之前聊了Redis很基础的一些东西,今天稍微聊点作为一个想要晋级为中级程序猿必须掌握的东西----Redis的集群。任何一个高并发的系统都一定绕不开Redis,而作为一个高并发的系统设计初期就一定会思考如何在保证吞吐的情况下提高自己记得容灾能力,对就是我们今天要聊的集群。先补充一句,没有最好的技术,只有最适合自己项目的技术。我们的目的是为了让项目在尽量少出Bug的情况下稳定运行,不是造缝合怪,一股脑的往项目里堆看起来最牛x的技术会增加很多不必要的维护成本。
一.为什么要集群
1.集群可以避免单节点故障
单节点的应用总会有单点故障的问题,当你的机器宕机,整个系统不可被访问,一般我们可以通过集群的方式来解决单节点故障,提高系统的可用性。
2.集群可以提高并发作业能力
单个机器(应用)的作业能力是有限的,在某些高业务量(并发)的应用中,我们也可以通过集群的手段来提升应用的作业能力。我之前闲来无聊试了一下,我8核16线程在开着不少进程的情况下依然跑出了九十多万的吞吐,如果换在Linux再优化一下跑一二百万的吞吐我觉得都没什么问题,关于Redis压测的文档官方也有,我贴在下面有兴趣的小伙伴可以自己去玩一下。
虽然在生产过程中我们遇到这么高QPS的情况相对罕见,但是什么也无法阻止我们学习的脚步,万一哪天我在的公司或者我写的程序就突然火了呢,哈哈哈哈。就算用不到,学个思想也是好的。况且集群就算Redis比较罕见存在需要进一步提升并发能力,但是集群依然可以预防单节点故障。且同样适用于其他的应用,比如我几年前写的代码,如果需要面临高并发的环境的话可能就需要大量的集群。
Redis压测官方文档
二.什么是集群
前面说了集群是为了提升应用的容灾能力和并发作业能力,这里的集群指的是把应用进行复制多个相同的应用一起工作来提高作业能力,多个应用做的是相同的事情。就如同我们生活中的场商场收银台,一个柜台不足以支撑超市大量客户的结账流程,所以需要多个收银台同时工作,多个收银台都是做的相同的收银工作,这就是集群。集群可以分为数据库集群,应用集群和功能集群等
