目录
引言:
awawkk是shell文本编辑的一把利剑
1.1概述
AWK是一种处理文本文件的语言,是一个强大的文本分析工具
它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描,过滤,统计汇总工作
数据可以来自标准输入也可以是管道或文件
20世纪70世纪诞生于贝尔实验室,现在CentOS用的是gawk
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
1.2工作原理
逐行读取文本,默认以空格或Tab键为分隔符进行分割,将分割所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较,倾向于将一行分成多个"“字段"然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符” &&“表示"与”、“||表示"或”、"!“表示非”;还可以进行简单的数学运算,如+、一、*、/、%、^分别表示加、减、乘、除、取余和乘方。
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次
1.3 命令格式
awk选项’模式或条件{操作}'文件1文件2 …
awk -f 脚本文件 文件1 文件2 …
格式:awk关键字 选项 命令部分 ‘{xxxx}’ 文件名
awk 包含几个特殊的内建变量(可直接用)如下所示:
| 变量 | 说明 |
|---|---|
| FS | 指定每行文本的字段分隔符,默认为空格或制表单位 |
| NF | 当前处理的行的字段个数 |
| NR | 当前处理的行的行号(序号) |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME | 被处理的文件名 |
RS∶ 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’
1.4awk常用小命令
#删除temp文件的重复行
awk '!($0 in array) { array[$0]; print }' temp
#查看最长使用的10个unix命令
