七大原则
1. 开闭原则(Open-Closed Principle, OCP)
- 详解:软件实体(类、模块、函数等)应该易于扩展,但是不易于修改。换句话说,当软件需求变化时,应该通过添加新代码来实现变化,而不是修改已有的代码。
- 例子:比如,一个绘图程序可以通过添加新的形状类来扩展,而不是修改现有的绘制方法。
- 代码:
// 基本类
class Shape {
public void draw() { /* ... */ }
}
// 扩展新形状而不修改Shape类
class Circle extends Shape {
public void draw() { /* 绘制圆形 */ }
}
2. 里氏替换原则(Liskov Substitution Principle, LSP)
- 详解:子类应该能够替换它们的基类,而不改变程序的正确性。这意味着子类的行为应该与基类一致。
- 例子:如果有一个函数接受基类Bird作为参数,那么它应该同样能接受Bird的子类如Sparrow或Penguin。
- 代码:
class Bird {
public void fly() { /* ... */ }
}
class Sparrow extends Bird { /* 保持fly方法行为一致 */ }
class Penguin extends Bird {
@Override
public void fly() {
throw new UnsupportedOperationException("Penguins can't fly");
}
}
// Penguin类违反了LSP原则,因为它改变了fly方法的行为。
3. 依赖倒置原则(Dependency Inversion Principle, DIP)
- 详解:高层模块不应依赖于低层模块,两者都应依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。
- 例子:在构建应用程序时,高层模块(如业务逻辑)不应直接依赖于低层模块(如数据库操作),而是依赖于抽象接口。
- 代码:
// 抽象接口
interface Repository {
void save(Object data);
}
// 高层模块
class Service {
private Repository repository;
public Service(Repository repository) {
this.repository = repository;
}
public void process(Object data) {
repository.save(data);
}
}
// 低层模块实现接口
class SQLRepository implements Repository {
public void save(Object data) { /* SQL存储逻辑 */ }
}
4. 接口隔离原则(Interface Segregation Principle, ISP)
- 详解:客户不应该被迫依赖于它们不使用的方法。接口应该小而专注,而不是大而全能。
- 例子:如果一个接口有太多的方法而客户只需要其中的一小部分,应该将这个接口拆分为更小的几个接口。
- 代码:
// 不好的设计:一个庞大的接口
interface Worker {
void work();
void eat();
}
// 好的设计:接口拆分
interface Workable {
void work();
}
interface Eatable {
void eat();
}
class Human implements Workable, Eatable {
public void work() { /* ... */ }
public void eat() { /* ... */ }
}
5. 单一职责原则(Single Responsibility Principle, SRP)
- 详解:一个类应该仅有一个引起它变化的原因。简言之,一个类应该只做一件事。
- 例子:如果有一个类同时处理用户信息管理和用户行为追踪,应该将其拆分为两个类。
- 代码:
// 不好的设计:两个职责
class User {
public void manageUserInfo() { /* ... */ }
public void trackUserActions() { /* ... */ }
}
// 好的设计:拆分职责
class UserInfoManager {
public void manageUserInfo() { /* ... */ }
}
class UserActionTracker {
public void trackUserActions() { /* ... */ }
}
6. 合成/聚合复用原则(Composite/Aggregate Reuse Principle, CARP)
- 详解:优先使用对象的合成/聚合来实现代码复用,而不是通过继承。
- 例子:在实现栈的功能时,而不是继承自ArrayList,应该内部持有一个ArrayList实例来实现功能。
- 代码:
// 不好的设计:通过继承实现复用
class Stack extends ArrayList { /* ... */ }
// 好的设计:通过合成实现复用
class Stack {
private ArrayList list = new ArrayList();
public void push(Object item) { list.add(item); }
// 其他方法...
}
7. 最少知识原则(Law of Demeter, LoD)或迪米特法则
- 详解:一个对象应该对其他对象有尽可能少的了解。通俗地说,只与你的直接朋友通信。朋友的意思就是出现在成员变量、方法的输入、输出参数中的类,而出现在方法体内部的累不属于朋友类。
- 例子:在一个方法中,应避免调用链过长,如a.getB().getC().doSomething()。
- 代码:
// 不好的设计:过长的调用链
class A {
B getB() { /* ... */ }
}
class B {
C getC() { /* ... */ }
}
class C {
void doSomething() { /* ... */ }
}
// 在外部调用
new A().getB().getC().doSomething();
// 好的设计:减少调用链
class A {
B b;
void doSomething() {
b.doSomething(); // A 只与直接朋友B通信
}
}
class B {
C c;
void doSomething() {
c.doSomething(); // B 只与直接朋友C通信
}
}
工厂设计模式
简单工厂模式
定义
简单工厂模式(又称为静态工厂模式)不是一种正式的设计模式,而是一种编程习惯。在这种模式中,一个工厂类负责创建其他类的实例,这些类通常都有一个共同的父类或接口。也就是我们可以使用这个工厂去创建各种类型的实例(如果你愿意的话)
优点
- 集中管理:创建对象的逻辑集中在一个地方,便于维护和修改。
- 客户端简化:客户端不需要知道具体的类名,只需知道参数。
缺点
- 违背开闭原则:添加新产品时,需要修改工厂类。
- 工厂类职责过重:随着产品类的增加,工厂类的逻辑会变得复杂。
使用了什么原则
- 单一职责原则:工厂类只负责创建对象。
违背了什么原则
- 开闭原则:在添加新产品时需要修改工厂类。
简单工厂模式解决的问题
简单工厂模式主要解决了客户端与产品类的紧密耦合问题,使客户端从直接创建对象转变为通过工厂类来创建,从而简化了客户端的代码和逻辑。
简单工厂模式通过一个中心化的工厂类来决定创建哪种类型的对象,客户端通过传递参数来指定所需对象的类型。这种模式适用于产品种类不多且产品创建逻辑不复杂的情况。它的优点在于减少了客户端和具体产品类之间的耦合,简化了客户端的使用。然而,这种模式的缺点是当新产品被添加到系统中时,需要修改工厂类,违背了开闭原则,并使得工厂类职责过重。
基于类名的简单工厂
假设我们有一个Product接口和几个实现类ProductA、ProductB等。工厂类根据传入的类名来创建相应的对象。
interface Product {
void use();
}
class ProductA implements Product {
public void use() { System.out.println("Using Product A"); }
}
class ProductB implements Product {
public void use() { System.out.println("Using Product B"); }
}
class SimpleFactory {
public static Product createProduct(String type) {
if ("A".equals(type)) {
return new ProductA();
} else if ("B".equals(type)) {
return new ProductB();
}
throw new IllegalArgumentException("Unknown product type");
}
}
基于反射的简单工厂
这种方式可以减少工厂类中的if-else语句,使得代码更加简洁。
class ReflectiveSimpleFactory {
public static Product createProduct(String className) {
try {
Class<?> clazz = Class.forName(className);
return (Product) clazz.newInstance();
} catch (Exception e) {
throw new IllegalArgumentException("Unknown class name");
}
}
}
在使用时,可以这样调用:
Product productA = ReflectiveSimpleFactory.createProduct("ProductA");
productA.use();
Product productB = ReflectiveSimpleFactory.createProduct("ProductB");
productB.use();
// Product接口及其实现
interface Product {
void use();
}
class ProductA implements Product {
public void use() { System.out.println("Using Product A"); }
}
class ProductB implements Product {
public void use() { System.out.println("Using Product B"); }
}
// 基于Class对象的工厂类
class ClassBasedSimpleFactory {
public static Product createProduct(Class<? extends Product> productClass) {
try {
return productClass.getDeclaredConstructor().newInstance();
} catch (Exception e) {
throw new RuntimeException("Creation of product failed", e);
}
}
}
Product productA = ClassBasedSimpleFactory.createProduct(ProductA.class);
productA.use();
Product productB = ClassBasedSimpleFactory.createProduct(ProductB.class);
productB.use();
工厂方法模式
定义
工厂方法模式是一种创建型设计模式,它定义了一个用于创建对象的接口,但让子类决定要实例化哪个类。工厂方法使一个类的实例化延迟到其子类。
优点
- 符合开闭原则:新增产品类时,无需修改现有类,只需添加相应的工厂子类。
- 符合单一职责原则:每个具体工厂类只负责创建对应的产品。
- 解耦:客户代码和具体产品类解耦,客户代码不需要知道具体产品类的名称。
缺点
- 类的数量增加:每增加一个产品,通常都需要增加一个相应的工厂类。
- 增加了系统的复杂度:更多的类意味着更复杂的代码结构。
使用了什么原则
- 开闭原则:通过扩展来添加新的产品类,而无需修改现有的工厂。
- 依赖倒置原则:工厂方法使客户代码依赖于抽象接口,而不是具体实现。
违背了什么原则
- 可能违背了最少知识原则(Law of Demeter),因为引入了更多的对象和交互。
工厂方法模式解决了简单工厂模式的什么问题
- 解决了开闭原则的问题:在简单工厂模式中,新增产品需要修改工厂类。工厂方法模式通过让子类创建对象来解决这个问题。
- 更好的扩展性:每个产品都有一个与之对应的工厂类,产品与工厂的关系更清晰。
工厂方法模式中,每种产品有一个与之对应的工厂类。这种模式允许系统在不直接依赖具体产品类的情况下,通过调用对应的工厂来创建产品对象。它适用于产品种类较多且每种产品的创建逻辑相对独立的情况。其优点是良好地遵循了开闭原则,易于扩展新产品。缺点是随着产品种类的增加,需要增加越来越多的工厂类,增加了系统的复杂度。
工厂方法模式实现代码
假设我们有一个Product接口,多个产品实现这个接口,每个产品有对应的工厂类。
