开发机场景概述
目前很多企业在做AI开发的场景时,对GPU资源的管理都是非常简单粗暴的。他们大多都是以开发小组为管理单位、由运维以台为单位分配给开发工程师使用。而在AI开发中涉及开发的场景和测试的场景,很多是将开发测试甚至训练任务都放在一起来使用资源,这时用户就会在资源使用方面遇到一些问题:
从管理角度看,用户会遇到资源无法统一管理和调度、也无法做到很好的监控和资源统计的问题;从算法人员的角度看,他们面临的问题就是资源紧张须相互协调、无法灵活动态地使用和申请资源的问题。
基于上述问题,OrionX AI算力资源池化解决方案给出了相应的解决思路,旨在为用户提高GPU利用率、提供灵活调度平台、统一管理算力资源,实现弹性扩展,按需使用。
根据算法工程师的使用习惯,我们归纳了三种开发机场景:
SSH模式:该模式就给算法人员一台机器,无论是物理机还是虚机或者是容器,由算法人员直接远程连接进行算法的开发使用资源。
Jupyter模式:Jupyter也是最近几年算法人员使用比较多的一种工具,很多企业已经将其改造集成开发工具,可以将Jupyter部署在容器或者虚机给算法人员使用。
CodeServer模式:微软的VSCode的服务器版本,近年也有很多企业在采用该工具,使用资源的方式类似Jupyter,也是部署在虚机或者容器当中。
我们将通过三篇文章逐一介绍OrionX vGPU基于这三种场景的最佳实践,今天,让我们从SSH开始探索。
环境准备
环境包含物理机器或者虚机、网络环境、GPU卡,操作系统以及容器平台。
硬件环境
本次POC环境准备三台虚机,其中一台CPU节点,两台GPU节点,每台GPU节点有一块T4卡。
操作系统为ubuntu 18.04
管理网络:千兆TCP
远程调用网络:100G RDMA
Kubernetes环境
三个节点安装K8s环境,可以使用kubeadm来安装,或者一些部署工具:
kubekey
kuboard-spray
当前部署Kubernetes环境如下:
root@sc-poc-master-1:~# kubectl get node
NAME STATUS ROLES AGE VERSION
sc-poc-master-1 Ready control-plane,master,worker 166d v1.21.5
sc-poc-worker-1 Ready worker 166d v1.21.5
sc-poc-worker-2 Ready worker 166d v1.21.5其中master为CPU节点,worker节点为2个T4 GPU节点。
OrionX vGPU池化环境
参考趋动科技《OrionX 实施方案-K8s版》,部署完之后我们可以在orion的namespace查看OrionX组件:
root@sc-poc-master-1:~# kubectl get pod -n orion
NAME READY STATUS RESTARTS AGE
orion-container-runtime-hgb5p 1/1 Running 3 63d
orion-container-runtime-qmghq 1/1 Running 1 63d
orion-container-runtime-rhc7s 1/1 Running 1 46d
orion-exporter-fw7vr 1/1 Running 0 2d21h
orion-exporter-j98kj 1/1 Running 0 2d21h
orion-gui-controller-all-in-one-0 1/1 Running 2 87d
orion-plugin-87grh 1/1 Running 6 87d
orion-plugin-kw8dc 1/1 Running 8 87d
orion-plugin-xpvgz 1/1 Running 8 87d
orion-scheduler-5d5bbd5bc9-bb486 2/2 Running 7 87d
orion-server-6gjrh 1/1 Running 1 74d
orion-server-p87qk 1/1 Running 4 87d
orion-server-sdhwt 1/1 Running 1 74d开发机场景:SSH远程连接模式
本次测试,我们启动一个Pod资源,分配OrionX vGPU资源,然后通过kubectl exec的方式进入Pod进行开发,该Pod使用的镜像是官方的TensorFlow镜像:tensorflow/tensorflow:2.4.3-gpu。
部署的Yaml文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
name: tf-243
namespace: orion
spec:
replicas: 1
selector:
matchLabels:
