Transformer架构是目前的大模型的基础架构,目前所有大模型都是基于transformer架构进行训练的。该架构是由 Google 2017 年提出的,后来 Google 用该架构训练出了大名鼎鼎的 Bert 模型,OpenAI 训练出了 GPT 模型,又推出了现象级产品 ChatGPT。
Transformer架构简单理解来说,从输入到输出,经过 Encoder 和 Decoder,例如翻译、问答都是典型场景。
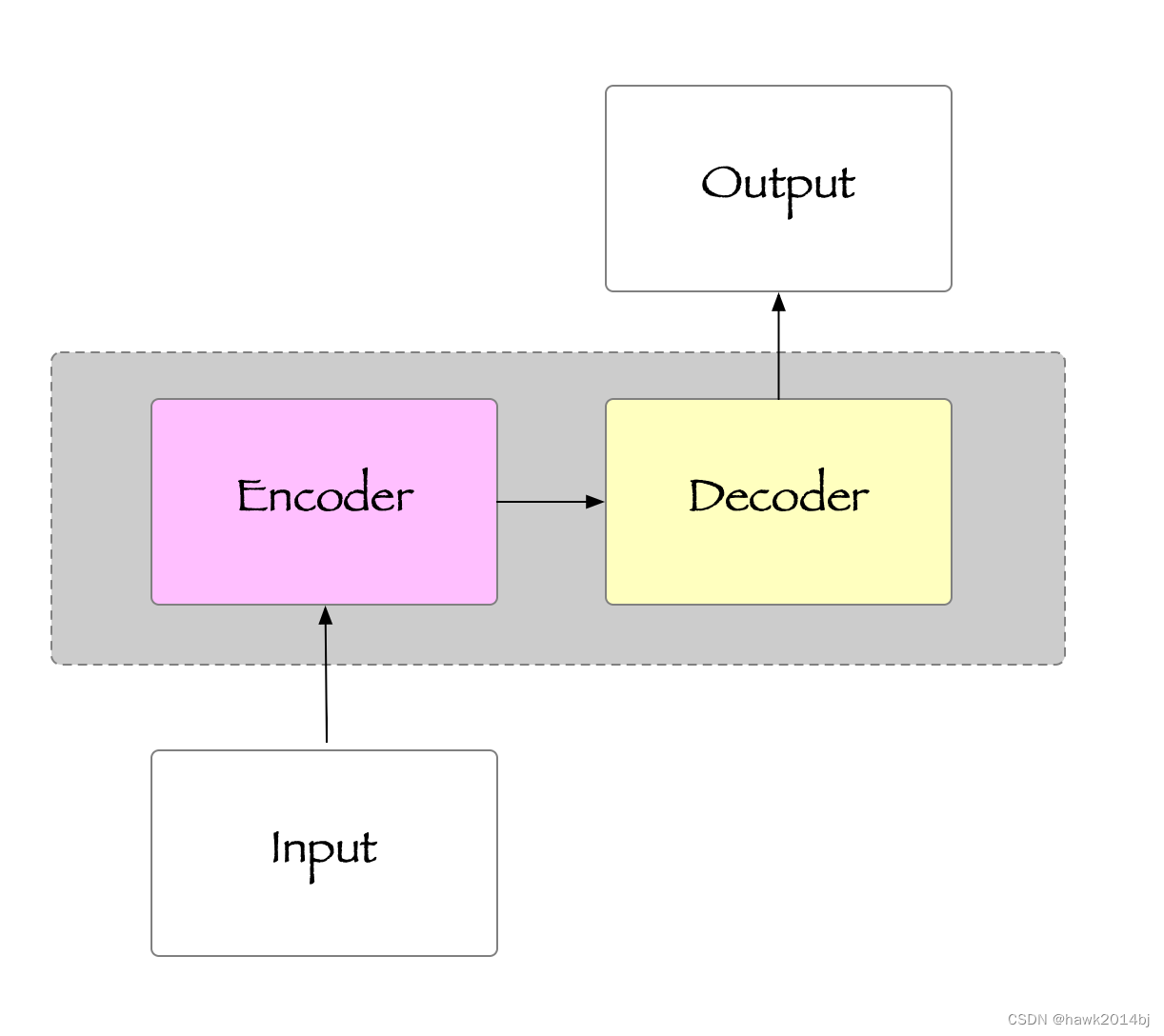
先来一张经典架构图,架构中把 Encoder 和 Decoder 进行详细的分解说明,可以看出 encoder 和 decoder 包含了哪些步骤。
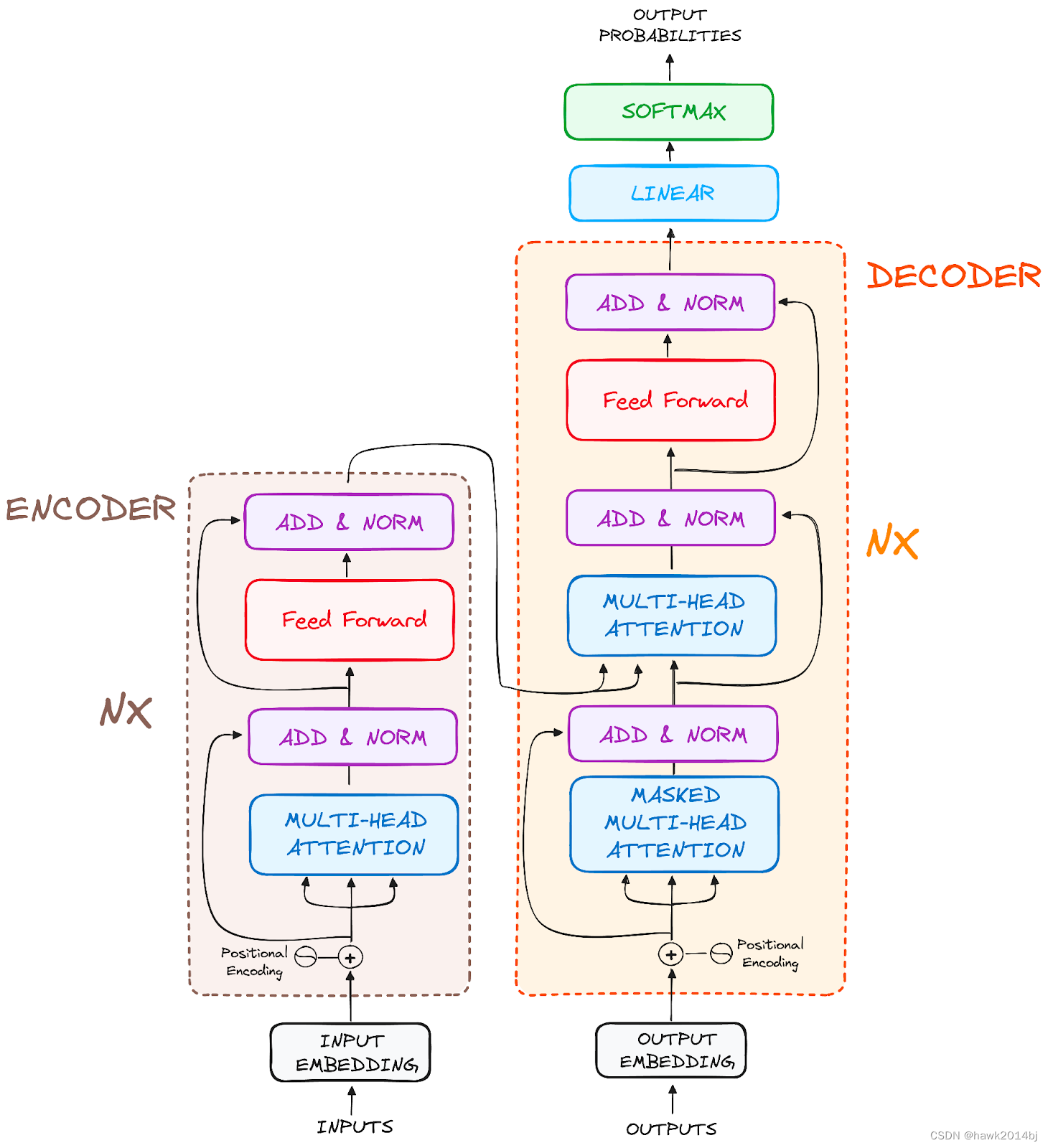
Encoder