// Product接口
interface Product {
void use();
}
// 具体产品类
class ConcreteProductA implements Product {
public void use() { System.out.println("Using Product A"); }
}
class ConcreteProductB implements Product {
public void use() { System.out.println("Using Product B"); }
}
// 抽象工厂接口
interface ProductFactory {
Product createProduct();
}
// 具体工厂类
class ConcreteFactoryA implements ProductFactory {
public Product createProduct() {
return new ConcreteProductA();
}
}
class ConcreteFactoryB implements ProductFactory {
public Product createProduct() {
return new ConcreteProductB();
}
}
使用工厂方法模式:
public class FactoryMethodDemo {
public static void main(String[] args) {
ProductFactory factoryA = new ConcreteFactoryA();
Product productA = factoryA.createProduct();
productA.use();
ProductFactory factoryB = new ConcreteFactoryB();
Product productB = factoryB.createProduct();
productB.use();
}
}
抽象工厂模式
定义
抽象工厂模式是一种创建型设计模式,它提供了一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。抽象工厂模式通常涉及多个工厂方法,用于创建一系列的产品。
优点
- 增强模块性:将一组具有共同主题的工厂方法封装起来。
- 促进一致性:产品系列在逻辑上相关联,确保客户端始终只使用同一个系列的产品。
- 符合开闭原则:添加新的产品系列时,无需修改现有代码,只需要添加新的工厂。
缺点
- 类的数量增加:随着新产品的增加,需要增加更多的类和接口。
- 复杂度增加:增加了系统的抽象性和理解难度。
使用了什么原则
- 开闭原则:可以在不修改现有代码的情况下引入新的产品族。
- 抽象化:工厂接口和产品接口都是抽象的,具体实现由具体工厂决定。
违背了什么原则
- 可能会违背单一职责原则,因为一个工厂类可能需要创建多个产品对象。
抽象工厂模式解决了什么问题
- 解决产品族的创建问题:允许创建一系列相关的产品,而不是仅仅创建一个产品。
- 解决了工厂方法模式中的扩展问题:工厂方法模式在添加新产品时需要修改工厂接口,而抽象工厂模式则无需修改现有的工厂接口。
抽象工厂模式提供了一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。适用于产品族的概念,即一组产品需要一起使用,并且可能需要增加新的产品族。其优点是能够保证客户端始终使用同一产品族中的对象。缺点是难以支持新种类的(单一的)产品,因为抽象工厂接口确定了可以创建的产品集合,增加新种类的产品需要修改接口以及所有实现了该接口的类。
抽象工厂模式实现代码
假设我们有一个产品族,包含两种产品:ProductA和ProductB。每种产品有不同的变体。
这里的产品族的意思是,一系列相关的产品,整合到一起使得他们有关联性。
// Product接口及其变体
interface ProductA {
void useA();
}
interface ProductB {
void useB();
}
class ProductA1 implements ProductA {
public void useA() { System.out.println("Using Product A1"); }
}
class ProductA2 implements ProductA {
public void useA() { System.out.println("Using Product A2"); }
}
class ProductB1 implements ProductB {
public void useB() { System.out.println("Using Product B1"); }
}
class ProductB2 implements ProductB {
public void useB() { System.out.println("Using Product B2"); }
}
// 抽象工厂接口
interface AbstractFactory {
ProductA createProductA();
ProductB createProductB();
}
// 具体工厂实现
class ConcreteFactory1 implements AbstractFactory {
public ProductA createProductA() {
return new ProductA1();
}
public ProductB createProductB() {
return new ProductB1();
}
}
class ConcreteFactory2 implements AbstractFactory {
public ProductA createProductA() {
return new ProductA2();
}
public ProductB createProductB() {
return new ProductB2();
}
}
使用抽象工厂模式:
public class AbstractFactoryDemo {
public static void main(String[] args) {
AbstractFactory factory1 = new ConcreteFactory1();
ProductA productA1 = factory1.createProductA();
ProductB productB1 = factory1.createProductB();
productA1.useA();
productB1.useB();
AbstractFactory factory2 = new ConcreteFactory2();
ProductA productA2 = factory2.createProductA();
ProductB productB2 = factory2.createProductB();
productA2.useA();
productB2.useB();
}
}
总结
- 简单工厂模式 是一种非常基础的创建型模式,它通过一个单一的类来创建所有类型的对象。最适合于产品类型较少且逻辑简单的情况。
- 工厂方法模式 引入了抽象层,每种产品由一个专门的工厂创建,更符合开闭原则,适用于产品种类较多的情况。
- 抽象工厂模式 是最复杂的创建型模式之一,提供了一个接口来创建相关或依赖对象的家族,而不需要指定具体类。适用于需要一起使用一组产品或需要大量相互操作的产品的情况。
在选择这些模式时,需要考虑实际的应用场景、产品的复杂性以及系统未来可能的扩展性。简单工厂模式适用于产品种类相对较少且不经常变化的情况,工厂方法模式适用于产品种类较多且可能经常变化的情况,而抽象工厂模式适用于需要处理产品族并且产品族可能扩展的复杂场景。
建造者模式
建造者模式是一种创建型设计模式,它用于构造一个复杂对象的分步骤接口。在这种模式中,同一个构建过程可以创建不同的表示。建造者模式将对象的构造过程与其表示分离,使得同样的构建过程可以创建不同的表示。
目的和作用
- 分离复杂对象的构造和表示:允许用户仅通过指定复杂对象的类型和内容就可以构建它们,隐藏了对象的构建过程和细节。
- 创建过程一步一步进行:构建一个对象常常需要几个步骤。建造者模式使这些步骤可被逐步执行,而不是一次性完成。
- 更好的控制构建过程:建造者模式提供了对构建过程的精确控制。
结构
- Builder:为创建一个Product对象的各个部件指定抽象接口。
- ConcreteBuilder:实现Builder的接口以构造和装配该产品的各个部件。定义并明确它所创建的表示,并提供一个检索产品的接口。
- Director:构造一个使用Builder接口的对象。
- Product:表示被构造的复杂对象。
// 产品类
class Car {
private String engine;
private String wheels;
private String body;
// 省略构造器和属性的setter和getter
@Override
public String toString() {
return "Car{" +
"engine='" + engine + '\'' +
", wheels='" + wheels + '\'' +
", body='" + body + '\'' +
'}';
}
}
// 抽象建造者
abstract class CarBuilder {
protected Car car;
public Car getCar() {
return car;
}
public void createNewCar() {
car = new Car();
}
public abstract void buildEngine();
public abstract void buildWheels();
public abstract void buildBody();
}
// 具体建造者
class SportsCarBuilder extends CarBuilder {
@Override
public void buildEngine() {
car.setEngine("Sports Engine");
}
@Override
public void buildWheels() {
car.setWheels("Sports Wheels");
}
@Override
public void buildBody() {
car.setBody("Sports Body");
}
}
// 导演类
class Director {
private CarBuilder carBuilder;
public Director(CarBuilder carBuilder) {
this.carBuilder = carBuilder;
}
public Car construct() {
//可以发现每次都得操作一个builder对象
//所以是不是可以在这里进行优化呢
carBuilder.createNewCar();
carBuilder.buildEngine();
carBuilder.buildWheels();
carBuilder.buildBody();
return carBuilder.getCar();
}
}
// 使用示例
public class BuilderDemo {
public static void main(String[] args) {
CarBuilder builder = new SportsCarBuilder();
Director director = new Director(builder);
Car car = director.construct();
System.out.println(car);
}
}
在这个例子中,Car是产品类,CarBuilder是抽象建造者,提供了创建产品各个部件的接口。SportsCarBuilder是具体的建造者,实现了这些接口以构造和装配SportsCar的各个部件。Director类负责管理构造过程。
适用场景
- 当创建复杂对象的算法应独立于该对象的组成部分以及它们的装配方式时。
- 当构造过程必须允许被构造的对象有不同的表示时。
建造者模式提供了一种更灵活构造复杂对象的方式,允许用户只通过指定复杂对象的类型和内容就可以构建它们,同时将对象的构建过程和细节隐藏起来。
可以发现,上面的构造过程中,其实非常繁琐,每次都要重复使用builder对象,所以我们可以进行优化。
使得它的使用更加方便和直观。优化的常见方法是使用所谓的“流式接口”(Fluent Interface),它通过返回当前对象的引用(通常是通过返回this),允许链式调用设置方法,从而使代码更加简洁易读。
以下是对之前建造者模式示例的优化:
class Car {
private String engine;
private String wheels;
private String body;
// ... 省略其他部分 ...
// 使用流式接口设置属性
public Car setEngine(String engine) {
this.engine = engine;
return this;
}
public Car setWheels(String wheels) {
this.wheels = wheels;
return this;
}
public Car setBody(String body) {
this.body = body;
return this;
}
// ... 省略其他部分 ...