awk '{print $1}' ~/.bash_history | sort | uniq -c | sort -rn | head -n 10
#查看机器的ip列表
ifconfig -a | awk '/Bcast/{print $2}' | cut -c 5-19
#查看机器的每个远程链接机器的连接数
netstat -antu | awk '$5 ~ /[0-9]:/{split($5, a, ":"); ips[a[1]]++} END {for (ip in ips) print ips[ip], ip | "sort -k1 -nr"}'
#查看某个进程打开的socket数量
ps aux | grep [process] | awk '{print $2}' | xargs -I % ls /proc/%/fd | wc -l
#查看无线网络的ip
sudo ifconfig wlan0 | grep inet | awk 'NR==1 {print $2}' | cut -c 6-
#批量重命名文件
find . -name '*.jpg' | awk 'BEGIN{ a=0 }{ printf "mv %s name%01d.jpg\n", $0, a++ }' | bash
#查看某个用户打开的文件句柄列表
for x in `ps -u 500 u | grep java | awk '{ print $2 }'`;do ls /proc/$x/fd|wc -l;done
#计算文件temp的第一列的值的和
awk '{s+=$1}END{print s}' temp
#查看最常用的命令和使用次数
history | awk '{if ($2 == "sudo") a[$3]++; else a[$2]++}END{for(i in a){print a[i] " " i}}' | sort -rn | head
#查找某个时间戳的文件列表
cp -p `ls -l | awk '/Apr 14/ {print $NF}'` /usr/users/backup_dir
#格式化输出当前的进程信息
ps -ef | awk -v OFS="\n" '{ for (i=8;i<=NF;i++) line = (line ? line FS : "") $i; print NR ":", $1, $2, $7, line, ""; line = "" }'
