目录
大概运作模式
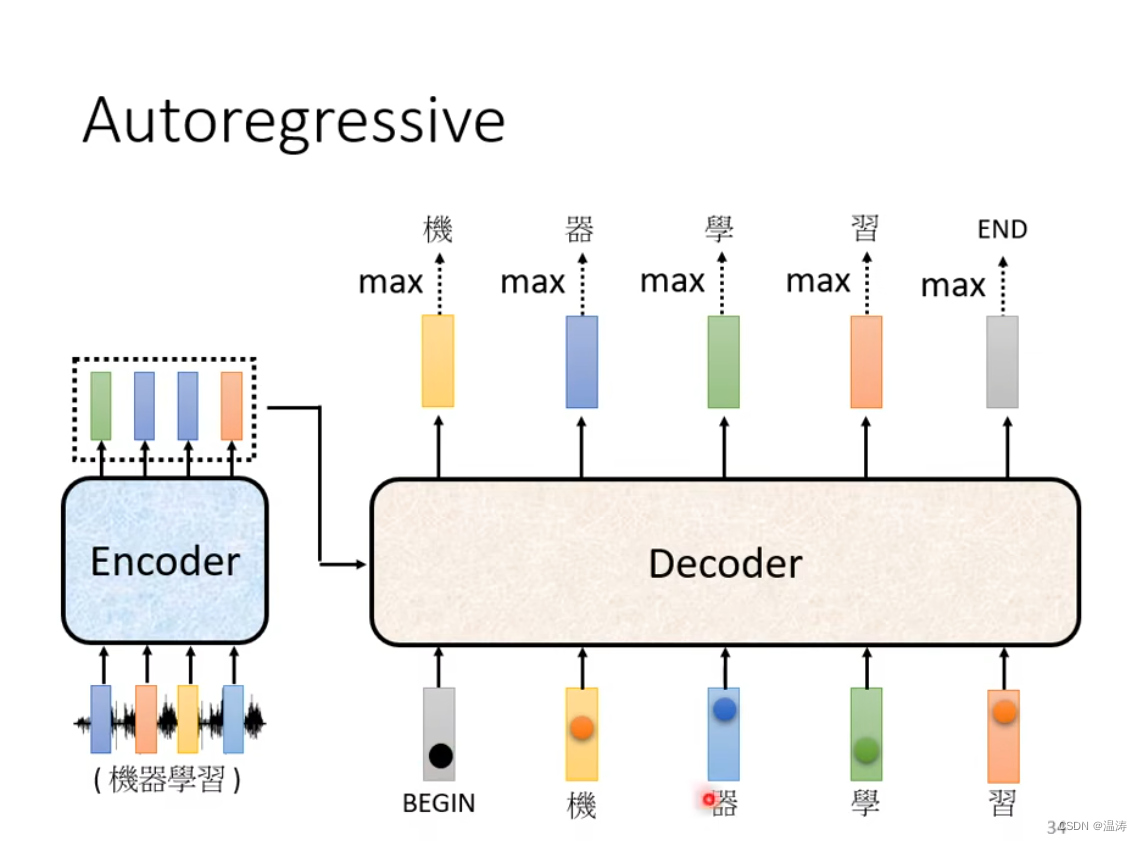
将Encoder的输出丢入到Deconder中,每一个输出会有一个distribution对应概率表,其中得分最高的即是现在的输出
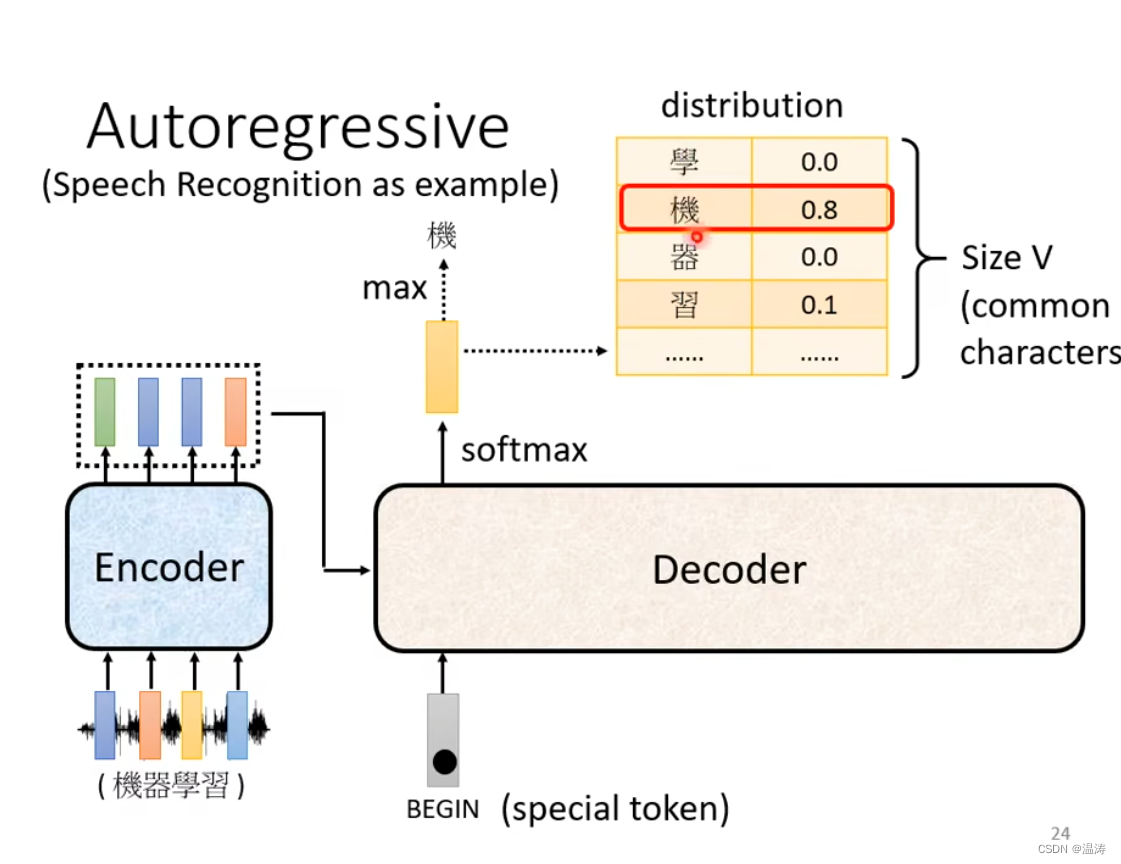
当在第二步时我们既有BEGIN作为输入也有机作为输入