name: tf-243
template:
metadata:
labels:
name: tf-243
spec:
#nodeName: sc-poc-master-1
hostNetwork: true
schedulerName: orion-scheduler
containers:
- name: tf-243
image: tensorflow/tensorflow:2.4.3-gpu
imagePullPolicy: Always
#imagePullPolicy: IfNotPresent
command: ["bash", "-c"]
args: ["while true; do sleep 30; done;"]
resources:
requests:
virtaitech.com/gpu: 1
limits:
virtaitech.com/gpu: 1
env:
- name : ORION_GMEM
value : "5000"
- name : ORION_RATIO
value : "60"
- name: ORION_VGPU
value: "1"
- name: ORION_RESERVED
value: "1"
- name: ORION_CROSS_NODE
value: "1"
- name: ORION_EXPORT_CMD
value: "orion-smi -j"
- name: ORION_CLIENT_ID
name: "orion"
- name : ORION_GROUP_ID
valueFrom:
fieldRef:
fieldPath: metadata.uid
- name: ORION_K8S_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ORION_K8S_POD_UID
valueFrom:
fieldRef:
fieldPath: metadata.uid关于OrionX详细参数可以参考《OrionX 用户手册》,此处介绍几个常用的参数:
ORION_VGPU:指的是申请的OrionX vGPU个数,比如1个或者多个
ORION_GMEM:指的是申请的显存大小,以MB计算,5000就是5GB的显存大小
ORION_RATIO:指的是申请的算力大小,OrionX vGPU的算力切分是按照物理卡的百分比进行切分的,此处填入的数字是一个百分比的数字,60就代表申请了单张物理卡60%的算力,最小单位是1%,最大是100%。100%的时候表示该vGPU申请了整张物理卡的资源。
ORION_RESERVED:指的是申请的资源是预留模式,OrionX申请资源时有两种模式一种是预留,一种是非预留。预留模式就是资源预分配,在Pod启动时就已经分配了,不论该Pod是否运行了AI任务跟使用物理GPU时类似;非预留模式就是Pod启动时并没有分配资源,只有当有AI任务运行的时候才会真正的分配,等任务结束,资源就会被自动释放。
采用预留模式申请资源
本次测试先使用预留模式申请资源,部署TF镜像:
# kubectl create -f 09-deploy-tf-243-gpu.yaml
# kubectl get pod
NAME READY STATUS RESTARTS AGE
tf-243-84657d76b5-jqqc8 0/1 ContainerCreating 0 30m
# 等着拉镜像启动通过查看OrionX GUI,该OrionX vGPU资源已经被分配。由于是预留模式,所以无论资源是否被使用,都会预分配资源。
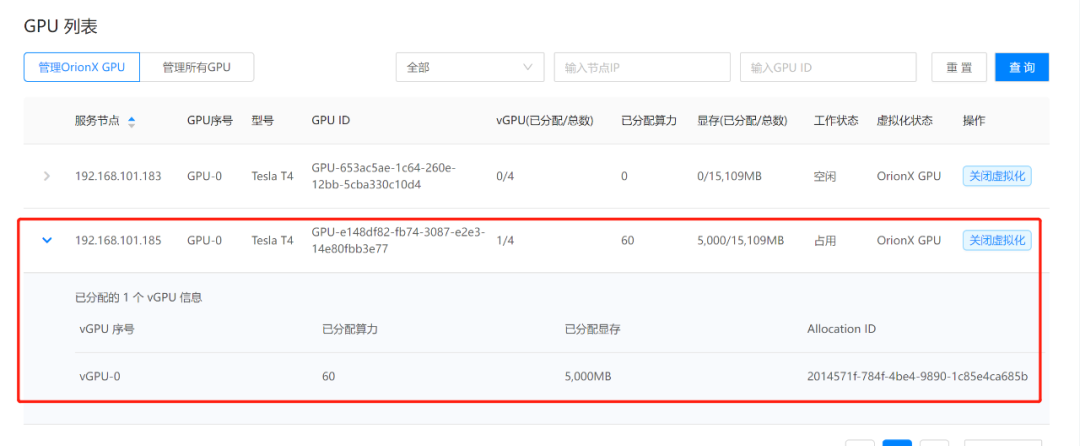
启动Pod之后,我们进入Pod查看申请的资源是否已经生效
root@sc-poc-master-1:~# kubectl exec -it tf-243-84657d76b5-jqqc8 -- bash
________ _______________
___ __/__________________________________ ____/__ /________ __
__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / /
_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ /
/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/
WARNING: You are running this container as root, which can cause new files in
mounted volumes to be created as the root user on your host machine.
