深度学习论文精读(一)Deep Residual Learning for Image Recognition
前言
核心内容来自博客链接1博客连接2希望大家多多支持作者
本文记录用,防止遗忘
ResNet
1 Summary总结
遇到的问题?
问题:更深的神经网络更难训练。ResNet是解决了深度CNN模型难训练的问题
解决方案?
提出了一个残差学习框架——ResNet。使得学习变简单,网络优化变容易,并且可以从gain accuracy随着深度的增加,同时复杂度没有提高。
成果?
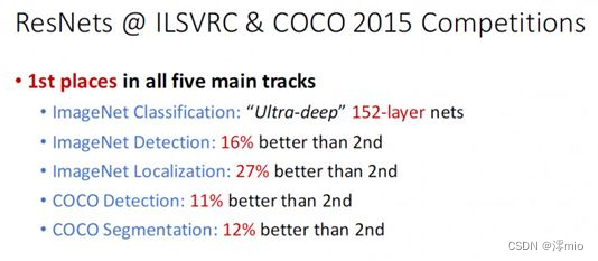
2 Introduction
神经网络叠的越深,则学习出的效果就一定会越好吗?
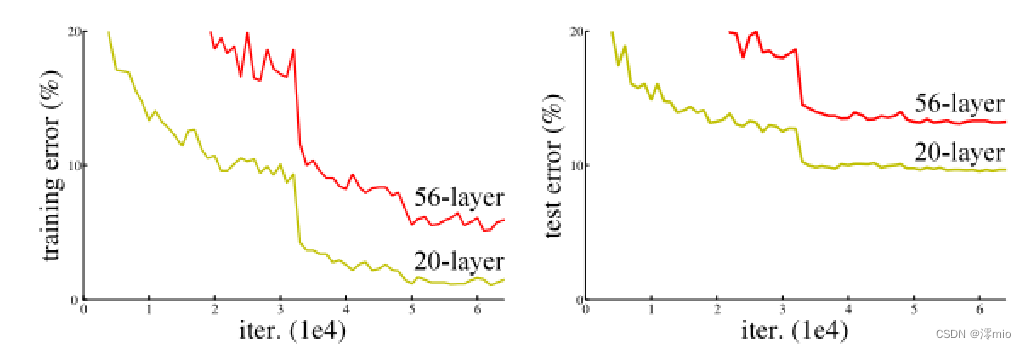
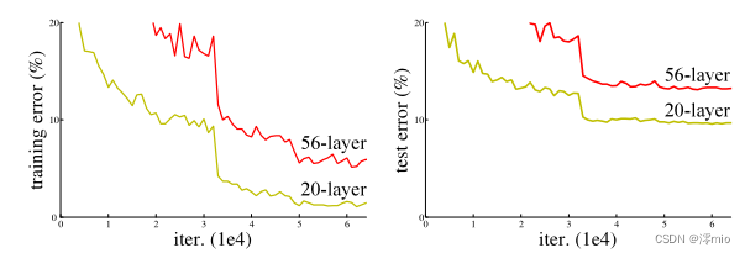
深度卷积网络对图像分类做出了重要贡献。不同级别的层可以学习到不同的级别的特征。而网络的深度至关重要。问题来了: Is learning better networks as easy as stacking more layers?答案无疑是否定的。首先存在了梯度爆炸/消失问题。但我们可以通过正则化初始化和中间的正则化层(Batch Normalization)来避免,从而可以收敛。但当更深的网络能够开始收敛时,我们发现当网络层数增加到某种程度,网络的效果将会不升反降。也就是说,网络发生了退化(degradation)。出乎意料的是,这种退化不是由过拟合引起的,并且向适当深度的模型添加更多层会导致更高的训练误差。
这说明,不是所有的系统都容易被优化。
但是,按理说,一个更深的网络不应该必一个比它浅的网络效果差。也就是说,当我们堆叠一个模型时,理所当然的会认为效果会越堆越好。因为,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。
极端情况:叠加一个恒等映射。
深度残差学习 Deep Residual Learning
然而事实上,这就是问题所在。“什么都不做”恰好是当前神经网络最难做到的东西之一。即神经网络很难实现恒等映射。本文提出了Deep Residual Learning Framework。那么如何拟合一个恒等映射?
