是什么以及发展过程

推理和响应, 主要是搜索和推理结合
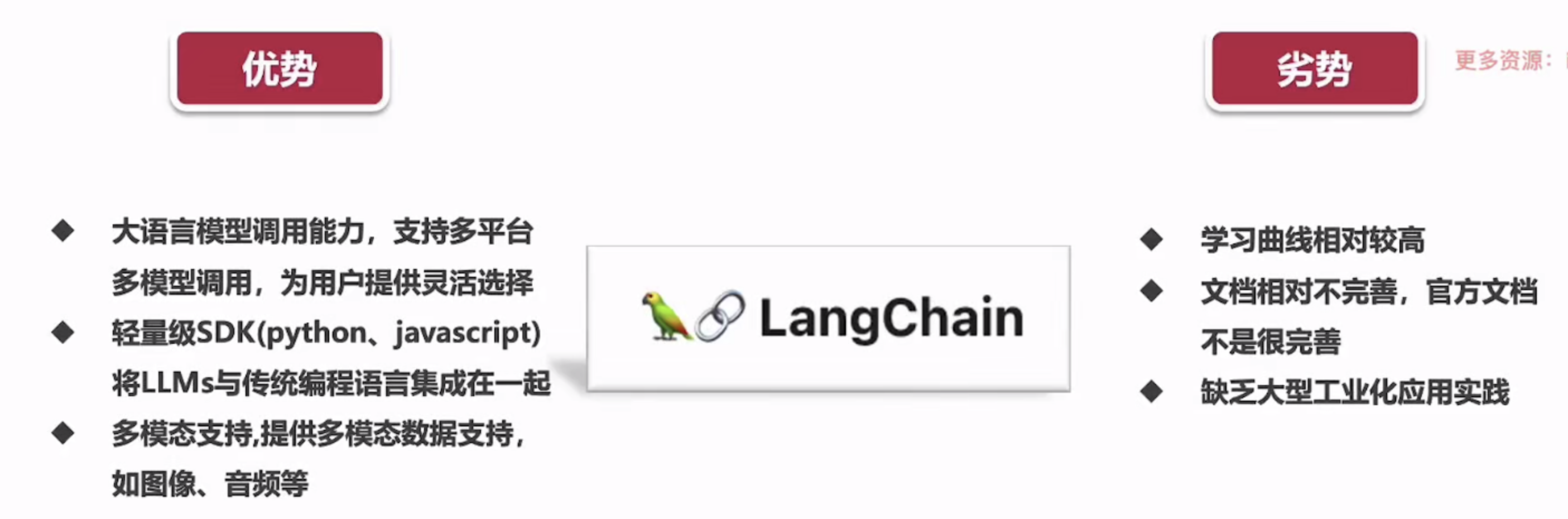
优劣势
环境搭建
- Python环境
- Jupyter Notebook 的安装与使用
- LangChain安装
Python简介
- 高级的接近人类语言的编程语言,易于学习
- 动态语言
- 直译式语言,可以跳过编译逐行执行代码
- 广泛应用于web应用、软件、数据科学和机器学习
- Al方向的主流语言
- 活跃的python社区
- 数据巨大且丰富的库

安装Python版本管理工具, pyenv 可以管理多个 python 的版本。
brew update
brew install pyenv安装Python3.11
pyenv install 3.11.5
升级pip
sudo python3.11 -m pip install --upgrade pip
Jupyter Notebook简介

安装jupyter notebook:
# 安装jupyter
pip3 install jupyter
# 启动jupyter
jupyter notebook安装jupyter-lab
# 安装
pip3 install jupyterlab
# 启动
jupyter lab- 界面: Jupyter Notebook提供了基于单个文档的界面,每个文档称为一个notebook,而JupyterLab提供了更丰富的多文档界面,可以同时打开多个notebook、代码文件、终端等。
- 插件支持: JupyterLab有更强大的插件支持,可以扩展其功能,例如添加新的编辑器、调试器等。
- 集成性: JupyterLab集成了更多的工具和功能,例如文件浏览器、终端、命令面板等,使得整个数据分析和开发过程更加流畅和高效。
可能遇到的问题
打开jupyter lab网页提示报错:
JupyterLab Error JupyterLab application assets not found in