集群就是多个应用分散在不同的服务器,每个应用跑的是同一套代码做的是相同的工作,以提高系统的整体性能,如果其中一个服务崩溃了,并不会影响集群内其他服务继续正常运行。
那么问题来了,既然两个程序执行完全一致的功能,那我请求来了是发给谁了呢,如果发给同一个程序的话不就是去了集群的意义吗。当我们为我们的程序做了集群之后作业能力得到提升,能够处理更高的并发请求,同时产生了一个新的问题,就是客户端的请求应该如何相对平局的分发到集群中的多个应用呢?这就需要负载均衡器了。
为了方便理解我们来再看我们的收银台案例:假如收银台排队的客户比较多,我们多设置几个收银台,当你拿着东西出来结账时是不是会去排在最短的那一队。
在我们的应用程序中也是这样,当我们的应用做了集群,那么就会存在多个应用节点,多个应用将会暴露多个访问地址(ip:port),那客户端是不知道该访问哪个应用节点的,这个时候我们就需要有一个请求分发的功能的组件(负载均衡器)将客户端的请求相对平均的分发多个应用节点上,这就是负载均衡。
这里就简单讲一下吧,分布式集群加负载均衡又是一大片森林,根本说不完。大概理解一下,应该能看到这里的好兄弟们这些概念性的东西应该不成问题。后面补全这部分再过来留链接。
三.Redis的集群方案之----主从
1.Redis主从
主从复制是指将一台Redis服务器(主)的数据,复制到其他的Redis服务器(从)。前者称为主节点(aster),后者称为从节点(slave),数据只能由主节点复制到从节点。默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
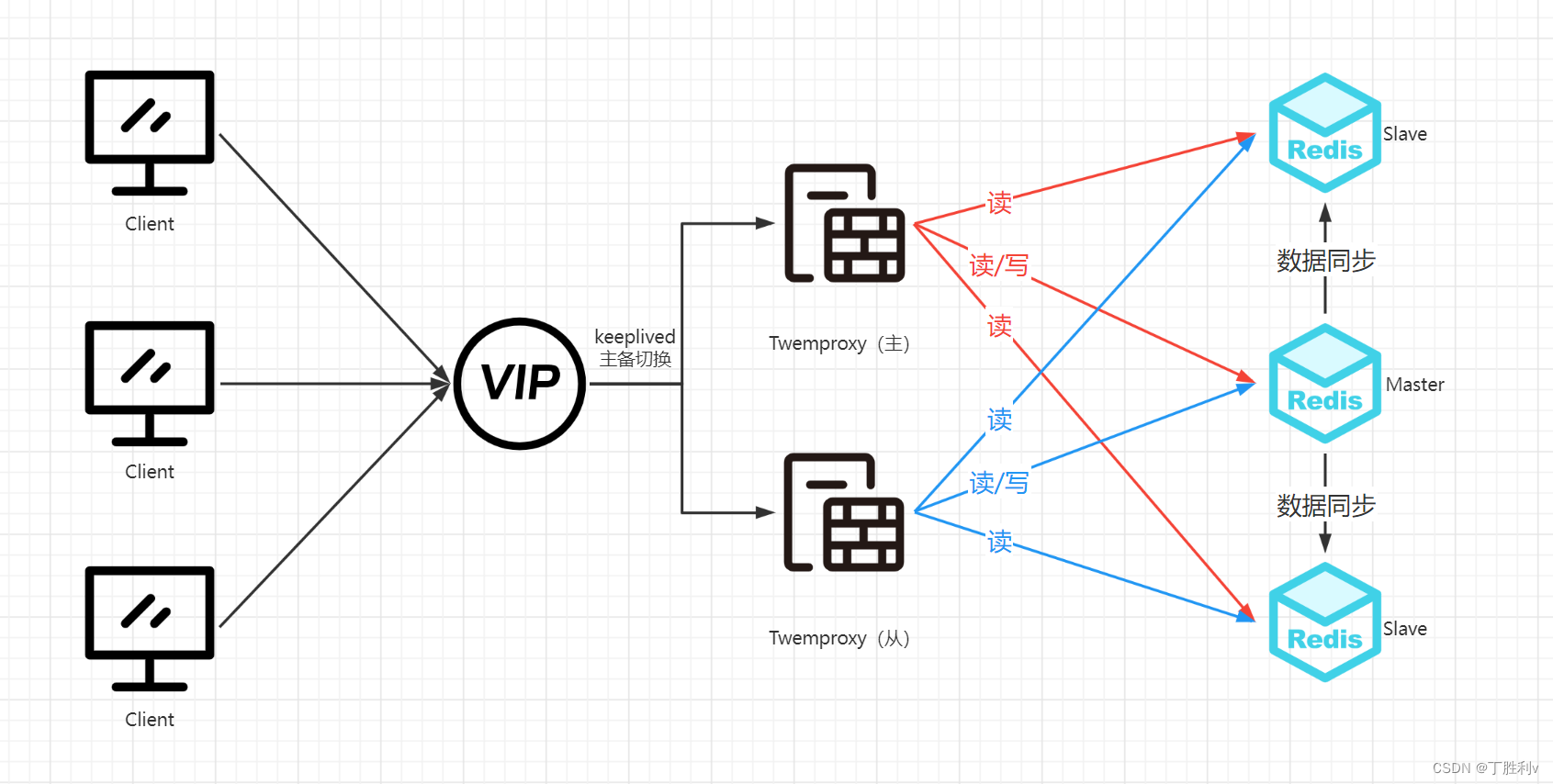
写请求到主Redis,读请求到从Redis ,读/写的路由需要负载均衡器(主Twemproxy/从Twemproxy) ,而主从Redis的负载均衡器需要做主备切换(keeplived)
