操作系统用于处理内存访问异常的入口操作系统的核心任务是对系统资源的管理,而重中之重的是对CPU和内存的管理。为了使进程摆脱系统内存的制约,用户进程运行在虚拟内存之上,每个用户进程都拥有完整的虚拟地址空间,互不干涉。而实现虚拟内存的关键就在于建立虚拟地址(Virtual Address,VA)与物理地址(Physical Address,PA)之间的关系,因为无论如何数据终究要存储到物理内存中才能被记录下来。
从事十年嵌入式转内核开发(23K到45K),给兄弟们的一些建议
腾讯T6-9首发“Linux内核源码嵌入式开发进阶笔记”,差距不止一点点哦
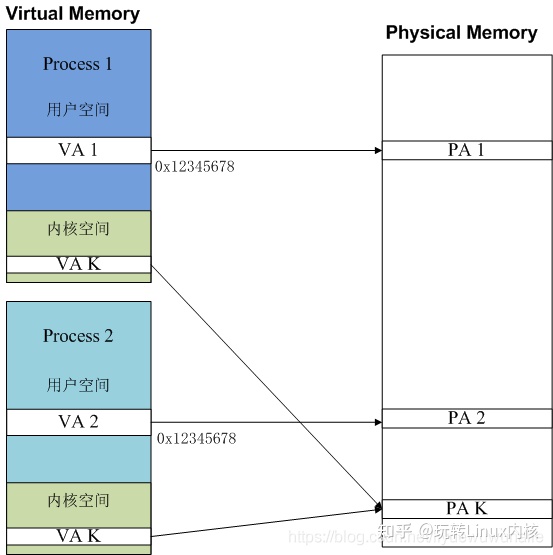
如下图所示,进程1和进程2拥有完整的虚拟地址空间,虚拟地址空间分为了用户空间和内核空间,对于不同的进程面对的都是同一个内核,其内核空间的地址对于的物理地址都是一样的,因而进程1和进程2中内核空间的VA K地址都映射到了物理内存的PA K地址。而不同的进程的用户空间是不同的,进程1和进程2相同的虚拟地址VA 1和VA 2分别映射到了不同的物理地址PA 1和PA 2上。
而虚拟地址到物理地址映射关系的实现可以称之为地址转换(Address Translation)。为了实现上述地址转换,操作系统需要借助硬件的帮助,即内存管理单元(Memory Management Unit,MMU)的帮助。
资料直通车:
Linux内核源码技术学习路线+视频教程代码资料docs.qq.com/doc/DTkZRWXRFcWx1bWVx正在上传…重新上传取消
内核学习直通车:
Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈-学习视频教程-腾讯课堂ke.qq.com/course/4032547?flowToken=1040236
对于MMU应当有如下功能:
| 要求 | 说明 |
|---|---|
| 特权模式 | 区分内核空间和用户空间,用户进程无法直接访问内核地址空间 |
| 基址/界限寄存器 | 记录地址转换基址的寄存器,用于寻址地址转换映射表 |
| 地址转换 | 完成地址转换过程 |
| 异常处理特权操作指令 | 操作系统用于处理内存访问异常的入口 |
MMU配合操作系统完成了诸多功能:
用户空间和内核空间,通过特权模式划分了内核空间和用户空间,用户空间无法直接访问内核空间,必须通过某些手段(系统调用,异常,中断等)切换到特权模式才能间接访问内核。
地址转换,通过基址/界限寄存器记录的转换映射表基址,结合虚拟地址,可以完成地址转换的功能,从而实现通过虚拟地址访问到物理地址。进程独立的虚拟地址空间,通过基址/界限寄存器的访问指令,在进程切换时修改基址/界限寄存器的值,从而使MMU在做地址转换时找到各个进程对应的地址映射表,从而实现不同进程虚拟地址完全独立。缺页异常,对于进程申请的内存,并不需要在其申请内存时即建立地址转换映射表,同时分配对应的物理空间,而是在进程真正访问内存地址时,MMU上报缺页异常再分配对应的物理空间。当然虚拟地址到物理地址映射表中的一些标志区可以实现更多的缺页异常类型,例如读写权限错误,特权错误,越界错误等异常。
本文重点关注地址转换,而地址转换的核心是页表映射。
一、分页
分页即将内存划分为固定长度的单元,每个单元就是一页。对于虚拟地址空间,分页机制将地址空间分割成固定大小的单元,每个单元称为一页。对于物理地址空间,物理内存被抽象成固定大小的单元,每个单元称为页帧(frame)。通过分页管理内存可以避免分段带来的内存外碎片问题。分页管理内存的核心问题是虚拟地址页到物理地址页帧的映射关系。虚拟地址到物理地址的转换可以抽象简化成下图,假设地址是32位的。
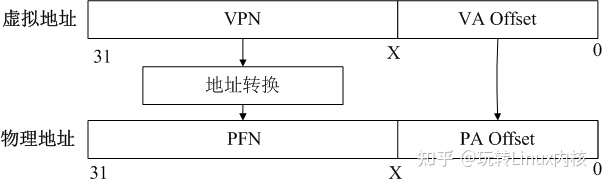
为了将虚拟地址转换成物理地址,将虚拟地址分割成两部分:
- 虚拟页面号,高31-X位组成,VPN(virtual page number);
- 虚拟地址偏移,低X位组成,VA Offset(virtual address offset);
物理地址也抽象成两部分:
- 物理页帧号,高31-X位组成,PFN(physical frame number);
- 物理地址偏移,低X位组成,PA Offset(physical address offset);
虚拟页面号VPN用于索引物理页帧号PFN,VPN索引PFN的过程就是地址转换的核心。VA offset通常就是PA offset,即PFN + VA offset就是最终物理地址。
所以,可以说分页机制的核心就是VPN到PFN的映射。而VPN到PFN的映射关系是通过页表记录的。MMU通过页表记录的映射关系完成VPN到PFN的转换,即找到了页表就找到了物理地址。
1.1 页表存在哪里?
以32位地址空间为例,分页大小为4KB(最常用的分页大小),上述抽象例子中的X为12,那么VPN长度就是20bit,偏移量为12bit。
20bit的VPN意味着操作系统需要2^20个地址转换映射,假设每个转换映射需要4Byte空间存储,那么所有映射关系需要4MB空间。
开篇我们提到,进程的虚拟地址到物理地址的转换是不同的,所以每个进程的映射关系也是不同的,就是说每个进程都需要4MB的空间来存储页表。如果操作系统运行100个进程,则需要400MB空间。
可见页表所需要的空间是很大的,所以页表都存储在物理内存中。即MMU通将虚拟地址转换为物理地址,需要访问物理内存中对应的页表。
当然页表占用物理内存大的问题还是需要解决的,这是分页相对于分段的一个劣势,解决方案是多级页表配合缺页异常的方式,后面再详细介绍多级页表的机制。
1.2 页表长啥样?