To avoid this, run the container by specifying your user's userid:
$ docker run -u $(id -u):$(id -g) args...
root@sc-poc-master-1:/# env | grep -iE "vgpu|gmem|ratio|rese"
ORION_GMEM=5000
ORION_RESERVED=1
ORION_RATIO=60
ORION_VGPU=1通过环境变量查看,申请的资源已经生效了。
由于该镜像是官方的镜像,该TensorFlow的base os镜像是Ubuntu 18.04,所以更新下国内源,然后安装下Git,我们后续下载一个TensorFlow benchmark作为测试脚本来模拟开发测试。
# sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
# apt update
# apt install git -y
# git clone https://github.com/tensorflow/benchmarks下载完TensorFlow Benchmark之后,我们就可以直接跑该Benchmark模拟一个训练的任务,该运行模式就跟实际研发场景类似,在Pod里面写代码之后运行代码,Benchmark运行代码如下:
python3 ./benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--forward_only=False \
--data_name=imagenet \
--model=resnet50 \
--num_batches=200 \
--num_gpus=1 \
--batch_size=32正常跑起来之后,我们会看到窗口有一个输出
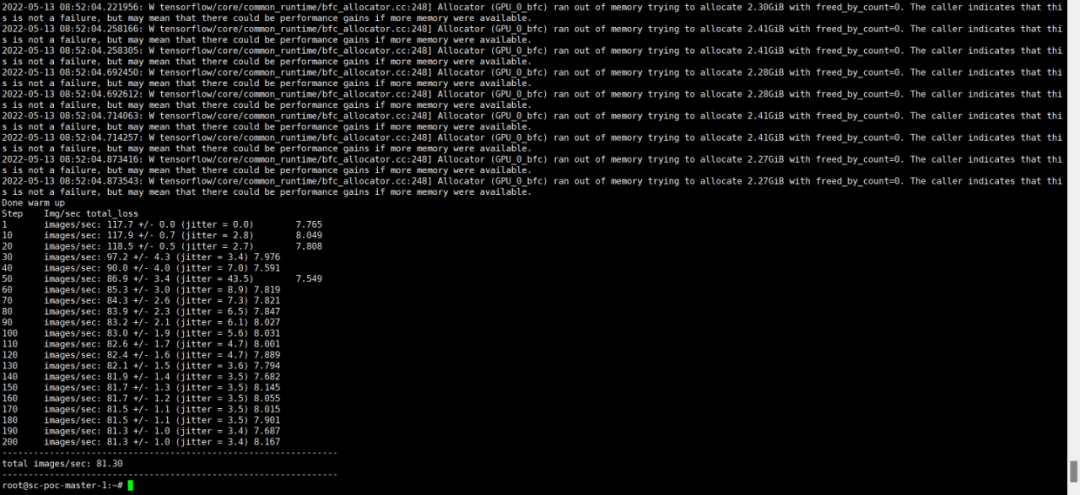
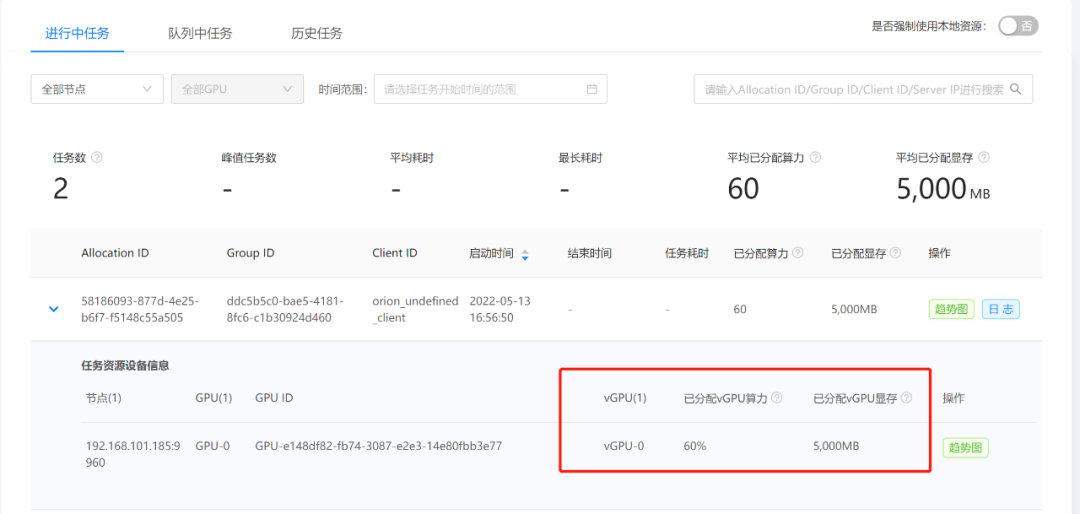
该结果显示每秒训练了81.3张图片,通过OrionX GUI的任务界面我们也能看到该任务的运行,该任务被分配了60%的算力和5G显存,跟实际申请的资源一样。
采用非预留模式申请资源
前面是预留模式,本次将yaml文件部署的参数ORION_RESERVED改成0,就是非预留模式。非预留模式在Pod启动时并不会分配资源,只有当有任务运行的时候才会分配资源。该模式能将GPU资源分时复用的效率提升数倍,同时有了该功能在研发测试场景也可以将GPU资源进行超分配,进一步提高资源利用率。
Pod启动之后,通过OrionX GUI界面发现,并没有资源被申请。
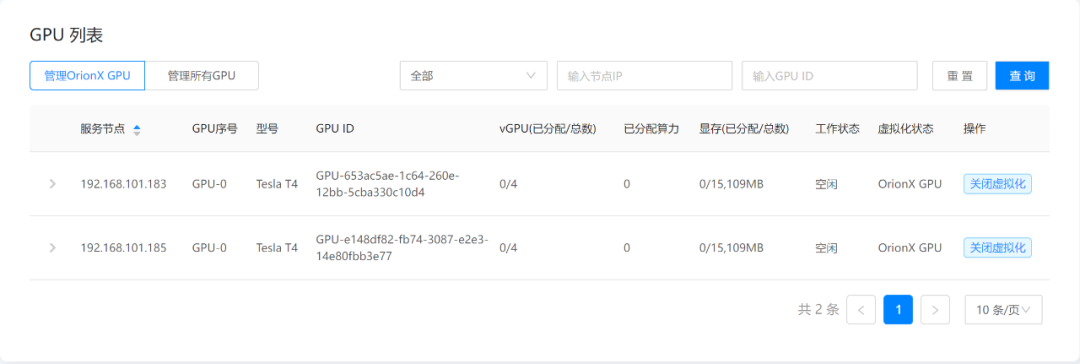
我们同样来运行一个上面的Benchmark任务,发现在任务启动时候资源已经被申请到了。
python3 ./benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--forward_only=False \
--data_name=imagenet \
--model=resnet50 \
--num_batches=200 \
--num_gpus=1 \
--batch_size=32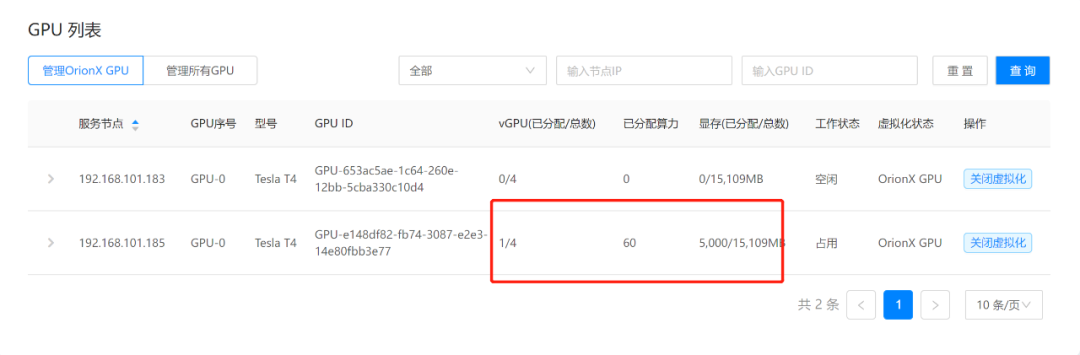