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。该方案很好的解决了单个Redis实例承载能力的问题。当然,Twemproxy本身也是单点,当一台Twemproxy在工作,另外一台处于备机,当一台挂掉以后vip自动漂移,备机接替工作。需要用Keepalived做高可用方案。通过Twemproxy可以使用多台服务器来水平扩张Redis服务,可以有效的避免单点故障问题。
Redis主从优点
防止数据丢失,数据在从节点都有备份
读写分离,分担读压力
Redis主从的缺点
不能分担写压力
主节点挂了整个集群不可用
数据存储上限为主节点的上限,未得到扩容
四.Redis的集群方案之----哨兵
1.什么是哨兵
当主服务器中断服务后,可以将一个从服务器升级为主服务器 ,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。Redis-Sentinel是用于管理Redis集群,该系统执行以下三个任务
1.监控(Monitoring) Sentinel会不断地检查你的主服务器和从服务器是否运作正常;
2.提醒(Notification) 当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知;
3.自动故障迁移(Automatic failover):当主服务器不可用,Sentinel会自动选举一个从服务器作为新主服务器,并让其它的从服务器从新的主服务器复制数据,用户的请求会被变更为新的主服务器
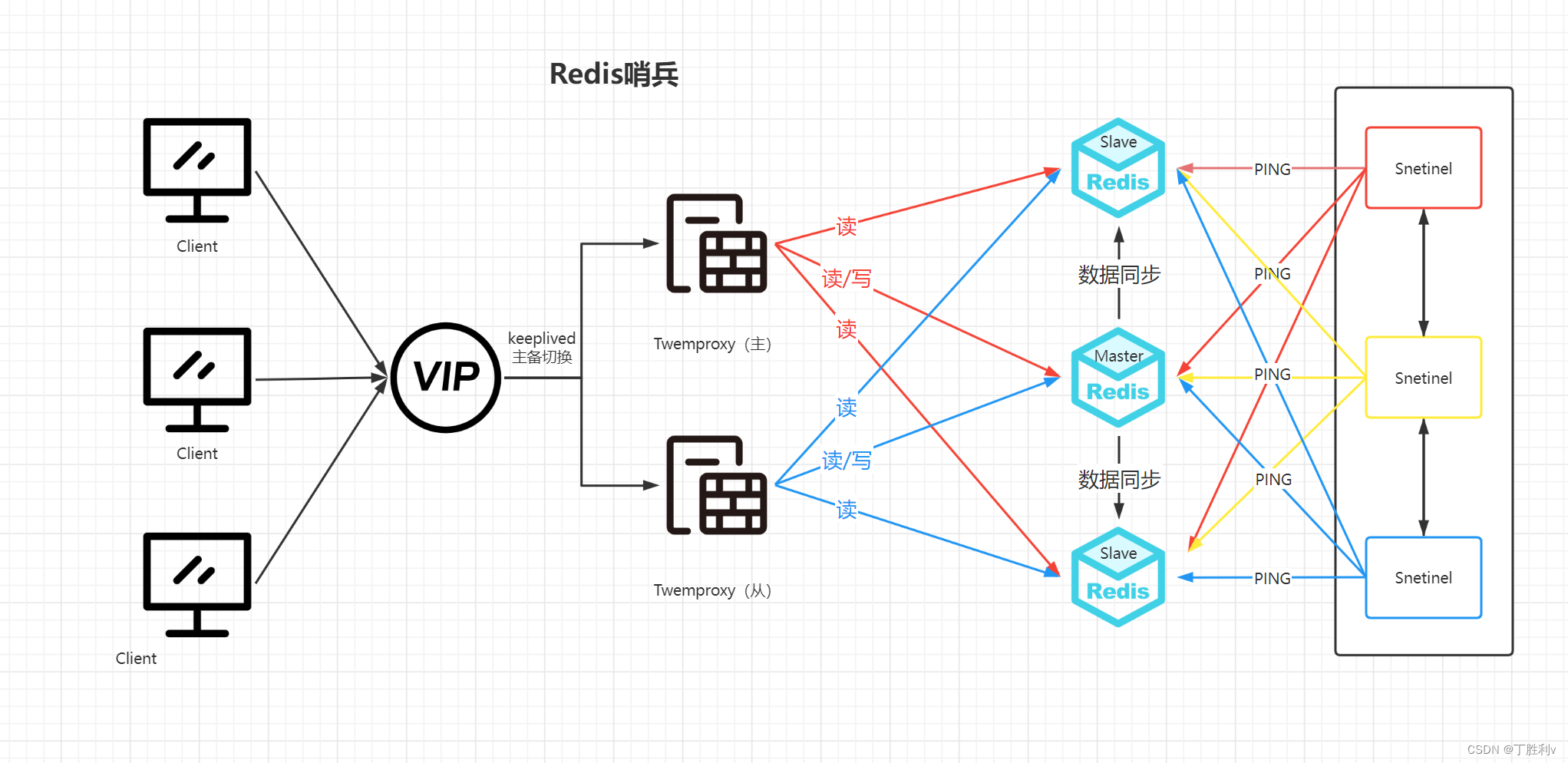
2.哨兵是如何运作的
(1)主观下线
每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及 其他Sentinel(哨兵)进程发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项 所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
(2)客观下线
