比较经典的一篇关于立体匹配论文,觉得有必要记录一下。
摘要
最近的研究表明,双目图像的深度估计可以表述为一个监督学习任务,可以用卷积神经网络来解决。为了能在不适定区域,利用上下文信息寻找对应关系,提出了PSM-Net。它包含了两个主要的模块:空间金字塔池化(spatial pyramid pooling)模块和3D卷积模块。空间金字塔池化模块通过聚合不同尺度和位置的上下文,充分利用了全局上下文信息的能力来形成cost volume。3D卷积模块利用堆叠的多个沙漏(hourglass)网络来规范化cost volume。
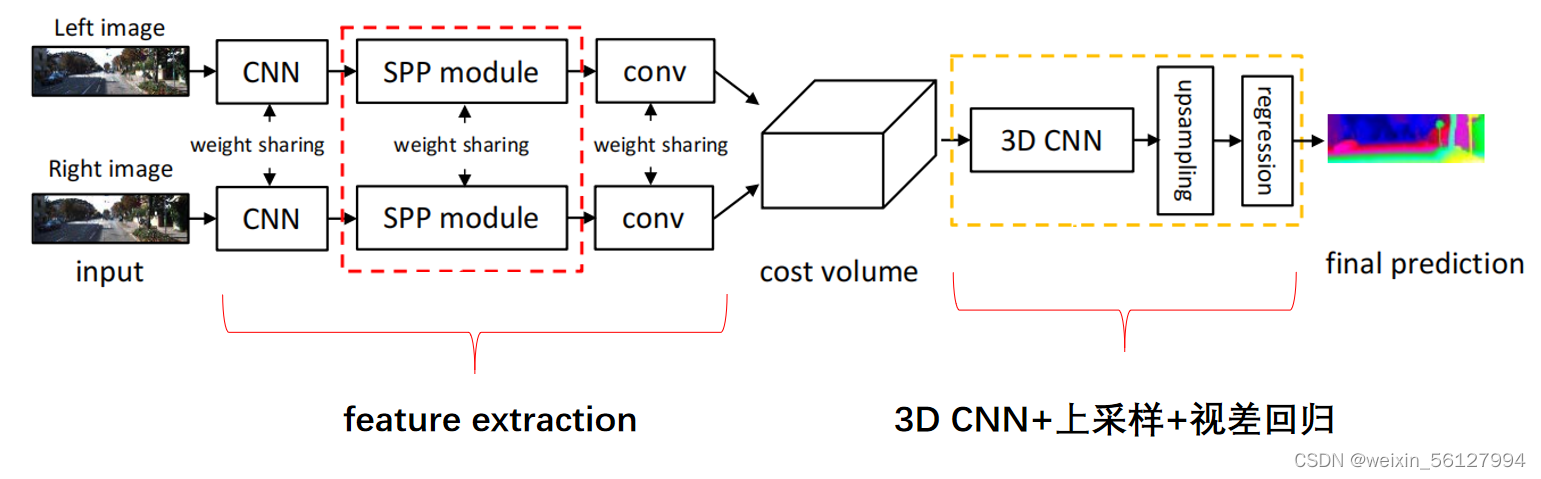
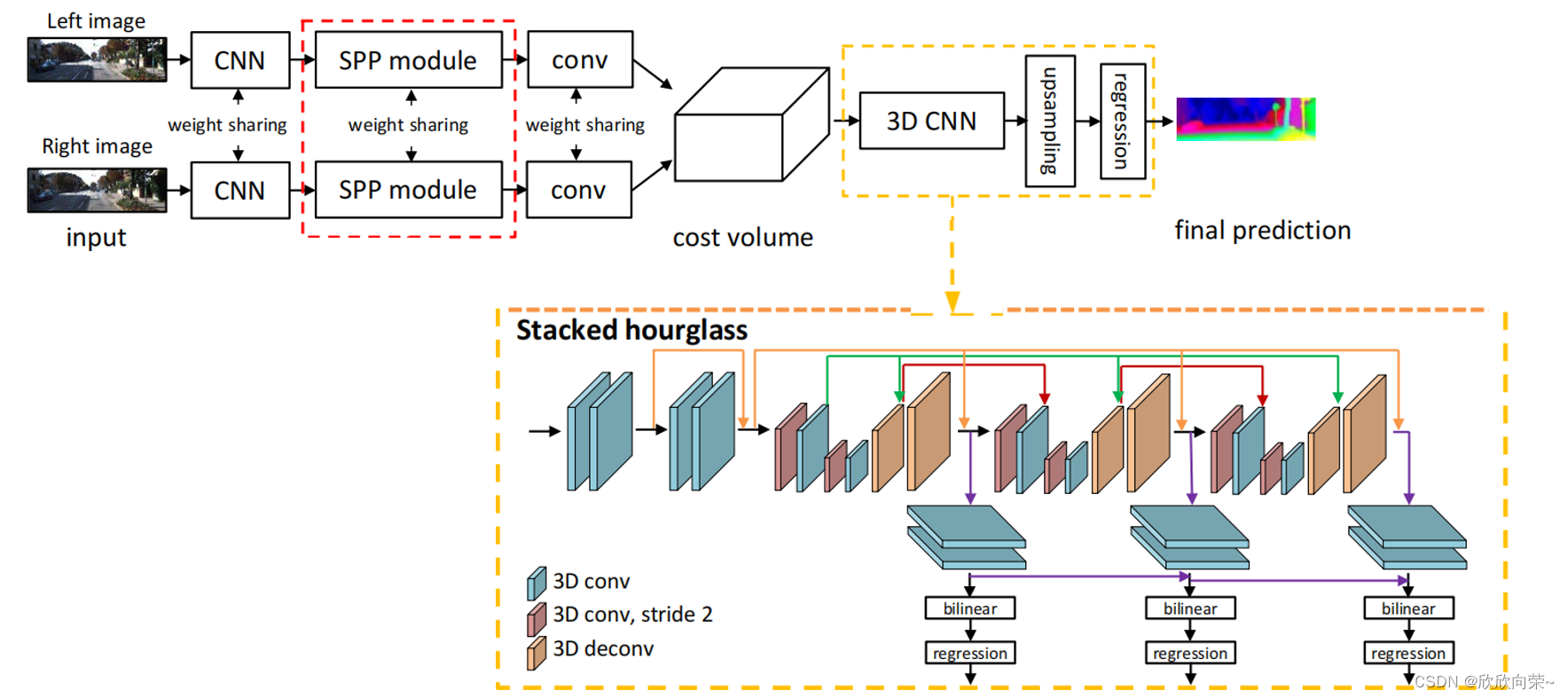
上图是PSM-Net的大致结构,主要分为特征提取、cost volume的构建、3D CNN+上采样+视差回归。