Input Embeddings: 首先做 Embedding,将输入的内容向量化。
Positional Encoding:Transformer在 encoder 阶段是并行处理每一个 token,没有 token 位置信息,所以需要加入位置信息,最终,将 Input Embedding 和 Position Embedding 加在一起。
Stack of Encoder Layers:Encoder是多层的,多层的 Encoder 会让模型学到更多的内容。每层包括多头注意力机制和一个全链接网络。
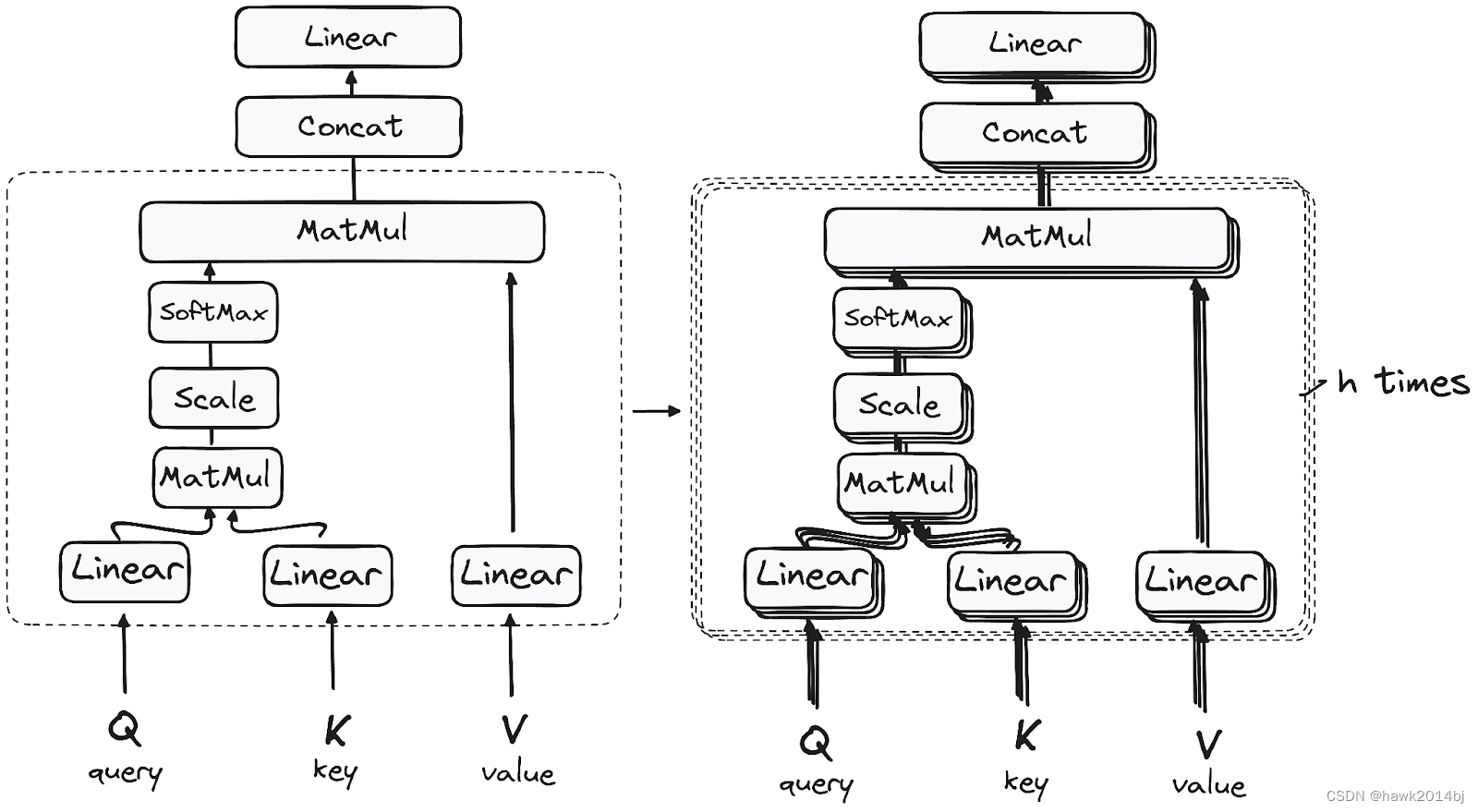
Multi-Headed Self-Attention Mechanism
