例题1

1、知识点总结
弗林分类法根据指令流和数据流的数量对计算机体系结构进行分类:
| 体系结构 | 指令流 | 数据流 | 描述 | 典型例子 |
|---|---|---|---|---|
| SISD | 单 | 单 | 单处理器体系结构。一次执行一条指令,处理一个数据流。 | 传统的单核CPU |
| SIMD | 单 | 多 | 单指令多数据。一条指令同时作用于多个数据流。 | 向量处理器、GPU |
| MISD | 多 | 单 | 多指令单数据。多个指令同时处理同一个数据流。 | 非常罕见,主要用于容错系统 |
| MIMD | 多 | 多 | 多指令多数据。多个处理器同时执行不同的指令,处理不同的数据流。 | 多计算机系统、多核CPU、集群 |
2、选项分析
A. SISD (单指令单数据) (× 错误)
原因:SISD是传统的单处理器计算机,显然不是多计算机系统的结构。
B. SIMD (单指令多数据) (× 错误)
- 原因:SIMD是阵列处理器或GPU的结构。一条指令同时控制多个处理单元对不同的数据进行相同的操作。多计算机系统的每个节点是独立工作的,不满足“单指令”的特征。
C. MISD (多指令单数据) (× 错误)
原因:MISD是一种理论模型,在实际中极少应用。它要求多个处理器对同一数据流执行不同的操作(如流水线处理),这与多计算机系统每个节点处理不同数据的特征不符。
D. MIMD (多指令多数据) (√ 正确)
原因:多计算机系统(如计算机集群、分布式系统)由多个独立的计算机(节点)组成。每个节点都有自己的处理器和内存,独立地执行自己的指令流(多指令),处理自己的数据流(多数据)。这完美符合MIMD的定义。
3、最终答案:D
例题2

1、知识点总结
这道题考察的是计算机总线与扩展接口的知识点。题目描述虽然部分文字模糊,但关键信息清晰:“用于将显卡、声卡、网卡和硬盘控制器等高速外围设备直接挂在 CPU 总线上”。
| 总线/接口 | 全称 | 主要用途与特点 | 对应选项 |
|---|---|---|---|
| PCI | Peripheral Component Interconnect | 用于连接高速外围设备(如图形卡、声卡、网卡、硬盘控制器)到主板芯片组(北桥),从而与CPU通信。是上世纪90年代至21世纪初的标准高速扩展总线。 | C (正确答案) |
| STD 总线 | - | 一种古老的、主要用于工业控制领域的8位总线标准,用于模块化板卡的连接,速度很慢,不适合连接高速外设。 | A |
| 交叉开关 | Crossbar Switch | 这不是一种“总线”,而是一种高速的内部互联结构(用于多处理器系统或路由器等设备的内部,连接多个输入和输出端口),不用于外接扩展卡。 | B |
| Centronic 总线 | - | 一种古老的、并行的打印机接口标准(俗称并口),速度极慢,主要用于连接打印机、扫描仪等低速设备。 | D |
2、选项分析
A. STD 总线 (× 错误)
原因:这是一种过时的、低速的工业控制总线,完全不适合连接显卡等高速设备
B. 交叉开关 (× 错误)
原因:这是一种用于系统内部互联的交换结构,而不是一种用于扩展外围设备的标准外部总线。用户无法将显卡、网卡插到“交叉开关”上。
C. PCI (√ 正确)
原因:PCI总线的设计目的就是为了解决高速外设(如显卡、声卡、网卡)与CPU的通信问题。它曾是个人计算机的标准扩展槽,完美匹配题目描述“将高速外围设备直接挂在CPU总线上”的场景。
D. Centronic 总线 (× 错误)
原因:这是一种低速的并行打印机接口,根本无法满足显卡、硬盘控制器等设备的高速数据传输需求。
3、最终答案:C
例题3

