Text4Seg++: Advancing Image Segmentation via Generative Language Modeling
Authors: Mengcheng Lan, Chaofeng Chen, Jiaxing Xu, Zongrui Li, Yiping Ke, Xudong Jiang, Yingchen Yu, Yunqing Zhao, Song Bai
Deep-Dive Summary:
多模态大语言模型(MLLMs)图像分割研究综述
引言
多模态大语言模型(MLLMs)通过将强大的大语言模型(LLMs)能力扩展到视觉领域,显著提升了基于自然语言的视觉交互与推理能力。MLLMs在图像生成、目标检测和语义分割等视觉任务中得到广泛应用。然而,将MLLMs无缝整合到这些任务中,特别是在语义分割方面,仍面临挑战。本文提出了一种新颖的“文本即掩码”范式,将图像分割转化为文本生成问题,简化了分割过程,并通过创新的语义描述符提升了性能。

相关工作
多模态大语言模型
MLLMs通过增强大语言模型的视觉感知模块,能够处理多模态输入并生成连贯的文本对话。例如,Flamingo引入感知重采样器,连接预训练视觉编码器与LLMs,实现高效的少样本学习;LLaVA系列则通过线性层或MLP作为模态连接器,结合多模态指令数据进行训练。尽管在视觉问答、文档理解等任务中表现出色,MLLMs在密集预测任务(如图像分割)中的能力仍有限。
MLLMs在视觉分割中的应用
- 判别式模型:通过附加特定任务模块(如掩码解码器),MLLMs能够支持图像分割。例如,LISA等模型通过生成标记并结合视觉特征生成分割掩码。然而,这种方法需要额外的损失函数和架构修改,增加了训练复杂性。
- 生成式模型:HiMTok和ALTo通过生成离散掩码标记实现分割,但直接预测多边形坐标的模型常因难以关联几何表示与精确形状而性能受限。
视觉定位
视觉定位任务通过自然语言指令定位图像中的特定目标。传统方法将此视为检测问题,而Kosmos-2等MLLMs通过量化边界框实现更灵活的定位。本文通过结合边界框与语义掩码,提供更细粒度的视觉-语言对齐。
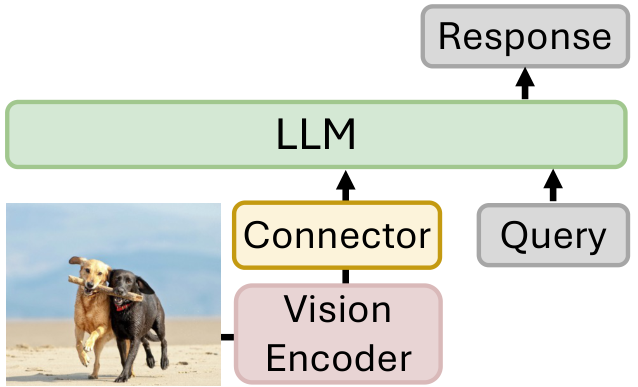
方法
图像级语义描述符(I-SD)
受视觉变换器(ViT)启发,I-SD将图像分割为16×16的网格,每个网格对应一个语义描述符(如“天空”或“棕色狗”),形成长度为256的文本序列。其优点包括:
- 与LLMs的下一标记预测范式无缝整合;
- 无需修改MLLM架构,易于扩展;
- 充分利用LLMs的文本生成能力。