当有足够数量(半数以上)的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围 内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线 (ODOWN)
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状 态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master 主服务器的主观下线状态就会被移除。
(3)故障转移
当前哨兵虽然发现了主数据客观下线,需要故障恢复,但故障恢复需要由领头哨兵来完成。这样来保 证同一时间只有一个哨兵来执行故障恢复,选出领头哨兵后,领头哨兵将会开始对主数据库进行故障 恢复。
首先是从主服务器的从服务器中选出一个从服务器作为新的主服务器。选出之后通过slaveif no ont将 该从服务器升为新主服务器。
所有在线的从数据库中,选择优先级最高的从数据库。优先级通过replica-priority参数设置,优先级相 同,则复制的命令偏移量越大(复制越完整)越优先 , 如果以上都一样,则选择运行ID较小的从数据库选出一个从数据库后,领头哨兵将向从数据库发送SLAVEOF NO ONE命令使其升格为主数据库,而后领 头哨兵向其他从数据库发送 SLAVEOF命令来使其成为新主数据库的从数据库,最后一步则是更新内部 的记录,将已经停止服务的旧的主数据库更新为新的主数据库的从数据库,使得当其恢复服务时自动 以从数据库的身份继续服务。
如下图
哨兵的优点
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
主从可以自动切换,系统更健壮,可用性更高。
哨兵的缺点
哨兵依然是主从模式,没法解决写的压力,只能减轻读的压力
存储得不到扩容,存储数据总量是主的数据总量
当主服务器宕机后,从服务器切换成主服务器的这段时间,服务不可用。
五.Redis的集群方案之----Cluster