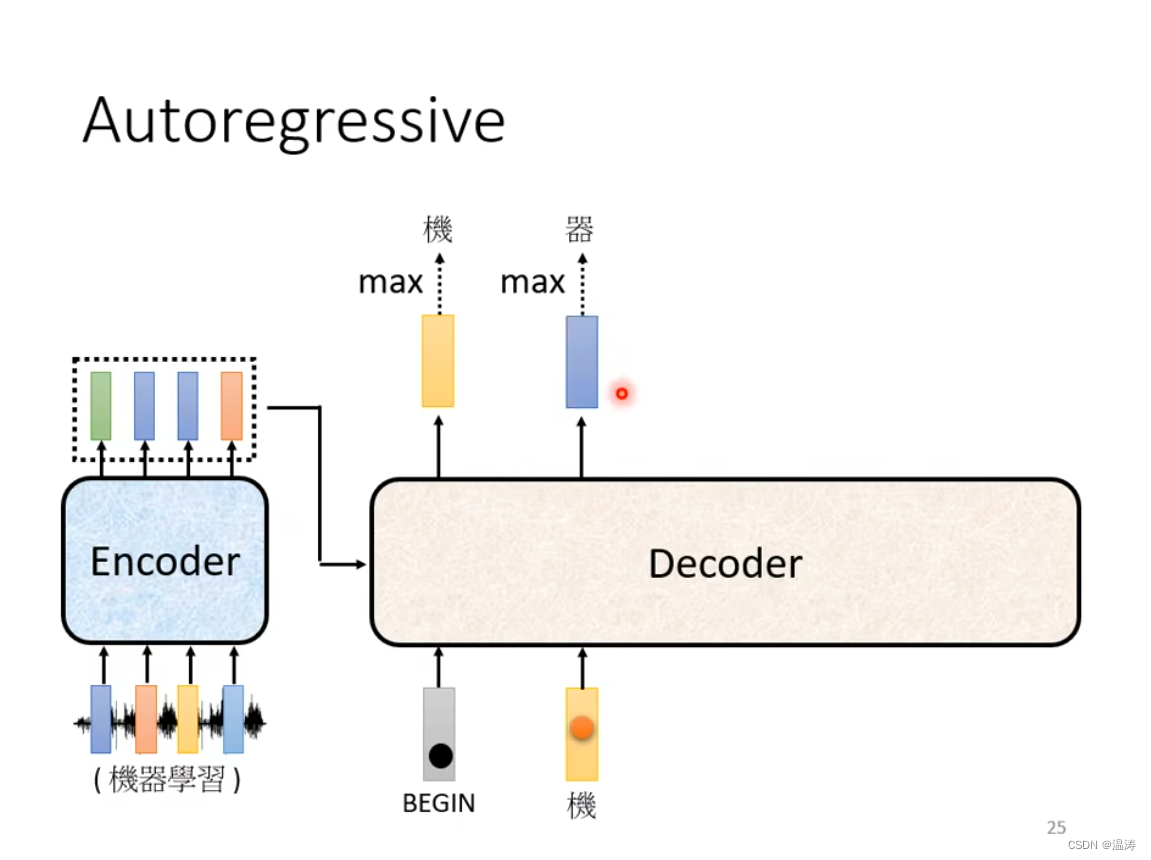 然后以此类推,但是有可能接受到错误的信息导致一步错步步错的结果(这个问题怎么解决最后再讲)
然后以此类推,但是有可能接受到错误的信息导致一步错步步错的结果(这个问题怎么解决最后再讲)
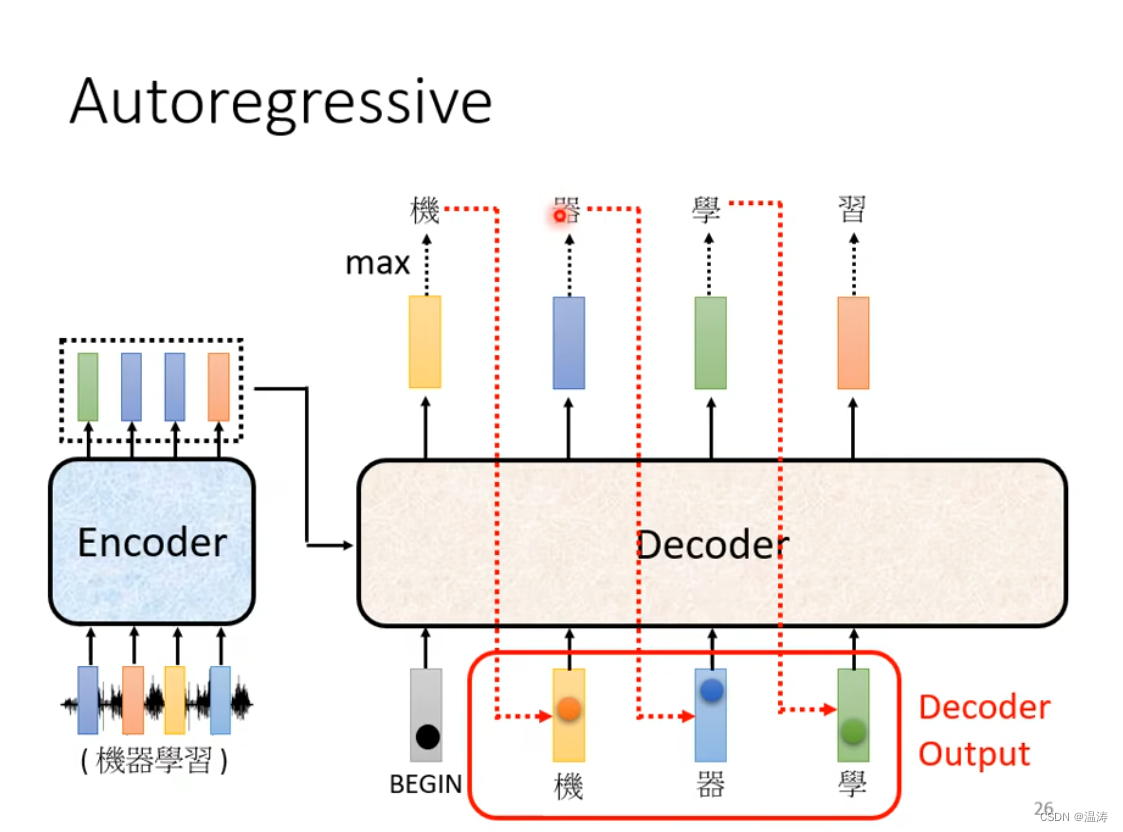