#查看输入数据的特定位置的单个字符
echo "abcdefg"|awk 'BEGIN {FS="''"} {print $2}'
#打印行号
ls | awk '{print NR "\t" $0}'
#打印当前的ssh 客户端
netstat -tn | awk '($4 ~ /:22\s*/) && ($6 ~ /^EST/) {print substr($5, 0, index($5,":"))}'
#打印文件第一列不同值的行
awk '!array[$1]++' file.txt
#打印第二列唯一值
awk '{ a[$2]++ } END { for (b in a) { print b } }' file
#查看系统所有分区
awk '{if ($NF ~ "^[a-zA-Z].*[0-9]$" && $NF !~ "c[0-9]+d[0-9]+$" && $NF !~ "^loop.*") print "/dev/"$NF}' /proc/partitions
#查看2到100所有质数
for num in `seq 2 100`;do if [ `factor $num|awk '{print $2}'` == $num ];then echo -n "$num ";fi done;echo
#查看第3到第6行
awk 'NR >= 3 && NR <= 6' /path/to/file
#逆序查看文件
awk '{a[i++]=$0} END {for (j=i-1; j>=0;) print a[j--] }'
#打印99乘法表
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
————————————————
版权声明:本文为CSDN博主「84岁带头冲锋」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/L2111533547/article/details/1246890161.5 awk的一些小案例
1.5.1 打印文本内容
awk可以将自动将多个空格压缩成一个空格
打印字符串需要加双引号