}
class CarBuilder {
private String engine = "Default Engine";
private String wheels = "Default Wheels";
private String body = "Default Body";
public CarBuilder setEngine(String engine) {
this.engine = engine;
return this;
}
public CarBuilder setWheels(String wheels) {
this.wheels = wheels;
return this;
}
public CarBuilder setBody(String body) {
this.body = body;
return this;
}
public Car build() {
return new Car().setEngine(engine).setWheels(wheels).setBody(body);
}
}
// 使用示例
public class BuilderDemo {
public static void main(String[] args) {
Car car = new CarBuilder()
.setEngine("Sports Engine")
.setWheels("Sports Wheels")
.setBody("Sports Body")
.build();
System.out.println(car);
}
}
在优化后的版本中,Car类和CarBuilder类都提供了设置各个属性的方法,并且这些方法都返回当前对象的引用。这允许在构建Car对象时可以进行链式调用,使代码更加清晰和简洁。
这种方式的优点是使得客户端代码更加直观和易于理解,同时保持了灵活性和可读性。这种风格的建造者模式在许多现代Java库中非常常见,尤其是在创建配置密集型对象时。
这种通过链式编程的方式来实现建造者方式,使得代码更加方便,我们使用Lombok注解提供的@Builder也就是通过这种方式实现的,非常的方便。
建造者模式的最直接的用法就是我们的StringBuffer了,它的append方法。
优点
- 分离复杂对象的构造和表示:建造者模式将一个复杂对象的构建过程与其表示分离,使得相同的构建过程可以创建不同的表示。
- 更好的封装性:客户端无需了解产品内部的构建细节,建造者隐藏了产品的内部结构和装配过程。
- 构建过程一步一步进行:建造者模式允许产品内部表示逐步构建并逐步细化,使用者可以控制产品的构建过程。
- 更好的控制构建过程:建造者模式可以更精细地控制产品的创建过程,尤其是当一个对象需要通过多个步骤构建时。
- 流式接口:建造者模式经常与“链式调用”结合使用,提供流畅的接口,使得代码更加直观和易于使用。
缺点
- 增加系统复杂性:引入多个新类,增加了系统的复杂性。
- 性能开销:由于涉及到创建多个建造者对象,可能会增加一些系统的性能开销。
- 代码冗长:在使用建造者模式时,可能会导致更多的代码编写,特别是当有多个属性需要设置时。
使用场景
- 构造复杂对象:当构造复杂对象时,特别是那些包含多个成员变量的对象,使用建造者模式可以更清晰地表示构造过程。
- 对象的组成部分可以有不同的表示:如果一个对象的组成部分可以有不同的表示或配置,建造者模式提供了一种灵活的解决方案。
- 当需要保证构造过程的稳定性:在构造过程中,不希望对象处于不一致的状态,或者对象的构造非常复杂,建造者模式可以在整个构造过程中保持对象的一致性。
- 流式API设计:在设计具有流式API的类时(如在配置构建过程中),建造者模式是一个很好的选择。
建造者模式和工厂模式都是为了创建对象,但是他们也有一些区别。
建造者模式
- 目的和用途:用于创建复杂对象,特别是那些包含多个成分和步骤的对象。它允许客户端逐步构建复杂对象,并能够改变对象的内部表示。
- 构造过程:建造者模式更关注于对象构造的细节和步骤。构造过程分步进行,每一步可以精细控制,可以创建具有不同表示的对象。
- 灵活性和控制:提供更多的控制灵活性,客户端可以仅通过指定类型和内容来构建复杂对象,隐藏了对象的创建细节。
工厂模式
- 目的和用途:主要用于创建对象,特别是在创建对象的逻辑比较复杂时,如依赖于某些动态条件或配置。它主要关注对象创建的结果,而不是创建过程。
- 构造过程:工厂模式通常通过一个工厂类提供一个创建对象的方法,并返回一个已经创建好的对象实例。创建过程通常是单步的。
- 灵活性和控制:工厂模式适用于那些对象的创建方式相对固定,但根据不同参数或配置可以创建不同类实例的场景。
区别总结
- 构造的复杂性:建造者模式用于构造复杂对象,允许步骤化构建,而工厂模式用于创建相对简单的对象,通常一步完成。
- 关注点:建造者模式关注如何分步骤构建一个复杂对象,而工厂模式关注如何创建一个对象。
- 灵活性:建造者模式在构建对象时提供了更多的灵活性,可以调整对象的各个组成部分,而工厂模式通常是固定的创建逻辑。
单例模式
定义
单例模式是一种常用的软件设计模式,其核心思想是确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。单例模式的实现通常涉及以下几个关键点:
- 私有构造函数:为了避免外部通过new关键字创建多个实例,单例类的构造函数需要被声明为私有。
- 私有静态实例:单例类内部创建一个私有的静态实例。
- 公共静态方法:提供一个公共的静态方法来获取这个唯一的实例。如果实例不存在,该方法会创建它;如果已存在,就直接返回。
单例模式的使用场景包括,但不限于,数据库连接、日志记录、配置管理等,这些场景中通常只需要一个共享的实例,或者因为创建实例的代价较高而需要限制实例的数量。
单例模式有几个变体,例如懒汉式(延迟初始化)、饿汉式(预先初始化)、双重检查锁定(Double-Check Locking)、注册式单例、ThreadLocal单例等,每种变体都有其特定的使用场景和优缺点。
对于ApplicationContext、ServletContext、DBPool等核心框架和系统组件被设计为单例,主要是出于以下几个原因:
- 资源和性能管理:这些对象通常管理着重要的资源,如数据库连接、配置数据和应用状态。如果每次使用时都创建新的实例,将极大增加资源消耗和性能开销。单例确保只有一个实例管理所有资源,从而提高效率。
- 全局访问性:这些组件通常在应用程序的不同部分被访问和使用。作为单例,可以很方便地在应用的任何位置通过一个全局访问点获取它们,而不必每次都传递对象引用。
- 保持一致性:如果有多个实例,每个实例可能会有自己的状态和配置。这可能导致应用程序的行为不一致,难以调试和维护。单例模式确保所有对这些组件的访问都是对同一个实例和同一状态的访问,从而保持了一致性。
- 简化配置和管理:如果每个组件都有多个实例,那么配置和管理这些实例将变得复杂。单例模式简化了配置管理,因为只需要配置一个实例。
例如,ApplicationContext在Spring框架中用于管理Bean的生命周期和依赖注入,如果有多个实例,每个实例可能会有不同的配置和状态,这会导致数据不一致和逻辑错误。同理,ServletContext用于表示整个web应用的环境,多实例将导致无法有效共享应用级信息。数据库连接池(DBPool)作为单例则能有效管理数据库连接,提高资源利用率,避免频繁创建和销毁连接带来的性能开销。
因此,将这些组件设计为单例是为了保持应用程序的一致性、减少资源消耗,并简化配置和管理的复杂性。
饿汉式单例
饿汉式单例模式是在类加载时就创建了单例对象,确保了单例的唯一性。以下是一个饿汉式单例的实现示例:
public class Singleton {
// 在类加载时就初始化
private static final Singleton INSTANCE = new Singleton();