然而,I-SD存在冗余描述导致序列过长的问题。为此,提出行向游程编码(R-RLE),将每行重复描述符压缩,平均序列长度从583减至154,推理速度提升3倍,且性能无损。
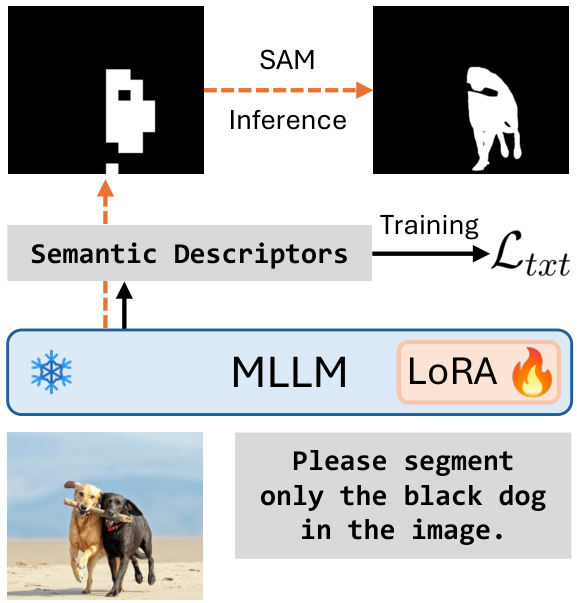
Text4Seg架构
Text4Seg无需架构修改即可整合到MLLMs中,通过低秩适配(LoRA)在视觉指令数据上进行微调,采用自回归训练目标。推理时,可选择SAM作为掩码精炼器以提升像素级分割精度。
框级语义描述符(B-SD)
为解决I-SD的局限性(如冗余描述和背景标记主导),提出B-SD,将分割分为视觉定位和分割两步。B-SD使用边界框定位感兴趣区域,并通过语义描述符生成掩码,格式为:

其核心组件包括:
<ref>...</ref>:语义标签或上下文相关标识;<box>...</box>:量化后的边界框坐标;<seg>...</seg>:简洁的掩码描述符。
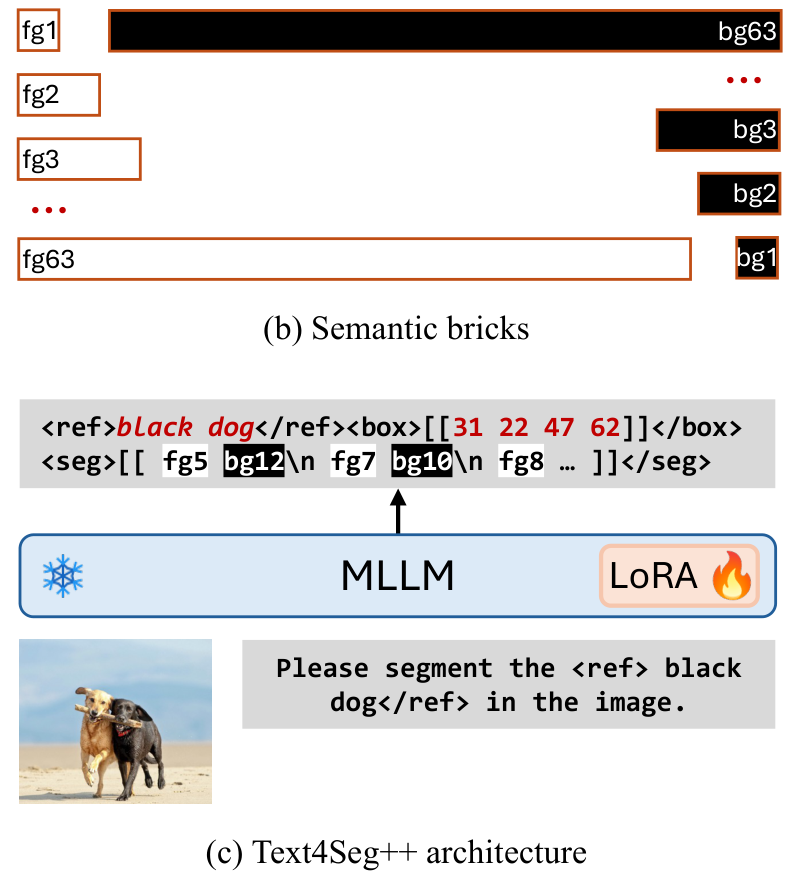
下一砖块预测
为进一步压缩序列,引入“语义砖块”,包含63个前景和63个背景标记,每个砖块编码二进制掩码片段。通过逐砖块预测,B-SD在64×64分辨率下平均序列长度降至150.4,显著提高效率。
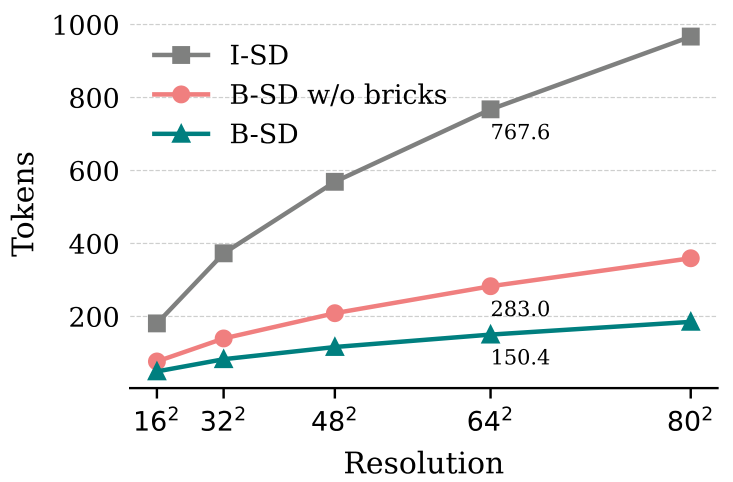
Text4Seg++架构
Text4Seg++通过生成高分辨率B-SD,保持架构简洁并支持高分辨率输入。采用Qwen2-VL-7B等模型,通过LoRA进行后训练,确保高效的视觉编码和文本解码。

实验
Text4Seg++在自然和遥感数据集上无需任务特定微调即可超越现有模型,展示出高效性、灵活性和鲁棒性。其与Qwen2-VL等MLLM骨干的兼容性进一步验证了其通用性。
结论
本文提出的Text4Seg和Text4Seg++通过文本即掩码范式革新了图像分割,I-SD和B-SD分别提供全局和区域级表示,结合R-RLE和语义砖块显著提升效率和精度。Text4Seg++作为统一框架,支持多样化的视觉任务,展现了生成式语言建模在密集预测任务中的潜力。
A. 实验设置
- 实现细节:
我们的方法旨在无缝集成到现有的多模态大语言模型(MLLM)架构中。对于Text4Seg,我们采用InternVL2-8B [6]和LLaVA-1.5-13B [4]作为基础模型。对于Text4Seg++,我们使用Qwen2-VL-7B [27],该模型原生支持动态输入分辨率并展现出更高的优化效率。在实验中,所有MLLM架构保持不变。此外,我们可选地引入SAMRefiner [67],其使用ViT-H骨干作为现成的掩码精炼模块。
