原文:Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
1 什么是KV Cache
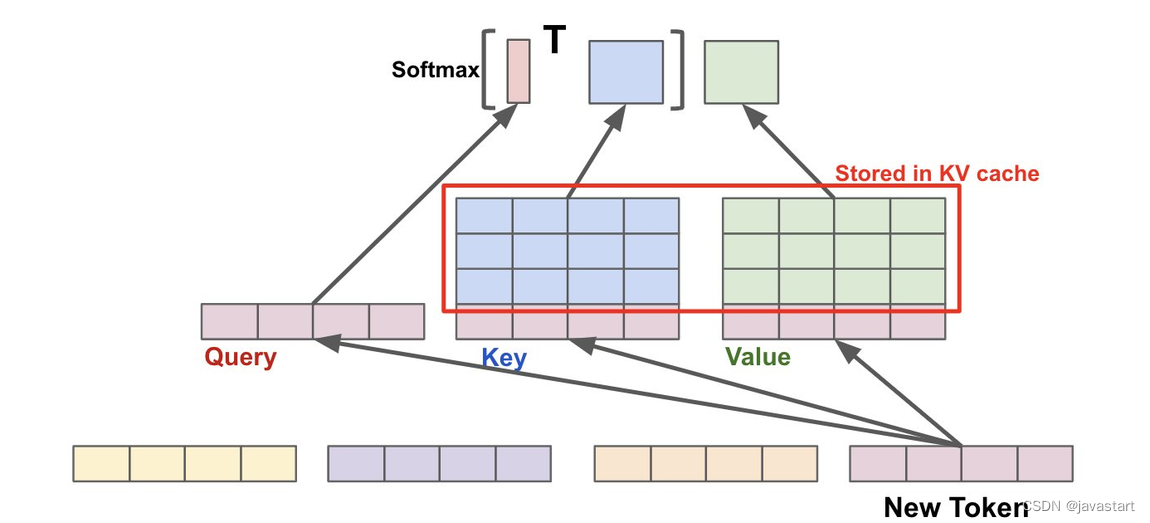
LLM(大型语言模型)中的 Attention 机制中的 KV Cache(键值缓存)主要作用是存储键值对,以避免在每次生成 token 时重新计算键值向量,从而减少计算量和提高效率。利用预先计算好的 K 值和 V 值,可以节省大量计算时间,尽管这会占用一定的存储空间。
随着模型规模的增大和数据量的增加,LLM 的窗口长度也在不断增大,因此就出现一组主要矛盾,即:对不断增长的 LLM 的窗口长度的需要与有限的 GPU 显存之间的矛盾。为了解决这个问题,需要优化 KV Cache,减少重复计算,以提高推理性能。
2 使用KV Cache
在推理的时候transformer本质上只需要计算出$O_i$,即一个字一个字地蹦。再根据上面的结论,
- Attention的第i个输出只和第 i 个query有关,和其他query无关,所以query完全没有必要缓存,每次预测$O_i$时只要计算最新的$Q_i$即可,其他的丢弃即可
- Attention的输出O_i的计算和完整的K和V有关,而K、V的历史值只和历史的O有关,和当前的O无关。那么就可以通过缓存历史的K、V,而避免重复计算历史K、V
因此,当预测 今天天气真 → 好 时,使用kv cache后流程如下:
- 输入
真的向量 - 提取真对应的$Q_i, K_i, V_i$
- 拼接历史K、V的值,得到完整的K、V
- 然后经过Attention计算,获得$O_i$ 输出
- 根据$O_i$ 计算得到
好
3 公式证明
Attention的计算公式如下:
$$ O=Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V $$
3.1 Attention的$O_i$只和$Q_i$有关
假设:
$$ \begin{align} Q &= \begin{bmatrix} Q_0\\ Q_1 \end{bmatrix}\\
K &= \begin{bmatrix} K_0\\ K_1 \end{bmatrix} \end{align} $$
那么,
$$ O = softmax(\frac{\begin{bmatrix} Q_0K_0^T & Q_0K_1^T\\ Q_1K_0^T & Q_1K_1^T\\ \end{bmatrix}}{\sqrt{d_k}})V $$
令,
$$ A = \begin{bmatrix} A_0\\ A_1 \end{bmatrix} = \begin{bmatrix} Q_0K_0^T & Q_0K_1^T\\ Q_1K_0^T & Q_1K_1^T\\ \end{bmatrix}, f(x) = \frac{softmax(x)}{\sqrt{d_k}} $$