我们设最终的底层映射为H(x),而这个映射包括F(x)和x两部分
思想:如果把网络设计为H(x) = F(x) + x,即直接把恒等映射作为网络的一部分。就可以把问题转化为学习一个残差函数F(x) = H(x) - x。
不是寻找输入到输出的映射而是寻找到“输出减输入”
只要F(x)=0,就构成了一个恒等映射H(x) = x。 而且,拟合残差至少比拟合恒等映射容易得多。实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能
。
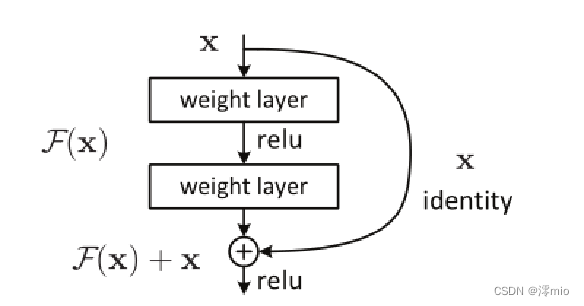
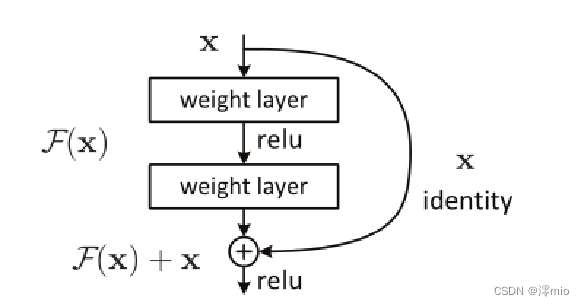
残差学习结构,如右图所示,通过一种短路连接(shortcut connection)来实现。短路连接不增加额外的参数,也不增加计算复杂性。
总结:
1)当深度增加时,深度残差网络很容易优化,对应的“普通”网络(简单地堆叠层)表现出更高的训练误差;
2)深度残差网络可以很容易地从深度增加中获得准确度,产生的结果比以前的网络要好得多。
3)这种优化困难和效果不仅仅类似于特定的数据集
相关工作Related Work
Residual Representations:VLAD是一种对残差向量编码表示图像的方法,Fisher Vector可以表述为 VLAD的概率版本。在图像分类、检索中,编码残差向量被证明比编码原始向量更有效。
在低级视觉和计算机图形学中,为了求解偏微分方程,广泛使用的多重网格方法。其替代方法分层基础预处理,它依赖于表示两个尺度之间的残差向量的变量。证明a good reformulation or preconditioning可以利于优化。