我们的方法基于SWIFT框架 [68]实现。Text4Seg++在8个NVIDIA H100 GPU上训练,全局批次大小为128。我们使用AdamW优化器 [69],初始学习率为 2 × 1 0 − 4 2 \times 10^{-4} 2×10−4,在预热阶段(比例为0.03)后遵循线性衰减调度。权重衰减设为0,梯度范数裁剪为1.0。为最小化GPU内存使用量,我们使用LoRA(秩为128)对所有模型进行微调,并结合ZeRO-1阶段内存优化 [70]。
- 评估协议:
我们采用一组全面的指标来评估方法的有效性:
- cIoU(累积交并比) [71]:计算所有样本的累积交集与并集之比,该指标倾向于较大物体,通过全局聚合像素级重叠。
- gIoU(广义交并比) [72]:计算所有样本的每张图像平均IoU。对于无目标情况,真阳性预测分配IoU为1,假阴性分配为0,提供对大小物体的平衡评估。
- mIoU(平均交并比):与gIoU类似,计算数据集的每张图像平均IoU。
- ACC@0.5:预测与真实边界框IoU在0.5阈值的准确率,反映参照表达式理解能力。
- 准确率:测量模型在视觉问答任务中的答案正确性,评估多模态理解和推理能力。
这些多样化指标为视觉分割定位和理解提供了全面评估。
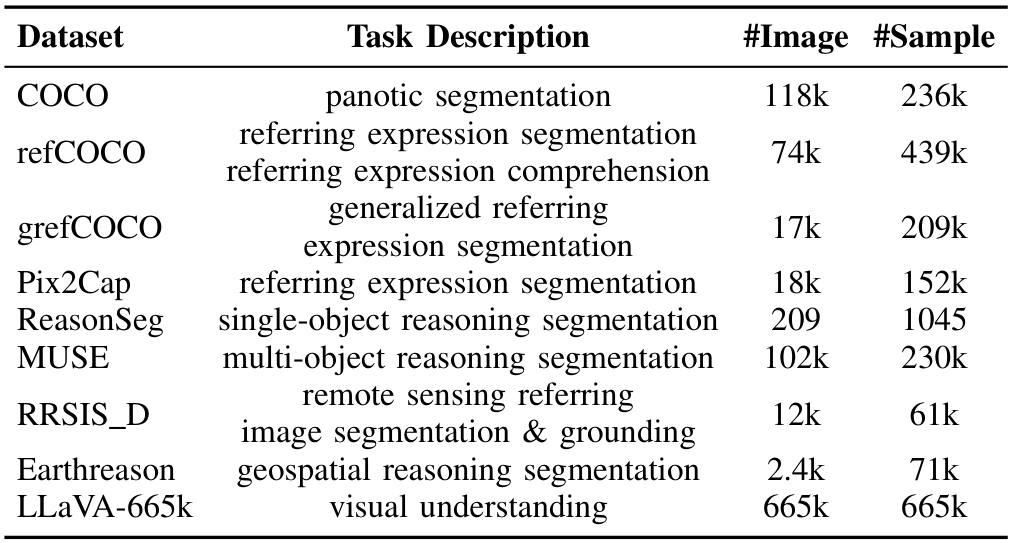
B. 数据集
遵循多模态图像分割的先前工作 [15], [17], [20],我们使用多样化的数据集集合训练Text4Seg++,具体通过第III-C节介绍的方法构建训练数据,包括以下数据集:
- COCO Panoptic Segmentation [79]:一个全面的分割数据集,包含80个物体类别(例如狗、猫)和91个背景类别(例如草地、天空)。我们使用包含约118,000张图像的训练集。
- refCOCO系列:包括多个单物体参照表达式分割数据集:RefCLEF、RefCOCO、RefCOCO+ [64]和RefCOCOg [73],我们使用所有数据集的训练集。
- grefCOCO [72]:一个广义参照表达式分割数据集,适用于多物体和无目标分割任务,包含278k个表达式,其中80k为多目标,32k为无目标。
- Pix2Cap [80]:包含167,254个描述,我们将每个掩码对应的描述视为参照表达式,使用包含18,212张图像的训练集。
- ReasonSeg [15]:一个单目标推理分割数据集,包含1,218个图像-指令-掩码样本,分为239个训练、200个验证和779个测试样本。
- MUsE [19]:一个多目标推理分割数据集,包含246,000个问答对,平均每个答案有3.7个目标,分为239k训练、2.8k验证和4.3k测试样本。