页表是如何完成VPN到PFN的转换的,要知道这个问题就得清楚页表的基本内容,即页表记录了什么信息。
页表的作用就是通过VPN找到PFN,那么页表最基本的组成部分需要包含如下内容:
- PFN物理页帧号;
- 有效位(valid),用于标记页面是否有效;
- 存在位(present),指示该页是否存在于物理内存,用于页面换入换出(swap);
- 特权标记,指示页面访问的特权等级;
- Dirty位,写操作时设置该位,表示页面被写过,页面交换时使用;
1.3 分页机制如何完成进程地址空间切换?
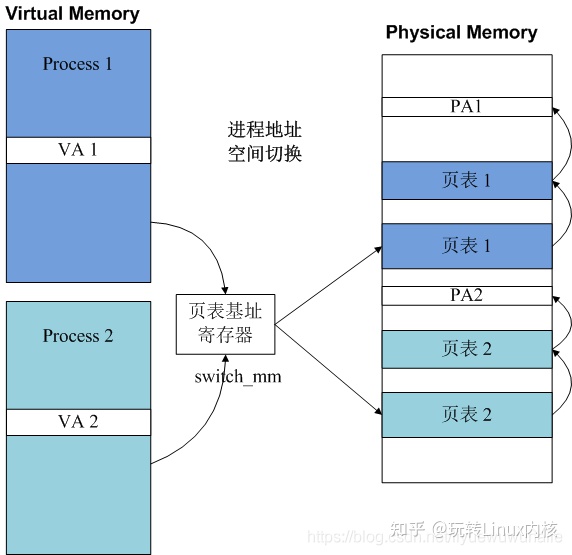
每个进程都拥有自己独立的地址空间,进程切换时地址空间也会切换。不同进程都拥有自己的一套页表,因而即使两个进程虚拟地址相同,映射的物理地址也是不同的。切换地址空间相当于控制MMU访问不同进程拥有的页表,MMU找到了页表就找到了物理地址。通常CPU会提供若干寄存器供操作系统使用,用于为MMU指示页表的基地址。
如下图所示,进程切换时,只需要设置页表基址寄存器即可完成页表的切换,也就完成了进程地址空间的切换。所以CPU会为操作系统提供页表基址寄存器用于进程地址空间的切换。
X86体系架构提供的寄存器是CR3(Control Register 3);ARM-v7体系架构提供的寄存器是协处理器CP15寄存器TTBR(Tranlation Table Base Register);ARM-v8体系架构提供的寄存器是系统寄存器TTBR(Tranlation Table Base Register)。
1.4 实际使用的分页机制
考虑到分页机制占用内存过多的问题,实际的分页机制是多级分页。
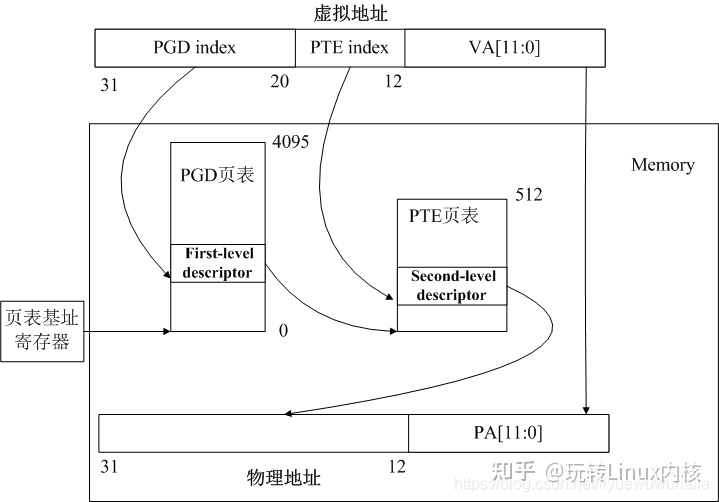
以二级页表为例,如下图所示,MMU通过页表基址寄存器配合虚拟地址中的PGD index(Page Global Directory)找到一级页表,通过一级页表配合虚拟地址中的PTE index(Page Table Entry)找到二级页表,通过二级页表配合虚拟地址中Offset找到物理地址。
多级页表要做到节省内存,还需要配合缺页异常,进程往往只需将一级页表保持到内存中,二级页表在缺页异常时再分配。
下图示例中,一级页表一共4096项(212),二级页表一共512项(29)。因此进程页表可以只使用4096 X 4Byte空间即可。如果使用一级页表,则需要2097152 X 4Byte空间。因此多级页表带来的最大好处就是降低了内存空间的占用。
1.5 多级页表的缺点
多级页表带来了好处,降低了操作系统进程管理,内存管理对内存空间的占用。当然计算机领域总是没有那么完美的方案,多级分页也逃避不了这个宿命,获得了空间的优势,也带来时间上的损失。
多级分页时间上的损失主要体现在如下几个方面:
用时下发的耗时:对于子进程写时复制(COW)技术大家比较熟悉,其实多级页表也利用了类似的思想。多级页表的后几级页表映射关系没有存在内存中,MMU地址转换中发现页表不存在需要向操作系统上报缺页异常,操作系统需要在缺页异常中下发页表到内存;
额外的内存访问:MMU进行地址转换需要通过页表基址寄存器找到一级页表,再依次找到下级页表,所有的页表都存放在内存中,访问内存是需要额外的时间消耗的,相对于CPU对寄存器的访问,Cache的访问速度而言,内存的访问速度是灾难性的,何况还是多次访问。当然额外的内存访问本身是分页机制相对分段机制的缺陷,一级页表映射也存在这样的缺陷,只是多级页表映射将这个缺点再次放大。
1.6 Translation Lookside Buffer
Translation Lookside Buffer简称TLB,按其真实作用应当翻译为地址转换缓存。
方才抨击了多级页表映射基址,提出了它可能导致系统变慢的缺点,那么如何解决这一问题呢?如果使MMU做页表转换时不访问内存,是不是就解决问题了?TLB就是干这个事的。
TLB之所以可以解决这个问题是因为TLB是Cache,它将CPU访问内存替换为CPU访问Cache,也就是说MMU做页表转换时不再访问内存的页表,而是访问缓存在TLB中的页表,因而降低了时间的消耗。
TLB要实现这个替换,其需要实现的基本工作原理是:
从虚拟地址中提取页号(VPN),检查TLB是否有该VPN的转换映射。
如果有,则表示TLB命中(TLB hit),意味着从TLB中找到VPN对应的物理页框号(PFN)。PFN与虚拟地址的偏移量组成成物理地址(PA)。
如果没有,表示TLB未命中(TLB miss),则需要处理TBL miss。
TLB miss处理有两种方法,一种是硬件处理,一种是软件处理。硬件处理TLB miss会自动更新TLB。软件处理则是由硬件抛出一个TLB miss异常,软件进入异常处理程序,查找物理页表中转换映射,再由指令更新TLB,并从异常中返回。
软件处理TLB miss异常与其他异常不同,异常处理返回后,应继续执行陷入异常之后的那条指令,而TLB miss异常处理返回后,从导致陷入异常的执行开始执行。这样保证TLB一定命中。
诚然,TLB是好,但是也引入了一些麻烦事(既然是Cache,就有一致性问题):进程切换时TLB如何处理?TLB表项满了如何处理?mmap映射的内存被munmap解除TLB怎么处理?……
针对这些话题本文不做深入探讨,可以阅读另一篇为其量身定做的博文《深入Linux内核(内存篇)—TLB》。
1.5 页表多大合适?
