详细步骤解释
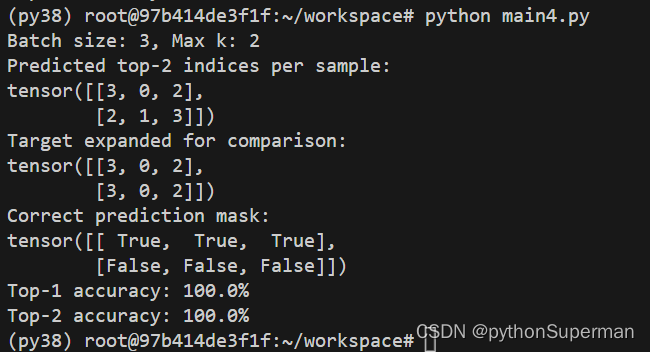
计算批次大小和最大K值:
- 批次大小为3(3个样本)。
- 最大K值为2(我们查找每个样本的前两个最高预测)。
提取Top-K预测索引:
- 对于第一个样本
[0.1, 0.2, 0.3, 0.4, 0.0],Top-2 的索引是[3, 2](值0.4和0.3)。 - 对于第二个样本
[0.5, 0.3, 0.2, 0.0, 0.0],Top-2 的索引是[0, 1](值0.5和0.3)。 - 对于第三个样本
[0.2, 0.1, 0.5, 0.2, 0.0],Top-2 的索引是[2, 3](值0.5和0.2)。
- 对于第一个样本
扩展目标标签以便比较:
将目标标签[3, 0, 2]转换为二维[ [3], [0], [2] ]并扩展以匹配预测索引的形状,结果是:
[[3, 3],
[0, 0],
[2, 2]]计算正确预测的掩码:
比较预测索引和扩展后的目标标签,得到正确的预测掩码。对于上面的例子,结果可能如下:
[[True, False],
[True, False],
[True, False]]计算每个Top-K的准确率:
- Top-1: 正确掩码第一行的平均值(所有样本的Top-1预测是否正确),例如100%。
- Top-2: 正确掩码所有行的平均值,也可能是100%。
完整的可运行代码
import torch
def print_step_by_step(output, target, topk=(1,2)):
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
print(f"Batch size: {batch_size}, Max k: {maxk}")
# 获取 top-k 预测索引
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
print(f"Predicted top-{maxk} indices per sample: \n{pred}")
# 目标标签转换为适合比较的形状
target_expanded = target.view(1, -1).expand_as(pred)
print(f"Target expanded for comparison: \n{target_expanded}")
# 计算正确预测的掩码
correct = pred.eq(target_expanded)
print(f"Correct prediction mask: \n{correct}")
# 计算每个 top-k 的准确率
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
accuracy_k = correct_k.mul_(100.0 / batch_size)
res.append(accuracy_k.item())
print(f"Top-{k} accuracy: {accuracy_k.item()}%")
return res
# 模拟的输出和目标标签
output = torch.tensor([
[0.1, 0.2, 0.3, 0.4, 0.0], # 第一个样本
[0.5, 0.3, 0.2, 0.0, 0.0], # 第二个样本
[0.2, 0.1, 0.5, 0.2, 0.0] # 第三个样本
])
target = torch.tensor([3, 0, 2]) # 真实类别索引
# 调用函数并打印结果
print_step_by_step(output, target, topk=(1, 2))