1.什么是Cluster
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上都可以存储不同的内容。
Redis-Cluster采用无中心结构,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
但是如果每台Redis都存储不同数据的话,我们应该到哪台Redis中去寻找我们所需要的数据呢。
2.Cluster的特点
(1)数据分散存储
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
举个栗子,我规定:号码为0-59总共60个小球,小明,小红,小李三个人分别拿0-19、20-39、40-59号码的小球,当你想拿到55号球的时候可以直接快速找到小李去拿到55号球。而不
(2)容错机制-投票
为了防止主节点数据丢失,可以为每个主节点可以准备特点数目的备节点,主节点挂掉从节点可以升级为主节点(哨兵模式) 。
容错机制指的是,如果半数以上master节点与故障节点通信超过(cluster-node-timeout),认为该节点故障,自动触发故障转移操作. 故障节点对应的从节点自动升级为主节点 , 如果某个主挂掉,而没有从节点可以使用,那么整个Redis集群进入宕机状态
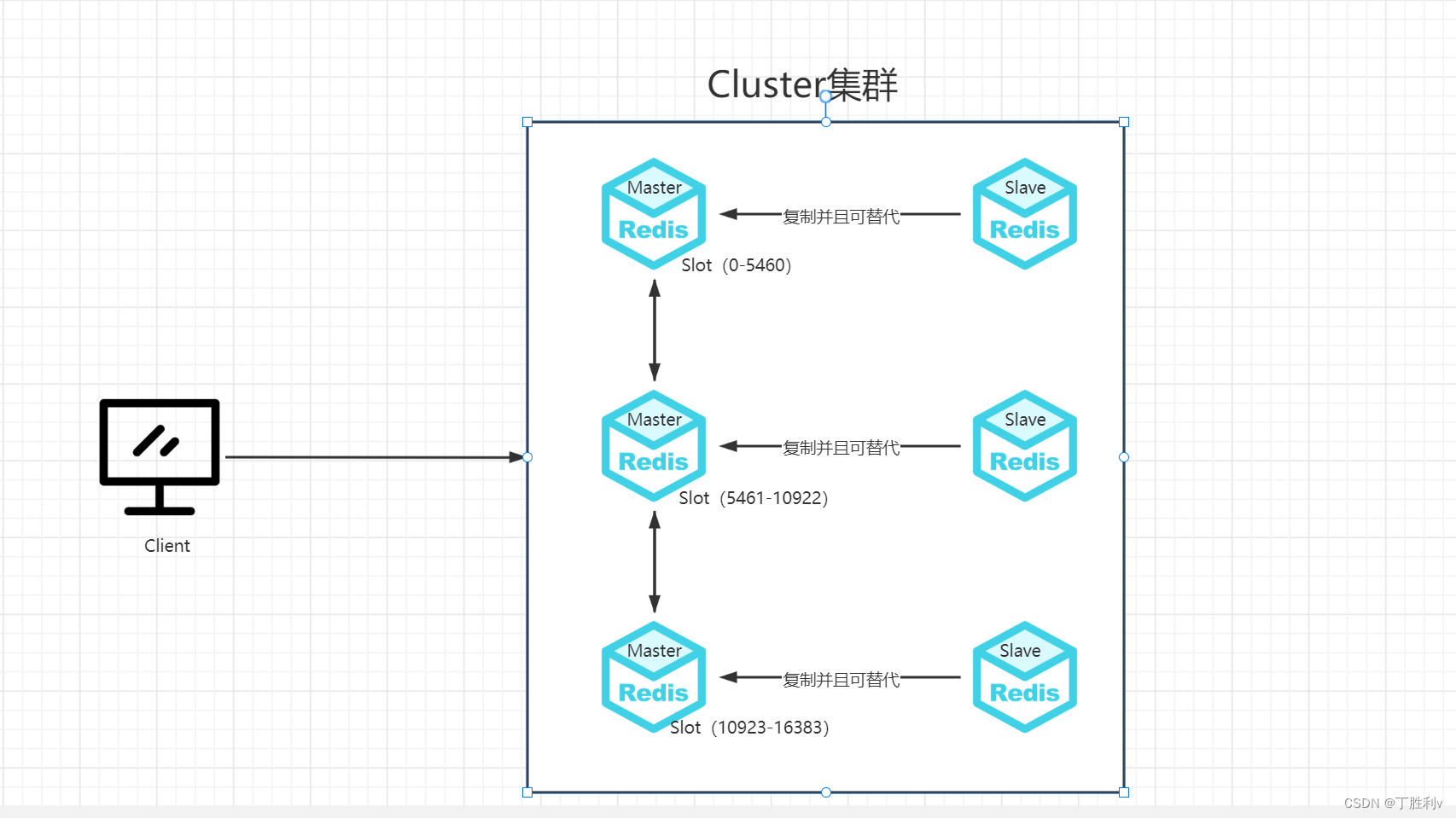
Cluster的优点
多主多从,数据分布式存储
每个主节点分别保存各自的数据和集群状态,相对独立
当一个主节点发生通信故障时,该节点的从节点可以自动升级为主节点继续运行知道故障主节点无对应的从节点,整个集群宕机
可以看出,Cluster拥有几乎主从和哨兵的全部优点。
Cluster的缺点
想了半天好像也没有什么致命缺陷,就除了部署成本较高就剩学习成本相对较高了吧。想到再回来补充吧,大家有什么想到的也欢迎交流。
为什么要做Redis集群以及Redis集群实现的原理,本专栏的下一期会介绍在我们的JAVA代码中如何实现Redis的集群。