此时,$A_1$只和$Q_1$有关,和$Q_0$无关,那么,
$$ \begin{bmatrix} O_0\\ O_1 \end{bmatrix} = O = \begin{bmatrix} f(A_0)\\ f(A_1) \end{bmatrix}V = \begin{bmatrix} f(A_0)V\\ f(A_1)V \end{bmatrix} $$
因此,$O_i$ 只和 $A_i$ 相关,而根据A的设定,$A_i$ 只和 $Q_i$ 相关,即:
<aside> 💡 Attention矩阵的第 i 个输出只和第 i 个 Q有关,和之前的 Q无关
</aside>
即:
$$ O_i = Attention(Q_i,K,V) = softmax(\frac{Q_iK^T}{\sqrt{d_k}})V $$
3.2 FNN/Dense的$Y_i$只和$X_i$有关
假设FNN层的变换如下:
$$ Y = XW^T $$
那么,
$$ \begin{bmatrix} Y_0\\ Y_1 \end{bmatrix} = \begin{bmatrix} X_0\\ X_1 \end{bmatrix}W^T = \begin{bmatrix} X_0W^T\\ X_1W^T \end{bmatrix} $$
也就是经过FNN层或者Dense层之后,第 i 个输出仍然只和第 i 个输入有关,和其他输入无关。
由于K、V的生成过程也是FNN过程,因此,
- $K_i$、$V_i$只和当前推理的上一层输出$O_i$有关,和上一层的历史O输出无关
- K、V的历史值只和历史的O有关,和当前的O无关
3.3 transformer的第i个输出只和第i个Q有关
结合结论1和结论2,transformer的第 i 个输出 $O_i$ 只和第 i 个query即 $Q_i$有关,和其他的query无关
3.4 K和V没有和Q一样的性质
即:
- 在Attention中,第 i 个O不仅和第 i 个K or V有关,还和其他K or V有关
- 因此,K或者V不具有传递性
根据3.1中证明得:
- $O_i$ 只和 $A_i$ 相关,而根据A的设定,$A_i$ 不仅和$K_i$有关还和其他的K有关。
- 由于 $O = f(A)\begin{bmatrix} V_0\\V_1 \end{bmatrix}$,因此O和所有的V都有关
综上,第 i 个输出$O_i$(可以拓展到每个transformer block的输出)和完整的K、V都有关
4 KV Cache的优化方法
4.1 MQA、MHA减少KV Cache
‣ ‣
下图展示了大模型中MHA、MQA、GQA之间的区别
 multi-head attention: 不共享任何head
multi-head attention: 不共享任何head- multi-query attention:共享所有的KV head,经过小批量训练后,仍然会导致精度损失
- grouped-query attention:分组共享KV head,经过小批量训练后,不会导致精度损失
