21 neurips
1 intro
1.1 背景
- 以ViT:《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》为代表的视觉Transformer通常将图像数据划分为固定数目的patch
- 将每个patch对应的像素值采用线性映射等方式嵌入为一维的token,作为Transformer模型的输入
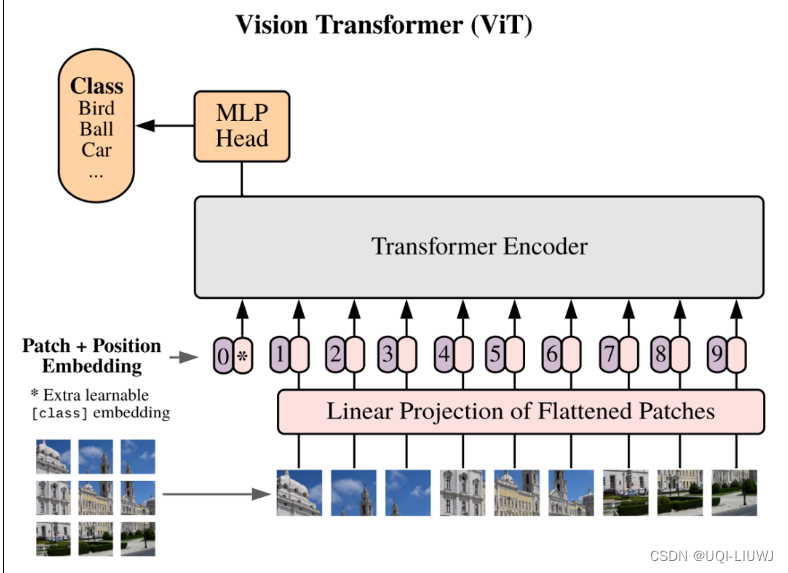
- 假设模型结构固定,即每个token的维度大小固定,将输入表征为更多的token可以实现对图片更为细粒度的建模,往往可以有效提升模型的测试准确率;
- 然而与此相对,由于Transformer的计算开销随token数目成二次方增长,增多token将导致大量增长的计算开销。
- 为了在精度和效率之间取得一个合适的平衡,现有的ViT模型一般将token数设置为14x14或16x16。
1.2 论文思路
- 但本篇论文认为,采用定长的token序列表征数据集中所有的图像是一种低效且次优的做法,一个更合适的方法应当是,根据每个输入的具体特征,对每张图片设置对其最合适的token数目
- 具体而言,不同图片在内容、远近、物体大小、背景、光照等诸多方面均存在较大的差异,将其切分为相同数目和大小的patch没有考虑适应这些要素的变化,因而极有可能是次优的
- 左侧的苹果图片构图简单且物体尺寸较大,右侧图片则包含复杂的人群、建筑、草坪等内容且物体尺寸均较小。
- 显然,前者只需要少量token就可以有效表征其内容,后者则需要更多的token描述不同构图要素之间的复杂关系。

- 论文使用比原文推荐值(14x14)更少的token数目训练了一个T2T-ViT-12模型,并报告了对应的测试精度和计算开销。