大页表的好处:
省内存:可以解决分页机制占用内存的问题,取得和多级页表一样节省内存的效果;
对TLB友好:大页表意味着地址转换时需要更少的页表映射表项,页表映射表项少了意味着TLB缓存的表项少,这样就提高了TLB的命中率;
大页表的坏处:
内存内碎片:操作系统申请内存时总是申请一大块内存,哪怕实际只需要很小的内存,导致大页内存得不到充分利用;而且内存很快会被这些大页侵占。
显然小页表的好处和坏处正好与大页表对立。
因此页表不是越大越好,也不是越小越好,找到折中的大小是才最适合。通常操作系统的使用的页大小是4KB。
各种体系架构的CPU都支持很多种页大小。因此实际页表的应用可能会更“聪明”,用户进程在请求地址空间时,可以因需求选择合适的页大小,这样既可以满足数据的存放,同时占用更少的TLB表项。一个典型的例子,DPDK使用了1GB的大页内存,这样DPDK进程的页表映射只占用一个TLB表项,在进程执行过程中杜绝了TLB miss情况的发生,保障了性能。
二、X86中的分页
X86中定义分页即将每个线性地址转换为物理地址,并确定对于每个转换,允许对线性地址的何种访问(地址的访问权限)以及用于此类访问的缓存类型(地址的内存类型)。
X86支持如下四种分页模式:

分页模式的选择主要由control register CR0,control register CR4,IA32_EFER MSR控制。
由上表可以看出:
- CR0.PG = 0,关闭分页单元,线性地址被直接解释成物理地址;
- CR0.PG = 1 && CR4.PAE = 0,使用32-bit分页机制,线性地址大小是232,物理地址大小可以达到240,支持的页大小是4KB和4MB;
- CR0.PG = 1 && CR4.PAE = 1,使用PAE(Physical Address Extension)分页机制,线性地址大小是232,物理地址大小可以达到252,支持的页大小是4KB和2MB;
- CR0.PG = 1 && CR4.PAE = 1 && IA32_EFER.LME = 1,使用4级分页机制,线性地址大小是248,物理地址大小可以达到252,支持的页大小是4KB、2MB和1GB;
- CR0.PG = 1 && CR4.PAE = 1 && IA32_EFER.LME = 1 && CR4.LA57 = 1,使用5级分页机制,线性地址大小是257,物理地址大小可以达到252,支持的页大小是4KB、2MB和1GB;
2.1 32-bit Paging
寄存器状态CR0.PG = 1 && CR4.PAE = 0 && IA32_EFER.LME = 0 时,X86选择32-BIT PAGING分页模式。
32-BIT PAGING分页模式支持页大小是4KB和4MB两种。
以4KB大小页为例,其分页机制如下图所示:
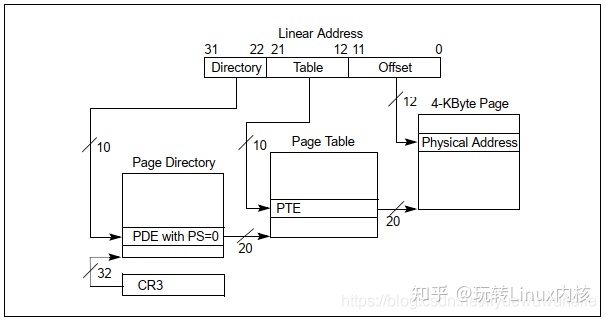
32bit线性地址被划分为3部分:
- Directory[31:22]:最高10bit;
- Table[21:12]:中间10bit;
- Offset[11:0]:最低12bit。
其原理与第一节所述原理如出一辙。页表基址寄存器为CR3,用于索引一级页表Page Directory(PDE),Page Directory用于索引二级页表Page Table(PTE),Page Table和Offset共同找到Physical Address。
2.2 32-bit Paging页表长啥样?