//使用static赋值 和上面的那种方式二选一即可
static{
INSTANCE = new Singleton();
}
// 私有构造方法,防止外部实例化
private Singleton() {}
// 提供一个全局访问点
public static Singleton getInstance() {
return INSTANCE;
}
// 示例方法
public void doSomething() {
// ...
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
Singleton singleton = Singleton.getInstance();
singleton.doSomething();
}
}
优点和设计理由
- 简单直观:实现简单,易于理解,且实例化代码安全在类加载时完成,避免了多线程同步问题。
- 线程安全:由于单例的唯一实例在类加载时创建,因此无需担心多线程环境下的同步问题。
- 即时加载:由于实例在类加载时创建,因此可以确保在第一次调用getInstance时单例对象已经被创建。
缺点
- 提前占用资源:单例对象无论是否需要都会在类加载时创建,可能会导致内存和资源的浪费,特别是当单例类的初始化过程中需要加载大量资源或执行耗时操作时。
- 无法延迟加载:与懒汉式单例相比,饿汉式单例无法实现延迟加载,即在真正需要对象之前就已经创建了对象。
- 可能影响启动性能:如果单例类在初始化时执行了大量的初始化操作,可能会导致应用启动速度变慢。
由于饿汉式单例的缺点是提前加载,因此在spring中就不可能使用饿汉式了,当然你也可以通过配置的方式来设定为某些类使用饿汉式单例,因为如果所有类都是用饿汉式单例加载,那么spring项目的启动速度将会大幅度降低。
懒汉式单例
懒汉式单例模式是一种单例实现方式,它在类加载时不会创建单例实例,而是在第一次被客户端调用时才创建这个唯一的实例。这种方式实现了延迟加载,有助于减少资源的浪费。
public class LazySingleton {
private static LazySingleton instance;
// 私有构造函数,防止外部实例化
private LazySingleton() {}
// 提供一个全局访问点
public static LazySingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
// 示例方法
public void doSomething() {
// ...
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
LazySingleton singleton = LazySingleton.getInstance();
singleton.doSomething();
}
}
优点
- 延迟加载:只有在真正需要使用对象时,才会创建单例对象,可以减少资源的消耗。
- 资源利用率高:在实例不需要时不会占用资源。
缺点
- 线程不安全:在多线程环境下,如果多个线程同时访问并且实例尚未创建,可能会导致创建多个实例。为了解决这个问题,需要在getInstance方法上添加synchronized关键字,但这会降低效率。
- 性能开销:添加同步锁后,每次访问都会进行线程同步,这在高并发环境下可能会成为性能瓶颈。
具体为什么会导致线程不安全,可以看下面我debug的方式。
我们当线程0先进入到断点,并且我们让其走进if,然后此时我们切换到线程1。
也就是此时两个线程下一步要执行的都是创建操作。
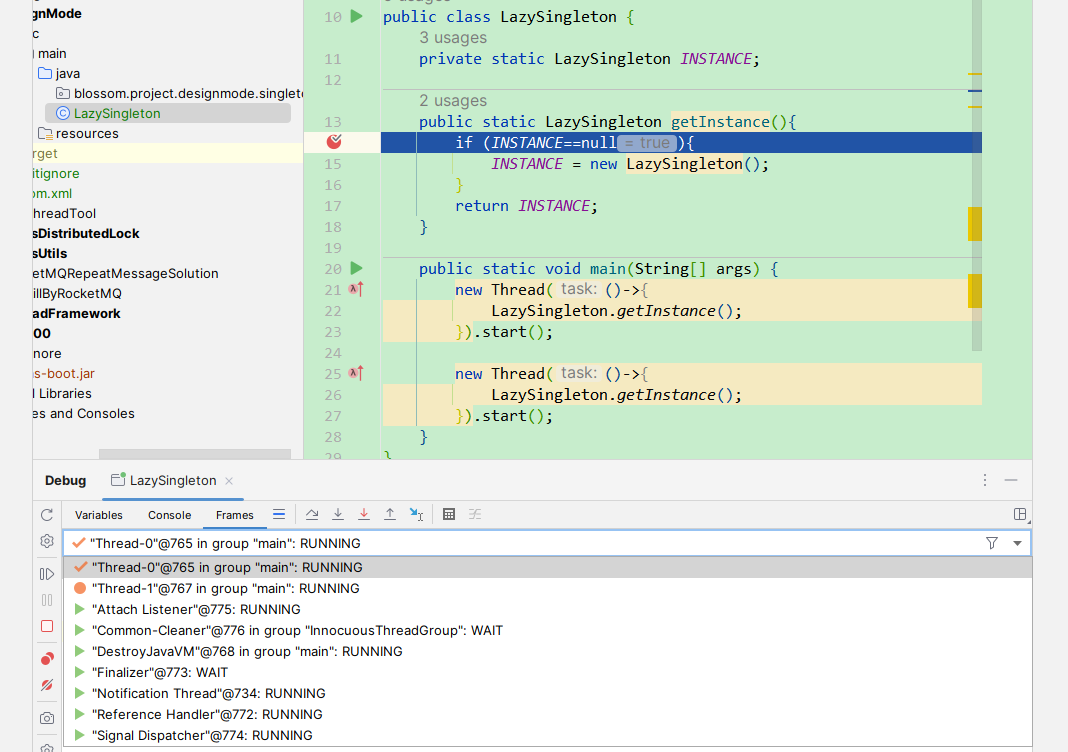
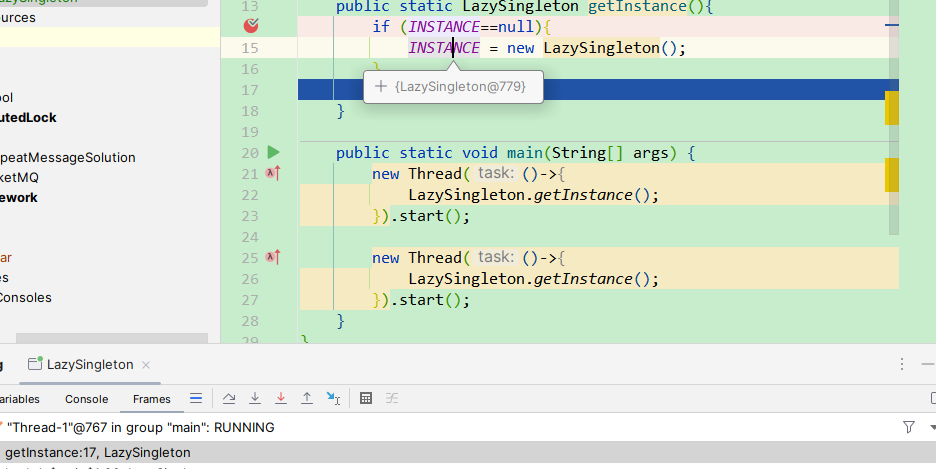
可以发现,这里就很明显的已经创建了两个的INSTANCE实例了,单例就被破坏。
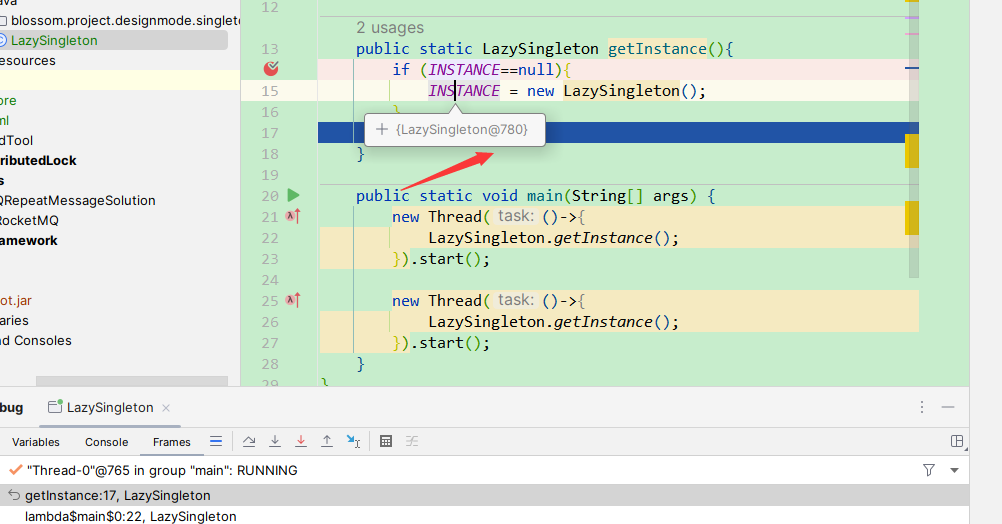
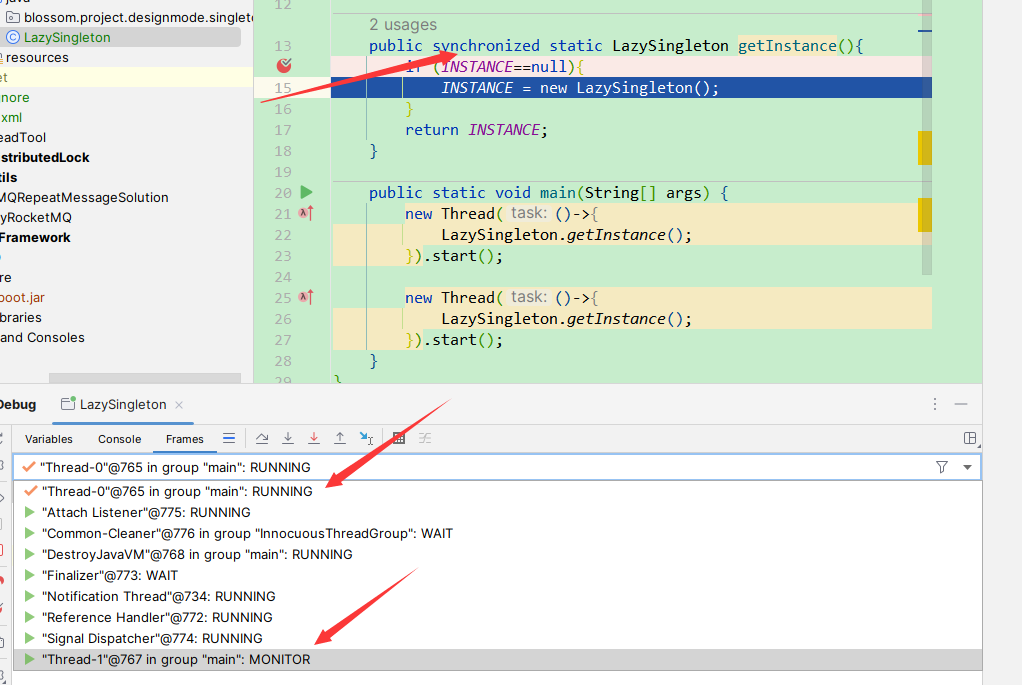
而如果要解决这个问题,我们可以考虑加锁,将我们的方法设定为synchronized修饰。
那么此时这两个线程只能二选一的去执行创建,也就解决了线程安全问题。但是我们都知道加锁会导致线程阻塞。而这也是我们需要去避免的问题。具体的解决方法我们可以看下一节。
双检锁单例
双重检查锁定单例是一种结合了懒汉式单例和同步锁的设计模式。它在单例的实例创建过程中进行了两次检查:第一次是为了避免不必要的同步,第二次是为了在单例实例尚未创建时创建实例。
public class DoubleCheckedLockingSingleton {
// 使用volatile关键字保证了instance变量的可见性
private static volatile DoubleCheckedLockingSingleton instance;
// 私有构造函数,防止外部实例化
private DoubleCheckedLockingSingleton() {}
// 提供一个全局访问点
public static DoubleCheckedLockingSingleton getInstance() {
if (instance == null) { // 第一重检查
synchronized (DoubleCheckedLockingSingleton.class) { // 同步锁
if (instance == null) { // 第二重检查
instance = new DoubleCheckedLockingSingleton();
}
}
}
return instance;
}
// 示例方法
public void doSomething() {
// ...
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
DoubleCheckedLockingSingleton singleton = DoubleCheckedLockingSingleton.getInstance();
singleton.doSomething();
}
}
优点
- 延迟加载和性能:只有在实例真正需要时才创建,并且大多数情况下不需要执行同步锁代码,相比于普通的懒汉式单例,提高了性能。
- 线程安全:通过同步锁和两次检查确保在多线程环境下的线程安全。
缺点
- 实现复杂:相比其他单例实现,代码更复杂,需要正确处理双重检查和volatile关键字。
- 对JVM的依赖:这种实现方式依赖于JVM的内存模型,早期版本的Java中volatile关键字的语义可能导致问题。在现代Java版本中,这一点已经得到了改善。
双重检查锁定单例模式的设计是为了解决懒汉式单例在多线程环境下的性能问题,同时保持延迟加载的优势。使用volatile关键字防止了JVM指令重排,保证了在多线程环境中对单例实例的安全发布。
静态内部类单例
静态内部类单例模式是利用Java语言特性实现单例的一种方式。它通过在单例类内部创建一个静态内部类,在这个内部类中持有单例对象的实例。由于静态内部类只会在第一次被加载时初始化一次,这种方法自然地实现了延迟加载和线程安全。
public class Singleton {
// 私有构造函数,防止外部实例化
private Singleton() {}
// 静态内部类
private static class SingletonHolder {
// 在内部类中持有单例的实例,并且可被直接初始化
private static final Singleton INSTANCE = new Singleton();
}
// 提供一个全局访问点
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
// 示例方法
public void doSomething() {
// ...