- RRSIS_D [81]:一个大规模遥感参照图像分割数据集,包含17,402个图像-掩码-表达式三元组,图像分辨率为800×800像素。
- Earthreason [48]:一个地理空间像素级推理数据集,评估复杂现实世界遥感场景,包含5,434个手动标注的图像-掩码对和超过30,000个隐式问答对,覆盖28个场景类别。
- LLaVA-665k [4]:一个视觉指令跟随数据集,包含665k个多模态样本,旨在增强视觉-语言推理能力。
我们在表I中总结了训练数据的统计信息。为实现通用图像分割框架,我们在统一基准上训练Text4Seg++ 50k步,并在多样化下游任务上评估其性能,无需任务特定微调。
C. 主要结果
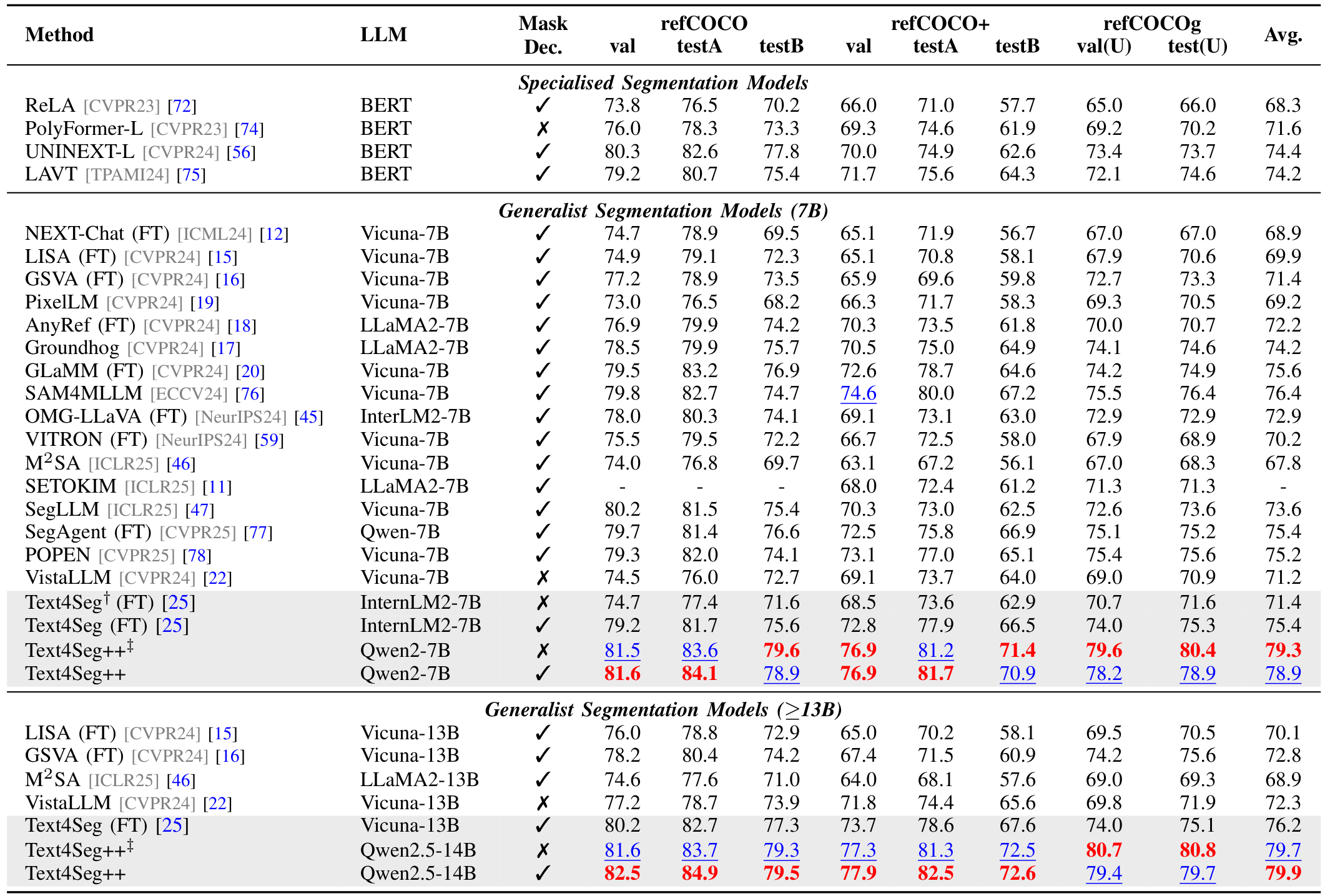
- 参照表达式分割:
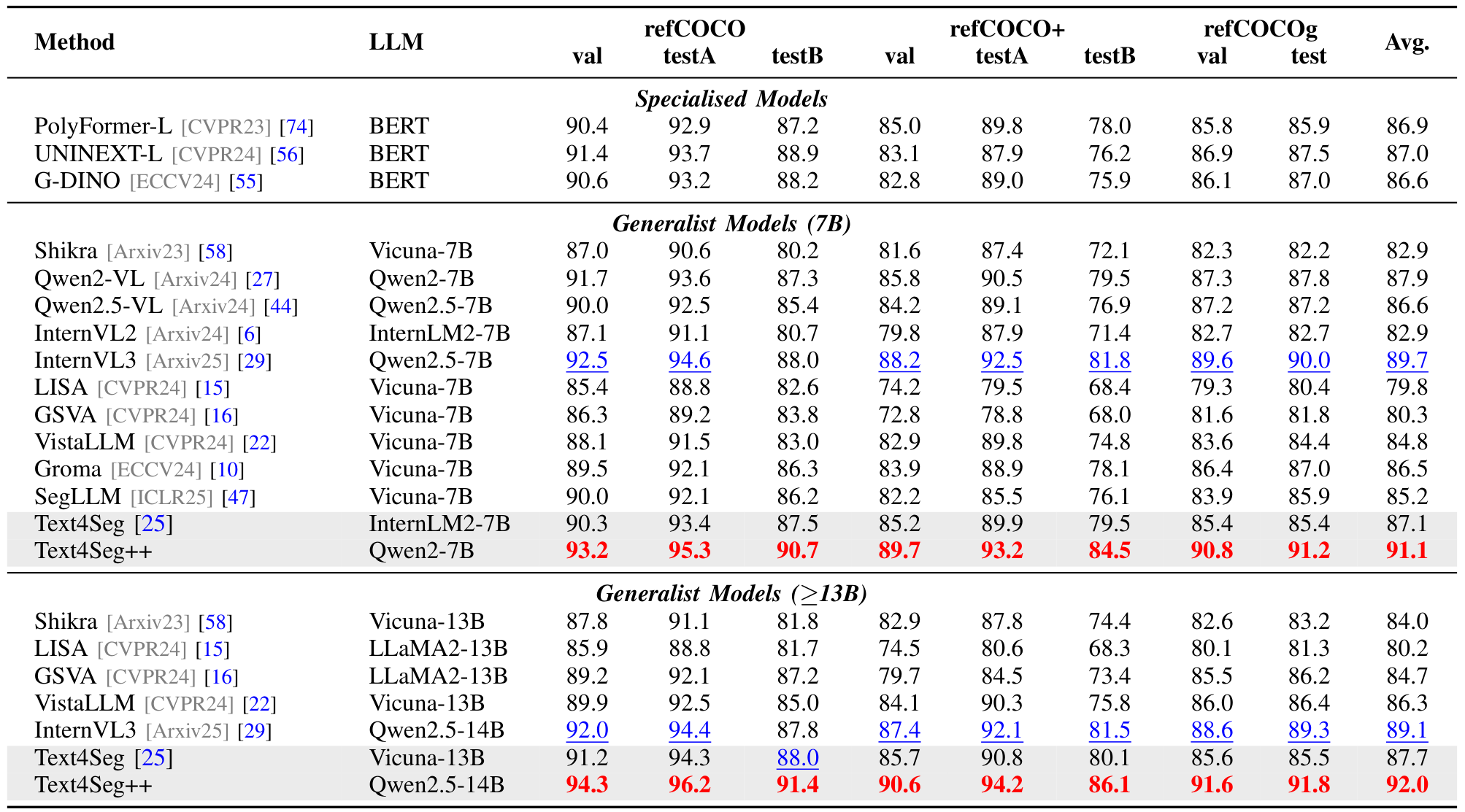
我们在RefCOCO系列基准上对方法进行全面评估,结果见表II。在7B规模的带掩码解码器的判别模型中,GLaMM平均cIoU为75.6,POPEN(利用偏好优化)为75.2,SAM4MLLM在7个单独拆分中的5个上获得次佳性能。在7B规模的无掩码解码器的生成模型中,Text4Seg平均cIoU为71.4,略优于生成多边形坐标的VistaLLM(71.2)。Text4Seg++在无掩码精炼的情况下,平均cIoU达79.3,比次佳模型(76.4)高近3个百分点,在所有8个评估拆分中均表现最佳,确立了新的技术前沿。在13B规模,Text4Seg++和Text4Seg分别达到79.7和76.2 cIoU,显著超越其他竞争模型,凸显了文本作为掩码框架的有效性和可扩展性。
![TABLEIVREASONINGSEGMENTATIONRESULTSONTHEREASONSEG[15]BENCHMARK.](https://i-blog.csdnimg.cn/img_convert/faa937cb4ca137c9fadf52a790499e5a.png)
![TABLEVMULTI-TARGETREASONINGSEGMENTATIONRESULTSONTHEMUSE [19] BENCHMARK.](https://i-blog.csdnimg.cn/img_convert/c678383da98c7da3a0c498443938ca62.png)
广义参照表达式分割:
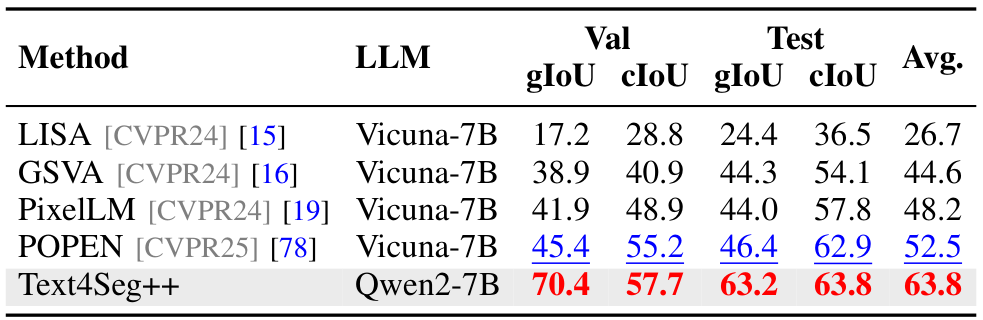