可以看到注意力机制是对 Q、K、V 进行计算,Q、K、V 分别代表 Query、Key 和 Value,Q、K、V 的值是通过初始化的三个向量与 Input Embedding 相乘得到的。如下图所示,用Q * K得到分数,分数越高代表关联度越高,只有高分数的会被保留下来,也就是关联度高的信息会保留下来,用结果与 Value 相乘,之后做归一化。
Normalization and Residual Connections:残差链接和归一化
Feed-Forward Neural Network:进入全链接网络层
Output of the Encoder:最终输出结果向量,每个 token 一个向量,每个向量中包含token 的上下文信息。
Decoder
- Output Embeddings: 同 encoder embedding
- Positional Encoding:同 encoder position embedding
- Stack of Decoder Layers:Decoder 有两层多头注意力,第一层和 Encoder 处理方式一致,第二层将 Encoder的输出和上一层多头注意力的输出作为输入, Q、K 是 Encoder 的输出,V 是上一层的输出,这样 encoder 和 decoder 就关联在一起了。
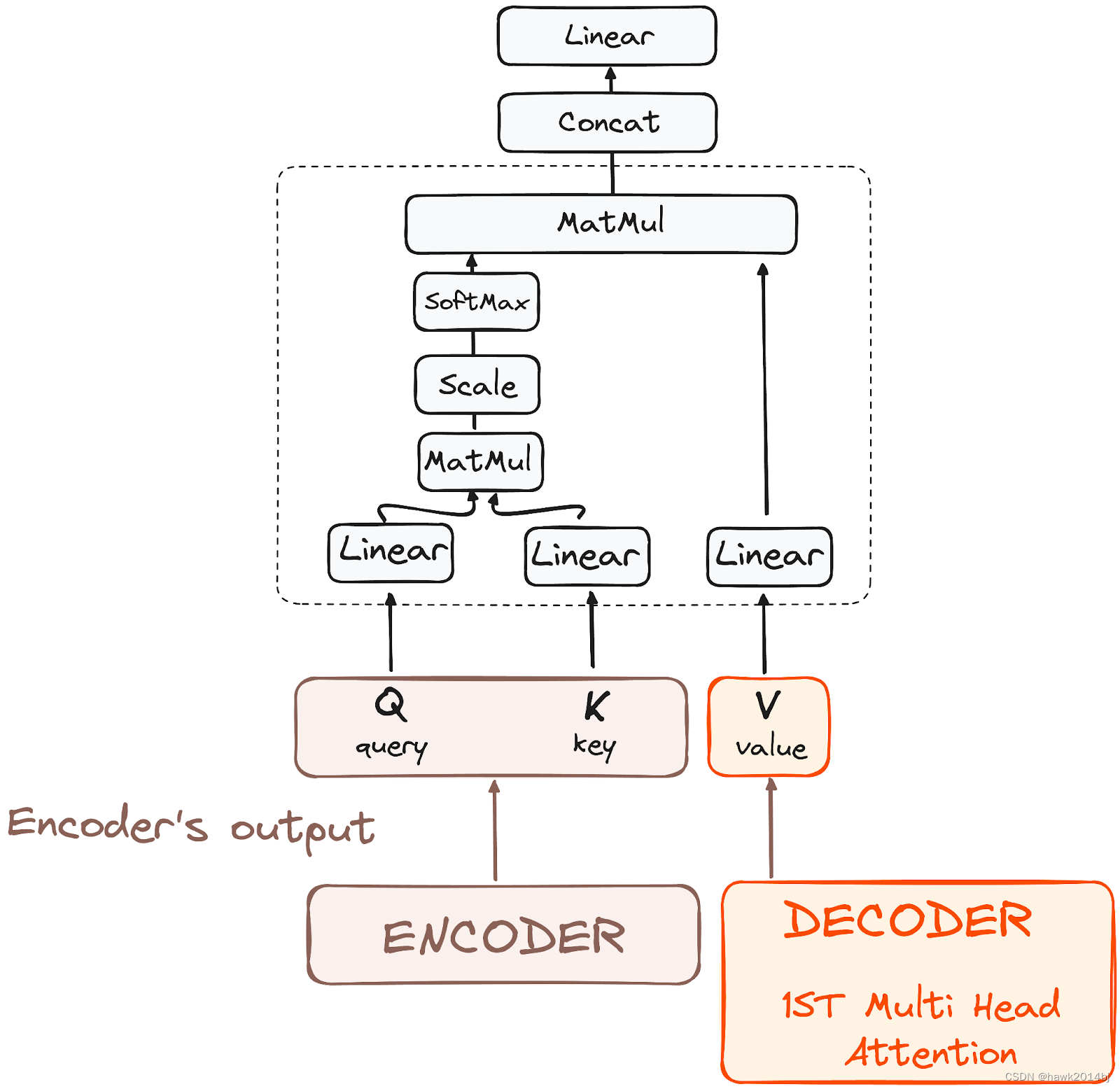
- Feed-Forward Neural Network:进入全链接网络层
- Linear Classifier and Softmax for Generating Output Probabilities:跟据词表计算结果概率。
Transformer提高了训练性能以及训练效果,为大模型的高速发展提供了基础。这些模型里的公式,不知道他们是怎么想出来的。