目录:
-
- 1. synchronized 和 ReentrantLock 的区别及应用场景
- 2. HashMap 与 LinkedHashMap 的区别
- 3. ConcurrentHashMap 的数据结构及 JDK1.7 与 JDK1.8 区别
- 4. Spring 常用的模式及应用场景
- 5. 事务的四大特性(ACID)
- 6. 锁机制:行级锁与游标锁
- 7. 索引的种类与使用场景
- 8. 慢 SQL 优化
- 9. Git 常用命令与解决冲突
- 10. 如何保证线程安全
- 11. MySQL 存储引擎
- 12. Redis 如何使用及应用场景
- 13. Redis 缓存穿透、击穿、雪崩有什么区别?如何解决?
- 14. 你能介绍一下你日常开发一个需求的全流程吗
- 15.你能简单介绍一下你常用的 Spring Cloud 微服务组件吗?
- 16. 反问问题
1. synchronized 和 ReentrantLock 的区别及应用场景
(1) 实现机制
- synchronized:Java 内置关键字,依赖 JVM 监视器锁(Monitor),隐式加锁/解锁,不可中断。
- ReentrantLock:显式锁(需手动调用 lock()/unlock()),支持尝试锁(tryLock)、超时、公平锁(构造函数指定)、条件变量(Condition)。
(2) 灵活性
- synchronized 简单但功能有限;ReentrantLock 更灵活,支持复杂场景(如定时锁、中断响应)。
性能 - JDK 1.6+ 后 synchronized 性能优化(偏向锁、轻量级锁),高竞争下 ReentrantLock 可能更优。
(3)应用场景:
- synchronized:简单同步需求(如单例模式、小临界区)。
- ReentrantLock:需要公平锁、超时控制或复杂条件变量的场景(如线程池任务调度、高并发资源竞争)。
2. HashMap 与 LinkedHashMap 的区别
(1) 数据结构
- HashMap:基于哈希表实现,无序。
- LinkedHashMap:继承自 HashMap,通过双向链表维护插入顺序或访问顺序(LRU 缓存)。
(2)应用场景
- HashMap:常规键值对存储,无需顺序控制。
- LinkedHashMap:需遍历顺序与插入/访问顺序一致(如缓存、历史记录)。
3. ConcurrentHashMap 的数据结构及 JDK1.7 与 JDK1.8 区别
JDK 1.7
- 分段锁(Segment):将数据分为多个 Segment,每个 Segment 独立加锁,提升并发度(默认 16 个 Segment)。
- 数据结构:数组 + 链表。
JDK 1.8
- CAS + synchronized:使用 CAS(无锁操作)和 synchronized(锁单个链表头节点),减少锁粒度。
- 红黑树优化:链表长度超过阈值(默认 8)时转为红黑树,查询时间从 O(n) 降为 O(log n)。
核心改进:减少内存开销,提升高并发性能。
4. Spring 常用的模式及应用场景

Spring 各模块中设计模式的体现
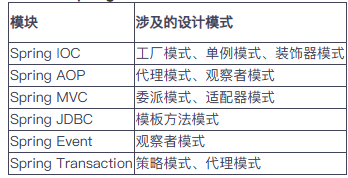
我在项目中使用过 Spring 的代理模式(AOP)实现日志记录和权限控制,使用模板方法模式封装通用数据库操作,使用观察者模式实现业务事件通知。这些设计模式提升了代码的可维护性和扩展性。
5. 事务的四大特性(ACID)
- 原子性(Atomicity):事务内操作要么全成功,要么全失败回滚。
- 一致性(Consistency):事务执行前后,数据库完整性约束不变(如外键约束)。
- 隔离性(Isolation):多个事务并发执行时,相互隔离(隔离级别:读未提交、读已提交、可重复读、串行化)。
- 持久性(Durability):事务提交后,修改永久保存到数据库。
6. 锁机制:行级锁与游标锁
- 行级锁
锁定特定行(如 MySQL InnoDB 的 SELECT … FOR UPDATE),减少锁冲突,提升并发。 - 游标锁(悲观锁)
在读取数据时锁定整个结果集(如 SQL Server 的 HOLDLOCK),防止其他事务修改,适用于高写入冲突场景。
7. 索引的种类与使用场景
1. 种类
- B+ 树索引:默认索引类型,适用于范围查询(如 WHERE id > 100)。
- 哈希索引:仅支持等值查询(如 Redis、Memory 引擎)。
- 全文索引:文本模糊匹配(如 MATCH() AGAINST())。
- 组合索引:多列联合索引(遵循最左前缀原则)。
2. 使用场景
- 主键索引:唯一标识记录。
- 唯一索引:防止重复值(如用户名)。
- 组合索引:优化多条件查询(如 WHERE name=‘A’ AND age=20)。
8. 慢 SQL 优化
- 分析工具:EXPLAIN 查看执行计划,定位全表扫描或临时表。
EXPLAIN SELECT * FROM your_table WHERE your_condition;
判断哪些索引是无效的?