我们在包含多物体和无物体情况的广义参照表达式分割基准上进一步评估,结果见表III。Text4Seg++在7B规模无掩码精炼时平均得分为69.8,优于GSVA(65.6)4个百分点以上。当配备掩码精炼并针对该基准微调时,Text4Seg平均得分为71.1,超越Text4Seg++。在13B规模,Text4Seg平均得分为71.5,领先GSVA 4.9个百分点。这些结果展示了Text4Seg和Text4Seg++在处理复杂分割场景的鲁棒性和多功能性。推理分割:
我们在ReasonSeg [15]和MUsE [19]两个推理分割基准上评估Text4Seg++的会话图像分割能力。Text4Seg++配备SAMRefiner作为后处理掩码精炼器。在ReasonSeg上,Text4Seg++平均得分为54.5,显著优于SegLLM(53.1),但略低于Seg-Zero(56.2)。在MUsE上,Text4Seg++平均得分为63.8,比最佳基线POPEN(52.5)高11.3个百分点,远超早期模型如LISA(26.7)等,展现了卓越的推理能力和分割精度。
![TABLEVIIIGEOSPATIAL PIXEL REASONING RESULTS ON THE EARTHREASON [48]BENCHMARK.](https://i-blog.csdnimg.cn/img_convert/299884d0ac5b60b88588b79af698eae6.png)
开放词汇分割:
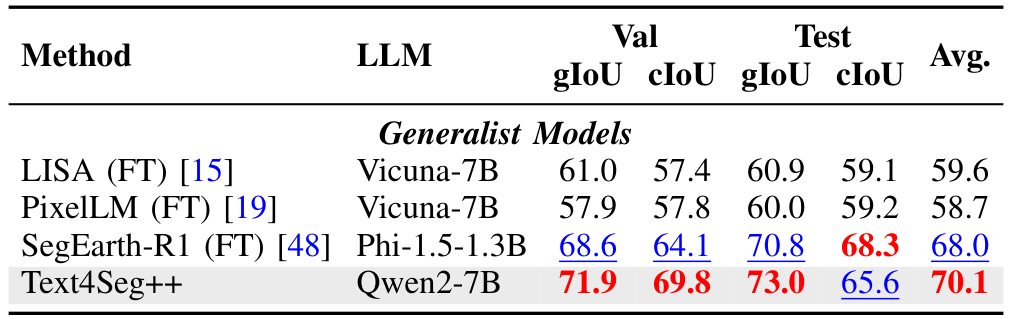
我们在ADE20K、PASCAL Context 59和PASCAL VOC 20数据集上评估Text4Seg的开放词汇分割性能,使用mIoU作为指标。Text4Seg在PC-59基准上表现具有竞争力,优于使用额外解码器的LaSagnA,展现了其在开放词汇分割中的潜力。遥感图像分割扩展:
我们在RRSIS-D [81]和EarthReason [48]两个遥感分割基准上评估Text4Seg++的泛化能力。在RRSIS-D上,Text4Seg++平均得分为70.8,接近最佳专用模型SegEarth-R1(74.4)。在EarthReason上,Text4Seg++以70.1的平均得分创下新纪录,超越SegEarth-R1(68.0),凸显了其跨领域的可扩展性和鲁棒推理能力。参照表达式理解:
Text4Seg++利用基于框的语义描述符统一视觉定位和分割。在RefCOCO基准上,Text4Seg++在7B规模的Acc@0.5平均值为91.1,优于InternVL3(89.7),在13B规模进一步提升至92.0,显著优于其他模型,展示了其高精度的空间理解能力。