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
Singleton singleton = Singleton.getInstance();
singleton.doSomething();
}
}
优点
- 延迟加载:单例实例在第一次被使用时创建,实现了延迟加载。
- 线程安全:Java虚拟机在加载静态内部类时确保了线程的安全性,不需要额外的同步措施。
- 无性能缺陷:不涉及同步锁,性能相对较高。
- 代码简洁:实现方式简单明了。
缺点
- 对静态内部类的理解:这种方法的理解和实现依赖于对Java语言中静态内部类的理解。对于不熟悉这一概念的开发者来说,可能稍显复杂。
- 序列化问题:如果单例类实现了Serializable接口,反序列化时可能会创建新的实例,违反单例模式。这可以通过实现readResolve方法来解决,但需要额外的注意。
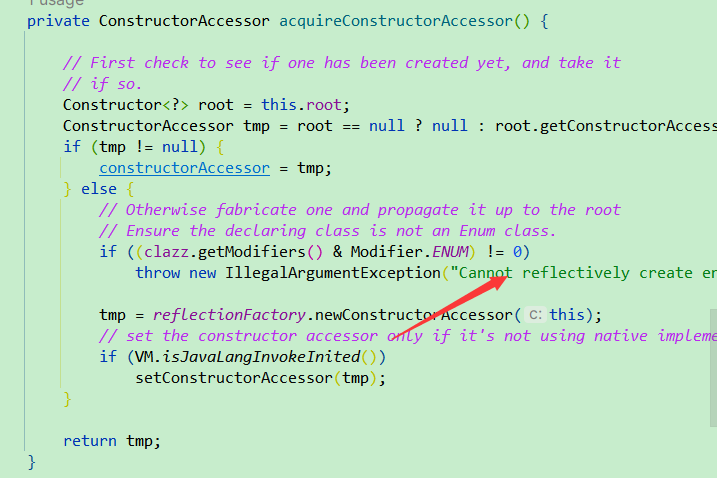
- 反射攻击:尽管这不是特定于静态内部类单例模式的问题,但如果不正确处理,通过反射机制仍然可以创建单例类的多个实例。要防止这种情况,可以在构造函数中添加逻辑来阻止反射创建新的实例。
- 类加载器问题:在复杂的Java应用中,不同的类加载器可能会导致同一个类被加载多次,从而创建多个实例。这在大型企业级应用或者模块化框架中可能需要特别注意。
反射破坏单例以及防御反射破坏
其实我们知道,反射是可以破坏掉所有常规单例的,因为我们可以直接通过获取到构造方法的方式来创建对象实例。这里使用反射破坏单例比较简单,我写一套代码来反射反射的破坏,这里就基于静态内部类单例的方式来解决反射的破坏。
根据上面我们的静态内部类的特性我们知道,反射破坏单例的方法其实就是通过直接获取到外部类的构造方法然后newInstance的方式来获取到实例对象,那么我们可以在构造方法这里进行判断,如果内部类还没有被创建,你就像调用我构造方法,我直接一个报错。
当然,就是写起来不那么优雅。
package blossom.project.designmode.singleton;
import java.lang.reflect.Constructor;
public class Singleton {
// 私有构造方法
private Singleton() {
// 防御反射破坏单例
if (SingletonHolder.INSTANCE != null) {
throw new IllegalStateException("Instance already exists!");
}
}
// 静态内部类
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
// 获取实例的公共静态方法
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
public void show() {
System.out.println("Singleton using static inner class");
}
}
class ReflectionSingletonTest {
public static void main(String[] args) {
try {
// 获取Singleton类的Class对象
Class<Singleton> clazz = Singleton.class;
// 获取私有构造方法
Constructor<Singleton> constructor = clazz.getDeclaredConstructor();
// 设置私有构造方法的可访问性
constructor.setAccessible(true);
// 创建Singleton的实例
Singleton instance1 = constructor.newInstance();
// 获取正常途径获得的实例
Singleton instance2 = Singleton.getInstance();
// 输出两个实例的哈希码,检查是否相同
System.out.println(instance1.hashCode());
System.out.println(instance2.hashCode());
} catch (Exception e) {
e.printStackTrace();
}
}
}
枚举式单例
枚举式单例模式是利用Java的枚举类型来实现单例模式。由于Java保证任何枚举值只实例化一次,在整个程序中不会被再次实例化,这自然形成了单例模式。并且由于枚举类型不能使用反射创建,所以保证了安全。
public enum Singleton {
INSTANCE;
public void doSomething() {
System.out.println("Doing something...");
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
Singleton singleton = Singleton.INSTANCE;
singleton.doSomething();
}
}
优点
- 简洁性:使用枚举实现单例模式非常简洁,无需自己处理线程安全或者实例化逻辑。
- 线程安全:枚举实例的创建是线程安全的,Java虚拟机保证其只被实例化一次。
- 防止反射攻击:由于枚举类没有公开的构造方法,因此无法通过反射来创建枚举实例。
- 防止序列化破坏:枚举序列化是由JVM特殊处理的,每个枚举类型和枚举变量在JVM中都是唯一的。
缺点
- 不够灵活:枚举类型不允许懒加载,即它们在类被加载时就被实例化了。
- 功能限制:枚举类本身的功能相对于普通类来说较为有限,如果单例需要继承其他类,或者需要灵活地扩展功能,使用枚举来实现单例就不太适合。
- **内存浪费:**枚举类被加载到内存中的时候,其中的枚举常量就已经被创建,类似于饿汉式,因此会造成内存浪费,Spring框架依旧不可能直接使用枚举单例。
枚举式单例能够防止反射攻击主要是由于Java枚举类型的语言特性。在Java中,枚举类型有以下特点:
- 无公开构造方法:枚举类型的构造方法在定义时就被自动声明为私有的。由于外部无法访问枚举的构造方法,因此无法通过反射来创建枚举类型的新实例。
- 枚举实例的唯一性:Java确保每个枚举常量只被实例化一次。在枚举类被加载到内存时,其枚举常量就已经被创建。JVM内部对枚举的实例化过程进行了控制,确保每个枚举常量只被实例化一次,且在整个Java程序中是单例的。
- 特殊的序列化机制:枚举的序列化和反序列化机制与普通类不同。当一个枚举实例被序列化时,只有其名称被保存下来;反序列化时,JVM会直接使用该名称在枚举类中查找对应的单一实例。因此,即使是通过反序列化,也不可能创建出枚举实例的多个副本。
枚举式单例模式是实现单例的最佳方法之一,特别是在简单的单例实现中,或者在需要确保单例实例绝对防止多次实例化的场景下。由于其简洁性和提供的安全保证,它在许多情况下是实现单例的首选方法。
容器式单例
容器式单例模式(也称为注册式单例模式)使用一个容器来维护单例对象的引用,通常通过一个键(如字符串标识)来访问容器中的单例对象。这种模式允许在运行时动态地管理单例对象,使得管理多种单例更为灵活。
spring就是类似于按照这种方式来实现单例,但是肯定更加复杂和完整。
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class SingletonManager {
private static final Map<String, Object> INSTANCE_MAP = new ConcurrentHashMap<>();
private SingletonManager() {}
@SuppressWarnings("unchecked")
public static <T> T getInstance(String className) {
return (T) INSTANCE_MAP.computeIfAbsent(className, key -> {
try {
Class<?> clazz = Class.forName(key);
return clazz.getDeclaredConstructor().newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
});
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
MySingleton singleton = SingletonManager.getInstance(MySingleton.class.getName());
singleton.doSomething();
}
}
class MySingleton {
public void doSomething() {
System.out.println("Doing something...");
}
}
优点
- 灵活性:可以管理多种单例,并且在运行时动态地创建和获取单例。
- 扩展性:容易扩展,可以适用于不同场景下的单例管理。
- 线程安全:使用ConcurrentHashMap确保了线程安全性。
缺点
- 管理复杂性:随着单例的增多,容器的管理可能变得复杂。
- 性能考虑:相比于其他单例实现方式,容器式单例可能在获取实例时有更高的性能开销,尤其是在多线程环境下。
- 安全性:如果不正确管理,可能会引入安全问题,例如在并发环境下可能出现的单例重复创建问题。
容器式单例模式适用于需要管理多种单例对象的场景,特别是在对象种类和数量在编译时无法完全确定,或者需要延迟加载的情况。这种模式通过统一的接口来管理和访问多个单例,使得单例对象的管理更加集中和统一。
注册式单例本身,在使用ConcurrentHashMap作为注册容器时,确实是线程安全的。ConcurrentHashMap通过提供线程安全的putIfAbsent、computeIfAbsent等方法,可以确保在多线程环境下对单个键值对的操作是安全的。
然而,线程安全问题可能出现在以下几个方面:
- 单例创建过程:如果单例对象的创建过程本身不是线程安全的,那么即使ConcurrentHashMap是线程安全的,也可能在实例化单例时遇到问题。例如,如果单例类的构造函数中包含非线程安全的操作,或者有可能被多次执行的副作用,那么在多线程环境下可能会出现问题。
- 单例使用后的状态变更:单例对象一旦被创建并存入ConcurrentHashMap,它的使用就不再由ConcurrentHashMap来控制。如果单例对象内部状态可以被更改,且这些状态更改操作不是线程安全的,那么即使单例的注册和获取是线程安全的,使用单例时仍然可能会遇到线程安全问题。
- 单例的延迟加载:如果注册式单例模式实现了延迟加载(例如,使用computeIfAbsent等方法),则必须确保单例对象的创建过程是原子的,并且在整个过程中不会有多个线程尝试创建同一个实例。
序列化反序列化破坏单例
序列化和反序列化机制在某些情况下可以破坏单例模式。这是因为反序列化每次都会创建一个新的实例,不管该类是否实现了单例模式。下面是一个演示如何使用序列化和反序列化来破坏单例模式的例子:
首先,我们创建一个实现了Serializable接口的单例类:
import java.io.Serializable;
public class Singleton implements Serializable {
private static final long serialVersionUID = -7604766932017737115L;
private static final Singleton INSTANCE = new Singleton();
private Singleton() {
if (INSTANCE != null) {
throw new RuntimeException("Use getInstance() method to get the single instance of this class.");
}
}
public static Singleton getInstance() {
return INSTANCE;
}
// 此方法用于防止反序列化破坏单例
protected Object readResolve() {
return getInstance();
}
}
接下来,我将这个单例实例序列化到一个文件中,然后再从该文件中反序列化两次,从而尝试创建两个实例:
import java.io.*;
public class SingletonSerializationTest {
public static void main(String[] args) throws Exception {
Singleton instanceOne = Singleton.getInstance();
ObjectOutput out = new ObjectOutputStream(new FileOutputStream("singleton.ser"));
out.writeObject(instanceOne);
out.close();
// 反序列化第一次
ObjectInput in = new ObjectInputStream(new FileInputStream("singleton.ser"));
Singleton instanceTwo = (Singleton) in.readObject();
in.close();
// 反序列化第二次
in = new ObjectInputStream(new FileInputStream("singleton.ser"));
Singleton instanceThree = (Singleton) in.readObject();
in.close();
// 检查是否相同
System.out.println("instanceOne hashCode=" + instanceOne.hashCode());
System.out.println("instanceTwo hashCode=" + instanceTwo.hashCode());
System.out.println("instanceThree hashCode=" + instanceThree.hashCode());
}
}
在这个例子中,即使Singleton类是单例的,序列化和反序列化机制仍然可以创建它的多个实例。为了防止这种情况,我们在Singleton类中添加了readResolve方法。这个方法在反序列化过程中被调用,用于返回单例实例,从而保护单例状态不被破坏。
当运行上述代码时,你会发现所有实例的哈希码都是相同的,这表明反序列化过程中没有创建新的实例,单例状态得到了维护。这正是readResolve方法的功效。
ThreadLocal单例
使用ThreadLocal实现单例模式是一种确保在每个线程中单例对象唯一的方法。这种实现方式适用于需要在多线程环境下为每个线程维护一个单独的单例实例的场景。