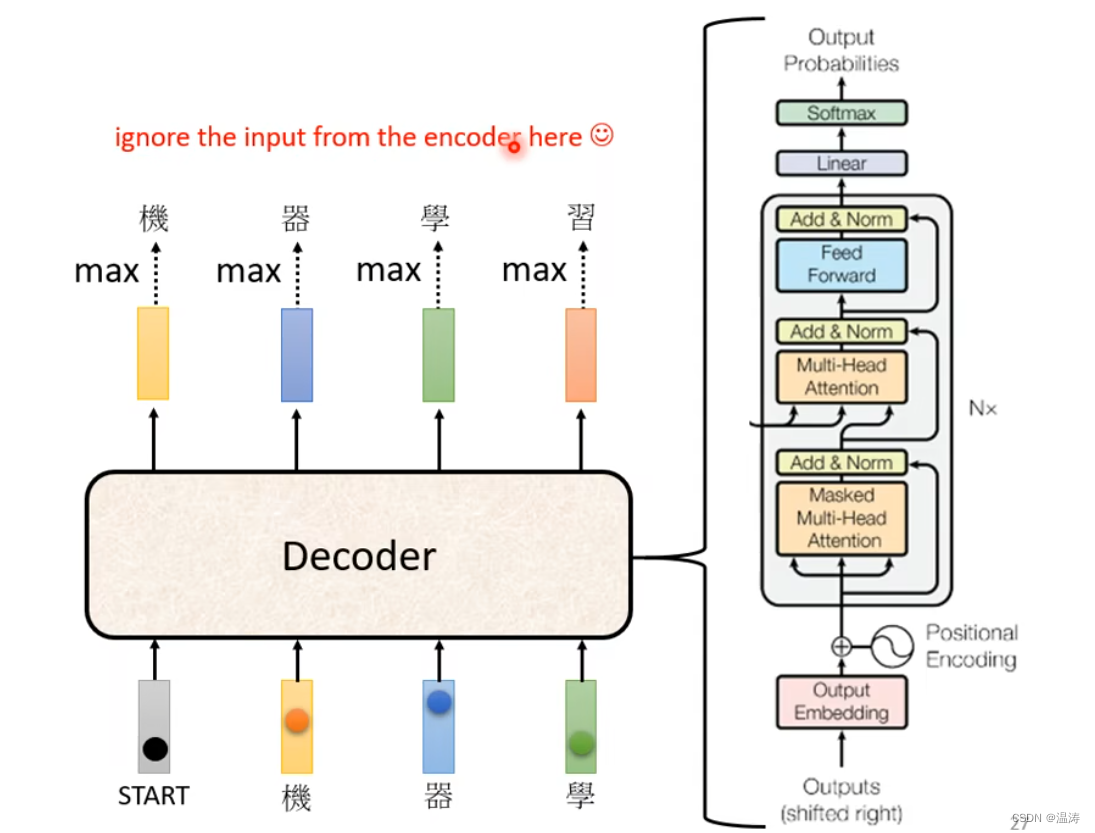
Encoder与Decoder对比
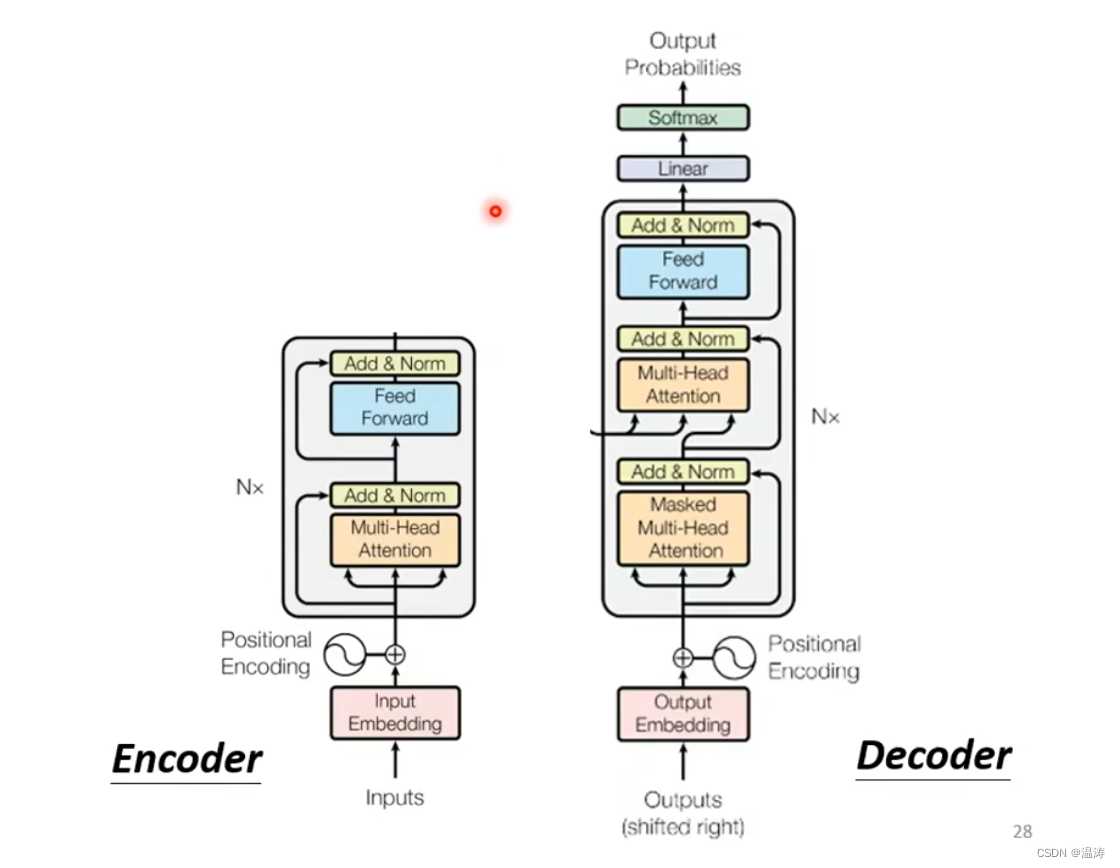
通过这个图我们会发现,如果我们把Decoder中间这块遮住,那么Encoder与Decoder就差不多
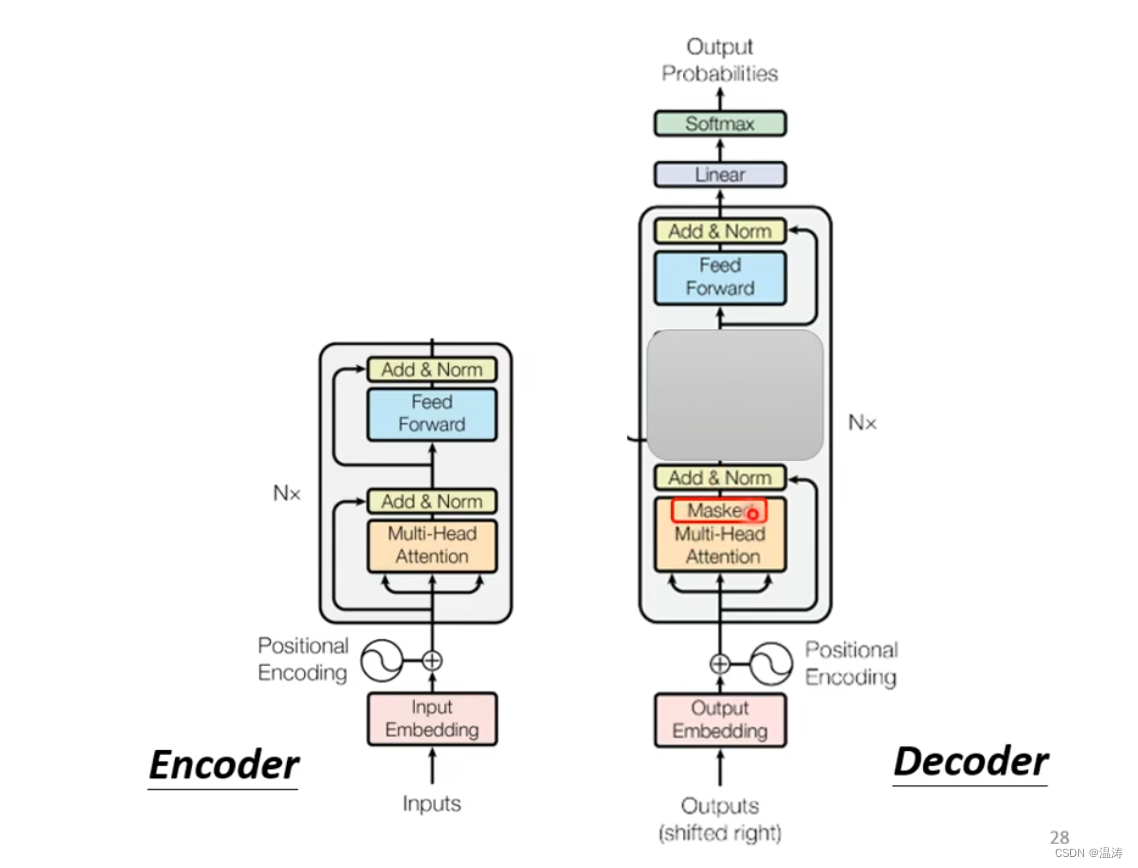