Shortcut Connections:“inception” layer is com-posed of a shortcut branch and a few deeper branches。“highway networks”
3 Deep Residual Learning
3.1 残差学习Residual Learning
让我们将 H(x) 视为由几个堆叠层(不一定是整个网络)拟合的底层映射,其中 x 表示这些层中第一层的输入。如果假设多个非线性层可以渐近逼近复杂函数,那么就相当于假设它们可以渐近逼近残差函数,即 H(x) - x(假设输入和输出具有相同的维度)。因此,我们不期望堆叠层逼近 H(x),而是明确地让这些层逼近残差函数 F(x) := H(x) - x。因此,原始函数变为 F(x)+x。尽管这两种形式都应该能够渐近地逼近所需的函数(如假设的那样),但学习的难易程度可能有所不同。
这种重构的动机是关于退化问题的违反直觉的现象。正如之前讨论的,如果添加的层可以构建为恒等映射,那么更深的模型应该具有不大于其较浅模型的训练误差。退化问题表明求解器可能难以通过多个非线性层来近似恒等映射。通过残差学习重构,如果恒等映射是最优的,求解器可以简单地将多个非线性层的权重推向零以接近恒等映射。在实际情况下,恒等映射不太可能是最优的。
3.2 Identity Mapping by Shortcuts
我们对每几个堆叠的层(block)采用残差学习。残差块表示为:y=F(x,{W_i})+x,其中F(x,{W_i})