public class ThreadLocalSingleton {
private static final ThreadLocal<ThreadLocalSingleton> INSTANCE = ThreadLocal.withInitial(ThreadLocalSingleton::new);
private ThreadLocalSingleton() {}
public static ThreadLocalSingleton getInstance() {
return INSTANCE.get();
}
public void doSomething() {
// 方法实现
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
ThreadLocalSingleton singleton = ThreadLocalSingleton.getInstance();
singleton.doSomething();
}
}
在这个实现中,ThreadLocal.withInitial(ThreadLocalSingleton::new) 确保了每个访问该单例的线程都有一个独立的ThreadLocalSingleton实例。当调用getInstance()方法时,它首先检查当前线程的ThreadLocal映射中是否有ThreadLocalSingleton的实例。如果没有,它将调用提供的Supplier接口(这里是通过方法引用ThreadLocalSingleton::new实现的)来创建一个新的实例并保存在当前线程的ThreadLocal映射中。
特点和适用场景
- 线程隔离:每个线程都有一个单独的单例实例,这保证了在多线程环境下各个线程之间的单例对象是隔离的。
- 延迟加载和高效性:实例是在第一次使用时创建的,而且由于ThreadLocal确保每个线程只创建一次实例,因此它是延迟加载且高效的。
- 适用场景:适用于多线程环境下,需要为每个线程维护一个独立状态的场景,如用户会话管理、事务管理等。
需要注意的是,ThreadLocal单例模式并不是传统意义上的全局单例,因为它为每个线程创建了一个单独的实例。在使用这种单例模式时,应该清楚地了解其线程隔离的特性以及适用的场景。
代理模式
定义与作用
代理模式是一种结构型设计模式,它为其他对象提供了一种代理(或称为替身),以控制对这个对象的访问。在代理模式中,代理对象插入到实际对象和访问者之间,作为中介,执行某些操作(如访问控制、延迟初始化、日志记录等),然后将调用传递给实际对象。代理模式的主要作用如下:
- 访问控制:代理可以控制对原始对象的访问,适用于需要基于权限的访问控制或保护目标对象的场景。
- 延迟初始化(虚拟代理):如果一个对象的创建和初始化非常耗时,代理模式可以延迟该对象的创建到真正需要的时候进行。
- 日志记录和审计:代理可以记录对目标对象的操作,用于审计或确保合规性。
- 智能引用:代理可以在对象被访问时执行额外的动作,如计数引用次数、检测对象是否已被释放等。
- 远程代理:代理可以隐藏一个对象存在于不同地址空间的事实,如在网络另一侧的对象。
静态代理
静态代理是指在编译期间就创建好代理类的一种代理模式。在这种模式下,代理类和目标对象实现相同的接口或继承相同的类,代理类持有目标对象的引用,并在调用目标对象的方法前后可以执行一些附加操作。
以一个简单的例子来说明,假设有一个接口和一个实现了这个接口的类,我们将创建一个代理类来增强这个实现类的功能:
javaCopy code
// 接口
interface Service {
void doSomething();
}
// 实现类
class RealService implements Service {
public void doSomething() {
System.out.println("Doing something in RealService");
}
}
// 静态代理类
class StaticProxy implements Service {
private Service realService;
public StaticProxy(Service realService) {
this.realService = realService;
}
public void doSomething() {
System.out.println("Before RealService doSomething");
realService.doSomething();
System.out.println("After RealService doSomething");
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
Service service = new StaticProxy(new RealService());
service.doSomething();
}
}
优点
- 编译时创建:静态代理的代理类在编译时就已经确定,代码中显式定义了代理类。
- 简单直观:实现起来相对简单,容易理解。
- 代码冗余:对于每个需要代理的类,都需要显式地创建一个代理类。
适用场景
- 当目标对象的行为不经常变化时,静态代理是一个不错的选择。
- 在需要对某个对象的方法调用进行统一的处理(如安全检查、事务处理、日志记录等)时使用。
缺点
- 代码量大:如果需要代理的方法很多,代理类的代码量会非常大。
- 灵活性差:由于代理类在编译期就已经确定,对代理的修改可能需要修改代理类的源代码,并重新编译。
静态代理模式在应用较为简单且目标对象稳定的情况下是非常有用的,但在需要大量动态代理的方法或目标对象经常变化的情况下,可能会导致代码的冗余和维护难度增加。在这种情况下,可以考虑使用动态代理模式。
JDK动态代理
JDK动态代理是Java提供的一种动态生成代理对象的机制,它允许开发者在运行时创建代理对象,而无需为每个类编写具体的代理实现。JDK动态代理主要通过java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来实现。
实现原理
JDK动态代理工作原理是利用InvocationHandler来关联代理对象和实际对象,当通过代理对象调用方法时,这个调用会被转发到InvocationHandler的invoke方法。在invoke方法内,开发者可以在调用实际对象的方法前后添加自定义逻辑。
下面是一个使用JDK动态代理的例子:
package blossom.project.designmode.proxy;
import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import sun.misc.ProxyGenerator;
// 接口
interface Service {
void doSomething();
}
// 实现类
class RealService implements Service {
public void doSomething() {
System.out.println("Doing something in RealService");
}
}
// 调用处理器
class ServiceInvocationHandler implements InvocationHandler {
//被代理的实际对象
private Object target;
public ServiceInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//代理前置处理
System.out.println("Before method " + method.getName());
//被代理对象的方法被调用
Object result = method.invoke(target, args);
//代理后置处理
System.out.println("After method " + method.getName());
return result;
}
}
// 使用示例
public class JdkProxy {
public static void main(String[] args) {
RealService realService = new RealService();
//创建代理对象 然后调用代理对象的方法即可
Service proxyService = (Service) Proxy.newProxyInstance(
RealService.class.getClassLoader(),
new Class<?>[] {Service.class},
new ServiceInvocationHandler(realService)
);
proxyService.doSomething();
//生成字节码文件
byte[] classFile = ProxyGenerator.generateProxyClass("$Proxy0", new Class[]{Service.class});
// 保存到文件系统
try (FileOutputStream out = new FileOutputStream("D://desktop//" + "$Proxy.class")) {
out.write(classFile);
} catch (IOException e) {
e.printStackTrace();
}
}
}
在这个例子中,Service是一个接口,RealService是它的一个实现。ServiceInvocationHandler是一个InvocationHandler,在invoke方法中添加了在执行方法前后的逻辑。我们使用Proxy.newProxyInstance方法创建了RealService的代理对象。
优点
- 灵活性:可以在运行时为多个接口动态创建代理,无需为每个接口编写专门的代理类。
- 减少冗余代码:通过处理器类(如ServiceInvocationHandler)来集中处理代理逻辑,减少了重复代码。
缺点
- 只支持接口:JDK动态代理只能代理接口,不支持类。
- 性能开销:由于使用反射机制,可能会有一定的性能开销。
适用场景
JDK动态代理适用于需要代理的对象实现了一个或多个接口的场景。它在AOP(面向切面编程)、事务代理、日志记录等场景中非常有用。
面试的时候有被问到JDK动态代理的底层实现源码,所以这里我也简单的介绍一下它的源码实现。
JDK动态代理原理
运行我们上面的代码并且进入debug状态,可以看到如下状态。

首先是我们的proxyService的内部的target就是我们一开始new出来的那个需要被代理的对象。
但是最后的这个proxyService可以发现它的类型是 P r o x y ,我们知道,使用 Proxy,我们知道,使用 Proxy,我们知道,使用代表的是他是一个子类或者内部类的意思。而这里用 P r o x y 开头代表的是他是一个代理类,在外面看不到只能在内存中看到。而这里的 0 代表的是 J d k 自增的一个序号。这里我们知道,动态代理的底层其实就是为我们再运行的时候生成了一个类,那么我们只需要看看这个类的代码,我们就能大概知道他是如何实现的了。接下来我们来获取动态代理生成的类的字节码文件,运行上面的代码:这里特别注意需要用 J D K 8 哦。此时我们会得到一个 c l a s s 文件,不用打开看了,你啥也看不懂的。 ! [ i m a g e . p n g ] ( h t t p s : / / i m g − b l o g . c s d n i m g . c n / i m g c o n v e r t / 19 e c 2 d 3 b b 048 f 7 c 0 e 1746490239248 b 3. p n g ) 然后我们使用 J A D 来进行反编译,如果没有下载 J A D 的可以下载一个,链接如下: [ J A D 反编译工具 ] ( h t t p s : / / v a r a n e c k a s . c o m / j a d / ) ! [ i m a g e . p n g ] ( h t t p s : / / i m g − b l o g . c s d n i m g . c n / i m g c o n v e r t / a b 93 a 53 f 7 e 2 f 082049 e a 263 a 2883 d b a e . p n g ) 之后就得到了反编译以后的文件了。上面的代码编译后如下:其中可以看到我们的被代理的方法,调用的是 s u p e r . h . i n v o k e 方法,那么我们就得了解一下这个 h 到底是什么了。我们进入到 P r o x y 类的源码进行查看。因为这里 Proxy开头代表的是他是一个代理类,在外面看不到只能在内存中看到。而这里的0代表的是Jdk自增的一个序号。 这里我们知道,动态代理的底层其实就是为我们再运行的时候生成了一个类,那么我们只需要看看这个类的代码,我们就能大概知道他是如何实现的了。 接下来我们来获取动态代理生成的类的字节码文件,运行上面的代码: 这里特别注意需要用JDK8哦。 此时我们会得到一个class文件,不用打开看了,你啥也看不懂的。  然后我们使用JAD来进行反编译,如果没有下载JAD的可以下载一个,链接如下: [JAD反编译工具](https://varaneckas.com/jad/)  之后就得到了反编译以后的文件了。 上面的代码编译后如下: 其中可以看到我们的被代理的方法,调用的是super.h.invoke方法,那么我们就得了解一下这个h到底是什么了。我们进入到Proxy类的源码进行查看。 因为这里 Proxy开头代表的是他是一个代理类,在外面看不到只能在内存中看到。而这里的0代表的是Jdk自增的一个序号。这里我们知道,动态代理的底层其实就是为我们再运行的时候生成了一个类,那么我们只需要看看这个类的代码,我们就能大概知道他是如何实现的了。接下来我们来获取动态代理生成的类的字节码文件,运行上面的代码:这里特别注意需要用JDK8哦。此时我们会得到一个class文件,不用打开看了,你啥也看不懂的。然后我们使用JAD来进行反编译,如果没有下载JAD的可以下载一个,链接如下:[JAD反编译工具](https://varaneckas.com/jad/)之后就得到了反编译以后的文件了。上面的代码编译后如下:其中可以看到我们的被代理的方法,调用的是super.h.invoke方法,那么我们就得了解一下这个h到底是什么了。我们进入到Proxy类的源码进行查看。因为这里Proxy0是继承了Proxy的,所以进入Proxy类。
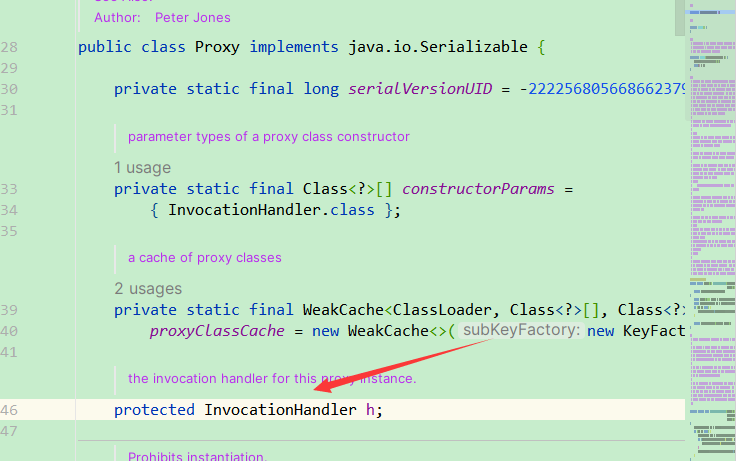
可以发现,这里的h应该就是我们传入的InvocationHadnler的对象了。也就是我们的代理类。
// Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov.