输入是一对左右视图,使用两个结构相同且权值共享的特征提取网络,得到左右视图的特征图之后就是构建cost volume,cost volume就是成本空间或者翻译成成本体积,用来衡量左右视图相似性的一个4维的tensor(bs,C,H,W)。在cost volume上做一系列3D卷积,用于规范化cost volume。之后就是上采样和视差回归,来形成视差图。接下来,一个部分一个部分讲。
SPP Module
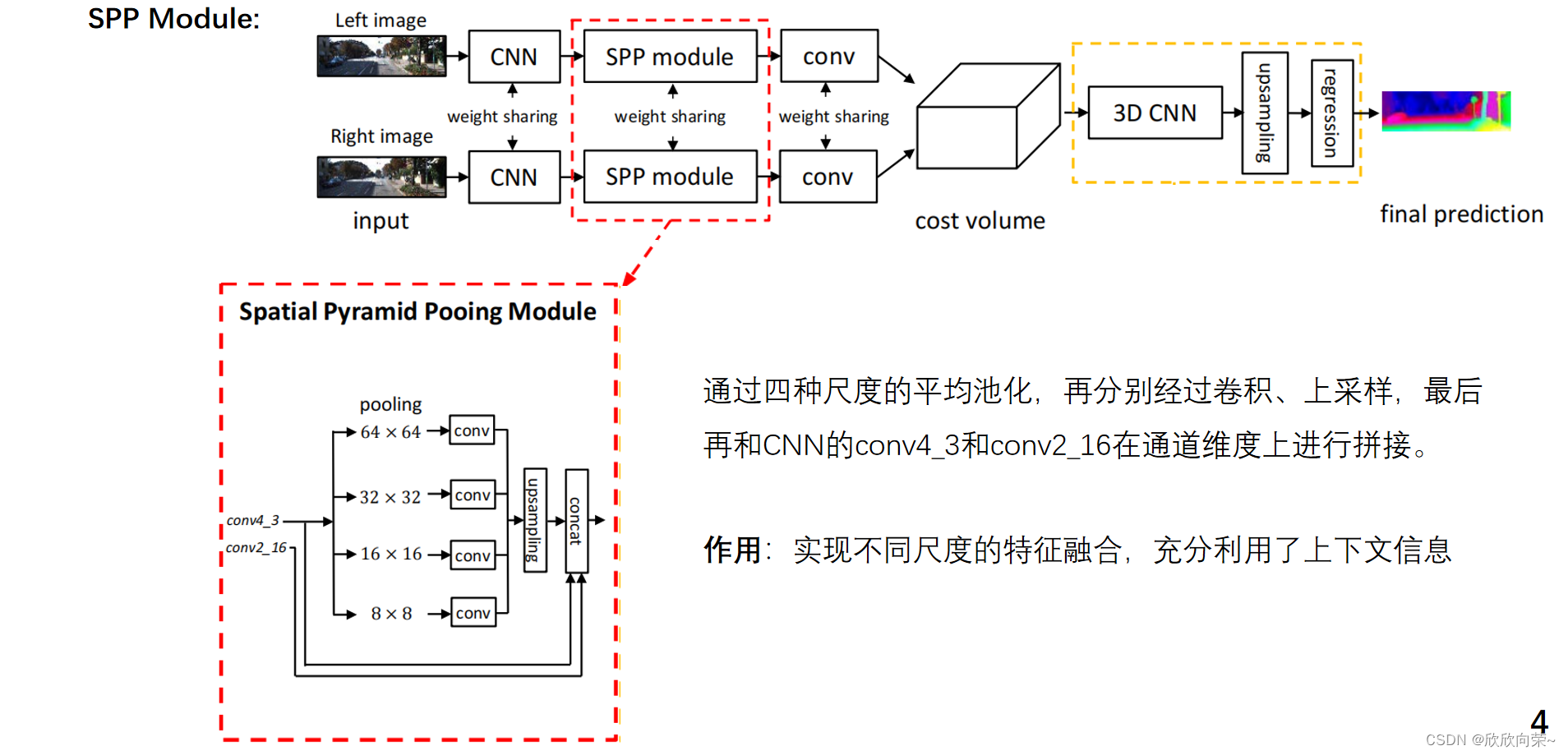
空间金字塔模块设计了4种不同尺度的分支,具有不同的感受野,四个分支经过平均池化再经过卷积然后都经过上采样,然后再和CNN部分的conv4_3和conv2_16在通道维度上进行拼接。图像中的车和车窗车轮尺度不同,它们之间的关系就是由空间金字塔池化模块学习的,来合并层次化的上下文信息。
cost volume的构建
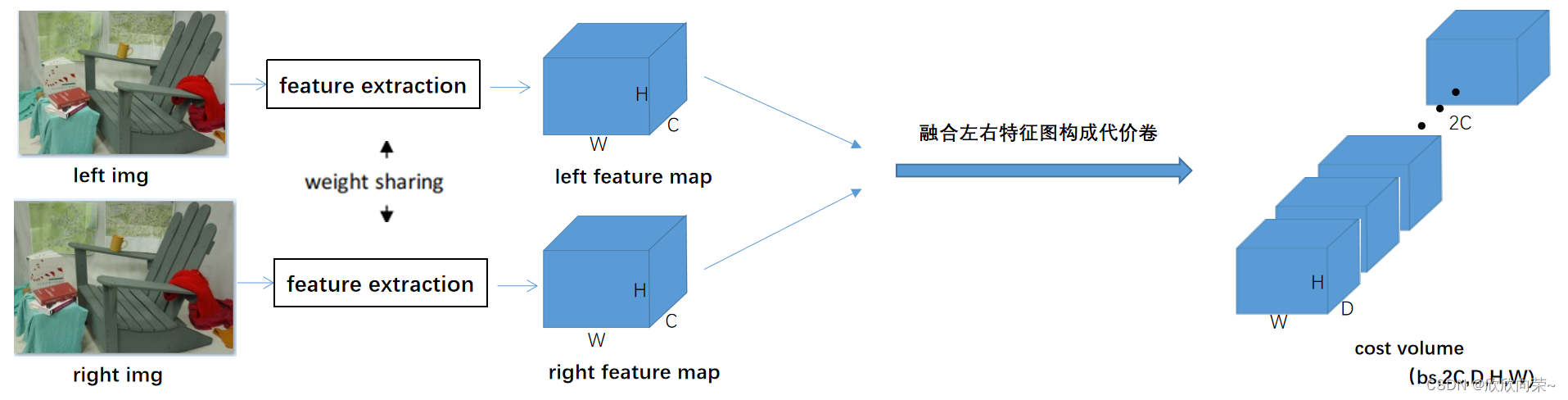
左右图像经过特征提取层,得到左右特征图,通过融合左右特征图构成cost volume,如下图所示。2C:左右特征图的通道数之和,D代表的是视差数