(1)使用 EXPLAIN 分析执行计划
EXPLAIN SELECT * FROM orders WHERE customer_id = 123;
查看 EXPLAIN 的输出,重点关注以下字段:

(2) 看索引是否被使用(可通过慢查询日志 + EXPLAIN 分析)
启用慢查询日志,找出执行时间长的 SQL。
对这些 SQL 执行 EXPLAIN,看是否使用了索引。
如果未使用索引,可能是索引失效或设计不合理。
(3)常见导致索引失效的 SQL 写法
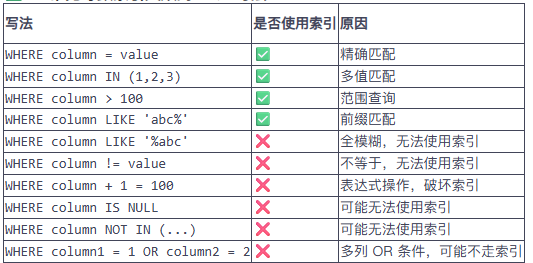
判断哪些索引是有效的?
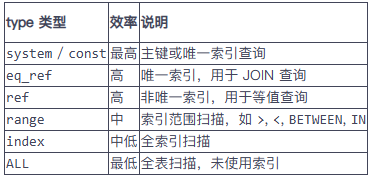
(1) 看 EXPLAIN 的 type 类型
(2) 看 rows 字段
rows 表示 MySQL 估计需要扫描的行数。
越小越好。
如果 rows 很大,说明索引可能不够高效。
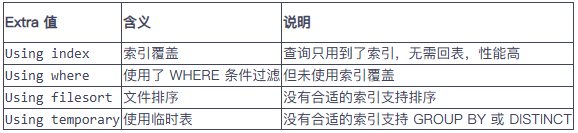
(3) 看 Extra 字段
优化策略**
(1) 添加索引(避免在低选择性字段建索引)。
(2) 避免 SELECT *,只查询必要字段。
(3) 分页优化:大分页改用游标分页(如 WHERE id > 1000 LIMIT 10)。
(4) 拆分复杂 SQL(减少子查询嵌套)。
(5) 定期分析表(ANALYZE TABLE 更新统计信息)。
9. Git 常用命令与解决冲突
常用命令
- git clone:克隆仓库。
- git add:添加修改到暂存区。
- git commit:提交本地仓库。
- git push/pull:推送/拉取远程分支。
- git branch:查看分支。
- git merge:合并分支。
- git rebase:变基(避免合并提交)。
解决冲突 - git pull 或 merge 时标记冲突文件。
- 手动编辑文件,删除冲突标记(<<<<<<<, =======, >>>>>>>)。
- git add <文件> 标记冲突已解决。
- git commit 提交最终版本。
10. 如何保证线程安全
- 同步机制,使用 synchronized 或 ReentrantLock 控制临界区访问。
- 原子类:AtomicInteger、AtomicReference(CAS 操作)。
- 线程本地变量:ThreadLocal 存储线程私有数据(如用户会话)。
- 并发工具类:ConcurrentHashMap、CopyOnWriteArrayList。
- volatile:保证变量可见性(适用于状态标志)。
11. MySQL 存储引擎
- InnoDB
支持事务、行级锁、崩溃恢复(默认引擎)。 - MyISAM
高速存储,不支持事务和行锁,适合只读或插入密集场景。 - Memory
数据存储在内存中,速度快,适合临时表。 - Archive
高压缩比,适合归档日志数据。
应用场景
- InnoDB:高并发写入(如订单系统)。
- MyISAM:只读数据(如静态资源表)。
- Memory:临时缓存(如会话统计)。
12. Redis 如何使用及应用场景
Redis 是一个高性能的内存数据库,支持多种数据结构,常用于缓存、分布式锁、计数器、排行榜等场景。在实际项目中,我主要用 Redis 做缓存和计数器。比如在电商系统中,将商品详情缓存到 Redis,设置 5 分钟过期时间;在社交系统中,使用 Redis 统计用户的点赞和评论数,避免频繁写数据库。
典型使用场景包括:
- 缓存:将热点数据缓存到 Redis,减少数据库压力,提升访问速度。
- 分布式锁:使用 SETNX 或 Redlock 实现跨服务的资源互斥访问。
- 计数器:使用 INCR 实现点赞、浏览量、订单号生成等。
- 排行榜:使用 ZSet 实现游戏积分榜、热门文章等。
- 消息队列:使用 List 或 Pub/Sub 实现任务队列或事件通知。
- 限流:使用 INCR + EXPIRE 实现滑动窗口限流,保护后端服务。
- 用户签到:使用 Bitmap 实现签到统计,节省空间。
13. Redis 缓存穿透、击穿、雪崩有什么区别?如何解决?
- 缓存穿透:查询一个既不在缓存也不在数据库中的数据(如非法 ID),导致每次请求都打到数据库。
- 解决:布隆过滤器(Bloom Filter)拦截非法请求;缓存空值并设置短过期时间。
- 缓存击穿:某个热点 key 突然失效,大量并发请求直接打到数据库。
- 解决:设置热点 key 永不过期;使用互斥锁(Mutex)或分布式锁控制重建缓存的并发。
- 缓存雪崩:大量 key 同时过期或 Redis 宕机,导致数据库压力激增。
- 解决:设置过期时间加随机值;使用高可用 Redis 集群;缓存降级、限流熔断。
14. 你能介绍一下你日常开发一个需求的全流程吗
日常开发一个需求的全流程,我理解为:从需求评审 → 技术设计 → 开发实现 → 代码审查 → 测试验证 → 上线部署 → 上线后维护。我会在每个阶段都保持清晰的文档和沟通,确保需求高质量落地。
15.你能简单介绍一下你常用的 Spring Cloud 微服务组件吗?
我常用的 Spring Cloud 微服务组件包括 Eureka/Nacos(服务注册)、Feign(服务调用)、Ribbon(负载均衡)、Hystrix/Sentinel(熔断限流)、Gateway(网关)、Config(配置中心)、Sleuth/Zipkin(链路追踪),它们分别承担了服务注册、通信、容错、统一入口、配置管理、链路监控等职责。
(补充知识)
- 1. Eureka / Nacos(服务注册与发现)
- 功能:服务注册中心,用于微服务之间的服务发现。
- 说明:服务启动后会自动注册到 Eureka 或 Nacos,其他服务可以通过服务名发现并调用目标服务。
区别:Nacos 还支持配置中心功能,适合需要动态配置管理的场景。
- 2. Ribbon(客户端负载均衡)
- 功能:在服务调用时,自动选择一个可用的服务实例,实现负载均衡。
- 使用场景:结合 Feign 使用,支持轮询、随机等策略,实现服务调用的负载均衡。
- 3. Feign(声明式服务调用)
- 功能:简化服务间调用,通过声明式接口实现远程调用。
- 使用场景:服务 A 调用服务 B 的接口时,只需定义一个接口即可完成调用,底层自动集成 Ribbon 实现负载均衡。
- 4. Hystrix(服务熔断与降级)
- 功能:在服务调用失败或超时时,触发熔断机制,返回降级结果,防止雪崩效应。
- 使用场景:保护系统稳定性,避免一个服务故障导致整个系统不可用。
- 注意:Hystrix 已进入维护模式,目前我们项目中使用 Sentinel 替代。
- 5. Zuul / Gateway(API 网关)
- 功能:统一入口、路由转发、权限校验、限流、鉴权等。
- 使用场景:所有外部请求都经过网关进入系统,进行统一的鉴权、限流、日志记录等操作。
- 区别:Zuul 是 Netflix 的网关组件,性能较差;Spring Cloud Gateway 基于 WebFlux,性能更优,是目前主流选择。
- 6. Config(配置中心)
- 功能:集中管理微服务的配置文件,支持不同环境(dev、test、prod)的配置。
- 使用场景:微服务启动时从 Config Server 获取配置,支持动态刷新,避免频繁修改配置文件。
- 7. Sleuth + Zipkin(分布式链路追踪)
- 功能:记录请求链路,分析服务调用耗时,定位性能瓶颈。
- 使用场景:排查慢接口、分析调用链、查看服务依赖关系。
16. 反问问题
- 目前团队的技术栈是怎样的?
- 项目中是否使用了微服务?使用的是 Spring Cloud 还是 Dubbo?
- 这个岗位主要负责哪些模块?是业务开发、中间件维护,还是平台开发?
- 目前团队正在做的项目或产品是什么?主要的业务场景有哪些?