如下图所示是32-BIT PAGING分页模式下,CR3寄存器和一级页表PDE,二级页表PTE的长相。

CR3寄存器
- Address of page directory[31:12]:线性地址转换一级页表物理地址,用于配合线性地址Page Directory找到一级页表物理地址;
- PCD[4]:Page-level cache disable
- PWT[4]:Page-level write-through
PDE
- Page size[7]:指定页大小,为1则页大小为4MB,为0则页大小为4KB,页大小不同则PDE的结构也不同,我们只看PS=0的情况,即4KB页大小;
- Present[0]:存在位,为1表示此页在内存中,为0表示此页不在内存中。地址转换时,发现此位为0,则MMU将该地址放入CR2寄存器,并产生缺页异常。
- Read/write[1]:读写权限,为0表示该页表只读;
- User/supervisor[2]:特权等级,为0则用户模式无法访问该页表;
- Page-level write-through[3]:控制Cache处理页表方式,指定Cache直写和回写策略;
- Page-level cache disable[4]:控制Cache处理页表方式,指定Cache是否禁用;
- Accessed[5]:访问页框时置位;
- Address of page table[31:12]:线性地址转换二级页表物理地址,用于配合线性地址Page Table找到二级页表物理地址;
PTE
- [5:0]:与PDE一样;
- Dirty[6]:对页框进行写操作时置位;
- Global[8]:CR4.PGE = 1时有效,防止常用页从TLB中Flush掉。
- Address of page table[31:12]:线性地址转换物理地址,用于配合线性地址Offset找到物理地址;
- 其长相与第一节所述如出一辙。
2.3 -Level Paging
再来看一个4级页表分页模式,支持的页大小是4KB、2MB和1GB。
以4KB页大小为例,如下图所示,显然相比于32-bit Paging,4-Level Paging扩展了线性地址(48bit)和物理地址(52bit)。
随着计算机的发展,32bit的地址空间显很局促,尤其是物理寻址范围也只有32bit,即4GB物理地址空间,在计算机发展初期4GB空间是天文数字,现在已经沦落到选择个人PC都看不上4GB内存,起码是8GB内存起步。这也是为什么X86 32位CPU支持PAE(Physical Address Extension)的原因。同样的,ARM-v7也支持了LPAE(Large Physical Address Extension),名字虽不同,但困境如出一辙。
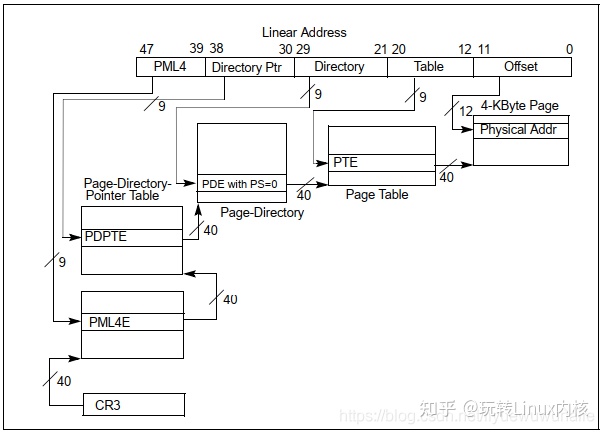
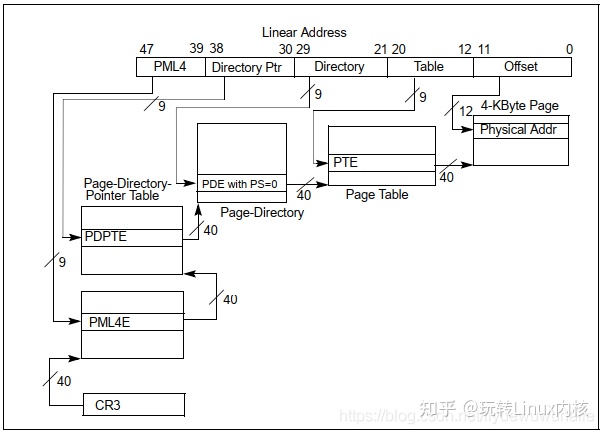
4级页表映射其原理与32bit Paging是一样的。将47bit线性地址被划分为5部分:
- PML4[47:39]:最高9bit;
- Directory Ptr[38:30]:中间9bit;
- Directory [29:21]:中间9bit;
- Table[20:12]:中间9bit;
- Offset[11:0]:最低12bit。
地址转换过程也是一样,从CR3开始逐级找到Physical Address,这里不再赘述了。
三、ARM中的分页
看完了X86中的分页,再看ARM中分页。
3.1 ARMv7 Paging
ARMv7架构支持三种页大小:1MB,64KB和4KB。同时ARMv7支持LPAE,可以将物理地址范围扩大到40bit。
以4KB页大小,未开启LPAE为例,如下图所示。

32bit线性地址被划分为3部分:
- L1 Table Index[31:20]:最高12bit;
- L2 Table Index[19:12]:中间8bit;
- Page Index[11:0]:最低12bit。
地址转换过程,TTBR寄存器Translation base[31:14]和虚拟地址的L1 Table Index[31:20]索引到一级页表物理地址,一级页表Page table base address[31:10]和虚拟地址L2 Table Index[19:12]索引到二级页表物理地址,二级页表Small page base address[31:12]和虚拟地址的Page Index[11:0]索引到物理地址。
3.2 ARMv7 4KB Paging页表长啥样?
ARMv7 4KB分页机制采用二级页表管理,其一级页表属性如下图所示。

Page table base address[31:10]:线性地址转换二级页表物理地址,用于配合线性地址Page Table找到二级页表物理地址;
NS[3]:Non-secure,非安全模式下忽略;
Domain[8:5]:域,内存区域的集合,可以定义16个域,划分其访问权限,超越域访问权限时会触发Permission fault。
二级页表属性如下图所示:

- Small page base address[31:12]:线性地址转换物理地址,用于配合线性地址offset找到物理地址;
- XN[0]:Execute-never;
- C,B[3:2]:定义内部cache属性。
- TEX[8:6]:定义外部cache属性。
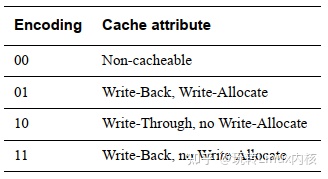
AP[9,5:4]:Access Permissions,当高位设置为1,则页表为只读权限;

- S[10]:Shareable;
- nG[11]:not global,指定页表是否是全局的,用于TLB;
3.3 ARMv8 分页配置
ARMv8架构AArm64支持三种页大小:64KB,16KB和4KB。
页大小选择由系统寄存器TCR控制,如下图所示为TCR_EL1寄存器。

比较重要的bit位说明:
- T0SZ[5:0]:The size offset of the memory region addressed by TTBR0_EL1,TTBR0_EL1寻址的内存区域的大小偏移量,内存区域大小计算方法2(64-T0SZ);
- T1SZ[21:16]:The size offset of the memory region addressed by TTBR1_EL1,TTBR1_EL1寻址的内存区域的大小偏移量,内存区域大小计算方法2(64-T0SZ);