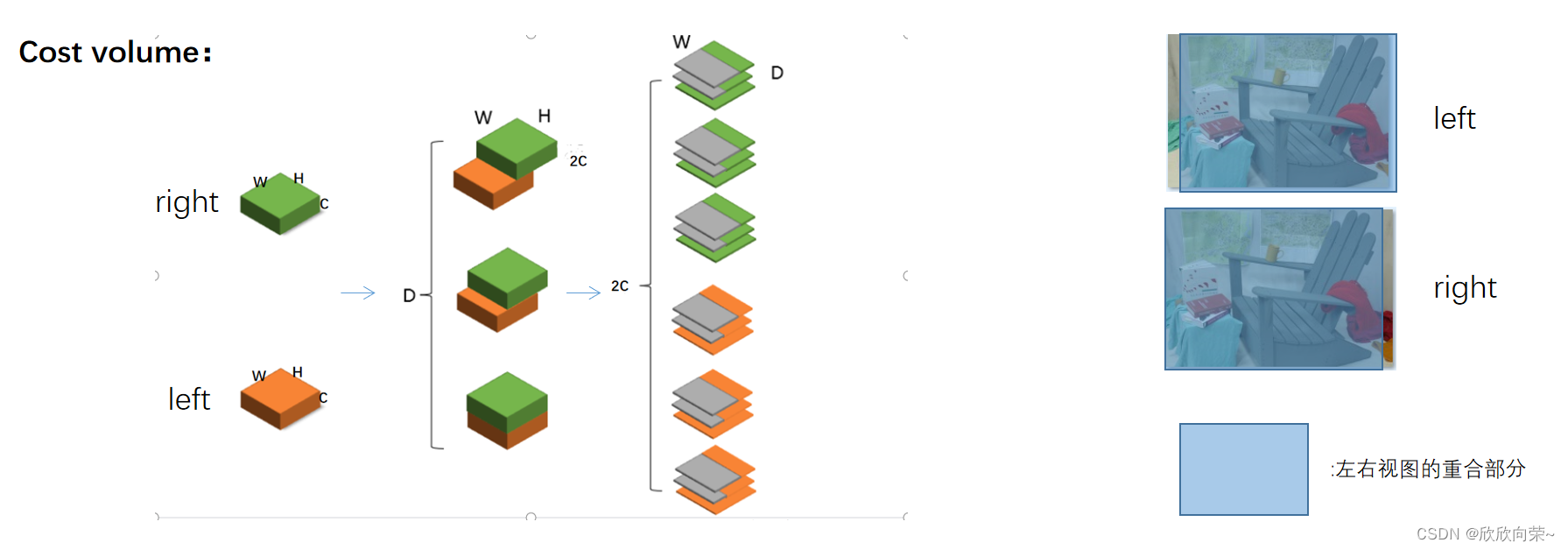
具体是怎么融合的呢?打个比方,如下图所示,左右特征矩阵size分别是(C,H,W),这里假设有3个视差水平,将左右特征矩阵根据不同的视差水平堆叠,得到每个视差水平的左右特征矩阵的重合部分,把每个视差水平的重合的特征矩阵按照通道维度拆开,然后组成一个四维的cost volume,构建的cost volume中左右特征矩阵没有重合的部分填充的是0(灰色部分),这样就可以得到一个size为(2C,D,H,W)的cost volume。为什么左右特征矩阵要这样堆叠呢?因为左右视图,二者重合的部分在左视图的右边,右视图的左边。
stacked hourglass
考虑到已经得到的匹配代价卷,需要学习一种模型来聚合并规则化其所包含的视差信息和环境信息,论文使用了堆叠的沙漏结构,沙漏结构就是用3D卷积做的encoder-decoder结构,在编码器部分使用2个3D卷积对代价卷进行下采样,在解码器部分,对称的使用2个3