使用yolov8训练人体关键点模型;
一个模型多个类别,不同类别关键点个数不一致;
我目前了解到的好像只有COCO是有全身关键点;
COCO全身关键点链接:https://github.com/jin-s13/COCO-WholeBody
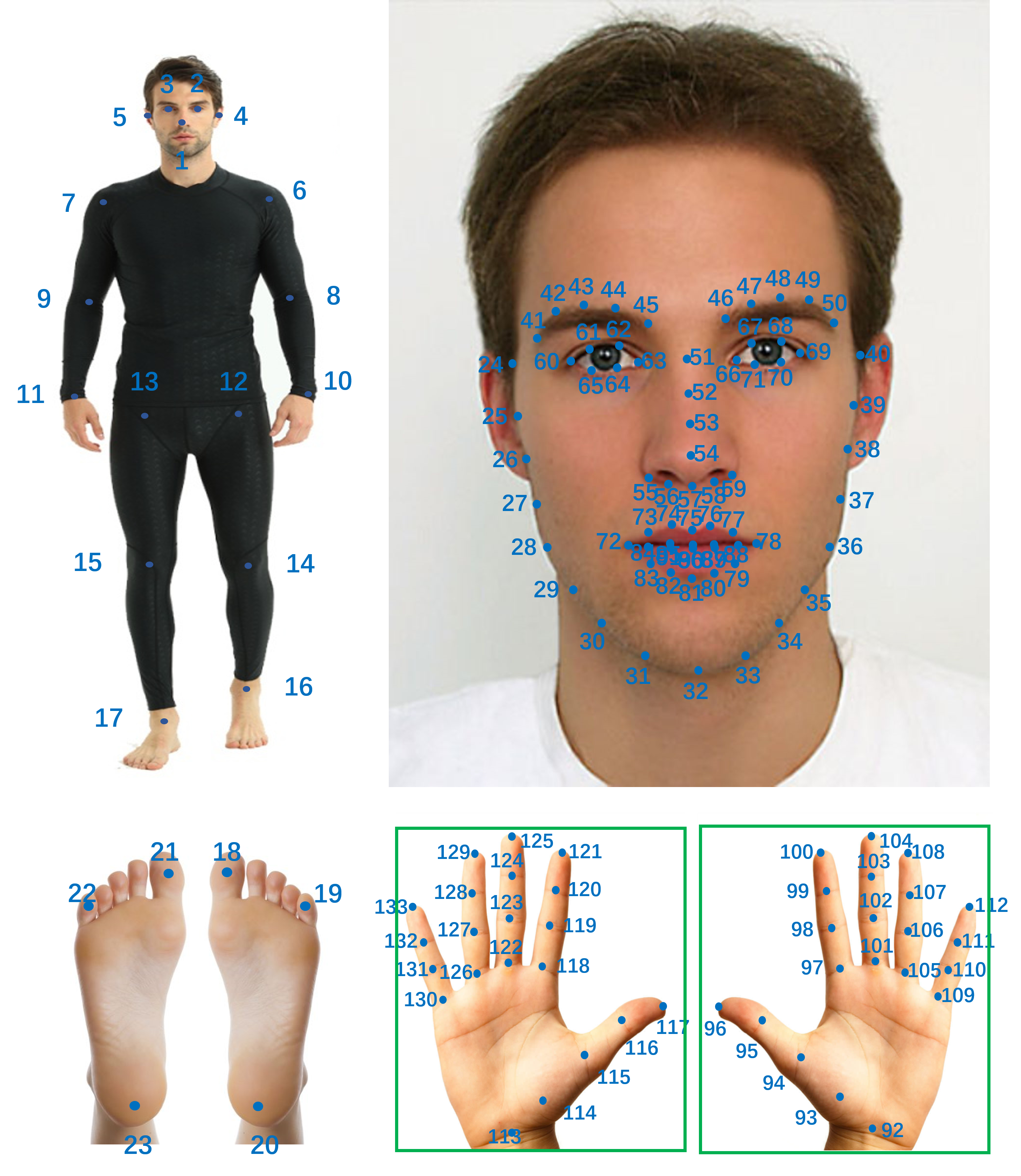
以下代码能从COCO全身标注的json中提取出来想要的关键点和对应的类别;并且直接转换成了yolov8可用的训练txt格式,
注意:其中图片使用的os.link,类似Linux中的硬链接,并非复制,如果内存充足的情况下可以使用shutil.copy替换;
20240408-测试版本代码
# -*- coding: UTF-8 -*-
"""
@Project :ultralytics
@IDE :PyCharm
@Author :沐枫
@Date :2024/4/8 15:11
"""
import os
import json
import shutil
from typing import Dict, List
from concurrent import futures
from tqdm import tqdm
import cv2
COCO_URL_ROOT = "http://images.cocodataset.org"
class DecodeWholeBodyImage:
"""
解析图片的字典信息
"""
def __init__(self, image_info: Dict):
self.license = image_info['license']
self.date_captured = image_info['date_captured']
self.flickr_url = image_info['flickr_url']
self.id = image_info['id']
self.image_id = image_info['id'] # 和annotation中的image_id一样,对应到一起可以找到对应的目标
self.file_name = image_info['file_name']
# 'http://images.cocodataset.org/val2017/000000397133.jpg'
self.coco_url = image_info['coco_url']
self.height = image_info['height']
self.width = image_info['width']
if 'http' not in self.flickr_url:
self.url = self.coco_url
else:
self.url = self.flickr_url
class DecodeWholeBodyAnnotation:
"""
一个目标的信息解析
边界框格式是ltwh
"""
def __init__(self, annotation: Dict):
# 通过这个id找图片
self.image_id = annotation['image_id']
# 是否是人群,0:不是
self.iscrowd = annotation['iscrowd']
# 分割
self.segmentation = annotation['segmentation']
# 目标的id
self.id = annotation['id']
# 目标的类别索引
self.category_id = annotation['category_id']
# 身体关键点和box
self.body_points = annotation['keypoints']
self.body_box = annotation['bbox']
self.num_keypoints = annotation['num_keypoints'] # 关键点有效个数
# 脚关键点
self.foot_points = annotation['foot_kpts']
self.foot_valid = annotation['foot_valid'] # 脚关键点的有效性
# 脸的关键点和box
self.face_points = annotation['face_kpts']
self.face_box = annotation['face_box']
self.face_valid = annotation['face_valid'] # 有效性
# left手关键点和box
self.lefthand_box = annotation['lefthand_box']
self.lefthand_points = annotation['lefthand_kpts']
self.lefthand_valid = annotation['lefthand_valid'] # 有效性
# right关键点和box
self.righthand_box = annotation['righthand_box']
