目录
hive on spark 和 spark on hive 区别
同一个SQL 的不同执行表现
首先,我们看一个很简单的SQL
select name,count(1) from student group by name;
表中的数据为
name |
scores |
we2 |
12 |
ss2 |
13 |
ss3 |
15 |
ww3 |
12 |
ww4 |
17 |
接下来,我们通过mr、hive on spark 和 spark on hive 这三种执行方式结合他们的执行计划来进行分析。
使用mr查询
当我们在hive中使用mr查询的时候,会发生如图1(mr 执行结果图)的过程:
- 表明我们使用的查询引擎
- 提交生成运行的job,这个job 提交到的是yarn
- 是这个job中stage 运行mr 执行的过程
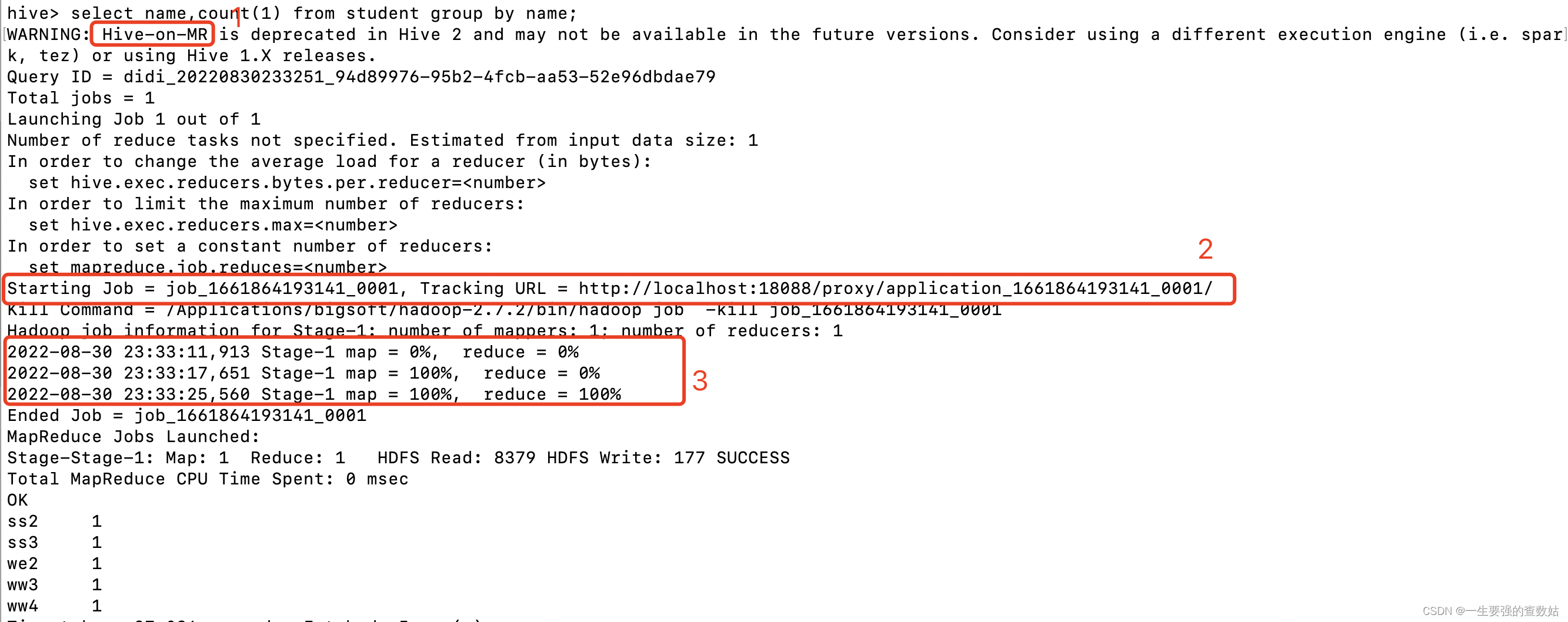
图1 mr 执行结果图
然后,我们看一下它的执行计划图2:

图2 mr执行计划图
使用hive on spark 查询
当我们在hive 中使用spark 引擎查询的时候,执行步骤1,2,3 为下,具体过程见图3(hive on spark 执行结果):