这里加了个mask,这个mask是什么意思呢
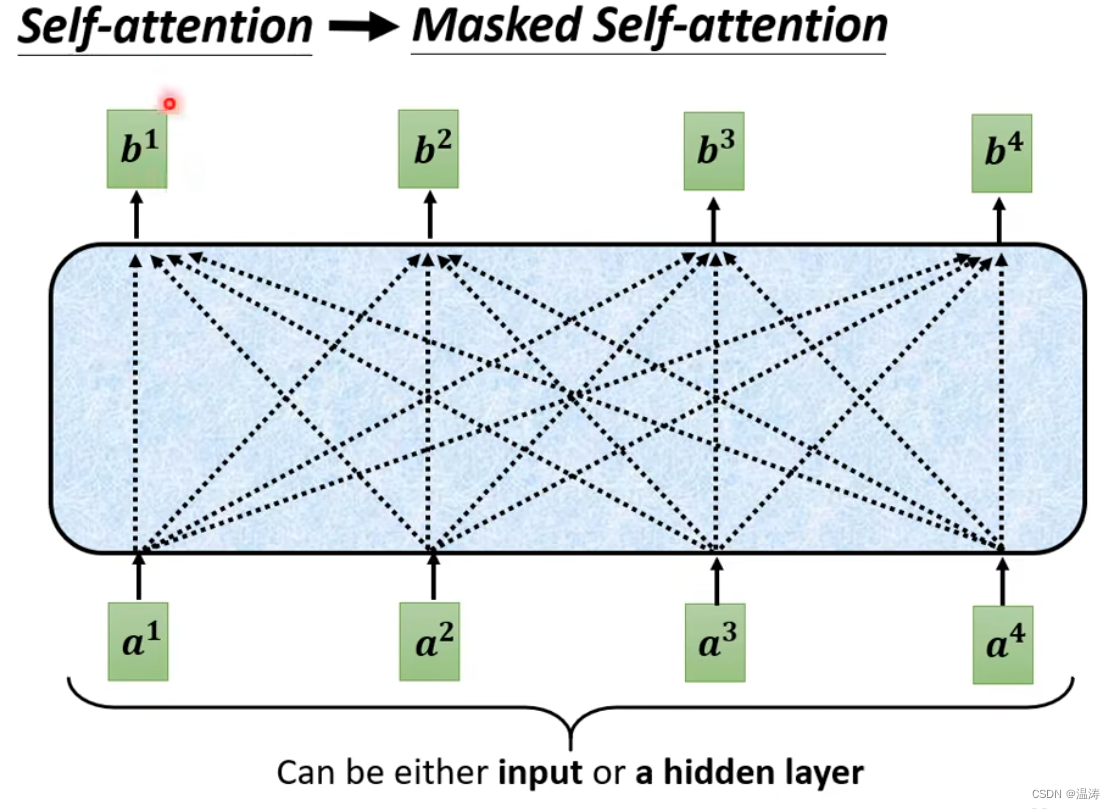
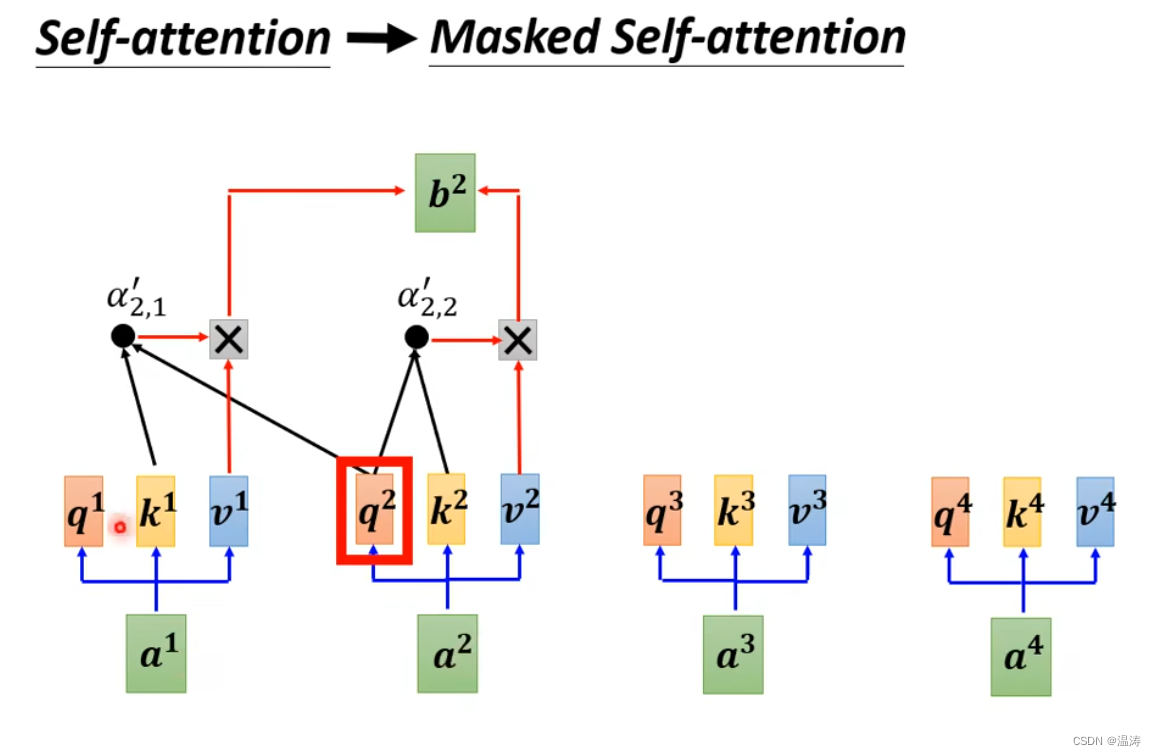
原来的self attention,b1会考虑所有a1到a4而,masked self-attention,b1只关心a1,而b2只关心a1和a2