self.righthand_points = annotation['righthand_kpts']
self.righthand_valid = annotation['righthand_valid'] # 有效性
# 把所有的关键点整合到一起
self.all_points = list()
self.all_points.extend(self.body_points)
self.all_points.extend(self.foot_points)
self.all_points.extend(self.face_points)
self.all_points.extend(self.lefthand_points)
self.all_points.extend(self.righthand_points)
def clip(value, min_v, max_v):
if value < min_v:
value = min_v
if value > max_v:
value = max_v
return value
def ltwh2xywhn(bbox, img_h, img_w):
"""
输入是COCO格式的box是ltwh,输出是归一化之后的xywhn,可以利用来训练yolo模型
Args:
bbox: ltwh
img_h:
img_w:
Returns:
"""
x1, y1, w, h = bbox # ltwh
x1 = clip(x1, 0, img_w)
y1 = clip(y1, 0, img_h)
x2 = clip(x1 + w, 0, img_w)
y2 = clip(y1 + h, 0, img_h)
w = x2 - x1
h = y2 - y1
# 计算box中心点坐标
x = x1 + w / 2
y = y1 + h / 2
# 归一化
x = x / img_w
y = y / img_h
w = w / img_w
h = h / img_h
return x, y, w, h
def get_point(point_index, all_points, img_shape_wh=None, max_point_num=0):
"""
根据关键点索引从关键点list中找到对应的关键点并进行归一化后转成字符串格式,返回回去
Args:
point_index: 想要的关键点的索引
all_points: 所有关键点的list
img_shape_wh: (w, h),入股哦是None,就不归一化
max_point_num: 关键点最多的个数
Returns: str
"""
current_point_num = len(point_index)
# 保存结果的字符串
res = ""
if current_point_num > 0:
# 先根据索引获取到想要的关键点
for index in point_index:
start = index * 3
end = (index + 1) * 3
x, y, v = all_points[start:end]
# 对可视信息调整
if 0 < v <= 1:
v = 1
if 1 < v <= 2:
v = 2
# 是否归一化
if img_shape_wh is not None:
img_w, img_h = img_shape_wh
x = clip(x, 0, img_w) / img_w
y = clip(y, 0, img_h) / img_h
res += f"{x:.6f} {y:.6f} {int(v)} "
# 如果关键点比较少,就使用全0填充
if current_point_num < max_point_num:
_temp = " ".join((["0"] * (max_point_num - current_point_num) * 3))
res += _temp
else: # 没有指定关键点索引,使用全0代替
_temp = " ".join((["0"] * MAX_POINT_NUM * 3))
res += _temp
return res.strip()
if __name__ == '__main__':
data_root = r"Z:\Datasets\Detection\COCO2017"
if data_root == "":
raise ValueError(f"{data_root} should not be empty string")
data_root = os.path.abspath(data_root)
# 项目名称
project = "FallAndSit"