1 是表名我们使用的查询引擎
2 提交生成运行的job,可以看出生成的是spark 的job
3 是这个spark job中stage 运行过程以及状态的变化
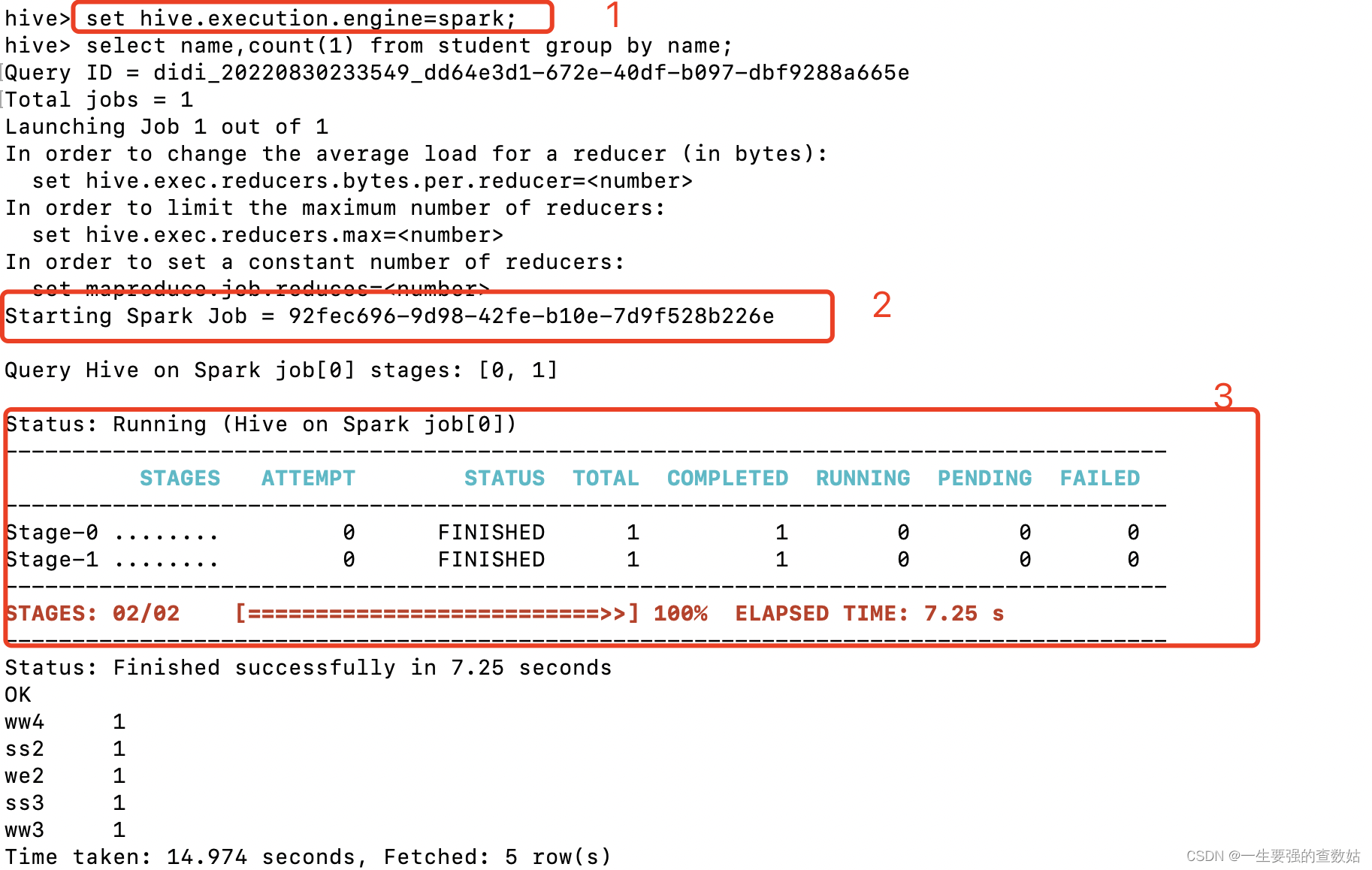
图3 hive on spark 执行结果
同样的,我们也查看一下它具体的执行计划,见图4(hive on spark执行计划)中的具体执行说明
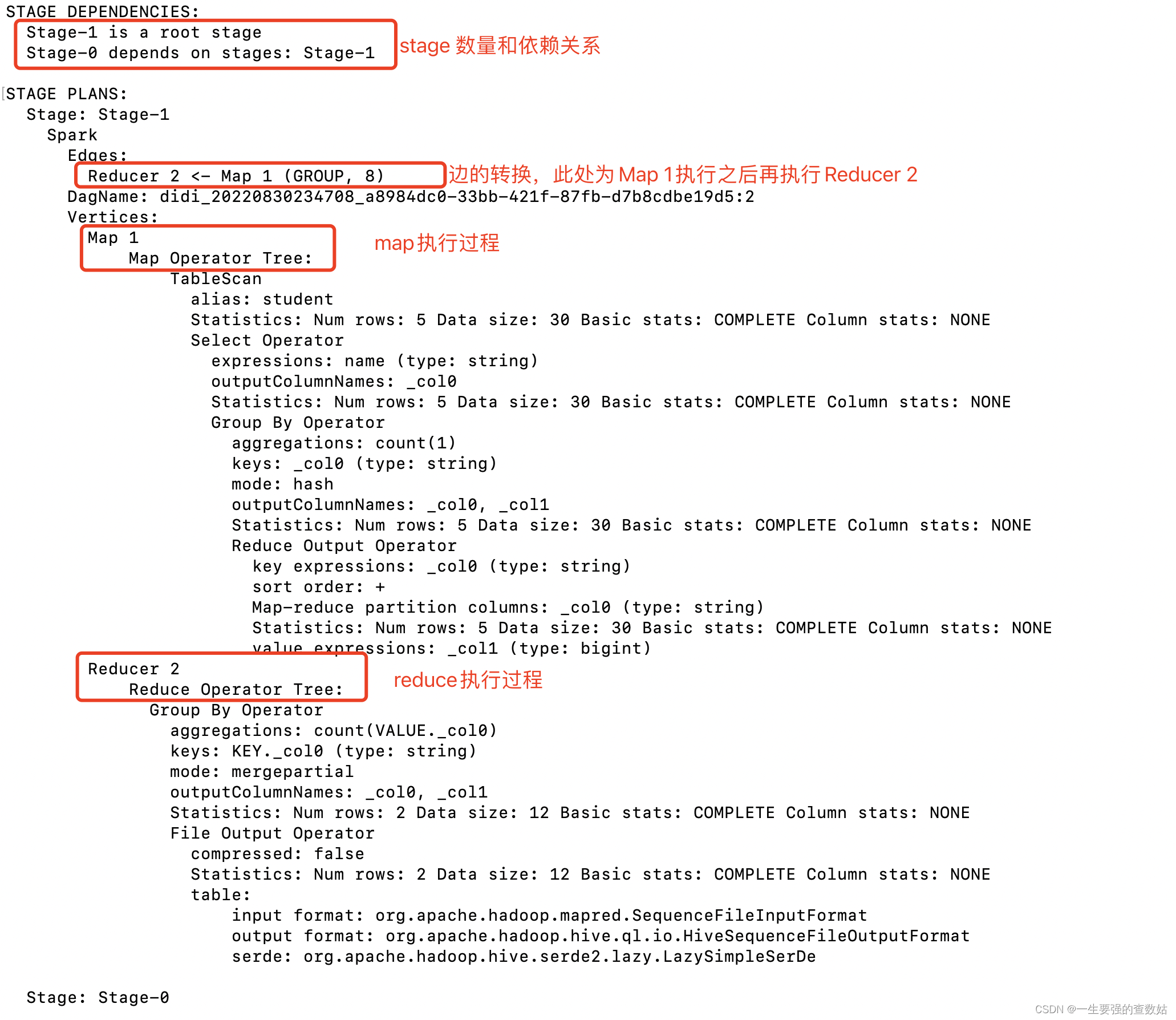
图4 hive on spark执行计划
使用spark on hive执行
对于spark on hive 我们主要查看他的执行计划,具体说明见图5 (spark on hive执行计划)
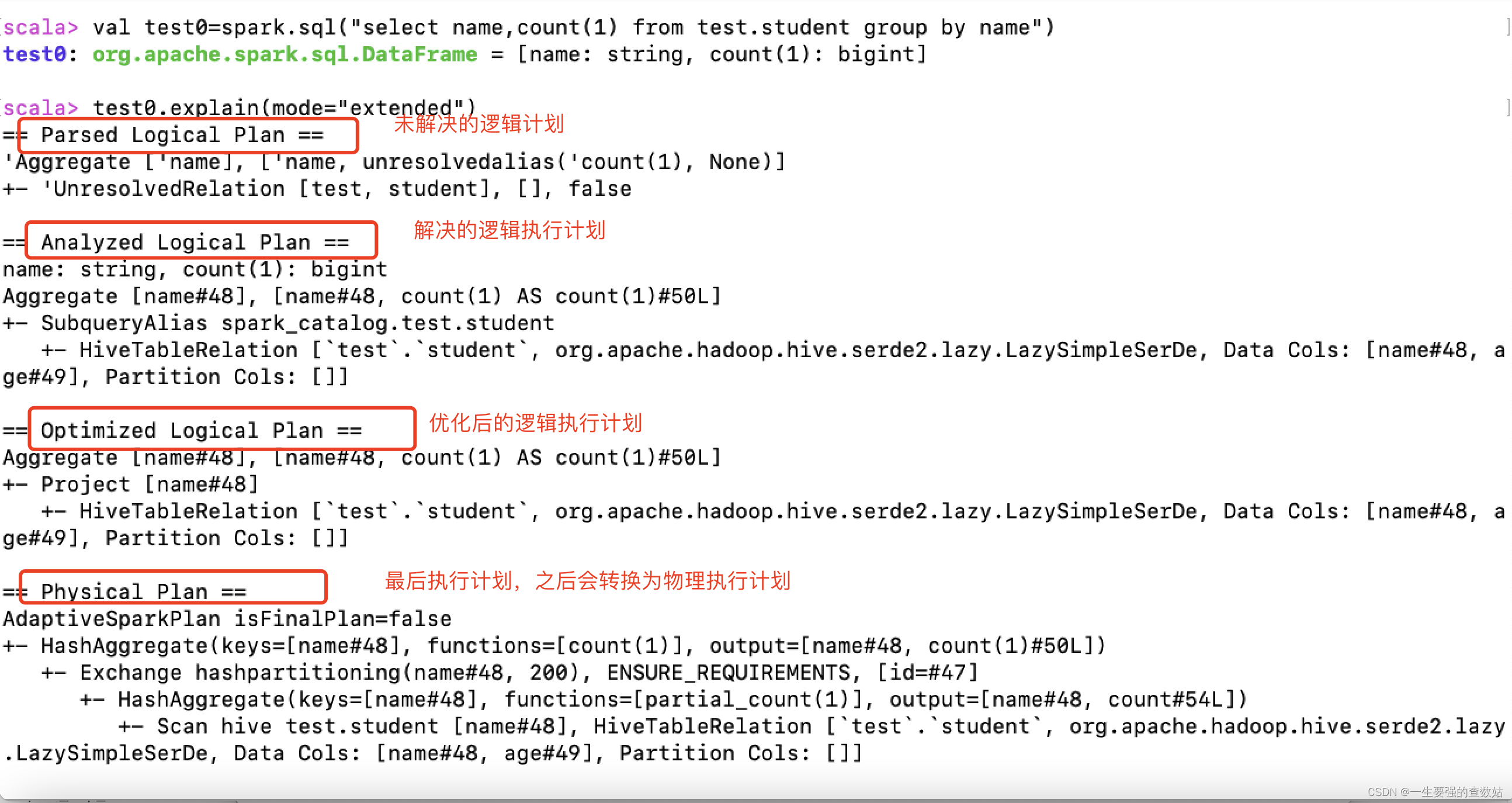
图5 spark on hive执行计划
通过以上的执行计划,我们会发现,虽然是同一个sql,虽然都是使用hive 和spark ,可执行计划为什么会有这么大的不同呢?接下来我们来进行一下分析。
hive 和 spark 介绍
首先,我们先来了解一下hive 和spark 。
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。这也就是SQL-on-Hadoop的解决方案之一。
