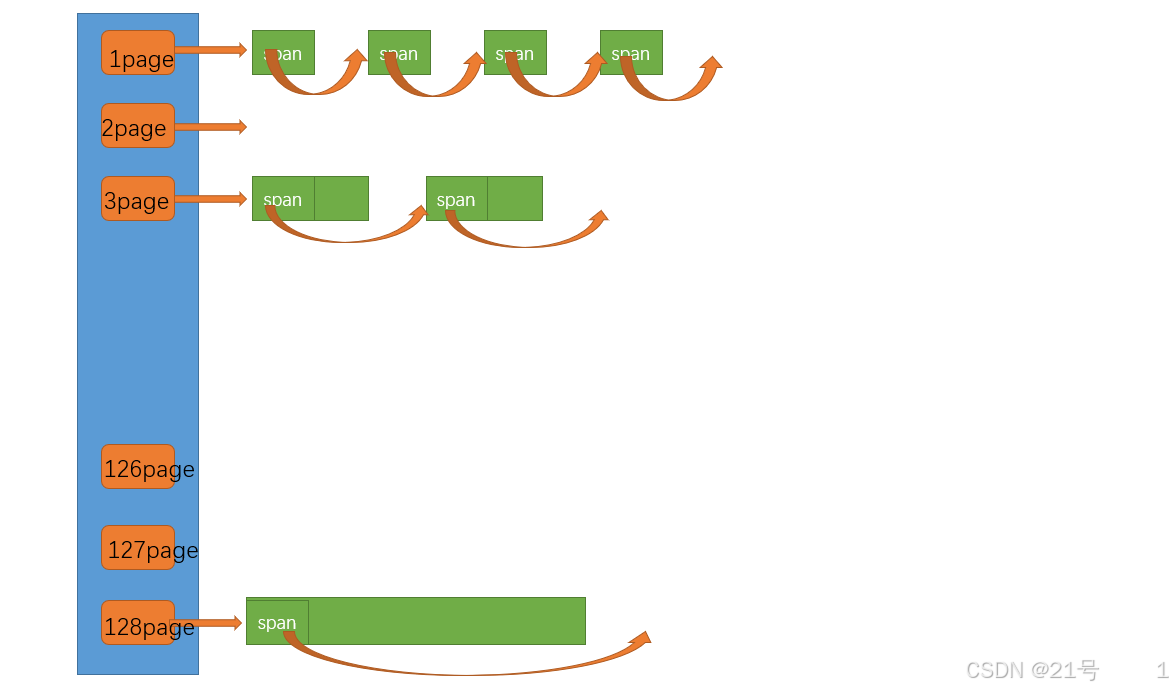
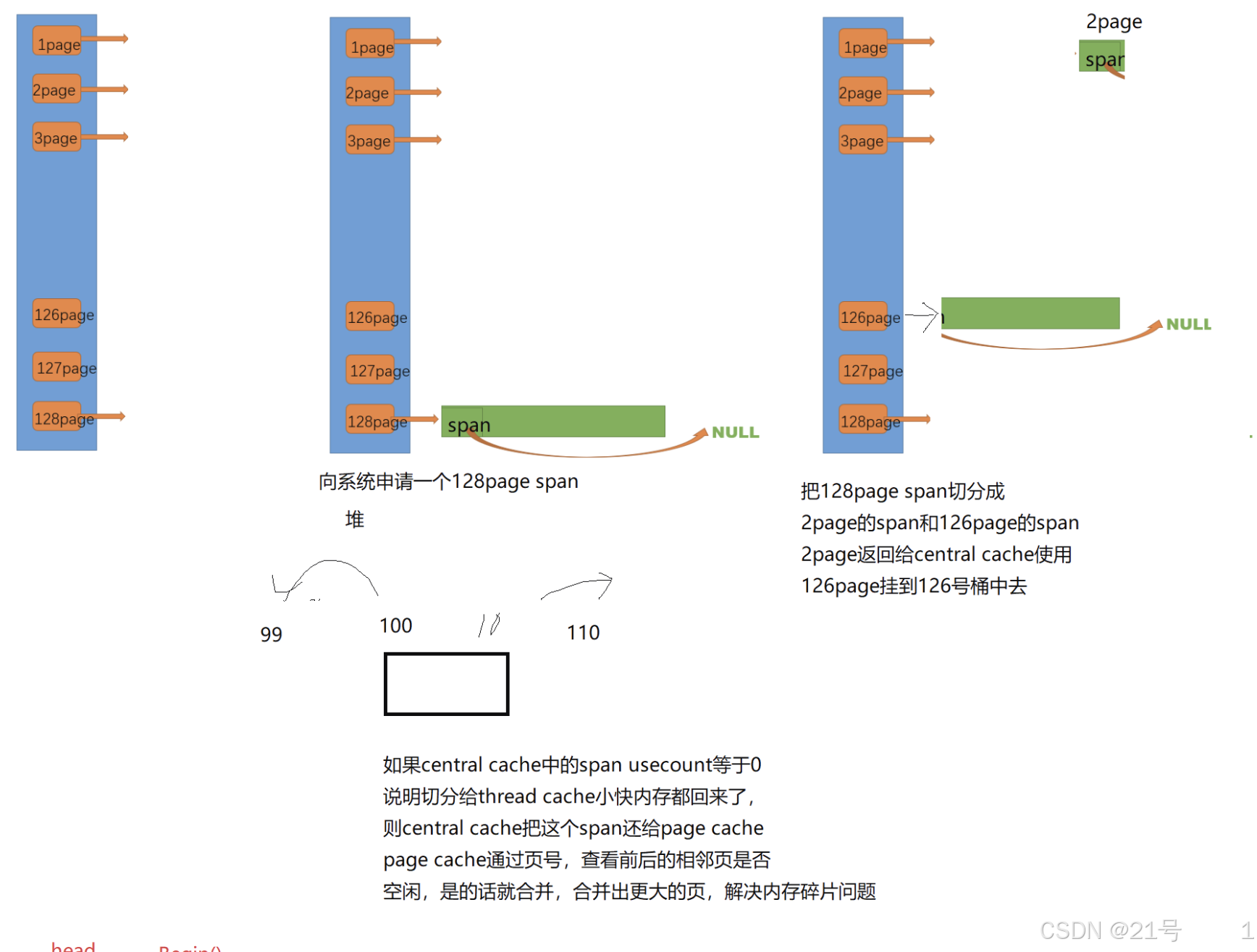
9. 高并发内存池 -- page cache
锁的设计遵循 “成本 - 收益” 原则
| 维度 | CentralCache 的锁 |
PageCache 的锁 |
|---|---|---|
| 粒度 | 细粒度(每个 SpanList 一把锁) |
粗粒度(全局一把锁) |
| 竞争频率 | 低(不同大小内存分配并行) | 较高(但访问频率低) |
| 实现复杂度 | 较高(需管理多把锁) | 低(单锁易于维护) |
| 适用场景 | 高频访问,需最大化并发 | 低频访问,需保证操作安全性 |
PageCache.h
PageCache.cpp