- IRGN0[9:8]/IRGN1[25:24]:Inner cacheability attribute for memory associated,控制内部Cache访问模式,直写和回写;
- ORGN0[11:10]/ORGN1[27:26]:Outer cacheability attribute for memory associated,控制外部Cache访问模式,直写和回写;
- TG0[15:14]:Granule size for the TTBR0_EL1,页大小,为0表示4KB,1表示64KB,2表示16KB;
- TG1[31:30]:Granule size for the TTBR1_EL1,页大小,为0表示4KB,1表示64KB,3表示16KB;
- A1[22]:ASID选择,为0选择TTBR0_EL1.ASID ,为1选择TTBR1_EL1.ASID;
- IPS[34:32]:Intermediate Physical Address Size,中间物理地址大小;
- AS[36]:ASID Size,ASID大小,为0表示8bit,为1表示16bit;
- HA[39]:Hardware Access flag update,Access使能位;
- HD[40]:Hardware management of dirty state,Dirty使能位;
说明:
- ARM架构提供了两个页表基址寄存器TTBR0和TTBR1,可以分别用于用户态和内核态。
- ASID用于标识进程,可以根据ASID划分TLB entry,避免TLB entry频繁Flush。
- 显然系统寄存器TCR控制了页表映射的参数,其中TCR.TG0/TG1决定了页大小。
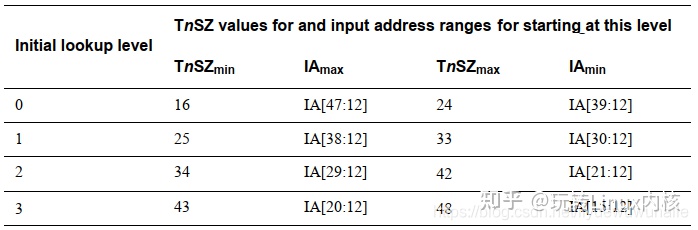
当页大小为4KB时,分页单元每级页表的地址范围如下,其中TnSZmin和TnSZmax分别表示TCR_ELx.TnSZ的最小最大值,IA表示Input Address,即虚拟地址:
3.4 ARMv8 Paging
以页大小为4KB,虚拟地址位宽为48bit为例,符合上一节中TCR_ELx.TnSZ为最小值的情况,如下图所示。
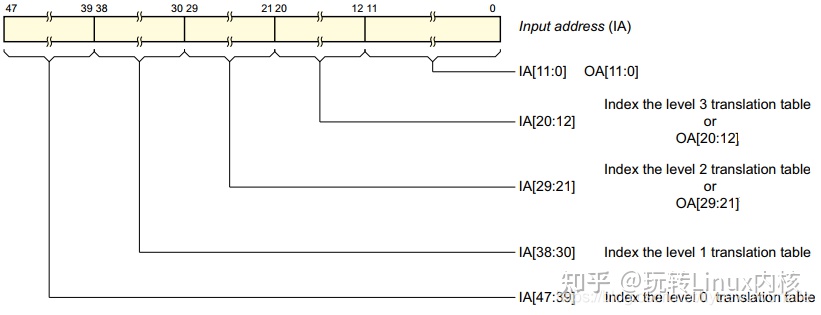
ARMv8对IA(input address)划分成了五部分:
- Index the level 0 translation table[47:39]:最高9bit;
- Index the level 1 translation table[38:30]:中间9bit;
- Index the level 2 translation table [29:21]:中间9bit;
- Index the level 3 translation table[20:12]:中间9bit;
- OA[11:0]:output address,最低12bit。
这个划分方法与X86 4-Level Paging一样。
其地址转换过程,与前述的地址转换过程并无差别,从页表基址寄存器TTBR_ELx开始逐级查找到物理地址,如下图所示。
四、Kernel中的分页
Linux Kernel分页为了支持不同的CPU体系架构,设计了五级分页模型,如下图所示。五级分页模型是为了兼容X86-64体系架构中的5-Level Paging分页模式,见第二节。
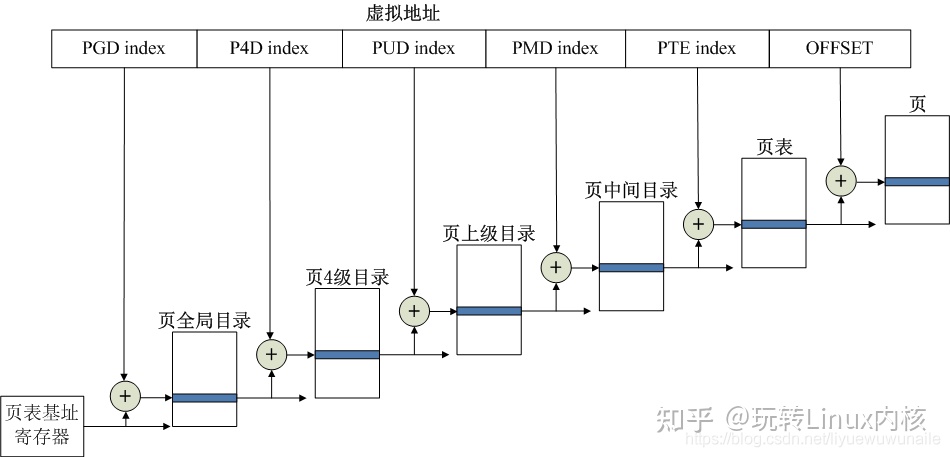
五级分页每级命名分别为页全局目录(PGD)、页4级目录(P4D)、页上级目录(PUD)、页中间目录(PMD)、页表(PTE)。对应的相关宏定义命名如下:
#define PGDIR_SHIFT
#define P4D_SHIFT
#define PUD_SHIFT
#define PMD_SHIFT
#define PAGE_SHIFT
这些宏定义与具体体系架构相关,如果体系架构只使用了4级,3级或者更少的分级映射,则将其中的某几个定义忽略即可。
Linux对于页表的操作主要定义了以下函数或宏。这些操作方法也是与体系架构相关的,因此需要按照体系架构的硬件定义去实现。
| 宏或函数 | 说明 |
|---|---|
| pgd_offset(mm, addr) | 根据入参内存描述符mm和虚拟地址address,找到address在页全局目录中相应表项的线性地址。 |
| pgd_offset_k(addr) | 根据入参虚拟地址address和init_mm,找到address在页全局目录中相应表项的线性地址。仅用于内核页表。 |
| p4d_offset(pgd, addr) | 根据入参pgd和虚拟地址address,找到address在页四级目录中相应表项的线性地址。 |
| pud_offset(p4d,addr) | 根据入参p4d和虚拟地址address,找到address在页上级目录中相应表项的线性地址。 |
| pmd_offset(pud, address) | 根据入参pud和虚拟地址address,找到address在页中间目录中相应表项的线性地址。 |
| pte_index(address) | 根据入参虚拟地址address,找到address在页表中索引。 |
| set_pgd(pgdp, pgd) | 向PGD写入指定的值 |
| set_p4d(p4dp, p4d) | 向P4D写入指定的值 |
分页机制与CPU体系架构强相关,因此分析Linux Kernel分页时还是需要根据体系架构分析。
4.1 X86分页
X86架构中支持四种分页模式:32-bit,PAE,4-Level Paging和5-Level Paging。对于ARM体系架构最多用到了4级分页,而X86架构可以用到5级分页。Linux对于X86分页定义如下。
#ifdef CONFIG_X86_5LEVEL
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
#define PGDIR_SHIFT pgdir_shift
#define PTRS_PER_PGD 512
/*
* 4th level page in 5-level paging case
*/
#define P4D_SHIFT 39
#define MAX_PTRS_PER_P4D 512
#define PTRS_PER_P4D ptrs_per_p4d
#define P4D_SIZE (_AC(1, UL) << P4D_SHIFT)
#define P4D_MASK (~(P4D_SIZE - 1))
#define MAX_POSSIBLE_PHYSMEM_BITS 52
#else /* CONFIG_X86_5LEVEL */