// Jad home page: http://www.kpdus.com/jad.html
// Decompiler options: packimports(3)
import blossom.project.designmode.proxy.Service;
import java.lang.reflect.*;
public final class $Proxy0 extends Proxy
implements Service
{
public $Proxy0(InvocationHandler invocationhandler)
{
super(invocationhandler);
}
public final boolean equals(Object obj)
{
try
{
return ((Boolean)super.h.invoke(this, m1, new Object[] {
obj
})).booleanValue();
}
catch(Error _ex) { }
catch(Throwable throwable)
{
throw new UndeclaredThrowableException(throwable);
}
}
public final void doSomething()
{
try
{
super.h.invoke(this, m3, null);
return;
}
catch(Error _ex) { }
catch(Throwable throwable)
{
throw new UndeclaredThrowableException(throwable);
}
}
public final String toString()
{
try
{
return (String)super.h.invoke(this, m2, null);
}
catch(Error _ex) { }
catch(Throwable throwable)
{
throw new UndeclaredThrowableException(throwable);
}
}
public final int hashCode()
{
try
{
return ((Integer)super.h.invoke(this, m0, null)).intValue();
}
catch(Error _ex) { }
catch(Throwable throwable)
{
throw new UndeclaredThrowableException(throwable);
}
}
private static Method m1;
private static Method m3;
private static Method m2;
private static Method m0;
static
{
try
{
m1 = Class.forName("java.lang.Object").getMethod("equals", new Class[] {
Class.forName("java.lang.Object")
});
m3 = Class.forName("blossom.project.designmode.proxy.Service").getMethod("doSomething", new Class[0]);
m2 = Class.forName("java.lang.Object").getMethod("toString", new Class[0]);
m0 = Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);
}
catch(NoSuchMethodException nosuchmethodexception)
{
throw new NoSuchMethodError(nosuchmethodexception.getMessage());
}
catch(ClassNotFoundException classnotfoundexception)
{
throw new NoClassDefFoundError(classnotfoundexception.getMessage());
}
}
}
那么到此为止我们就大概知道JDK动态代理的实现了。
我们现在来手写一个JDK动态代理。
手写一个JDK动态代理
CGLIB动态代理
CGLIB(Code Generation Library)是一个功能强大的高性能代码生成库,它允许在运行时动态地扩展Java类和实现Java接口。在代理模式中,CGLIB常被用于实现动态代理,特别是当被代理的对象没有实现任何接口时。
实现原理
CGLIB动态代理通过继承要代理的类并在运行时生成子类来实现。CGLIB通过拦截所有对代理对象的方法调用,将这些调用转发到一个方法拦截器(Method Interceptor)中,从而实现代理逻辑。
要使用CGLIB,需要引入CGLIB库。如果你使用Maven,可以添加以下依赖:
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
// 被代理的类(不需要实现接口)
class RealService {
public void doSomething() {
System.out.println("Doing something in RealService");
}
}
// 方法拦截器
class ServiceMethodInterceptor implements MethodInterceptor {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before method " + method.getName());
Object result = proxy.invokeSuper(obj, args);
System.out.println("After method " + method.getName());
return result;
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(RealService.class);
enhancer.setCallback(new ServiceMethodInterceptor());
RealService proxyService = (RealService) enhancer.create();
proxyService.doSomething();
}
}
优点
- 不需要接口:与JDK动态代理不同,CGLIB可以代理没有实现任何接口的类。
- 高性能:CGLIB使用字节码生成技术,生成的代理类性能通常比JDK动态代理高。
缺点
- 外部依赖:使用CGLIB需要引入CGLIB库。
- 无法代理final方法:由于CGLIB通过继承方式实现代理,因此无法代理final修饰的方法。
- 可能的类加载问题:在某些应用服务器中,CGLIB动态生成的类可能导致类加载器的问题。
适用场景
CGLIB代理非常适合以下场景:
- 需要代理的对象没有实现任何接口。
- 需要最大化代理性能。
在Spring框架中,当AOP需要代理没有实现接口的Bean时,通常会使用CGLIB代理。
代理模式实现多数据源切换
我们知道项目开发的时候一般会用到多数据源,而多数据源的实现也是依赖于我们的代理模式。
对于多数据源的切换,我们得考虑如下几点:
- 当前线程切换数据源不会影响其他线程
- 切换数据源应该在调用实际操作的数据库方法之前执行
- 当前线程处理完毕之后应该恢复为使用默认数据源
按照如上的几点,我们可以写出如下的代码:
首先创建一个动态数据源类,其中使用ThreadLocal来实现线程隔离切换数据源。
public class DynamicDataSource {
public final static String DEFAULE_DATA_SOURCE = "DB_2022";
private final static ThreadLocal<String> local = new ThreadLocal<String>();
private DynamicDataSource(){}
public static String get(){return local.get();}
public static void reset(){
local.set(DEFAULE_DATA_SOURCE);
}
public static void set(String source){local.set(source);}
public static void set(int year){local.set("DB_" + year);}
}
然后我们实现InvocationHandler接口。
要做的就是在执行具体的被代理增强的方法之前切换一下数据源即可。
public class UserServiceDynamicProxy implements MyInvocationHandler {
private SimpleDateFormat yearFormat = new SimpleDateFormat("yyyy");
Object proxyObj;
public Object getInstance(Object proxyObj) {
this.proxyObj = proxyObj;
Class<?> clazz = proxyObj.getClass();
return MyProxy.newProxyInstance(new MyClassLoader(),clazz.getInterfaces(),this);
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
before(args[0]);
Object object = method.invoke(proxyObj,args);
after();
return object;
}
private void after() {
System.out.println("Proxy after method");
//还原成默认的数据源
DynamicDataSource.reset();
}
//target 应该是订单对象Order
private void before(Object target) {
try {
//进行数据源的切换
System.out.println("Proxy before method");
//约定优于配置
Long time = (Long) target.getClass().getMethod("getCreateTime").invoke(target);
Integer dbRouter = Integer.valueOf(yearFormat.format(new Date(time)));
System.out.println("静态代理类自动分配到【DB_" + dbRouter + "】数据源处理数据");
DynamicDataSource.set(dbRouter);
}catch (Exception e){
e.printStackTrace();
}
}
}
public class DbRouteProxyTest {
public static void main(String[] args) {
try {
User user = new User();
// user.setCreateTime(new Date().getTime());
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd");
Date date = sdf.parse("2023/03/01");
user.setCreateTime(date.getTime());
IUserService orderService = (IUserService)new UserServiceDynamicProxy().getInstance(new UserService());
// IOrderService orderService = (IOrderService)new UserServiceStaticProxy(new UserService());
orderService.createUser(user);
}catch (Exception e){
e.printStackTrace();
}
}
}
区别
JDK动态代理和CGLIB动态代理是Java中实现动态代理的两种主要方法,它们各有特点和适用场景。下面详细比较这两种动态代理方式:
JDK动态代理
底层实现
- JDK动态代理是基于接口的代理方式,它使用Java原生的反射API实现代理功能。
- 代理对象是在运行时动态生成的,它们实现了目标对象所实现的接口。
- JDK动态代理使用java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来创建和管理代理。
优点
- 接口导向:只要目标对象实现了接口,就能使用JDK代理。
- 无需第三方依赖:使用标准Java API,不需要引入额外的库。
- 更轻量级:不需要创建新的类文件,比CGLIB消耗的资源更少。
缺点
- 仅限接口:只能代理实现了接口的类,对于没有实现接口的类不能直接使用。
- 性能问题:反射操作相比直接方法调用有性能开销。
CGLIB动态代理
底层实现
- CGLIB(Code Generation Library)是一个强大的高性能代码生成库,它在运行时动态生成目标对象的子类。
- 代理对象是目标对象的子类,它覆盖了目标对象的方法。
- CGLIB通过操作字节码实现代理,使用了net.sf.cglib.proxy.Enhancer和net.sf.cglib.proxy.MethodInterceptor等类。
优点
- 无需接口:可以代理没有实现任何接口的类。
- 性能较好:在代理类的生成和方法调用方面,通常比JDK动态代理快。
- 灵活性:提供了比JDK更多的代理控制功能。
缺点
- 第三方依赖:需要引入CGLIB库。
- 类的生成:动态生成的代理类是目标类的子类,如果目标类是final的,就无法使用CGLIB代理。
- 可能的兼容性问题:CGLIB动态生成的类可能会和某些JVM不兼容。
总结
- 选择JDK代理还是CGLIB代理? 如果目标对象实现了接口,推荐使用JDK代理,因为它更简单,不需要额外依赖,并且资源消耗较少。如果目标对象没有实现接口,或者你需要一个功能更强大、性能更高的代理,可以选择CGLIB代理。
- 性能考虑:虽然通常认为CGLIB性能优于JDK代理(尤其是在代理类的初始化阶段),但在实际应用中,这种性能差异可能非常小,不足以成为选择代理方式的决定性因素。代码的清晰性和维护性通常更为重要。
在实际的软件开发中,具体选择哪种代理方式取决于具体的应用场景和需求。在Spring框架中,当AOP代理需要被应用时,如果目标对象实现了接口,默认会使用JDK动态代理;如果目标对象没有实现接口,或者显式配置使用CGLIB代理,则会使用CGLIB。
原型模式
原型模式是一种创建型设计模式,它使得一个对象能够通过复制现有的实例来创建新的实例,而无需知道相应类的具体实现。在原型模式中,被复制的实例就是所谓的“原型”,这种模式通常涉及到实现一个克隆(Clone)操作。
作用
- 高效的对象复制:允许快速地创建对象副本,特别是在创建新实例的成本比较高时(例如,通过数据库读取)。
- 避免构造函数的约束:不需要与对象的类耦合,也无需知道如何正确地创建对象。
- 动态添加或减少产品:可以在运行时通过克隆已有的原型来增加或减少产品类别。
在Java中,原型模式通常是通过实现Cloneable接口和重写Object类中的**clone()**方法来实现的。