- 视觉理解:
我们的文本作为掩码范式将分割任务无缝集成到MLLM预训练中。Text4Seg在LLaVA-1.5-7B基础上训练,结合LLaVA-v1.5-mix665k和参照分割数据集,在视觉问答和RES基准上表现与LLaVA-1.5相当,验证了其在不牺牲对话能力的情况下增强分割功能。
D. 可视化分析
我们在图9和图10中展示了Text4Seg与GSVA在不同分割场景的定性比较。在单物体RES任务中,Text4Seg生成更准确的分割图。在GRES任务中,Text4Seg避免了GSVA的空物体错误分割问题。Text4Seg++在图11中展示了跨视觉-语言任务的泛化能力,准确分割ReasonSeg和MUsE中的复杂区域,以及遥感数据集中的高分辨率航拍图像,验证了其多功能性和鲁棒性。
![Fig. 9: Qualitative results of Text4Seg and GSVA [16] on the RES task. Thecorresponding referring expressions are displayed in the bottom.](https://i-blog.csdnimg.cn/img_convert/e4c65e4759ecd561b7e468dbc4d116cc.png)


E. 消融研究与分析
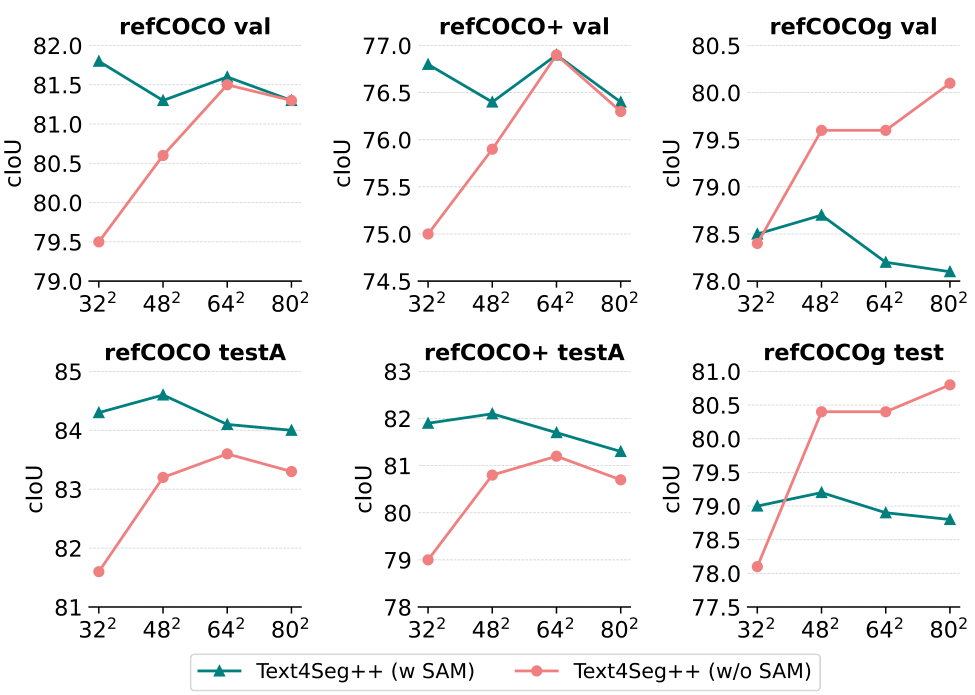
- 语义描述符分辨率:
我们评估了从32×32到80×80不同分辨率的基于框的语义描述符对分割性能的影响。图12显示,高分辨率描述符生成更精细的分割输出,64×64分辨率已接近SAM精炼效果,兼顾性能与序列长度。

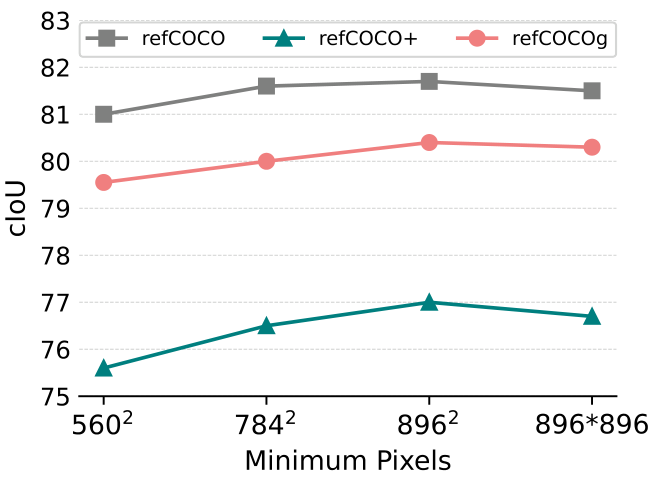
- 输入图像分辨率:
Text4Seg++通过视觉-语言建模进行分割,输入分辨率直接影响细节感知。图14显示,分辨率从 56 0 2 560^2 5602提高到 89 6 2 896^2 8962时,cIoU显著提升,784^2为默认分辨率,平衡空间保真度和计算效率。
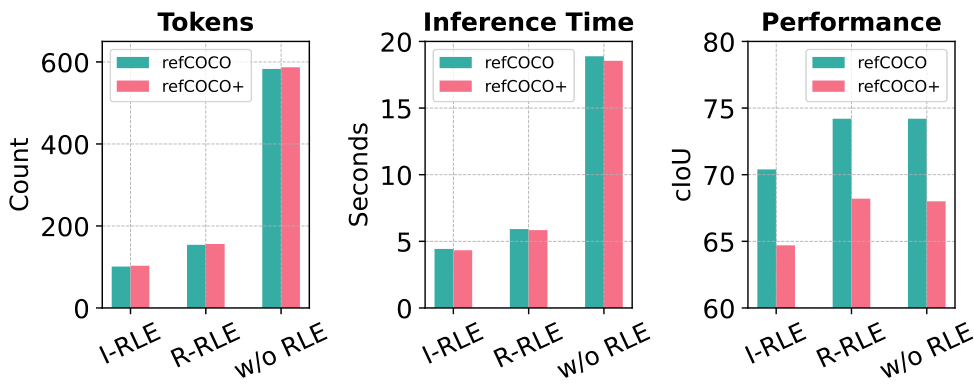
- I-RLE vs. R-RLE:
我们比较了16×16分辨率下不同编码方法。图15显示,R-RLE在减少74%描述符长度和提高3倍推理速度的同时,保持几乎相同的性能,优于I-RLE。

- 语义砖块消融研究:
表XI显示,移除语义砖块(SB)对性能影响较小,但在refCOCO+和refCOCOg上略有下降。语义砖块显著减少序列长度,支持更高分辨率(64×64)分割并加速训练和推理。