是我们要学习的目标,即输出输入的残差y−x。如图,残差部分为两层且有一个Relu激活函数,即F=W_2σ(W_1x),其中σ表示权重。注意:一个Block中必须至少含有两个层,否则加了等于没加
x和F的维度必须相等。如果不相等的话,有两种方法:
(1)x直接padding补0
(2)对x做一个线性投影y=F(x,{W_i})+W_sx
3.3 网络架构Network Architectures
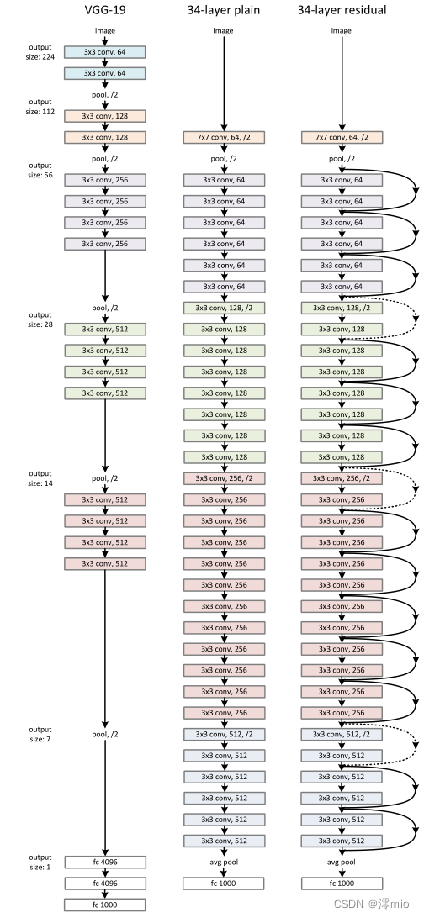
(1)plain network:主要受到 VGG 网络启发,遵循两个原则。(i)对于输出feature map大小相同的层,有相同数量的filters,即channel数相同; (ii)当feature map大小减半时(池化),filters数量翻倍。以保持每层的时间复杂度。我们直接通过步长为 2 的卷积层执行下采样。网络以全局平均池化层和带有 softmax 的 1000 路全连接层结束。值得注意的是,ResNet比 VGG 网络具有更少的过滤器和更低的复杂性(图 3,左)。我们的 34 层baseline有 36 亿次 FLOP(乘加),仅是 VGG-19(196 亿次 FLOP)的 18%
(2)Residual Network:基于普通网络,加入shortcut connection将网络转换为对应的残差版本。当输入和输出具有相同的维度时(实线),可以直接使用恒等映射。当维度增加时(虚线),两个选项:(A)仍然执行恒等映射,为增加维度填充额外的零条目。该选项不引入额外参数; (B) 投影短路连接用于匹配维度。乘以W矩阵投影到新的空间。实现是用1x1卷积实现的,直接改变1x1卷积的filters数目。这种会增加参数。对于这两个选项,当短路连接跨越两种大小的特征图时,它们以 2 的步幅执行。