# 规定想保留的目标
# cls_index指的是类别索引
# box_type指的是该类别的边界框类型,
# body_box指的是人体的边界框;face_box指的是人脸边界框;lefthand_box指的是左手边界框;righthand_box指的是右手边界框
# point_index指的是该类别的关键点索引,整体的索引,会按照顺序取关键点
BOX_TYPE = ("body_box", "face_box", "lefthand_box", "righthand_box",)
POINT_INDEX_MAX = 129
Object_info: List[Dict] = [
{"cls_index": 0,
"box_type": "body_box",
"point_index": (6, 5, 12, 11, 14, 13, 16, 15)},
{"cls_index": 1,
"box_type": "face_box",
"point_index": (2, 1, 4, 3, 71, 77)},
# {"cls_index": 1,
# "box_type": "face_box",
# "point_index": tuple()},
]
# 关键点最多的数量,用来对齐关键点的数量,如果不够的使用[0, 0, 0]填充
MAX_POINT_NUM = 0
for value in Object_info:
MAX_POINT_NUM = max(MAX_POINT_NUM, len(value["point_index"]))
if len(Object_info) == 0:
raise ValueError("Object_dict is empty")
image_root = os.path.join(data_root, project, "images")
txt_root = os.path.join(data_root, project, "labels")
if os.path.exists(image_root):
shutil.rmtree(image_root)
os.makedirs(image_root)
if os.path.exists(txt_root):
shutil.rmtree(txt_root)
os.makedirs(txt_root)
json_path_list = [
os.path.join(data_root, "annotations", "coco-wholebody", "coco_wholebody_val_v1.0.json"),
# os.path.join(data_root, "annotations", "coco-wholebody", "coco_wholebody_train_v1.0.json"),
]
for json_path in json_path_list:
# 保存数据
information = dict()
print(f"read {json_path}")
# 读文件
with open(json_path, 'r', encoding="utf-8") as rFile:
json_data = json.load(rFile)
print(f"read {json_path} finish ...")
# 先处理图片
print(f"deal images ...")
# list:[dict ...]
image_list = json_data['images']
for step in tqdm(range(len(image_list)), desc=f"deal {os.path.basename(json_path)}"):
# 下面这些可以写成一个函数,使用多线程处理
img_info = DecodeWholeBodyImage(image_list[step])
# 图片路径img_info.coco_url:'http://images.cocodataset.org/val2017/000000397133.jpg'
# 原图路径
img_path = os.path.join(data_root,
img_info.coco_url.replace(COCO_URL_ROOT, "images").replace("/", os.sep))
img = cv2.imread(img_path)
if img is None:
continue
h, w = img.shape[:2]
dst_img_path = img_path.replace(os.path.join(data_root, "images"), image_root)
information[img_info.id] = {
"file_name": img_info.file_name, # 图片名称
'h': h, # 图片的高
'w': w, # 图片的宽
"src_path": img_path, # 原图路径
"dst_path": dst_img_path, # 该项目中目标路径
}
print("deal image information finish ...")