// 实现Cloneable接口
public class Prototype implements Cloneable {
private String value;
public Prototype(String value) {
this.value = value;
}
public String getValue() {
return value;
}
// 重写clone方法
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class PrototypeDemo {
public static void main(String[] args) {
try {
Prototype prototype = new Prototype("Original");
Prototype clone = (Prototype) prototype.clone();
System.out.println(prototype.getValue()); // 输出: Original
System.out.println(clone.getValue()); // 输出: Original
// 修改克隆的值
clone.setValue("Cloned");
System.out.println(prototype.getValue()); // 输出: Original
System.out.println(clone.getValue()); // 输出: Cloned
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
在这个例子中,Prototype类实现了Cloneable接口,并重写了clone()方法。这允许创建Prototype对象的副本。PrototypeDemo类展示了如何使用原型模式来创建对象的副本。
注意事项
- 深拷贝与浅拷贝:Java中的**clone()方法默认是浅拷贝,如果对象包含对其他对象的引用,这些引用将被复制,但引用的对象不会被复制。在需要深拷贝的情况下,应该在clone()**方法中显式地复制这些对象。
- Cloneable接口:Cloneable接口本身不包含任何方法,它是一个标记接口,用于指示类的实例是可克隆的。如果一个类没有实现Cloneable接口而调用了clone()方法,将抛出CloneNotSupportedException异常。
浅克隆
下面是一个演示浅克隆问题的Java示例。在这个示例中,我将创建一个包含引用类型字段的类,并展示在浅克隆过程中这个引用类型字段如何被处理,从而导致克隆对象和原始对象共享相同的引用类型字段。
class RefType {
private int data;
public RefType(int data) {
this.data = data;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
}
class ShallowCloneExample implements Cloneable {
private RefType refType;
public ShallowCloneExample(RefType refType) {
this.refType = refType;
}
// 实现浅克隆
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public RefType getRefType() {
return refType;
}
public static void main(String[] args) {
try {
RefType refType = new RefType(100);
ShallowCloneExample original = new ShallowCloneExample(refType);
ShallowCloneExample cloned = (ShallowCloneExample) original.clone();
System.out.println("Original object refType data: " + original.getRefType().getData()); // 输出: 100
System.out.println("Cloned object refType data: " + cloned.getRefType().getData()); // 输出: 100
// 修改原始对象的引用类型字段
refType.setData(200);
// 因为是浅克隆,所以克隆对象的refType字段也被改变了
System.out.println("Original object refType data (after modification): " + original.getRefType().getData()); // 输出: 200
System.out.println("Cloned object refType data (after modification): " + cloned.getRefType().getData()); // 输出: 200
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
在这个例子中,ShallowCloneExample类包含一个名为refType的引用类型字段。这个类实现了Cloneable接口,并重写了**clone()**方法来提供浅克隆功能。
- 当我们修改原始对象original的refType字段时,克隆对象cloned的refType字段也会受到影响,因为在浅克隆中,对象的引用类型字段只是引用被复制,而不是引用的对象本身。
- 你也可以使用List集合去模拟,拷贝对象的时候由于浅拷贝导致两个对象使用同一个List集合从而导致的意外是比较常见的。
这正是浅克隆的问题所在:如果对象包含引用其他对象的字段,这些字段的内容不会被克隆,而是两个对象(原始对象和克隆对象)将共享同一个引用。这可能导致意外的行为,尤其是在涉及可变对象时。
深克隆
要解决浅克隆带来的问题,我们可以实现深克隆(Deep Clone)。在深克隆过程中,不仅克隆对象本身,还会克隆它所引用的所有对象。这样,克隆出的对象与原始对象在引用类型上不再共享同一个实例。
下面是实现深克隆的示例代码,包括对引用类型成员的深度复制:
import java.io.*;
class RefType implements Serializable {
private int data;
public RefType(int data) {
this.data = data;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
}
class DeepCloneExample implements Serializable {
private RefType refType;
public DeepCloneExample(RefType refType) {
this.refType = refType;
}
// 实现深克隆
public DeepCloneExample deepClone() {
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (DeepCloneExample) ois.readObject();
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
public RefType getRefType() {
return refType;
}
public static void main(String[] args) {
RefType refType = new RefType(100);
DeepCloneExample original = new DeepCloneExample(refType);
DeepCloneExample cloned = original.deepClone();
System.out.println("Original object refType data: " + original.getRefType().getData()); // 输出: 100
System.out.println("Cloned object refType data: " + cloned.getRefType().getData()); // 输出: 100
// 修改原始对象的引用类型字段
refType.setData(200);
// 检查克隆对象的refType字段是否受到影响
System.out.println("Original object refType data (after modification): " + original.getRefType().getData()); // 输出: 200
System.out.println("Cloned object refType data (after modification): " + cloned.getRefType().getData()); // 输出: 100
}
}
在这个例子中,我们使用了序列化和反序列化来实现深克隆。这种方法要求被克隆的对象以及它引用的所有对象必须实现Serializable接口。
- deepClone方法首先将对象写入一个ByteArrayOutputStream(通过ObjectOutputStream),然后从这个流中读回(通过ObjectInputStream),从而实现了对象的深度复制。
- 在main方法中,我们修改了原始对象original的refType字段后,检查了克隆对象cloned的refType字段。可以看到,克隆对象的refType字段并没有随着原始对象的修改而改变,这证明了深克隆的效果。
注意事项
- 使用序列化/反序列化进行深克隆要求所有涉及的类(包括嵌套引用的类)都必须实现Serializable接口。
- 这种深克隆方法虽然简单,但可能不适用于所有情况,特别是当对象结构非常复杂或性能要求较高时。在这些情况下,可能需要更细致地控制克隆过程。
- 而且在单例模式中我们也提到了,如果你使用到了序列化,是有可能破坏单例的。
原型模式破坏单例与解决
特别注意:我们知道在spring中可以选择类的类型,也就是选择单例/原型。
因此,这两个模式本身就是冲突的。只能二选一,这也就是为什么spring中分别提供了两种模式,而不是提供一个:单例原型类型。
原型模式有可能破坏单例模式。当一个单例类实现了克隆(Cloneable)接口并重写了clone方法时,克隆操作可能会创建单例对象的多个副本,从而破坏单例的唯一性。
下面是一个展示原型模式如何破坏单例的示例代码:
javaCopy code
class Singleton implements Cloneable {
private static Singleton instance = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return instance;
}
@Override
protected Object clone() throws CloneNotSupportedException {
// 调用Object类的clone方法
return super.clone();
}
}
public class SingletonCloneTest {
public static void main(String[] args) {
try {
Singleton singleton1 = Singleton.getInstance();
Singleton singleton2 = (Singleton) singleton1.clone();
System.out.println(singleton1 == singleton2); // 输出:false
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
在这个例子中,我们有一个Singleton类,它是一个标准的单例实现。但是,这个类同时实现了Cloneable接口并重写了clone方法,这使得我们可以通过克隆方法创建它的副本。在SingletonCloneTest类的main方法中,我们首先获取了单例实例singleton1,然后通过克隆创建了第二个实例singleton2。由于克隆操作创建了一个新的实例,因此singleton1和singleton2不是同一个对象,这就破坏了单例的原则。
要防止单例被克隆破坏,可以在重写的clone方法中抛出异常,或者直接返回单例实例:
javaCopy code
@Override
protected Object clone() throws CloneNotSupportedException {
// 抛出异常,阻止克隆
throw new CloneNotSupportedException("Cannot clone a singleton.");
// 或者返回单例实例
// return instance;
}
这种方式可以确保即使单例类实现了Cloneable接口,也不会通过克隆创建出多个实例,从而维护单例的唯一性。
总结
在JDK中,很多类都是用了原型模式。
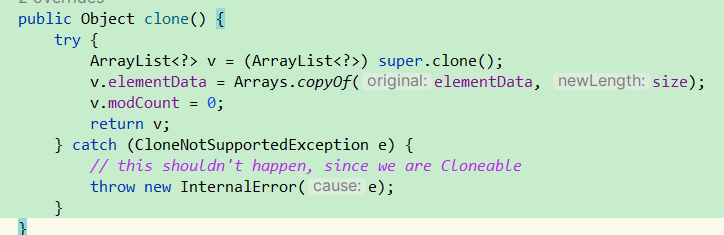
首先是ArrayList中的clone方法。这就是一个深拷贝。
再来看看HashMap。
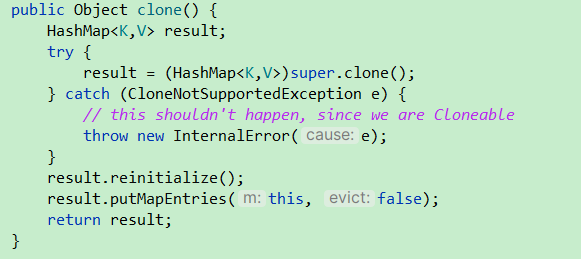
一句话概括深浅拷贝的区别的话:浅拷贝就是拷贝引用,深拷贝拷贝的就是值。
使用场景
- 需要大量相似对象时:当需要创建大量相似的对象,并且创建过程成本较高时,使用原型模式可以提高效率。
- 动态加载或运行时构建对象时:在运行时动态加载类或构建复杂对象的场景下,可以利用原型模式快速创建对象副本。
- 需要解耦对象创建和系统的场合:原型模式可以将对象的创建过程从具体的类解耦,系统只需关心对象的接口而不是具体类。
- 作为对象的备份机制:在需要保存对象状态的场合,原型模式可以作为一种备份机制,通过克隆来保存对象的当前状态。
缺点
- 深拷贝和浅拷贝问题:原型模式中最主要的问题是正确实现深拷贝和浅拷贝。浅拷贝可能导致共享对象的问题,而深拷贝可能是一个复杂且成本较高的操作。
- 复杂对象的克隆:如果对象结构非常复杂,特别是存在循环引用时,实现深克隆会非常困难。
- 破坏单例模式:如果单例对象实现了克隆方法,原型模式可能会破坏单例模式的原则。
- 隐藏复杂性:原型模式隐藏了对象创建的细节,这在一定程度上也隐藏了系统的复杂性,可能会给维护和调试带来问题。
优点:
- 高效的对象复制:原型模式允许快速地复制或克隆对象。对于一些创建成本较高的对象(如需要进行复杂计算或网络请求的对象),使用原型模式可以提高性能。
- 减少重复代码:通过克隆已有的实例来创建新的实例,可以减少重复的初始化代码。这对于创建过程复杂或配置繁多的对象尤其有用。
- 动态增加或减少产品类:原型模式允许在运行时通过克隆已有的原型来动态地添加或删除产品的类别,提高了系统的灵活性。
- 解耦代码和类:客户代码可以在不知道对象具体类型的情况下生成对象的实例,只需知道对象实现了克隆接口并且如何获取到这些对象。
- 原型的独立性:原型模式允许客户仅依赖于对象的接口而不是具体实现,从而使得客户端和具体类之间解耦,增加了代码的可维护性和扩展性。
- 作为配置的一部分:原型对象可以作为系统的一部分配置,可以动态地更改现有行为,而不需要更改代码。