3.4 网络架构Network Architectures
4 Experiments
4.1 ImageNet 分类
数据集:ImageNet 2012 classifi-cation dataset(1000类)
数据量:128 万张训练图像,5万张测试图像
标准:评估 top-1 和 top-5 错误率
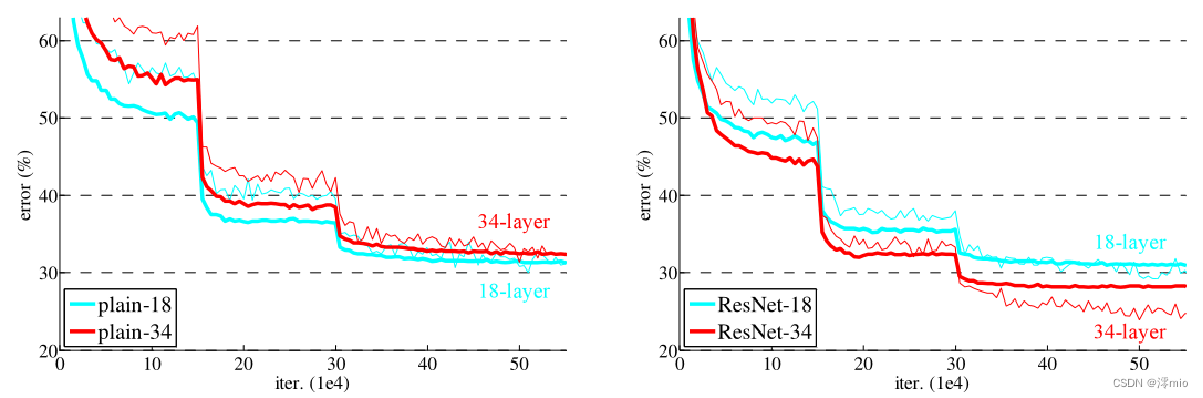
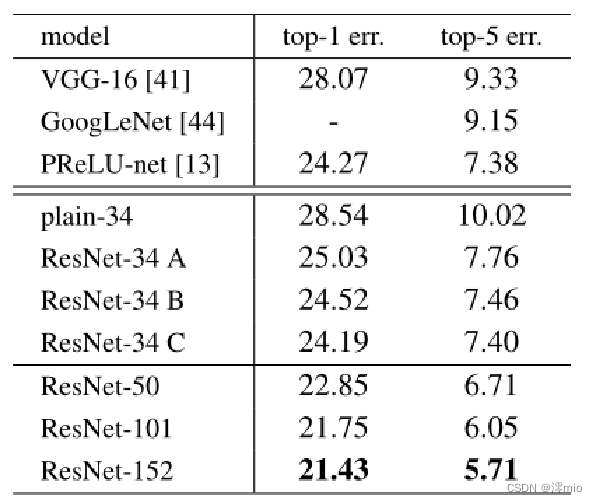
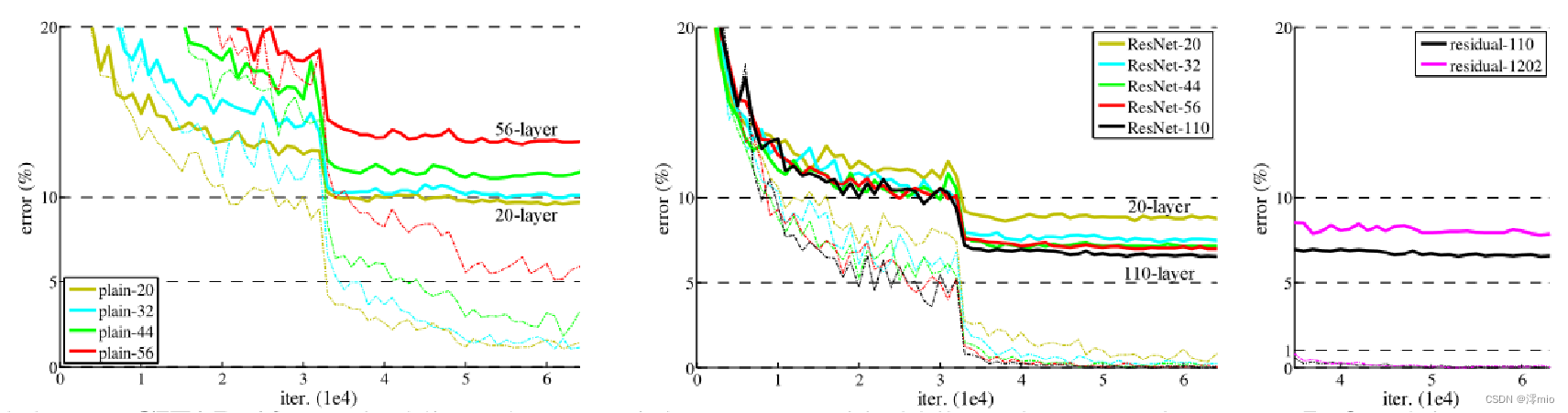
普通网络,结论:
(1)较深的 34 层普通网络比较浅的 18 层普通网络具有更高的验证误差。34 层普通网络在整个训练过程中具有较高的训练误差,尽管 18 层普通网络的解空间是 34 层网络的子空间。
(2)论文认为这种优化困难不是由梯度消失引起的。这些普通网络使用 BN 进行训练,确保前向传播的信号具有非零方差。我们还验证了反向传播的梯度在 BN 中表现出健康的范数。所以前向和后向信号都不会消失。事实上,34 层的普通网络仍然能够达到有竞争力的精度(表 3),这表明求解器在一定程度上起作用。我们推测深的普通网络的收敛速度可能呈指数级低,这会影响训练误差的减少。
ResNet,结论:
(1)34 层 ResNet 优于 18 层 ResNet(提高 2.8%)。更重要的是,34 层的 ResNet 表现出相当低的训练误差,并且可以推广到验证数据。这表明退化问题在此设置中得到了很好的解决,可以通过增加深度来获得准确度。