# 收集好图片的信息之后,开始收集目标的信息
print("deal annotation ...")
annotations = json_data['annotations']
for step in tqdm(range(len(annotations)), desc=f"deal {os.path.basename(json_path)}"):
# 解析目标
annotation = DecodeWholeBodyAnnotation(annotations[step])
# 获取目标对应的图片的信息
image_info = information[annotation.image_id]
# 图片名
file_name = image_info["file_name"]
# 后缀
_, suffix = os.path.splitext(file_name)
# 原图路径
src_image_path = image_info["src_path"]
# 目标图路径
dst_image_path = image_info["dst_path"]
# 标签保存路径
txt_path = dst_image_path.replace(image_root, txt_root).replace(suffix, ".txt")
# 图片的宽高
img_h = image_info['h']
img_w = image_info['w']
# 开始获取想要的关键点和目标
results = list()
for value in Object_info:
cls_index = value["cls_index"]
box_type = value["box_type"]
assert box_type in BOX_TYPE, f"{box_type} not in {BOX_TYPE}"
# 目标字符串
res = ""
if box_type == "body_box" and (not annotation.iscrowd): # 不是人群,大密集的
box = ltwh2xywhn(annotation.body_box, img_h=img_h, img_w=img_w)
res += f"{cls_index} {box[0]:.6f} {box[1]:.6f} {box[2]:.6f} {box[3]:.6f} "
# 关键点的索引tuple
point_index = value["point_index"]
# 关键点字符串
res += get_point(point_index=point_index,
all_points=annotation.all_points,
img_shape_wh=(img_w, img_h),
max_point_num=MAX_POINT_NUM
)
elif box_type == "face_box" and annotation.face_valid:
box = ltwh2xywhn(annotation.face_box, img_h=img_h, img_w=img_w)
res += f"{cls_index} {box[0]:.6f} {box[1]:.6f} {box[2]:.6f} {box[3]:.6f} "
# 关键点的索引tuple
point_index = value["point_index"]
# 关键点字符串
res += get_point(point_index=point_index,
all_points=annotation.all_points,
img_shape_wh=(img_w, img_h),
max_point_num=MAX_POINT_NUM
)
elif box_type == "lefthand_box" and annotation.lefthand_valid:
box = ltwh2xywhn(annotation.lefthand_box, img_h=img_h, img_w=img_w)
res += f"{cls_index} {box[0]:.6f} {box[1]:.6f} {box[2]:.6f} {box[3]:.6f} "
# 关键点的索引tuple
point_index = value["point_index"]
# 关键点字符串
res += get_point(point_index=point_index,
all_points=annotation.all_points,
img_shape_wh=(img_w, img_h),
max_point_num=MAX_POINT_NUM
)
elif box_type == "righthand_box" and annotation.lefthand_valid:
box = ltwh2xywhn(annotation.righthand_box, img_h=img_h, img_w=img_w)
res += f"{cls_index} {box[0]:.6f} {box[1]:.6f} {box[2]:.6f} {box[3]:.6f} "
# 关键点的索引tuple
point_index = value["point_index"]
# 关键点字符串
res += get_point(point_index=point_index,
all_points=annotation.all_points,
img_shape_wh=(img_w, img_h),
max_point_num=MAX_POINT_NUM,
)
#
if res != "":
results.append(res)
os.makedirs(os.path.dirname(txt_path), exist_ok=True)
with open(txt_path, "a", encoding="utf-8") as wFile:
for line in results:
wFile.write(f"{line}\n")
# 映射图片
if not os.path.exists(dst_image_path):
os.makedirs(os.path.dirname(dst_image_path), exist_ok=True)
os.link(src_image_path, dst_image_path)
示例:【人脸7个关键点,身体8个关键点】