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
#define MAX_PTRS_PER_P4D 1
#endif /* CONFIG_X86_5LEVEL */
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
/*
* PMD_SHIFT determines the size of the area a middle-level
* page table can map
*/
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
/*
* entries per page directory level
*/
#define PTRS_PER_PTE 512
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE - 1))
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE - 1))
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE - 1))
我们以4级分页为例,其对虚拟地址的划分如下图所示,在2.3节中已经说明。从Linux宏定义可以看出PGDIR_SHIFT对应PML4,值为39;PUD_SHIFT对应Directory Ptr,值为30;PMD_SHIFT对应Directory,值为21;使用4KB也大小时,PAGE_SIZE为4KB,即PAGE_SHIFT大小为12,对应Table。
PTRS_PER_PGD,PTRS_PER_PUD,PTRS_PER_PMD分别对应每级表项的个数,都是512个表项(2^9)。
4.2 ARMv7分页
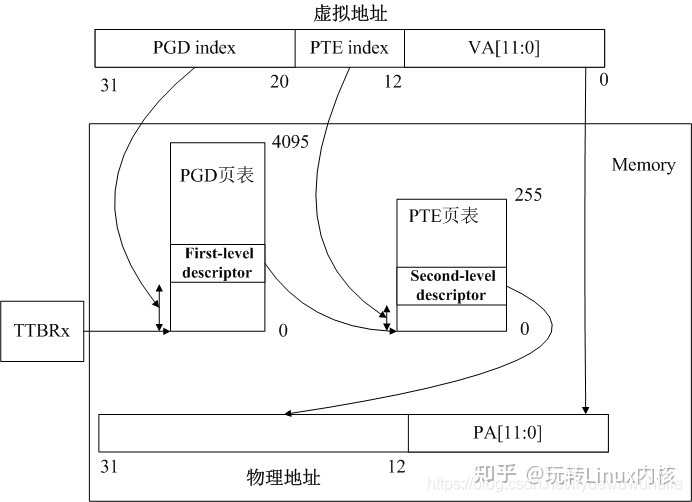
ARMv7作为32bit CPU架构,其分页一般采用两级分页。第一级为页目录(PGD),第二级为页映射表(PTE),页大小为4KB。
如下图所示为ARMv7页表映射示意图,与ARMv7硬件4KB分页机制相对应。页表基址寄存器TTBRx(x为0或1)。
TTBRx(Translation Table Base Register x)即页表转换基址寄存器,ARMv7提供了TTBR0和TTBR1两个寄存器,Linux分别将其应用于内核态和用户态。进程地址空间切换实质就是将TTBR0寄存器中Translation Table Base 0 Address修改为当前进程的PGD(页全局目录)。一级页表数量为4096,二级页表数量为256。
页表映射过程是MMU通过TTBRx和虚拟地址VA[31:20]索引到PGD一级页表,再由PGD一级页表和虚拟地址VA[19:12]索引到PTE页映射表,在由PTE页映射表和虚拟地址VA[11:0]索引到物理地址。
Linux对于上述PGD,PTE等数据的定义位于ARM体系架构目录,如下所示:
/*
* PMD_SHIFT determines the size of the area a second-level page table can map
* PGDIR_SHIFT determines what a third-level page table entry can map
*/
#define PMD_SHIFT 21
#define PGDIR_SHIFT 21
#define PMD_SIZE (1UL << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
这里会有一个疑惑,PMD和PGD没有定义成20,和之前分析的不一致?
之前分析了ARMv7硬件分页机制,4KB页表大小进行分页时,采用二级页表结构,第一级有4096个表项,第二级有256个表项。二级页表中的属性没有“dirty”位。
而Linux有一个三层的页表结构,可以很容易地将其包装成适合两层的页表结构—只使用PGD和PTE。但是,Linux还要求每个页面有一个“PTE”表,而且至少要有一个“dirty”位。对于“dirty”位我们前面也讲到了,“dirty”位在写操作时被置位,表示页面被写过,页面交换时会使用该标记。
因此,在这里稍微调整了实现—告诉Linux在第一级有2048个条目,每个都是8字节。二级页表包含两个连续排列的硬件PTE表项,前面的表项是包含Linux需要的状态信息的Linux PTE。因此,最终在“PTE”级别上有512个表项。宏定义如下所示。
#define PTRS_PER_PTE 512
#define PTRS_PER_PMD 1
#define PTRS_PER_PGD 2048
#define PTE_HWTABLE_PTRS (PTRS_PER_PTE)
#define PTE_HWTABLE_OFF (PTE_HWTABLE_PTRS * sizeof(pte_t))
#define PTE_HWTABLE_SIZE (PTRS_PER_PTE * sizeof(u32))
当页面在Linux PTE中被标记为“可写”和“dirty”时,“dirty”位通过授予硬件写权限模拟。也就是说ARM页表设置时将权限设置为只读,当向页面写入时,会触发缺页异常(Linux PTE页面表项标记了可写权限,但是ARM硬件页面表项是只读权限),在缺页异常处理函数handle_pte_fault()中会在该页的Linux PTE页面表项标记为“dirty”,为了让硬件注意到权限的更改,必须刷新TLB条目,而ptep_set_access_flags()为我们完成了这项工作。ARMv7页表属性的定义分为Linux版本的页表和ARMv7硬件的页表。
Linux版本的PTE页表属性定义加入前缀L_,如下所示:
/*
* "Linux" PTE definitions.
*
* We keep two sets of PTEs - the hardware and the linux version.
* This allows greater flexibility in the way we map the Linux bits
* onto the hardware tables, and allows us to have YOUNG and DIRTY
* bits.
*
* The PTE table pointer refers to the hardware entries; the "Linux"
* entries are stored 1024 bytes below.
