一、深度理解二叉树的前中后序遍历
二叉树遍历框架如下:
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
// 前序位置
traverse(root->left);
// 中序位置
traverse(root->right);
// 后序位置
}
先不管所谓前中后序,单看 traverse 函数,你说它在做什么事情?
1.1 链表前后序
其实它就是一个能够遍历二叉树所有节点的一个函数,和你遍历数组或者链表本质上没有区别:
//递归遍历单链表
void traverse(ListNode* head) {
if (head == nullptr) {
return;
}
//前序位置
traverse(head -> next);
//后序位置
}所谓前序位置,就是刚进入一个节点(元素)的时候,后序位置就是即将离开一个节点(元素)的时候,如下图:

如果让你倒序打印一条单链表上所有节点的值,你怎么搞?
实现方式当然有很多,但如果你对递归的理解足够透彻,可以利用后序位置来操作:
// 递归遍历单链表,倒序打印链表元素
void traverse(ListNode *head) {
if (head == NULL) {
return;
}
traverse(head->next);
// 后序位置
print(head->val);
}
1.2 二叉树前中后序
我们在递归遍历的二叉树中不同位置进行处理时,实际上就是在下面三个位置进行处理

反映到整颗树上,如下图:

同时我们要知道,二叉树在进行遍历时,处理流程如下:
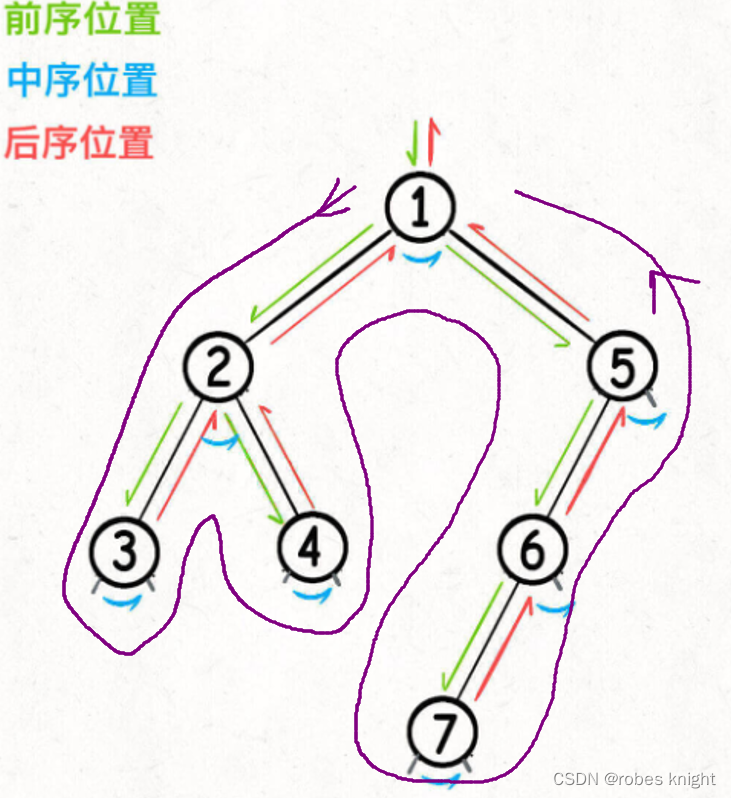
1.2.1 前序
前序如下图:
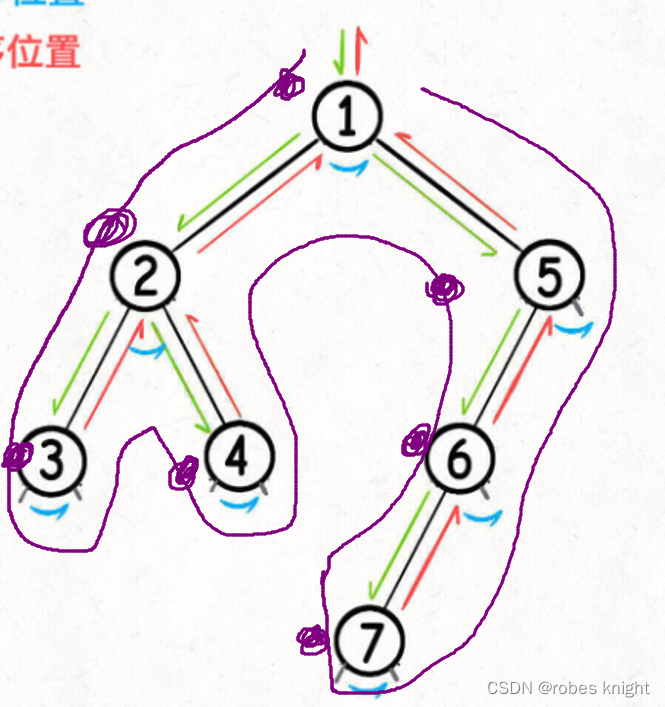
由此我们可以看见,如果我们在前序位置进行处理(每个节点左侧),在第一次经过一个节点的时候就可以获取其信息,但无法用来获取子树信息,因此前序一般用来遍历
1.2.2 后序
后序如下图:

由此我们可以看见,如果我们在后序位置进行处理(每个节点右侧),那么当我们第一次处理一个节点的时候, 其左右的子节点都被处理过了,也就是我们可以在后序获取子树的所有信息了
1.2.3 中序
中序主要和回溯有关,我们一般在中序处进行撤回
二、图论
图论中最重要的就是遍历,一般都是用到dfs进行回溯(bfs属于层序遍历,这里先不和为一谈)
回溯框架为:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
(选择是否处理)
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}为什么要在前序位置判断是否终止?
因为前序位置时是每一节点第一次到达的位置,在这里判断最省时间
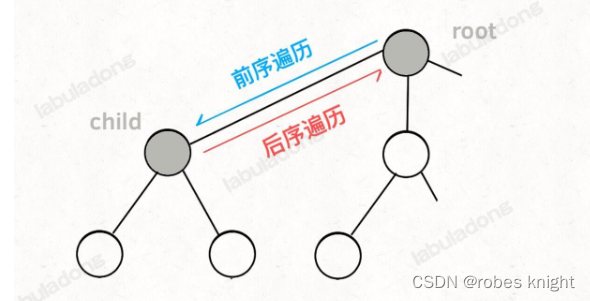
一般以搜索为目的的dfs,都是从上往下思考,从根节点往下搜索,backtracking(路径,选择列表)中做的选择一般都是子节点
三、动态规划
为了方便对比,我们以记忆化搜索为主要研究对象
动态规划就是把大问题抽象为多个小问题,然后用选择连接多个小问题,如下图:

我们以下面一段动态规划代码进行解释:
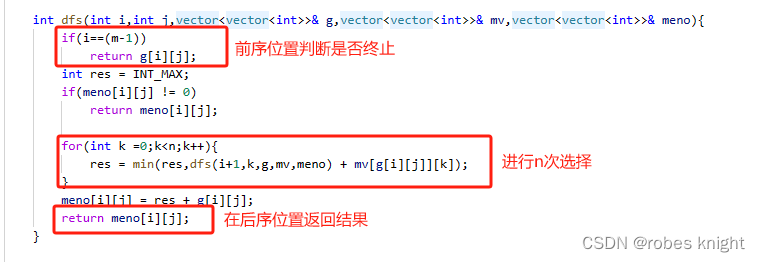
由于我们的决策要在遍历完所有选择之后再做,因此我们在后序位置进行状态更新
在动态规划中,我们一般都是从下往上思考(上面这题除外,有些题也可以从上往下,只是说我们从下往上状态转移方程更好思考),每个dfs中做的选择一般都是上一层的节点