V. 讨论
A. 结论
我们提出了文本作为掩码的范式,将图像分割重塑为MLLM中的文本生成问题,消除了额外解码器的需求。Text4Seg通过图像级语义描述符和行式运行长度编码(R-RLE)实现高效分割。Text4Seg++引入基于框的语义描述符和下一砖块预测,显著提升分割精度和效率。广泛实验表明,Text4Seg++在参照表达式、推理和遥感分割等任务中超越现有技术前沿,展现出卓越的多功能性和鲁棒性。
B. 未来工作与广泛影响
文本作为掩码范式为将精细视觉理解集成到大规模视觉-语言模型提供了新方向,未来可进一步探索其在更多任务中的应用。
Original Abstract: Multimodal Large Language Models (MLLMs) have shown exceptional capabilities
in vision-language tasks. However, effectively integrating image segmentation
into these models remains a significant challenge. In this work, we propose a
novel text-as-mask paradigm that casts image segmentation as a text generation
problem, eliminating the need for additional decoders and significantly
simplifying the segmentation process. Our key innovation is semantic
descriptors, a new textual representation of segmentation masks where each
image patch is mapped to its corresponding text label. We first introduce
image-wise semantic descriptors, a patch-aligned textual representation of
segmentation masks that integrates naturally into the language modeling
pipeline. To enhance efficiency, we introduce the Row-wise Run-Length Encoding
(R-RLE), which compresses redundant text sequences, reducing the length of
semantic descriptors by 74% and accelerating inference by 3 × 3\times 3×, without
compromising performance. Building upon this, our initial framework Text4Seg
achieves strong segmentation performance across a wide range of vision tasks.
To further improve granularity and compactness, we propose box-wise semantic
descriptors, which localizes regions of interest using bounding boxes and
represents region masks via structured mask tokens called semantic bricks. This
leads to our refined model, Text4Seg++, which formulates segmentation as a
next-brick prediction task, combining precision, scalability, and generative
efficiency. Comprehensive experiments on natural and remote sensing datasets
show that Text4Seg++ consistently outperforms state-of-the-art models across
diverse benchmarks without any task-specific fine-tuning, while remaining
compatible with existing MLLM backbones. Our work highlights the effectiveness,
scalability, and generalizability of text-driven image segmentation within the
MLLM framework.
PDF Link: 2509.06321v1
部分平台可能图片显示异常,请以我的博客内容为准