“/opt/homebrew/Cellar/python@3.10/3.10.10_1/Frameworks/Python.framework/Versions/3.10/share/jupyter/lab” Please run jupyter lab build or use a different app directory根据提示执行命令jupyter lab build查看控制台显式的报错:
Please install nodejs >=18.0.0 before continuing
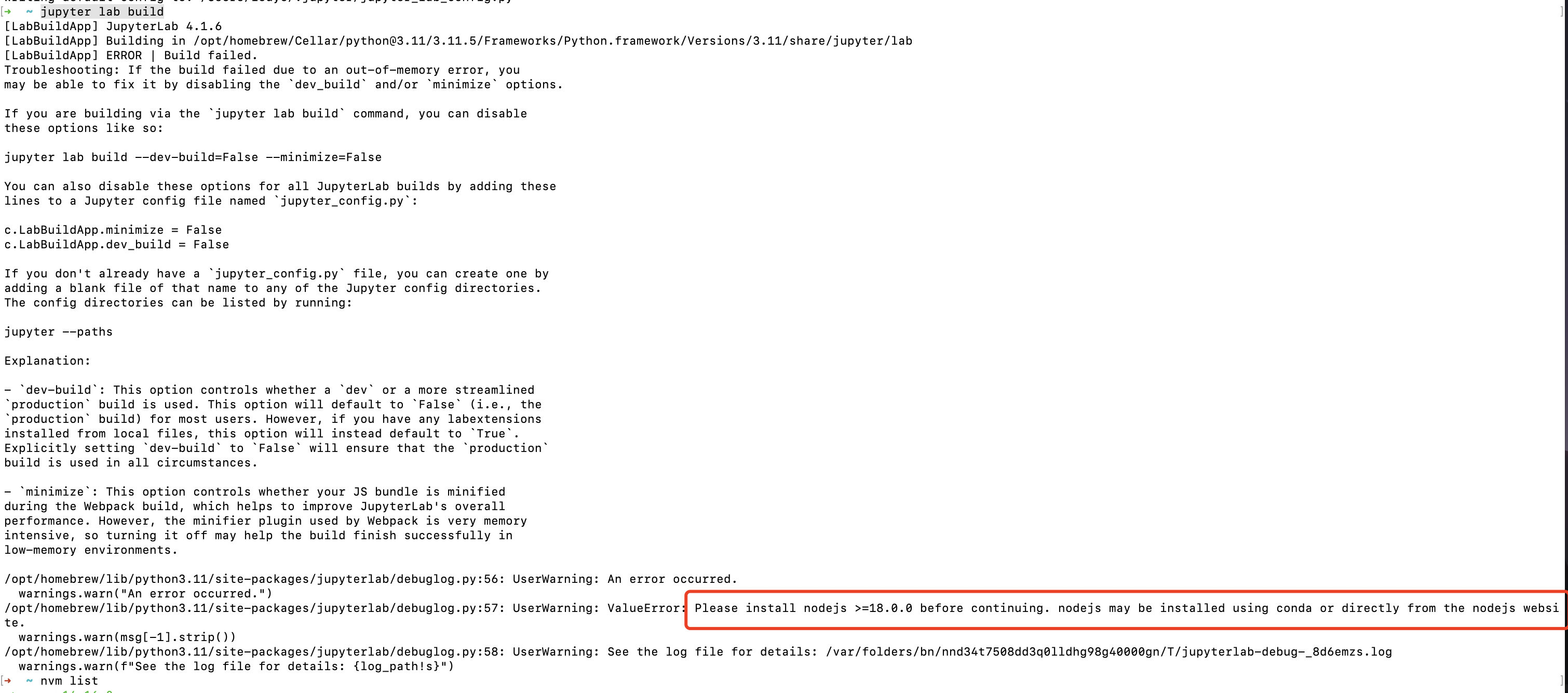
所以可能是node版本导致不能build成功
查看node版本, 并切换:

重新build再重启 jupyter lab 即可
openAI-key获取
网页上GPT3.5以下都是免费使用的, 只是API调用在3.5和4.0都需要收费的, 可以使用国内的代理服务 F2API
注册后直接使用key 和代理即可, 调用的时候就可以直接调用openAI的api服务

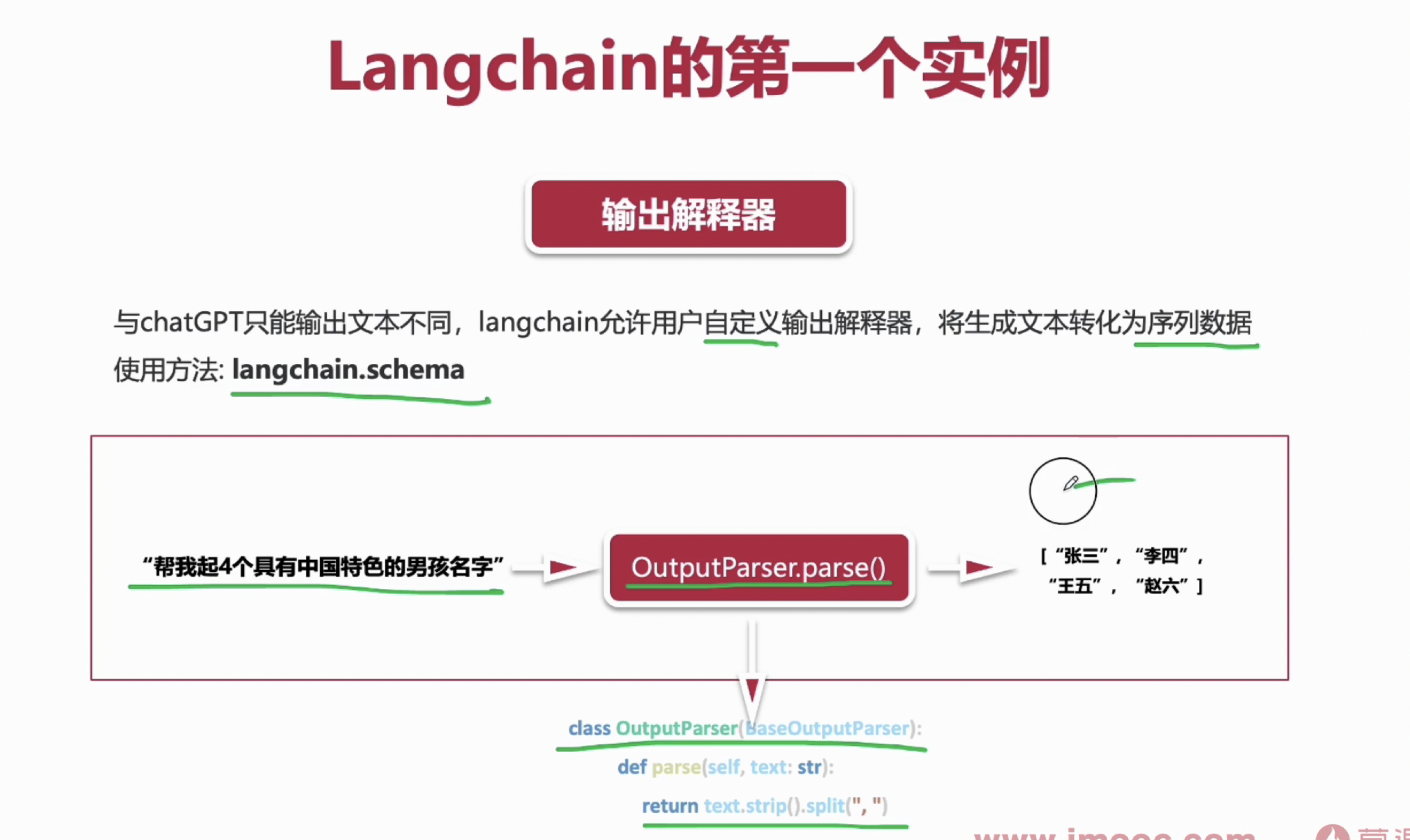
LangChain的第一个实例
打开jupyter lab:
卸载和安装langchain和openai
# 卸载
! pip3 uninstall langchain -y
! pip3 uninstall openai -y# 安装 langchain
! pip3 install --upgrade langchain==0.0.279 -i https://pypi.org/simple
#如果没有科学上网,可以用这个命令安装
! pip3 install --upgrade langchain==0.0.279 -i https://pypi.tuna.tsinghua.edu.cn/simple依赖安装
- 安装openai的api包
- 或者使用Baichuan、ChatGLM这样的开源包
! pip3 install openai==v0.28.1 -i https://pypi.org/simple
! pip install --upgrade openai0.27.8
#如果没有科学上网,可以使用这个命令安装