1、知识点总结
计算机的CPU主要由运算器和控制器两大部分组成。
控制器的核心功能:
负责协调并控制计算机各部件执行程序的指令序列。其基本功能包括:取指令、分析指令、执行指令、控制程序和数据的输入与输出等。
控制器的主要组成部分:
- 程序计数器 (PC - Program Counter):存放下一条要执行的指令的地址。
- 指令寄存器 (IR - Instruction Register):存放当前正在执行的指令。
- 指令译码器 (ID - Instruction Decoder):对指令的操作码进行解析,产生相应的控制信号。
- 时序发生器 (Timing Generator):产生时序脉冲和节拍电位,为整个计算机提供时序控制信号,确保各部件按时序协调工作。
- 操作控制器:根据指令译码器和时序信号,产生各种操作控制信号,以正确地建立数据通路,完成指令的执行。
- 数据缓冲寄存器 (DR - Data Register):暂时存放由内存储器读出或写入的指令或数据。
程序状态字寄存器 (PSW - Program Status Word) 属于谁?
PSW 是一个特殊的寄存器,用于存放当前程序执行的状态信息(如进位标志、零标志、溢出标志、中断允许标志等)和控制信息。
从其功能来看,它记录的是算术逻辑单元 (ALU) 操作的结果状态,并根据这些状态来影响后续的操作(如条件跳转)。
因此,PSW 不属于控制器,而是属于运算器的一部分。它是运算器输出状态信息的存储地,控制器会读取PSW的内容来做出决策(如是否跳转),但它本身不是控制部件。
2、选项分析
A. 程序计数器 PC (属于控制器)
控制器依靠PC来确定指令的执行流程,是控制器的核心部件。
B. 时序发生器 (属于控制器)
产生控制整个机器工作的时序信号,是控制器的“节拍器”,绝对是控制器的一部分。
C. 程序状态字寄存器 PSW (不属于控制器)
这是正确答案。PSW存储的是运算结果的特征(状态标志位),它更贴近于运算器(ALU) 的功能单元。控制器会使用PSW的信息,但PSW本身不属于控制器。
D. 数据缓冲寄存器 (属于控制器)
数据缓冲寄存器(DR)用于暂时存放数据,是CPU和内存、外设之间数据传送的中转站,由控制器管理,属于控制器的组成部分。
3、最终答案:C
例题4

1、知识点总结
溢出是指运算结果超出了机器所能表示的范围。对于有符号数,溢出会导致结果错误。
溢出的基本条件:
溢出只可能发生在以下两种情况:
两个正数相加,结果为负(正+正=负)。
两个负数相加,结果为正(负+负=正)。

2、选项分析
SF (Sign Flag):符号标志,即结果的最高位。结果为负时SF=1,为正时SF=0。
CF (Carry Flag):进位标志,记录最高位(符号位) 向前产生的进位。有进位时CF=1,无进位时CF=0。