spark的前身是shark,即"Hive on Spark",在启动初期,当时Hive 几乎算是唯一的SQL-on-Hadoop的选择方案,Hive 将SQL语句翻译为MapReduce ,但是这样,性能会受限于MapReduce的计算模型,始终无法满足各种交互SQL分析的需求,所以Shark的提出是针对这种需求的。
但是,随着 Spark 的不断发展, Shark对 Hive 的重度依赖体现在架构上的瓶颈越来越突出 。一 方面, Hive 的语法解析和查询优化等模块本身针对的是 MapReduce,限制了在 Spark 系统上的深度优化和维护; 另一方面,过度依赖Hive制约了Spark的“OneStackRuleThemAll”既定方针,也制约了技术检中各个组件的灵活集成。 在此背景下, SparkSQL项目被提出来,由MichaelArmbrust主导开发。 SparkSQL抛弃原有 Shark的架构方式,但汲取了 Shark的一些优点,如内存列存储(In-MemoryColumnarStorage)、 Hive兼容性等, 重新开发了 SQL各个模块的代码。 由于摆脱了对Hive的依赖, SparkSQL在数据兼容、性能优化、组件扩展方面都得到了极大的提升。
hive on spark 和 spark on hive 区别
了解了基本的概念,接下来,我们通过SQL的执行过程,来进行分析。
首先,从图1-图5的各种执行计划中我们会发现,mr 的执行计划和hive on spark 的执行计划差不多一样的,只是在提交的时候,mr 是通过mapreduce,而hive on spark 却是通过spark 作业运行的。
而spark on hive 的执行计划,它对于sql的解析是完全按照spark 自己的解析器进行的,作业的提交也是通过spark作业。使用SQL执行的模型来说,可归结为下图6 (SQL转化过程):
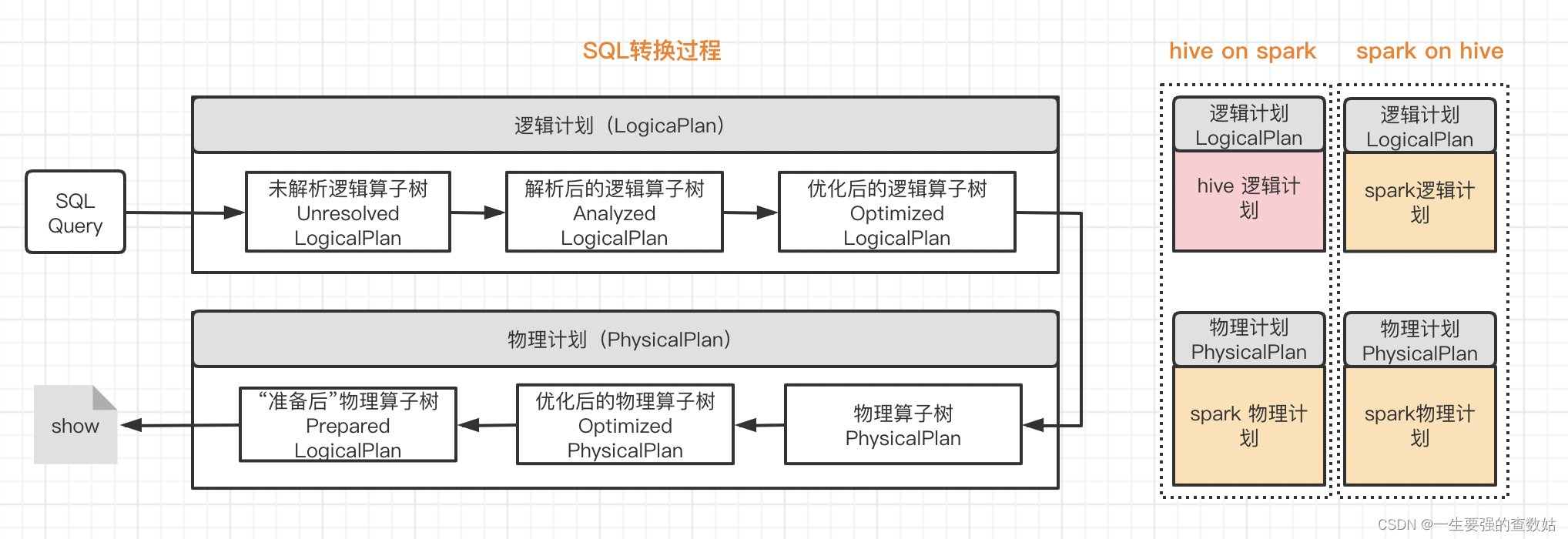
图6 SQL转换过程
从这张图中,我们可以很明显的看出:
hive on spark :在进行到物理执行计划前,都是使用hive原生的语法解析器,而在最后运行阶段交由spark 执行。
spark on hive: 除了链接了hive 的metastore 来获取hive的元数据,从语法解析到物理执行全过程都是由spark 自身的catalyst 来进行处理。
具体来说:
- hive on spark:在这种模式下,数据是以table的形式存储在hive中的,用户处理和分析数据,使用的是hive语法规范的 hql (hive sql)。 但这些hql,在用户提交执行时(一般是提交给hiveserver2服务去执行),底层会经过hive的解析优化编译,最后以spark作业的形式来运行。目前hive支持了三种底层计算引擎,即mr, tez和spark.用户可以通过set hive.execution.engine=mr/tez/spark来指定具体使用哪个底层计算引擎。
- spark on hive:当我们使用spark来处理分析存储在hive中的数据时,这种模式就称为为 spark on hive。这种模式下,用户可以使用spark的 java/scala/pyhon/r 等api,也可以使用spark语法规范的sql ,甚至也可以使用hive 语法规范的hql 。(其实从技术细节来将,这里把hql语句解析为抽象语法书ast,使用的是hive的语法解析器,但后续进一步的优化和代码生成,使用的都是spark sql 的catalyst)。
那么,本篇文章先讲到这里,而对于详细的spark sql 和hive sql 的区别,会在后续文章继续进行。欢迎大家评论并提出意见。