! pip install openai0.27.8 -i https://pypi.tuna.tsinghua.edu.cn/simple查看安装
! pip3 show langchain
! pip3 show openai引入openai key
import os
os.environ["OPENAI_KEY"] = "你的key"
os.environ["OPENAI_API_BASE"] = "https://api.f2gpt.com/v1"从环境变量中读取
import os
openai_api_key = os.getenv("OPENAI_KEY")
openai_api_base = os.getenv("OPENAI_API_BASE")
print("OPENAI_API_KEY:", openai_api_key)
print("OPENAI_PROXY:", openai_api_base)openai官方SDK
#使用openai的官方sdk
import openai
import os
openai.api_base = os.getenv("OPENAI_API_BASE")
openai.api_key = os.getenv("OPENAI_KEY")
messages = [
{"role": "user", "content": "介绍下你自己"}
]
res = openai.ChatCompletion.create(
model="gpt-4-1106-preview",
messages=messages,
stream=False,
)
print(res['choices'][0]['message']['content'])使用langchain调用
#hello world
from langchain.llms import OpenAI
import os
api_base = os.getenv("OPENAI_API_BASE")
api_key = os.getenv("OPENAI_KEY")
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
# 使用 temperature=0 相当于不带任何调参输出当前大模型传入文本的固定回答
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
llm.predict("介绍下你自己")示例
起名大师
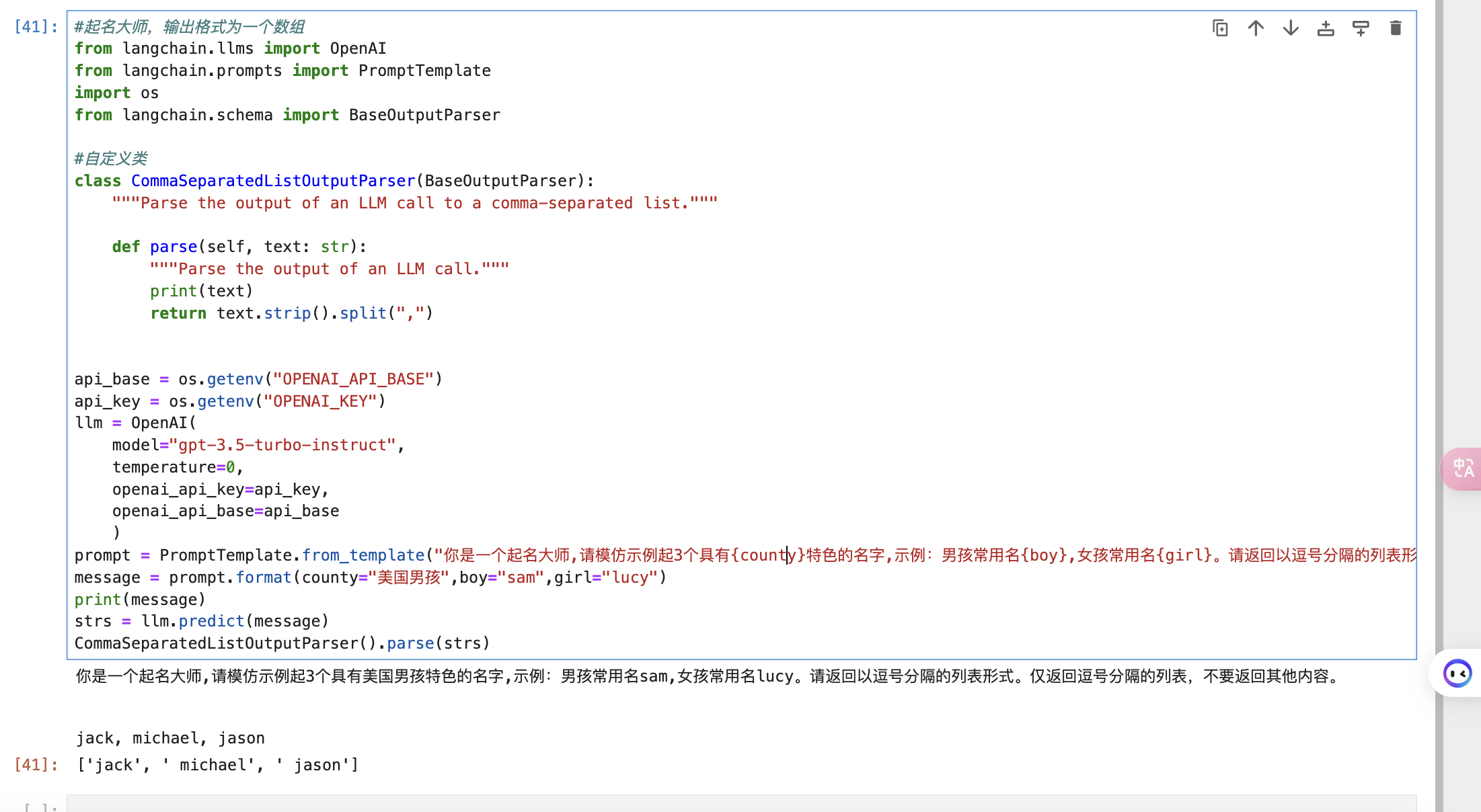
#起名大师,输出格式为一个数组
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
import os
from langchain.schema import BaseOutputParser
#自定义类
class CommaSeparatedListOutputParser(BaseOutputParser):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str):
"""Parse the output of an LLM call."""
print(text)
return text.strip().split(",")
api_base = os.getenv("OPENAI_API_BASE")
api_key = os.getenv("OPENAI_KEY")
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
prompt = PromptTemplate.from_template("你是一个起名大师,请模仿示例起3个具有{county}特色的名字,示例:男孩常用名{boy},女孩常用名{girl}。请返回以逗号分隔的列表形式。仅返回逗号分隔的列表,不要返回其他内容。")
message = prompt.format(county="美国男孩",boy="sam",girl="lucy")
print(message)
strs = llm.predict(message)
CommaSeparatedListOutputParser().parse(strs)