D反卷积恢复代价卷的尺寸,但是这样会造成空间信息的损失,所以论文参考resnet的跳跃连接结构,将编码器和解码器对应尺寸的卷连接起来,这样能够在反卷积恢复卷的分辨率的过程中,补充丢失的细节信息和来自底层的信息,为了让网络能够提取更多的细节信息,将3个相同的编码解码器连接起来。具体结构如下图所示。
视差回归
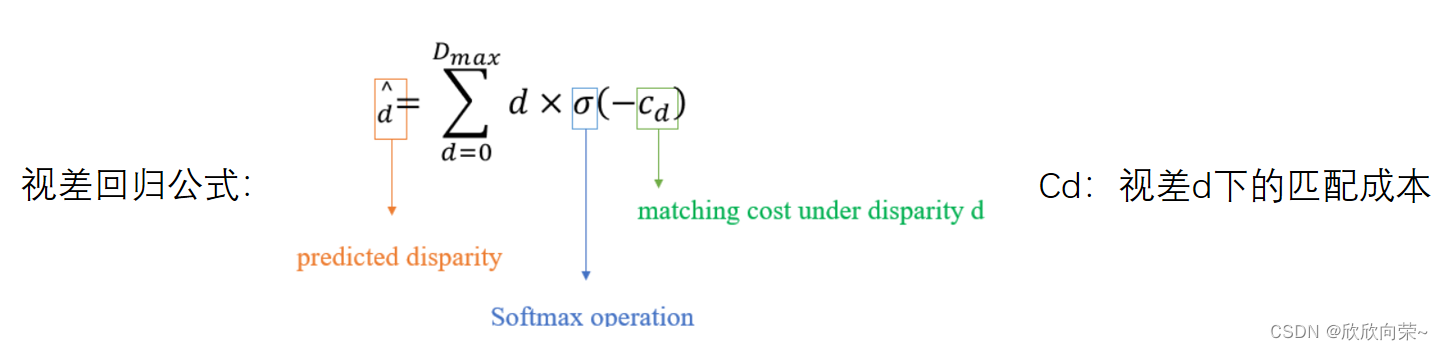
具有3个主要的沙漏结构网络,每个网络都生成一个视差图,也就是说,堆叠的沙漏网络结构有3个输出,所以在训练阶段,总损失是三个输出对应的三个损失的加权和,如果是测试阶段,最终的视差图是三个输出中的最后一个。这里的bilinear结构是上采样,将矩阵size上采样到(bs,1,D,H,W),然后squeeze将矩阵的size变成(bs,D,H,W),之后softmax处理,在视差维度softmax操作,将每个视差的概率计算出来。视差回归的公式如下,公式中Cd是视差d下的匹配成本,成本越大则表示匹配的概率越低,因此取预测成本的负值,并通过softmax操作进行正则化处理,得到每个像素属于不同视差的概率,然后以概率值作为权重,对视差进行加权和,得到每个像素点处的视差值d^。
经过所有像素点的视差回归之后,矩阵维度变成(bs,H,W),就是最终的视差图了。
训练集Loss计算
论文采用平滑的L1损失函数作为基础的损失函数,平滑的L1损失函数具有较强的鲁棒性和对异常值的低敏感性。论文对每个编码解码结构输出的卷进行视差回归,得到预测的视差图,然后再与真实的视差图比较,计算损失值,最终的损失值是由每一层的损失值加权求和得到的。
验证集的评估指标
论文采用两个的指标,一种是点对点的像素误差,缩写成EPE,另一种是三像素误差,俗称3PE,3PE的定义是视差图中估计错误的像素占所有像素的百分比,当视差估计值与真实值的差大于3个像素,这个估计值就被判定为错误。对于Scene flow验证数据集,采用的是点对点误差,计算每个像素点的预测视差值与真实视差值之间的欧式距离并取平均。对于KITTI2015验证数据集采用3像素误差。

总结