那为什么要用masked Self-attention呢
Deconder用self-attention是因为Decoder常常可以拿到一大批数据,而Encoder拿得是Decoder的输出,而Decoder的输出是一个一个产生的,现有a1才有a2
怎么让输出停下来
在distruibution里面加入end,它可以和begin是同一字符也可以是不同字符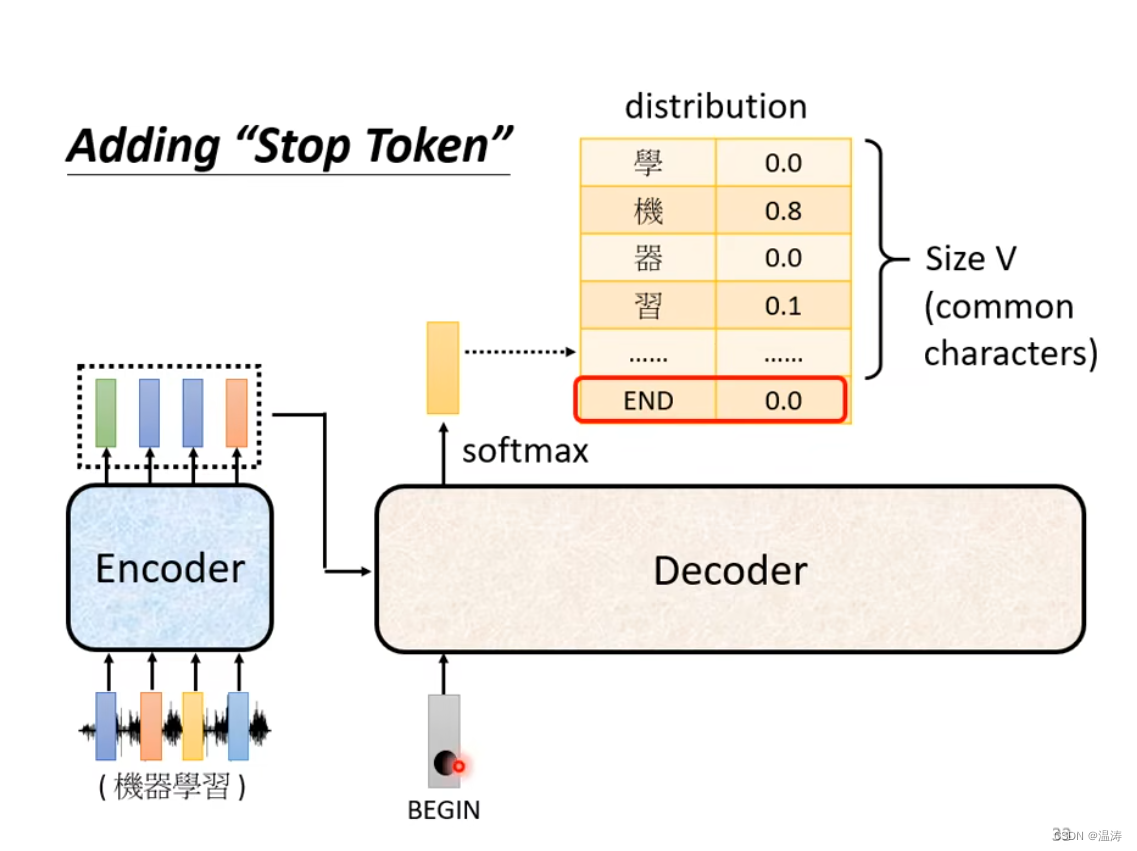