- 从结果中可以看到,若将token数目设置为4x4,准确率仅仅下降了15.9%,但计算开销下降了8.5倍
- ——>这一结果表明,正确识别占数据大多数的较“简单”的样本只需4x4或更少的token,相当多的计算浪费在了使用存在大量冗余的14x14 token表征他们
- 从结果中可以看到,若将token数目设置为4x4,准确率仅仅下降了15.9%,但计算开销下降了8.5倍
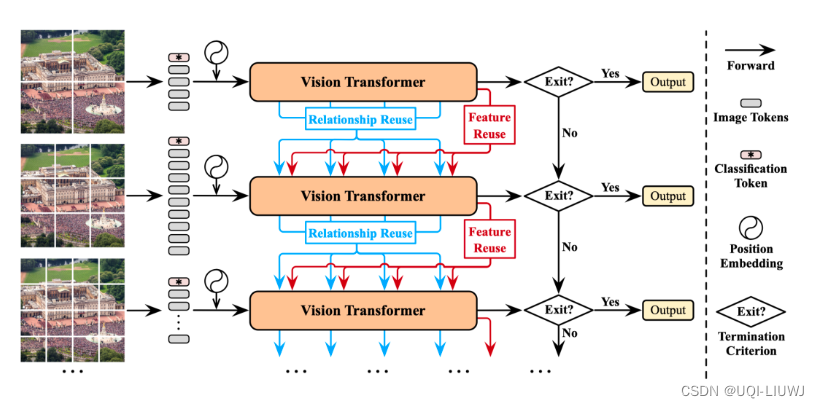
- 提出一种可针对每个样本自适应地使用最合适的token数目进行表征的动态ViT模型。
- 该方法在ImageNet上将T2T-ViT的平均推理速度(GPU实测)加快了1.4-1.7倍。
- 其主要思想在于利用级联的ViT模型自动区分“简单”与“困难”样本,实现自适应的样本推理。
- 为了减少级联模型中的冗余计算,文章还提出了特征重用与关系重用的模型设计思路。
2 方法
- 论文提出了一个动态视觉Transformer框架(Dynamic Vision Transformer,DVT),意在针对每个样本选择一个合适数目的token来进行表征
2.1 推理过程
- 使用从小到大的token数目训练了一组Transformer模型,他们具有相同的基本结构,但是参数相互独立,以分别适应逐渐增多的token数目
- 对于任意测试样本,首先将其粗略表征为最小数目的token,输入第一个Transformer,以低计算成本迅速得到初步预测。
- 而后判断预测结果是否可信
- 若可信,则直接输出当前结果并终止推理;
- 若不可信,则将输入图片表征为更多的token,激活下一个Transformer进行更细粒度、但计算开销更大的的推理,得到结果之后再次判断是否可信,以此类推。