案例1:打印磁盘已经使用情况
[rootljy.localdomain~]# df | awk '{print $5}'
已用%
4%
0%
0%
1%
0%
15%
1%
0%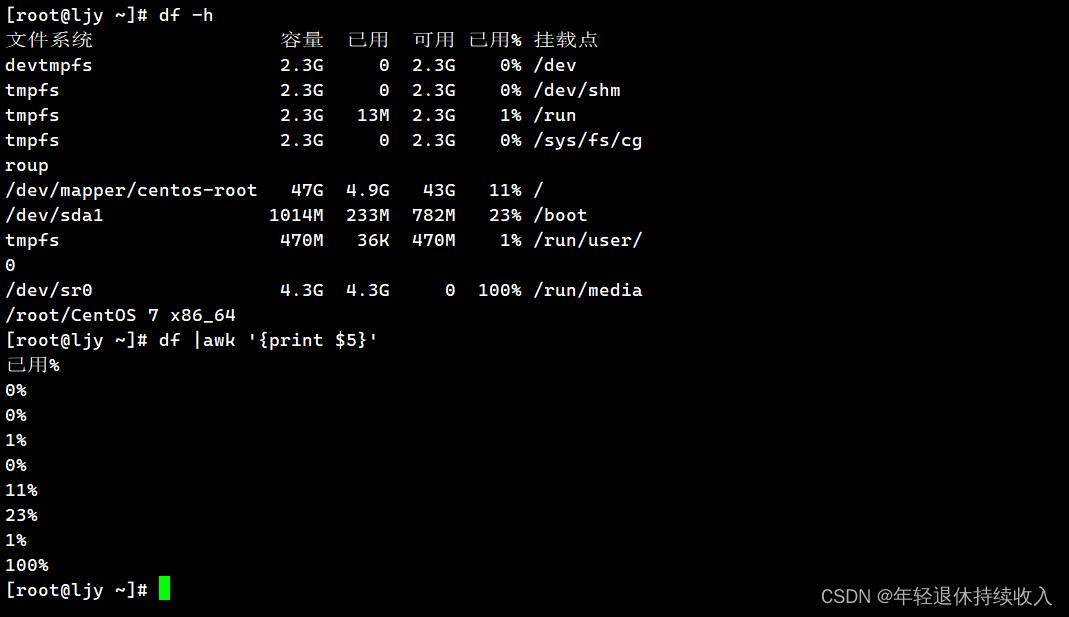
1.5.2 根据$n提取字段
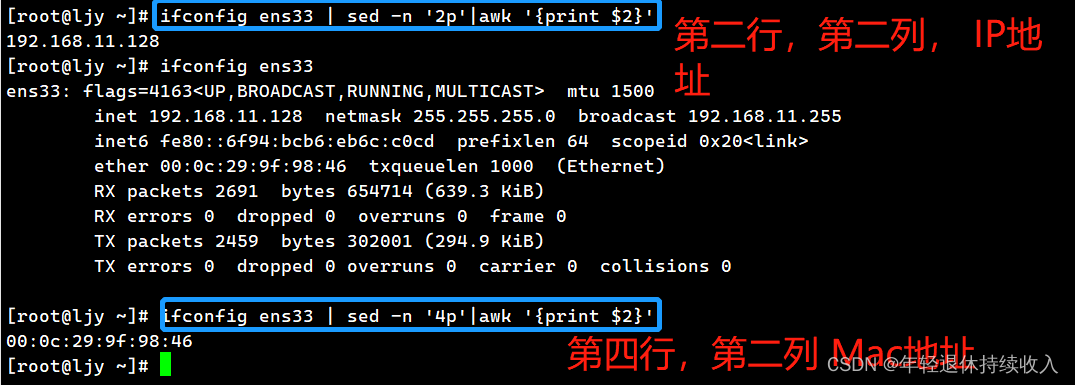
提取IP地址,Mac地址,结合sed命令
[root@ljy ~]# ifconfig ens33 | sed -n '2p'|awk '{print $2}'
192.168.11.128
[root@ljy ~]# ifconfig ens33
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.11.128 netmask 255.255.255.0 broadcast 192.168.11.255
inet6 fe80::6f94:bcb6:eb6c:c0cd prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:9f:98:46 txqueuelen 1000 (Ethernet)
RX packets 2691 bytes 654714 (639.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2459 bytes 302001 (294.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@ljy ~]# ifconfig ens33 | sed -n '4p'|awk '{print $2}'
00:0c:29:9f:98:46
1.5.3 根据选项-F指定分隔符
打印单列
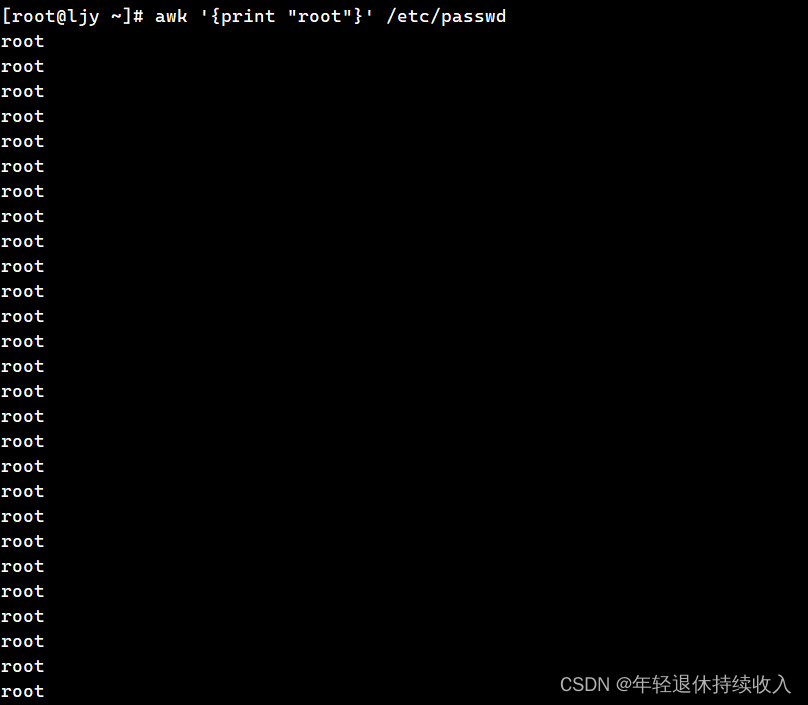
[root@ljy ~]# cat /etc/passwd |awk -F":" '{print $1}'
root
bin
daemon
adm
lp
sync
shutdown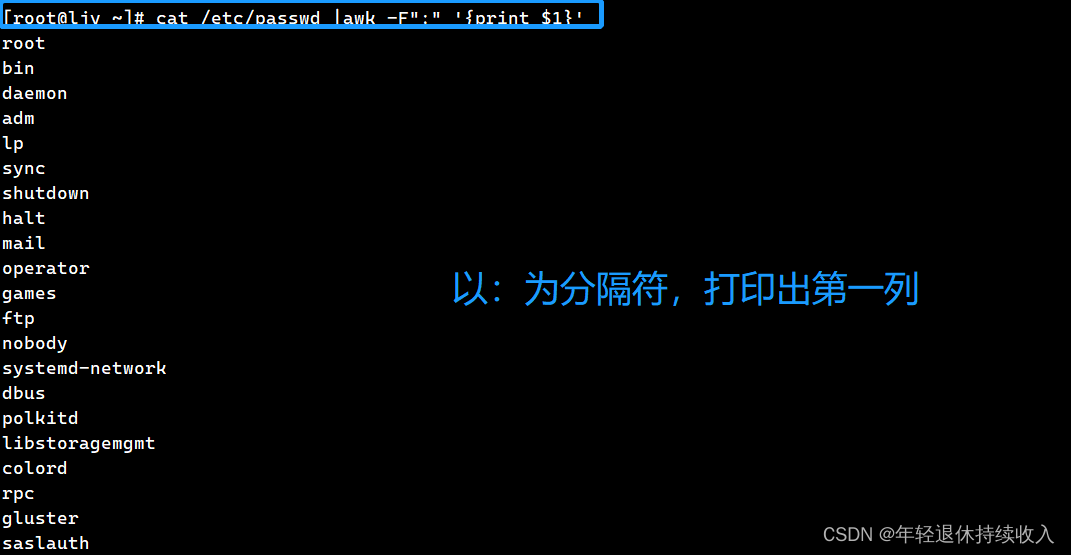
打印多列内容