AT vs NAT
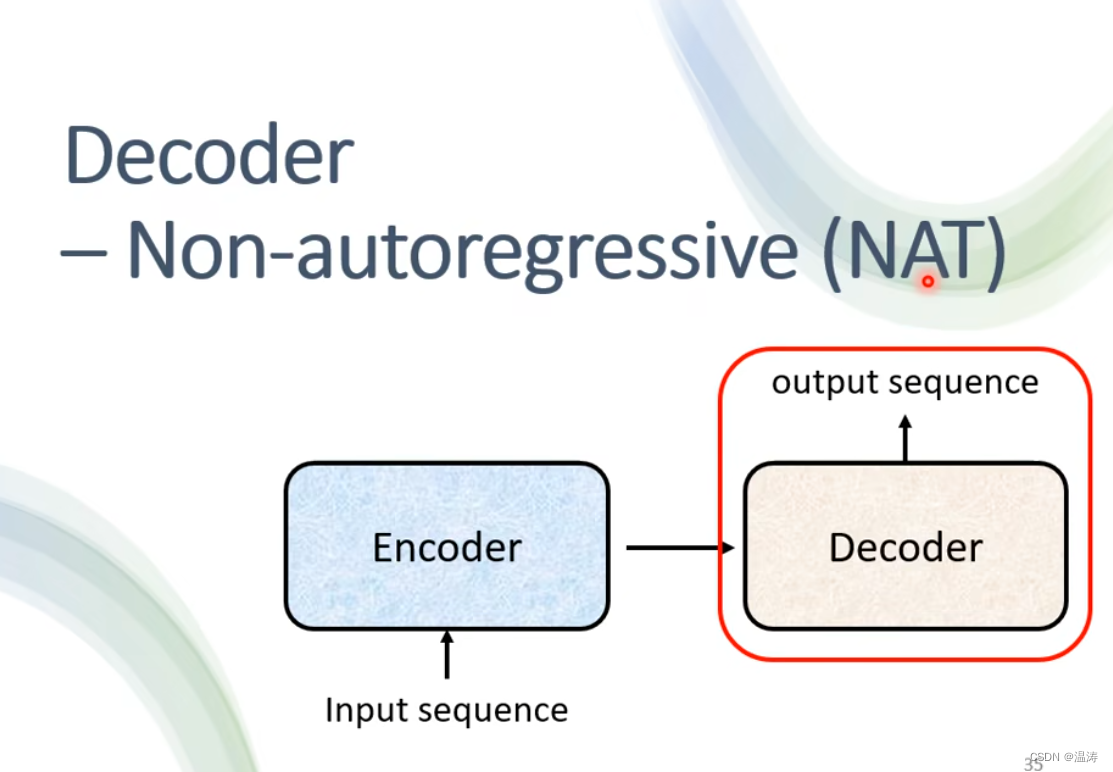
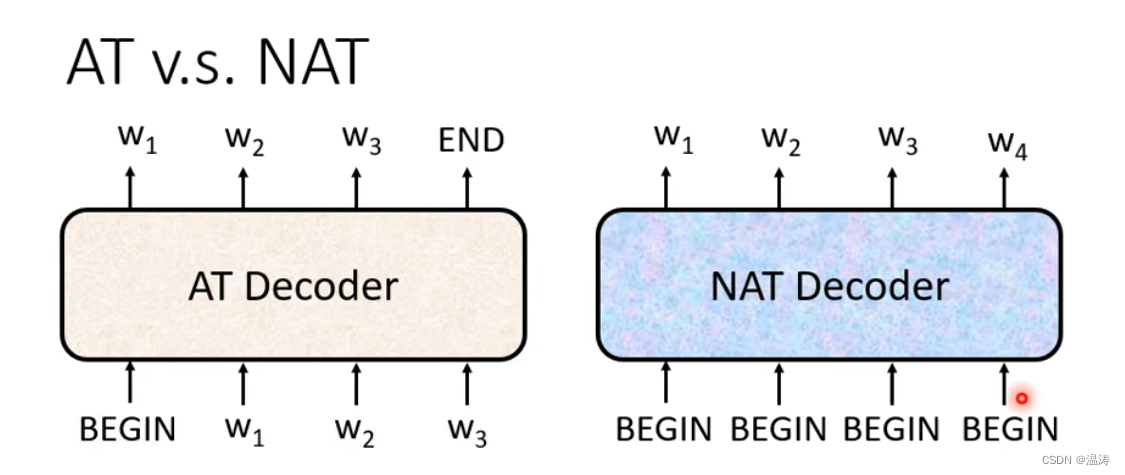
AT是一个一个丢进去,而Nat是一堆丢进去要判断结束要设置一个分类器。当然AT的效果好但是NAT速度快(并行处理)
cross-attention