*/
#define L_PTE_VALID (_AT(pteval_t, 1) << 0) /* Valid */
#define L_PTE_PRESENT (_AT(pteval_t, 1) << 0)
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 1)
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 6)
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 7)
#define L_PTE_USER (_AT(pteval_t, 1) << 8)
#define L_PTE_XN (_AT(pteval_t, 1) << 9)
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10) /* shared(v6), coherent(xsc3) */
#define L_PTE_NONE (_AT(pteval_t, 1) << 11)
ARMv7硬件的页表属性定义如下所示:
/*
* - extended small page/tiny page
*/
#define PTE_EXT_XN (_AT(pteval_t, 1) << 0) /* v6 */
#define PTE_EXT_AP_MASK (_AT(pteval_t, 3) << 4)
#define PTE_EXT_AP0 (_AT(pteval_t, 1) << 4)
#define PTE_EXT_AP1 (_AT(pteval_t, 2) << 4)
#define PTE_EXT_AP_UNO_SRO (_AT(pteval_t, 0) << 4)
#define PTE_EXT_AP_UNO_SRW (PTE_EXT_AP0)
#define PTE_EXT_AP_URO_SRW (PTE_EXT_AP1)
#define PTE_EXT_AP_URW_SRW (PTE_EXT_AP1|PTE_EXT_AP0)
#define PTE_EXT_TEX(x) (_AT(pteval_t, (x)) << 6) /* v5 */
#define PTE_EXT_APX (_AT(pteval_t, 1) << 9) /* v6 */
#define PTE_EXT_COHERENT (_AT(pteval_t, 1) << 9) /* XScale3 */
#define PTE_EXT_SHARED (_AT(pteval_t, 1) << 10) /* v6 */
#define PTE_EXT_NG (_AT(pteval_t, 1) << 11) /* v6 */
ARMv7硬件的页表属性定义与3.2节中描述的硬件页表的属性是相互对应的,其含义与硬件页表属性含义一致。
通过对比Linux版本的页表和ARMv7硬件的页表会发现,ARMv7硬件的页表缺少“dirty”位和“young”位。“dirty”位前边已经讲过,“young”位用于标志页面刚刚被访问过,在页面换出时,如果页面“young”位被标记,则不会将该页换出,同时清除“young”位标记。“young”位的模拟方法与“dirty”位类似,也是利用了两套PTE页表模拟,一套用于Linux,一套用于ARM硬件。
ARMv7页表如何下发到硬件?是通过set_pte_ext()函数实现的
#define set_pte_ext(ptep,pte,ext) cpu_set_pte_ext(ptep,pte,ext)
#define cpu_set_pte_ext PROC_TABLE(set_pte_ext)
不同CPU有不同的实现方式,以Cortex-A9为例,其实现是汇编函数cpu_v7_set_pte_ext:
/*
* cpu_v7_set_pte_ext(ptep, pte)
*
* Set a level 2 translation table entry.
*
* - ptep - pointer to level 2 translation table entry
* (hardware version is stored at +2048 bytes)
* - pte - PTE value to store
* - ext - value for extended PTE bits
*/
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] @ linux version @Linux PTE设置到r0指向的内存
bic r3, r1, #0x000003f0
bic r3, r3, #PTE_TYPE_MASK
orr r3, r3, r2
orr r3, r3, #PTE_EXT_AP0 | 2
tst r1, #1 << 4
orrne r3, r3, #PTE_EXT_TEX(1)
eor r1, r1, #L_PTE_DIRTY
tst r1, #L_PTE_RDONLY | L_PTE_DIRTY
orrne r3, r3, #PTE_EXT_APX @模拟“dirty”位,如果L_PTE_DIRTY置位,
@则设置ARM硬件页表APX位置位,设置页表为只读权限
tst r1, #L_PTE_USER
orrne r3, r3, #PTE_EXT_AP1
tst r1, #L_PTE_XN
orrne r3, r3, #PTE_EXT_XN
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_VALID
eorne r1, r1, #L_PTE_NONE
tstne r1, #L_PTE_NONE
moveq r3, #0 @模拟“young”位,如果L_PTE_YONG清除且L_PTE_PRESENT置位,
@则保持Linux版本页表不变,ARM硬件页表清除(r3置0即清空页表)
ARM( str r3, [r0, #2048]! ) @ARM PTE设置到r0+2048指向的内存
THUMB( add r0, r0, #2048 )
THUMB( str r3, [r0] )
ALT_SMP(W(nop))
ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endif
bx lr
ENDPROC(cpu_v7_set_pte_ext)
寄存器r0是PTE表项指针,Linux使用的表项即r0所指内存,ARM硬件使用的表项地址是r0+2048。寄存器r1表示要写入内存的Linux PTE表项的内容,其属性bit位设置均使用L_前缀的宏定义。
第一句语句将Linux PTE设置到r0指向的内存。
str r1, [r0]
str为内存操作指令,表示将数据从寄存器写的内存。
如下语句将ARM PTE设置到r0+2048指向的内存。
ARM( str r3, [r0, #2048]! )1
[r0, #2048]为前索引寻址模式,地址为寄存器R0中的值+立即数2048,偏移量为2048,计算出的新地址回写到R0中。
关于内存操作指令详细内容请看《ARM体系架构—ARMv7-A指令集:内存操作指令》
如下语句为ARMv7协处理器指令,指令含义为Data Cache Clean by MVA to PoC,即清除cache。
ALT_UP (mcr p15, 0, r0, c7, c10, 1)
4.3ARMv8分页
ARMv8页表支持三种粒度:4KB,16KB和64KB。
ARMv8支持48bit虚拟地址空间, 实现ARMv8.2-LVA( Large Virtual Address)并使用64KB页大小时虚拟地址寻址空间可达52bit。当使用64KB页大小时,ARMv8使用三级页表;当使用4KB和16KB页大小时,ARMv8使用四级页表。正如下图所示。
ARMv8采用4KB页大小,使用4级页表时,内存分布如下,内核空间和用户空间大小分别为256TB。内核空间地址范围从0xffff000000000000到0xffffffffffffffff,共256TB空间,用户空间地址范围从0x0000000000000000到0x0000ffffffffffff,共256TB空间。
AArch64 Linux memory layout with 4KB pages + 4 levels (48-bit)::
Start End Size Use
-----------------------------------------------------------------------
0000000000000000 0000ffffffffffff 256TB user
ffff000000000000 ffff7fffffffffff 128TB kernel logical memory map
ffff800000000000 ffff9fffffffffff 32TB kasan shadow region
ffffa00000000000 ffffa00007ffffff 128MB bpf jit region
ffffa00008000000 ffffa0000fffffff 128MB modules
ffffa00010000000 fffffdffbffeffff ~93TB vmalloc