等任务结束我们再去OrionX GUI查看资源又被动态释放掉,通过该模式我们能提高GPU资源的分时复用效率,可以将平均利用率提升3-5倍。
通过SSH远程POD
前面都是通过kubectl命令行进入Pod,那么在很多企业中是不会直接给算法人员该权限的,那么我们是否可以通过远程虚机的方式远程一个Pod呢,答案是肯定的。接下来我们就介绍如何通过SSH远程一个Pod进行开发。远程连接Pod需要的条件跟远程虚机一样:开启SSH端口、配置用户名密码(或者秘钥方式)、开启远程连接的端口和连接方式。
开启Pod的SSH端口
要开启SSH端口,我们就需要改造原有的镜像,我们需要安装SSH服务,并在启动是时候启动sshd服务,改造的Dockerfile如下,同时为了测试方便,我们把benchmark脚本也clone到镜像里面:
配置秘钥
为了保证安全,我们本次通过秘钥的方式远程连接Pod,首先我们可以通过xshell或者直接Linux命令行生成我们自己的秘钥,然后通过configmap的方式把秘钥挂载给Pod,configmap如下:
# cat ssh-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: ssh-config
data:
sshd_config: |
PasswordAuthentication no
ChallengeResponseAuthentication no
UsePAM no
authorized_keys: |
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAwgGoBqurkauiio8zhh6HRX/8PJ0daXmnW38EyvIghW9au7qG3yBjxEzsDcPpUILne1gMmb6WO1+IdENPIsqZ1ycsfrKjpCbeXUKL7vbuUasBKlkoG/xvhCy1G+GTEwSdyPQnjYsE5cnTedIvbd0wfSjgtMqa3D4fKT/1eCBoGs8n4yPKOZo8l/jKFv5/ph8qi5uvNPMdWx43+4prpOVN8oPLWRSFJ1WZ8zTRGOwnkdi0LZLrbQ7OqMaEsUKrMndAH56e9MToex2J3ngbTYceFGo2SWCKGAmy32RFvmoxHfCjUQlcGvElNh5OEPlBSGMc5RLXQlrzpD5iVm7hkzgxzQ==修改该镜像的启动参数和挂载configmap,Pod启动Yaml如下:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
name: tf-243
namespace: orion
spec:
replicas: 1
selector:
matchLabels:
name: tf-243
template:
metadata:
labels:
name: tf-243
spec:
nodeName: sc-poc-worker-1
#hostNetwork: true
schedulerName: orion-scheduler
containers:
- name: tf-243
image: tensorflow/tensorflow:2.4.3-gpu-ssh
imagePullPolicy: IfNotPresent
#imagePullPolicy: IfNotPresent
#command: ["bash", "-c"]