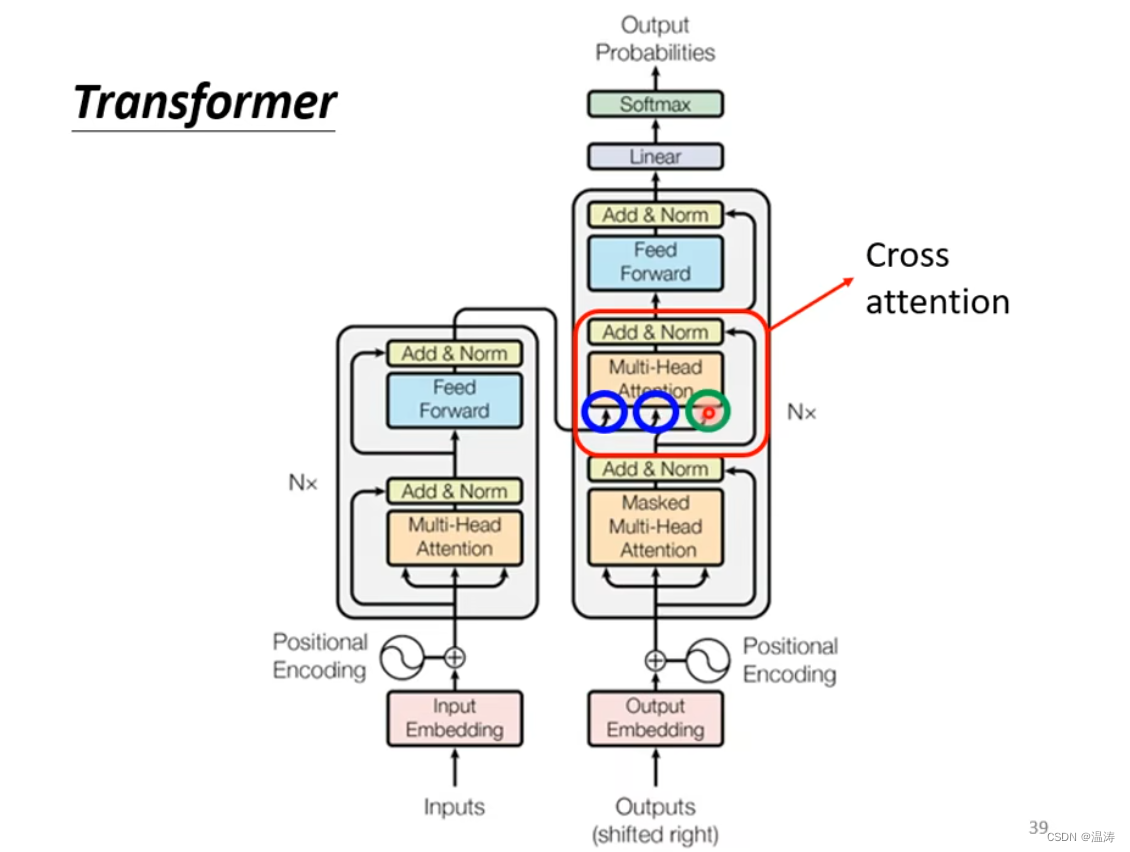 其中两个输入来自decoder,一个输入来自encoder
其中两个输入来自decoder,一个输入来自encoder
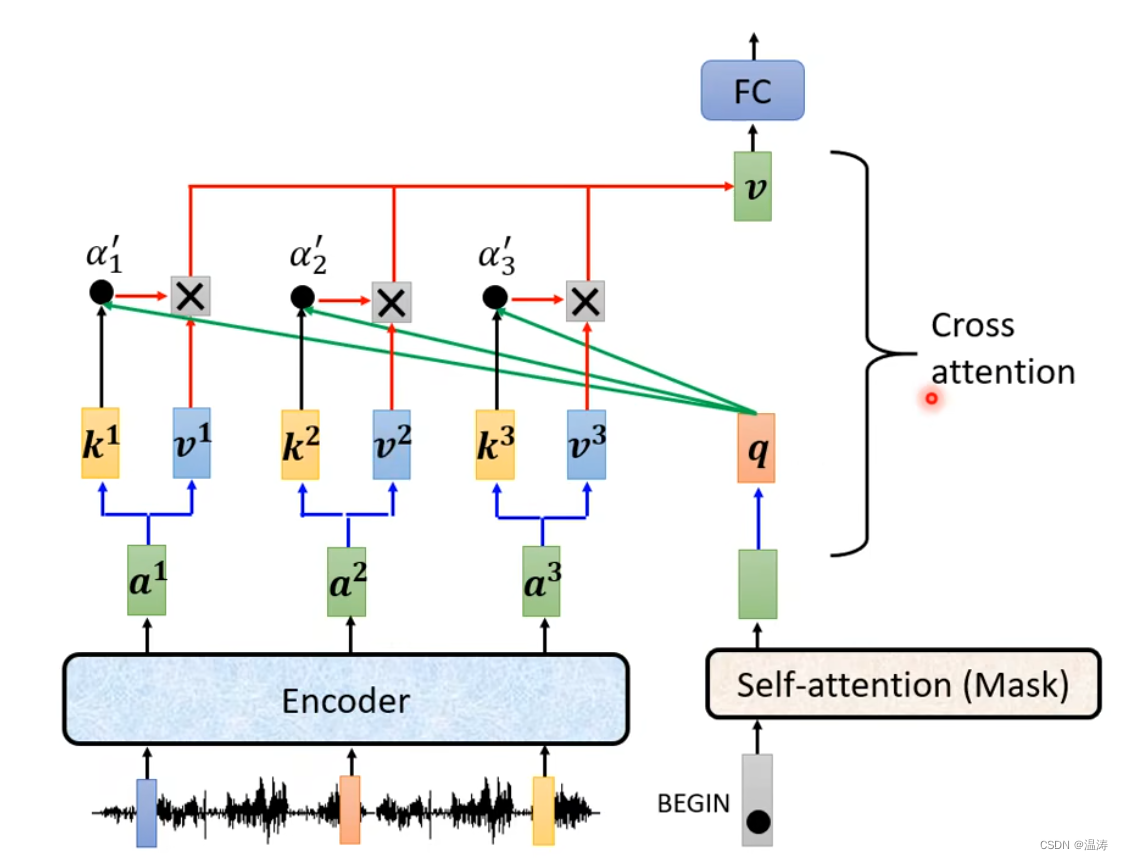
其中q来自decoder,k和v来的encoder这个就是cross attention