3、最终答案:D
例题5

1、知识点总结
“32位计算机”中的“位”(bit)是一个核心概念,它主要指的是计算机CPU一次能处理的数据宽度。
字长 (Word Size):CPU一次能并行处理的二进制数据的位数。这决定了CPU的处理能力、计算精度和寻址能力。
32位计算机:是指该计算机的CPU字长为32位。这意味着:
数据处理:CPU的通用寄存器、运算器(ALU)和数据总线的宽度通常是32位。因此,它能同时处理(例如:相加、相减、移动)32位的二进制数。
寻址能力:CPU的寻址能力(能访问的内存大小)由地址总线的位数决定,但它通常与字长相关。32位地址总线最多可以寻址 2^32 = 4GB 的内存空间。但字长并不直接等于地址总线宽度。
运算精度:字长影响了CPU进行整数运算的精度,但与小数的精度(由浮点运算单元决定)没有直接关系。
2、选项分析
A. 能同时处理 32 位二进制数 (√ 正确)
原因:这直接对应了“字长”的定义。32位计算机的核心特征就是其CPU能够并行处理32位的二进制数据。这是“32位”最准确、最根本的含义。
B. 能同时处理 32 位十进制数 (× 错误)
原因:计算机内部使用二进制进行计算和存储,而不是十进制。CPU的位宽指的是二进制位数。处理十进制数需要额外的编码(如BCD码)和转换,与CPU的字长没有这种直接对应关系。
C. 具有 32 根地址总线 (× 错误)
原因:这是一个常见的混淆点。字长(数据总线宽度)并不直接等于地址总线宽度。虽然32位计算机的地址总线通常是32位(从而寻址能力为4GB),但这不是绝对的。历史上存在过地址总线与数据总线宽度不同的CPU(例如Intel 8088是16位CPU,但地址总线为20位)。因此,用地址总线宽度来定义“32位计算机”是不准确的。
D. 运算精度可达小数点后 32 位 (× 错误)
原因:CPU的字长主要影响整数的表示范围和精度。浮点数的精度(即小数点后的位数)是由浮点运算单元(FPU) 遵循的IEEE 754标准决定的(如32位单精度浮点数、64位双精度浮点数),与CPU的整数字长没有直接的等量关系。一个32位CPU完全可以处理64位的双精度浮点数。
3、最终答案:A
例题6
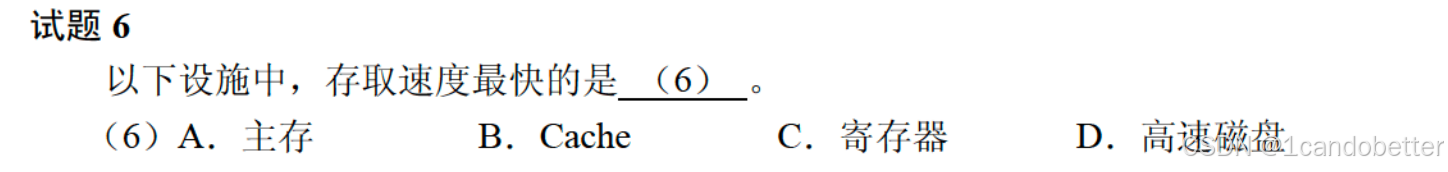
1、知识点总结
计算机的存储系统是一个层次结构,从上到下,容量越来越大,但存取速度越来越慢,成本也越来越低。其核心思想是:用少量快速昂贵的存储设备作为大量低速廉价存储设备的高速缓存。
存储层次(从快到慢,容量从小到大):
寄存器 (Registers):位于CPU内部,速度最快,容量最小(以字节计),用于存储当前正在执行的指令所直接使用的操作数和结果。
高速缓存 (Cache):位于CPU和主存之间,由SRAM构成,速度仅次于寄存器,容量比寄存器大(通常为KB到MB级别),用于缓存主存中当前最可能被CPU使用的指令和数据。
主存储器 (主存 / Main Memory):通常由DRAM构成,速度比Cache慢一个数量级,容量更大(通常为GB级别),是CPU能直接寻址访问的存储空间。
辅助存储器 (外存 / Secondary Storage):如硬盘、固态硬盘(SSD)、磁盘阵列等,速度最慢,但容量最大(通常为TB级别),用于长期持久地存储数据。题目中的“高速磁盘”即属于此类,即使再“高速”,其速度也无法与内存级别的设备相比。
2、选项分析
速度对比(近似概念):
访问寄存器 ≈ 1个CPU时钟周期
访问Cache ≈ 几到几十个CPU时钟周期
访问主存 ≈ 上百个CPU时钟周期
访问磁盘 ≈ 几百万个CPU时钟周期
3、最终答案:C
例题7