fffffdffbfff0000 fffffdfffe5f8fff ~998MB [guard region]
fffffdfffe5f9000 fffffdfffe9fffff 4124KB fixed mappings
fffffdfffea00000 fffffdfffebfffff 2MB [guard region]
fffffdfffec00000 fffffdffffbfffff 16MB PCI I/O space
fffffdffffc00000 fffffdffffdfffff 2MB [guard region]
fffffdffffe00000 ffffffffffdfffff 2TB vmemmap
ffffffffffe00000 ffffffffffffffff 2MB [guard region]
ARM提供了两个页表基址寄存器TTBR0和TTBR1,在Linux中分别用于用户空间和内核空间,内核空间地址高16位全为1,用户空间地址高16位全为0,。如下图所示,TTBR1和TTBR0分别管理0xffff000000000000到0xffffffffffffffff和0x0000000000000000到0x0000ffffffffffff两部分地址空间,其余地址空间访问则会发生异常。MMU做地址转换时选择TTBR1和TTBR0是根据虚拟地址VA[63],如果63bit为1则选择TTBR1,为0则选择TTBR0。
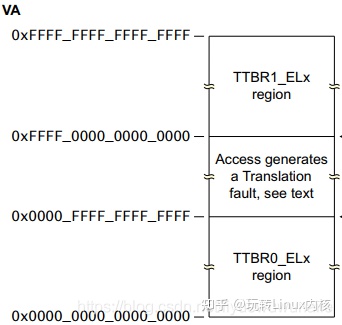
ARMv8采用4KB页大小,4级页表映射,其虚拟地址划分为,在3.4节中已经做过说明。

Linux上述 Index the level 0 & 1 & 2 & 3 translation table等数据的定义位于ARM体系架构目录,如下所示。
#define VA_BITS (CONFIG_ARM64_VA_BITS)
#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)
#define PTRS_PER_PTE (1 << (PAGE_SHIFT - 3))
/*
* PMD_SHIFT determines the size a level 2 page table entry can map.
*/
#if CONFIG_PGTABLE_LEVELS > 2
#define PMD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(2)
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PTRS_PER_PMD PTRS_PER_PTE
#endif
/*
* PUD_SHIFT determines the size a level 1 page table entry can map.
*/
#if CONFIG_PGTABLE_LEVELS > 3
#define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1)
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE-1))
#define PTRS_PER_PUD PTRS_PER_PTE
#endif
/*
* PGDIR_SHIFT determines the size a top-level page table entry can map
* (depending on the configuration, this level can be 0, 1 or 2).
*/
#define PGDIR_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(4 - CONFIG_PGTABLE_LEVELS)
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define PTRS_PER_PGD (1 << (VA_BITS - PGDIR_SHIFT))
PGDIR_SHIFT宏对应了 Index the level 0 translation table,当4KB页大小,4级页表映射时(PAGE_SHIFT = 12;CONFIG_PGTABLE_LEVELS = 4),通过计算可得PGDIR_SHIFT宏为39,与硬件分页定义一致。
PGDIR_SHIFT = (12-3)*(4-0)+3 = 39
CONFIG_PGTABLE_LEVELS表示使用页表级数,当前使用的是4级页表,所以CONFIG_PGTABLE_LEVELS>3。因此PUD定义为:
#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)
#define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1)
PUD_SHIFT宏对应了 Index the level 1 translation table,带入计算可知PUD_SHIFT为30,与硬件分页定义一致。
PUD_SHIFT = (12-3)*(4-1)+3 = 30
CONFIG_PGTABLE_LEVELS表示使用页表级数,当前使用的是4级页表,所以CONFIG_PGTABLE_LEVELS>2。因此PMD定义为:
#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)
#define PMD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(2)
PMD_SHIFT宏对应了 Index the level 3 translation table,带入计算可知PUD_SHIFT为21,与硬件分页定义一致。
PMD_SHIFT = (12-3)*(4-2)+3 = 21
至此,PGD,PUD,PMD都已获悉,对应的其他宏的值也可以顺利计算出结果。
#define PGDIR_SIZE 512GB
#define PTRS_PER_PGD 512
#define PUD_SIZE 1GB
#define PTRS_PER_PUD 512
#define PMD_SIZE 2MB
#define PTRS_PER_PMD 512
ARMv8 Linux下发PGD,PUD,PMD,PTE并没有使用汇编语言,而是使用C语言实现,对应的函数如下,其实现原理都是将对应的表项内容写入表项所在地址。
/* 向内存下发PGD页表,入参分别为pgd页表虚拟地址和pgd表项*/
static inline void set_pgd(pgd_t *pgdp, pgd_t pgd)
{
if (in_swapper_pgdir(pgdp)) {
set_swapper_pgd(pgdp, pgd); /* 将pgd写入swapper_pg_dir所指地址 */
return;
}
WRITE_ONCE(*pgdp, pgd); /* 将pgd写入pgdp所指地址 */
dsb(ishst); /* 数据内存屏障 */
isb(); /* 指令内存屏障 */
}
static inline void set_pud(pud_t *pudp, pud_t pud)
{
#ifdef __PAGETABLE_PUD_FOLDED
if (in_swapper_pgdir(pudp)) {
set_swapper_pgd((pgd_t *)pudp, __pgd(pud_val(pud)));
return;
}
#endif /* __PAGETABLE_PUD_FOLDED */
WRITE_ONCE(*pudp, pud); /* 将pud写入pudp所指地址 */
if (pud_valid(pud)) {
dsb(ishst);
isb();
}
}
static inline void set_pmd(pmd_t *pmdp, pmd_t pmd)
{
#ifdef __PAGETABLE_PMD_FOLDED
if (in_swapper_pgdir(pmdp)) {
set_swapper_pgd((pgd_t *)pmdp, __pgd(pmd_val(pmd)));
return;
}
#endif /* __PAGETABLE_PMD_FOLDED */
WRITE_ONCE(*pmdp, pmd); /* 将pmd写入pmdp所指地址 */
if (pmd_valid(pmd)) {
dsb(ishst);
isb();
}
}
static inline void set_pte(pte_t *ptep, pte_t pte)
{
WRITE_ONCE(*ptep, pte); /* 将pte写入ptep所指地址 */
/*
* Only if the new pte is valid and kernel, otherwise TLB maintenance
* or update_mmu_cache() have the necessary barriers.
*/
if (pte_valid_not_user(pte)) {
dsb(ishst);
isb();
}
}