Decoder接受的输入
在原始paper里,Encoder有好多层,都是拿Encoder最后一层的输出去给Decoder。但是也不一定这样,下图指出了可能性
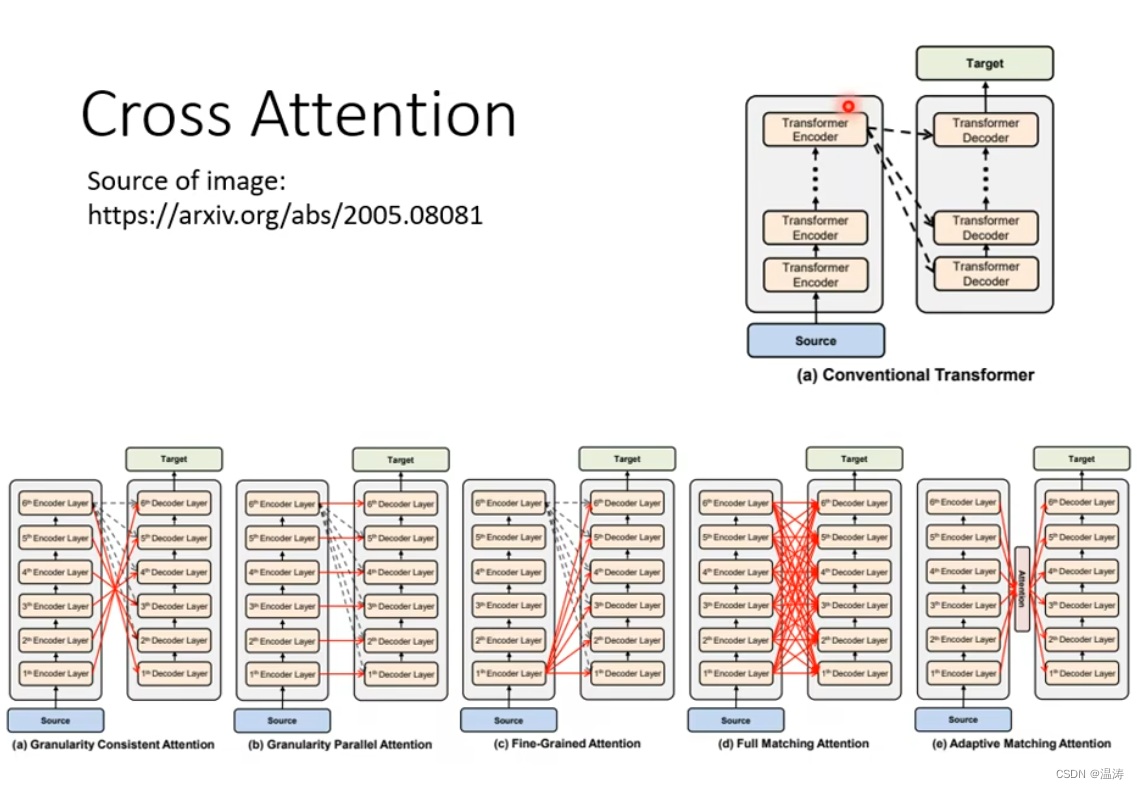
到这里讲的都是训练好的模型怎么做testing,而没有讲怎么训练,下一章我们会将怎么训练
本文含有隐藏内容,请 开通VIP 后查看