1、知识点总结
局部性原理是计算机科学中一个非常重要的概念,它是缓存技术能够高效工作的理论基础。该原理指出,程序在执行时,倾向于访问相对集中的存储区域。局部性原理主要分为两类:
时间局部性 (Temporal Locality)
- 含义:如果一个信息项(指令或数据)正在被访问,那么它在近期很可能还会被再次访问。
- 例子:循环结构中的循环变量、计数器、频繁调用的函数指令。
空间局部性 (Spatial Locality)
含义:如果一个信息项被访问,那么其邻近的信息项也很可能在近期被访问。
例子:顺序执行的指令、顺序遍历数组或集合中的元素。
局部性原理的综合描述就是:程序在执行时,对内存的访问不是均匀分布的,而是趋于聚集或成簇的。程序在一段时间内,会集中地访问一个相对较小的地址空间片段。
2、选项分析
A. 程序代码顺序执行 (× 错误)
原因:这只描述了空间局部性的一个特例(指令顺序执行),但完全忽略了时间局部性(如循环跳转、函数调用)。局部性原理的含义远比“顺序执行”广泛。
B. 程序按照非一致性方式访问内存 (× 错误)
原因:这个描述与局部性原理完全相反。局部性原理描述的是程序访问内存的规律性和一致性(即访问行为在时间和空间上是集中的),而不是“非一致性”的随机访问。
C. 程序连续地访问许多变量 (× 错误)
原因:这个描述是模糊且具有误导性的。“访问许多变量”听起来像是访问范围很广,这与“访问相对集中的地址空间”相矛盾。局部性原理强调的是“访问集中”,而不是“访问许多”。
D. 程序在一段时间内访问相对小的一段地址空间 (√ 正确)
原因:这直接、准确地概括了局部性原理的核心思想。它同时涵盖了时间局部性(“一段时间内”的重复访问)和空间局部性(访问“一段地址空间”及其邻近区域)。
3、最终答案:D
例题8

1、知识点总结
| 数据交换方式 | 核心特点 | 优点 | 缺点 | CPU参与度 |
|---|---|---|---|---|
| 程序控制(查询)方式 | CPU主动地、不断地查询I/O设备的状态,准备就绪则进行数据传送。 | 接口简单,易于实现。 | CPU效率极低,绝大部分时间都在等待和查询。 | 高,全程参与 |
| 中断方式 | I/O设备完成后主动向CPU发出中断请求,CPU中断当前程序,转去执行中断服务程序来完成数据传送。 | 提高了CPU利用率,CPU在I/O操作期间可以执行其他程序。 | 每次传输都需要CPU干预(执行ISR),传输大量数据时开销很大。 | 中,每次传输都需介入 |
| DMA方式 | 由DMA控制器(DMAC) 在不需要CPU干预的情况下,直接管理I/O设备与主存之间的数据交换。 | 传输数据不需要CPU干预,极大提高了CPU效率和数据传输效率。 | 接口电路复杂,成本较高。 | 低,仅在传输开始和结束时介入 |
DMA请求与中断请求的优先级:
通常,DMA请求的优先级高于中断请求。因为DMA请求通常用于高速设备的数据传输,如果得不到及时响应可能导致数据丢失。而中断请求的处理稍作延迟通常不会造成灾难性后果。
2、选项分析
A. 中断方式下,CPU 需要执行程序来实现数据传送 (√ 正确)
原因:在中断方式下,当CPU收到中断请求后,会执行一段名为“中断服务程序(ISR)”的代码来完成实际的数据传输工作。这个叙述是正确的。
B. 按交换数据的效率从低到高:程序控制方式、中断方式、DMA 方式 (√ 正确)
原因:这是三种方式的标准效率排序。
程序控制方式效率最低(CPU忙等待)。
中断方式效率中等(CPU无需等待,但每次传输都要介入)。
DMA方式效率最高(CPU几乎不参与数据传输过程)。这个叙述是正确的。
C. 中断方式和 DMA 方式相比,快速 I/O 设备更适合采用中断方式传递数据 (× 错误)
- 原因:这是错误的叙述。快速I/O设备(如磁盘、网卡)的数据传输率很高,如果采用中断方式,每次传输一个数据块(如一个扇区)都需要CPU中断一次,频繁的中断会消耗大量CPU时间,成为系统瓶颈。相反,DMA方式正是为这类设备设计的,它允许设备与内存直接进行大批量数据交换, 在传输开始和结束时需要CPU干预,从而解放了CPU。因此,快速I/O设备更适合采用DMA方式。
D. 若同时接到 DMA 请求和中断请求,CPU 优先响应 DMA 请求 (√ 正确)
原因:如前所述,DMA请求的优先级通常高于中断请求。这是为了防止高速设备的数据丢失,是计算机系统中的一种常见设计。这个叙述是正确的。
3、最终答案:C
例题9