(2)相比普通网络ResNet 将 top-1 误差降低了 3.5%(表 2),这是由于成功降低了训练误差。这种比较验证了残差学习在极深系统上的有效性。
(3)我们还注意到 18 层的普通/残差网络相当准确,但 18 层的 ResNet 收敛速度更快。当网络“不太深”(此处为 18 层)时,当前的 SGD 求解器仍然能够为普通网络找到好的解决方案。在这种情况下,ResNet 通过在早期提供更快的收敛来简化优化。
Identity vs. Projection Shortcuts.:
我们已经证明无参数的短路连接有助于训练。接下来我们研究投影短路连接。在表中我们比较了三个选项: (A) 零填充短路连接用于增加维度,并且所有连接方式都是无参数的; (B) 投影短路连接用于增加维度,其他短路连接是恒等映射; © 所有的短路连接都是投影短路连接。
表中,显示所有三个选项都比普通选项好得多。 B 略好于 A。我们认为这是因为 A 中,zero padding的部分没有参与残差学习。 C 略好于 B,我们将此归因于许多(13 个)投影短路连接引入的额外参数。但是 A/B/C 之间的微小差异表明投影短路连接对于解决退化问题并不是必不可少的。因此,我们在本文的其余部分不使用选项 C,以降低内存/时间复杂度和模型大小。恒等映射短路连接方式对于不增加下面介绍的架构的复杂性特别重要。
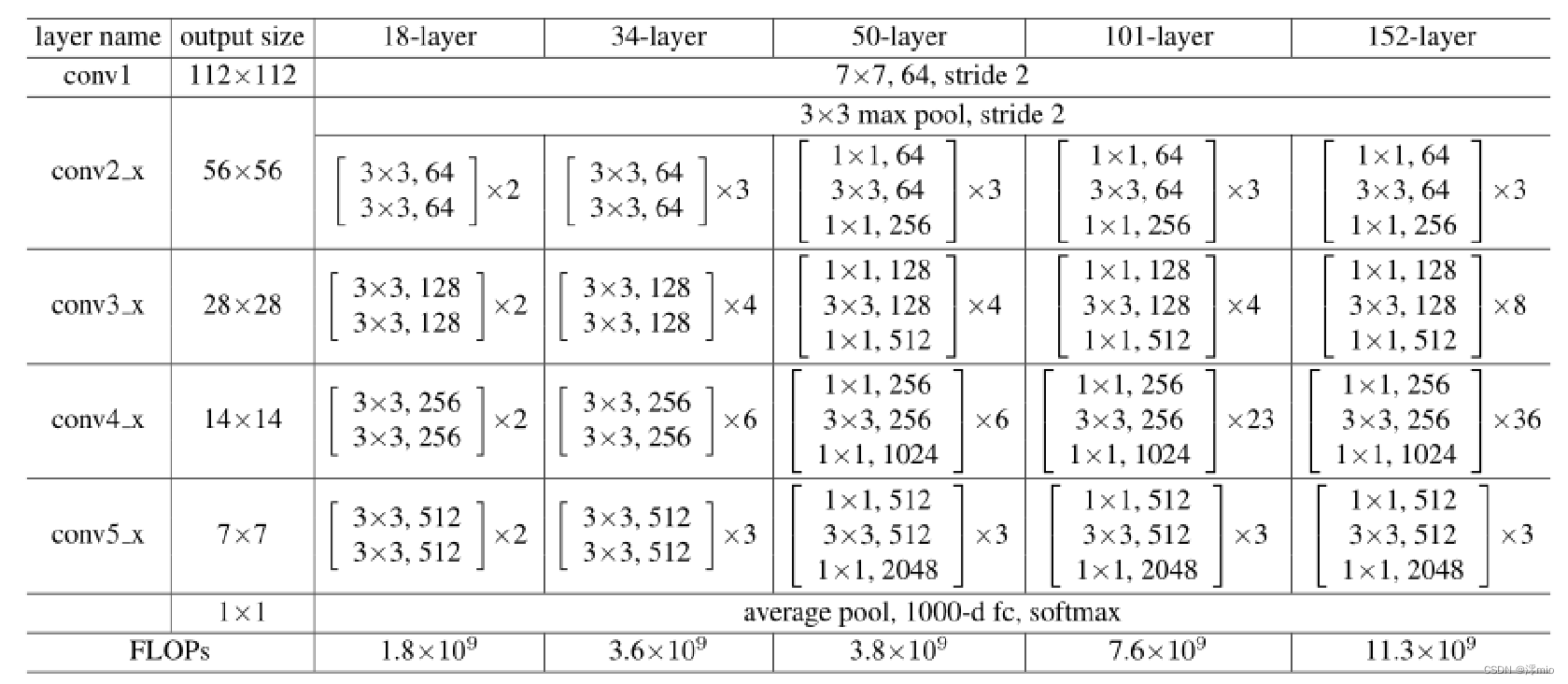
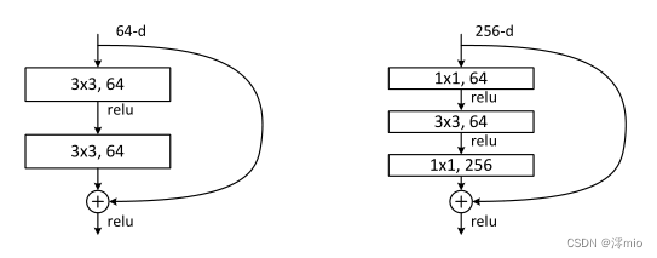
Deeper Bottleneck Architectures:
如何构建一个更深的网络呢?