可以发现,MQA和GQA本质上都是通过共享K、V的head实现对MHA的优化。这直接让MQA、GQA减少了计算时的显存占用。另外由于KV Cache和head数量直接成正相关,因此减少KV head数量后,也就相当于直接减少了KV Cache
4.2 窗口约束减少KV Cache
‣
Longformer提出了利用滑动窗口约束attention的上下文范围,从而达到提升上下文长度的目的。
 由于SWA通过滑动窗口的技巧,约束了上下文的长度而不再是全局,KV Cache也会被限制到固定长度,而不再是全局。最终实现了减小KV Cache的目的
由于SWA通过滑动窗口的技巧,约束了上下文的长度而不再是全局,KV Cache也会被限制到固定长度,而不再是全局。最终实现了减小KV Cache的目的
‣
LM-Infinite同样是利用滑动窗口的原理,通过GLM + 窗口约束的方式实现限制KV Cache显存占用上限
 4.3 量化和稀疏
4.3 量化和稀疏
通过量化和稀疏方式用于压缩KV Cache的显存占用,关于具体的方法,这里就不再详述。
4.4 PageAttention
‣
PageAttention是在vLLM 中提出的KV Cache优化方法,它将在操作系统的虚拟内存中分页的经典思想引入到 LLM 服务中。在无需任何模型架构修改的情况下,可以做到比 HuggingFace Transformers 提供高达 24 倍的 Throughput。下面是实现流程:
内存分区
主要受到操作系统虚拟内存和分页思想启发的注意力算法。具体来说,PagedAttention 将每个序列的 KV cache 划分为块,每个块包含固定数量 token 的键和值。PagedAtention的KV cache显存管理主要分为逻辑内存区和物理内存区:
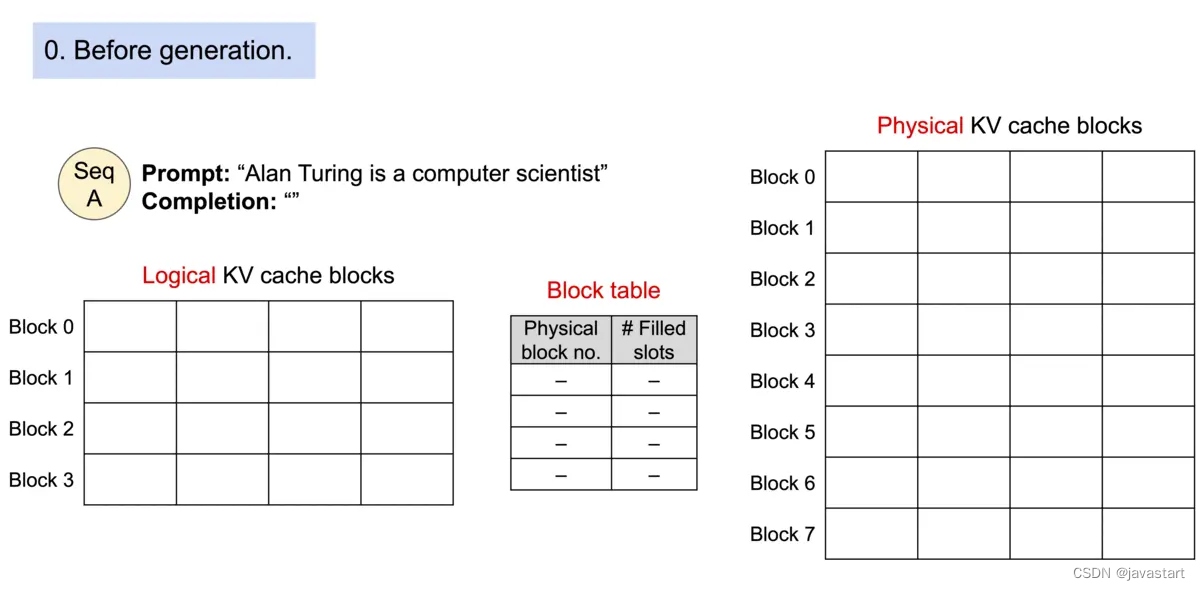 逻辑内存区:按照token作为key在block table中查询物理内存区的位置
逻辑内存区:按照token作为key在block table中查询物理内存区的位置- 物理内存区:分成多个不同的block对连续token进行保存。但是block之间的地址可以不连续。因此内存回收时,就可以基于block进行。
内存共享
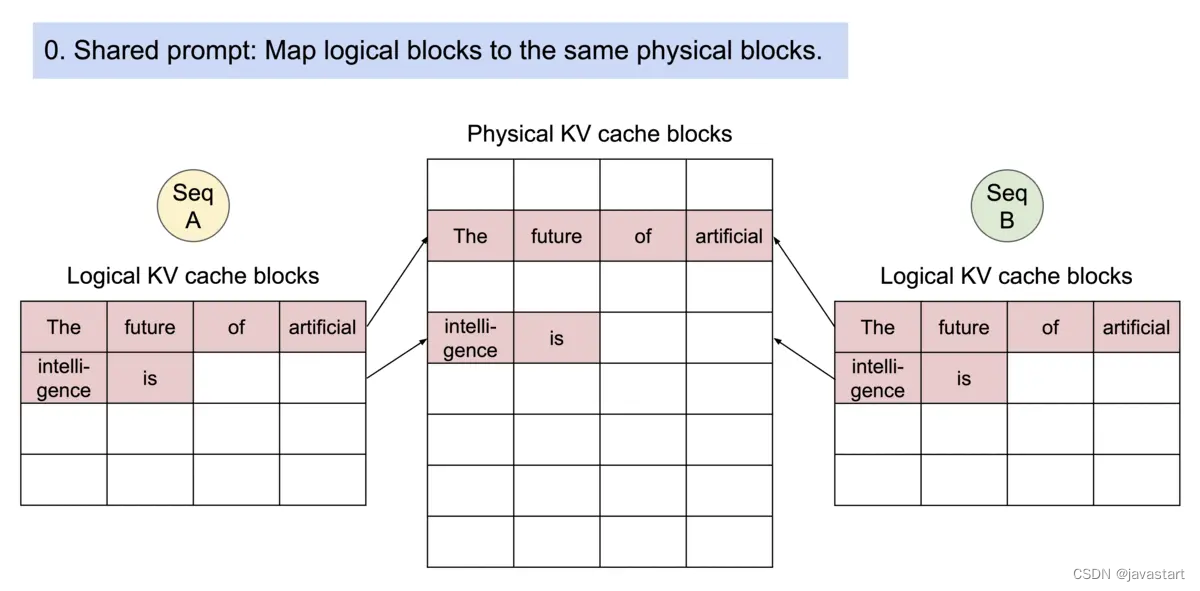 由于是通过逻辑内存的key对物理内存区进行查询动作,因此多个不同的序列可以进行内存共享:
由于是通过逻辑内存的key对物理内存区进行查询动作,因此多个不同的序列可以进行内存共享:- 如果多个序列使用相同的block,那么直接返回相同block的地址空间
- 写时复制:如果新block开始部分和之前的block一样,但是之后的不一样,那么就会对相同部分直接复制,然后创建新的block
5 总结
kv cache通过空间换时间的思路加速推理速度,在不做压缩和裁剪的情况下对精度没有影响