hadoop更适合在liunx环境下运行,会节省后期很多麻烦,而用虚拟器就太占主机内存了,因此后面我们将把hadoop安装到wsl后进行学习,后续学习的环境是Ubuntu-16.04 (windows上如何安装wsl)
千万强调,创建完hadoop用户后,所有命令都是在hadoop用户中执行的,即使我们后面给他权限了,但是有的命令还是要加sudo!
千万强调,创建完hadoop用户后,所有命令都是在hadoop用户中执行的,即使我们后面给他权限了,但是有的命令还是要加sudo!
千万强调,创建完hadoop用户后,所与命令都是在hadoop用户中执行的,即使我们后面给他权限了,但是有的命令还是要加sudo!
一 安装Hadoop及基础配置
关于安装时出现的部分问题
- 如何切换用户
su 用户名 #linux下切换用户
- ssh到本地时出现Permission denied (publickey).
sudo vim /etc/ssh/sshd_config #修改配置文件
将文件中的PasswordAuthentication 的值no改为yes
- SSH设置和密钥生成各步骤详解
$ ssh-keygen -t rsa #采用rst算法生成一对秘钥(公钥id_rsa.pub,私钥id_rsa)
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #本地ssh公钥复制到远程服务器的.ssh/authorized_keys中,这样就可以免密登录了
$ chmod 0600 ~/.ssh/authorized_keys #给足够的权限
- java配置到环境变量中
我选择的是jdkl1.8.0_411,用原先博客上的配置方法并不能检测到java,换成下面的方式即可:
export JAVA_HOME=/usr/java/jdk1.8.0_411
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
本地无法访问hadoop服务
按照博客的操作最后发现会连接失败,原因就是因为hadoop3.x之后将默认的端口50070改为了9870,才导致链接失败
jps或者java版本不显示
先确定是否成功配置了环境变量(即/etc/profile文件下有没有配置java路径)
有的话,再激活一次环境变量试试 source /etc/profile
- 启动hadoop程序显示localhost: ssh: connect to host localhost port 22: Connection refused
原因是ssh服务没有开启,开启一下即可
sudo systemctl start ssh
二 配置Hadoop的YARN环境
yarn是hadoop生态中主要负责集群的资源管理和作业调度,可以理解成hadoop生态中的话事人。
首先 依旧是移动到hadoop的基础配置文件路径下
cd /usr/local/hadoop/etc/hadoop
然后修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
然后修改yarn-site.xml文件,配置 NodeManager 上运行的附属服务
<configuration>
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可
以在
Yarn 上运行 MapRedvimuce 程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
最后启动yarn服务
cd ${HADOOP_HOME}/sbin/ #移动到对应文件夹下,这个环境变量你是之前已经配置好了的
./start-yarn.s #启动服务
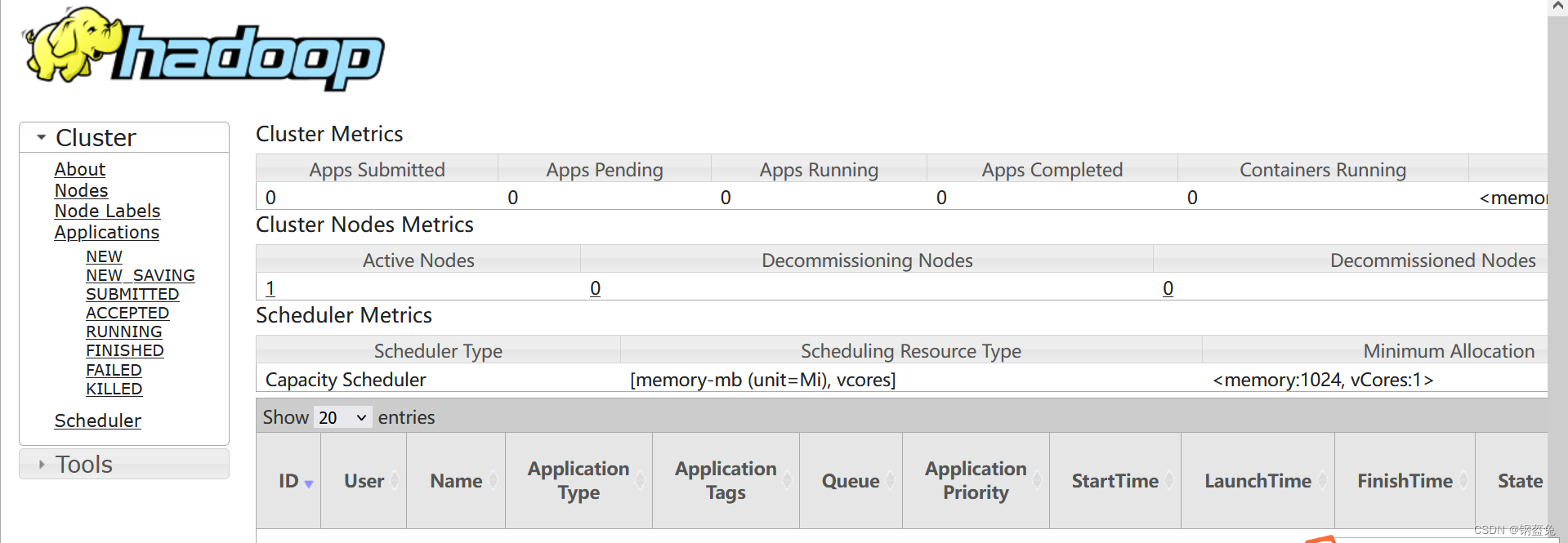
检验是否成功启动yarn服务,成功的话会出现下面的页面
http://localhost:8088/
三 小试牛刀
好嘞,现在hadoop的基础配置已经完全结束了,现在让我们体验一个小案例,Hadoop自带的hadoop-mapreduce-examples-x.jar中包含一些示例程序,位于
${HADOOP_HOME}/share/hadoop/mapreduce 目录。我们将直接利用内置的程序计算PI值:
cd ${HADOOP_HOME}/share/hadoop/mapreduce/ #移动到路径存放内置程序的路径下
hadoop jar hadoop-mapreduce-examples-3.3.5.jar pi 2 10 #启动程序,具体命令取决于你所安装的hadoop版本

四 后续总结
上面的流程全都走了一遍之后,后面我们就可以直接愉快的启动和关闭
cd ${HADOOP_HOME}/sbin #后续命令都是在这个路径下完成的
#开启hadoop服务
./start-dfs.sh
./start-yarn.sh
#关闭hadoop服务
./stop-dfs.sh
./stop-yarn.sh