对于每个残差函数 F,我们使用 3 层而不是 2 层的块。这三层分别是 1×1、3×3 和 1×1 卷积,其中 1×1 层负责减少然后增加(恢复)维度,使 3×3 层成为输入/输出维度较小的瓶颈。其中两种设计具有相似的时间复杂度。即,先降维再升维。
无参数的短路连接对于沙漏架构尤为重要。如果将中的恒等短路连接替换为投影,可以看出时间复杂度和模型大小加倍,因为短路连接连接了两个高维端。
50-layer ResNet:
101-layer and 152-layer ResNets:
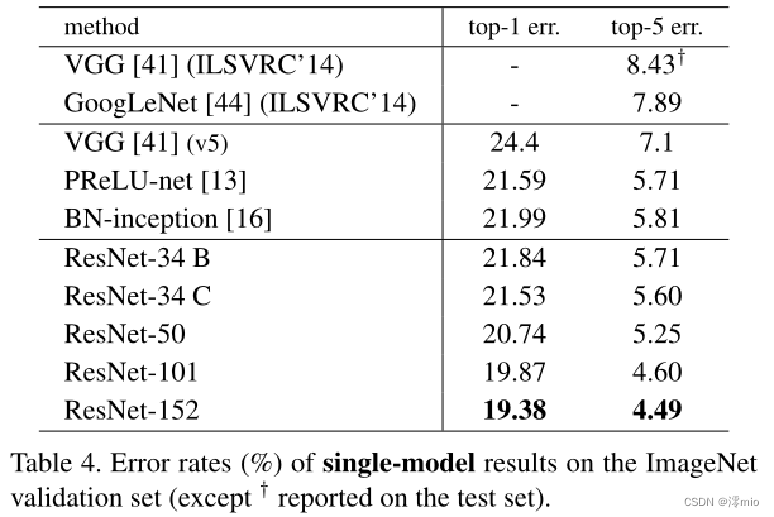
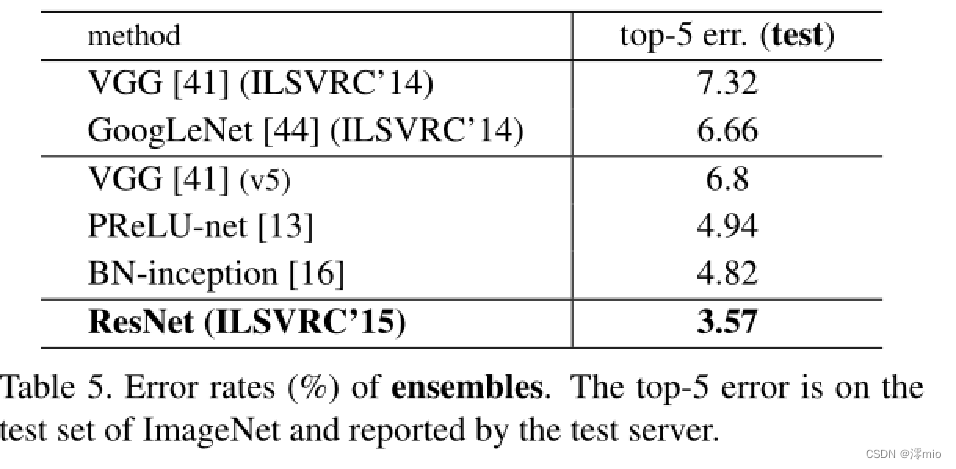
Comparisons with State-of-the-art Methods:
4.2 CIFAR-10 and Analysis
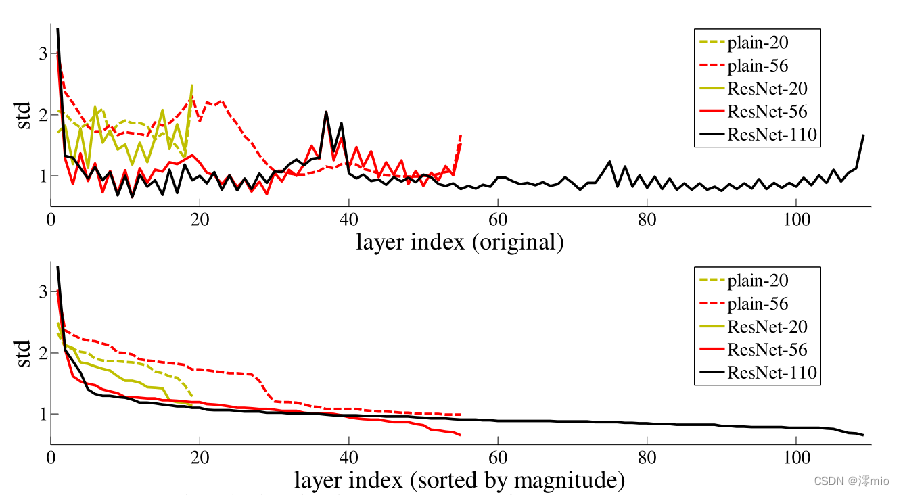
层响应分析。左图显示了层响应的标准偏差 (std)。响应是每个 3×3 层的输出,在 BN 之后和其他非线性(ReLU/加法)之前。对于 ResNets,该分析揭示了残差函数的响应强度。
ResNet 的响应通常比普通的响应小。这些结果支持我们的基本动机,即残差函数可能通常比非残差函数更接近于零。
我们还注意到,更深的 ResNet 的响应幅度更小。当层数更多时,ResNet 的单个层往往对信号的修改更少。
后记
ResNet是如此简洁高效,以至于模型提出后还有无数论文讨论“ResNet到底解决了什么问题(The Shattered Gradients Problem: If resnets are the answer, then what is the question?)”