- 而后判断预测结果是否可信
- 论文采用将预测的置信度(confidence)与一个固定阈值进行比较的方式作为准出的判断准则

- 第i个出口产生softmax预测pi时,pi的最大条目,即
(定义为置信度)与阈值ηi进行比较。
- 如果
- 否则,图像将使用更多token来激活下游Transformer。
- 如果
- B是给定的计算资源的预算
- 第i个出口产生softmax预测pi时,pi的最大条目,即
2.2 训练过程
记pi为第i个出口库的softmax预测概率,表示交叉熵损失,那么训练目标为:

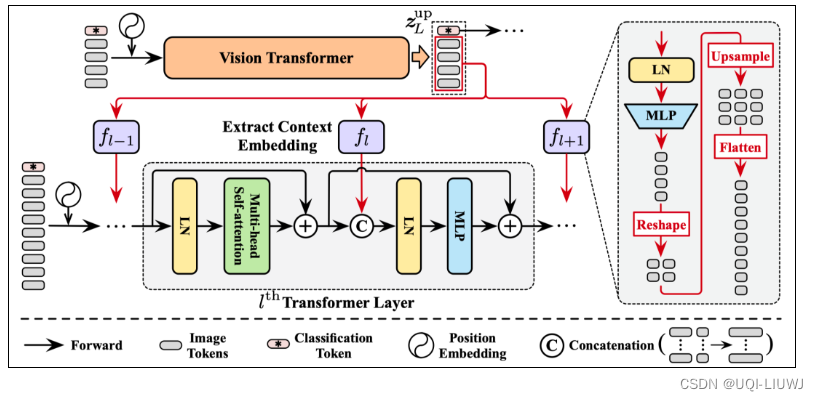
2.3 上下文嵌入
- DVT框架中所有的Transformer都具有相同的训练目标。
- 因此当一个处于下游位置的Transformer被激活时,一个显然更为高效的做法是,在先前Transformer已提取的特征的基础上进行进一步提升,而非完全从0开始重新提取特征。
- ——>论文提出了一个特征复用机制
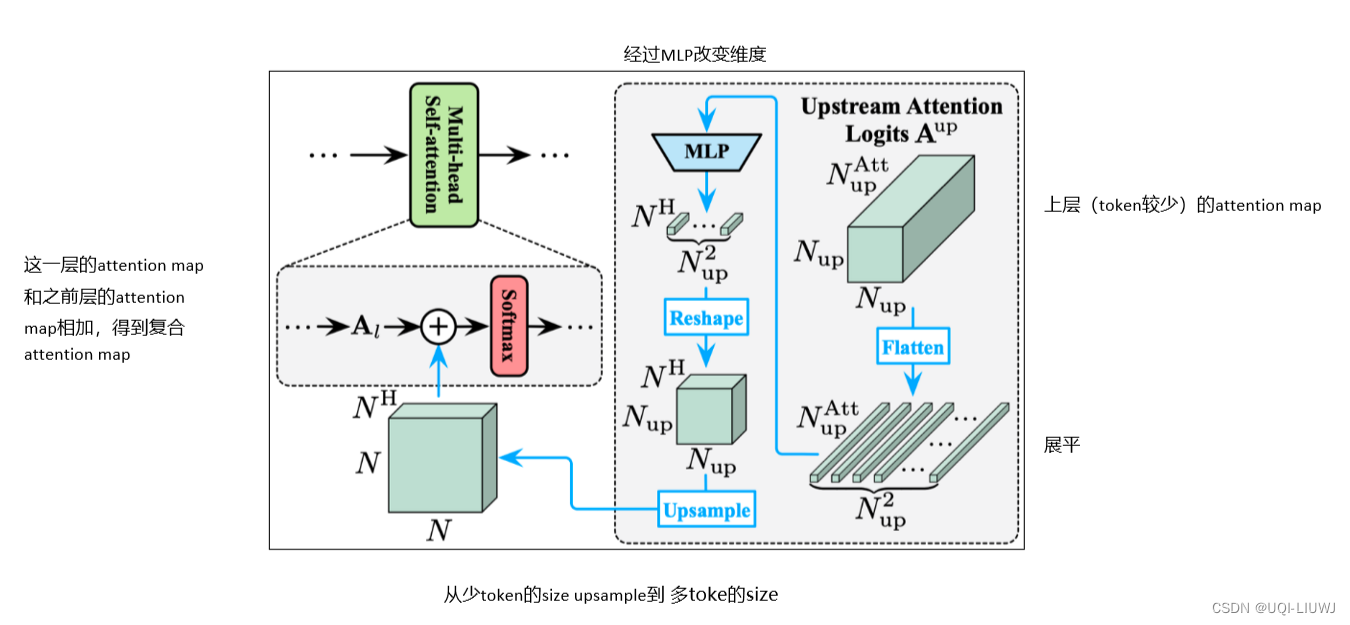
将上游Transformer最后一层输出的特征取出
经MLP变换和上采样(Upsample)后,作为上下文嵌入(Context Embedding)以Concat的方式整合入下游模型每一层的MLP模块中。
2.4 关系复用
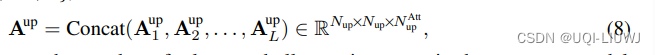
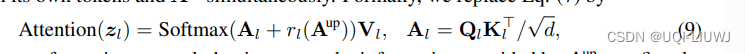
- 位于下游的模型同样可以借助上游Transformer已经得到的注意力图来进行更准确的全局注意力关系建模,论文称之为关系复用