打印时逗号可以表示空格,如果使用“:”或者“+”,需要将特殊符号加上双引号当成字符串打印
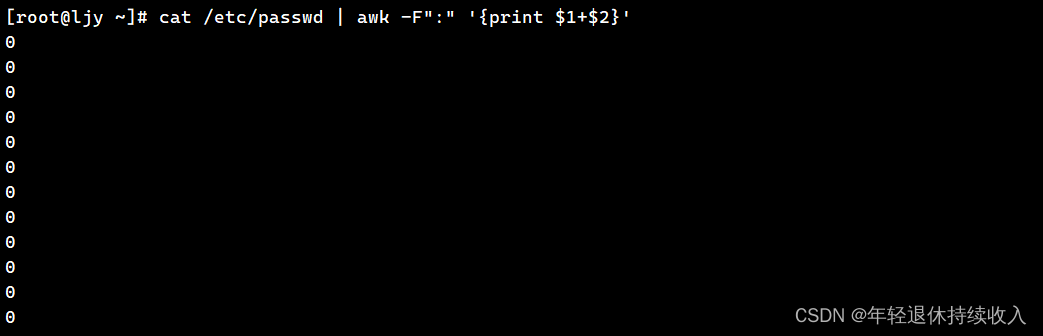
[root@ljy ~]# cat /etc/passwd | awk -F":" '{print $1+$2}'
0
0
0
0
0
0
0
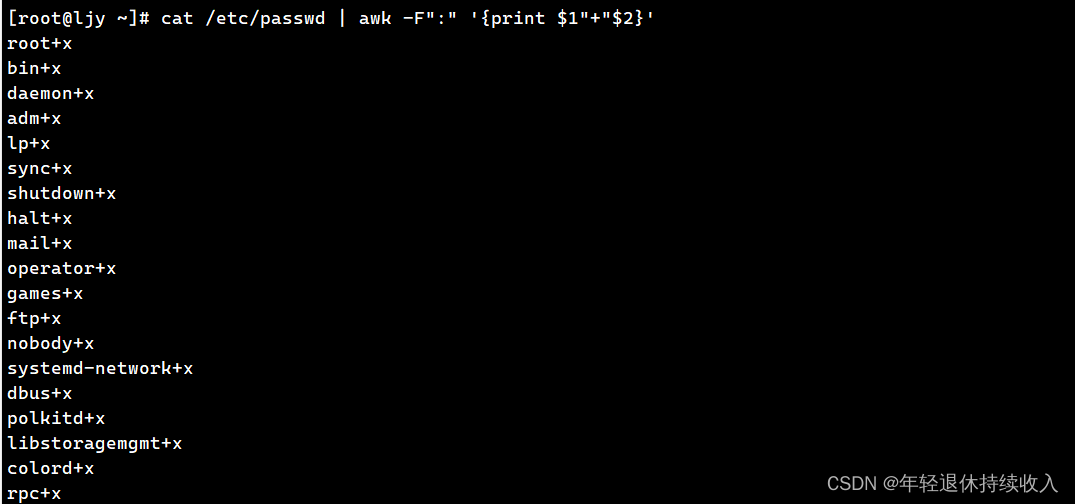
[root@ljy ~]# cat /etc/passwd | awk -F":" '{print $1"+"$2}'
root+x
bin+x
daemon+x
adm+x
lp+x
sync+x
shutdown+x
halt+x
mail+x
operator+x
[root@ljy ~]# localdomain~]# cat /etc/passwd | awk -F":" '{print $1,$2}'
打印磁盘已经使用情况,去除%
[root@ljy ~]# df|awk '{print $5}'|awk -F% '{print $1}'|sed -n "1,3p"
已用
0
0
[root@ljy ~]# df |awk -F"( |%)+" '{print $5}' |sed -n "1,3p"
已用
0
0
[root@ljy ~]# df |awk -F"( |%)+" '{print $5}' |sed -n "1,3p"
已用
0
0

1.6 使用BEGIN输出包含指定字符的行并统计有多行
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;
awk再处理指定的文本,之后再执行END模式中指定的动作;
END{ } 语句块中,往往会放入打印结果等语句。
示例:
统计打印出/bin/bash结尾的数目
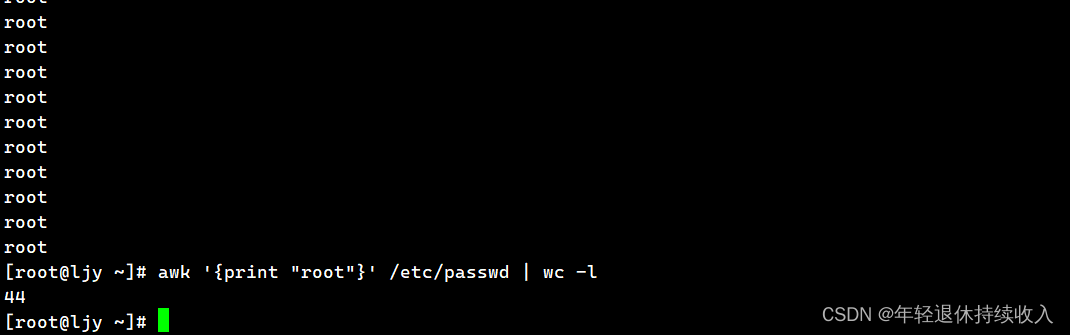
[root@ljy ~]# awk 'BEGIN {x=0};/\/bin\/bash$/;{x++};END{print x}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
cxsr:x:1000:1000:cxsr:/home/cxsr:/bin/bash