1、知识点总结
这道题考察的是CISC(复杂指令集计算机)和RISC(精简指令集计算机)架构的区别。
| 特性 | CISC (Complex Instruction Set Computer) | RISC (Reduced Instruction Set Computer) |
|---|---|---|
| 设计哲学 | 强调指令的功能性,一条指令完成一个复杂功能 | 强调指令的简洁性,一条指令只完成一个基本操作 |
| 指令系统 | 指令数量多,格式可变长,寻址方式丰富 | 指令数量少,格式固定,寻址方式简单 |
| 指令使用频度 | 80-20定律:约20%的简单指令在程序中占80%的使用时间 | 通过精简,使指令使用频度相对均衡 |
| 执行方式 | 主要采用微程序控制(微码),执行复杂指令需多个时钟周期 | 主要采用硬布线逻辑控制,大部分指令在单时钟周期内完成 |
| 编译优化 | 更依赖硬件,编译器设计相对简单 | 更依赖编译器优化,将复杂操作由编译器用多条简单指令实现 |
| 访存操作 | 允许指令直接操作内存 | 采用Load/Store结构,只有专门的Load/Store指令才能访问内存 |
2、选项分析
A. 虽然 RISC 机器指令数量比 CISC 机器少,但功能更强大 (× 错误)
原因:说反了。CISC的单一指令功能更强大(如一条指令完成内存到内存的字符串拷贝),而RISC的单一指令功能非常基本(如只完成寄存器之间的加法)。RISC的“强大”体现在通过简单指令的组合和流水线技术实现更高的执行效率,而非单一指令的功能。
B. RISC 机器指令使用频度比 CISC 机器更均衡 (× 错误)
原因:这个描述不准确。RISC通过剔除那些不常用的复杂指令,使得保留下来的简单指令的使用频率都较高,从而变得“均衡”。而CISC由于指令集庞大,大量复杂指令很少被使用,才导致了“80-20”的不均衡现象。是CISC的不均衡催生了RISC的均衡设计,但选项的对比描述显得RISC是主动追求均衡,而CISC是主动追求不均衡,这不符合历史事实。
C. RISC 采用硬布线逻辑控制;CISC 采用微程序控制技术 (√ 正确)
原因:这是CISC和RISC在控制单元实现上的一个经典且关键的区别。RISC指令简单、规整,适合用速度更快的硬布线逻辑直接实现。而CISC指令复杂、可变长,更适合用微程序(微码)来控制执行,灵活性更高但速度相对较慢。
D. RISC 机器指令系统中,各类指令都可以操作内存 (× 错误)
原因:这恰恰是RISC最重要的设计原则之一——Load/Store结构。在RISC中,只有专门的Load(加载)和Store(存储)指令可以访问内存,其他所有指令(如算术、逻辑指令)都只能操作寄存器。而CISC则允许很多指令直接操作内存。
3、最终答案:C
例题10

1、知识点总结
这道题考察的是浮点数表示法中,指数和尾数的位数分配对表示范围和精度的影响。

在总位数固定的情况下,指数部分 E 和尾数部分 M 的位数分配是一种权衡
| 部分 | 位数增加的影响 | 位数减少的影响 |
|---|---|---|
| 指数 (E) | 可表示的数的范围扩大(指数最大值变大) |
可表示的数的范围减小(指数最大值变小) |
| 尾数 (M) | 可表示的数的精度提高(有效数字位数变多) |
可表示的数的精度降低(有效数字位数变少) |
核心关系:
范围主要由指数位数决定。
精度主要由尾数位数决定。