- 上游模型的全部注意力图以logits的形式进行整合,经MLP变换和上采样后,加入到下层每个注意力图的logits中
- 这样,下游模型每一层的attention模块都可灵活复用上游模型不同深度的全部attention信息,且这一复用信息的“强度”可以通过改变MLP的参数自动地调整。
机器学习笔记: Upsampling, FCN, DeconvNet,U-Net, U-net variant_u-net地物分类机器学习_UQI-LIUWJ的博客-CSDN博客
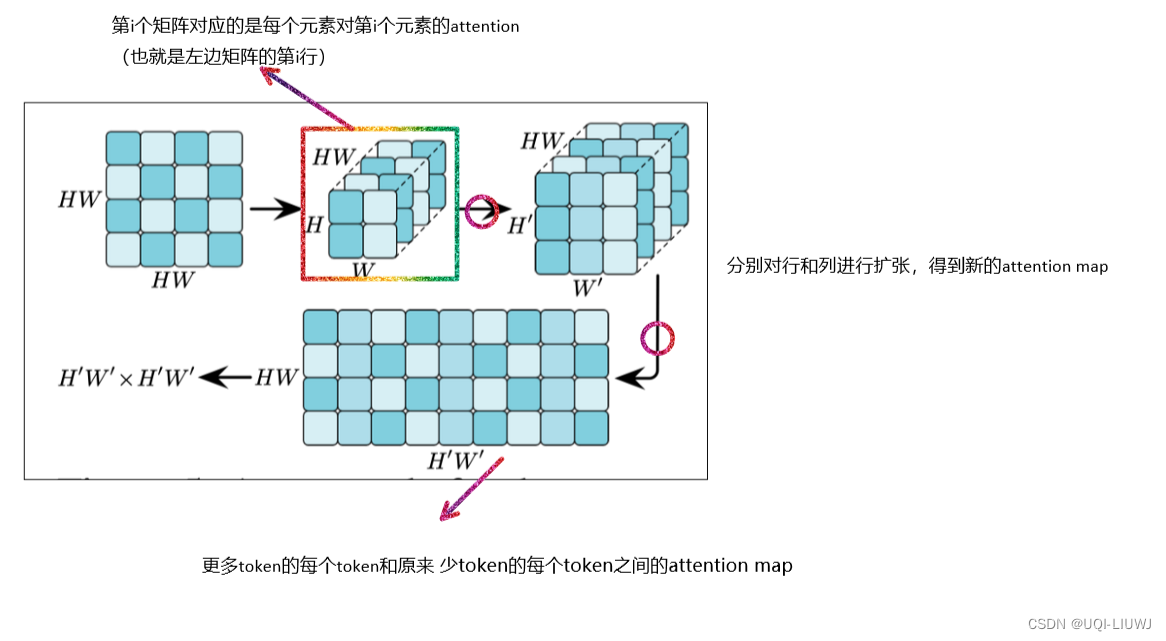
这一段论文没说特别仔细,是我推断的,如有错误,欢迎批评指正
对特征图进行上采样需要对其行或列进行重组后分别完成,以确保其几何关系的对应性
传统的上采样方法不可行
4 实验
4.1 图像识别效果
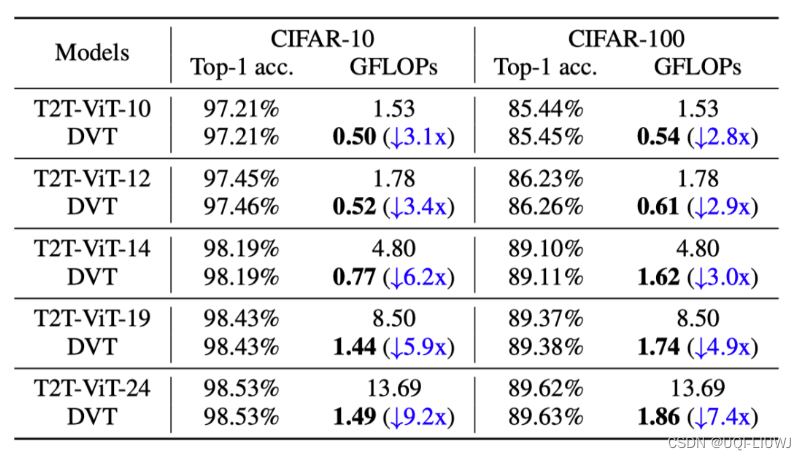
DVT(T2T-ViT-12/14)在ImageNet图像识别任务上的计算效率如下:
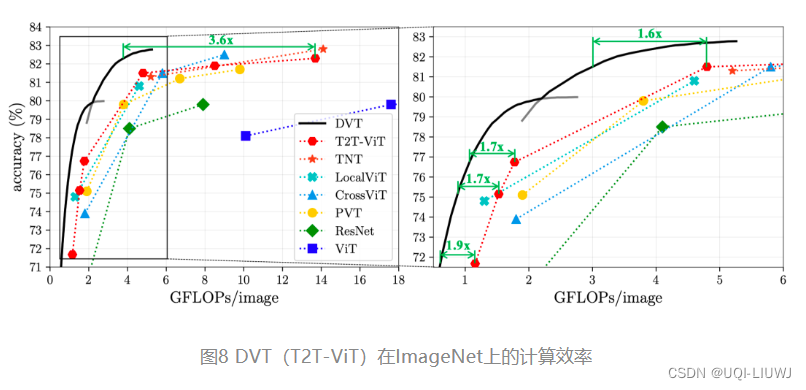
可见该方法对backbone的提速比在1.6-3.6x,对大模型效果尤为明显。
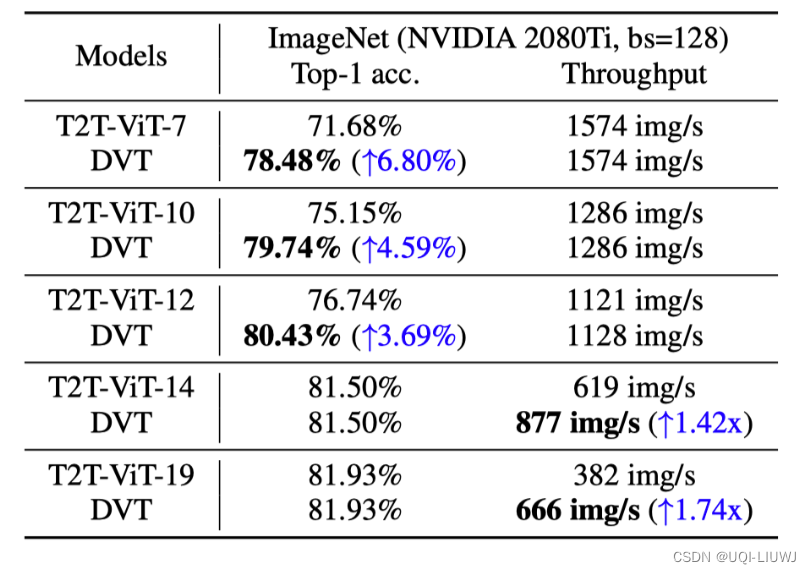
4.2 推理速度
对于小模型,DVT可以在不减慢速度的前提下显著提升效果
对于大模型,DVT可以在不降低表现的前提下显著提速
4.3 什么样的样本适合小token,什么样的样本适合多token?
“easy”和“hard”分别代表需要少和多的token数目。
可见,后者往往包含复杂的场景、较小的物体尺寸、以及一些非常规的姿态和角度。

本文含有隐藏内容,请 开通VIP 后查看