44
[root@ljy ~]#

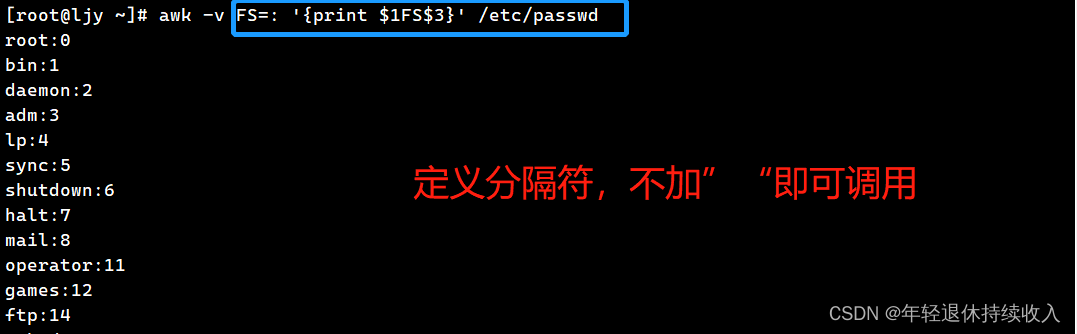
1.7 FS∶ 列分割符提取列
[root@ljy ~]# awk -v FS=: '{print $1FS$3}' /etc/passwd
root:0
bin:1
daemon:2
adm:3
lp:4
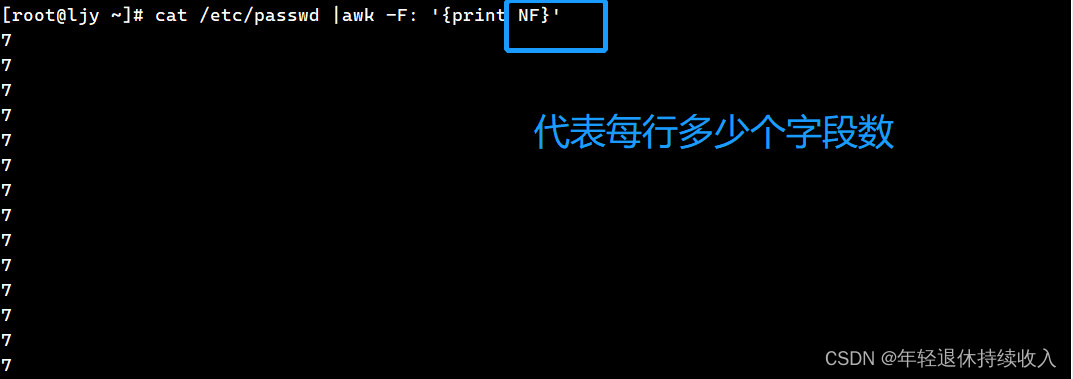
1.8 NF∶当前处理的行的字段个数
[root@ljy ~]# cat /etc/passwd |awk -F: '{print NF}'
7
7
7
7
7
7
7
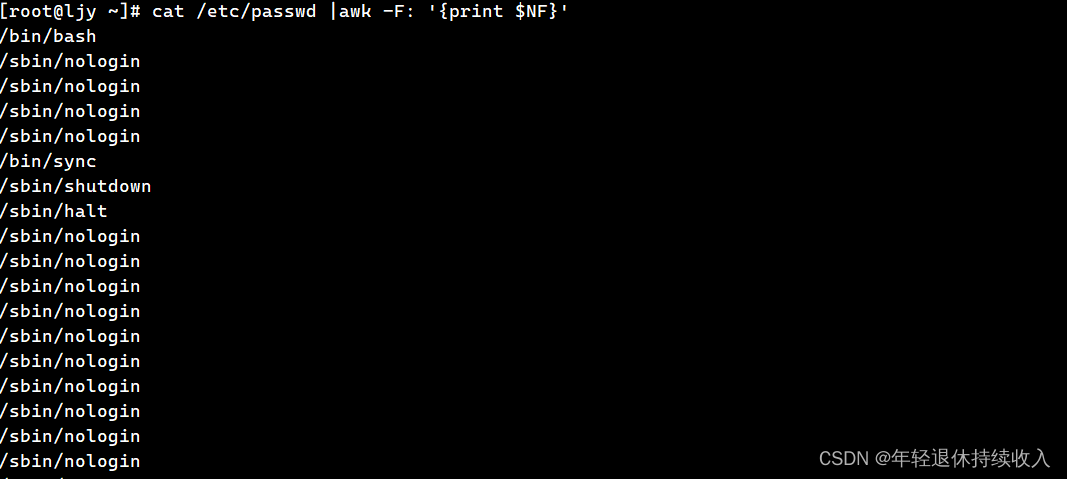
打印出每段最后一个字符
[root@ljy ~]# cat /etc/passwd |awk -F: '{print $NF}'
/bin/bash
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
打印出倒数第二行
[root@ljy ~]# cat /etc/passwd |awk -F: '{print $(NF-1)}'
/root
/bin
/sbin
/var/adm
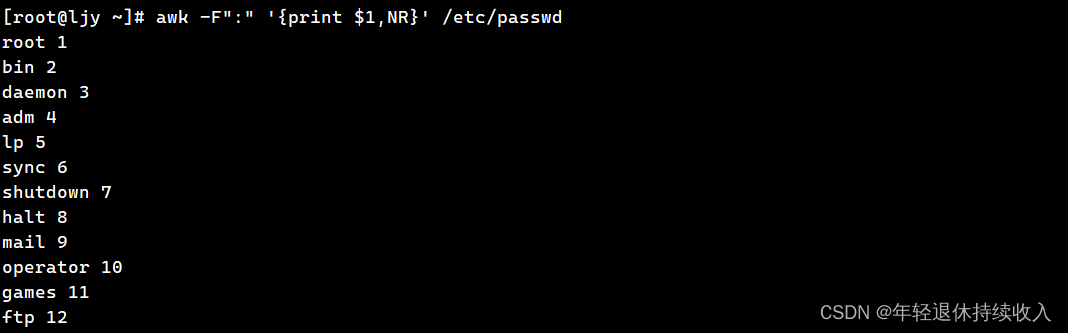
1.9 NR: 当前处理的行的行号
[root@ljy ~]# awk -F":" '{print $1,NR}' /etc/passwd
root 1
bin 2
daemon 3
adm 4
lp 5
sync 6
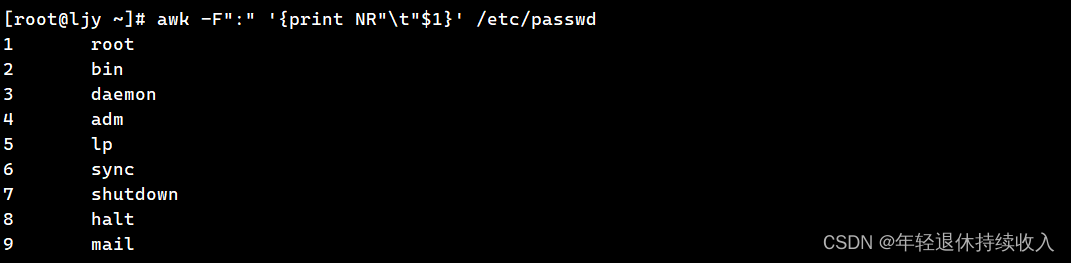
[root@ljy ~]# awk -F":" '{print NR"\t"$1}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
 NR==n代表行号等于什么
NR==n代表行号等于什么
[root@ljy ~]# awk -F: 'NR==2 {print $1}' /etc/passwd
bin
[root@ljy ~]#

总结
通过sed 与awk的配合可以更好的查找到我们想要的数据