#args: ["while true; do sleep 30; done;"]
resources:
requests:
virtaitech.com/gpu: 1
limits:
virtaitech.com/gpu: 1
env:
- name : ORION_GMEM
value : "5000"
- name : ORION_RATIO
value : "60"
- name: ORION_VGPU
value: "1"
- name: ORION_RESERVED
value: "0"
- name: ORION_CROSS_NODE
value: "1"
- name: ORION_EXPORT_CMD
value: "orion-smi -j"
- name: ORION_CLIENT_ID
name: "orion"
- name : ORION_GROUP_ID
valueFrom:
fieldRef:
fieldPath: metadata.uid
- name: ORION_K8S_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ORION_K8S_POD_UID
valueFrom:
fieldRef:
fieldPath: metadata.uid
ports:
- containerPort: 22
volumeMounts:
- name: ssh-volume
subPath: sshd_config
mountPath: /etc/ssh/sshd_config
- name: ssh-volume
subPath: authorized_keys
mountPath: /root/.ssh/authorized_keys
volumes:
- name: ssh-volume
configMap:
name: ssh-config 通过NodePort方式远程连接Pod
如果有条件的可以通过LB的方式,目前我们这里通过NodePort方式提供Pod一个连接地址,创建svc如下:
apiVersion: v1
kind: Service
metadata:
name: ssh-service
spec:
type: NodePort
ports:
- protocol: TCP
port: 22
targetPort: 22
selector:
name: tf-243部署该TensorFlow镜像并通过xshell远程
将以上yaml文件直接部署,部署出来如下:
# kubectl get pod
NAME READY STATUS RESTARTS AGE
tf-243-9fb569b9d-klmtj 1/1 Running 0 12m
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ssh-service NodePort 172.16.7.214 <none> 22:32550/TCP 2d通过svc查看,映射了一个32550的端口,我们通过xshell远程宿主机IP加32550端口,就可以远程该服务了。我们使用前面的脚本再跑下benchmark,可以正常运行,至此我们就可以通过SSH远程该Pod进行开发了。
以上就是OrionX vGPU在SSH模式下的开发机场景的最佳实践。我们将在以后的文章中继续分享OrionX vGPU基于Jupyter和CodeServer模式下的开发实践,欢迎留言探讨!