10. 内存分配释放接口:
ConcurrentAlloc.h


11.映射结构

二级基数树

三级基数树

PageMap.h

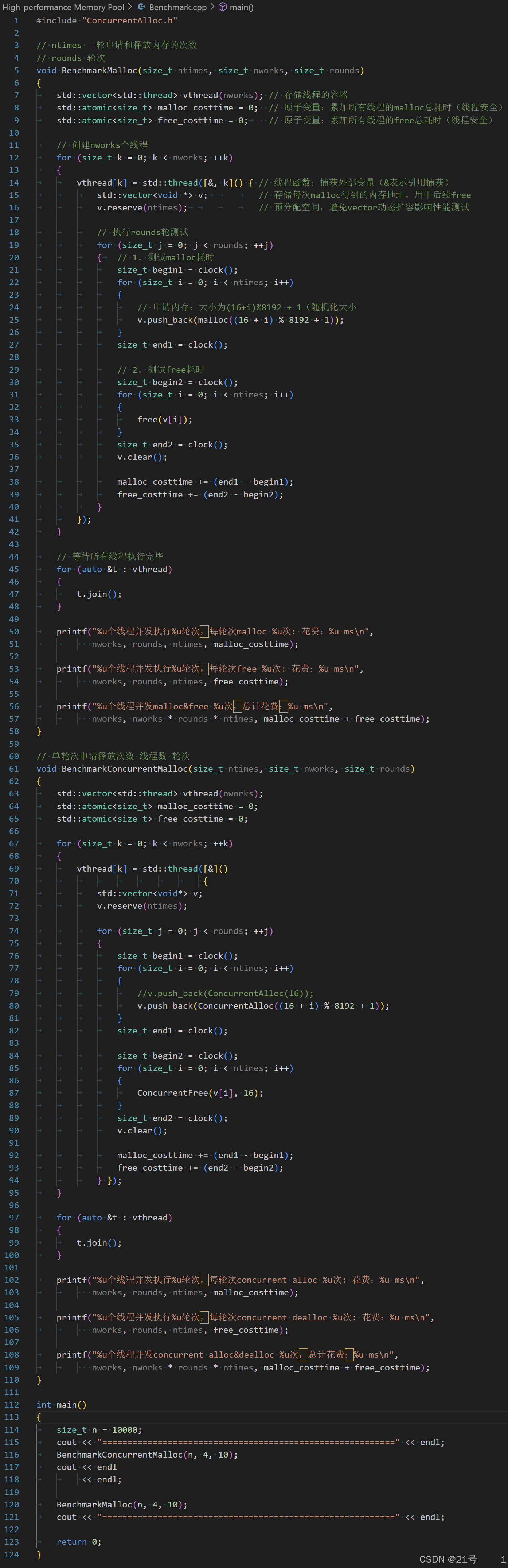
12.测试代码
Benchmark.cpp