即使BN过后梯度的模稳定在了正常范围内,但梯度的相关性实际上是随着层数增加持续衰减的。而经过证明,ResNet可以有效减少这种相关性的衰减。
对于L层的网络来说,没有残差表示的Plain Net梯度相关性的衰减在1/2^L ,而ResNet的衰减却只有 1/√L 。这也验证了ResNet论文本身的观点,网络训练难度随着层数增长的速度不是线性,而至少是多项式等级的增长(如果该论文属实,则可能是指数级增长的)
而对于“梯度消失”观点来说,在输出引入一个输入x的恒等映射,则梯度也会对应地引入一个常数1,这样的网络的确不容易出现梯度值异常,在某种意义上,起到了稳定梯度的作用。
除此之外,shortcut类似的方法也并不是第一次提出,之前就有“Highway Networks”。可以只管理解为,以往参数要得到梯度,需要快递员将梯度一层一层中转到参数手中(就像我取个快递,都显示要从“上海市”发往“闵行分拣中心”)。而跳接实际上给梯度开了一条“高速公路”(取快递可以直接用无人机空投到我手里了),效率自然大幅提高,不过这只是个比较想当然的理由。
第一个已经由Feature Pyramid Network[5]提出了,那就是短路连接相加可以实现不同分辨率特征的组合,因为浅层容易有高分辨率但是低级语义的特征,而深层的特征有高级语义,但分辨率就很低了。
第二个理解则是说,引入短路连接实际上让模型自身有了更加“灵活”的结构,即在训练过程本身,模型可以选择在每一个部分是“更多进行卷积与非线性变换”还是“更多倾向于什么都不做”,抑或是将两者结合。模型在训练便可以自适应本身的结构。
为什么使用1×1卷积?不就是乘以数字么?
过滤器为1×1,这里是数字2,输入一张6×6×1的图片,然后对它做卷积,起过滤器大小为1×1×1,结果相当于把这个图片乘以数字2,所以前三个单元格分别是2、4、6等等。用1×1的过滤器进行卷积,似乎用处不大,只是对输入矩阵乘以某个数字。但这仅仅是对于6×6×1的一个通道图片来说,1×1卷积效果不佳。如果是一张6×6×32的图片,那么使用1×1过滤器进行卷积效果更好。具体来说,1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。
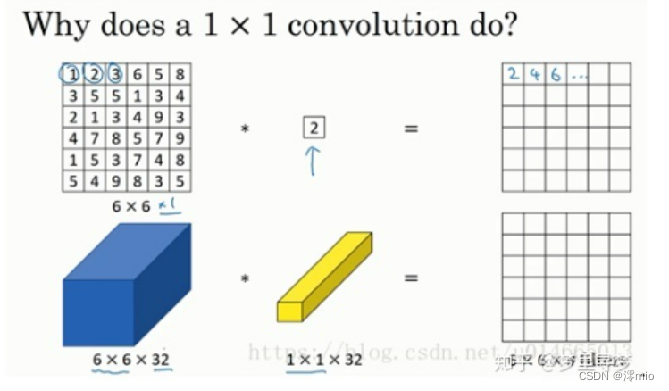

我们以其中一个单元为例,它是这个输入层上的某个切片,用这36个数字乘以这个输入层上1×1切片,得到一个实数,像这样把它画在输出中。这个1×1×32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字(输入图片中左下角位置32个通道中的数字),即相同高度和宽度上某一切片上的32个数字,这32个数字具有不同通道,乘以32个权重(将过滤器中的32个数理解为权重),然后应用ReLU非线性函数,在这里输出相应的结果。
一般来说,如果过滤器不止一个,而是多个,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6×6过滤器数量。
所以1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字(过滤器数量标记为,在这36个单元上重复此过程),输出结果是6×6×#filters(过滤器数量),以便在输入层上实施一个非平凡(non-trivial)计算。


这种方法通常称为1×1卷积,有时也被称为Network in Network,在林敏、陈强和杨学成的论文中有详细描述。虽然论文中关于架构的详细内容并没有得到广泛应用,但是1×1卷积或Network in Network这种理念却很有影响力,很多神经网络架构都受到它的影响
1×1卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。